Fuzzy Weighted Clustering Method for Numerical Attributes of Communication Big Data Based on Cloud Computing

Abstract
:1. Introduction
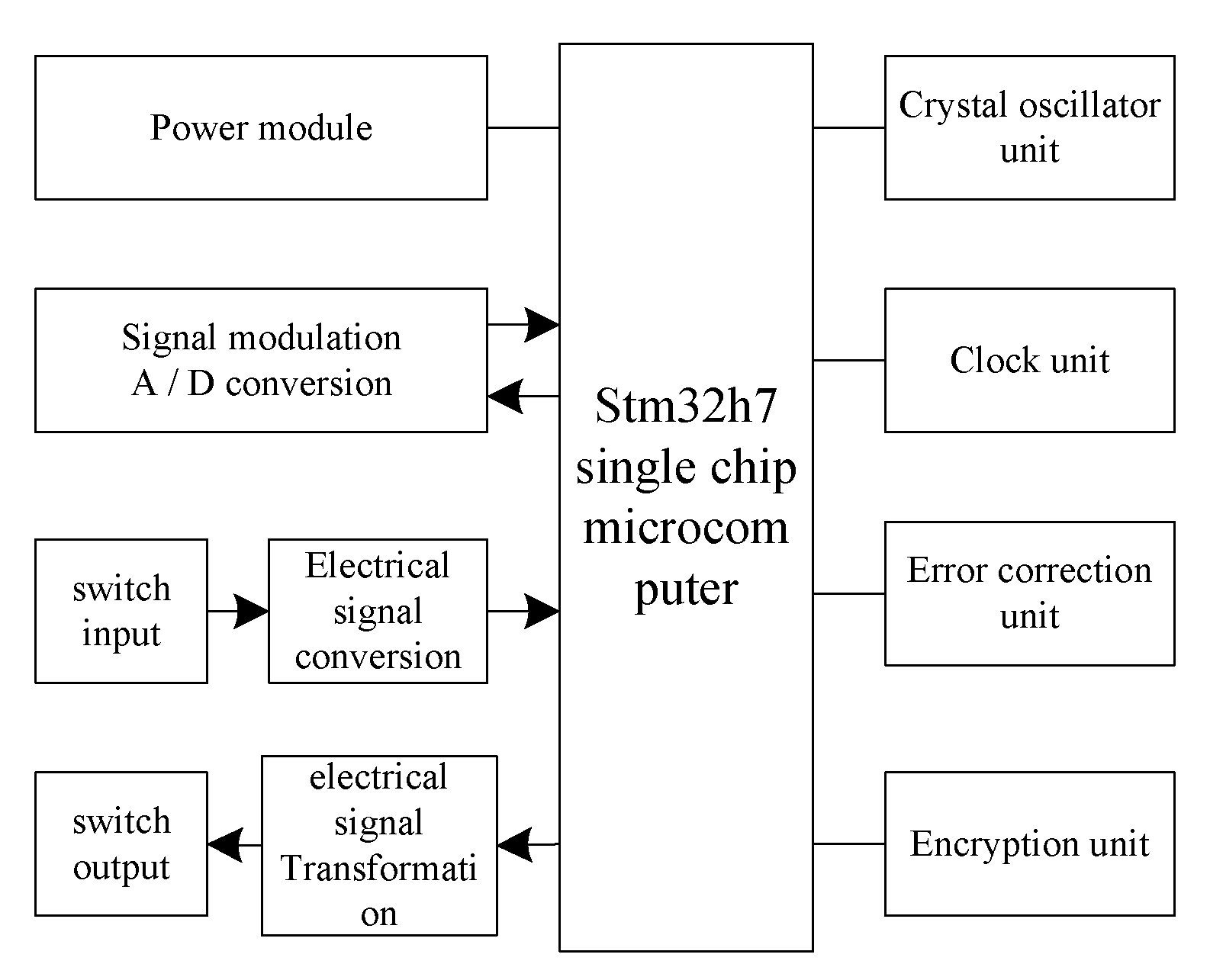
2. Numerical Attribute Sampling and Feature Parameter Extraction of Communication Big Data
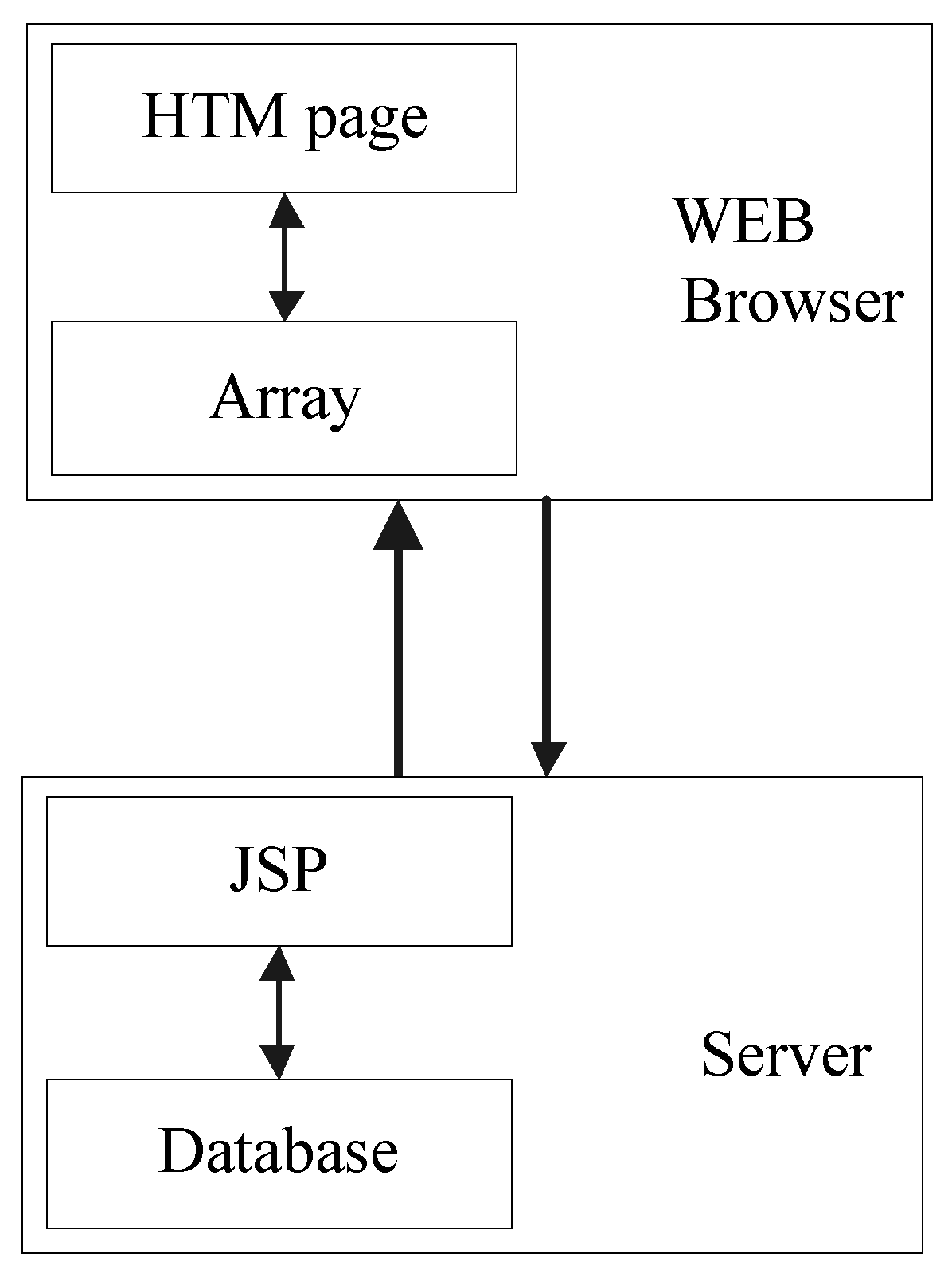
2.1. Communication Big Data Numerical Attribute Multi-Dimensional Text Feature Data Sampling
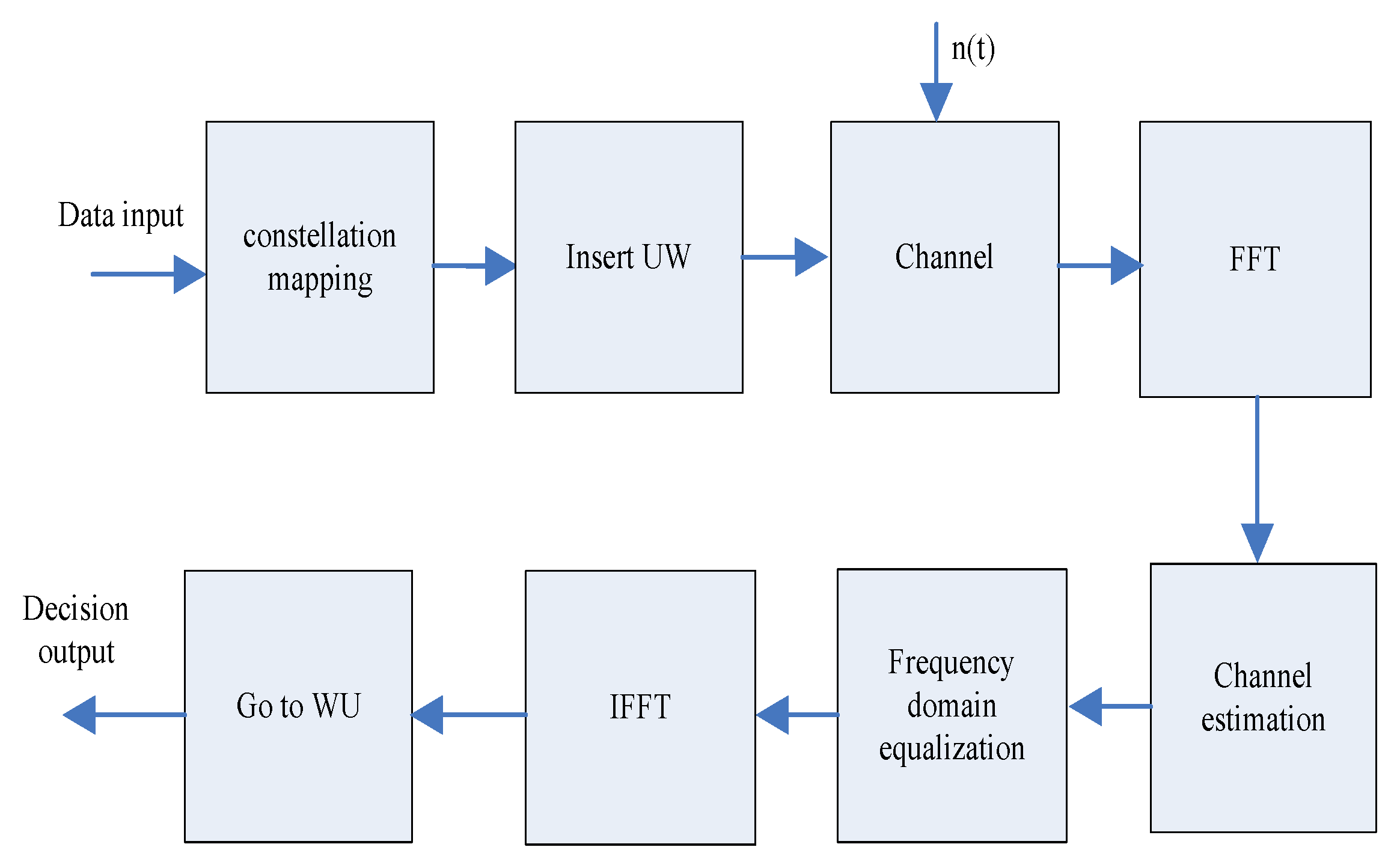
2.2. Communication Big Data Numerical Attribute Linear Programming Processing
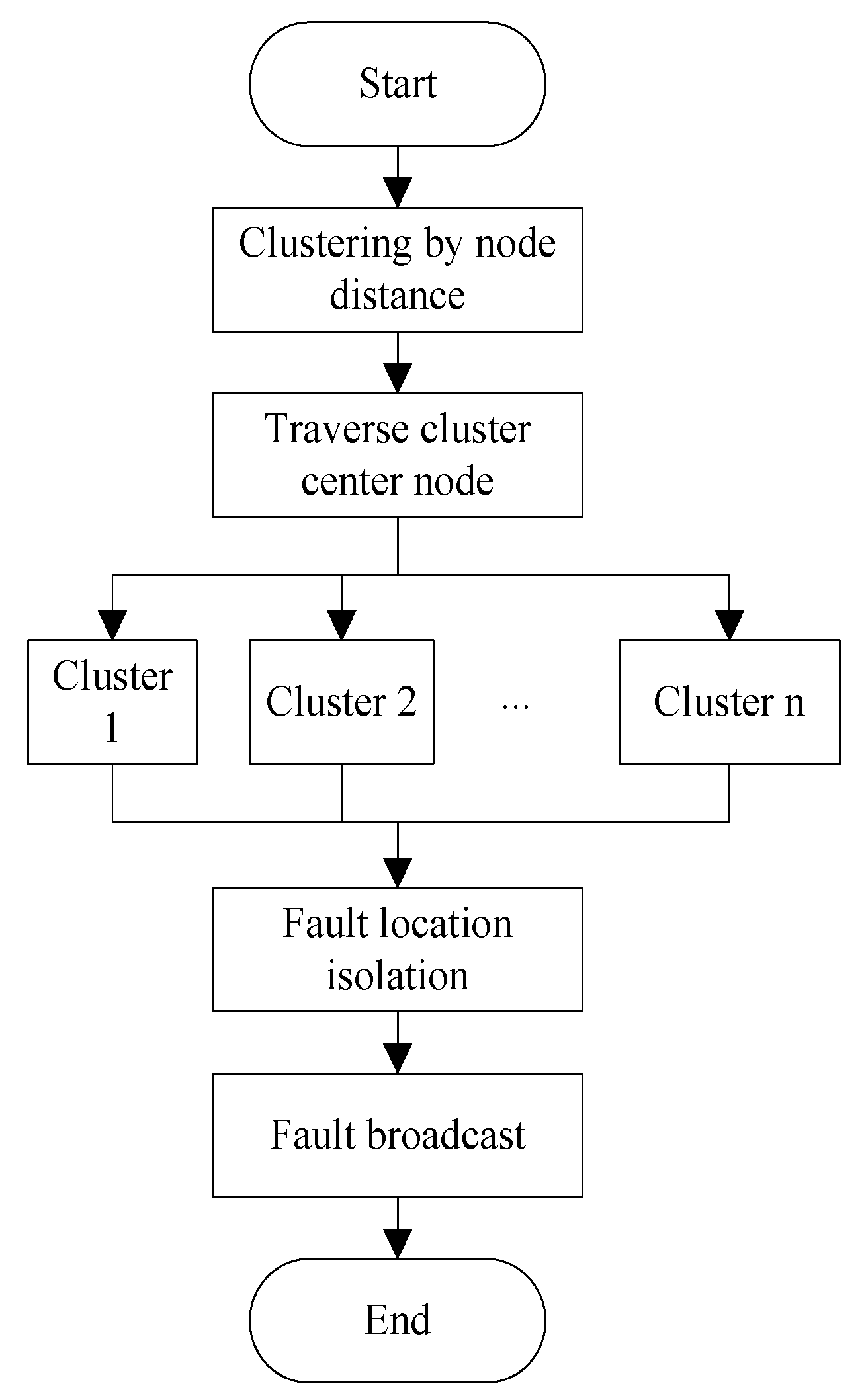
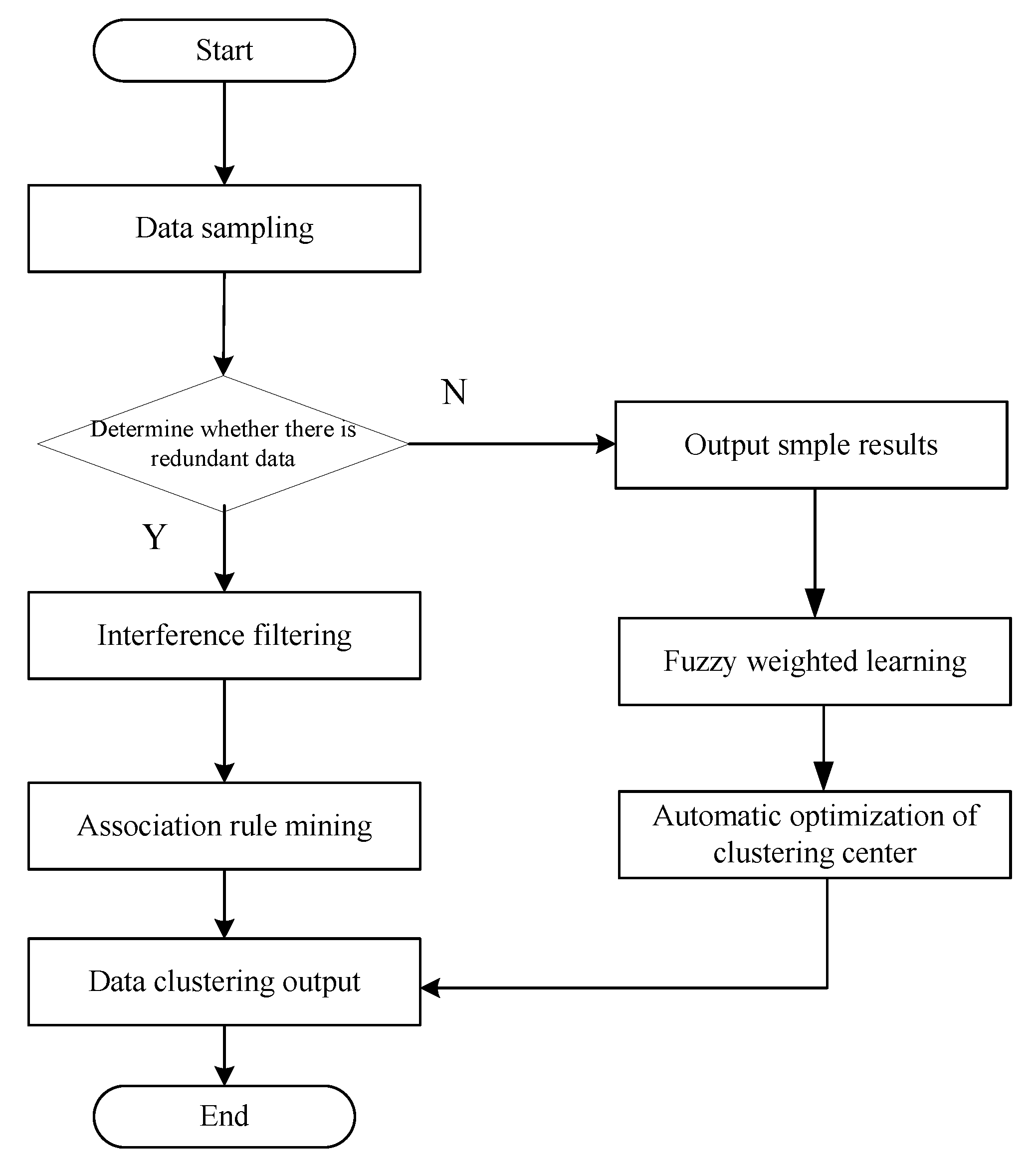
3. Big Data Fuzzy Weighted Clustering Optimization
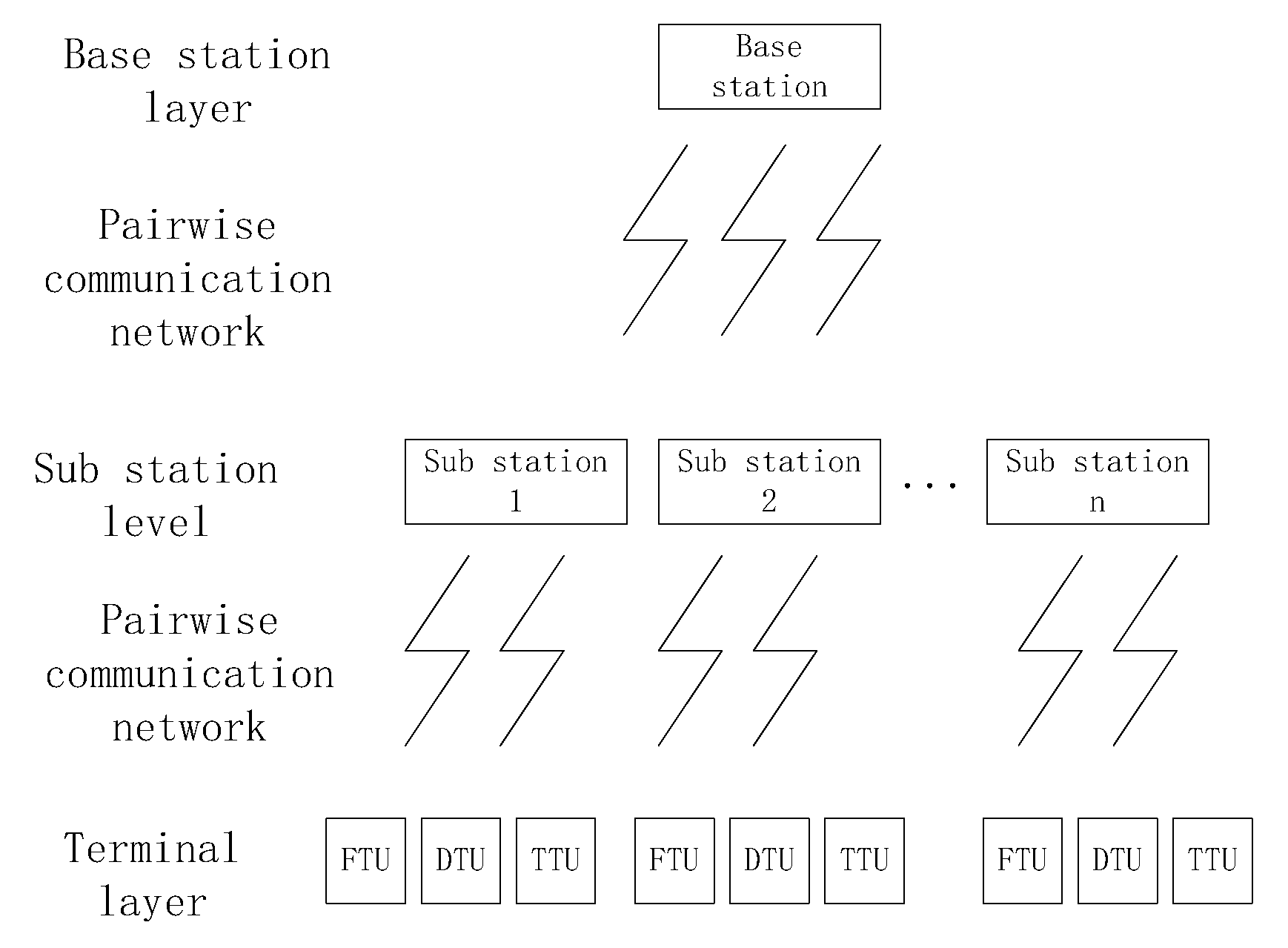
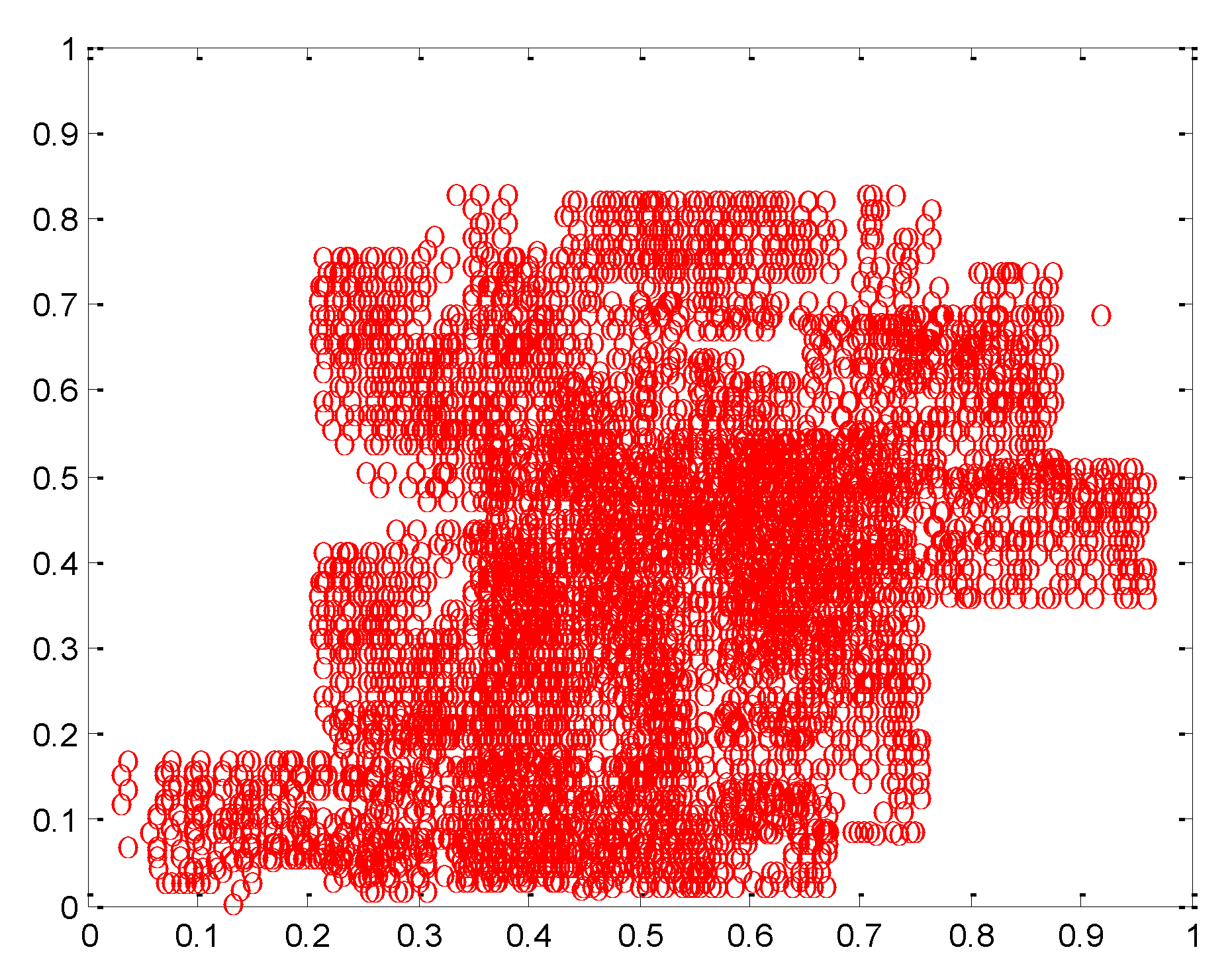
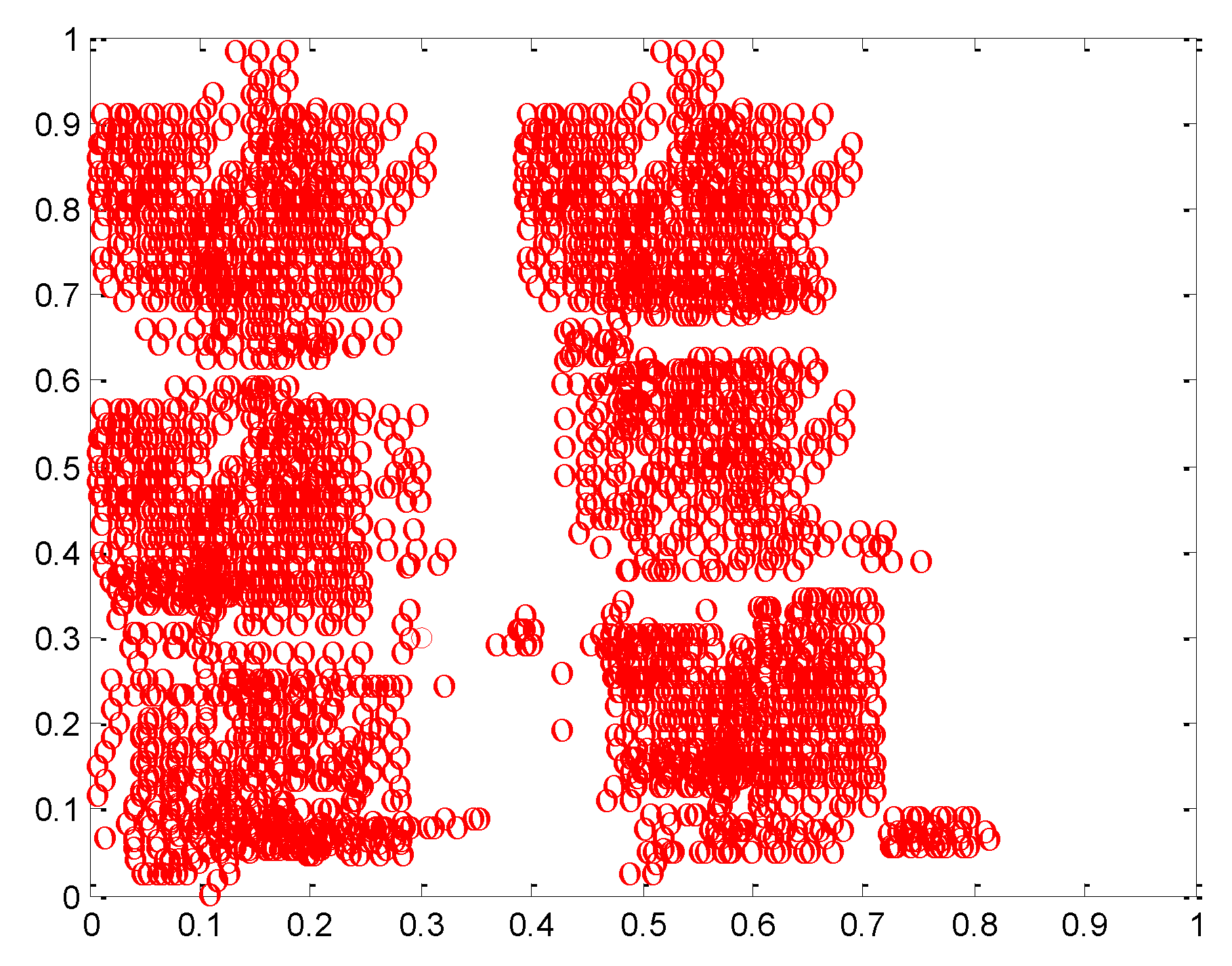
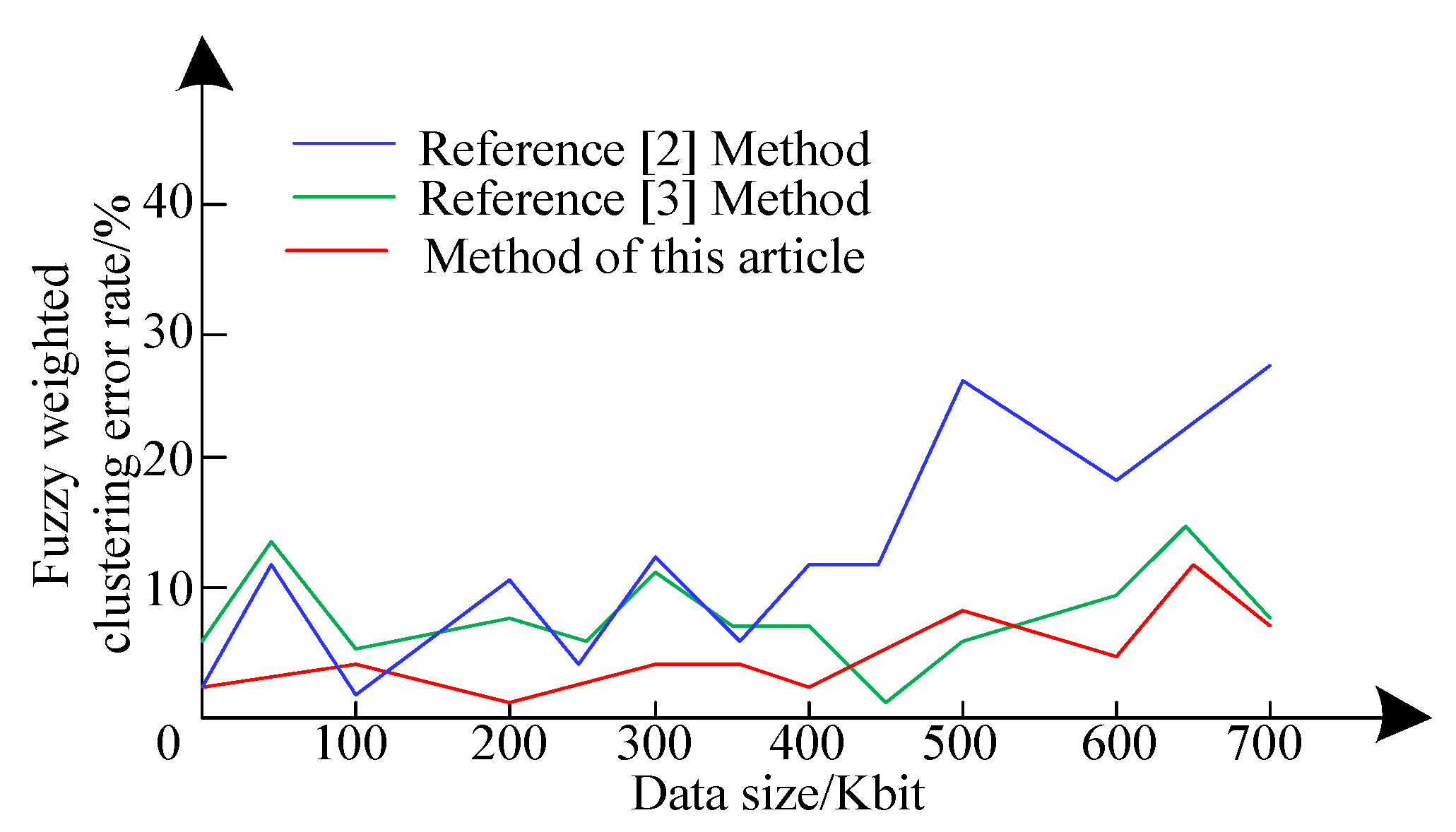
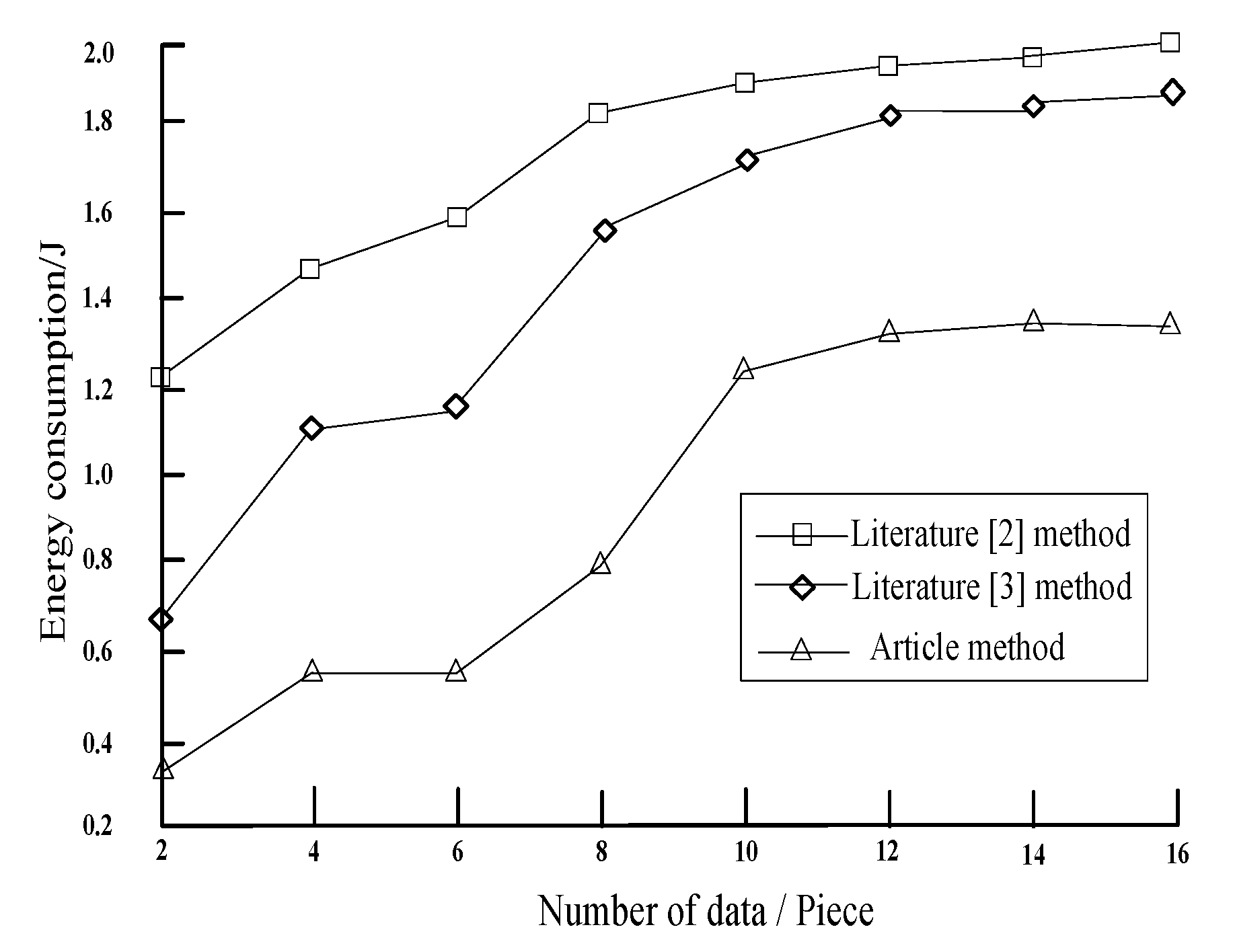
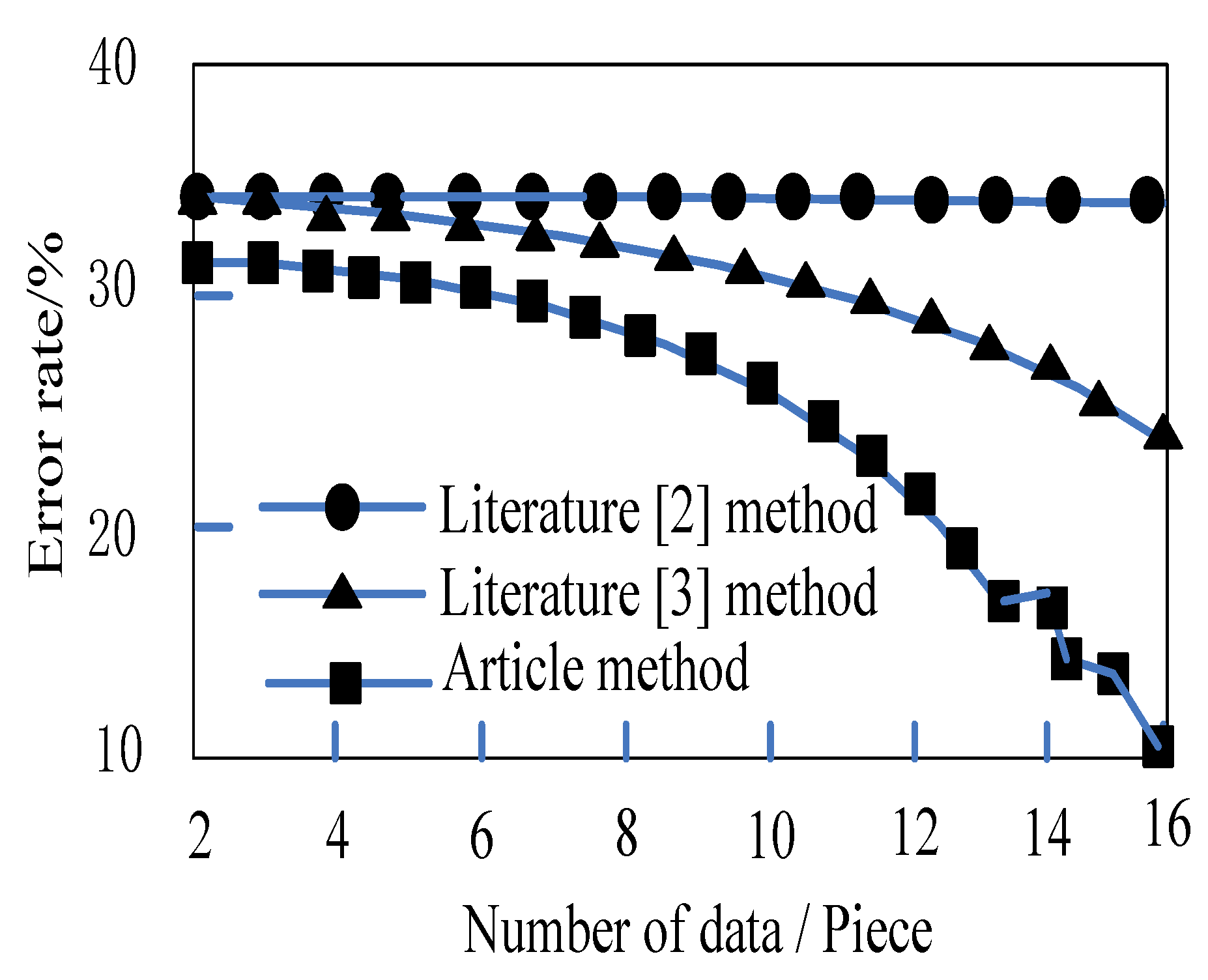
4. Simulation Experiment Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gao, H.B.; Li, H.; Qian, C.J. Parallel monte carlo simulation of single polymer chain. Appl. Mech. Mater. 2013, 263–266, 3317–3320. [Google Scholar] [CrossRef]
