
A Survey on Knowledge Graph Embeddings for Link Prediction


Abstract
:1. Introduction
- This paper provides a theoretical analysis and comparison of existing KGE methods for generating KG embeddings for link prediction in KGs.
- Several representative models in each category are also analyzed and compared along five main lines.
- We conducted experiments on two benchmark datasets to report comprehensive findings and provide new insights into the strengths and weaknesses of existing models. We also provide new insights into existing techniques that are beneficial for future research.
2. Preliminaries and Problem Definition
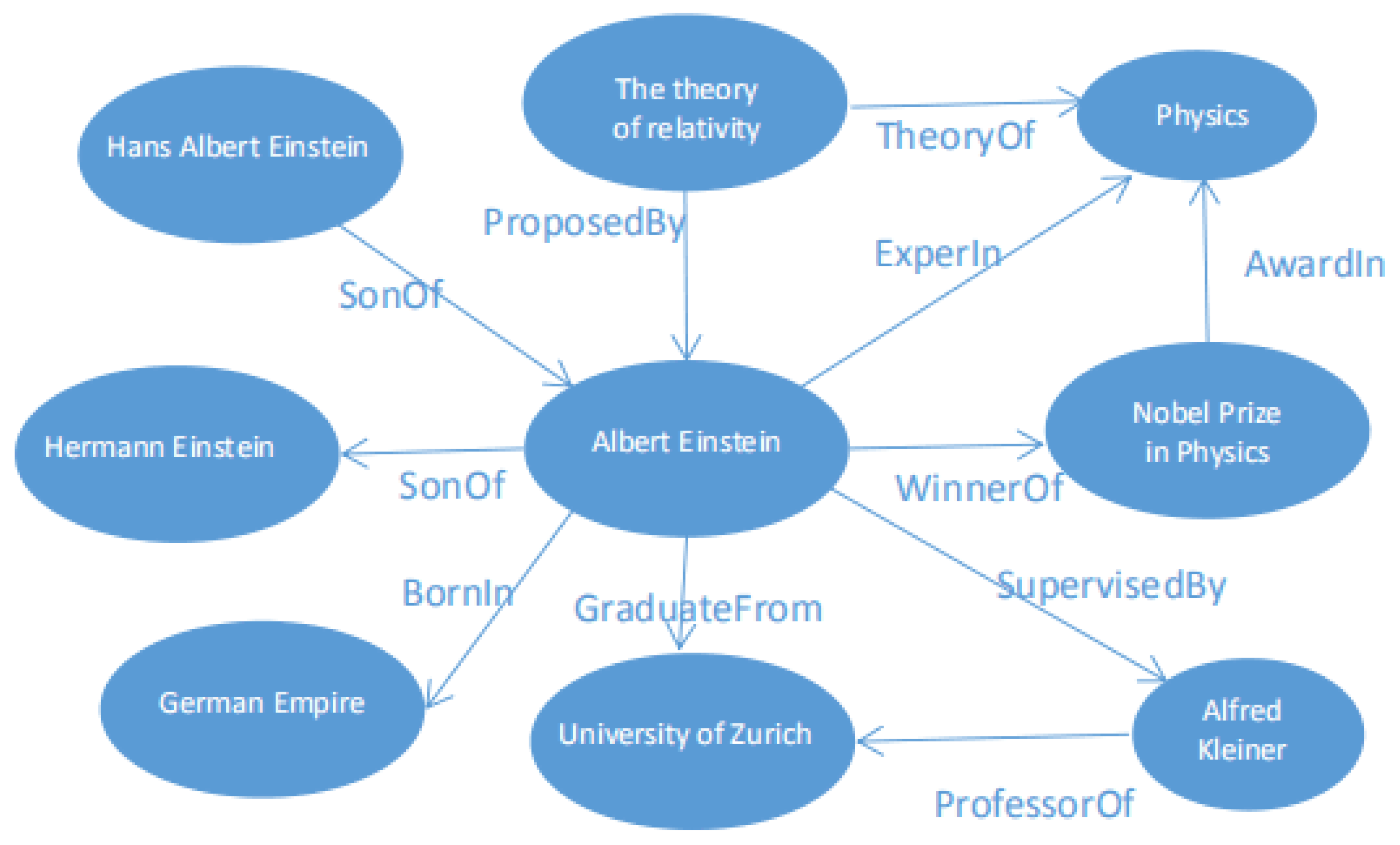
2.1. Preliminaries
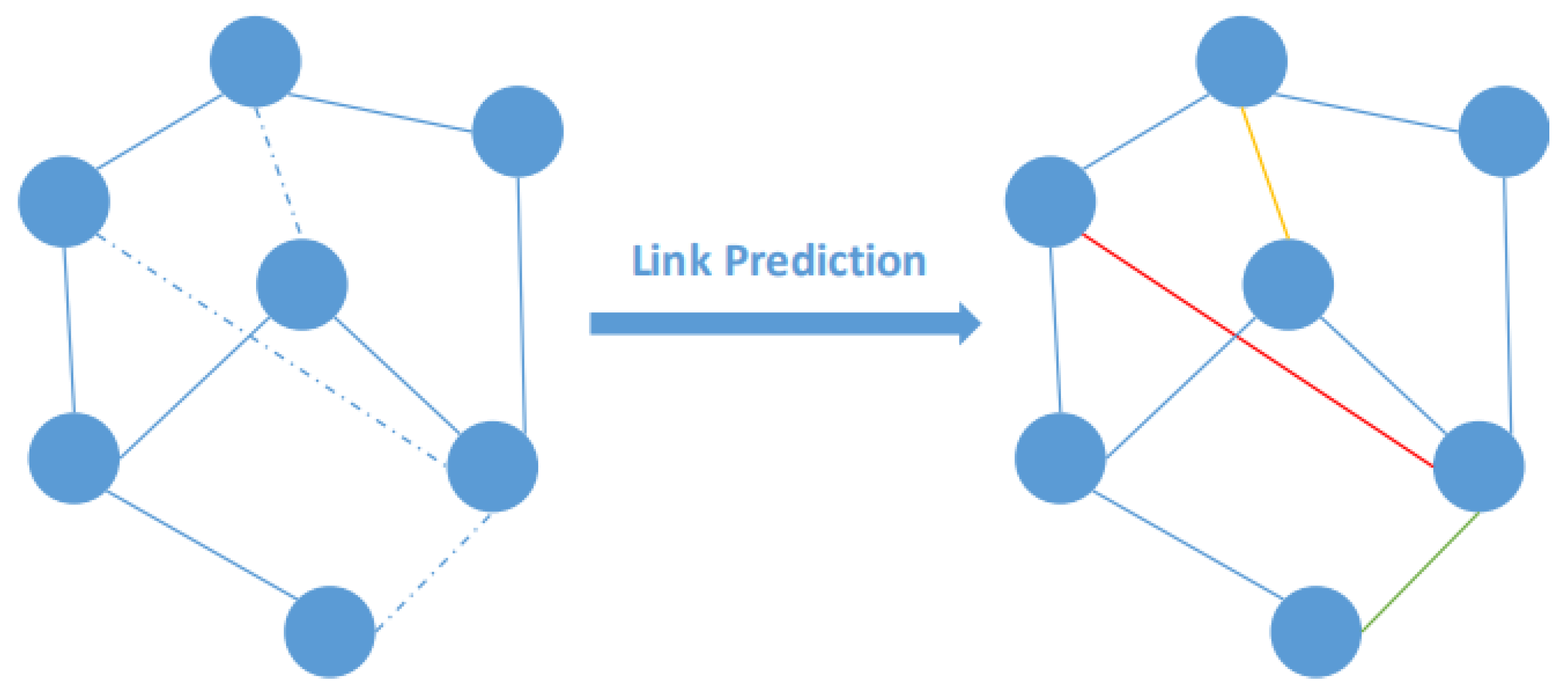
2.2. Link Prediction
2.3. Research Questions
- It is difficult to model the heterogeneity of graphs.
