
User Selection Approach in Multiantenna Beamforming NOMA Video Communication Systems


Abstract
:1. Introduction
2. Related Works
- (1)
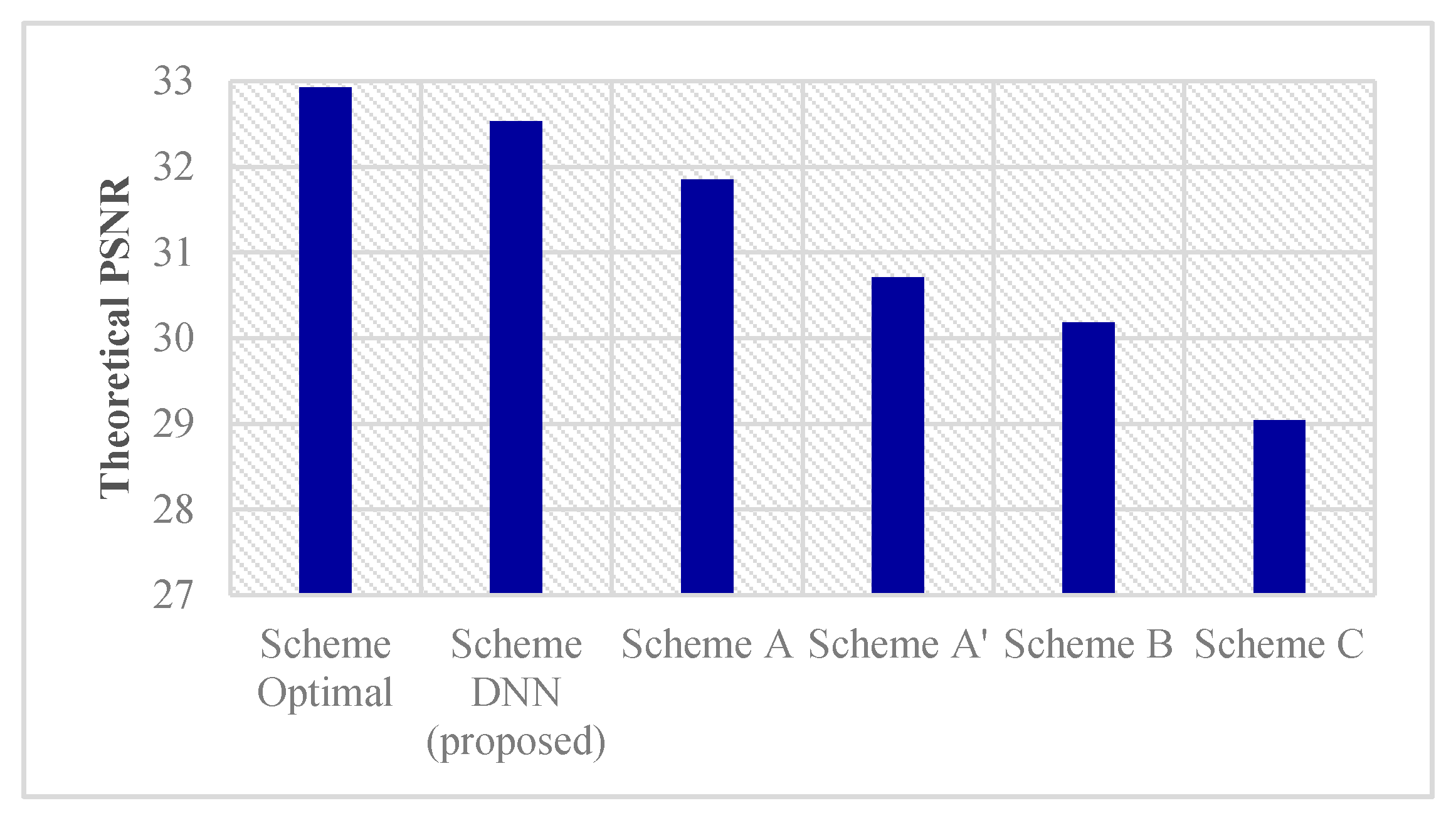
- A deep learning scheme (Scheme DNN in Section 4) to learn from the optimal scheme (Scheme Optimal) is proposed. The Scheme Optimal attempts all the combinations/permutations of K candidate users (exhaustive search) and chooses the best performing user grouping. Scheme DNN uses the Scheme Optimal results as training data. The proposed Scheme DNN achieves near optimal performance at lower complexity. It outperforms the previous suboptimal schemes proposed in [12,13].
