1. Introduction
Steganography [
1] is a technique for sending secret messages without being perceived by others. The embedding process is generally symmetric with the extracting process. The sender uses the key to hide the secret message in the carrier, then the receiver uses the key to obtain the secret message from the carrier. Social networks are ideal carriers for steganography because of the wide geographical distribution of users, rich usage scenarios, and large data volumes involved. It is worth noting that covert communication in social networks is also carried out in a symmetric way. This allows the sender and receiver to achieve covert communication without establishing a peer-to-peer channel, and the communication behaviors are difficult for a third party to notice in particular. This ensures the concealment of the communication and the security of both the sender and the receiver. The study of the use of steganographic methods in social networks has important theoretical and practical value. It has attracted widespread attention from scholars in this field.
The carriers of steganographic methods based on social networks include image, text, audio, video, behavior, etc. Steganography can be grouped into carrier selection, carrier modification, and carrier synthesis (generation) according to different embedding principles [
2]. Steganography based on social network carrier selection includes image selection steganography [
3,
4], text selection steganography [
5,
6], and video selection steganography [
7,
8]. When sending secret message, this type of method is used for finding a carrier that conforms to the secret message through the constructed carrier database [
9]. It does not modify the carrier data and can effectively resist attacks of steganalysis, but its low embedding capacity is still a challenge. The steganographic methods used for carrier modification based on social networks consist of image modification steganography [
10,
11], text modification steganography [
12], audio modification steganography [
13], and video modification steganography. They make use of the covert features of human organs and the redundant features of digital carriers to embed a secret message into the carriers by slightly modifying the social network carriers [
14]. These methods are characterized by a high embedding capacity, robustness, and anti-detection performance. With the development of machine learning, however, the steganographic methods used for carrier modification may face new threats [
15,
16,
17,
18]. Social network-based generative carrier steganography methods are grouped into generative image steganography [
19], generative text steganography [
20,
21], generative audio steganography [
22], etc. Early generative methods conformed to statistical features, but the limitations of algorithms and computational power lead to content that does not conform to common sense and can be easily recognized [