- There are few studies on dynamic graphs, which are better able to reflect the real world.
- How to incorporate prior knowledge to obtain deep semantics should be determined.
- How to capture multi-hop neighbor information should be determined.
- It has been argued that many models struggle to perform on hierarchical graphs such as WN18RR [8].
3. Embedding Models for Link Prediction
3.1. Translation-Distance-Based Models
3.2. Semantic Information-Based Models
3.3. Neural Network-Based Models
3.4. Connections between Typical Models
4. Experiments
4.1. Experimental Settings
4.2. Dataset
4.3. The Implemented Models
4.4. Performance Analysis
4.5. Training Time Analysis
- For CNN-based models, the initial model ConvE, which introduces numerous parameters because it uses an embedded 2D convolution, is very time-consuming for training. Similarly, for LiteralE, the introduction of additional information and its complex model structure lead to some additional parameter overhead. While HypER utilizes a 1D relation-specific filter and a nonlinear (quadratic) combination of entity and relation embeddings via hypernetworks to perform weight sharing, it has many fewer parameters than ConvE, so it saves much training time.
- Semantic matching models such as DistMult and ComplEx all suffer from longer training times.
- Translational distance models such as HAKE and RotatE all have shorter training times because the translational-distance model has a relatively simple model structure and scoring function without too many parameters.
- The bilinear+TR model has the shortest training time, with a type regularizer incorporated into the loss function, which fully considers the type information of entities. The times of the linear models are short, but their performance is not good.
- LiteralE introduces some overhead in terms of the number of parameters compared to the base method, leading to a long training time. This is due to the choice of the core function g, which takes an entity’s embedding and a literal vector as inputs and maps them to a vector of the same dimension as the entity embedding. Thus, it can make much effort in this step to choose a better function.
4.6. Suggestions for Improvement
5. Conclusions
- Neural network models with excellent structure and a small number of parameters have good performance. Especially, the graph convolution neural network has a strong ability to mine the underlying semantics of knowledge graphs. In addition, if the node information of a multi-hop domain can be aggregated, the accuracy of the model in specific tasks can be greatly improved.
- Models with additional information, such as node attributes, node types, relationship types, prior knowledge and so on, have better performance.
- This survey only focused on the link prediction of KGE; we will research more tasks of knowledge graph completion in the future, such as entity prediction, entity classification and triple classification.
- This survey only used two datasets (FB15k and FB15k-237) for the experiments; we will use more knowledge graph datasets, such as WN18, WN18RR and FB13.
- This survey only focused on static graphs; we will explore new model architectures, such as dynamic graphs and heterogeneous graphs.
- The categories we proposed for KGE models may not be the perfect ones; we will attempt to mine new category strategies for KGE models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bollacker, K.D.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge; SIGMOD: Vancouver, BC, Canada, 2008; pp. 1247–1250. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Kleef, P.V.; Auer, S.; et al. DBpedia—A Large-Scale, Multilingual Knowledge base Extracted from Wikipedia; Springer: Berlin/Heidelberg, Germany, 2015; Volume 6, pp. 167–195. [Google Scholar]
- Mahdisoltani, F.; Biega, J.A.; Suchanek, F.M. YAGO3: A Knowledge Base from Multilingual Wikipedias. In Proceedings of the CIDR, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- Wang, R.; Wang, M.; Liu, J.; Chen, W.; Cochez, M.; Decker, S. Leveraging Knowledge Graph Embeddings for Natural Language Question Answering. In Proceedings of the DASFAA 2019, Chiang Mai, Thailand, 22–25 April 2019; pp. 659–675. [Google Scholar]
- Musto, C.; Basile, P.; Semeraro, G. Embedding Knowledge Graphs for Semantics-aware Recommendations based on DBpedia. In Proceedings of the UMAP 2019, Larnaca, Cyprus, 9–12 June 2019; pp. 27–31. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Cai, H.; Zheng, V.W.; Chang, K.C. A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications. IEEE Trans. Knowl. Data Eng. 2017, 30, 1616–1637. [Google Scholar] [CrossRef] [Green Version]
- Siddhant, A. A Survey on Graph Neural Networks for Knowledge Graph Completion. arXiv 2020, arXiv:2007.12374. [Google Scholar]
- Ma, J.; Qiao, Y.; Hu, G.; Wang, Y.; Zhang, C.; Huang, Y.; Sangaiah, A.K.; Wu, H.; Zhang, H.; Ren, K. ELPKG: A High-Accuracy Link Prediction Approach for Knowledge Graph Completion. Symmetry 2019, 11, 1096. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.; Yih, W.; Yang, B.; Meek, C. Typed Tensor Decomposition of Knowledge Bases for Relation Extraction. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014; pp. 1568–1579. [Google Scholar]
- Lao, N.; Mitchell, T.; Cohen, W.W. Random Walk Inference and Learning in A Large Scale Knowledge Base. In Proceedings of the EMNLP, Edinburgh, UK, 27–31 July 2011; pp. 529–539. [Google Scholar]
- Lu, F.; Cong, P.; Huang, X. Utilizing Textual Information in Knowledge Graph Embedding: A Survey of Methods and Applications. IEEE Access 2020, 8, 92072–92088. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Minervini, P.; d’ Amato, C.; Fanizzi, N.; Esposito, F. Efficient Learning of Entity and Predicate Embeddings for Link Prediction in Knowledge Graphs. In Proceedings of the URSW@ISWC, Bethlehem, PA, USA, 11–15 October 2015; pp. 26–37. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes; AAAI Press: Palo Alto, CA, USA, 2014; pp. 1112–1119. [Google Scholar]
