
Data Anomaly Detection of Bridge Structures Using Convolutional Neural Network Based on Structural Vibration Signals


Abstract
:1. Introduction
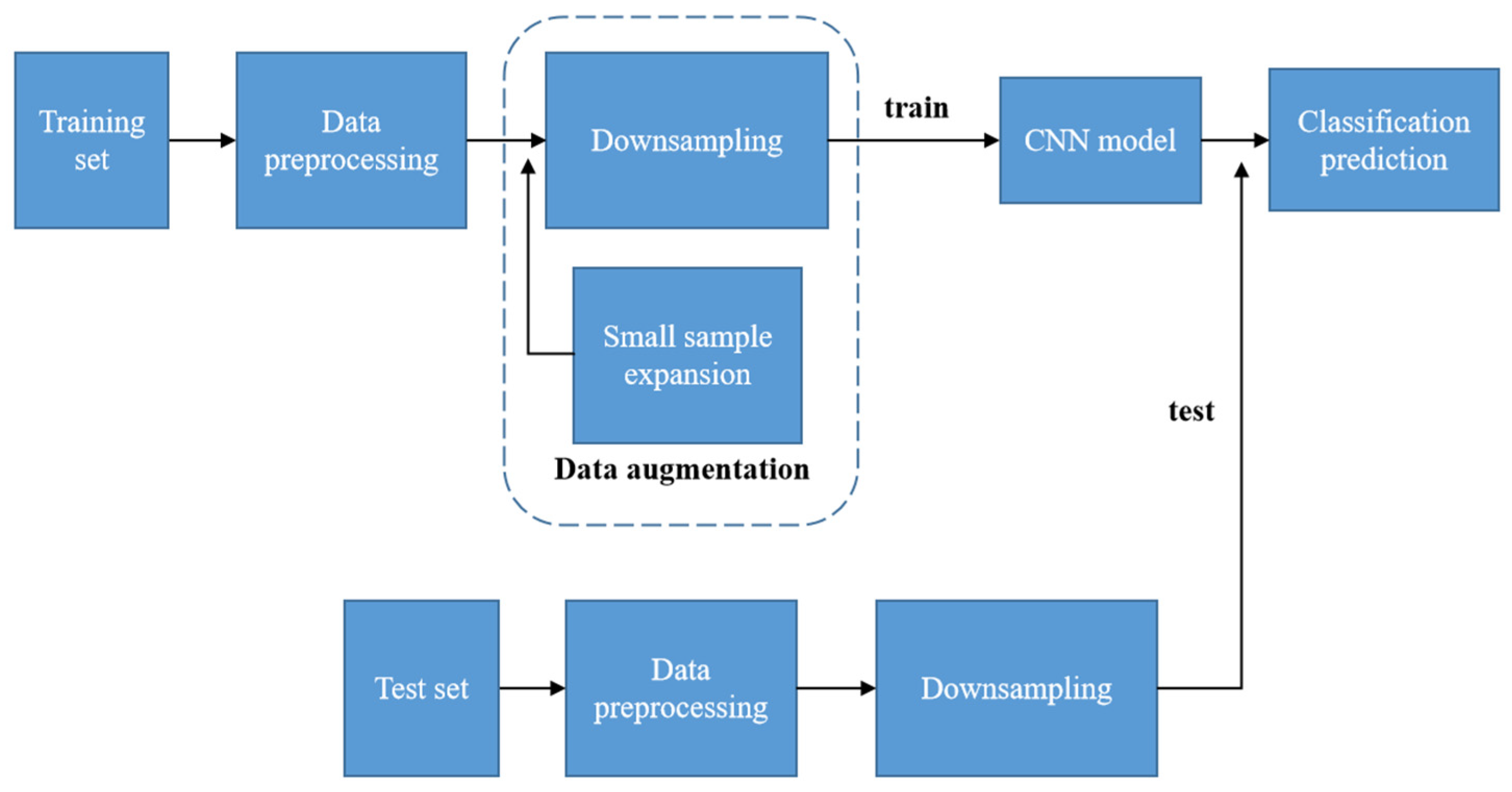
2. Data Anomaly Classification Method Based on 1D-CNN
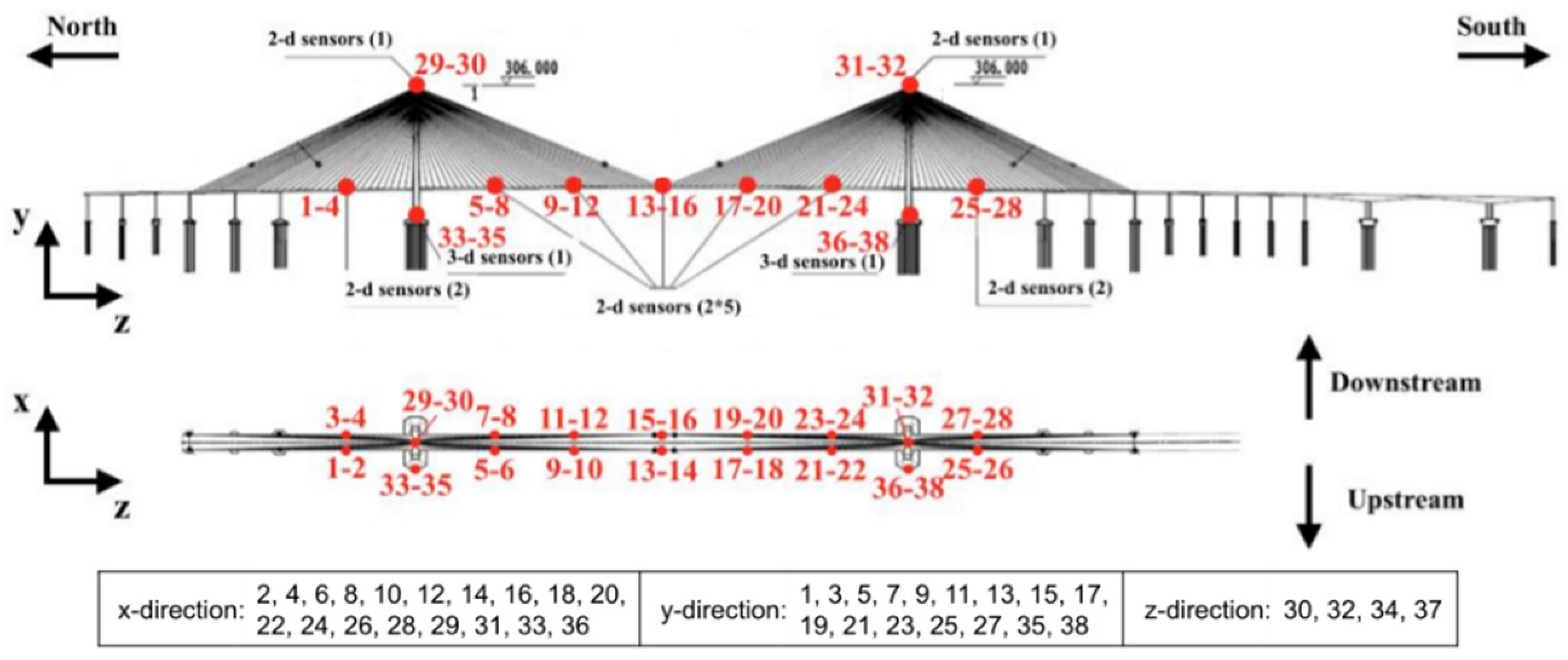
2.1. Bridge Overview and Data Set Composition
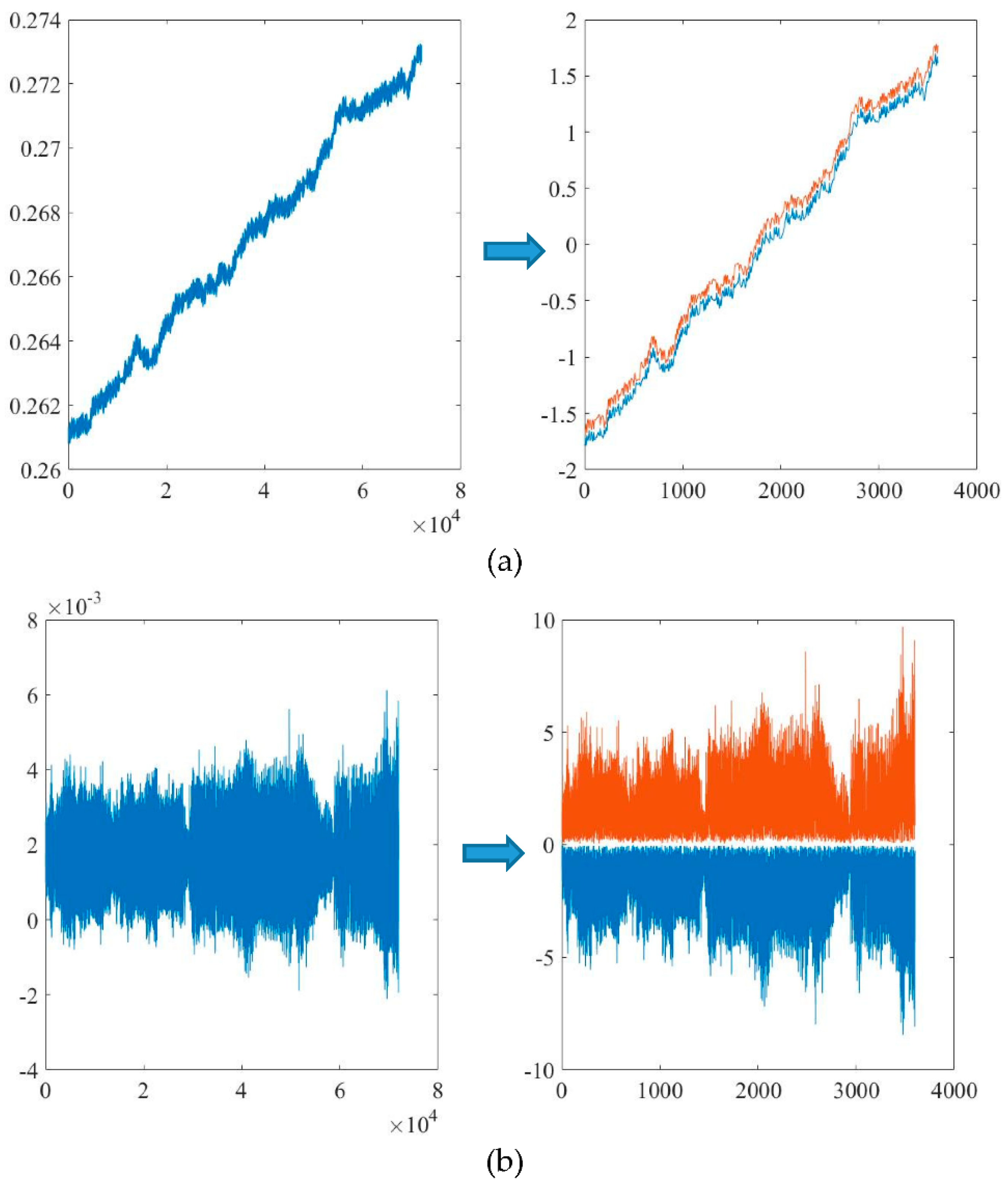
2.2. Data Preprocessing
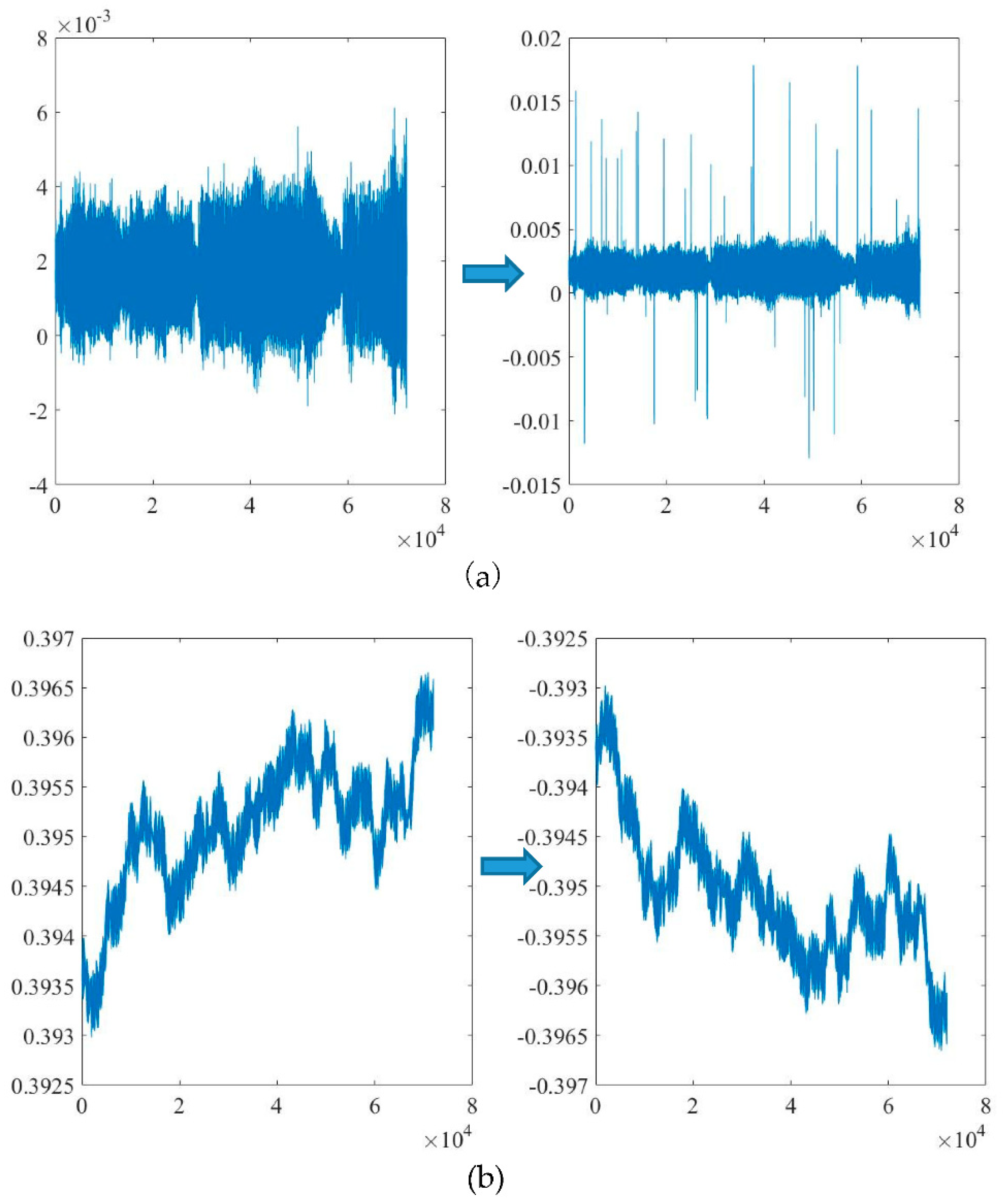
2.3. Data Augmentation
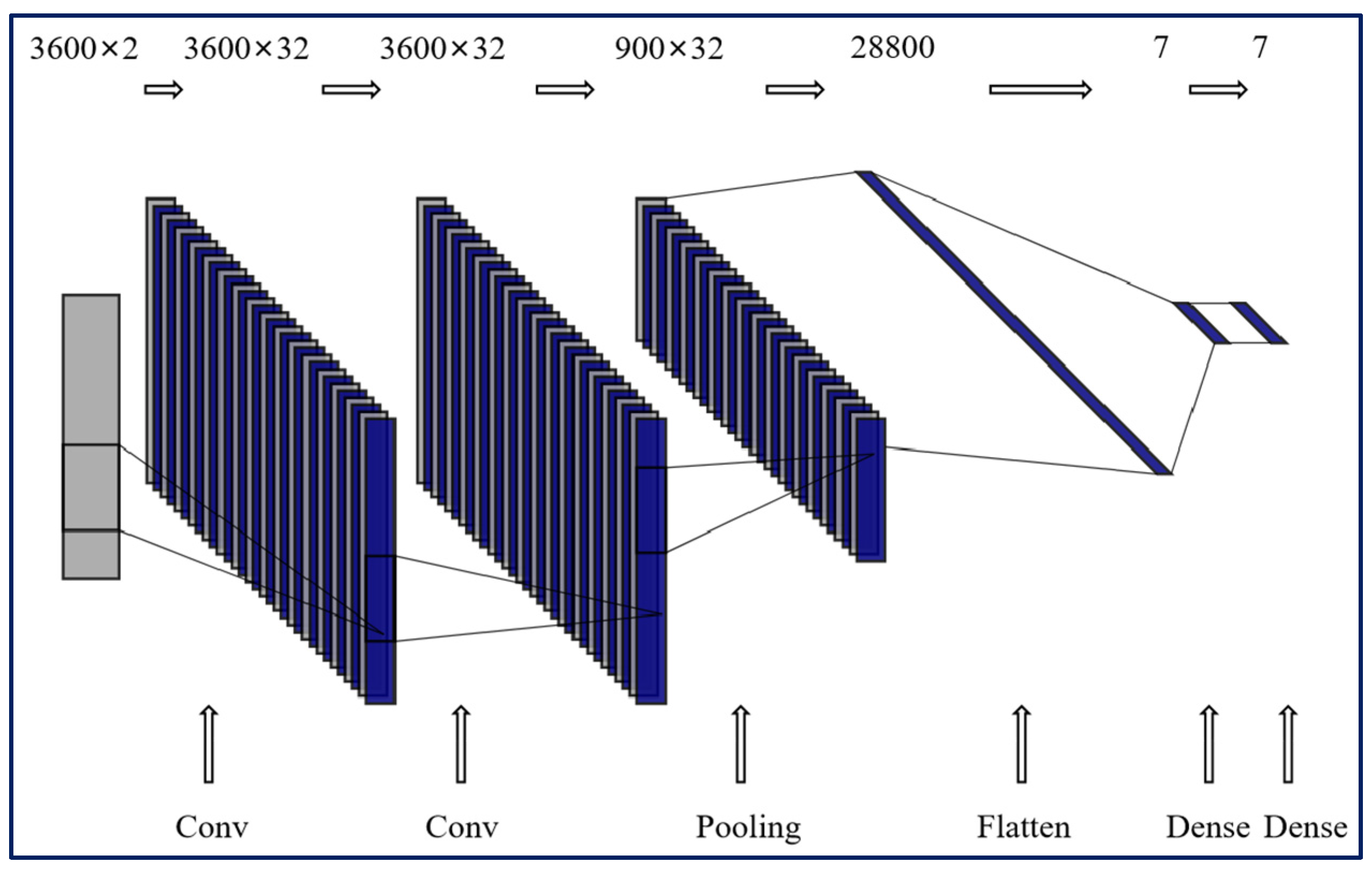
2.4. 1D-CNN
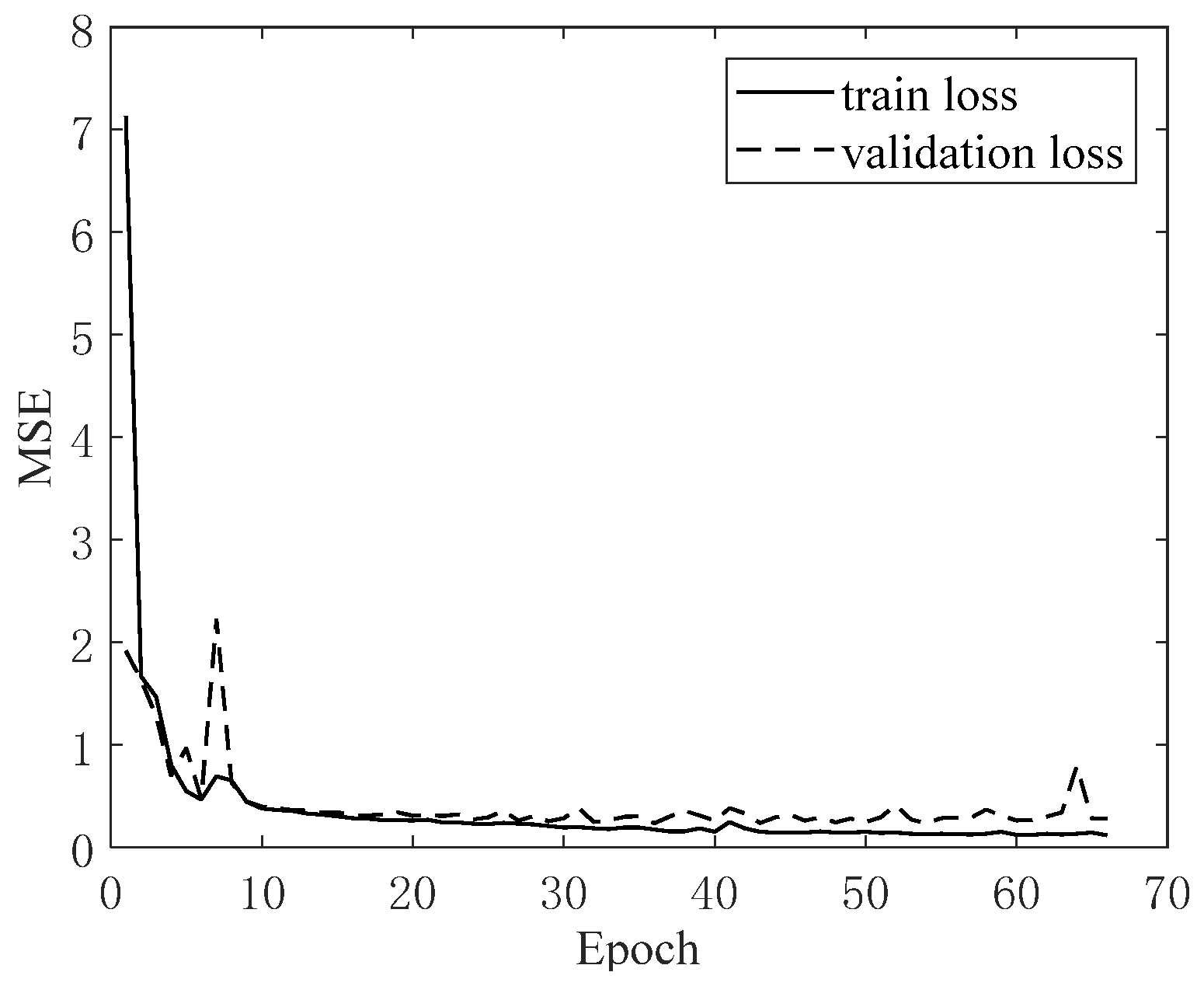
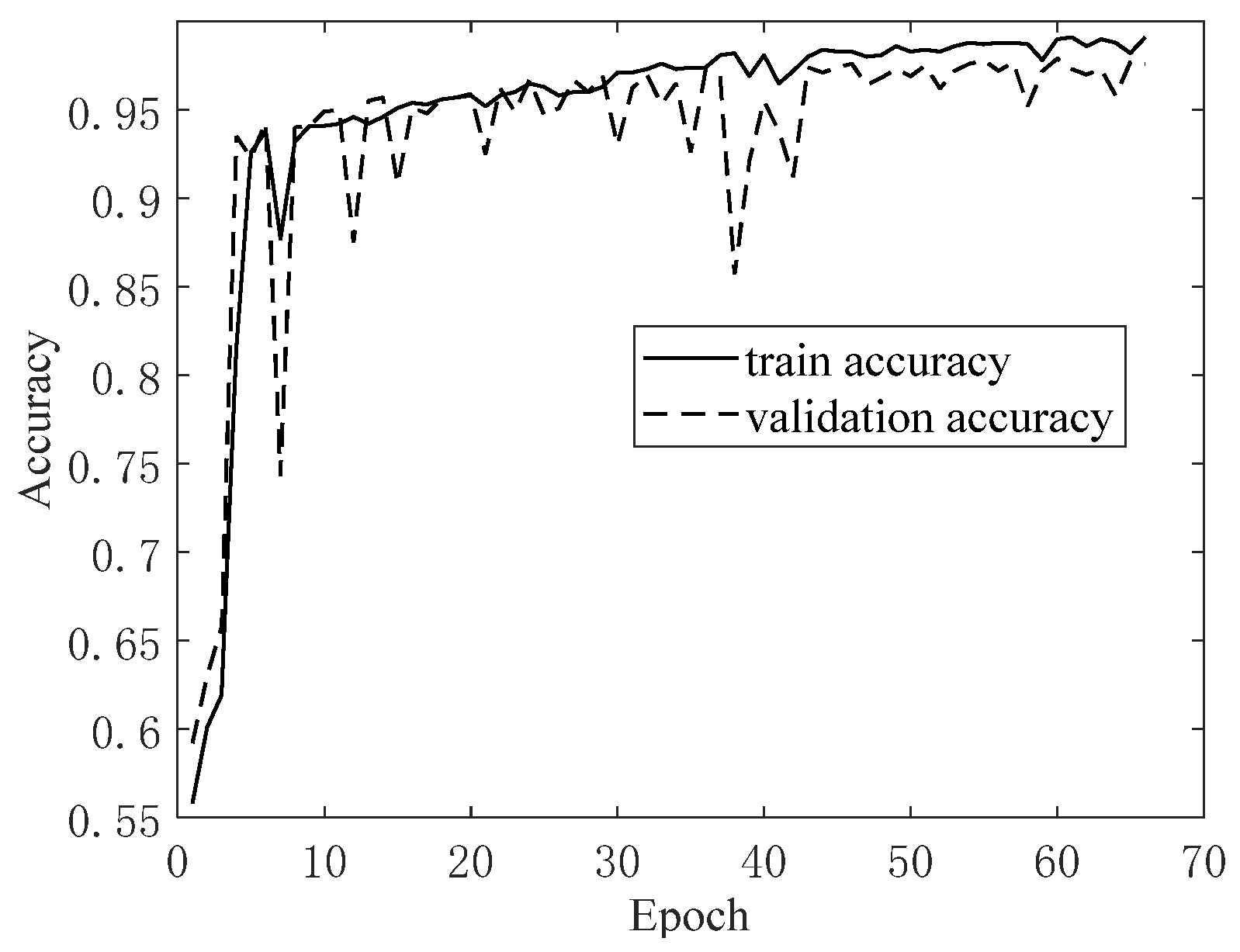