23]. With the development of artificial neural networks (ANN) and the increase in computing power, the statistical features and contents of the generated stego are more natural and their quality has been significantly improved. However, Yang et al. recently pointed out that the better the quality of the stego generated, the lower the concealment may be [
21]. This has caused some experts and scholars to worry.
In recent years, social networks have developed rapidly. Scholars realize that social networks not only contain huge multimedia data but also rich behaviors, such as likes, forwards, posts, comments, and shares, which can be used for covert communication. Zhang [
24] and Hu et al. [
25] used WeChat, a mainstream social software in China, to realize covert communication. Li et al. [
26] sent secret messages by reposting posts. Yang et al. [
27] embed secret message through statistical features of posts. Nechta [
28] proposed a method for covert communication through the behavior of adding friends. Wu et al. [
29,
30] performed covert communication on social networks by constructing graph structures. This type of method does not modify the carrier content, resulting in a higher robustness and invisibility. However, its embedding capacity still needs to be improved.
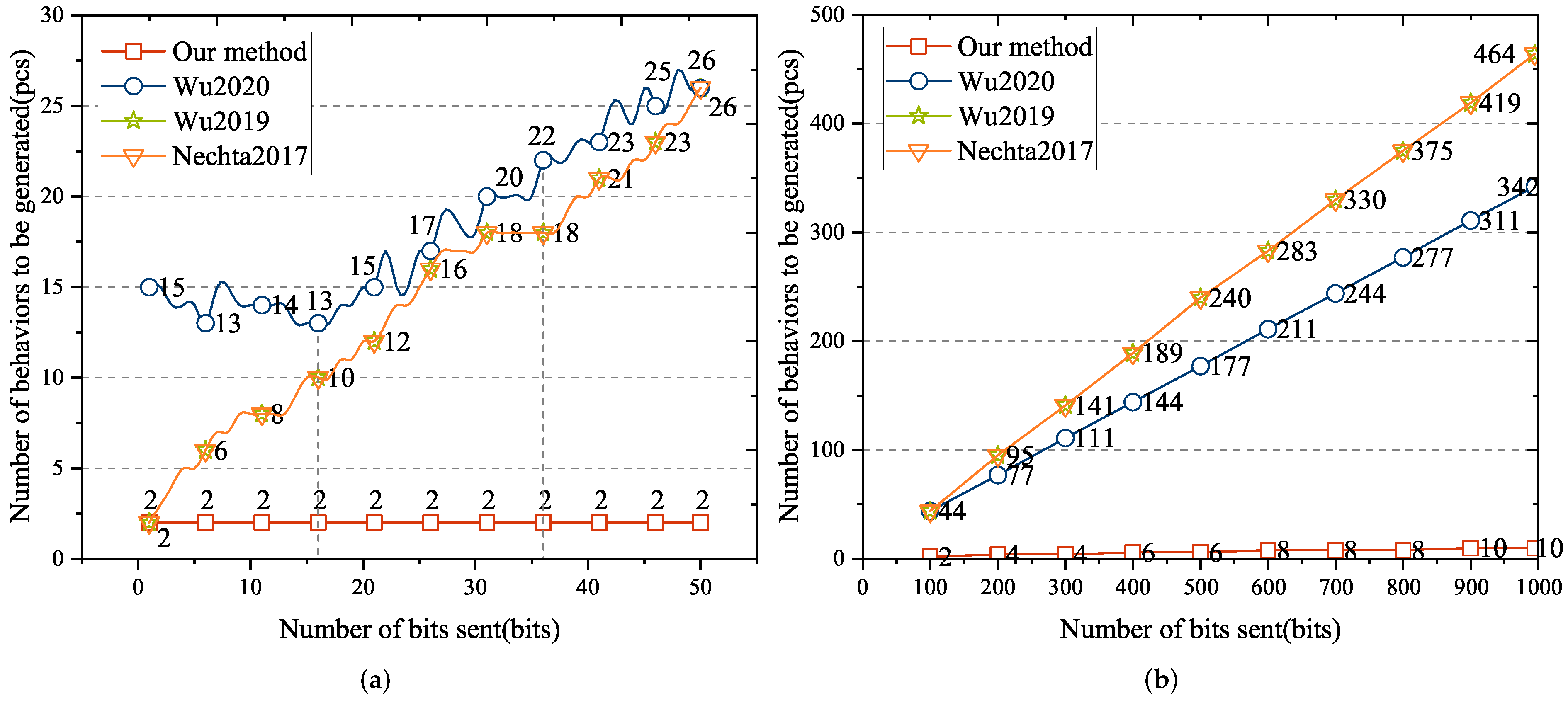
To improve the embedding capacity, this paper proposes a carrier selection high-capacity behavioral steganographic method based on timestamp modulation. The main work is as follows:
A method is proposed to indicate to the positions of mapping keywords in posts through timestamps. This method greatly improves the embedding capacity while keeping the carrier natural.
An adaptive retrieval algorithm for posts with mapping keywords is given. When the target post cannot be retrieved on a given social network, this algorithm can automatically adjust the matching parameters. This ensures that secret messages are sent successfully.
The remainder of this paper is organized as follows:
Section 2 briefly introduces related work on behavioral steganography.
Section 3 introduces the method proposed in this paper. The performance of the proposed method is analyzed in
Section 4. After that,
Section 5 gives the experimental results. Finally, we summarize the full text and discuss the direction of further research in the future.
3. Proposed Method
Firstly, this section introduces each step of the proposed method. Next, three key steps are explained in detail. Finally, the process of sending secret message is explained by an example.
In order to achieve the high embedding capacity of the behavioral steganography on social networks and at the same time ensure the naturalness of content and behaviors, we propose a symmetric covert communication method that combines the time attribute of the behavior and the carrier selection. It converts secret message into high-frequency mapping keywords and adaptively retrieves eligible keyword posts on social networks. The behavioral attributes are dynamically used to point to the positions of keywords in posts, which in turn greatly improves the embedding capacity of behavioral steganography.
