Document Clustering Using K-Means with Term Weighting as Similarity-Based Constraints


Abstract
:1. Introduction
2. Related Works
2.1. Comparative Analysis on Four Learning/Mining Schemes
2.2. Similarity-Based Constrained Clustering
3. Constrained Document Clustering with Distribution-Based Term Weighting
3.1. Distribution-Based Term Weighting Scheme
- Term frequency (TF):
- Inverse document frequency (IDF):
- Standard deviation (SD):
- Average class standard deviation (ACSD):
- Inter-class standard deviation (ICSD):
3.2. Constrained Document Clustering with Term Weighting
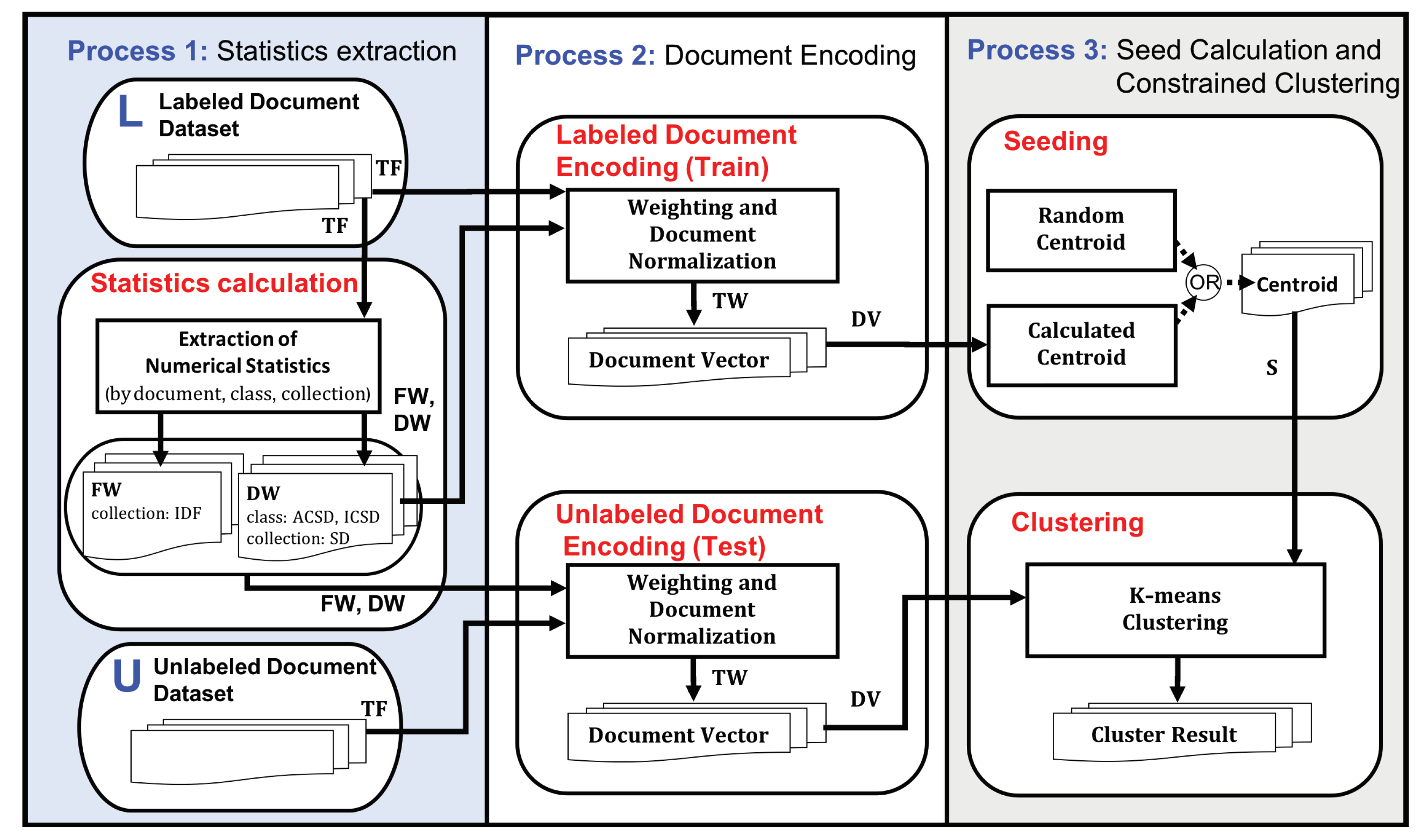
3.3. The Framework of Clustering with Term Weighting
| Algorithm 1 Pseudo-code of main procedure of the constrained k-means clustering (semi-unsupervised learning) by distribution-based term weighting |
|
| Algorithm 2 Pseudo-code of sub-functions for constrained k-means clustering |
|
4. Experiment Settings and Metrics
4.1. Data Sets and Preprocessing
4.2. Experiment Settings
4.3. Evaluation Measures
5. Experimental Results
5.1. Cluster Quality of Single Factor
5.2. Cluster Quality of Multiple Factors
5.3. Term Weighting as Expression of User Intention
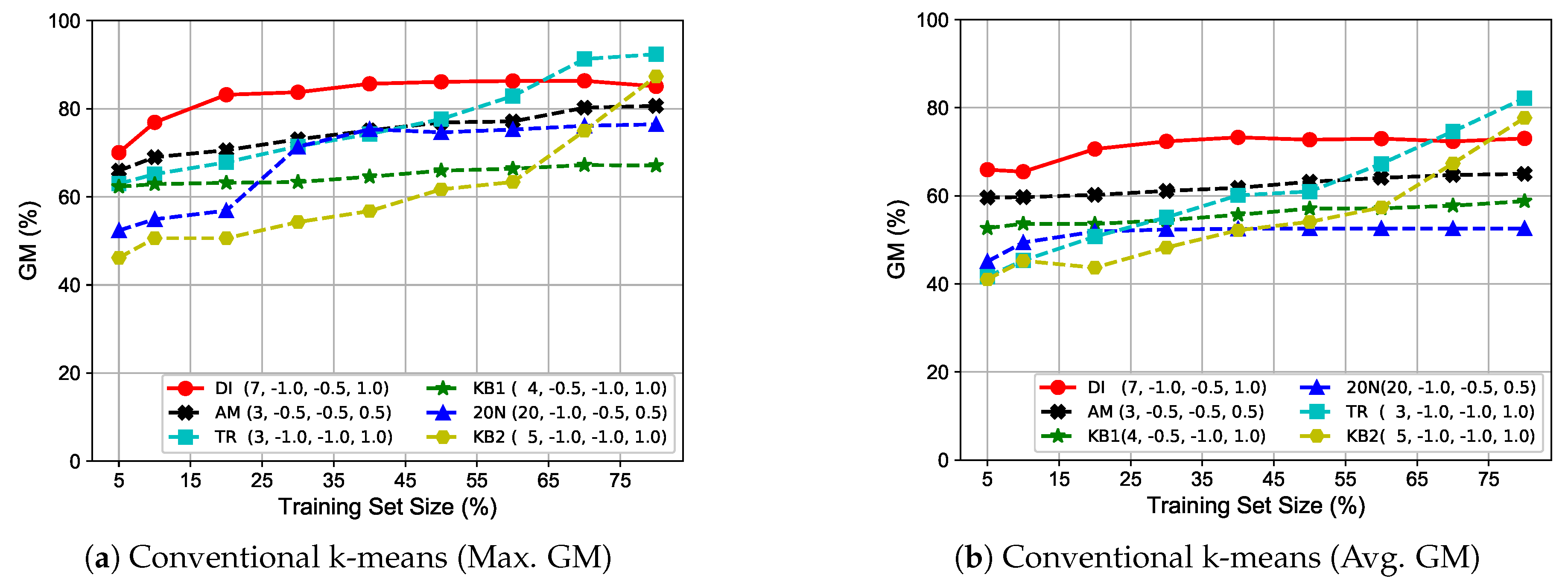
5.4. Investigation of Various Training Set Sizes
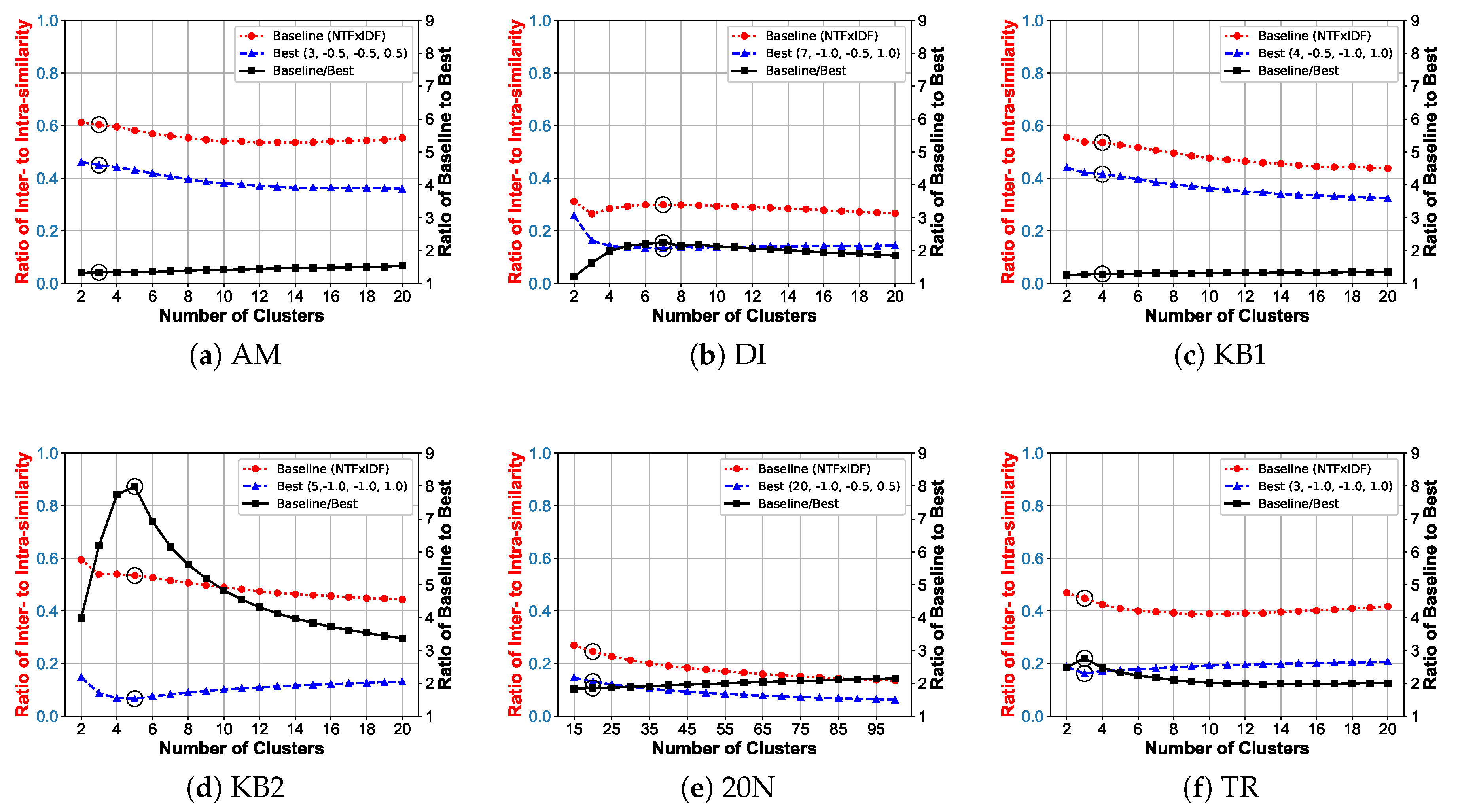
5.5. Effect of Cluster Number on Cluster Quality
6. Discussion and Related Works
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goswami, J. A Comparative Study on Clustering and Classification Algorithms. Int. J. Sci. Eng. Appl. Sci. (IJSEAS) 2015, 1, 170–178. [Google Scholar]
- Hinneburg, A.; Keim, D.A. A general approach to clustering in large databases with noise. Knowl. Inf. Syst. 2003, 5, 387–415. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, C.H.; Khoo, L.P. Kansei clustering for emotional design using a combined design structure matrix. Int. J. Ind. Ergon. 2012, 42, 416–427. [Google Scholar] [CrossRef]
- Ding, H.; Sun, C.; Zeng, J. Fuzzy Weighted Clustering Method for Numerical Attributes of Communication Big Data Based on Cloud Computing. Symmetry 2020, 12, 530. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Ma, B.; Zhang, K. On the similarity metric and the distance metric. Theor. Comput. Sci. 2009, 410, 2365–2376. [Google Scholar] [CrossRef] [Green Version]
- Willetts, M.; Roberts, S.J.; Holmes, C.C. Semi-Unsupervised Learning with Deep Generative Models: Clustering and Classifying using Ultra-Sparse Labels. arXiv 2019, arXiv:1901.08560. [Google Scholar]
- Nigam, K.; McCallum, A.K.; Thrun, S.; Mitchell, T. Text classification from labeled and unlabeled documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef] [Green Version]
- Lam, D.; Wei, M.; Wunsch, D. Clustering data of mixed categorical and numerical type with unsupervised feature learning. IEEE Access 2015, 3, 1605–1613. [Google Scholar] [CrossRef]
- Zhao, Z.; Qi, W.; Han, J.; Zhang, Y.; Bai, L.-F. Semi-supervised classification via discriminative sparse manifold regularization. Signal Process. Image Commun. 2016, 47, 207–217. [Google Scholar] [CrossRef]
- Dong, A.; Chung, F.L.; Wang, S. Semi-supervised classification method through oversampling and common hidden space. Inf. Sci. 2016, 349, 216–228. [Google Scholar] [CrossRef]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schrödl, S. Constrained K-means Clustering with Background Knowledge. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June–1 July 2001; pp. 577–584. [Google Scholar]