- (2)
- A new loss function for deep learning of the user selection to deal with constraint violation is proposed. If a user is selected in both of the strong set and weak set (constraint violation), extra value is added to the cost function. This avoids post-processing after the training stage to satisfy the constraint that a user can’t be in both of the strong set and weak set and reduces the complexity. For comparison, Tseng. et. al. [25] investigated the deep leaning-based resource allocation for OFDMA/NOMA but not MIMO. Its scheme has the post-processing after the training stage to satisfy the constraints and additional complexity and latency during the runtime. The scheme in [26] modified the loss function for satisfying the constraint that each user has at least one subcarrier and thus avoid post-processing, but it deals with different constraint (a user has at least one subcarrier, not that a user can’t be in both of the strong set and weak set) in different systems (OFDMA/NOMA, not NOMA-MIMO).
- (3)
- The proposed deep learning approach for NOMA resource management crosses the physical and application layers. Previous NOMA schemes such as [4,5,6,12,27] focus on the physical layer and there is currently no deep learning-based cross-layer user selection scheme for NOMA-MIMO video systems [28,29,30].
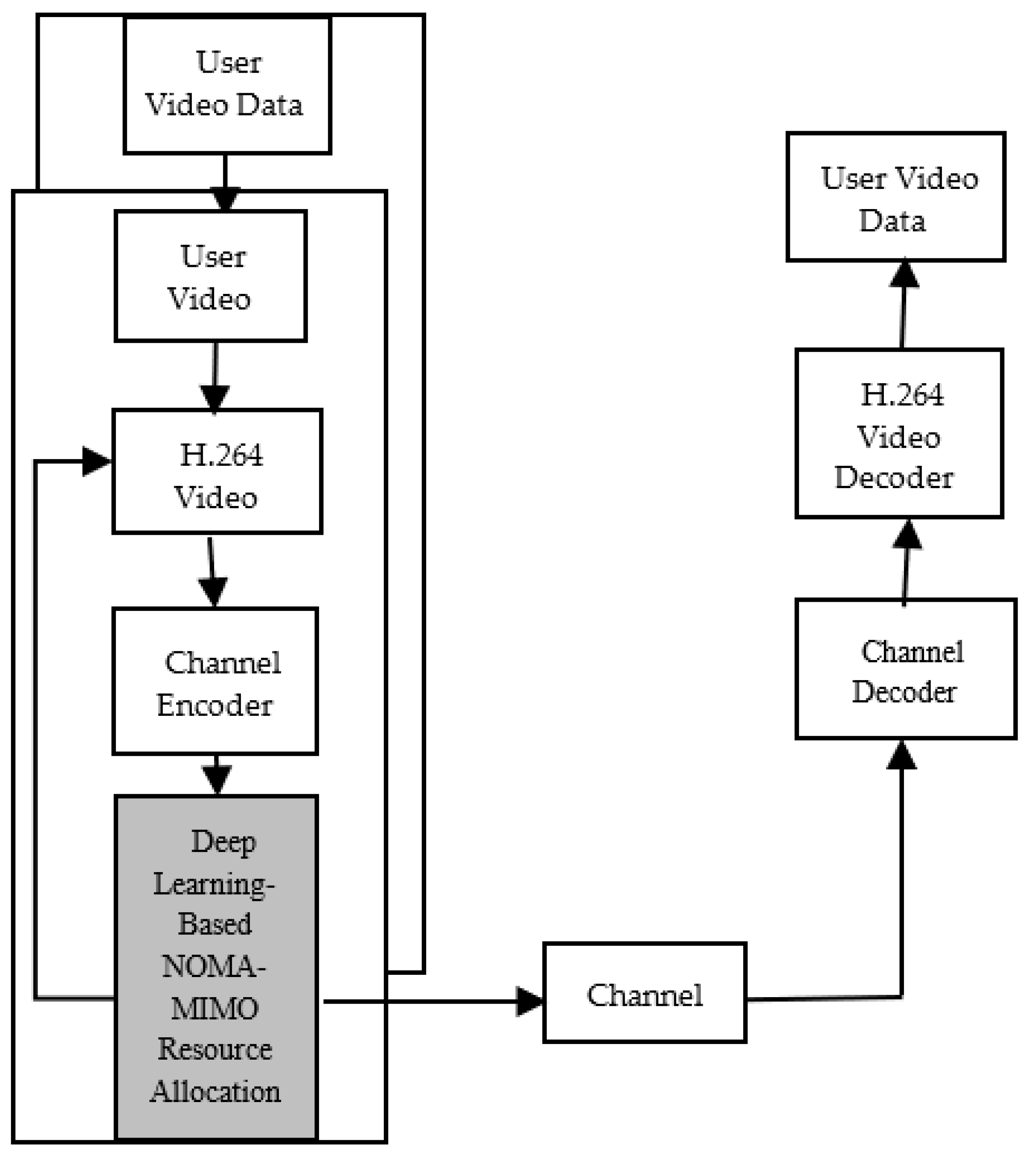
3. Uplink NOMA-MIMO Video Transmission System Model
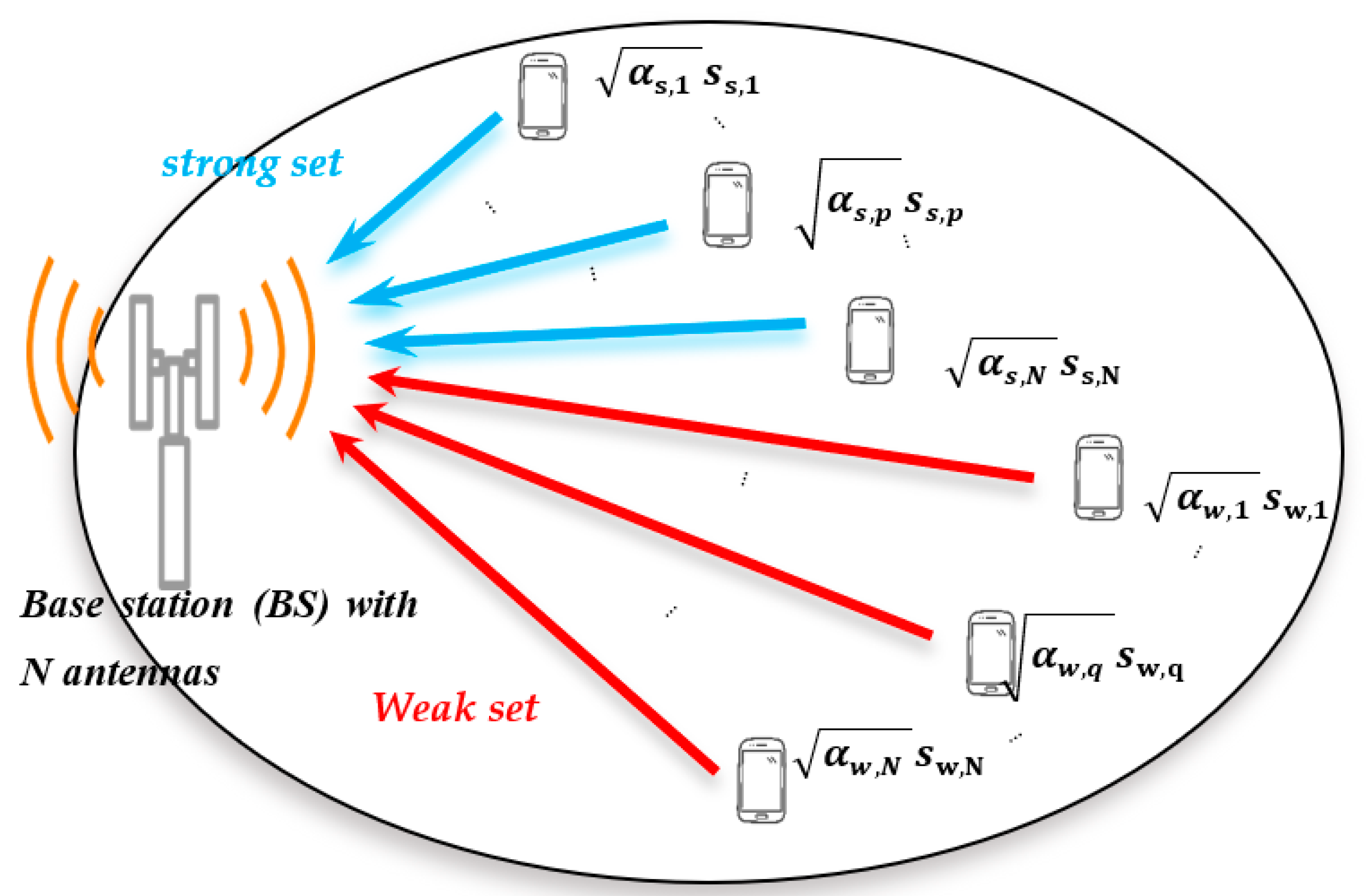
3.1. Uplink Noma-Mimo System Structure
3.2. Received Signal Model
3.3. Multiantenna Beamforming: Zero-Forcing Post-Coder
3.4. Received Sinr and Information (Data) Rate of Users
3.5. Video MSE Distortion Model and Psnr
4. Proposed Deep Learning Approach for User Selection (Scheme DNN)
4.1. Deep Neural Networks Structure
4.2. DNN System Model
4.3. Proposed Modified Cost Function for Constrained Optimization
4.4. Statistical Analysis
5. Simulation Results
- (1)
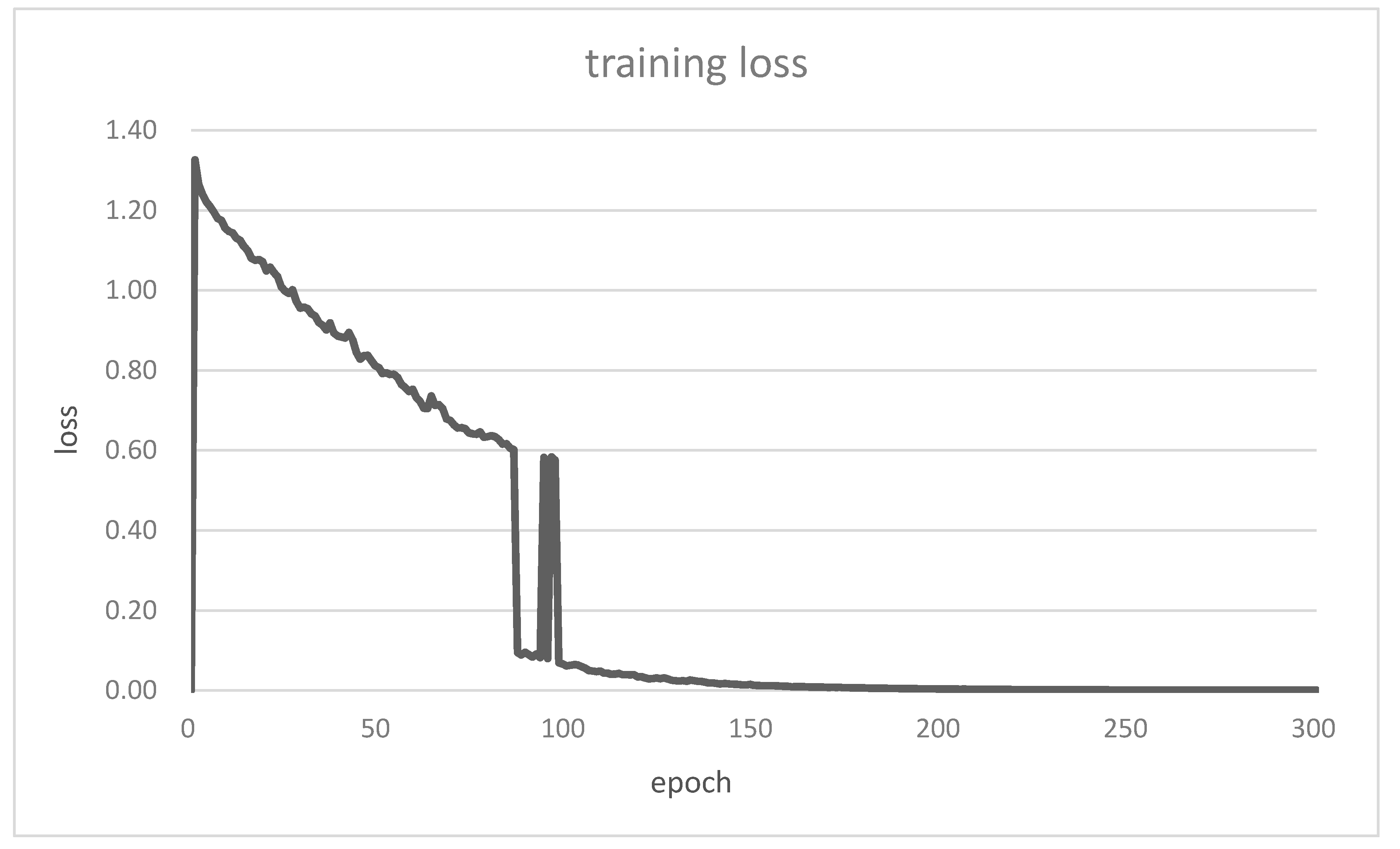