- Fan, M.; Zhou, Q.; Chang, E.; Zheng, T.F. Transition-based Knowledge Graph Embedding with Relational Mapping Properties. In Proceedings of the PACLIC, Phuket, Thailand, 12–14 December 2014; pp. 328–337. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion; AAAI Press: Palo Alto, CA, USA, 2015; pp. 2181–2187. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Liu, Z.; Sun, M.; Lin, Y.; Xie, R. Knowledge Representation Learning: A Review. J. Comp. Res. Develop. 2016, 247–261. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the ICLR (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction; ICML: New York City, NY, USA, 2016; pp. 2071–2080. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings; AAAI Press: Palo Alto, CA, USA, 2017; pp. 1811–1818. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D.Q. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 327–333. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, T.M. Hypernetwork Knowledge Graph Embeddings. In Proceedings of the ICANN (Workshop), Munich, Germany, 17–19 September 2019; pp. 553–565. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P.P. Composition-based Multi-Relational Graph Convolutional Networks. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; Zhou, B. End-to-End Structure-Aware Convolutional Networks for Knowledge Base Completion; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3060–3067. [Google Scholar]
- Jagvaral, B.; Lee, W.; Roh, J.S.; Kim, M.S.; Park, Y.T. Path-based reasoning approach for knowledge graph completion using CNN-BiLSTM with attention mechanism. Expert Syst. Appl. 2020, 142, 112960. [Google Scholar] [CrossRef]
- Rossi, A.; Barbosa, D.; Firmani, D.; Matinata, A.; Merialdo, P. Knowledge graph embedding for link prediction: A comparative analysis. ACM Trans. Knowl. Discov. Data TKDD 2021, 15, 1–49. [Google Scholar]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948.1–112948.21. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition and Applications. arXiv 2020, arXiv:2002.00388. [Google Scholar]
- Lin, Y.; Han, X.; Xie, R.; Liu, Z.; Sun, M. Knowledge Representation Learning: A Quantitative Review. arXiv 2018, arXiv:1812.10901. [Google Scholar]
- Nguyen, D.Q. An overview of embedding models of entities and relationships for knowledge base completion. arXiv 2017, arXiv:1703.08098. [Google Scholar]
- Kazemi, S.M.; Goel, R.; Jain, K.; Kobyzev, I.; Sethi, A.; Forsyth, P.; Poupart, P. Representation Learning for Dynamic Graphs: A Survey. J. Mach. Learn. Res. 2020, 21, 1–73. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the ICLR(Poster), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix; ACL: Beijing, China, 2015; pp. 687–696. [Google Scholar]
- Jia, Y.; Wang, Y.; Lin, H.; Jin, X.; Cheng, X. Locally Adaptive Translation for Knowledge Graph Embedding; AAAI: Phoenix, AZ, USA, 2016; pp. 992–998. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge Graph Completion with Adaptive Sparse Transfer Matrix; AAAI Press: Palo Alto, CA, USA, 2016; pp. 985–991. [Google Scholar]
- Xiao, H.; Huang, M.; Zhu, X. From One Point to a Manifold: Knowledge Graph Embedding for Precise Link Prediction. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 1315–1321. [Google Scholar]
- Nguyen, D.Q.; Sirts, K.; Qu, L.; Johnson, M. STransE: A novel embedding model of entities and relationships in knowledge bases. In Proceedings of the HLT-NAACL, San Diego, CA, USA, 21 May 2016; pp. 460–466. [Google Scholar]
- Feng, J.; Huang, M.; Wang, M.; Zhou, M.; Hao, Y.; Zhu, X. Knowledge Graph Embedding by Flexible Translation. In Proceedings of the KR, Cape Town, South Africa, 25–29 April 2016; pp. 557–560. [Google Scholar]
- Chang, L.; Zhu, M.; Gu, T.; Bin, C.; Qian, J.; Zhang, J. Knowledge graph embedding by dynamic translation. IEEE Access 2017, 5, 20898–20907. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, M.; Han, X.; Hu, Z.; Ji, Y. Knowledge Graph Embedding for Hyper-Relational Data. J. Tsinghua Univ. Nat. Sci. Ed. 2017, 22, 185–197. [Google Scholar] [CrossRef]
- Du, Z.; Hao, Z.; Meng, X.; Wang, Q. CirE: Circular Embeddings of Knowledge Graphs. In Proceedings of the DASFAA, Suzhou, China, 27–30 May 2017; pp. 148–162. [Google Scholar]
- Tan, Z.; Zhao, X.; Fang, Y.; Xiao, W. GTrans: Generic knowledge graph embedding via multi-state entities and dynamic relation spaces. IEEE Access 2018, 6, 8232–8244. [Google Scholar] [CrossRef]
- Zhu, J.; Jia, Y.; Xu, J.; Qiao, J.; Cheng, X. Modeling the Correlations of Relations for Knowledge Graph Embedding. Comput. Sci. Technol. 2018, 33, 323–334. [Google Scholar] [CrossRef]
- Do, K.; Tran, T.; Venkatesh, S. Knowledge Graph Embedding with Multiple Relation Projections. In Proceedings of the ICPR, Beijing, China, 20–24 August 2018; pp. 332–337. [Google Scholar]
- Zhu, Q.; Zhou, X.; Tan, J.; Liu, P.; Guo, L. Learning Knowledge Graph Embeddings via Generalized Hyperplanes. In Proceedings of the ICCS, Wuxi, China, 11–13 June 2018; pp. 624–638. [Google Scholar]
- Geng, Z.; Li, Z.; Han, Y. A Novel Asymmetric Embedding Model for Knowledge Graph Completion. In Proceedings of the ICPR, Beijing, China, 20–24 August 2018; pp. 290–295. [Google Scholar]
- Zhang, Y.; Du, Z.; Meng, X. EMT: A Tail-Oriented Method for Specific Domain Knowledge Graph Completion. In Proceedings of the PAKDD, Macau, China, 14–17 April 2019; pp. 514–527. [Google Scholar]
- Yao, J.; Zhao, Y. Knowledge Graph Embedding Bi-vector Models for Symmetric Relation. In Chinese Intelligent Systems Conference; Springer: Singapore, 2019. [Google Scholar]
- Yang, S.; Tian, J.; Zhang, H.; Yan, J.; He, H.; Jin, Y. TransMS: Knowledge Graph Embedding for Complex Relations by Multidirectional Semantics. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 1935–1942. [Google Scholar]
- Ebisu, T.; Ichise, R. Generalized Translation-Based Embedding of Knowledge Graph. IEEE Trans. Knowl. Data Eng. 2020, 32, 941–951. [Google Scholar] [CrossRef]
- Cui, Z.; Liu, S.; Pan, L.; He, Q. Translating Embedding with Local Connection for Knowledge Graph Completion. In Proceedings of the AAMAS, Auckland, New Zealand, 9–13 May 2020; pp. 1825–1827. [Google Scholar]
- He, S.; Liu, K.; Ji, G.; Zhao, J. Learning to Represent Knowledge Graphs with Gaussian Embedding. In Proceedings of the CIKM, Melbourne, VIC, Australia, 19–23 October 2015; pp. 623–632. [Google Scholar]
- Xiao, H.; Huang, M.; Hao, Y.; Zhu, X. TransG: A Generative Mixture Model for Knowledge Graph Embedding. ACL 2015, 1, 2316–2325. [Google Scholar]
- Song, H.J.; Park, S.B. Enriching translation-based knowledge graph embeddings through continual learning. IEEE Access 2018, 6, 60489–60497. [Google Scholar] [CrossRef]
- Ebisu, T.; Ichise, R. TorusE: Knowledge Graph Embedding on a Lie Group; AAAI Press: Palo Alto, CA, USA, 2018; pp. 1819–1826. [Google Scholar]
- Zhang, S.; Tay, Y.; Yao, L.; Liu, Q. Quaternion Knowledge Graph Embeddings. arXiv 2019, arXiv:1904.10281. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. In Proceedings of the AAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 3065–3072. [Google Scholar]