- Bilenko, M.; Basu, S.; Mooney, R.J. Integrating constraints and metric learning in semi-supervised clustering. In Proceedings of the Twenty-First International Conference on Machine Learning; ACM: New York, NY, USA, 2004; p. 11. [Google Scholar]
- Basu, S.; Banerjee, A.; Mooney, R. Semi-supervised clustering by seeding. In Proceedings of the 19th International Conference on Machine Learning (ICML-2002); Citeseer: Sydney, Australia, 2002. [Google Scholar]
- Basu, S.; Banerjee, A.; Mooney, R.J. Active semi-supervision for pairwise constrained clustering. In Proceedings of the 2004 SIAM international Conference on Data Mining; SIAM: Lake Buena Vista, FL, USA, 2004; pp. 333–344. [Google Scholar]
- Okabe, M.; Yamada, S. Clustering with Extended Constraints by Co-Training. In Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology-Volume 03, IEEE Computer Society, Macau, China, 4–7 December 2012; pp. 79–82. [Google Scholar]
- Xiong, S.; Azimi, J.; Fern, X.Z. Active learning of constraints for semi-supervised clustering. IEEE Trans. Knowl. Data Eng. 2014, 26, 43–54. [Google Scholar] [CrossRef]
- Xu, X.; He, P. Improving clustering with constrained communities. Neurocomputing 2016, 188, 239–252. [Google Scholar] [CrossRef]
- Davidson, I.; Wagstaff, K.L.; Basu, S. Measuring constraint-set utility for partitional clustering algorithms. In European Conference on Principles of Data Mining and Knowledge Discovery; Springer: Berlin, Germany, 2006; pp. 115–126. [Google Scholar]
- Klein, D.; Kamvar, S.D.; Manning, C.D. From Instance-Level Constraints to Space-Level Constraints: Making the Most of Prior Knowledge in Data Clustering. Technical Report, Stanford. 2002. Available online: http://ilpubs.stanford.edu:8090/528/ (accessed on 5 June 2020).
- Lertnattee, V.; Theeramunkong, T. Effect of term distributions on centroid-based text categorization. Inf. Sci. 2004, 158, 89–115. [Google Scholar] [CrossRef]
- Lertnattee, V.; Theeramunkong, T. Class normalization in centroid-based text categorization. Inf. Sci. 2006, 176, 1712–1738. [Google Scholar] [CrossRef]
- Qian, P.; Zhou, J.; Jiang, Y.; Liang, F.; Zhao, K.; Wang, S.; Su, K.H.; Muzic, R.F. Multi-view maximum entropy clustering by jointly leveraging inter-view collaborations and intra-view-weighted attributes. IEEE Access 2018, 6, 28594–28610. [Google Scholar] [CrossRef]
- Dinler, D.; Tural, M.K. A Survey of Constrained Clustering. In Unsupervised Learning Algorithms; Springer: Berlin, Germany, 2016; pp. 207–235. [Google Scholar]
- Basu, S.; Bilenko, M.; Mooney, R.J. Comparing and unifying search-based and similarity-based approaches to semi-supervised clustering. In Proceedings of the ICML-2003 Workshop on the Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining; Citeseer: Washington, DC, USA, 2003; pp. 42–49. [Google Scholar]
- Sun, Y.; Norick, B.; Han, J.; Yan, X.; Yu, P.S.; Yu, X. Pathselclus: Integrating meta-path selection with user-guided object clustering in heterogeneous information networks. ACM Trans. Knowl. Discov. Data (TKDD) 2013, 7, 11. [Google Scholar] [CrossRef]
- Basu, S.; Bilenko, M.; Mooney, R.J. A probabilistic framework for semi-supervised clustering. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2004; pp. 59–68. [Google Scholar]