- The loss function converges after 200 epochs, so the epochs = 200 in Table 2.
- (2)
- The validation loss converges to almost zero in a way as the training loss, and no overfitting occurs. The DNN model can learn the correct answer from the unseen data (the validation data are different from the training data). This validates the DNN system model with the parameters in Table 2.
- (3)
- The initial loss is greater than 1 (maximum of the binary cross entropy). Also, there are jumps of 0.5 (constraint violation) before convergence (about epoch 100) in the training and validation loss curves. These validate the in (20) in the DNN system model.
Discussions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Zhang, X.; Xu, Y.; Xiong, J.; Zhu, Y.; Wang, X. MuVi: Multiview Video Aware Transmission Over MIMO Wireless Systems. IEEE Trans. Multimed. 2017, 19, 2788–2803. [Google Scholar] [CrossRef]
- Yang, Y.-S.; Pu, J.-W.; Yeh, P.-H.; Li, C.-P.; Li, H.-J. Investigation on Distributed User Selection for Uplink Multicell Systems with MIMO. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–5. [Google Scholar]
- Lee, K.; Kim, D. Cross-layer optimization for heterogeneous MU-MIMO/OFDMA networks. Sensors 2021, 21, 2744. [Google Scholar] [CrossRef]
- Gui, G.; Huang, H.; Song, Y.; Sari, H. Deep learning for an effective non orthogonal multiple access scheme. IEEE Trans. Veh. Technol. 2018, 67, 8440–8450. [Google Scholar] [CrossRef]
- Jiao, R.; Dai, L.; Zhang, J.; MacKenzie, R.; Hao, M. On the Performance of NOMA-Based Cooperative Relaying Systems Over Rician Fading Channels. IEEE Trans. Veh. Technol. 2017, 66, 11409–11413. [Google Scholar] [CrossRef] [Green Version]
- Gui, G.; Sari, H.; Biglieri, E. A New Definition of Fairness for Non-Orthogonal Multiple Access. IEEE Commun. Lett. 2019, 23, 1267–1271. [Google Scholar] [CrossRef]