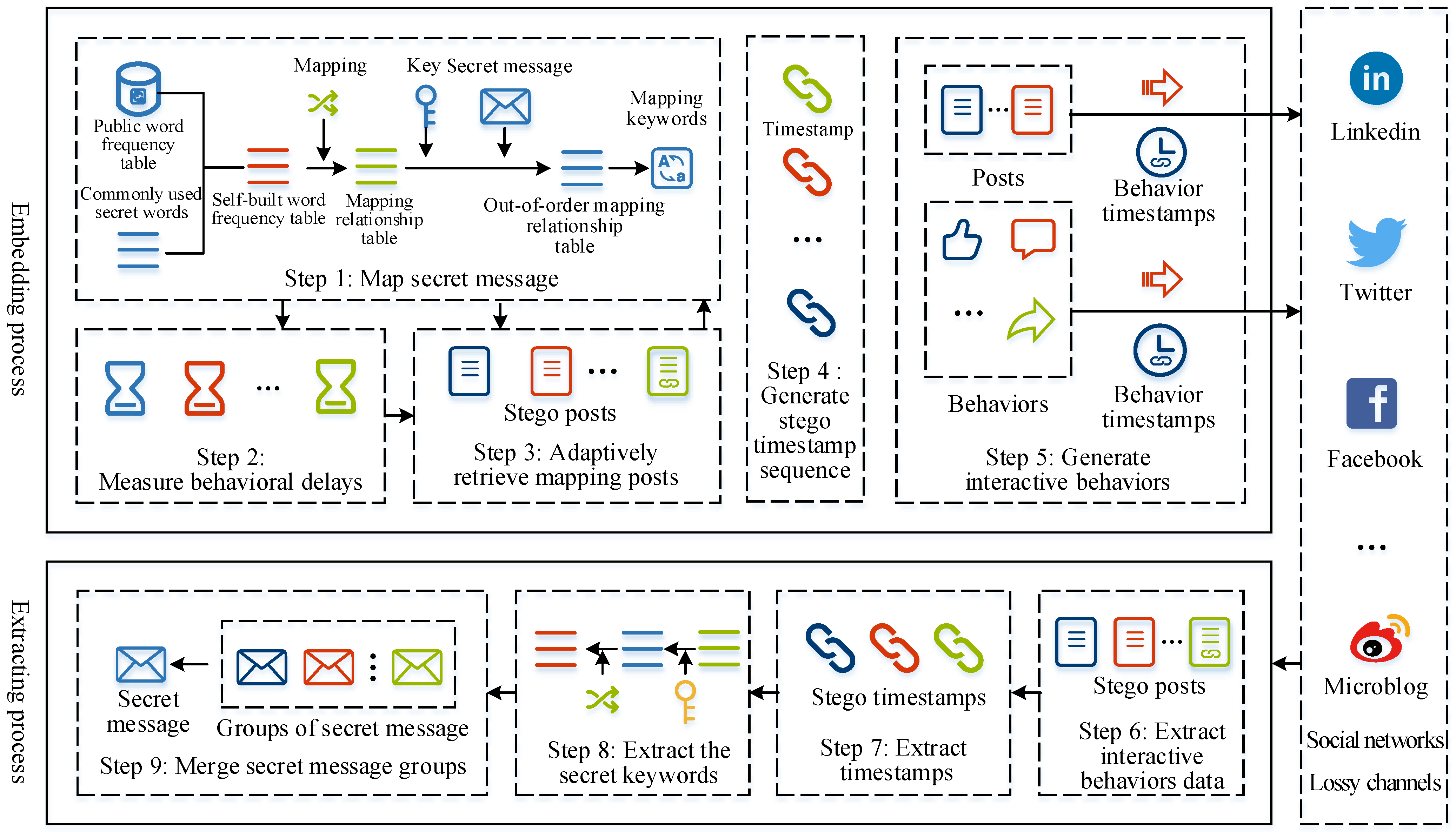
There are 9 steps in this method, as shown in
Figure 2. Steps 1–5 belong to the embedding process, and steps 6–9 belong to the extracting process.
Step 1: Map secret message. This first combines the commonly used secret words with the public word frequency table to generate a table named a self-built word frequency table. Then, a mapping relationship table is constructed by combining the self-built word frequency table with the public word frequency table. The words in the secret message are called secret keywords. Finally, the secret keywords are converted into mapping keywords by the mapping relationship table that has been disordered, which can map one word to another one. The purpose of the self-built word frequency table is to ensure that all keywords in the secret message exist in the mapping relationship table shared by the sender and receiver. The purpose of the mapping relationship table is to map a keyword in the self-built word frequency table to another keyword so as to prevent the secret message from directly appearing in the post and ensure the security of the secret message. The out-of-order mapping table is used to fine-tune the order of the keywords in the mapping relationship table according to the key. If the key does not match, the secret message cannot be extracted by the receiver.
Step 2: Measure behavioral delays. The purpose of measuring behavioral delays is to address the impact they have on timestamps. Automated interactions on social networks, behavioral delays for a while are recorded and the maximum behavioral delay is obtained.