- Kong, X.; Chen, X.; Hovy, E.H. Decompressing Knowledge Graph Representations for Link Prediction. arXiv 2019, arXiv:1911.04053. [Google Scholar]
- Chen, Y.; Liu, J.; Zhang, Z.; Wen, S.; Xiong, W. MobiusE: Knowledge Graph Embedding on Mobius Ring. arXiv 2021, arXiv:2101.02352, arXiv. [Google Scholar]
- Chen, H.; Wang, W.; Li, G.; Shi, Y. A quaternion-embedded capsule network model for knowledge graph completion. IEEE Access 2020, 8, 100890–100904. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the ICML, Washington, DC, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs; AAAI: Phoenix, AZ, USA, 2016; pp. 1955–1961. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical Inference for Multi-Relational Embeddings; ICML: Sydney, NSW, Australia, 2017; pp. 2168–2178. [Google Scholar]
- Lacroix, T.; Usunier, N.; Obozinski, G. Canonical Tensor Decomposition for Knowledge Base Completion. In Proceedings of the ICML, Vienna, Austria, 23–31 July 2018; pp. 2869–2878. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, M.T. TuckER: Tensor Factorization for Knowledge Graph Completion; EMNLP/IJCNLP: Hong Kong, China, 2019; pp. 5184–5193. [Google Scholar]
- Mohamed, S.K.; Novácek, V. Link Prediction Using Multi Part Embeddings. In Proceedings of the ESWC, Portoroz, Slovenia, 2–6 June 2019; pp. 240–254. [Google Scholar]
- Zhang, W.; Paudel, B.; Zhang, W.; Bernstein, A.; Chen, H. Interaction Embeddings for Prediction and Explanation in Knowledge Graphs; WSDM: Melbourne, VIC, Australia, 2019; pp. 96–104. [Google Scholar]
- Xue, Y.; Yuan, Y.; Xu, Z.; Sabharwal, A. Expanding Holographic Embeddings for Knowledge Completion. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Tran, H.N.; Takasu, A. Multi-Partition Embedding Interaction with Block Term Format for Knowledge Graph Completion. In Proceedings of the ECAI, Copenhagen, Denmark, 19–24 July 2020; pp. 833–840. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M.g. Representation Learning of Knowledge Graphs with Hierarchical Types. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, B.; Wang, L.; Guo, L. SSE: Semantically Smooth Embedding for Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2017, 29, 884–897. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, Q.; Qi, B.; Qiu, Y.; Li, P.; Wang, B. Attentive Path Combination for Knowledge Graph Completion. In Proceedings of the ACML, Seoul, Korea, 15–17 November 2017; pp. 590–605. [Google Scholar]
- Moon, C.; Jones, P.; Samatova, N.F. Learning Entity Type Embedding for Knowledge Graph Completion. In Proceedings of the CIKM, Singapore, 6–10 November 2017; pp. 2215–2218. [Google Scholar]
- Ma, S.; Ding, J.; Jia, W.; Wang, K.; Guo, M. TransT: Type-Based Multiple Embedding Representations for Knowledge Graph Completion. In Proceedings of the ECML/PKDD, Skopje, Macedonia, 18–22 September 2017; pp. 717–733. [Google Scholar]
- Kotnis, B.; Nastase, V. Learning Knowledge Graph Embeddings with Type Regularizer; K-CAP: Austin, TX, USA, 2017; pp. 1–4. [Google Scholar]
- Rahman, M.M.; Takasu, A. Knowledge Graph Embedding via Entities’ Type Mapping Matrix. In Proceedings of the ICONIP, Siem Reap, Cambodia, 13–16 December 2018. [Google Scholar]
- Zhou, B.; Chen, Y.; Liu, K.; Zhao, J. Relation and Fact Type Supervised Knowledge Graph Embedding via Weighted Scores. In Proceedings of the CCL, Kunming, Chinapp, 18–20 October 2019; pp. 258–267. [Google Scholar]
- Ma, J.; Zhong, M.; Wen, J.; Chen, W.; Zhou, X.; Li, X. RecKGC: Integrating Recommendation with Knowledge Graph Completion. In Proceedings of the ADMA, Dalian, China, 21–23 November 2019; pp. 250–265. [Google Scholar]
- Lin, X.; Liang, Y.; Giunchiglia, F.; Feng, X.; Guan, R. Relation path embedding in knowledge graphs. Neur. Comput. Appl. 2019, 31, 5629–5639. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Liu, Z.; Luan, H.B.; Sun, M.; Rao, S.; Liu, S. Modeling Relation Paths for Representation Learning of Knowledge Bases. arXiv 2015, arXiv:1506.00379. [Google Scholar]
- Zeng, P.; Tan, Q.; Meng, X.; Zhang, H.; Xu, J. Modeling Complex Relationship Paths for Knowledge Graph Completion. IEICE Transact. 2018, 101, 1393–1400. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Wang, Y.; Jin, X.; Cheng, X. Path-specific knowledge graph embedding. Knowl. Based Syst. 2018, 151, 37–44. [Google Scholar] [CrossRef]
- Xiong, S.; Huang, W.; Duan, P. Knowledge Graph Embedding via Relation Paths and Dynamic Mapping Matrix. In Proceedings of the ER Workshops, Xi’an, China, 22–25 October 2028; pp. 106–118. [Google Scholar]
- Zhang, M.; Wang, Q.; Xu, W.; Li, W.; Sun, S. Discriminative Path-Based Knowledge Graph Embedding for Precise Link Prediction. In Proceedings of the ECIR, Grenoble, France, 26–29 March 2018. [Google Scholar]
- Nastase, V.; Kotnis, B. Abstract Graphs and Abstract Paths for Knowledge Graph Completion. In Proceedings of the *SEM@NAACL-HLT 2019, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar]
- Sun, J.; Xu, G.; Cheng, Y.; Zhuang, T. Knowledge Map Completion Method Based on Metric Space and Relational Path. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 108–113. [Google Scholar]
- Wang, Q.; Huang, P.; Wang, H.; Dai, S.; Jiang, W.; Liu, J.; Lyu, Y.; Zhu, Y.; Wu, H. CoKE: Contextualized Knowledge Graph Embedding. arXiv 2019, arXiv:1911.02168. [Google Scholar]
- Wang, C.; Yan, M.; Yi, C.; Sha, Y. Capturing Semantic and Syntactic Information for Link Prediction in Knowledge Graphs. In Proceedings of the ISWC, Auckland, New Zealand, 26–30 October 2019; pp. 664–679. [Google Scholar]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs. In Proceedings of the ACL 2019, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Wang, R.; Li, B.; Hu, S.; Du, W.; Zhang, M. Knowledge Graph Embedding via Graph Attenuated Attention Networks. IEEE Access 2020, 8, 5212–5224. [Google Scholar] [CrossRef]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation Learning of Knowledge Graphs with Entity Descriptions; AAAI Press: Palo Alto, CA, USA, 2016; pp. 2659–2665. [Google Scholar]
- Xiao, H.; Huang, M.; Meng, L.; Zhu, X. SSP: Semantic Space Projection for Knowledge Graph Embedding with Text Descriptions; AAAI Press: Palo Alto, CA, USA, 2017; pp. 3104–3110. [Google Scholar]
- Chen, M.; Tian, Y.; Chang, K.-W.; Skiena, S.; Zaniolo, C. Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-Lingual Entity Alignment. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 3998–4004. [Google Scholar]
