1. Introduction
Software defect prediction (SDP) is an essential procedure in software engineering. It involves the deployment of machine learning (ML) methods on software features or metrics derived from software systems repositories to predict the quality and reliability of a software system [
1,
2]. These software features are the quantifiable attributes of software system that can be analyzed to ascertain software systems quality and reliability [
3,
4]. Knowledge gained from SDP processes can be used by software engineers for improving software development processes and managing limited software resources. Software engineers are expected to develop high quality and reliable software systems with or within limited resources [
5,
6,
7].
Modern software systems are fundamentally massive and convolute with multiple and inter-related modules or components. In addition, these software systems are often periodically updated and upgraded with new features or functionalities based on new system requirements or software users demands. Determining the quality of these modern software systems can involve multiple software metrics (mechanisms) with varying capabilities [
8,
9,
10,
11]. Consequently, the number of software features generated is usually large leading to a high-dimensionality problem [
12,
13]. Some existing studies pointed out that the poor predictive performances of SDP models are often caused by the high dimensionality of software features. That is, the existence of irrelevant and redundant software metrics has negative effects on SDP model performance [
12,
13,
14,
15,
16,
17].
Data pre-processing task such as feature selection (FS) has been regarded as an important aspect in the prediction process as it enhances the efficiency of prediction models by improving the data quality [
18,
19]. Feature selection targets subsets of features in the original software features that can best represent the original features without losing its value. FS methods evaluate the available feature’s characteristics and determine a set of germane features based on labelled datasets [
19,
20,
21]. Therefore, deploying FS methods in SDP processes can mitigate the high dimensionality problem in SDP datasets.
The aforementioned reasons have motivated researchers to propose a range of FS methods in SDP to address the high dimensionality problem by selecting important and irredundant software features. Most of the existing studies are based on proposing and appraising the efficacy of novel FS methods on SDP models [
22,
23,
24]. This makes it crucial to continually compare and distinguish the efficacy of these FS methods. Some empirical studies on the impact and effectiveness of FS methods on SDP models have been conducted with varying results and conclusions [
2,
10,
20,
25,
26,
27,
28,
29,
30]. These empirical studies often lead to contradictory experimental results and inconsistent research findings.
Some researchers are opined that some specific FS methods are superior to others [
2,
10,
20,
25,
28,
31,
32], while some researchers postulated that there is not much difference in the efficacy of FS methods in SDP [
10,
26,
30,
33]. These contradictions and inconsistencies may be due to several sources of bias, such as small datasets, limited FS search methods, and unsuitable prediction models as a result of relative limitation in the scope of the respective studies. Ghotra, et al. [
25] and Xu, et al. [
28] in their respective studies deliberated that the contradictions may be from a limited number of SDP models and limited or quality of datasets used in the existing studies. In our initial study [
30], we addressed the contradiction based on various FS search methods. However, there is an imperative need for a more detailed study to address these contradictions and inconsistencies collectively. It is hence critical to carefully conduct an extensive empirical study to address these biases in order to guide the researchers and buttress the scientific tenacity of the experimental conclusions. This study aims to extend the existing empirical studies [
25,
28,
30] into an extensive empirical study by addressing the aforementioned biases.
Instigated by preceding findings, an extensive benchmark study of 46 FS methods (inclusive of NO FS method configuration) was conducted with two commonly used classifiers, i.e., naïve Bayes (NB) and decision tree (DT) to investigate the impact of FS methods on the predictive performances of SDP models. The 46 FS methods were selected based on three forms of FS methods (filter-feature-ranking (FFR), filter-feature-subset (FFS), and wrapper-based feature selection (WFS) methods) as used in the existing SDP studies [
20,
25,
28,
30]. Specifically, 13 FFR methods from 6 FFR families (statistical-based methods, probabilistic-based methods, instance-based methods, classifier-based methods, cluster-based methods, and projection-based methods), and two FFS methods from 2 FFS families (correlation-based feature selection (CFS) and consistency-based feature selection (CNS) methods). Thirteen distinct search methods (exhaustive and metaheuristic-based methods) were used for subset evaluators in each of the FFS methods, while the FFR was based on the ranker search method. Wrapper-based techniques were implemented based on three search mechanisms (linear forward search (LFS), subset-size forward selection (SFS), and incremental wrapper subset selection (IWSS)) and the respective classifiers (NB and DT) were used as the wrapper subset evaluators in respective cases. Each model was trained and tested using 25 datasets from four repositories (NASA, PROMISE, ReLink, and AEEEM). The predictive performances of each SDP model were based on accuracy and area under the curve (AUC) value. Statistical tests (Scott–Knott ESD and Double Scott–Knott Rank Test) were used to further analyze and statistically rank the FS methods based on their performances.
The main contributions of this study are as follows:
An extensive benchmark study on the impact of 46 FS methods on two classifiers over 25 datasets in SDP. An empirical study of this magnitude is the strength of this study.