- Wagstaff, K.; Cardie, C. Clustering with Instance-level Constraints. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford, CA, USA, 29 June–2 July 2000; pp. 1103–1110. [Google Scholar]
- Zhu, S.; Wang, D.; Li, T. Data clustering with size constraints. Knowl.-Based Syst. 2010, 23, 883–889. [Google Scholar] [CrossRef]
- Ganganath, N.; Cheng, C.T.; Tse, C.K. Data Clustering With Cluster Size Constraints Using a Modified K-Means Algorithm; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2014. [Google Scholar]
- Tang, W.; Yang, Y.; Zeng, L.; Zhan, Y. Optimizing MSE for Clustering with Balanced Size Constraints. Symmetry 2019, 11, 338. [Google Scholar] [CrossRef] [Green Version]
- Chai, J.; Chen, Z.; Chen, H.; Ding, X. Designing bag-level multiple-instance feature-weighting algorithms based on the large margin principle. Inf. Sci. 2016, 367, 783–808. [Google Scholar] [CrossRef]
- Buatoom, U.; Kongprawechnon, W.; Theeramunkong, T. Constrained Clustering with Feature Weighting Scheme. In Proceedings of the Fourth Asian Conference on Defence Technology (ACDT 2017); ACDT: Tokyo, Japan, 2017; p. 35. [Google Scholar]
- Buatoom, U.; Kongprawechnon, W.; Theeramunkong, T. Improving Seeded k-Means Clustering with Deviation-and Entropy-Based Term Weightings. IEICE Trans. Inf. Syst. 2020, 103, 748–758. [Google Scholar] [CrossRef]
- Bianchi, G.; Bruni, R.; Scalfati, F. Identifying e-Commerce in Enterprises by means of Text Mining and Classification algorithms. Math. Probl. Eng. 2018, 2018. [Google Scholar] [CrossRef]
- Bruni, R.; Bianchi, G. Website categorization: A formal approach and robustness analysis in the case of e-commerce detection. Expert Syst. Appl. 2020, 142, 113001. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Liu, J.; Peng, D.; Wu, C. A general multiobjective clustering approach based on multiple distance measures. IEEE Access 2018, 6, 41706–41719. [Google Scholar] [CrossRef]
- Zhang, Z.; Kwok, J.T.; Yeung, D. Parametric Distance Metric Learning with Label Information. In Proceedings of the 18th International Joint Conference on Artificial Intelligence (IJCAI), Acapulco, Mexico, 9–15 August 2003; pp. 1450–1452. [Google Scholar]
- Wang, D.; Tan, X. Robust Distance Metric Learning in the Presence of Label Noise; AAAI Publications: Palo Alto, CA, USA, 2014; pp. 1321–1327. [Google Scholar]
- Buchta, C.; Kober, M.; Feinerer, I.; Hornik, K. Spherical k-means clustering. J. Stat. Softw. 2012, 50, 1–22. [Google Scholar]
- Huang, A. Similarity measures for text document clustering. In Proceedings of the Sixth New Zealand Computer Science Research Student Conference (NZCSRSC-2008), Christchurch, New Zealand, 14–18 April 2008; pp. 49–56. [Google Scholar]
- Kim, M.; Kang, D.; Kim, H. Geometric mean based boosting algorithm with over-sampling to resolve data imbalance problem for bankruptcy prediction. Expert Syst. Appl. 2015, 42, 1074–1082. [Google Scholar] [CrossRef]
- Kang, B.; Kim, D.; Lee, S. Exploiting concept clusters for content-based information retrieval. Inf. Sci. 2005, 170, 443–462. [Google Scholar] [CrossRef]
- Lan, M.; Tan, C.L.; Su, J.; Lu, Y. Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 721–735. [Google Scholar] [CrossRef]