- Gui, G.; Liu, M.; Tang, F.; Kato, N.; Adachi, F. 6G: Opening New Horizons for Integration of Comfort, Security, and Intelligence. IEEE Wirel. Commun. 2020, 27, 126–132. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, Y.; Li, W.; Rong, B.; Salehian, K.; LaFleche, S.; Wang, X.; Park, S.I.; Kim, H.M.; Lee, J.-Y.; et al. Layered-Division-Multiplexing for High Spectrum Efficiency and Service Flexibility in Next Generation ATSC 3.0 Broadcast System. IEEE Wirel. Commun. 2019, 26, 116–123. [Google Scholar] [CrossRef]
- Ding, Z.; Liu, Y.; Choi, J.; Sun, Q.; Elkashlan, M.; Chih-Lin, I.; Poor, H.V. Application of Non-Orthogonal Multiple Access in LTE and 5G Networks. IEEE Commun. Mag. 2017, 55, 185–191. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; He, W.; He, Q.; He, J. The application and development of SIC technology in wireless communication system. In Proceedings of the 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN), Guangzhou, China, 6–8 May 2017; pp. 565–570. [Google Scholar]
- Senel, K.; Cheng, H.V.; Bjornson, E.; Larsson, E.G. What Role can NOMA Play in Massive MIMO? IEEE J. Sel. Top. Signal. Process. 2019, 13, 597–611. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Chung, W.; Lim, S.; Suh, S.; Kwun, J.; Choi, S.; Hong, D. Uplink NOMA with multi-antenna. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–5. [Google Scholar]
- Tseng, S.-M.; Chen, Y.-F.; Fang, H.-H. Cross PHY/APP layer user grouping and power allocation for uplink multi-antenna NOMA video communication systems. IEEE Syst. J. 2020, 14, 3351–3359. [Google Scholar] [CrossRef]
- Qureshi, S.; Hassan, S.A. MIMO uplink NOMA with successive bandwidth division. In Proceedings of the 2016 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Doha, Qatar, 3–6 April 2016; pp. 481–486. [Google Scholar]
- Wang, D.; Toni, L.; Cosman, P.; Milstein, L.B. Uplink Resource Management for Multiuser OFDM Video Transmission Systems: Analysis and Algorithm Design. IEEE Trans. Commun. 2013, 61, 2060–2073. [Google Scholar] [CrossRef]