This study addresses the biases found in the existing SDP studies in terms of limited FS methods, small datasets, and unsuitable prediction models. To the best of our knowledge, this is the first study to address these biases (limited FS methods, small datasets, and unsuitable prediction models), and no study has addressed them collectively.
This study establishes sets of good FS methods in lieu of a single method as potential and useful alternatives in real-life applications and other ML tasks.
This paper is organized as follows.
Section 2 presents the critically examined existing studies on FS methods in SDP. FS methods, prediction models, defect datasets, and evaluation metrics are presented in
Section 3.
Section 4 describes in detail the experimental framework and procedure. In
Section 5, we present and discuss our experimental results for the research findings.
Section 6 elaborates the threats to the validity of this study.
Section 7 concludes this paper and highlights some future works.
2. Related Studies
High dimensionality problem is one of the major data quality problems that affect the predictive performance of classifiers or prediction models in data classification or prediction tasks. SDP is no exception in this case as the high number of software features has a negative effect on the predictive performance of SDP models. As a solution to high dimensionality problem in SDP, feature selection methods are deployed to address this issue by selecting only the important and irredundant software features. Many existing studies have examined the efficacy of FS methods on the predictive performance of SDP models.
Shivaji, et al. [
34] investigated 6 FS methods in SDP using NB and support vector machine (SVM) on 11 defect datasets. They reported that FS methods improve the performance of SDP models. Afzal and Torkar [
20] empirically conducted a comparison of eight FS methods on five defect datasets from the PROMISE repository. Likewise, they reported that FS methods are beneficial for SDP as it improves the predictive performance of the studied classifiers (NB and DT). Regarding the impact of FS methods, there are no critical differences in the predictive performance (AUC) in the FS methods studied. However, a set of FSS methods were reported to be better than other FS methods as they regularly selected fewer features. Muthukumaran, et al. [
26] explored 10 FS methods (seven FFR, two wrapper methods, and one embedded method) on 16 defect datasets. Wrapper methods based on greedy search methods were superior to other FS methods in their study. Akintola, et al. [
3] conducted a comparative study of FFS methods on SDP. They reported that FFS methods improve the performance of SDP models. However, the scope of their study is only limited to FFS methods which are not the only form of the feature selection method. In addition, other forms of FS have been reported to be better than FFS [
35,
36]. Rodriguez, et al. [
24] also performed a comparative study on FS methods based on three different filter methods (CFS, CNS, and fast correlation-based filter (FCBF)) and two wrapper methods on four defect datasets. Their experimental results gave credit to small datasets as they maintain predictability with lesser features than the original datasets. They also reported that wrapper methods are superior to other FS methods examined. In another extensive study, Rathore and Gupta [
27] analyzed 15 FS methods with varying computational characteristics. From their results, information gain (IG) and principal component analysis (PCA) were superior to other FFR methods and ClassifierSubsetEval and logistic regression (LR) methods were better than other FFS methods. Kondo, et al. [
2] investigated the impact of feature reduction (FR) methods on SDP models. Eight FR methods were used on 10 prediction models (supervised and unsupervised). FR methods were reported to be superior when compared with two FS methods (CFS and CNS). However, FR methods construct new features from the original feature space which gives different meaning to the dataset [
37].
Ghotra, et al. [
25] conducted a large-scale empirical study of 28 FS methods on 21 classifiers over 18 datasets. From their study, based on the studied datasets, they reported that the correlation-based filter-FS (CFS) method using the best-first search (BFS) method is superior to other FS methods considered in their study. Nonetheless, the scope of the search methods used for their FFS method was limited to BFS, rank search (RS) and genetic algorithm (GA) search only. As there are many search methods that can be used for FS, there may be other search methods that may outperform the FS methods used in their study. Xu, et al. [
28] considered 32 FS methods for performance impact analysis in SDP with respect to controversies and limitations in existing studies. Their study focused on how noise and the type of defect dataset can affect SDP models. They reported that filter-based and wrapper-based methods are superior to other examined FS methods. However, their study only addressed the limitations of existing methods based on noise in the dataset. Balogun, et al. [
30] also investigated these inconsistencies by analyzing 18 FS methods over five defect datasets. Their study focused on the inconsistency by considering some set of search methods that were not used in existing studies [
25,
28]. Their results showed that there is no significant difference on the impact of the FS methods although FFR methods were more stable with respect to their performance accuracy values. However, the study can be extended in terms of datasets as small datasets were used and the number of search methods can be increased.
