1. Introduction
The diagnosis process has a remarkable impact within the medical sector, due to the wide scope and complexity of clinical knowledge domains. In general, diagnosis is a dynamic process in which clinicians have to process various types of data, e.g., signs and symptoms, vital parameters that vary over time, biomedical and clinical data, results of instrumental and laboratory tests, results of imaging devices, in order to accurately detect a specific disease. Since the amount of data and information to be processed is typically rather high, computerized systems based on Machine Learning (ML) classification techniques can be effectively exploited for improving the effectiveness of diagnosis processes and reduce misdiagnosis. With ML, the diagnostic process (basically a classification task) is represented and analysed on the basis of retrospective observed data by exploiting an inductive approach.
Generally speaking, classification is the process of predicting the category of given data points. A classifier is a function that can perform classification task.
In detail, let be a dataset with n instances denoted by , . Each instance consists of m attributes and a class label from a finite set of disjoint labels . Let be a test instance; a classifier returns the class label predicted for .
A Multi-Classifier System (MCS) is a system that uses different classifiers with the aim to obtain better results in a classification task by exploiting the single classifier competences [
1,
2].
The development of an MCS involves three phases: generation, selection and integration. In the generation phase, a pool of several classifiers, which are called base classifiers, is trained using a training set. The classifiers in the pool must be characterized by different performance, since it does not make sense to combine classifiers that provide the same accuracy in the prediction. Different strategies have been proposed in the literature to generate a diverse pool of classifiers: classifier of different types, different architectures, different features, different training sets, different parameters for each classifier [
3]. In the selection phase one or a subset of the base classifiers is selected based on an appropriate selection criterion. Dynamic Ensemble Selection (DES) techniques select more classifiers for the classification of each test instance [
4,
5] whereas Dynamic Classifier Selection (DCS) techniques select a single classifier [
2]. Finally, in the integration phase a decision is made based on the predictions of the selected classifiers.
Two approaches of classifier selections have been proposed in the literature: static and dynamic [
6]. MCS based on a static classifiers selection exploits the same classifier to classify any test instances. MCS based on dynamic selection instead, selects a specific classifier to classify each test instance, due to the assumption that each base classifier is an expert in a different local region. The local region consists of labelled instances located near to a given test instance and the most appropriate classifier in the local region is selected according to a given competence criterion. The key issues in Dynamic Selection (DS) are (1) how to define the local region and (2) how to estimate the competence of the base classifiers.
In many DS approaches, the local region is constructed using the k-Nearest Neighbour (k-NN) algorithm where
k is a static parameter [
7,
8,
9,
10] defined through computational experiments. With a static value of
k the local region has the same size for each test instance. Several versions of the k-NN algorithm have been proposed to improve the construction of these regions where
k is a static parameter for the algorithm as reported in the survey presented in [
3]. Some works proposed the use of adaptive region that changes according to the test instance. In [
11] the
k parameter of the k-NN algorithm is selected according to the output of the classifier. For a given classifier
and a given
k, if there is no instance in the local region belonging to the same class assigned to the test instance, the value of
k is increased.
However, these approaches does not take into account where the instances are located and therefore how far they are from the test instance.
Several criteria are used for estimating the competence level of the base classifiers mainly based on accuracy [
9], ranking of classifiers [
12], probabilistic information [
7], classifier’s behaviour [
8], oracle-based measures [
13], diversity measures [
14], ambiguity-based measures [
15].
In this paper, we propose a general MCS framework based on DCS in order to improve the accuracy of diagnostic process. The novelty of the proposed approach is based on: (1) the local region of each test instance is defined dynamically; (2) the most competent classifier is selected by a procedure based on performance indexes evaluated on both local region and a specific set of instances. We further extend the preliminary results appeared in [
16]. By computational experiments carried out on clinical datasets, we compared the proposed MCS framework with state-of-the-art DCS techniques, namely Overall Local Accuracy (OLA) and Local Class Accuracy (LCA) [
3,
6,
9]. A statistical analysis was performed using the Wilcoxon signed rank test.