3. Bridge Monitoring Data Verification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yi, T.H.; Huang, H.B.; Li, H.N. Development of sensor validation methodologies for structural health monitoring: A comprehensive review. Measurement 2017, 109, 200–214. [Google Scholar] [CrossRef]
- Chang, C.M.; Chou, J.Y. Damage detection of seismically excited buildings based on prediction errors. J. Aerosp. Eng. 2018, 31, 04018032.1–04018032.9. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Dai, J. Prediction of long-term temperature effect in structural health monitoring of concrete dams using support vector machines with jaya optimizer and salp swarm algorithms. Adv. Eng. Softw. 2019, 131, 60–76. [Google Scholar] [CrossRef]
- Moriot, J.; Quaegebeur, N.; Le Duff, A.; Masson, P. A model-based approach for statistical assessment of detection and localization performance of guided wave-based imaging techniques. Struct. Health Monit. 2017, 17, 1460–1472. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, Y.M.; Mao, J.X.; Wan, H.P.; Tao, T.Y.; Zhu, Q.X. Modeling and forecasting of temperature-induced strain of a long-span bridge using an improved bayesian dynamic linear model. Eng. Struct. 2019, 192, 220–232. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Xu, B.; He, J.; Masri, S.F. Data-based model-free hysteretic restoring force and mass identification for dynamic systems. Comput. Aided Civ. Infrastruct. Eng. 2015, 30, 2–18. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 2019, 21, 7833–7848. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning-based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Tang, Z.; Chen, Z.; Bao, Y.; Li, H. Convolutional neural network-based data anomaly detection method using multiple information for structural health monitoring. Struct. Control. Health Monit. 2018, 26, e2296. [Google Scholar] [CrossRef] [Green Version]
- Mao, J.; Wang, H.; Spencer, B.F. Toward data anomaly detection for automated structural health monitoring: Exploiting generative adversarial nets and autoencoders. Struct. Health Monit. 2020. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478v1. [Google Scholar]
- Sun, J.; Wang, M.T.; Zhao, X.; Zhang, D.J. Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation. Symmetry 2020, 12, 1116. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Y.; He, D.J.; Li, Y.X. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Chen, W.; Chen, Y. Multi-scale convolutional neural networks for time series classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Data augmentation using synthetic data for time series clas-sification with deep residual networks. arXiv 2018, arXiv:1808.02455v1 [cs.CV]. [Google Scholar]
- Wen, T.; Keyes, R. Time series anomaly detection using convolutional neural networks and transfer learning. arXiv 2019, arXiv:1905.13628v1 [cs.LG]. [Google Scholar]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv 2020, arXiv:2002.09535. [Google Scholar]
- Francois Chollet. Deep Learning with Python; Manning: New York, NY, USA, 2018; pp. 188–190. [Google Scholar]
- Keras. Available online: https://keras.io/ (accessed on 31 October 2019).