Step 3: Adaptively retrieve mapping posts. The purpose of this step is to find a set of posts that can contain all the secret keywords. We set an initial number of keywords and group the mapping keywords into subsets according to the initial number of keywords. Each subset is called a mapping group. The post that contains one mapping group is dynamically retrieved on the social networks and the post is called a mapping post. If the mapping post that contains the mapping group is not found, the initial number of keywords is shortened and the retrieval continues. If it is retrieved, the information of the post is saved. This retrieval process does not end until all the mapping keywords are retrieved.
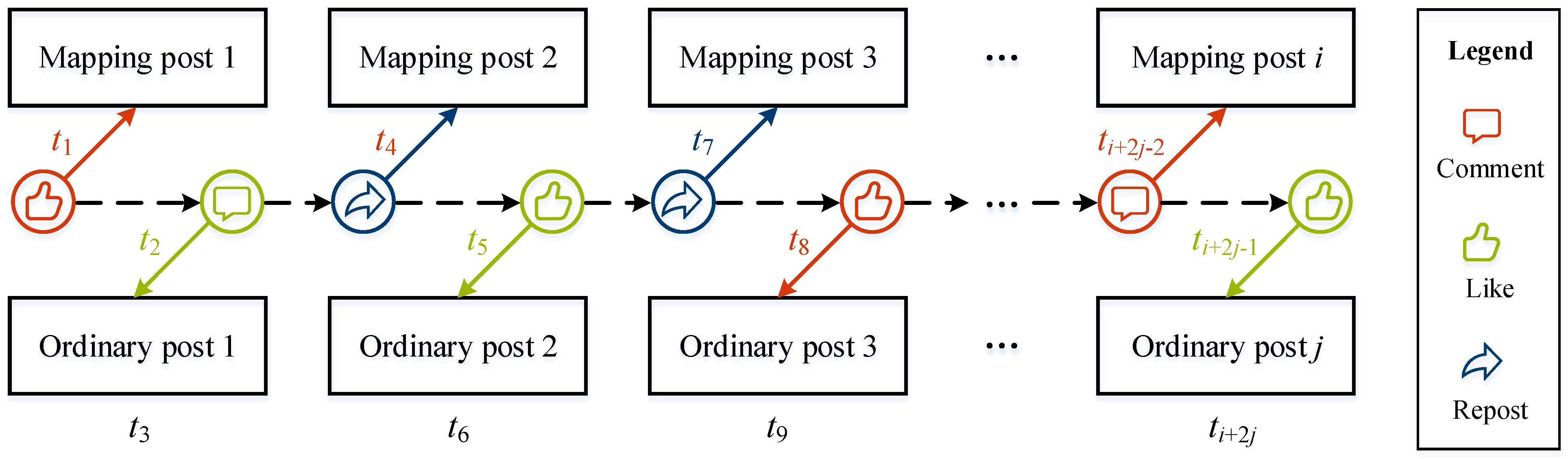
Step 4: Generate a stego timestamp sequence. The purpose of generating the stego timestamp sequence is to hide the positions of the mapping keywords in the mapping post into timestamps. The timestamp of the post that already exists on social networks is no longer affected by the behavioral delay, and this kind of post is noted as an ordinary post. To hide the positions of the mapping keywords, the accounts controlled by the sender interact with other posts. The behaviors generated in this process are called interactive behaviors. The positions of the mapping keywords in the mapping posts are specified by both the timestamp of the ordinary posts and the timestamp of the interactive behaviors, which are shown in
Figure 3. In
Figure 3, the colored font indicates the timestamps of the interactive behaviors, such as
,
, and so on, while the black font indicates the timestamp of the ordinary post, such as
,
. When hiding the positions of the mapping keywords with timestamps, the sender first extracts all the positions of mapping keywords from all the mapping groups to form a mapping position sequence and converts the mapping position sequence into a binary position string. Then, the timestamps of ordinary posts and interactive behaviors can carry a secret message of different lengths. The binary position string is divided according to their length. Finally, the split binary string is used to modulate the timestamp sequence, which is called the stego timestamp sequence.
Step 5: Generate interactive behaviors. The purpose of generating interactive behaviors is to release the stego timestamp sequence to social networks. The sender’s account interacts with mapping posts and ordinary posts at the time corresponding to the stego timestamps, generating interactive behaviors. The secret message will eventually be hidden on the social network.
The following are the steps used to extract the secret message.