From these reviews, it is clear that FS methods enhance the predictive performances of SDP models. Several FS methods were used in SDP to enhance the SDP models as the adverse effect of misclassifications or wrong predictions of software defect can be disastrous [
15,
21]. However, inconsistencies and contradictory experimental results and research findings were observed in some of these studies as presented in
Table 1. It was observed that these contradictions are usually from the research scope of these studies which are in most cases relative. For instance, the size of defect datasets used in existing studies usually varies and relative to specific studie. Ghotra, et al. [
25] and Xu, et al. [
28] in their respective studies used 18 and 16 defects datasets, respectively. In other existing studies, lesser number of defects datasets were used [
3,
24,
30]. These datasets were from different repositories and have different characteristics. Gao, et al. [
10] conducted study on private datasets while some existing studies make use of publicly available defect datasets from NASA, PROMISE, or AEEEM. AEEEM dataset has been reported to be developed under different settings from NASA datasets. Thus, using findings from studies with a small or different datasets may not be sufficient as defect datasets are developed under different conditions [
28]. Hence, this may be one of the causes for the inconsistencies and contradictions found in the existing studies.
The number and types of FS method used can also be a reason for the inconsistencies as deployment of FS methods varied amongst existing studies. Shivaji, et al. [
34] considered only six FS methods. Afzal and Torkar [
20] conducted their study using five FS methods. Some studies used more than 10 FS methods [
10,
26], while other studies used more than 20 FS methods [
25,
27,
28,
30]. Although the type and number of FS methods may have fewer implications; nonetheless, it is still a factor to be considered as different FS methods have varying computational characteristics.
Another instance is the search methods used as subset evaluators in FS methods. Most studies used a limited or small number of search methods. Using different search methods in FS such as FFS and WFS will lead to different predictive performance. Ghotra, et al. [
25] used only three search methods for FFS in their study. Most existing studies used one type of search method, i.e., BFS [
24,
28]. Balogun, et al. [