Among the DCS techniques, OLA and LCA display the best performances [
3]. OLA evaluates the accuracy of each base classifier as the percentage of correct labelled instances in the local region. The classifier that gets the highest accuracy is considered the most competent. LCA evaluates the accuracy of each base classifier of a single class. In this case, the accuracy is defined as the percentage of correct labelled instances in the local region belonging to the class assigned by the classifier to a given test instance. Even in this case, the classifier that gets the highest accuracy is considered the most competent. In both cases the local region is defined during the testing phase by the static k-NN algorithm and only one classifier is selected to perform the classification task.
The paper is organized as follows. In
Section 2, we describe and motivate the proposed MCS framework. Experimental results and relevant discussion are detailed in
Section 3, by considering representative clinical diagnosis decision-making problems. Some conclusions are sketched in
Section 4.
2. Proposed MCS Framework
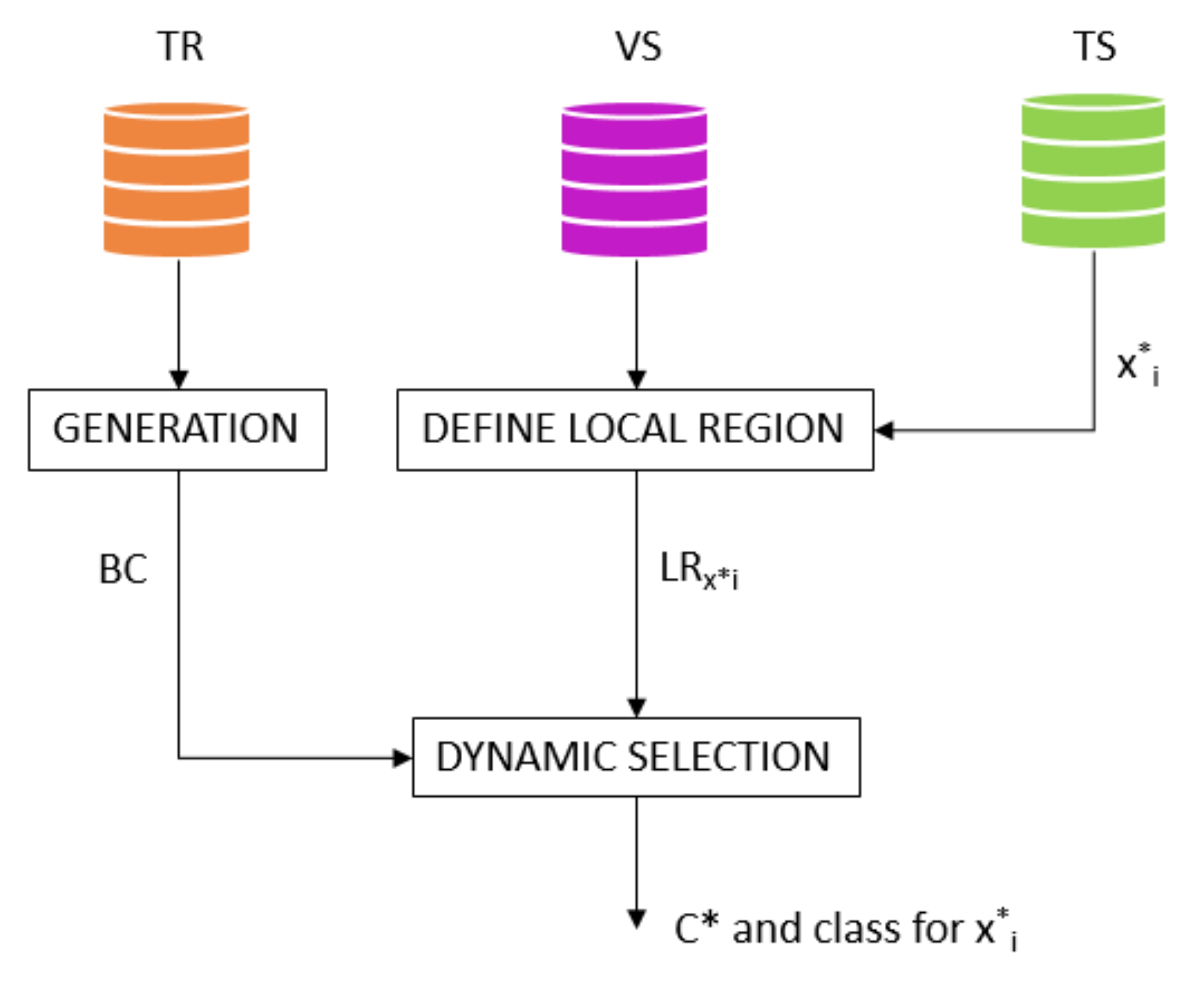
The proposed MCS framework follows the general pattern of a supervised classification process (i.e., the class label of data is known).