Step 6: Extract interactive behavior data. The purpose of this step is to extract data from the accounts shared by the sender to extract secret keywords. According to the information such as the mapping relationship table and the number of accounts shared by the sender, the receiver extracts interactive behavior data over a period of time from the corresponding accounts of the social network. This data includes behaviors such as posted posts, reposted posts, comments, and likes.
Step 7: Extract timestamps. The purpose of extracting the timestamps is to obtain the positions of keywords. When extracting timestamp information from the interactive behavioral data, the stego timestamps are identified based on the secret key and identification fields.
Step 8: Extract the secret keywords. The positions of the keywords in the mapping posts are determined according to the mapping timestamps, and the mapping keywords are converted to secret keywords by the mapping relationship table. The embedding and extracting of a secret message is symmetric and the step is the reverse process of Step 4.
Step 9: Merge secret message groups. The secret message is extracted by merging the secret message groups.
There are three key steps in this method, which are: mapping a secret message, adaptively retrieving mapping posts, and generating a stego timestamp sequence. Next, the details of the key steps will be introduced in turn.
3.1. Map Secret Message
When sending a secret message, two problems will arise if secret keywords are carried directly by mapping posts. First, secret keywords may not be commonly used words. Even the public word frequency table may not contain certain out-of-the-way secret keywords. If they appear directly in the posts, this may cause anomalies. Second, keywords that are not frequently used have a low probability of appearing on social networks and may not be easily retrieved.