- Li, F.; Wang, T.; Cosman, P.C. Joint rate adaptation and resource allocation for real-time H.265/HEVC video transmission over uplink OFDMA systems. Multimed. Tools Appl. 2019, 78, 26807–26831. [Google Scholar] [CrossRef] [Green Version]
- Simeone, O. A Very Brief Introduction to Machine Learning with Applications to Communication Systems. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 648–664. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Kim, N.-I.; Lee, W.; Cho, D.-H. Deep Learning-Aided SCMA. IEEE Commun. Lett. 2018, 22, 720–723. [Google Scholar] [CrossRef]
- Lee, W.; Kim, M.; Cho, D.-H. Deep Learning Based Transmit Power Control in Underlaid Device-to-Device Communication. IEEE Syst. J. 2019, 13, 2551–2554. [Google Scholar] [CrossRef]
- Ahmed, I.; Khammari, H. Joint machine learning based resource allocation and hybrid beamforming design for massive MIMO systems. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Kim, Y. Application of machine learning to antenna design and radar signal processing: A review. In Proceedings of the 2018 International Symposium on Antennas and Propagation (ISAP), Busan, Korea, 23–26 October 2018; pp. 1–2. [Google Scholar]
- Sun, H.; Chen, X.; Shi, Q.; Hong, M.; Fu, X.; Sidiropoulos, N.D. Learning to Optimize: Training Deep Neural Networks for Interference Management. IEEE Trans. Signal Process. 2018, 66, 5438–5453. [Google Scholar] [CrossRef]
- López, D.; Rivas, E.; Gualdron, O. Primary user characterization for cognitive radio wireless networks using a neural system based on Deep Learning. Artif. Intell. Rev. 2019, 52, 169–195. [Google Scholar] [CrossRef]
- Wang, Y.; Ye, Z.; Wan, P.; Zhao, J. A survey of dynamic spectrum allocation based on reinforcement learning algorithms in cognitive radio networks. Artif. Intell. Rev. 2018, 51, 493–506. [Google Scholar] [CrossRef]
- Tseng, S.-M.; Chen, Y.-F.; Tsai, C.-S.; Tsai, W.-D. Deep-Learning-Aided Cross-Layer Resource Allocation of OFDMA/NOMA Video Communication Systems. IEEE Access 2019, 7, 157730–157740. [Google Scholar] [CrossRef]