A dataset is split into three disjunctive sets, i.e., training set, validation set, and test set, which are denoted by TR, VS, and TS, respectively. The training set is used to train classifiers; the validation set is used to estimate classifiers’ ability to recognize new instances; finally, a test set contains instances that have to be labelled by the trained classifiers and it is used to estimate the classifier accuracy. Let , be a pool of k base classifiers, which are denoted by , . Let , be a test instance. The MCS framework consists of three main phases:
Generation The pool of base classifiers
is generated and they are thus trained on instances of
. As we show in
Section 3, a pool contains diverse classification ML algorithms in order to provide a broad coverage of problem space variability and improve thus performance
Definition of the local region The local region
of a test instance
is constructed as set of neighbours in
of
. An adaptive k-NN algorithm selects a given number of neighbours in
by considering a hypersphere centered in
and with radius
R that is defined in Equation (
1). The Euclidean norm is used for the distance between
and instances in
.
where
and
are the maximum and the minimum distance, respectively, between
and all other instances in the validation set.
The radius R of the hypersphere is set to if , from which .
Therefore the radius of the hypersphere is set as otherwise, the radius would be less than and the local region would be empty. For this reason we set when the condition is not verified, that is, when .
Depending on Equation (
1), the radius of the smallest hypersphere is
whereas that one of the biggest hypersphere is
, which occurs when
is close to zero.
The idea behind the adaptive k-NN algorithm is to consider only instances that are really close to in the original features space. If , the local region could contain only one instance. When the local region is made up of only one instance, can be found in a low-density region.
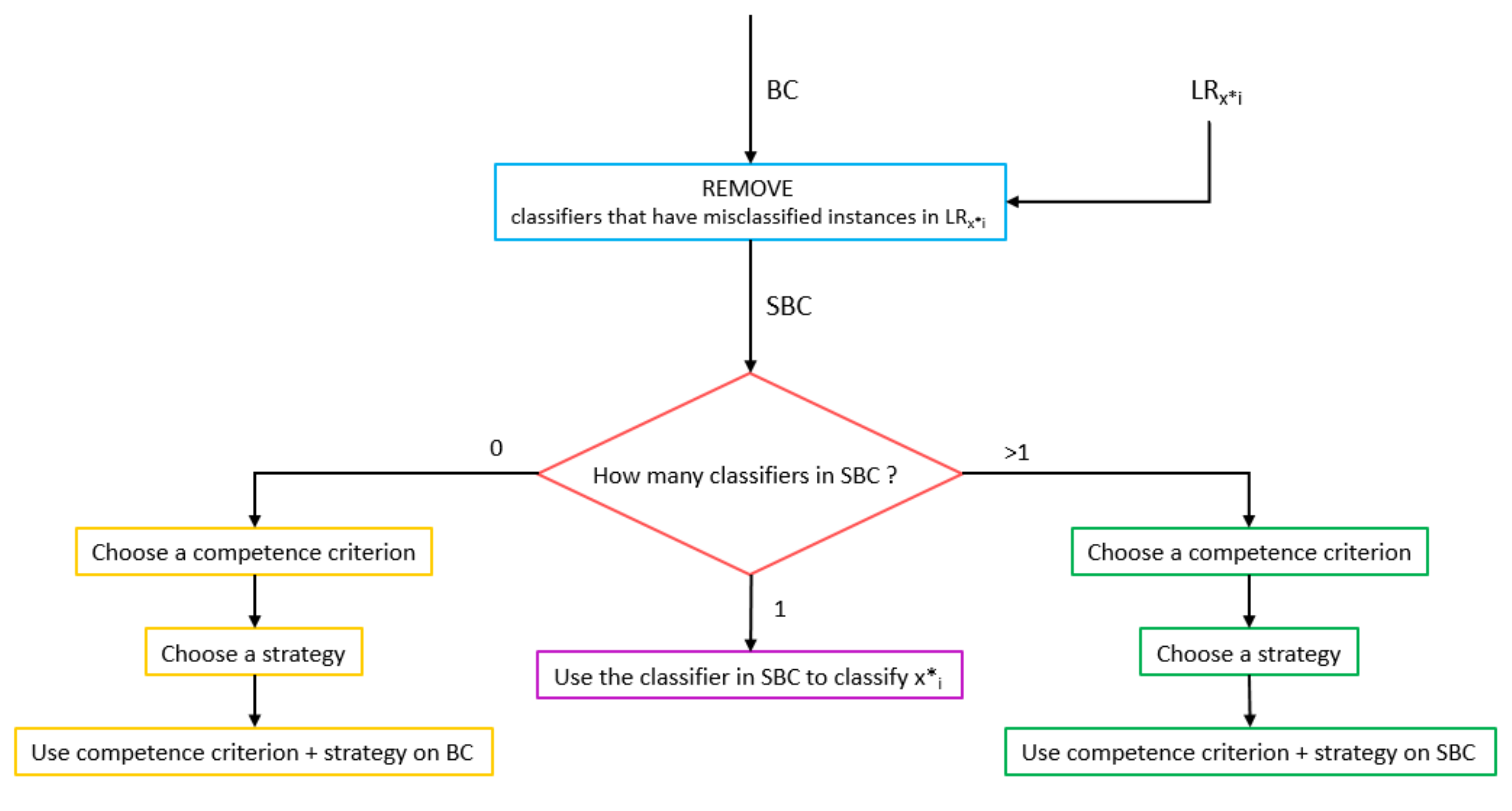