- Zhao, M.; Zhao, Y.; Xu, B. Knowledge Graph Completion via Complete Attention between Knowledge Graph and Entity Descriptions. In Proceedings of the CSAE, Sanya, China, 22–24 October 2019. [Google Scholar]
- Veira, N.; Keng, B.; Padmanabhan, K.; Veneris, A.G. Unsupervised Embedding Enhancements of Knowledge Graphs using Textual Associations. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 5218–5225. [Google Scholar]
- Shah, H.; Villmow, J.; Ulges, A.; Schwanecke, U.; Shafait, F. An Open-World Extension to Knowledge Graph Completion Models; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3044–3051. [Google Scholar]
- Wang, S.; Jiang, C. Knowledge graph embedding with interactive guidance from entity descriptions. IEEE Access 2019, 7, 156686–156693. [Google Scholar]
- Ma, L.; Sun, P.; Lin, Z.; Wang, H. Composing Knowledge Graph Embeddings via Word Embeddings. arXiv 2019, arXiv:1909.03794. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Jointly embedding knowledge graphs and logical rules. In Proceedings of the EMNLP, Austin, TX, USA, 1–4 November 2016; pp. 192–202. [Google Scholar]
- Yoon, H.-G.; Song, H.-J.; Park, S.-B.; Park, S.-Y. A Translation-Based Knowledge Graph Embedding Preserving Logical Property of Relations. In Proceedings of the HLT-NAACL, San Diego, CA, USA, 21 May 2016; pp. 907–916. [Google Scholar]
- Du, J.; Qi, K.; Wan, H.; Peng, B.; Lu, S.; Shen, Y. Enhancing Knowledge Graph Embedding from a Logical Perspective. In Proceedings of the JIST, Gold Coast, Australia, 10–12 November 2017; pp. 232–247. [Google Scholar]
- Han, X.; Zhang, C.; Sun, T.; Ji, Y.; Hu, Z. A triple-branch neural network for knowledge graph embedding. IEEE Access 2018, 6, 76606–76615. [Google Scholar] [CrossRef]
- Yuan, J.; Gao, N.; Xiang, J. TransGate: Knowledge Graph Embedding with Shared Gate Structure; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3100–3107. [Google Scholar]
- Wang, M.; Rong, E.; Zhuo, H.; Zhu, H. Embedding Knowledge Graphs Based on Transitivity and Asymmetry of Rules. In Proceedings of the PAKDD, Melbourne, VIC, Australia, 3–6 June 2018; pp. 141–153. [Google Scholar]
- Wang, P.; Dou, D.; Wu, F.; Silva, N.; Jin, L. Logic Rules Powered Knowledge Graph Embedding. arXiv 2019, arXiv:1903.03772. [Google Scholar]
- Zhang, J.; Li, J. Enhanced Knowledge Graph Embedding by Jointly Learning Soft Rules and Facts. Algorithms 2019, 12, 265. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Guan, Y.; Missier, P. Towards Learning Instantiated Logical Rules from Knowledge Graphs. arXiv 2020, arXiv:2003.06071. [Google Scholar]
- Das, R.; Godbole, A.; Dhuliawala, S.; Zaheer, M.; McCallum, A. A Simple Approach to Case-Based Reasoning in Knowledge Bases; AKBC: San Francisco, CA, USA, 2020. [Google Scholar]
- Das, R.; Godbole, A.; Monath, N.; Zaheer, M.; McCallum, A. Probabilistic Case-based Reasoning for Open-World Knowledge Graph Completion. arXiv 2020, arXiv:2010.03548. [Google Scholar]
- García-Durán, A.; Niepert, M. KBLRN: End-to-End Learning of Knowledge Base Representations with Latent, Relational, and Numerical Features. In Proceedings of the UAI, Monterey, CA, USA, 6–10 August 2018; pp. 372–381. [Google Scholar]
- Wu, Y.; Wang, Z. Knowledge Graph Embedding with Numeric Attributes of Entities. In Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; pp. 132–136. [Google Scholar]
- Kristiadi, A.; Khan, M.A.; Lukovnikov, D.; Lehmann, J.; Fischer, A. Incorporating Literals into Knowledge Graph Embeddings. In Proceedings of the ISWC, Auckland, New Zealand, 26–30 October 2019; pp. 347–363. [Google Scholar]
- Feng, M.-H.; Hsu, C.-C.; Li, C.-T.; Yeh, M.-Y.; Lin, S.-D. MARINE: Multi-relational Network Embeddings with Relational Proximity and Node Attributes. In The World Wide Web Conference; ACM: New York, NY, USA, 2019; pp. 470–479. [Google Scholar]
- Zhang, Z.; Cao, L.; Chen, X.; Tang, W.; Xu, Z.; Meng, Y. Repressentation Learning of Knowledge Graphs With Entity Attributes. IEEE Access 2020, 7435–7441. [Google Scholar] [CrossRef]
- Jiang, T.; Liu, T.; Ge, T.; Sha, L.; Li, S.; Chang, B.; Sui, Z. Encoding Temporal Information for Time-Aware Link Prediction. In Proceedings of the EMNLP, Austin, TX, USA, 1–4 November 2016. [Google Scholar]
- Esteban, C.; Tresp, V.; Yang, Y.; Baier, S.; Krompass, D. Predicting the co-evolution of event and Knowledge Graphs. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016. [Google Scholar]
- Trivedi, R.; Dai, H.; Wang, Y.; Song, L. Know-evolve: Deep Temporal Reasoning for Dynamic Knowledge Graphs. In Proceedings of the ICML, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 3462–3471. [Google Scholar]
- Jia, Y.; Wang, Y.; Jin, X.; Lin, H.; Cheng, X. Knowledge Graph Embedding: A Locally and Temporally Adaptive Translation-Based Approach. ACM Trans. Web 2018, 12, 8:1–8:33. [Google Scholar] [CrossRef]
- Dasgupta, S.S.; Ray, S.N.; Talukdar, P.P. HyTE: Hyperplane-based Temporally aware Knowledge Graph Embedding. In Proceedings of the EMNLP, Jeju, Korea, 31 October–4 November 2018; pp. 2001–2011. [Google Scholar]
- Xu, C.; Nayyeri, M.; Alkhoury, F.; Lehmann, J.; Yazdi, H.S. Temporal Knowledge Graph Completion Based on Time Series Gaussian Embedding. In Proceedings of the ISWC, Athens, Greece, 2–6 November 2020; pp. 654–671. [Google Scholar]
- Chen, S.; Qiao, L.; Liu, B.; Bo, J.; Cui, Y.; Li, J. Knowledge Graph Embedding Based on Hyperplane and Quantitative Credibility. In Proceedings of the MLICOM, Nanjing, China, 24–25 August 2019; pp. 583–594. [Google Scholar]
- Tang, X.; Yuan, R.; Li, Q.; Wang, T.; Yang, H.; Cai, Y.; Song, H. Timespan-Aware Dynamic Knowledge Graph Embedding by Incorporating Temporal Evolution. IEEE Access 2020, 8, 6849–6860. [Google Scholar] [CrossRef]
- Jung, J.; Jung, J.; Kang, U. T-GAP: Learning to Walk across Time for Temporal Knowledge Graph Completion. arXiv 2020, arXiv:2012.10595. [Google Scholar]
- Wu, J.; Cao, M.; Cheung, J.K.; Hamilton, W.L. TeMP: Temporal Message Passing for Temporal Knowledge Graph Completion. arXiv 2020, arXiv:2010.03526. [Google Scholar]
- Feng, J.; Huang, M.; Yang, Y.; Zhu, X. GAKE: Graph Aware Knowledge Embedding. In Proceedings of the COLING, Osaka, Japan, 11–16 December 2016. [Google Scholar]
- Zhou, C.; Liu, Y.; Liu, X.; Liu, Z.; Gao, J. Scalable Graph Embedding for Asymmetric Proximity; AAAI Press: Palo Alto, CA, USA, 2017; pp. 2942–2948. [Google Scholar]
- Zhang, W. Knowledge Graph Embedding with Diversity of Structures. In Proceedings of the WWW (Companion Volume), Perth, Australia, 3–7 April 2017. [Google Scholar]