For this reason, we will take two measures to solve these two problems. On the one hand, a self-constructed word frequency table is constructed by combining the commonly used secret keywords with the public word frequency table. In other words, the self-built word frequency table contains both secret keywords and the public word frequency table. For example, when we send the Declaration of Independence as a secret message, there is a word “sufferable” that does not appear in the public word frequency table. For this reason, we have added “sufferable” to our selected public word frequency table. On the other hand, a mapping relationship is constructed between the self-built word frequency table and the public word frequency table. This is based on the principle that the commonly used secret keywords are mapped to the high-frequency words in the public word frequency table. In addition, the public word frequency table in the self-built word frequency table is mapped to the high-frequency words as much as possible. In this way, the secret keywords do not appear directly in the posts and the first problem is solved. The secret keywords are mapped as high-frequency words that are easily retrieved on social networks, and thus the second problem is solved.
The disordered mapping relationship table is denoted as
, and the secret keywords table
to be sent by the sender is converted into the mapping keywords table
by
. This process can be formalized as:
where
k denotes the key and
denotes the mapping relationship table.
The word frequency table composed of frequently used secret keywords is denoted by . The self-built word frequency table is composed of and the public word frequency table . The construction process of is shown in Algorithm 1.
In the Algorithm 1, it can be found that a small number of low-frequency words in the self-built word frequency table are ignored.
| Algorithm 1: Generation algorithm for the mapping relationship table. |
![Symmetry 14 00111 i001]() |
3.2. Adaptively Retrieve Mapping Posts
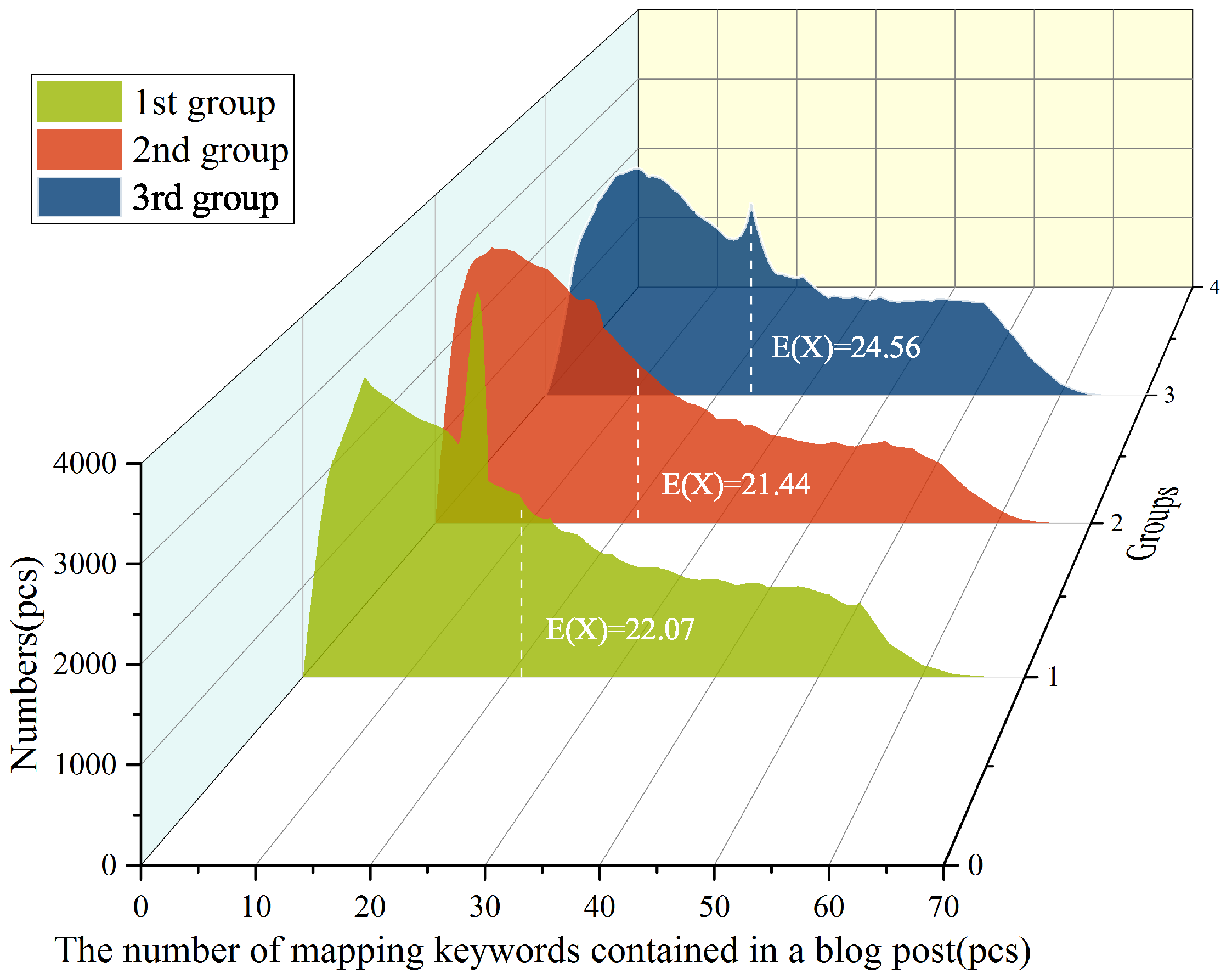
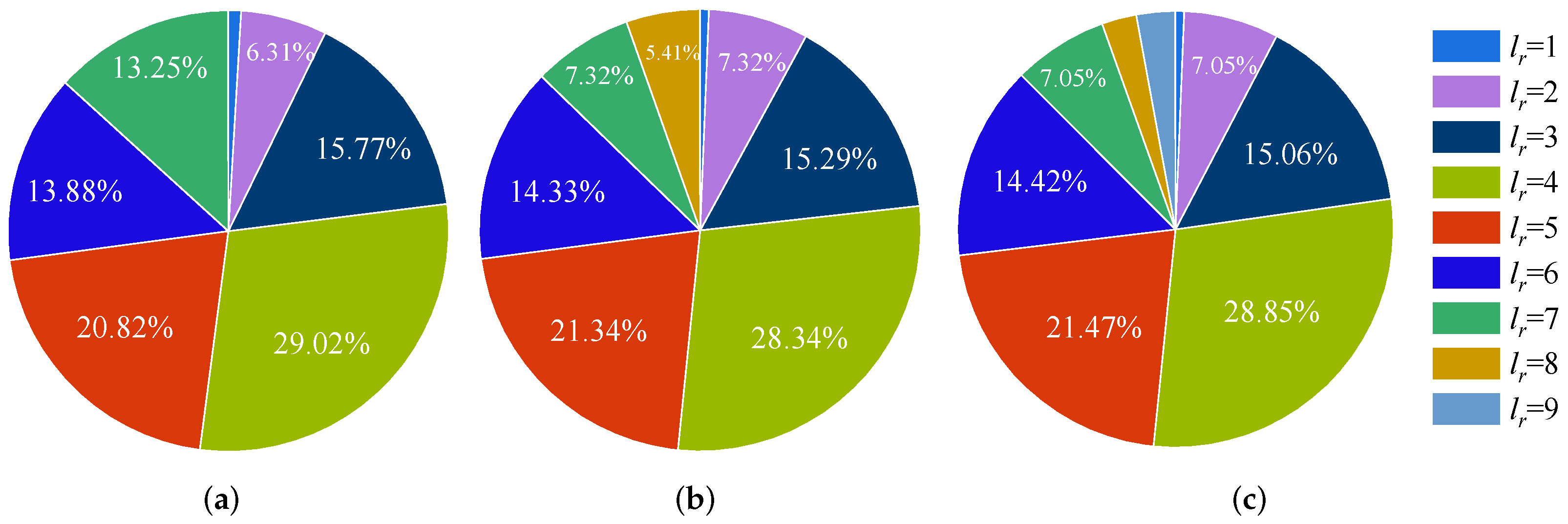
The initial number of keywords is denoted by , which is used to specify the maximum number of mapping keywords contained in a mapping post. The number of mapping keywords contained in a retrieved mapping post is often not . Its actual number of keywords is denoted by . The algorithm for adaptively retrieving mapping posts is shown in Algorithm 2.