30] used seven different search methods for FFS in their study and reported that the Bat search method had the best impact on FFS methods. In addition, there are new and novel meta-heuristics search methods that can be used with FFS and WS, which may have better impacts on SDP predictive models.
Consequently, based on the aforementioned reviews, conducting an extensive empirical benchmark study on FS impact analysis in SDP is becoming crucial. The limitations or inconsistencies from existing studies should be addressed comprehensively to empirically validate knowledge of FS methods in SDP. In this study, a benchmark study of 46 FS methods with varying characteristics and search methods was conducted. Respective FS methods were used with two different classifiers (NB and DT). These classifiers have been widely used in existing studies and have been reported to be empirically stable with class imbalance [
24,
26,
34,
38,
39]. The resulting models were trained and tested with 25 defect datasets selected from NASA, PROMISE, ReLink, and AEEEM repositories. Each predictive model was evaluated based on accuracy and AUC.
5. Experimental Results and Discussion
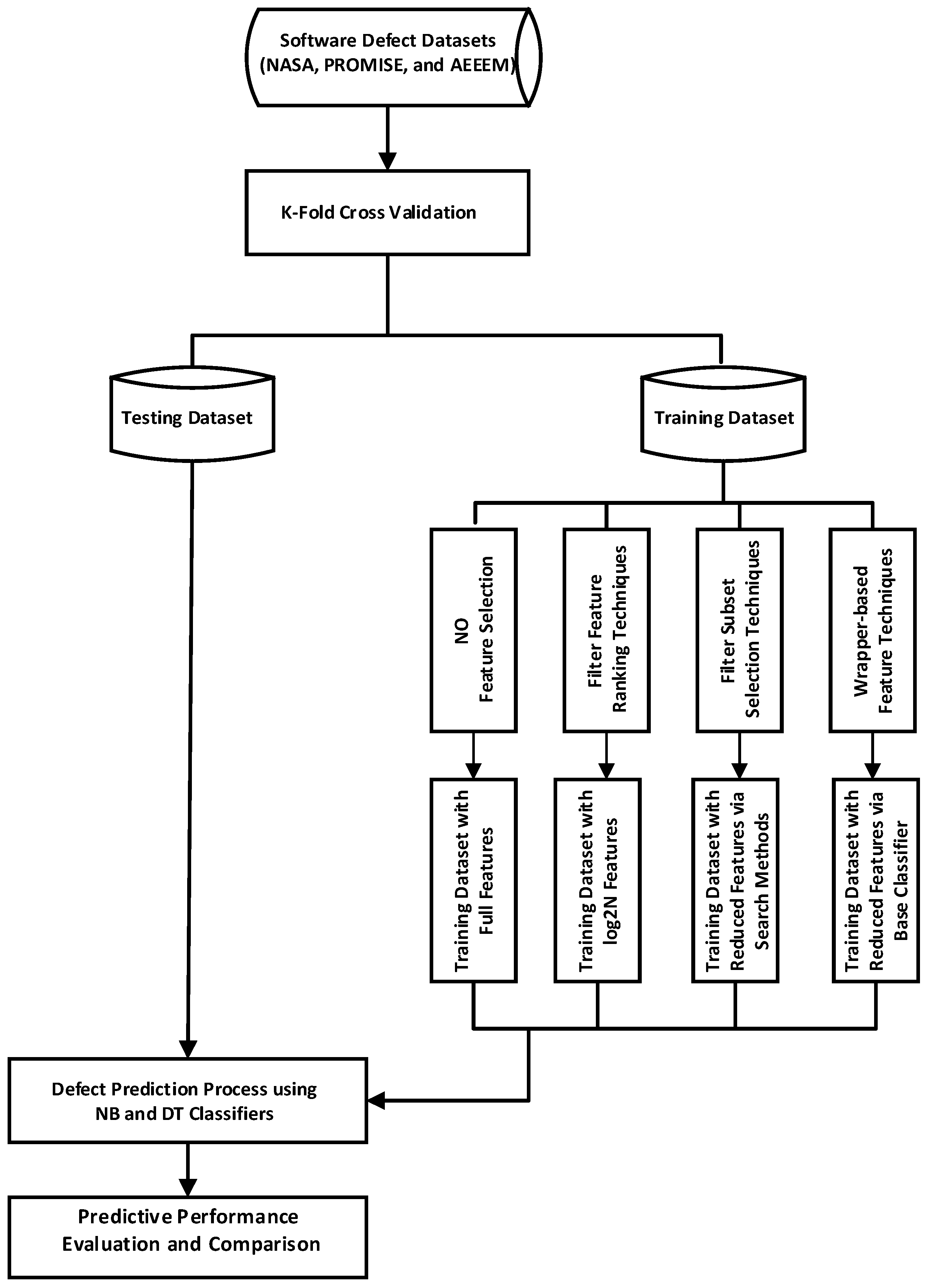
The experimental results in accordance with the experimental framework (see
Figure 1) are presented in this section. The predictive performances of each SDP model using accuracy and AUC were evaluated. Experimental results of both cases of experiments (with and without FS methods) were considered. All prediction models were built using the WEKA machine learning tool [
52]. R-language and OriginLab were used for statistical tests and graphical analyses, respectively. The experimental results analyses and discussion are structured based on formulated research questions (RQs) (see
Section 4.2).
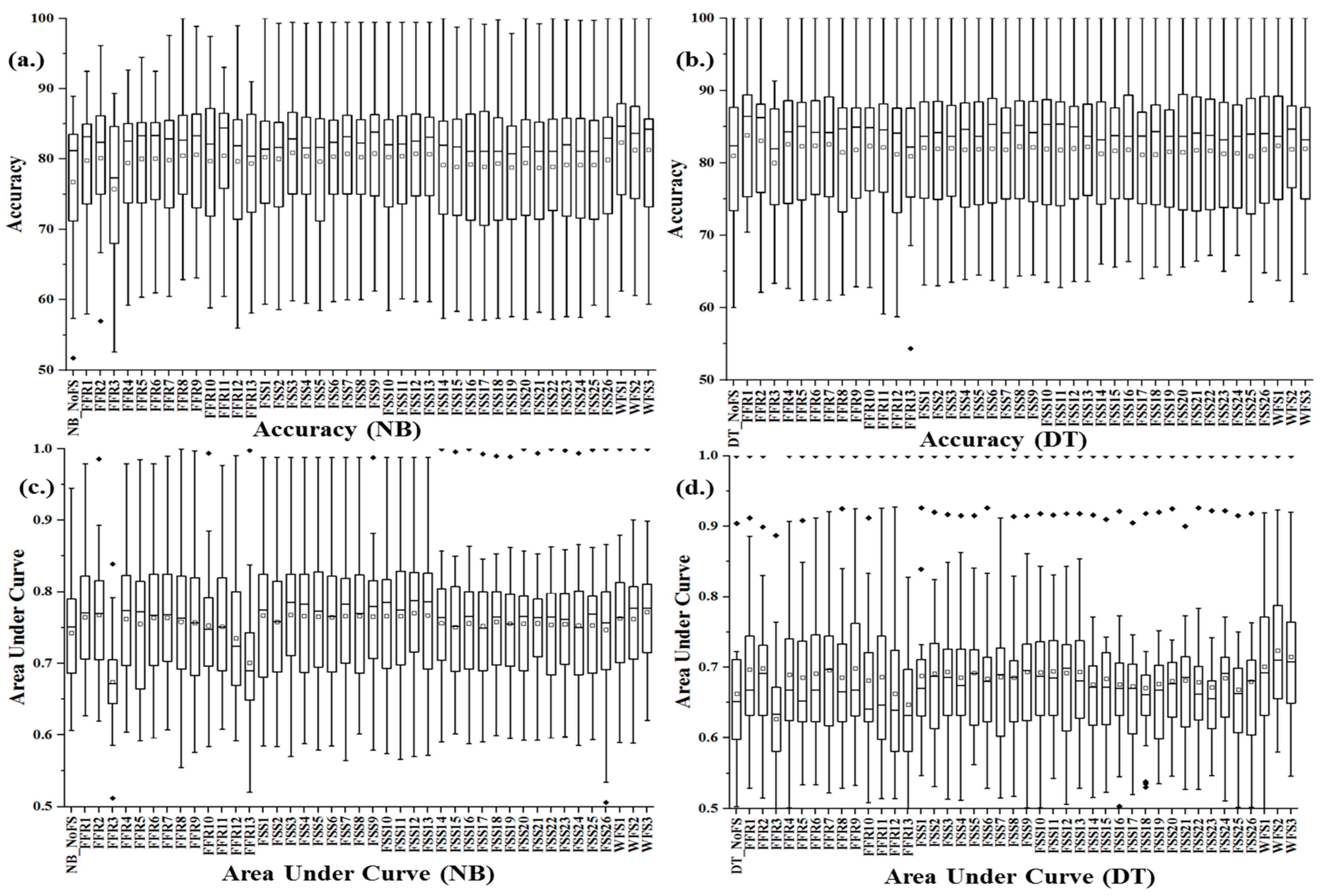
Answer to RQ1:Figure 2 and
Figure 3 shows the box-plot representation of the prediction performances (accuracy and AUC) and the Scott–Knott Rant test of FS methods on NB and DT classifiers across the studied dataset respectively. Specifically, for NB classifier, apart from FFR3 (clustering variation filter), there were significant differences (increment) in the prediction accuracy and AUC values of NB classifier models based on FS methods when compared with only NB classifier. Ninety-eight percent of NB classifier models with FS methods outperform the NB classifier model with no FS method based on average accuracy and AUC values. The prediction performances of DT classifier correspond