- Huang, Z.H.; Wang, Y.L.; Li, G.F.; Zhang, S. Adaptive frequency-domain equalization for few-mode fiber transmission systems. Laser Technol. 2017, 41, 124–128. [Google Scholar]
- Huang, C.B.; Hu, G.J. Demultiplexing Technology for mode division multiplexing system based on unconstrained frequency-domain equalization. Chin. J. Lasers. 2017, 44, 246–253. [Google Scholar]
- Cristani, M.; Raghavendra, R.; Bue, D.A. Human behavior analysis in video surveillance: A Social Signal Processing perspective. Neurocomputing 2013, 100, 86–97. [Google Scholar] [CrossRef] [Green Version]
- Lakshmi, D.C.; Revathí, R. Video surveillance systems-a survey. Int. J. Comput. Sci. Issues. 2011, 8, 635–642. [Google Scholar]
- Tsai, J.Z.; Peng, S.J.; Chen, Y.W.; Wang, K.W.; Wu, H.K.; Lin, Y.Y.; Lee, Y.Y.; Chen, C.J.; Lin, H.J.; Smith, E.E.; et al. Automatic detection and quantification of acute cerebral infarct by fuzzy clustering and histographic characterization on diffusion weighted mrimaging and apparent diffusion coefficient map. Biomed Res. Int. 2017, 2014, 96–102. [Google Scholar]
- Mahmoud, E.E. Complex complete synchronization of two nonidentical hyperchaotic complex nonlinear systems. Math. Methods Appl. Sci. 2014, 37, 321–328. [Google Scholar] [CrossRef]
- Palomares, I.; Martinez, L.; Herrera, F. A consensus model to detect and manage non-cooperative behaviors in large scale group decision making. IEEE Trans Fuzzy Syst. 2014, 22, 516–530. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Liu, D.A. Comprehensive review of stability analysis of continuous-time recurrent neural networks. IEEE Trans Neural Netw. Learn. Syst. 2014, 25, 229–1262. [Google Scholar] [CrossRef]
- Eldemerdash, Y.A.; Dobre, O.A.; Liao, B.J. Blind identification of SM and Alamouti STBC-OFDM signals. IEEE Trans. Wirel. Commun. 2015, 14, 972–982. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.C. Throughput analysis of multi-hop network and design of real-time estimation on neighbor nodes. J. Comput. Appl. 2017, 37, 2484–2490. [Google Scholar]