The Algorithm 2 first takes mapping keywords from . Next, the mapping posts containing of the specified mapping keywords are retrieved on the social networks. If no keyword is found, the number of keywords searched in the previous round is subtracted by one and the retrieval continues. If a post is found, the number of keywords is set to and the retrieval continues until all the mapping keywords are hidden in the found mapping posts. If it is still not found when = 0, the retrieval fails, which rarely happens.
It is worth noting that
will affect the efficiency of retrieval. When
is too large, posts containing
mapping keywords may not be retrieved on social networks, which can lead to a decline in the number of keywords. For each reduction, the retrieval will be performed again, which will consume additional time.
| Algorithm 2: Algorithm used for adaptively retrieving mapping posts. |
![Symmetry 14 00111 i002]() |
3.3. Generate Stego Timestamp Sequence
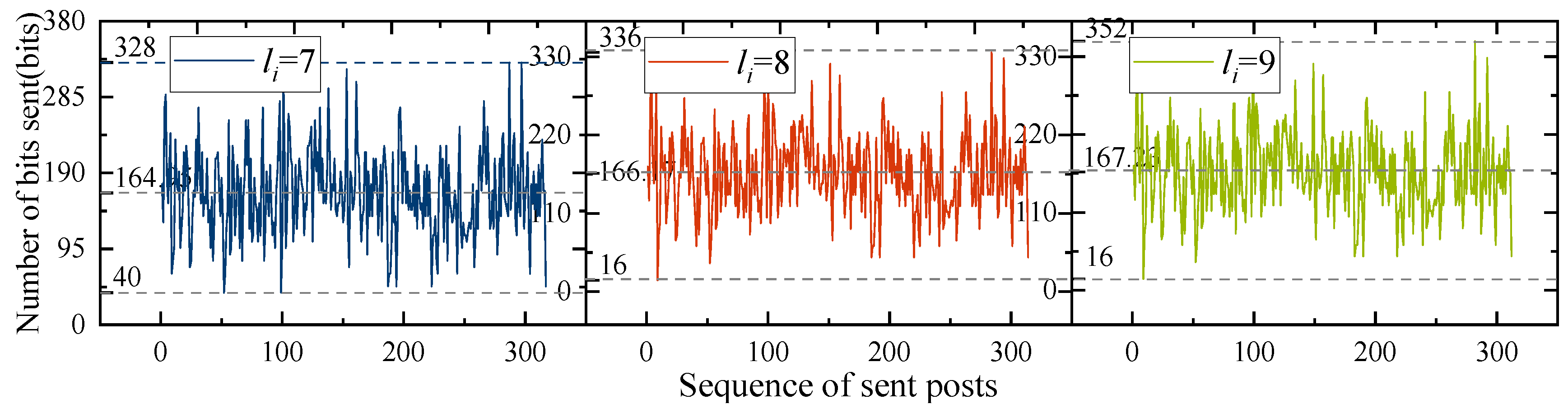
In this paper, timestamps of ordinary posts and interactive behaviors are used to hide the positions of mapping keywords. This step focuses on three issues regarding timestamps: first, the factors that influence the secret message in the timestamp cannot be extracted correctly; second, the amount of information that the timestamp can carry; third, the process by which the secret message is converted into timestamps.