- Wang, P. Outage Capacity Considered Supervised Learning Based NOMA OFDMA Video Communication Resource Allocation. Master’s Thesis, Department of Electronic Engineering, National Taipei University of Technology, Taipei, Taiwan, 2021. [Google Scholar]
- Liu, M.; Song, T.; Hu, J.; Yang, J.; Gui, G. Deep Learning-Inspired Message Passing Algorithm for Efficient Resource Allocation in Cognitive Radio Networks. IEEE Trans. Veh. Technol. 2018, 68, 641–653. [Google Scholar] [CrossRef]
- Ahmed, K.I.; Tabassum, H.; Hossain, E. Deep Learning for Radio Resource Allocation in Multi-Cell Networks. IEEE Netw. 2019, 33, 188–195. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Guo, S.; Gui, G.; Yang, Z.; Zhang, J.; Sari, H.; Adachi, F. Deep Learning for Physical-Layer 5G Wireless Techniques: Opportunities, Challenges and Solutions. IEEE Wirel. Commun. 2020, 27, 214–222. [Google Scholar] [CrossRef] [Green Version]
- Mao, Q.; Hu, F.; Hao, Q. Deep Learning for Intelligent Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2595–2621. [Google Scholar] [CrossRef]
- Stuhlmuller, K.; Farber, N.; Link, M.; Girod, B. Analysis of video transmission over lossy channels. IEEE J. Sel. Areas Commun. 2000, 18, 1012–1032. [Google Scholar] [CrossRef]
- Lee, W. Resource Allocation for Multi-Channel Underlay Cognitive Radio Network Based on Deep Neural Network. IEEE Commun. Lett. 2018, 22, 1942–1945. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Jing, X.Y.; Zhang, X.; Zhu, X.; Wu, F.; You, X.; Gao, Y.; Shan, S.; Yang, J.Y. Multiset feature learning for highly imbalanced data classification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 139–156. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- General Guidance Hung-Yi Lee. Available online: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/overfit-v6.pptx (accessed on 9 September 2021).