with that of NB classifier as 90% of DT classifier models with FS methods outperform the DT classifier model with no FS method. Only 70% of the FS methods significantly increase the predictive performance of DT classifier. FFR3 (cross validation filter) and FFR13 (targeted projection pursuit filter) had the worst influence on NB and DT classifier models. Evidently, FS methods enhance positively the prediction performances of SDP models, and its level of influence partly depends on the choice of the prediction model. WFS methods had a superior effect on the studied SDP models. These findings correlate with the findings in existing studies [
2,
10,
16,
20,
25,
27,
28,
30,
31]. However, these aforementioned findings do not give the full picture of how the FS methods really enhance the prediction models as they are based on the predictive performances of SDP models on the aggregated studied dataset. That is, further analyses are required to highlight the effect of FS methods on each defect repository as the characteristics of defect repository varies in terms of features and module (see
Section 3.3).
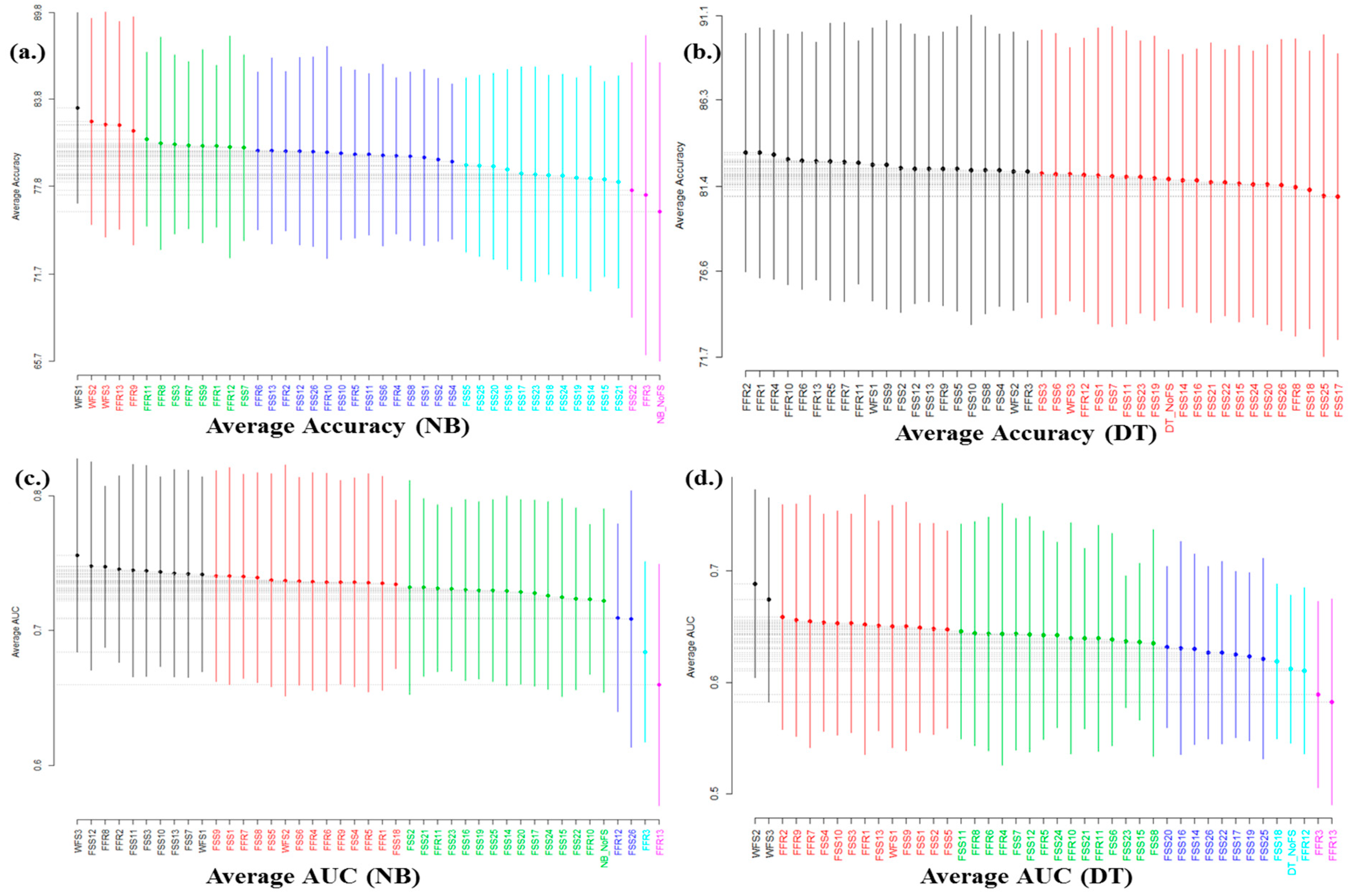
Figure 4,
Figure 5,
Figure 6 and
Figure 7 present the Scott-Knott rank test results of FS methods with NB and DT classifiers based on Accuracy and AUC for each studied dataset repositories. As aforementioned, the aim of these rank tests is to further analyze the impact of FS methods on each studied defect repository.
On AEEEM dataset, based on average accuracy, 79% and 86% of the FS methods recorded a positive impact (increment) on NB and DT classifier models respectively. Here, 70% and 92% of the FFR methods (with FFR2 ranking highest) had a significant positive effect on NB and DT classifier models. The WFS methods (WFS1, WFS2, and WFS3) also improved the accuracy of NB and DT classifiers significantly. In the case of FSS methods, only FSS12 and FSS13 had significant positive effect on NB classifier models. Most of the FSS methods especially CNS based FS methods had no significant positive effect on NB classifier models. However, on DT classifier models, 84% of the FSS methods had a significant positive impact on DT classifier models. FFR3 had the worst influence on both NB and DT classifier models. With respect to average AUC, 88% and 91% of the FS methods increased the AUC values of NB and DT classifier models. Summarily, the studied FS methods had positive effect (increment) on both NB and DT classifier models on AEEEM dataset. The WFS methods are superior in performance to other FS methods on AEEEM dataset. This is expected since WFS had the advantage of selecting features based on prediction models. Our findings, in this case, agreed with the study of Xu, et al. [