To begin with, let us consider the first problem. It often happens in life that when we access a website, we may have to wait for a short period before we can see the content of the page. In fact, when posting a post on a social network, it may be necessary to wait a while for this post to be seen by other users, even if this time is very short. This situation is the behavioral delay, which may result in the secret message not being properly embedded in the timestamps. For example, a sender intends to deliver a decimal number 2 and start hiding the message at timestamp 1735150139. The sender reposts a post when the timestamp is 1735150141. However, the behavior is delayed due to a series of requests and is only recorded by the social network at timestamp 1735150142. When the secret message is extracted, the receiver subtracts 1735150142 from 1735150139 to obtain 3. At this point, the receiver extracts the wrong secret message. To solve this problem, the sender needs to measure the maximum behavioral delay
on the social networks for a while before sending the secret message. When sending a secret message, the secret message is converted to decimal and multiplied by
+ 1 to prevent errors in the secret data. The detailed analysis and data can be found in
Section 4.1.
Next, we give equations for the number of bits that can be carried by different kinds of timestamps. An interactive behavior timestamp uses
bits to encode the positions of keywords, which are calculated as follows (
denotes rounding down):
where
b denotes the last
b digits of the timestamp used to encode the positions in mapping posts. The number of bits that can be carried by the timestamp of an interactive behavior is denoted by
, and
denotes the length that can be used for encoding. Considering the existence of behavioral delays in social networks, this decimal number, if used directly to encode the message, will cause the message hidden in the timestamp to change, resulting in the secret message not being extracted correctly by the receiver. Equation (
4) gives some redundancy capability.
When sending a secret message, the secret message needs to be converted to binary and then to decimal. For this purpose, taking the logarithm of and rounding down will give the number of bits of binary that can represent.
In addition, the timestamp of an ordinary post is denoted by
. The number of bits it can carry is denoted by
, and is calculated as follows:
The timestamp when the sender is about to send a secret message is denoted by
. The minimum timestamp of a certain social network is denoted by
. When
is the earliest timestamp of this social network,
takes the maximum value.
is the timestamp of a behavior that already exists on the social network and is no longer affected by the behavior delay, so there is no need to set redundant information for this timestamp. For Twitter,
can take the maximum value when
is the timestamp of the first post on the Twitter. The timestamp for the interaction between the account controlled by the sender and the mapping post is denoted by
, and the time for interaction with the ordinary post is denoted by
. The timestamp of an ordinary post is denoted as
. If corresponding to
Figure 3,
,
, and
can be
,
, and
, respectively.
A sender is able to send a secret message by interacting with a mapping post and an ordinary post on a social network. The number of bits that these two behaviors can carry is denoted by
, and the equation is as follows:
Finally, an algorithm for the generation of the stego timestamps is given as Algorithm 3. Among the parameters, the sequence of mapping groups is denoted by
, the generated sequence of stego timestamps is denoted by
. The algorithm first calculates the number of bits that can be hidden by different types of timestamps and then generates a sequence of secret timestamps based on it.
| Algorithm 3: Algorithm used for the generation of stego timestamps. |
![Symmetry 14 00111 i003]() |
3.4. Example
In this subsection, we briefly describe the process of embedding and extracting secret messages using an example. In this example, the sender sends a secret message to the receiver on a social network. Suppose we send a secret message as “This is a secret message.” Their mapping keywords are “can”, “a”, “good”, “not”, “search”, and “.” by Algorithm 1 respectively, which form a mapping group. Suppose the minimum timestamp available for the social network carrying the secret message is 1633017600 and the timestamp for sending the secret message is 1577808000. The maximum behavioral delay of the current network is 2. The last 2 digits of the timestamp are used to convey secret messages. So,
= 1633017600,
= 1577808000,
b = 3,
d = 2. Calculated by Equations (
4)–(
7),
= 25,
= 8,
= 41. The mapping posts containing this mapping group is retrieved on social networks by Algorithm 2, and one of the results is shown in
Figure 4. The higher the frequency of the mapping keyword in the public word frequency table, the more likely the post containing the keyword is to be retrieved. The positions of the mapping keywords in the post are 9, 19, 27, 13, 22, and 30.
The positions are converted to binary and are split into three groups. The number of each group is 8, 25, 8, and then each group is converted from binary to decimal.
=
+ 37 × (
+ 1) = 1633017711,
=
= 1625835084,
=
+ 192 × (
+ 1) = 1633018687. The calculation process and data are shown in
Table 1. The mapping keywords are sent when the sender interacts with the post on the left side of
Figure 4 at 1 October 2021 00:01:51. When the sender interacts with the post to the right of
Figure 4 at 1 October 2021 00:09:36, the positions of mapping keywords are sent. Corresponding to the
Figure 3,
is equivalent to
,
is equivalent to
, and
is equivalent to
. The extracting process is the inverse of the embedding process and will not be repeated here.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}