- Luo, Q.; Chen, E.; Xiong, H. A semantic term weighting scheme for text categorization. Expert Syst. Appl. 2011, 38, 12708–12716. [Google Scholar] [CrossRef]
- Liu, Y.; Loh, H.T.; Sun, A. Imbalanced text classification: A term weighting approach. Expert Syst. Appl. 2009, 36, 690–701. [Google Scholar] [CrossRef]
- Ren, F.; Sohrab, M.G. Class-indexing-based term weighting for automatic text classification. Inf. Sci. 2013, 236, 109–125. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme Property | SL | SSL | SUSL | USL |
|---|---|---|---|---|
| Predefined classes | ◯ | ◯ | × | × |
| Model learning | ◯ | ◯ | △ | × |
| Availability of labeled examples | ◯ | △ | △ | × |
| Availability of unlabeled examples | × | △ | ◯ | ◯ |
| Term Weighting Scheme | WebKB1 (4 Classes) | WebKB2 (5 Classes) | ||||
|---|---|---|---|---|---|---|
| SL | SSL | USL | SL | SSL | USL | |
| TF | 73.79 | 63.76 | 52.63 | 71.52 | 32.46 | 30.62 |
| (74.71, 73.18) | (64.94, 62.60) | (53.94, 51.36) | (74.92, 68.27) | (40.19, 26.21) | (39.35, 23.83) | |
| nTF | 75.12 | 48.67 | 47.24 | 76.39 | 40.08 | 28.03 |
| (74.96, 75.29) | (47.78, 49.58) | (48.14, 46.36) | (80.27, 72.70) | (46.49, 34.56) | (31.68, 24.80) | |
| TF × IDF | 79.66 | 70.55 | 55.03 | 86.43 | 61.68 | 30.25 |
| (80.10, 79.22) | (71.01, 70.10) | (58.12, 52.11) | (90.03, 82.97) | (63.95, 59.48) | (39.06, 30.25) | |
| nTF × IDF | 81.82 | 78.68 | 56.00 | 93.32 | 86.24 | 38.14 |
| (82.03, 81.60) | (78.42, 78.93) | (57.73, 54.32) | (95.34, 91.34) | (88.20, 84.32) | (43.45, 33.47) | |
| Dataset | Amazon | Drug Info. | WebKB1 | WebKB2 | 20Newsgroups | Thai-Reform |
|---|---|---|---|---|---|---|
| General Characteristics | ||||||
| Abbreviation | AM | DI | KB1 | KB2 | 20N | TR |
| Language | English | English | English | English | English | Thai |
| Genre | Product | Medicine | Education | Education | News | Politic |
| # classes | 3 | 7 | 4 | 5 | 20 | 3 |
| # doc./class | 2000 each | 640 each | 501/922/1118/1620 | 221/237/249/304/3150 | various (628-999) | 1000 each |
| Total terms | 387,493 | 1,243,566 | 572,949 | 572,949 | 1,896,335 | 131,717 |
| Distinct terms | 7614 | 7768 | 6527 | 6527 | 8286 | 3549 |
| Document Size (total terms) | ||||||
| Avg. | 64.58 | 277.58 | 137.70 | 137.70 | 100.76 | 43.91 |
| Max. | 1654 | 4063 | 17,719 | 17,719 | 5366 | 1114 |
| Min. | 1 | 2 | 4 | 4 | 1 | 2 |
| SD. | 73.26 | 323.92 | 315.70 | 315.70 | 210.35 | 53.64 |
| Document Size (distinct terms) | ||||||
| Avg. | 51.52 | 136.60 | 79.64 | 79.64 | 64.43 | 31.98 |
| Max. | 743 | 846 | 2505 | 2505 | 1288 | 357 |
| Min. | 1 | 2 | 2 | 2 | 1 | 2 |
| SD. | 49.38 | 117.16 | 74.29 | 74.29 | 75.71 | 28.79 |
| Class Size (total terms) | ||||||
| Avg. | 129,164.33 | 177,652.29 | 143,237.25 | 114,589.80 | 94,816.75 | 43,905.67 |
| Max. | 148,115 | 309,812 | 181,757 | 430,950 | 173,234 | 56,608 |
| Min. | 94,784 | 59,112 | 86,085 | 28,499 | 52,972 | 21,459 |
| SD. | 24,353.03 | 97,841.22 | 35,145.48 | 158,348.95 | 20,107.90 | 15,918.06 |
| Class Size (distinct terms) | ||||||
| Avg. | 6041.67 | 5005.71 | 5446.75 | 4072.20 | 4891.55 | 2545.67 |
| Max. | 6933 | 6029 | 6008 | 6435 | 5613 | 2835 |
| Min. | 4375 | 3520 | 4839 | 3204 | 4136 | 2001 |
| SD. | 1179.46 | 977.75 | 515.30 | 1167.89 | 482.08 | 385.39 |
| Inter/Intra size of TF by cosine similarity | ||||||
| Inter-similarity | 0.0291 | 0.0487 | 0.1252 | 0.1314 | 0.0204 | 0.2063 |