- Leonardo, E.J.; Yacoub, M.D. Exact formulations for the throughput of IEEE 802.11 DCF in Hoyt, Rice, and Nakagami-m fading channels. IEEE Trans. Wirel. Commun. 2013, 12, 2261–2271. [Google Scholar] [CrossRef]
- Marimon, M.C.; Tangonan, G.; Libatique, N.J.; Sugimoto, K. Development and evaluation of wave sensor nodes for ocean wave monitoring. IEEE Syst. J. 2015, 9, 292–302. [Google Scholar] [CrossRef]
- Jeon, W.S.; Han, J.A.; Dong, G.J. A novel MAC scheme for multichannel cognitive radio Ad Hoc networks. IEEE Trans. Mob. Comput. 2012, 11, 922–934. [Google Scholar] [CrossRef]
- Hao, S.G.; Zhang, L.; Muhammad, G. A union authentication protocol of cross-domain based on bilinear pairing. J. Softw. 2013, 8, 1094–1100. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.Z.; Zhang, Z.H.; Lin, C.J. Research progress in similarity join query of big data. J. Comput. Appl. 2018, 38, 978–986. [Google Scholar]
- Liu, F.; Liu, Y.; Jin, D.; Jia, X.; Wang, T. Research on workshop-based positioning technology based on internet of things in big data background. Complexity 2018, 7875460. [Google Scholar] [CrossRef]
- Li, J.; Zhang, L.; Feng, X.; Jia, K.; Kong, F. Feature extraction and area identification of wireless channel in mobile communication. J. Internet Technol. 2019, 20, 544–553. [Google Scholar]
- Pang, J.; Gu, Y.; Xu, J.; Yu, G. Research advance on similarity join queries. J. Front. Comput. Sci. Technol. 2013, 7, 1–13. [Google Scholar]
- Lin, X.M.; Wang, W. Set and string similarity queries: a survey. Chin. J. Comput. 2011, 34, 1853–1862. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Q.; Leng, S.; Fan, B.; Wu, F. Data and energy integrated communication networks for wireless big data. Sci. Sin. 2018, 4, 713–723. [Google Scholar] [CrossRef]
- Alfano, S.; Pröllochs, N.; Feuerriegel, S.; Neumann, D. Say it right: is prototype to enable evidence-based communication using big data. Anal. Data Sci. 2018, 14, 217–221. [Google Scholar]