- Pal, S.; Urbani, J. Enhancing Knowledge Graph Completion By Embedding Correlation. In Proceedings of the CIKM, Singapore, 6–10 November 2017; pp. 2247–2250. [Google Scholar]
- Shi, J.; Gao, H.; Qi, G.; Zhou, Z. Knowledge Graph Embedding with Triple Context. In Proceedings of the CIKM, Singapore, 6–10 November 2017; pp. 2299–2302. [Google Scholar]
- Gao, H.; Shi, J.; Qi, G.; Wang, M. Triple context-based knowledge graph embedding. IEEE Access 2018, 6, 58978–58989. [Google Scholar] [CrossRef]
- Li, W.; Zhang, X.; Wang, Y.; Yan, Z.; Peng, R. Graph2Seq: Fusion Embedding Learning for Knowledge Graph Completion. IEEE Access 2019, 7, 157960–157971. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhuang, F.; Qu, M.; Lin, F.; He, Q. Knowledge Graph Embedding with Hierarchical Relation Structure. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3198–3207. [Google Scholar]
- Han, X.; Zhang, C.; Guo, C.; Sun, T.; Ji, Y. Knowledge Graph Embedding Based on Subgraph-Aware Proximity; AAAI Press: Palo Alto, CA, USA, 2018; pp. 306–318. [Google Scholar]
- Tan, Y.; Li, R.; Zhou, J.; Zhu, S. Knowledge Graph Embedding by Translation Model on Subgraph. In Proceedings of the HCC, Mérida, Mexico, 5–7 December 2018; pp. 269–280. [Google Scholar]
- Zhang, Y.; Yao, Q.; Chen, L. Neural Recurrent Structure Search for Knowledge Graph Embedding. arXiv 2019, arXiv:1911.07132. [Google Scholar]
- Wan, G.; Du, B.; Pan, S.; Wu, J. Adaptive knowledge subgraph ensemble for robust and trustworthy knowledge graph completion. World Wide Web 2020, 23, 471–490. [Google Scholar] [CrossRef]
- Qiao, Z.; Ning, Z.; Du, Y.; Zhou, Y. Context-Enhanced Entity and Relation Embedding for Knowledge Graph Completion. arXiv 2020, arXiv:2012.07011. [Google Scholar]
- Ding, B.; Wang, Q.; Wang, B.; Guo, L. Improving Knowledge Graph Embedding Using Simple Constraints. In Proceedings of the ACL, Trujillo, Perupp, 13–16 November 2019; pp. 110–121. [Google Scholar]
- Huang, Y.; Xu, K.; Wang, X.; Sun, H.; Lu, S.; Wang, T.; Zhang, X. CoRelatE: Modeling the Correlation in Multi-fold Relations for Knowledge Graph Embedding. In Proceedings of the ICLR, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Kanojia, V.; Maeda, H.; Togashi, R.; Fujita, S. Enhancing Knowledge Graph Embedding with Probabilistic Negative Sampling. In Proceedings of the 26th International Conference on World Wide Web Companion; ACM: New York, NY, USA, 2017; pp. 801–802. [Google Scholar]
- Niu, J.; Sun, Z.; Zhang, W. Enhancing Knowledge Graph Completion with Positive Unlabeled Learning. In Proceedings of the IICPR, Beijing, China, 20–24 August 2018; pp. 296–301. [Google Scholar]
- Qin, S.; Rao, G.; Bin, C.; Chang, L.; Gu, T.; Xuan, W. Knowledge Graph Embedding Based on Adaptive Negative Sampling. In Proceedings of the ICPCSEE, Guilin, China, 20–23 September 2019; pp. 551–563. [Google Scholar]
- Yan, Z.; Peng, R.; Wang, Y.; Li, W. Enhance knowledge graph embedding via fake triples. In Proceedings of the IJCNN, Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Guo, C.; Zhang, C.; Han, X.; Ji, Y. AWML: Adaptive weighted margin learning for knowledge graph embedding. J. Intell. Inf. Syst. 2019, 53, 167–197. [Google Scholar] [CrossRef]
- Yuan, J.; Gao, N.; Xiang, J.; Tu, C.; Ge, J. Knowledge Graph Embedding with Order Information of Triplets. In Proceedings of the PAKDD, Macau, China, 14–17 April 2019; pp. 476–488. [Google Scholar]
- Wang, Y.; Liu, Y.; Zhang, H.; Xie, H. Leveraging Lexical Semantic Information for Learning Concept-Based Multiple Embedding Representations for Knowledge Graph Completion. In Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data; Springer: Berlin/Heidelberg, Germany, 2019; pp. 382–397. [Google Scholar]
- Guan, N.; Song, D.; Liao, L. Knowledge graph embedding with concepts. Knowl. Based Syst. 2019, 164, 38–44. [Google Scholar] [CrossRef]
- Yu, Y.; Xu, Z.; Lv, Y.; Li, J. TransFG: A Fine-Grained Model for Knowledge Graph Embedding. In Proceedings of the WISA, Qingdao, China, 20–22 September 2019. [Google Scholar]
- Kazemi, S.M.; Poole, D. SimplE Embedding for Link Prediction in Knowledge Graphs. NeurIPS 2018. [Google Scholar]
- Fatemi, B.; Ravanbakhsh, S.; Poole, D. Improved Knowledge Graph Embedding Using Background Taxonomic Information; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3526–3533. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A.Y. Reasoning With Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 926–934. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the KDD, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Liu, Q.; Jiang, H.; Ling, Z.H.; Wei, S.; Hu, Y. Probabilistic Reasoning via Deep Learning: Neural Association Models. arXiv 2016, arXiv:1603.07704. [Google Scholar]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; Berg, R.v.d.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the ESWC, Crete, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Guo, L.; Zhang, Q.; Ge, W.; Hu, W.; Qu, Y. DSKG: A Deep Sequential Model for Knowledge Graph Completion. In Proceedings of the CCKS, Tianjin, China, 14–17 August 2018; pp. 65–77. [Google Scholar]
- Guan, S.; Jin, X.; Wang, Y.; Cheng, X. Shared Embedding Based Neural Networks for Knowledge Graph Completion. In Proceedings of the CIKM, Turin, Italy, 22–26 October 2018; pp. 247–256. [Google Scholar]
- Zhu, Q.; Zhou, X.; Zhang, P.; Shi, Y. A neural translating general hyperplane for knowledge graph embedding. J. Comput. Sci. 2019, 30, 108–117. [Google Scholar] [CrossRef]
- Huang, Z.; Li, B.; Yin, J. Knowledge Graph Embedding by Learning to Connect Entity with Relation. In Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data; Springer: Berlin/Heidelberg, Germany, 2018; pp. 400–414. [Google Scholar]
- Wang, L.; Lu, X.; Jiang, Z.; Zhang, Z.; Li, R.; Zhao, M.; Chen, D. FRS: A simple knowledge graph embedding model for entity prediction. Math. Biosci. Eng. 2019, 16, 7789–7807. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Nguyen, T.D.; Phung, D.Q. A Relational Memory-based Embedding Model for Triple Classification and Search Personalization. arXiv 2019, arXiv:1907.06080. [Google Scholar]
- Cai, L.; Yan, B.; Mai, G.; Janowicz, K.; Zhu, R. TransGCN: Coupling Transformation Assumptions with Graph Convolutional Networks for Link Prediction. In Proceedings of the K-CAP, Marina Del Rey, CA, USA, 19–21 November 2019; pp. 131–138. [Google Scholar]