| Intra-similarity | 0.0429 | 0.1444 | 0.1659 | 0.1408 | 0.0575 | 0.2802 |
| Inter/Intra | 0.6784 | 0.3373 | 0.7547 | 0.9332 | 0.3548 | 0.7363 |
| Method | FW = TF × IDF | Avg. | FW = NTF × IDF | Avg. | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FW | ⊙ | DW | AM | DI | KB1 | KB2 | 20N | TR | AM | DI | KB1 | KB2 | 20N | TR | |||
| Panel I: Centroid-based method (Classification) | |||||||||||||||||
| FW | / | 92.13 | 92.21 | 89.69 | 90.74 | 87.56 | 94.76 | 91.18 | 92.25 | 91.96 | 89.61 | 91.20 | 87.80 | 94.92 | 91.29 | ||
| FW | × | 84.72 | 69.05 | 59.75 | 44.91 | 57.21 | 75.35 | 65.17 | 84.90 | 68.77 | 59.86 | 46.03 | 57.19 | 75.84 | 65.43 | ||
| FW | / | 92.83 | 92.06 | 89.78 | 92.00 | 86.26 | 95.20 | 91.36 | 92.96 | 91.91 | 89.06 | 92.19 | 86.48 | 95.19 | 91.30 | ||
| FW | × | 83.15 | 70.48 | 54.67 | 41.50 | 54.01 | 66.07 | 61.65 | 83.37 | 70.14 | 52.59 | 42.12 | 53.88 | 66.33 | 61.41 | ||
| FW | / | 77.44 | 69.18 | 78.17 | 79.43 | 81.94 | 79.90 | 77.68 | 78.57 | 68.79 | 77.74 | 80.42 | 82.02 | 79.84 | 77.90 | ||
| FW | × | 81.22 | 78.72 | 60.56 | 73.72 | 57.70 | 85.14 | 72.84 | 81.25 | 78.69 | 60.88 | 74.05 | 57.06 | 85.22 | 72.86 | ||
| FW | / | 94.25 | 96.55 | 89.45 | 93.25 | 91.90 | 94.24 | 93.27 | 94.23 | 95.99 | 89.11 | 94.24 | 91.86 | 93.58 | 93.17 | ||
| FW | × | 79.77 | 81.01 | 62.79 | 65.49 | 66.27 | 85.22 | 73.43 | 79.80 | 81.24 | 60.30 | 65.83 | 66.16 | 85.54 | 73.15 | ||
| FW | / | 94.60 | 97.02 | 90.59 | 93.83 | 90.08 | 94.76 | 93.48 | 94.63 | 96.53 | 90.30 | 94.48 | 90.03 | 94.01 | 93.33 | ||
| FW | × | 78.36 | 82.45 | 56.99 | 59.16 | 61.30 | 81.82 | 70.01 | 78.79 | 82.31 | 57.05 | 59.29 | 61.38 | 81.72 | 70.09 | ||
| FW | / | 84.43 | 86.41 | 83.78 | 83.18 | 88.19 | 83.48 | 84.91 | 84.48 | 86.86 | 83.27 | 83.10 | 88.17 | 83.38 | 84.88 | ||
| FW | × | 77.66 | 80.16 | 65.54 | 77.64 | 59.69 | 85.57 | 74.38 | 77.89 | 79.98 | 65.55 | 77.99 | 59.81 | 85.61 | 74.47 | ||
| FW | / | 88.71 | 91.71 | 83.12 | 88.04 | 84.56 | 92.05 | 88.03 | 92.40 | 93.04 | 90.27 | 94.12 | 88.48 | 95.37 | 92.28 | ||
| FW | × | 88.19 | 56.44 | 61.67 | 53.10 | 63.59 | 90.47 | 68.91 | 89.25 | 59.62 | 61.88 | 54.05 | 64.33 | 91.07 | 70.03 | ||
| FW | / | 88.94 | 91.55 | 82.43 | 86.69 | 84.08 | 91.38 | 87.51 | 93.31 | 93.00 | 90.86 | 93.68 | 87.18 | 95.76 | 92.3 | ||
| FW | × | 88.37 | 53.48 | 60.81 | 65.91 | 63.40 | 89.96 | 70.32 | 89.33 | 56.83 | 62.14 | 68.43 | 64.43 | 90.84 | 72.00 | ||
| FW | / | 61.93 | 46.61 | 63.27 | 59.26 | 76.50 | 58.62 | 61.03 | 69.47 | 63.98 | 79.34 | 78.40 | 83.80 | 67.74 | 73.79 | ||
| FW | × | 86.14 | 71.32 | 67.24 | 86.28 | 64.17 | 88.23 | 77.23 | 86.71 | 71.75 | 68.40 | 86.33 | 64.54 | 88.24 | 77.66 | ||
| FW | / | 94.68 | 96.77 | 89.42 | 97.83 | 91.75 | 96.46 | 94.49 | 87.57 | 93.37 | 80.12 | 97.82 | 86.42 | 94.93 | 90.04 | ||
| FW | × | 86.38 | 80.42 | 77.82 | 88.82 | 75.59 | 90.74 | 83.30 | 85.07 | 77.41 | 76.04 | 88.8 | 73.73 | 90.74 | 81.97 | ||
| FW | / | 94.95 | 97.31 | 90.21 | 98.03 | 90.45 | 97.45 | 94.73 | 86.66 | 94.47 | 80.07 | 98.02 | 85.54 | 97.45 | 90.37 | ||
| FW | × | 85.69 | 80.93 | 76.81 | 86.24 | 73.19 | 90.21 | 82.18 | 84.31 | 77.13 | 75.42 | 86.24 | 71.06 | 90.22 | 80.73 | ||
| FW | / | 83.72 | 90.17 | 84.00 | 86.52 | 89.38 | 86.51 | 86.72 | 70.04 | 61.99 | 61.23 | 86.54 | 76.88 | 86.51 | 73.87 | ||