- Alom, M.Z.; Taha, T.M.; Yakopcic, C. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Nie, Z.; Ma, H. Structural Damage Detection with Automatic Feature-Extraction through Deep Learning. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 1025–1046. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Anomaly Patterns | Description | Quantity |
|---|---|---|---|
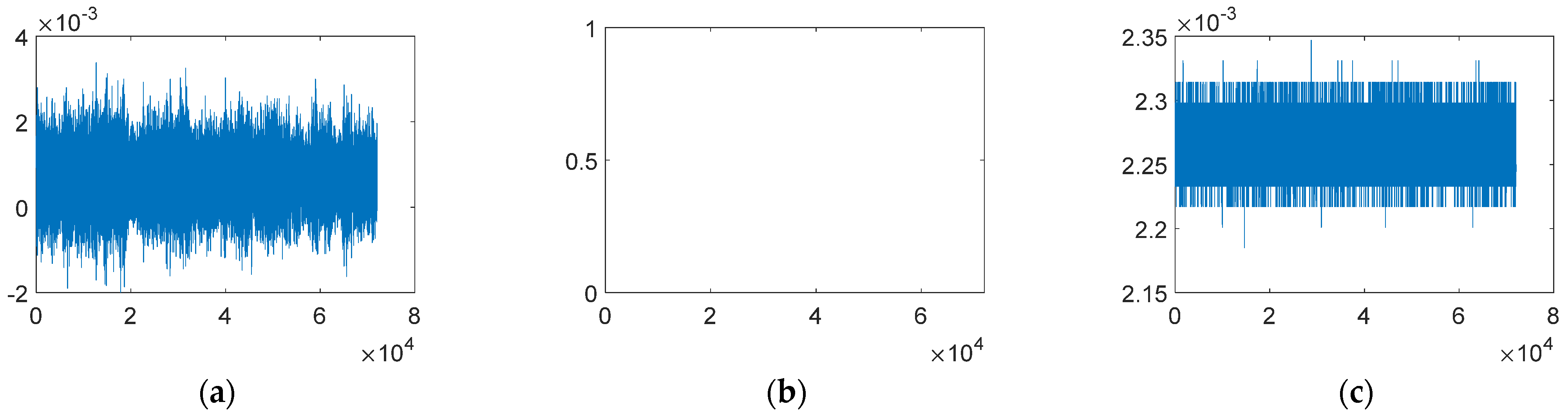
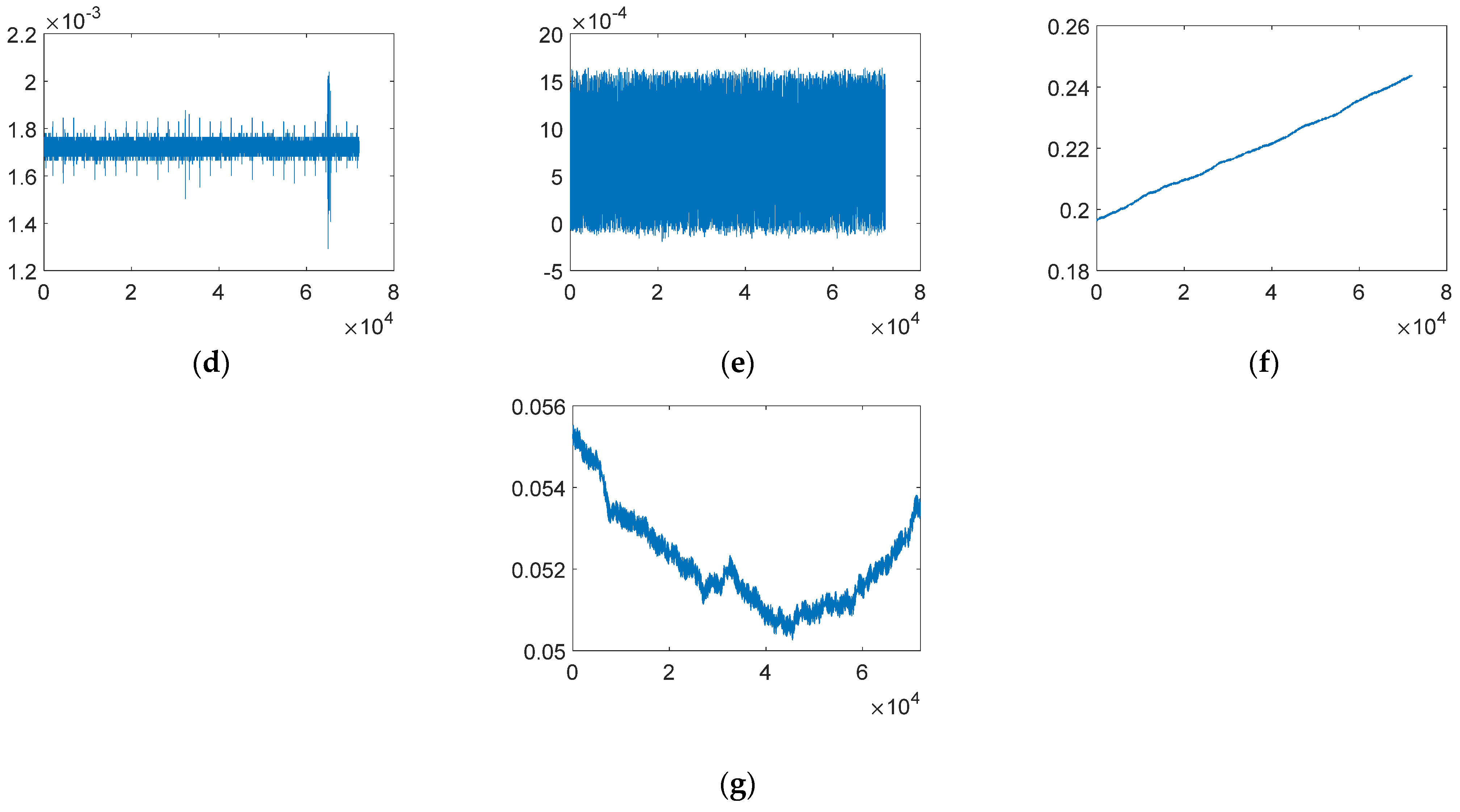
| 1 | Normal | The time response is normal oscillation curve; frequency response is peak-like (may differ between bridges) | 13575 (48%) |
| 2 | Missing | Most/all of the time response is missing, which makes the time and frequency response zero | 2942 (10.4%) |
| 3 | Minor | Relative to normal sensor data, the amplitude is very small in the time domain | 1775 (6.3%) |
| 4 | Outlier | One or more outliers appear in the time response | 527 (1.9%) |
| 5 | Square | The time response is like a square wave | 2996 (10.6%) |
| 6 | Trend | The data has an obvious trend in the time domain and has an obvious peak value in the frequency domain | 5778 (20.4%) |
| 7 | Drift | The vibration response is non-stationary, with random drift | 679 (2.4%) |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| Anomaly patterns | Normal | Missing | Minor | Outlier | Square | Trend | Drift |
| Quantity | 2688 | 603 | 360 | 106 | 616 | 1147 | 136 |
| Percentage | 47.5% | 10.7% | 6.4% | 1.9% | 10.9% | 20.3% | 2.4% |
| Layer | Type | Input Shape | Output Shape | Kernel Num | Kernel Size | Stride | Padding | with BN | Activation |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Conv | (3600, 2) | (3600, 32) | 32 | 16 | 1 | Same | True | Leaky ReLU |
| 2 | Conv | (3600, 32) | (3600, 32) | 32 | 16 | 1 | Same | True | Leaky ReLU |
| 3 | Pooling | (3600, 32) | (900, 32) | None | 4 | 4 | Valid | False | None |
| 4 | Flatten | (900, 32) | (28800) | None | None | None | None | None | None |