Dynamic Selection The most competent classifier for each is selected. This phase selects locally the most competent classifier for a given test instance . The overall selection process is based on performance indexes evaluated both on a local region and a specific set of instances. The selection procedure consists of two stages: Firstly, classifiers’ competence is evaluated on local region . In order to select the most competent classifier, those ones that misclassify instances in are removed. The subset of remaining classifiers is denoted by . Then, the classifiers are assessed using different data sets according to the current situation.
Figure 1 show the steps of the selection phase based on the cardinality of the set
. The three possible cases are detailed in the following.
- case 1 :
, that is, all base classifiers misclassify instances in . The most competent classifier is thus selected among the base classifiers in the original pool .
- case 2 :
, only one base classifier remains in and it is used to classify .
- case 3 :
, that is, more than one base classifier remain and the most competent classifier is selected among them.
Case 2 is the simplest because there is only one classifier. For Case 1 and Case 3, it is necessary to choose a competence criterion and a strategy to resolve the indeterminacy, as described in the following. We design two criteria based on recall and accuracy, respectively, and two strategies based on training and validation results, and only on validation results, respectively. We remind that Recall is the percentage of instances belonging to a given class and correctly classified; Accuracy is defined as the percentage of instances correctly classified.
Criterion based on recall Let , be the class of majority instances in . The recall of the classifiers is evaluated on instances of the class ; thus, classifier with the highest recall is selected
Criterion based on accuracy The classifier with the highest accuracy is selected. In this case, we do not consider a specific class
Strategy 1 (validation and training results): one of the two above defined criteria is chosen. The criterion is thus firstly applied to evaluate classifiers on the validation set. If there is indeterminacy because more classifiers have the same performance index value, the criterion is applied on the training set. More specifically, the criterion is applied on the training set only for the classifiers with the same performance. If there is indeterminacy again, the mean absolute error (MAE) on the training set is evaluated and the classifier with the minimum MAE is selected. The MAE is calculated on all training instances.