| FW | × | 82.12 | 81.88 | 80.55 | 87.89 | 68.21 | 89.44 | 81.68 | 81.70 | 82.00 | 79.74 | 87.88 | 67.21 | 89.44 | 81.33 | ||
| Panel II: Seeded k-means method (Clustering) | |||||||||||||||||
| FW | / | 90.92 | 89.58 | 81.79 | 86.79 | 83.65 | 92.30 | 87.51 | 91.44 | 89.93 | 87.18 | 87.30 | 84.60 | 93.16 | 88.94 | ||
| FW | × | 75.31 | 43.83 | 53.74 | 31.78 | 40.05 | 46.29 | 48.50 | 72.66 | 44.15 | 53.79 | 31.41 | 41.25 | 54.04 | 49.55 | ||
| FW | / | 91.73 | 90.37 | 81.90 | 80.76 | 82.47 | 93.39 | 86.77 | 92.31 | 90.81 | 85.73 | 83.77 | 83.32 | 94.05 | 88.33 | ||
| FW | × | 73.68 | 36.57 | 46.96 | 31.39 | 33.69 | 43.31 | 44.27 | 71.31 | 43.30 | 49.62 | 31.42 | 29.27 | 50.11 | 45.84 | ||
| FW | / | 60.59 | 59.84 | 66.36 | 61.65 | 74.15 | 71.82 | 65.74 | 65.75 | 46.77 | 69.72 | 63.15 | 71.47 | 67.91 | 64.13 | ||
| FW | × | 75.60 | 65.81 | 46.28 | 66.19 | 46.26 | 79.94 | 63.35 | 75.39 | 58.75 | 45.87 | 67.98 | 45.12 | 78.05 | 61.86 | ||
| FW | / | 88.17 | 84.98 | 70.73 | 77.13 | 82.76 | 79.33 | 80.52 | 88.74 | 95.48 | 87.5 | 90.58 | 90.69 | 88.64 | 90.27 | ||
| FW | × | 70.36 | 63.76 | 51.67 | 32.43 | 47.19 | 82.10 | 57.92 | 67.35 | 62.10 | 45.13 | 42.38 | 44.97 | 78.06 | 56.67 | ||
| FW | / | 89.19 | 86.83 | 72.18 | 65.51 | 82.61 | 80.76 | 79.51 | 89.21 | 96.00 | 88.76 | 78.71 | 88.54 | 89.44 | 88.44 | ||
| FW | × | 69.29 | 60.77 | 49.95 | 31.53 | 35.41 | 58.86 | 50.97 | 64.58 | 58.17 | 46.12 | 32.47 | 30.33 | 59.67 | 48.56 | ||
| FW | / | 66.67 | 64.45 | 62.12 | 51.55 | 69.91 | 62.44 | 62.86 | 73.78 | 79.75 | 77.94 | 62.87 | 82.28 | 75.04 | 75.28 | ||
| FW | × | 74.74 | 71.26 | 51.73 | 68.33 | 47.55 | 85.71 | 66.55 | 73.90 | 70.90 | 50.14 | 69.62 | 45.32 | 85.21 | 65.85 | ||
| FW | / | 87.38 | 84.73 | 75.46 | 75.17 | 82.24 | 91.12 | 82.68 | 91.79 | 82.30 | 83.32 | 89.74 | 86.35 | 94.59 | 88.02 | ||
| FW | × | 83.94 | 32.91 | 49.40 | 34.95 | 81.66 | 76.06 | 59.82 | 76.63 | 43.42 | 53.48 | 40.57 | 48.74 | 87.20 | 58.34 | ||
| FW | / | 87.75 | 86.25 | 74.57 | 67.88 | 69.33 | 91.01 | 79.47 | 92.86 | 92.60 | 83.14 | 88.76 | 84.92 | 95.17 | 89.58 | ||
| FW | × | 86.59 | 30.20 | 48.31 | 32.68 | 76.66 | 81.06 | 59.25 | 76.95 | 38.86 | 51.61 | 42.85 | 42.61 | 85.08 | 56.33 | ||
| FW | / | 35.04 | 33.41 | 52.56 | 38.62 | 49.46 | 44.95 | 42.34 | 36.55 | 37.58 | 68.12 | 50.41 | 76.25 | 40.47 | 51.56 | ||
| FW | × | 79.05 | 67.52 | 53.56 | 85.25 | 43.65 | 86.12 | 69.19 | 77.57 | 62.16 | 48.29 | 85.50 | 51.84 | 83.64 | 68.17 | ||
| FW | / | 89.45 | 86.65 | 75.24 | 82.47 | 82.97 | 83.66 | 83.41 | 85.23 | 92.39 | 67.76 | 97.59 | 85.18 | 93.16 | 86.88 | ||
| FW | × | 75.39 | 52.92 | 69.04 | 66.62 | 60.54 | 89.70 | 69.04 | 73.20 | 60.07 | 52.36 | 81.89 | 56.87 | 89.61 | 69.00 | ||
| FW | / | 90.95 | 88.18 | 77.36 | 76.50 | 84.61 | 85.46 | 83.84 | 84.45 | 93.00 | 68.78 | 96.60 | 83.98 | 97.38 | 87.37 | ||
| FW | × | 74.80 | 49.19 | 65.39 | 49.29 | 51.33 | 88.99 | 63.17 | 70.83 | 51.91 | 57.47 | 67.54 | 46.55 | 87.41 | 63.62 | ||
| FW | / | 52.87 | 67.61 | 58.01 | 54.51 | 73.05 | 65.46 | 61.92 | 55.64 | 53.72 | 49.68 | 76.26 | 70.14 | 74.82 | 63.38 | ||
| FW | × | 77.42 | 69.29 | 65.71 | 85.86 | 54.10 | 88.56 | 73.49 | 75.80 | 76.30 | 63.60 | 85.93 | 56.22 | 88.14 | 74.33 | ||
| Method | Power of DW (p) | Total | ||||
|---|---|---|---|---|---|---|
| −1 | −0.5 | 0 | 0.5 | 1 | ||