28] and Muthukumaran, et al. [
26].
Regarding the NASA dataset, 100% and 69% of the FS methods increases the accuracy of NB and DT classifier models accordingly; 100% and 84% of the FFR methods had a statistically significant positive influence on NB and DT classifier models based on accuracy. The FSS methods also had a similar influence on NB models, but only 28% of FSS methods (mostly CFS based FSS methods) were statistically significant on DT models with respect to accuracy. The WFS methods also improved the accuracy of NB and DT classifiers significantly except for WFS3 which influences DT classifier models but was not significant. On AUC values, 88% and 90% of the FS methods had a statistically significant influence on NB and DT classifier models. FFR3, FRR11, and FFR13 are the worst performer on NASA dataset. As same with AEEEM, the studied FS methods had a positive effect on both NB and DT classifier models on NASA dataset. Both FFR and WFS methods are top performer on NASA dataset.
For ReLink dataset, with respect to average accuracy, 95% and 93% of the FS methods had a positive effect on NB and DT classifier models respectively. The FFR and WFS are the top performers on this dataset. Presented in
Figure 6, 95% and 93% of the FS methods increased the AUC values of NB and DT classifier models on ReLink dataset. It was observed that the studied FS methods work well for NB classifier than DT classifier. The worst FS performer is FFR3 (cross validation filter). This may be due to its inability to handle large features as CV often works well when the number of features is limited [
53].
On the PROMISE dataset, 93% of the FS methods had a positive influence on NB and DT classifier models respectively; 95% and 775 of these FS methods were statistically significant with respect to average accuracy on the dataset corpus. This indicates that FS methods-based models work well on PROMISE dataset. Although there was no significant difference in the performance of the FS methods based on accuracy, all of the studied FS methods performed well on this dataset except for FFR3, FFR12 and FFR13. On AUC, 83% and 62% of the studied FS methods had a positive effect on the AUC values with 94% and 96% statistically significant, respectively.