Strategy 2 (validation results): one of the two above defined criteria is chosen. The criterion is firstly applied to evaluate classifiers on the validation set. If there is indeterminacy, the MAE of each classifier is evaluated on the validation set and the classifier with the minimum MAE is selected. In this case, the MAE is computed on all VS instances
An overview of the MCS framework is depicted in
Figure 2.
3. Computational Experiments
In order to evaluate the proposed MCS framework, we designed three algorithms. Algorithm 1 is based on Strategy 1; Algorithm 2 is based on Strategy 2, and Algorithm 3 is a hybrid version of the two previous ones. Observe that Algorithm 3 is reduced to Algorithm 1 when the removal step leads to Case 1, and to Algorithm 2 when the removal step leads to Case 3.
3.1. Datasets Description
We tested the three algorithms with both selection strategies on six datasets available at the UCI Machine Learning Repository [
17]. These datasets have been widely used for academic research and are related to some important diagnostic problems.
Cleveland database is used to diagnoses the presence of heart disease. Wisconsin Diagnosis Breast Cancer (WDBC), Wisconsin Breast Cancer (WBC) and Mammographic mass datasets are used to diagnose the severity (benign or malignant) of a breast mass. Diabetic retinopathy dataset is used to predict whether a diagnostic image contains signs of diabetic retinopathy. Dermatology dataset is used for differential diagnosis of erythemato-squamous diseases: psoriasis, seboreic dermatitis, lichen planus, pityriasis rosea, cronic dermatitis, and pityriasis rubra pilaris.
Table 1 summarizes the main characteristics of these datasets in terms of number of instances, number of attributes and number of classes.
3.2. Pool of Base Classifiers
Among the several machine learning algorithms, we choose Support Vector Machines (SVM) [
18], Multi-Layer Perceptron (MLP) [
19], Naive Bayes (NB) [
20], Decision Tree (DT) [
21], and k-NN [
22], as they are widely used in different classification problems. For each classifier, we used the related algorithm implemented in Weka [
23]. For this reason, in the next tables we refer to SVM as SMO (Sequential Minimal Optimization), and to k-NN as Ib
k (Instance-based method with parameter
k).
For SVM, we used polynomial kernel and Gaussian kernel. The MLP contains one input layer, one hidden layer, and one output layer; the number of neurons in each layer is specified by I, H and O, respectively. All of the nodes use a standard sigmoid activation function. The MLP was trained using error back-propagation algorithm, with a learning rate L, a momentum M, a training time (epochs) of 500, and a back size of 100. Moreover, for DT we used the J48 classifier that implements the C4.5 algorithm. The tuning of specific classifier parameters was carried out on each dataset in order to find the best parameter values. These used best values are in
Table 2.
As the performance of the proposed framework depends on the base classifiers in the pool, we have combined and then tested pools with two, three and four base classifiers. The overall number of pools is 25. The proposed MCS framework was implemented in Java.
3.3. Performance Evaluation
The results that we details in the following tables were found by employing the stratified ten-fold cross validation (10-fold CV) method. A dataset is randomly partitioned into ten subsets and then one subset is selected for validation and testing and the remaining nine subsets for training. The whole process is repeated ten times to avoid the possible bias during dataset partitioning for cross-validation. The final results in terms of mean classification accuracy were computed by averaging the ten results. The classification accuracy is computed as reported in Equation (
2), where
is the number of instances correctly classified by a given approach and
N is the total number of instances.
Each dataset was then divided by a stratified 10-fold CV (1-fold for testing and validation, 9-fold for training) followed by a stratified 2-fold CV (the test fold was divided into 1 fold for validation and 1 fold for test). All data were normalized and no attribute selection was performed.
The proposed MCS approaches are compared with OLA and LCA techniques. For a fair comparison, we used local regions as defined in
Section 2 even for these two techniques.
3.4. Results and Discussion
The aim of the carried out computational experiments is to evaluate the proposed MCS framework and assess whether the proposed approaches improve the classification task compared to other techniques in the literature. To this end, we have considered the three algorithms above introduced, namely, Algorithm 1, Algorithm 2 and Algorithm 3. We discuss then the gain in terms of accuracy of these approaches.