| Panel I: Centroid-based algorithm | ||||||
| Panel A (Best): | ||||||
| SD | 5(3) | 7(5) | 5(2) | 2(0) | 1(0) | 20(10) |
| ACSD | 8(3) | 7(5) | 4(2) | 1(0) | 0(0) | 20(10) |
| ICSD | 0(0) | 0(0) | 11(6) | 7(4) | 2(0) | 20(10) |
| Panel B (Worst): | ||||||
| SD | 5(4) | 4(2) | 2(0) | 3(1) | 6(3) | 20(10) |
| ACSD | 5(3) | 3(2) | 1(1) | 2(1) | 9(3) | 20(10) |
| ICSD | 12(8) | 5(2) | 1(0) | 1(0) | 1(0) | 20(10) |
| Panel II: Seeded k-means algorithm | ||||||
| Panel A (Best): | ||||||
| SD | 6(3) | 7(4) | 5(2) | 1(1) | 1(0) | 20(10) |
| ACSD | 7(3) | 6(4) | 5(2) | 2(1) | 0(0) | 20(10) |
| ICSD | 0(0) | 0(0) | 10(7) | 7(3) | 3(0) | 20(10) |
| Panel B (Worst): | ||||||
| SD | 3(0) | 3(0) | 2(1) | 4(3) | 8(6) | 20(10) |
| ACSD | 3(0) | 2(0) | 1(1) | 4(3) | 10(6) | 20(10) |
| ICSD | 11(6) | 5(3) | 3(1) | 0(0) | 1(0) | 20(10) |
| Panel III: Conventional k-means algorithm | ||||||
| Panel A (Best): | ||||||
| SD | 6(4) | 6(4) | 5(2) | 3(0) | 0(0) | 20(10) |
| ACSD | 7(3) | 6(4) | 5(3) | 2(0) | 0(0) | 20(10) |
| ICSD | 0(0) | 0(0) | 0(0) | 10(4) | 10(6) | 20(10) |
| Panel B (Worst): | ||||||
| SD | 2(0) | 3(1) | 6(3) | 6(3) | 3(3) | 20(10) |
| ACSD | 3(0) | 2(0) | 4(3) | 5(3) | 6(4) | 20(10) |
| ICSD | 16(9) | 4(1) | 0(0) | 0(0) | 0(0) | 20(10) |
| Method | Power of DW | AM | DI | KB1 | KB2 | 20N | TR | Avg. | Panel Ranking | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SD | ACSD | ICSD | I | II | III | ||||||||
| Panel I:Centroid-based algorithm | |||||||||||||
| SC1 | −0.5 | −1 | 0.5 | 91.15 | 95.99 | 84.85 | 95.80 | 84.93 | 96.10 | 91.47 | 1 | 1 | 18 |
| SC2 | −1 | −0.5 | 0.5 | 91.46 | 95.77 | 84.43 | 94.91 | 85.51 | 95.93 | 91.34 | 2 | 2 | 21 |
| SC3 | −0.5 | −1 | 0 | 91.04 | 95.38 | 84.48 | 95.45 | 86.20 | 95.23 | 91.30 | 3 | 3 | 45 |
| SC4 | 0 | −0.5 | 0 | 91.23 | 94.54 | 84.08 | 95.58 | 86.76 | 95.19 | 91.23 | 4 | 4 | 50 |
| SC5 | −0.5 | 0 | 0 | 91.68 | 94.38 | 83.23 | 96.03 | 86.31 | 95.63 | 91.21 | 5 | 5 | 54 |
| SC6 | 0 | −1 | 0.5 | 91.93 | 94.47 | 86.35 | 93.13 | 83.24 | 93.91 | 90.51 | 6 | 11 | 12 |
| SC7 | −1 | −0.5 | 0 | 91.20 | 93.71 | 82.35 | 95.14 | 84.67 | 95.22 | 90.38 | 7 | 9 | 44 |
| SC8 | −0.5 | −0.5 | 0 | 87.18 | 94.20 | 80.32 | 98.53 | 86.47 | 95.23 | 90.32 | 8 | 7 | 72 |
| SC9 | −0.5 | −0.5 | 0.5 | 91.77 | 94.35 | 85.41 | 92.40 | 83.21 | 94.14 | 90.21 | 9 | 6 | 3 |
| SC10 | −1 | 0 | 0 | 87.57 | 93.37 | 80.12 | 97.82 | 86.42 | 94.93 | 90.04 | 10 | 10 | 71 |
| B-SC | 0 | 0 | 0 | 91.25 | 90.78 | 81.82 | 93.32 | 83.06 | 93.74 | 89.00 | 16 | 12 | 65 |
| Panel II:Seeded k-means algorithm | |||||||||||||
| SK1 | −0.5 | −1 | 0.5 | 91.87 | 95.75 | 80.52 | 95.37 | 83.65 | 96.04 | 90.53 | 1 | 1 | 18 |
| SK2 | −1 | −0.5 | 0.5 | 91.79 | 93.88 | 79.39 | 92.68 | 83.98 | 95.11 | 89.47 | 2 | 2 | 21 |
| SK3 | −0.5 | −1 | 0 | 91.33 | 92.95 | 76.93 | 95.40 | 84.95 | 94.56 | 89.35 | 3 | 3 | 45 |
| SK4 | 0 | −0.5 | 0 | 89.93 | 94.80 | 72.39 | 95.06 | 84.12 | 95.56 | 88.64 | 4 | 4 | 50 |
| SK5 | −0.5 | 0 | 0 | 90.33 | 95.71 | 72.14 | 94.49 | 83.65 | 95.40 | 88.62 | 5 | 5 | 54 |
| SK6 | −0.5 | −0.5 | 0.5 | 91.51 | 90.21 | 78.03 | 91.68 | 80.21 | 93.88 | 87.59 | 9 | 6 | 3 |
| SK7 | −0.5 | −0.5 | 0 | 90.74 | 89.76 | 79.25 | 86.21 | 84.98 | 93.03 | 87.33 | 8 | 7 | 72 |
| SK8 | 0 | −1 | 0 | 84.46 | 93.00 | 68.78 | 96.60 | 85.61 | 94.05 | 87.08 | 11 | 8 | 70 |