- CS231n: Convolutional Neural Networks for Visual Recognition Stanford—Spring 2021. Available online: https://cs231n.github.io/neural-networks-3/#eval (accessed on 9 September 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Lin, K.; Dumitrescu, S. Cross-layer resource allocation for scalable video over OFDMA wireless networks: Tradeoff between quality fairness and efficiency. IEEE Trans. Multimed. 2017, 19, 1654–1669. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [12] | [13] | Proposed | |
|---|---|---|---|
| User selection | Base on physical layer metric information rate in (9) and (13) | Base on ross layer metric video MSE in (14) | Learn from [13] |
| Power allocation | Base on physical layer metric information rate in (9) and (13) | Base on cross layer metric video MSE in (14) | the same as [13] |
| Computational complexity | Iterative algorithm, so high computation complexity | Iterative algorithm, so high computation complexity | Non-iterative, deep learning-based approach, so low online computation complexity |
| Parameter | Value |
|---|---|
| Batch size | 100 |
| Learning Rate | 0.0001 |
| Activation function (hidden layers) | ReLU |
| Activation function (last layer) | Sigmoid |
| Cost function | Proposed modified cost function in (21) |
| Epochs | 200 |
| Number of hidden layers | 4 |
| Number of training data | 24,000 |
| Number of validation data | 6000 |
| Number of testing data | 3000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tseng, S.-M.; Kao, S.-C. User Selection Approach in Multiantenna Beamforming NOMA Video Communication Systems. Symmetry 2021, 13, 1737. https://doi.org/10.3390/sym13091737
Tseng S-M, Kao S-C. User Selection Approach in Multiantenna Beamforming NOMA Video Communication Systems. Symmetry. 2021; 13(9):1737. https://doi.org/10.3390/sym13091737
Chicago/Turabian StyleTseng, Shu-Ming, and Shih-Chun Kao. 2021. "User Selection Approach in Multiantenna Beamforming NOMA Video Communication Systems" Symmetry 13, no. 9: 1737. https://doi.org/10.3390/sym13091737