From the above analyses on each dataset repository, it was deduced that FS methods clearly enhance positively the predictive performances of classifiers or prediction models in SDP on each studied dataset repository and this clearly answers RQ1. However, the performance of FS method varies across the studied repositories. In addition, this impact clearly depends on the choice of classifiers and performance evaluation metrics. From
Figure 4,
Figure 5,
Figure 6 and
Figure 7, if the accuracy is considered as the evaluation metric FFR methods are superior to other FS methods. However, if AUC is used for performance evaluation, WFS methods are superior to other methods. Although the difference in the performance of these FS methods is not statistically significant in most cases and it varies from one repository to another. Further, NB works well with FS methods as it had high accuracy and AUC values.
Answer to RQ2: From RQ1, FS methods enhance positively the predictive performance of classifiers in SDP with FSS techniques inclusive. However, RQ2 investigates if there is any significant difference in the predictive performance of FSS techniques with a change in search methods.
Figure 8 presents the Scott-Knott Tank test results of FSS techniques with different search methods (See
Table 3) on NB and DT classifiers based on accuracy and AUC values. From
Figure 8, it is clear that using other or different search methods, in this case, metaheuristics methods can give better predictive performance results than using conventional BFS. Specifically, with respect to average accuracy and AUC values, FSS3, FFS9, FSS12, FSS7, FSS11, FSS4, FSS6, and FSS1 search methods had superior predictive performance than BFS (FSS13 and FSS 26) in NB classifier models. In DT models, FSS10, FSS12, FSS3, FSS9, FSS5, and FSS2 search methods were superior to BFS. Although, there was no statistically significant difference in the predictive performances of these search methods, however, FSS based on metaheuristics were superior to BFS.
Consequently, the answer to RQ2 is positive. FSS based on metaheuristic search methods have a positive impact (increment) on NB and DT classifiers. Metaheuristics search methods such as BAT, AS, FS, FLS, WS, NSGA-II, CS, and RS were superior to BFS. Although, there is not a statistically significant difference in the predictive performance of these search methods. In addition, CFS based FSS methods significantly outperforms CNS methods with NB and DT classifiers.
Summarily, using different search methods apart from conventional BFS in FSS techniques can generate better prediction performance results. Metaheuristic methods such as BAT, AS, FS, FLS, WS, NSGA-II, CS, and RS are strongly recommended as search methods in FSS techniques to be used in SDP.
Answer to RQ3:Figure 9 presents the Scott-Knott Rank test results of FFR techniques with NB and DT classifiers on the studied datasets. Aside from FFR3, there was no statistically significant effect of FFR methods on the predictive performances (accuracy and AUC values) of NB classifier-based models on the studied datasets. That is, the predictive performances of the FFR methods are more or less the same amongst themselves. With respect to the accuracy, FFR9 was superior to other FFR methods and FFR2 had the highest positive effect on NB classifier models with respect to AUC values. As depicted in
Figure 9, there is a statistical difference in the predictive performance amongst the FFR methods. FFR3, FFR12, and FFR13 had the worst effect on the NB classifier. In the case of DT classifier, FFR1 and FFR2 were superior to other method based on accuracy. There is no statistical difference in the AUC values of the FFR methods except for FFR3, FFR12, FFR13, and FFR8, which had a poor predictive performance. In addition, to get more details on the effect of FFR methods, a double Scott-Knott Rank test was conducted to generate a statistical ranking of the FFR methods on the studied datasets. The statistical ranking is based on the ascending order of superiority.
Figure 10 presents the double Scott–Knott Rank test results, and
Table 7 summarized the statistical ranking of the FFR methods on the studied datasets.
As presented in
Table 7, the predictive performance of the FFR methods depends on the choice of the classifier. In NB classifier-based models with respect to the accuracy, FFR11 ranked first (superior), FFR9 and FFR2 ranked second, while FFR8, FFR6, and FFR5 ranked third. FFR1, FFR4, FFR7, FFR10, FFR12, and FFR 13 ranked fourth and FFR3 ranked fifth.
For DT classifier-based models with respect to the accuracy, FFR1 AND FFR2 jointly ranked first (superior), FFR4, FFR5, FFR6, FF7, FFR10, and FFR11 collectively ranked second; FFR8 and FFR9 ranked third; while FFR12 and FFR13 ranked fourth, and FFR3 ranked fifth (last).
Based on AUC values, FFR1, FFR2, FFR6 and FFR1, FFR2, FFR7, FFR9 ranked first (superior) for NB and DT classifier models respectively. FFR4 and FFR6 ranked second in NB classifier-based models, and FFR6 ranked second in DT classifier models. FFR8 and FFR 9 ranked third in NB classifier, while FFR11 ranked third in DT classifier-based models. FFR5, FFR10, FFR11, and FFR4, FFR5 ranked fourth for NB and DT classifier-based models respectively. In both NB and DT classifier-based models, FFR3 ranked last.