- Ye, R.; Li, X.; Fang, Y.; Zang, H.; Wang, M. A Vectorized Relational Graph Convolutional Network for Multi-Relational Network Alignment. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 4135–4141. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Agrawal, N.; Talukdar, P.P. InteractE: Improving Convolution-Based Knowledge Graph Embeddings by Increasing Feature Interactions; AAAI Press: Palo Alto, CA, USA, 2020; pp. 3009–3016. [Google Scholar]
- Hu, K.; Liu, H.; Zhan, C.; Tang, Y.; Hao, T. A Bi-Directional Relation Aware Network for Link Prediction in Knowledge Graph. In Proceedings of the International Conference on Neural Computing for Advanced Applications, Shenzhen, China, 3–5 July 2020; pp. 259–271. [Google Scholar]
- Hu, K.; Liu, H.; Zhan, C.; Tang, Y.; Hao, T. Learning Knowledge Graph Embedding with a Bi-Directional Relation Encoding Network and a Convolutional Autoencoder Decoding Network; Neural Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–17. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Chen, J.; Zhang, W.; Chen, H. Relation Adversarial Network for Low Resource Knowledge Graph Completion. In Proceedings of the WWW, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Tian, A.; Zhang, C.; Rang, M.; Yang, X.; Zhan, Z. RA-GCN: Relational Aggregation Graph Convolutional Network for Knowledge Graph Completion. In Proceedings of the ICMLC, Shenzhen China, 15–17 February 2020; pp. 580–586. [Google Scholar]
- Jiang, W.; Guo, M.; Chen, Y.; Li, Y.; Xu, J.; Lyu, Y.; Zhu, Y. Multi-view Classification Model for Knowledge Graph Completion. In Proceedings of the AACL/IJCNLP, Suzhou, China, 4–7 December 2020. [Google Scholar]
- Zeb, A.; Haq, A.U.; Zhang, D.; Chen, J.; Gong, Z. KGEL: A novel end-to-end embedding learning framework for knowledge graph completion. Expert Syst. Appl. 2021, 167, 114164. [Google Scholar] [CrossRef]
- Han, Y.; Fang, Q.; Hu, J.; Qian, S.; Xu, C. GAEAT: Graph Auto-Encoder Attention Networks for Knowledge Graph Completion. In Proceedings of the CIKM, New York, NY, USA, 15–19 July 2020; pp. 2053–2056. [Google Scholar]
- Wang, Q.; Ji, Y.; Hao, Y.; Cao, J. GRL: Knowledge graph completion with GAN-based reinforcement learning. Knowl. Based Syst. 2020, 209, 106421. [Google Scholar] [CrossRef]
- Shi, B.; Weningr, T. ProjE: Embedding Projection for Knowledge Graph Completion; AAAI Press: Palo Alto, CA, USA, 2017; pp. 1236–1242. [Google Scholar]
- Liu, H.; Bai, L.; Ma, X.; Yu, W.; Xu, C. ProjFE: Prediction of fuzzy entity and relation for knowledge graph completion. Appl. Soft Comput. 2019, 81, 105525. [Google Scholar] [CrossRef]
- Zhang, W.; Li, J.; Chen, H. ProjR: Embedding Structure Diversity for Knowledge Graph Completion. In Proceedings of the NLPCC, Hohhot, China, 26–30 August 2018; pp. 145–157. [Google Scholar]
- Shi, B.; Weninger, T. Open-World Knowledge Graph Completion; AAAI Press: Palo Alto, CA, USA, 2018; pp. 1957–1964. [Google Scholar]
- Fu, C.; Li, Z.; Yang, Q.; Chen, Z.; Fang, J.; Zhao, P.; Xu, J. Multiple Interaction Attention Model for Open-World Knowledge Graph Completion. In International Conference on Web Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 630–644. [Google Scholar]
- Nie, B.; Sun, S. Knowledge graph embedding via reasoning over entities, relations, and text. Future Gener. Computer Syst. 2019, 91, 426–433. [Google Scholar] [CrossRef]
- Zhu, J.; Zheng, Z.; Yang, M.; Fung, G.P.C.; Tang, Y. A semi-supervised model for knowledge graph embedding. Data Min. Knowl. Discov. 2020, 34, 1–20. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, S.; Chen, X.; Xu, C.; Guo, W. Generative adversarial networks based on Wasserstein distance for knowledge graph embeddings. Knowl. Based Syst. 2020, 190, 105165. [Google Scholar] [CrossRef]
- Wang, P.; Han, J.; Li, C.; Pan, R. Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding; AAAI Press: Palo Alto, CA, USA, 2019; pp. 7152–7159. [Google Scholar]
- Qian, W.; Fu, C.; Zhu, Y.; Cai, D.; He, X. Translation Embeddings for Knowledge Graph Completion with Relation Attention Mechanism. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4286–4292. [Google Scholar]
- Liu, W.; Cai, H.; Cheng, X.; Xie, S.; Yu, Y.; Zhang, H. Learning High-order Structural and Attribute information by Knowledge Graph Attention Networks for Enhancing Knowledge Graph Embedding. arXiv 2019, arXiv:1910.03891. [Google Scholar]
- Liu, Y.; Hua, W.; Xin, K.; Zhou, X. Context-Aware Temporal Knowledge Graph Embedding. In Proceedings of the WISE, Hong Kong, China, 26–30 November 2019. [Google Scholar]
- Oh, B.; Seo, S.; Lee, K.-H. Knowledge Graph Completion by Context-Aware Convolutional Learning with Multi-Hope Neighborhoods. In Proceedings of the CIKM, Turin, Italy, 22–26 October 2018; pp. 257–266. [Google Scholar]
- Wu, T.; Khan, A.; Gao, H.; Li, C. Efficiently Embedding Dynamic Knowledge Graphs. arXiv 2019, arXiv:1910.06708. [Google Scholar]
- Han, X.; Zhang, C.; Ji, Y.; Hu, Z. A Dilated Recurrent Neural Network-Based Model for Graph Embedding. IEEE Access 2019, 7, 32085–32092. [Google Scholar] [CrossRef]
- Tay, Y.; Luu, A.T.; Phan, M.C.; Hui, S.C. Multi-task Neural Network for Non-discrete Attribute Prediction in Knowledge Graphs. In Proceedings of the CIKM 2017, Singapore, 6–10 November 2017. [Google Scholar]
- Nayyeri, M.; Xu, C.; Lehmann, J.; Yazdi, H.S. LogicENN: A Neural Based Knowledge Graphs Embedding Model with Logical Rules. arXiv 2019, arXiv:1908.07141. [Google Scholar]
- Zhao, F.; Xu, T.; Jin, L.; Jin, H. Convolutional Network Embedding of Text-enhanced Representation for Knowledge Graph Completion. IEEE Int. Things J. 2020. [Google Scholar] [CrossRef]
- Wang, H.; Ren, H.; Leskovec, J. Entity Context and Relational Paths for Knowledge Graph Completion. arXiv 2020, arXiv:2002.06757. [Google Scholar]
- Wang, Y.; Zhang, H. HARP: A Novel Hierarchical Attention Model for Relation Prediction. ACM Trans. Knowl. Discov. Data TKDD 2021, 15, 1–22. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Subcategories | Models |
|---|---|---|
| Based on translation distance | TransE and its extensions | TransE [13], TransH [15], TransM [16], TransR [17], TransD [36], TransA [37], TranSparse [38], ManifoldE [39], STransE [40], TransX-FT [41], TransX-DT [42], TransHR [43], CirE [44], GTrans [45], TransCore [46], TransF [47], TransGH [48], AEM [49], EMT [50], TransX-SYM [51], TransMS [52], KGLG [53], TransL [54]. |
| Gaussian embedding | KG2E [55], TransG [56]. | |
| Others | KGE Continual Learning [57], TorusE [58], QuatE [59], RotatE [35], HAKE [60], DeCom [61], MobiusE [62], QuaR [63]. | |