| 5 | Dense | (28800) | (7) | None | None | None | None | False | Leaky ReLU |
| 6 | Dense | (7) | (7) | None | None | None | None | False | Softmax |
| Name | Value | Description |
|---|---|---|
| Batch size | 128 | The size of data batch used in every training iteration |
| Initial learning rate | 10−3 | The initial learning rate of Adam algorithm |
| Patience | 40 | A parameter of early stopping |
| α | 0.01 | A parameter in Leaky RELU function 0.01 in every activation function |
| Predicted Data Pattern | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | Total | Recall (%) | ||
| Real data pattern | 1-normal | 2542 | 0 | 60 | 72 | 14 | 0 | 0 | 2688 | 94.57 |
| 2-missing | 0 | 602 | 1 | 0 | 0 | 0 | 0 | 603 | 99.83 | |
| 3-minor | 26 | 0 | 326 | 8 | 0 | 0 | 0 | 360 | 90.56 | |
| 4-outlier | 21 | 0 | 1 | 84 | 0 | 0 | 0 | 106 | 79.24 | |
| 5-square | 1 | 0 | 1 | 2 | 612 | 0 | 0 | 616 | 99.35 | |
| 6-trend | 0 | 0 | 2 | 0 | 0 | 1110 | 35 | 1147 | 96.77 | |
| 7-drift | 0 | 0 | 0 | 0 | 0 | 13 | 123 | 136 | 90.44 | |
| Total | 2590 | 602 | 391 | 166 | 626 | 1123 | 158 | 5656 | 95.45 | |
| Precision (%) | 98.15 | 100.0 | 83.38 | 50.60 | 97.76 | 98.84 | 77.85 | |||
| F1 score | 0.96 | 1.00 | 0.87 | 0.62 | 0.99 | 0.98 | 0.84 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lei, Y. Data Anomaly Detection of Bridge Structures Using Convolutional Neural Network Based on Structural Vibration Signals. Symmetry 2021, 13, 1186. https://doi.org/10.3390/sym13071186
Zhang Y, Lei Y. Data Anomaly Detection of Bridge Structures Using Convolutional Neural Network Based on Structural Vibration Signals. Symmetry. 2021; 13(7):1186. https://doi.org/10.3390/sym13071186
Chicago/Turabian StyleZhang, Yixiao, and Ying Lei. 2021. "Data Anomaly Detection of Bridge Structures Using Convolutional Neural Network Based on Structural Vibration Signals" Symmetry 13, no. 7: 1186. https://doi.org/10.3390/sym13071186