- Cappella, J.N. Vectors into the future of mass and interpersonal communication research: big data, social media, and computational social science: vectors into the future. Hum. Commun. Res. 2017, 43, 545–550. [Google Scholar] [CrossRef] [PubMed]
- Noh, L.S. Model of knowledge-based process management system using big data in the wireless communication environment. Wirel. Pers. Commun. 2017, 98, 1–16. [Google Scholar] [CrossRef]
- Gao, W.; Farahani, M.R. Distance learning techniques for ontology similarity measuring and ontology mapping. Clust. Comput. -J. Netw. Softw. Tools Appl. 2017, 20, 959–968. [Google Scholar] [CrossRef]
- Yang, J.; Shen, Y.T. The reality and dilemma of social media big data research: from the perspective of communication studies. Glob. Media J. 2018, 14, 45–51. [Google Scholar]
- Kim, S.J.; Marsch, L.A.; Hancock, J.T.; Das, A.K. Scaling up research on drug abuse and addiction through social media big data. J. Med. Internet. Res. 2017, 19, 26–31. [Google Scholar] [CrossRef]
- Jindal, A.; Kumar, N.; Singh, M. A unified framework for big data acquisition, storage and analytics for demand response management in smart cities. Future Gener. Comput. Syst. 2018, 15, 31–37. [Google Scholar] [CrossRef]
- Zhang, X.; Jian, M.; Sun, Y.; Wang, H.; Zhang, C. Improving image segmentation based on patch-weighted distance and fuzzy clustering. Multimed. Tools Appl. 2019, 12, 25–31. [Google Scholar] [CrossRef]
- Khorramnejad, K.; Ferdouse, L.; Guan, L.; Anpalagan, A. Performance of integrated workload scheduling and pre-fetching in multimedia mobile cloud computing. J. Cloud Comput. 2018, 7, 1–4. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, P.H.; Li, Y.G.; Li, M.Y. Fuzzy weighted c-harmonic regressions clustering algorithm. Soft Comput. 2017, 22, 1–17. [Google Scholar] [CrossRef]
- Chen, C.; Zhong, W.D. Hybrid space-frequency domain pre-equalization for DC-biased optical orthogonal frequency division multiplexing based imaging multiple-input multiple-output visible light communication systems. Opt. Eng. 2017, 56, 36–42. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Description or Value |
|---|---|
| Total node value | 400 |
| Spacing between nodes | 50‒100 m |
| Queue control | Optimize queue |
| Experimental wireless channel model | MICAZE |
| Experimental time | Longest 900 s |
| Experimental range | 1000 × 1000 m |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, H.; Sun, C.; Zeng, J. Fuzzy Weighted Clustering Method for Numerical Attributes of Communication Big Data Based on Cloud Computing. Symmetry 2020, 12, 530. https://doi.org/10.3390/sym12040530
Ding H, Sun C, Zeng J. Fuzzy Weighted Clustering Method for Numerical Attributes of Communication Big Data Based on Cloud Computing. Symmetry. 2020; 12(4):530. https://doi.org/10.3390/sym12040530
Chicago/Turabian StyleDing, Haitao, Chu Sun, and Jianqiu Zeng. 2020. "Fuzzy Weighted Clustering Method for Numerical Attributes of Communication Big Data Based on Cloud Computing" Symmetry 12, no. 4: 530. https://doi.org/10.3390/sym12040530