| SK9 | −1 | −0.5 | 0 | 90.92 | 91.30 | 76.05 | 91.76 | 78.23 | 93.86 | 87.02 | 7 | 9 | 44 |
| SK10 | −1 | 0 | 0 | 85.23 | 92.39 | 67.76 | 97.59 | 85.18 | 93.16 | 86.88 | 10 | 10 | 72 |
| B-SK | 0 | 0 | 0 | 90.17 | 89.28 | 78.68 | 86.24 | 80.12 | 93.01 | 86.25 | 16 | 12 | 65 |
| Panel III:Conventional k-means algorithm | |||||||||||||
| UK1 | −1 | −0.5 | 1 | 80.25 | 85.08 | 66.91 | 86.63 | 71.81 | 89.57 | 80.04 | 21 | 19 | 1 |
| UK2 | −0.5 | −1 | 1 | 79.74 | 82.96 | 67.09 | 86.97 | 72.70 | 89.46 | 79.82 | 19 | 17 | 2 |
| UK3 | −0.5 | −0.5 | 0.5 | 80.65 | 83.49 | 64.10 | 72.88 | 76.12 | 90.74 | 78.00 | 9 | 6 | 3 |
| UK4 | −1 | −1 | 1 | 74.94 | 78.51 | 58.68 | 87.34 | 74.38 | 92.38 | 77.71 | 12 | 20 | 4 |
| UK5 | −1 | 0 | 0.5 | 76.03 | 83.94 | 64.27 | 73.82 | 75.40 | 91.78 | 77.54 | 14 | 14 | 5 |
| UK6 | 0 | −1 | 1 | 73.05 | 79.31 | 66.41 | 86.28 | 68.42 | 88.30 | 76.96 | 30 | 27 | 6 |
| UK7 | 0 | −0.5 | 0.5 | 76.04 | 77.99 | 62.72 | 84.10 | 71.26 | 89.07 | 76.86 | 20 | 13 | 7 |
| UK8 | −1 | 0 | 1 | 77.02 | 80.97 | 64.55 | 85.97 | 63.24 | 88.62 | 76.73 | 35 | 29 | 8 |
| UK9 | −0.5 | 0 | 0.5 | 76.66 | 80.23 | 62.31 | 82.65 | 69.67 | 88.61 | 76.69 | 25 | 16 | 9 |
| UK10 | −0.5 | −0.5 | 1 | 74.70 | 79.49 | 66.30 | 85.96 | 65.16 | 88.36 | 76.66 | 32 | 21 | 10 |
| B-UK | 0 | 0 | 0 | 59.85 | 51.21 | 51.80 | 33.15 | 44.04 | 68.13 | 51.36 | 16 | 12 | 65 |
| Methods | Power of DW | User Dimension | Difference | |||
|---|---|---|---|---|---|---|
| SD | ACSD | ICSD | Dim.1 no. class = 4 | Dim.2 no. class = 5 | |Dim.1 − Dim.2| | |
| Panel I: Distribution-based term weighting from KB1 (K = 4) | ||||||
| UK-KB1-1 | −0.5 | −1 | 1 | 67.09 (70.46, 63.88) | 29.80 (34.08, 26.05) | 37.29 (36.38, 37.83) |
| UK-KB1-2 | −1 | −0.5 | 1 | 66.91 (68.11, 65.72) | 30.30 (34.15, 27.05) | 36.61 (33.96, 38.67) |
| UK-KB1-3 | 0 | −1 | 1 | 66.41 (70.35, 62.69) | 29.95 (33.63, 26.67) | 36.46 (36.72, 36.02) |
| UK-KB1-4 | −0.5 | −0.5 | 1 | 66.30 (69.00, 63.71) | 31.14 (34.90, 27.78) | 35.16 (34.10, 35.93) |
| UK-KB1-5 | −1 | 0 | 1 | 64.55 (67.68, 61.56) | 30.39 (34.15, 27.05) | 34.16 (33.53, 34.51) |
| Panel II: Distribution-based term weighting from KB2 (K = 5) | ||||||
| UK-KB2-1 | −1 | −1 | 1 | 35.29 (48.32, 25.78) | 87.34 (90.73, 84.07) | 52.05 (42.41, 58.29) |
| UK-KB2-2 | −0.5 | −1 | 1 | 31.72 (39.96, 25.18) | 86.97 (90.18, 83.87) | 55.25 (50.22, 58.69) |
| UK-KB2-3 | −1 | −0.5 | 1 | 30.10 (35.69, 25.38) | 86.63 (89.93, 83.45) | 56.53 (54.24, 58.07) |
| UK-KB2-4 | 0 | −1 | 1 | 35.72 (46.66, 27.35) | 86.28 (89.59, 83.09) | 50.56 (42.93, 61.74) |
| UK-KB2-5 | −1 | 0 | 1 | 33.55 (44.68, 25.19) | 85.97 (89.19, 82.86) | 52.42 (44.51, 57.67) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buatoom, U.; Kongprawechnon, W.; Theeramunkong, T. Document Clustering Using K-Means with Term Weighting as Similarity-Based Constraints. Symmetry 2020, 12, 967. https://doi.org/10.3390/sym12060967
Buatoom U, Kongprawechnon W, Theeramunkong T. Document Clustering Using K-Means with Term Weighting as Similarity-Based Constraints. Symmetry. 2020; 12(6):967. https://doi.org/10.3390/sym12060967
Chicago/Turabian StyleBuatoom, Uraiwan, Waree Kongprawechnon, and Thanaruk Theeramunkong. 2020. "Document Clustering Using K-Means with Term Weighting as Similarity-Based Constraints" Symmetry 12, no. 6: 967. https://doi.org/10.3390/sym12060967