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 list the average accuracy evaluated by a 10-fold CV on the six datasets for every algorithm. There are thus 25 × 9 accuracy values in each table. The relevant implementation for each algorithm is even specified, that is, if the selection criterion is based on recall (CR) or accuracy (CA). The tables also show the accuracy of OLA and LCA techniques. The best results for every pool of base classifiers are in bold in each row and standard deviation is shown in parenthesis. The algorithms that exceed OLA and LCA appears with a “*” marker.
We can observe that the performance of a pool is problem dependent and that our approaches outperform OLA and LCA techniques in most cases. On Cleveland dataset, for instance, the accuracy of our approaches is better than that one found with OLA and LCA in 15 pools, and that Algorithm 1 and Algorithm 3 achieve the best performance with a mean accuracy of 85.15 %. On WDBC they exceed the OLA and LCA techniques in the majority of pools (21 pools out of 25). On the Dermatology dataset, the highest classification accuracy is 99.18 % that is achieved by several pools and the classification accuracy of both OLA and LCA techniques in 15 pools and with Algorithm 2 and Algorithm 3. These two approaches have the same performance on this dataset. We investigated this aspect and we found that the removal step produced Case 3 always (see
Section 2).
Table 3 reports the best accuracy value per each dataset and specifies the corresponding pool by which this value was found.
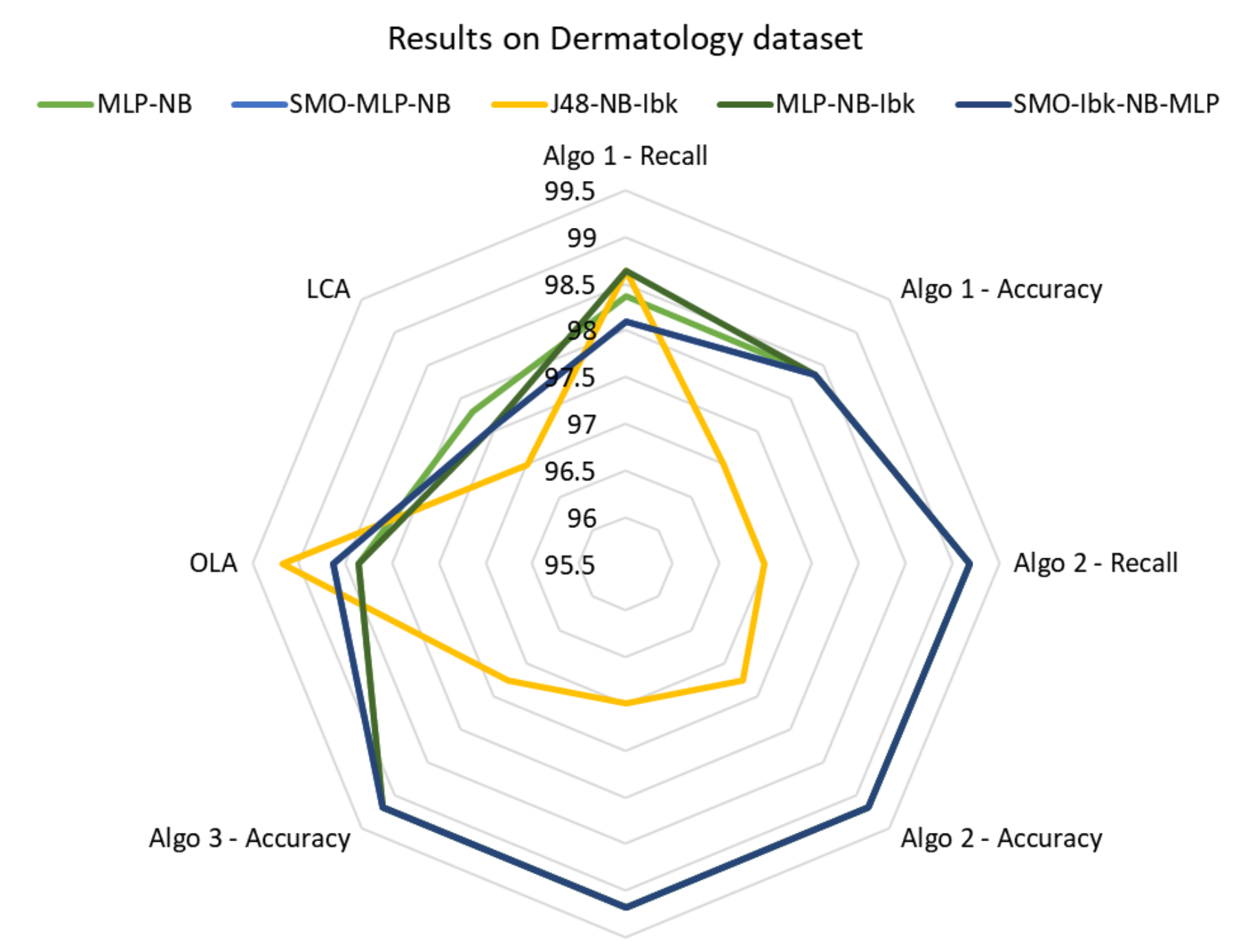
For WDBC and Dermatology dataset there is a set of pools that found the same best value, i.e., six pools on WDBC dataset, and five pools on Dermatology dataset. The accuracy values found by the five pools on Dermatology dataset with all algorithms are compared in
Figure 3.
In order to compare the algorithm among them, we compute the average mean accuracy on the six datasets for every algorithm and evaluated on all pools, as shown in
Table 4. The best results for each dataset are highlighted in bold. Based on these results, we can see that the proposed algorithms achieved the best average accuracy on all datasets.
The computational experiments show that the proposed approaches are more inclined to select the best classifier in the pool compared to OLA and LCA techniques when the same technique is used to generate the local region. Under this respect, we remark that considering the same local region, the proposed approaches outperform the OLA and LCA techniques in many cases in all datasets.