| Based on semantic information | No additional information | RESCAL [64], DistMult [20], Hole [65], ComplEx [21], ANALOGY [66], ComplEx-N3 [67], TuckER [68], TriModel [69], CrossE [70], HolEx [71], MEI [72]. |
| Fusing additional information | Entity/relation types: TKRL [73], SSE [74], Att-Model+Types [75], ETE [76], TransT [77], Bilinear+TR [78], TransET [79], KGE via weighted score [80], RecKGC [81], RPE [82]. Relation paths: PTransE [83], Att-Model+Types [75], TransP [84], PaSKoGE [85], PTransD [86], DPTransE [87], abstract paths for KGC [88], ELPKG [9], PTranSparse [89], CoKE [90], RPE [82], RW-LMLM [91], KBAT [92], GAATs [93], path-based reasoning [27]. Textual descriptions: DKRL [94], SSP [95], KDCoE [96], CATT [97], textural association [98], pen-world extension for KGC [99], EDGE [100], TransW [101]. Logic rules: KALE [102], lppTransX [103], BiTransX+ [104], ELPKG [9], X-lc [105], RUGE [106], TARE [107], logic rule powered KGE [108], SoLE [109], GPFL [110], CBR [111], probabilistic case-based reasoning [112]. Entity attributes: KBLRN [113], TransEA [114], LiteralE [115], MARINE [116], AKRL [117]. Temporal: Time-aware link prediction [118], co-evolution of event and KGs [119], Know-Evolve [120], iTransA [121], HyTE [122], ATiSE [123], QCHyTE [124], TDG2E [125], T-GAP [126], TeMP [127]. Structure: GAKE [128], APP [129], ORC [130], KGC by embedding correlations [131], TCE(2017) [132], TCE(2018) [133], Graph2Seq [134], HRS [135], SA-KGE [136], TransS [137], S2E [138], AKSE [139], AggrE [140]. Constraints: ComplEx+NNE+AER [141], RPE [82], CoRelatE [142]. Negative sampling: TransR-PNC [143], TSLRF [144], TransE-ANS [145]. Fake triples: KGE via fake triples [146], AWML [147]. Order: RKGE [148], RW-LMLM [91]. Concepts: TransC [149], KEC [150], TransFG [151]. Background: SimplE [152], SimplE+ [153]. | |
| Based on neural network | No additional information | SME [154], NTN [155], MLP [156], NAM [157], R-GCNs [158], DSKG [159], SENN [160], TBNN [105], NTransGH [161], ConvE [22], ConvKB [23], ConnectER [162], FRS [163], HypER [24], CompGCN [25], TransGate [106], R-MeN [164], TransGCN [165], VR-GCN [166], InteractE [167], KBAT [92], BDRAN [168], BDR+CA [169], wRAN [170], RA-GCN [171], path-based reasoning [72], MultiView [172], KGEL [173], GAEAT [174], GRL [175]. |
| Fusing additional information | ProjE [176], ProjFE [177], ProjR [178], SACN [26], CNN-BiLSTM [27], ConMask [179], MIA Model [180], TKGE [181], a semi-supervised model for KGE [182], GAN based on Wasserstein [183], LAN [184], TransAt [185], KANE [186], context-aware temporal KGE [187], CACL [188], DKGE [189], G-DRNN [190], MTKGNN [191], LogicENN [192], TECRL [193], PATHCON [194], HARP [195]. |
| Model | Symmetry | Antisymmetry | Inversion | Composition |
|---|---|---|---|---|
| SE | ✕ | ✕ | ✕ | ✕ |
| TransE | ✕ | ✓ | ✓ | ✓ |
| TransX | ✓ | ✓ | ✕ | ✕ |
| DistMult | ✓ | ✕ | ✕ | ✕ |
| ComplEx | ✓ | ✓ | ✓ | ✕ |
| RotatE | ✓ | ✓ | ✓ | ✓ |
| Dataset | Entity | Relation | Triple | Train | Valid | Test |
|---|---|---|---|---|---|---|
| FB15k | 14,951 | 1345 | 592,213 | 483,142 | 50,000 | 59,071 |
| FB15k-237 | 14,541 | 237 | 310,116 | 272,115 | 17,535 | 20,466 |
| Categories | Model | Embedding Space | Additional Information | Scoring Function |
|---|---|---|---|---|
| Based on | RotatE | Complex | None | |
| translation | space | |||
| distance | HAKE | Vector | None | |
| space | ||||
| Based on | RW-LMLM | Matrix | Order | |
| semantic | space | information | ||
| information | SimplE | Vector | Background | |
| space | knowledge | |||
| LiteralE | Vector | Literal | ||
| space | information | |||
| Bilinear+TR | Tensor | Entity | ||
| space | types | |||
| ComplEx | Complex | None | ||
| space | ||||
| DistMult | Vector | None | ||
| space | ||||
| Based on | SACN | Vector | Relation | |
| neural | space | types | ||
| network | ConvE | Vector | None | |
| space | ||||
| HypER | Vector | None | ||
| space |
| Model | FB15k-237 | FB15k | ||||||
|---|---|---|---|---|---|---|---|---|
| Hits@1 | Hits@3 | Hits@10 | MRR | Hits@1 | Hits@3 | Hits@10 | MRR | |
| RotatE | 0.2471 | 0.3802 | 0.5370 | 0.3432 | 0.7387 | 0.8240 | 0.8797 | 0.7905 |
| HAKE | 0.2561 | 0.3871 | 0.5488 | 0.3523 | 0.5745 | 0.7614 | 0.8482 | 0.6809 |
| Bilinear+ | 0.1288 | 0.1524 | 0.1912 | 0.1503 | 0.1522 | 0.1584 | 0.1695 | 0.1604 |
| TR-TransE | ||||||||
| Bilinear+ | 0.2370 | 0.3549 | 0.4855 | 0.3246 | 0.4119 | 0.5683 | 0.6586 | 0.5064 |
| TR-bilinear | ||||||||
| DistMult | 0.2129 | 0.3215 | 0.4635 | 0.2953 | 0.3055 | 0.4230 | 0.5149 | 0.3785 |
| ComplEx | 0.2014 | 0.3165 | 0.4526 | 0.2851 | 0.4407 | 0.5366 | 0.6168 | 0.5028 |
| LiteralE+ | 0.2192 ↓ | 0.3285 ↓ | 0.4651 ↓ | 0.3013 ↓ | 0.2730 ↓ | 0.3537 ↓ | 0.4431 ↓ | 0.3323 ↓ |
| text+DistMult | ||||||||
| LiteralE+ | 0.2209 | 0.3279 | 0.4628 | 0.3022 | 0.2917 ↓ | 0.3820 ↓ | 0.4758 ↓ | 0.3555 ↓ |
| DistMult | ||||||||
| LiteralE+ | 0.1936 ↓ | 0.3029 ↓ | 0.4397 ↓ | 0.2753 ↓ | 0.5138 | 0.6102 | 0.6963 | 0.5777 |
| ComplEx | ||||||||
| LiteralE+ | 0.2092 ↓ | 0.3277 ↓ | 0.4675 ↓ | 0.2963 ↓ | 0.6055 ↓ | 0.7014 ↓ | 0.7768 ↓ | 0.6667 ↓ |
| ConvE | ||||||||
| SimplE | 0.0895 | 0.1701 | 0.3170 | 0.1623 | 0.6593 | 0.7758 | 0.8434 | 0.7283 |
| RW-LMLM | 0.2249 | 0.3396 | 0.4859 | 0.3109 | 0.6767 | 0.7947 | 0.8648 | 0.7466 |
| ConvE | 0.2212 | 0.3371 | 0.4787 | 0.3070 | 0.6250 | 0.7254 | 0.7956 | 0.6874 |
| SACN | 0.2522 | 0.3699 | 0.5154 | 0.3400 | - | - | - | - |
| HypER | 0.2482 | 0.3629 | 0.5080 | 0.3335 | 0.7005 | 0.8167 | 0.8799 | 0.7668 |
| Categories | Models | Training Time |
|---|---|---|
| Based on | HAKE | 4.8908 h |
| translation distance | RotatE | 6.9708 h |
| Based on | Bilinear+TR_bilinear | 1.8083 h |
| semantic | Bilinear+TR_transE | 1.8935 h |
| information | SimplE | 4.4111 h |
| LiteralE-ComplEx | 11.1810 h | |
| DistMult | 31.5515 h | |
| RW-LMLM | 33.6141 h | |
| ComplEx | 38.1560 h | |
| LiteralE-DistMult | 42.3798 h | |
| LiteralE-text-DistMult | 44.9654 h | |
| Based on | HypER | 8.9695 h |
| neural | ConvE | 50.8799 h |
| network | LiteralE-ConvE | 60.1813 h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Qiu, L.; Wang, X. A Survey on Knowledge Graph Embeddings for Link Prediction. Symmetry 2021, 13, 485. https://doi.org/10.3390/sym13030485
Wang M, Qiu L, Wang X. A Survey on Knowledge Graph Embeddings for Link Prediction. Symmetry. 2021; 13(3):485. https://doi.org/10.3390/sym13030485
Chicago/Turabian StyleWang, Meihong, Linling Qiu, and Xiaoli Wang. 2021. "A Survey on Knowledge Graph Embeddings for Link Prediction" Symmetry 13, no. 3: 485. https://doi.org/10.3390/sym13030485