From the above analyses, the predictive performance of FFR methods differs based on the choice of classifier and evaluation metric. However, from the summary of the statistical ranking in
Table 7, FFR1, FFR2, FFR4, FFR6, FFR7, and FFR9 are the top performers in the FFR methods. That is, there is no one best FFR method as these top-performing FFR methods have different computational characteristics (see
Table 2). We therefore recommend the usage of statistical-based, probability-based, and classifier-based FFR methods in SDP.
Figure 11 presents the Scott-Knott Rank test results of FSS techniques with NB and DT classifiers on the studied datasets. The FSS techniques had a significant positive impact (increment) on the predictive performances of NB and DT classifier models with CFS having the highest impact. Comparing the impact of the FSS techniques, CFS was superior to CNS, however, this superiority is not statistically significant in some cases. CFS based on metaheuristic search methods were amongst the top performers. Although CFS and CNS based on BFS had good predictive performances, CFS and CNS based on metaheuristics were superior in most cases. Especially CFS based on metaheuristics (FSS1, FSS2, FSS3, FSS4, FSS6, FSS7, FSS8, FSS9, FSS10, FSS11, and FSS12), they ranked first (superior) to other FSS techniques. Clearly, using metaheuristics as search methods in FSS techniques can produce predictive models with better predictive performance. This finding shows that FSS techniques with metaheuristic search methods can lead to different research findings as most existing studies are based on BFS [
10,
25,
27,
28]. In this study, we observed that using metaheuristics as search methods in FSS techniques can produce predictive models with superior predictive performance and in some cases as good as conventional BFS.
Figure 12 presents the Double Scott-Knott Rank Test of FSS Methods and
Table 8 summarizes the statistical rank test of FSS techniques on the studied datasets. Based on average accuracy, CFS methods (FSS1, FSS2, FSS3, FSS4, FSS5, FSS6, FSS7, FSS8, FSS9, FSS10, FSS11, and FSS12) ranked first on both NB and DT classifier-based models. While on average AUC values, the CFS methods ranked first except FFS2 and FFS9. CNS methods mostly ranked low on both NB and DT classifier based models. Based on our findings, we recommend the usage of metaheuristic search methods (see
Table 3) with CFS for FSS technique in SDP.
Figure 13 presents the Scott–Knott rank test results of WFS methods with NB and DT on the studied datasets. The WFS methods had a significant positive impact (increment) on the predictive performances of NB and DT classifier models and amongst the studied FS methods; WFS had the highest impact (increment) on NB and DT classifier models. WFS1 and WFS2 which are based on IWSS search methods were superior to other search methods (SFS and LFS) in WFS. It was observed that IWSS was superior in performance to known SFS (based on greedy step-wise) and LFS (an extended version of BFS) and should be used more as search methods in WFS. However, there was no statistically significant difference in the prediction performances of IWSS, SFS, and LHS based WFS prediction models.
Figure 14 presents the double Scott–Knott rank test of FSS methods and
Table 9 summarized the statistical rank test of FSS techniques on studied datasets. IWSS-based WFS methods (WFS1 and WFS4) ranked first with both NB and DT models on both accuracy and AUC values. WFS2, WFS6 ranked second and WFS3, WFS5 ranked third based on average accuracy, while for average AUC values, WFS3 and WFS6 ranked second and WFS5 ranked third with both NB and DT-based models respectively.
In answering RQ3, we observed that there is no best FS method as the performance of FS methods varies with respect to the choice of classifiers, choice of evaluation metrics, and FS search methods. However, the following observations were made on FS methods based on their respective performances with respect to the dataset and underlining computational characteristics.
FFR methods had a positive impact on the predictive performance of prediction models (NB and DT) regardless of the dataset repository. However, there is no one best FFR method as these top-performing FFR methods have different computational characteristics. We recommend the usage of statistical-based (CS and CO), probability-based (IG, GR, SU, and PS), and classifier-based (SVM and OR) FFR methods, respectively, in SDP.
FSS methods also had a positive impact on the predictive performance of prediction models (NB and DT). CFS recorded superior performance to CNS regardless of the implemented FSS search methods and dataset repository. In addition, metaheuristics search methods had a superior effect on FSS technique than conventional BFS method. We, therefore, recommend the usage of CFS based on metaheuristic search methods (AS, BS, BAT, CS, ES, FS, FLS, NSGA-II, PSOS, and WS) in FSS methods for SDP.
WFS methods had a positive impact on the predictive performance of prediction models. WFS methods were superior in performance to FSS and FFR, but there is no statistical difference in their respective performances. IWSS-based WFS methods rank superior to SFS and LHS-based WFS methods.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}