3.5. Statistical Analysis
To compare performances of the pools we perform a statistical comparison [
24]. More specifically, we compare the pools accuracies using the Wilcoxon signed-ranks test [
25] with
. We are trying to reject the null-hypothesis that both pools of base classifiers perform equally well. To simplify the interpretation of the results, we refer to a given pool by its position as they are listed in the first column of the tables of results, in the
Appendix section. Moreover, we choose to analyse the performance of the pool with high accuracy and lower number of base classifiers. This statistical analysis has been carried out per each dataset and it is detailed and summarised in
Table 5, where we report per each dataset the chosen pool of base classifier, the
p-value range that attests a significant difference with all other pools except to those listed in the last column of the table. Analysing, for instance, the accuracy values related to the Cleveland dataset, we found that the pool IbK-SMO, which has the best accuracy value if we do not consider SMO-Ibk-NB with OLA technique (i.e., pool 11), is significantly better than all other pools of base classifiers except to the pools
because there are no significant differences. The found
p-value range of the pools with significant difference is 0.007–0.042. A similar significance have the other data reported in
Table 5.
For a better comparison of the proposed algorithms with OLA and LCA techniques, we conducted a pairwise test using the Wilcoxon Sign Test with a significance level of with . We compare the classification accuracies of the pools for every method per each dataset. The results of the performed Wilcoxon Sign test can be summarised as follows:
Algorithms vs. LCA
All the proposed algorithms significantly exceed LCA on Dermatology, Diabetic retinopathy and WDBC datasets with a p-value between 0.0002 and 0.01935.
Algorithm 2 (CR and CA versions) significantly outperforms LCA on WBC dataset with a p-value of 0.01168 and 0.00196, respectively
Algorithms vs. OLA
The proposed algorithms are statistically equivalent to OLA on Cleveland, WBC and Dermatology datasets
Algorithm 1-CA and Algorithm 3-CA instead, significantly exceed OLA on Diabetic retinopathy dataset with a p-value of 0.04218 and 0.00120 respectively. Algorithm 2-CR instead, outperforms significantly OLA on Mammographic mass dataset with a p-value of 0.00112
All proposed algorithms significantly outperform OLA on WDBC dataset



{kind=link}
{kind=link}
{kind=link}


