Classification of Guillain–Barré Syndrome Subtypes Using Sampling Techniques with Binary Approach

 , , and
, , and
Abstract
:1. Introduction
1.1. Guillain–Barré Syndrome
- 1
- Initial phase: evolution of symptoms lasting days to up to four weeks
- 2
- Plateau phase: lasting weeks to months
- 3
- Recovery phase: remyelination, lasting weeks to months. Critical patients can take a minimum of two years or more. Full recovery is not achieved in some cases.
- Acute Inflammatory Demyelinating Polyneuropathy (AIDP)
- Acute Motor Axonal Neuropathy (AMAN)
- Acute Motor Sensory Axonal Neuropathy (AMSAN)
- Miller–Fisher Syndrome (MF)
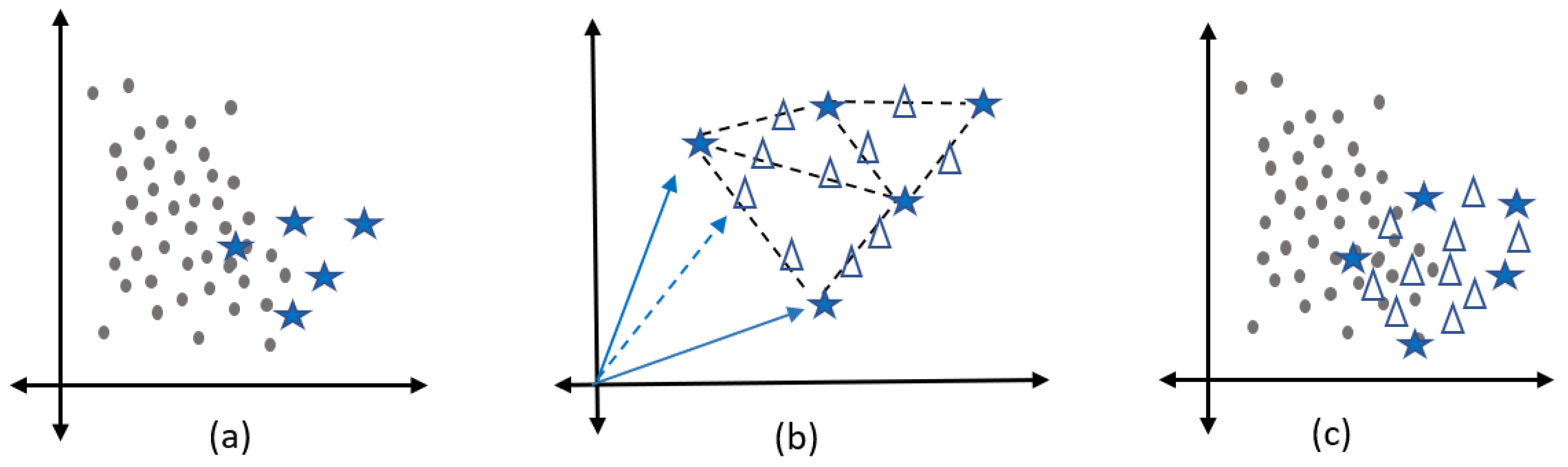
1.2. Imbalanced Data Classification
- ∗
- Algorithm Level: It makes a modification to the algorithm, generally adds more weight to the minority class. This method requires a deep knowledge of the operation of the algorithm to be modified. Each algorithm must be adapted to the dataset to be used.
- ∗
- Data Level: It consists of balancing the training set by matching the majority class with the minority class. This method is known as preprocessing since the modification of the data is done before the application of the classification algorithm. Standard classifiers are designed to work with a balanced dataset. The advantages of this method are that they are easy to configure, and they can be used with any classification algorithm. There are three sampling methods:
- ☉
- Undersampling: It consists of eliminating instances of the majority class until matching the number of instances with the minority class. There are other undersampling variants that eliminate instances in a directed manner such as noise or instances that are in the border of the decision area.
- ☉
- Oversampling: This method adds instances to the minority class until the majority class is balanced with the minority class. There are different variants for oversampling. For example, Random Oversampling (ROS), makes a copy of existing instances and adds a copy of them randomly. SMOTE is one of the most successful methods for oversampling. This adds instances in synthetic form to the minority class. There are also variants of SMOTE which have demonstrated great precision.
- ☉
- Hybrid: It is the combination of the different Oversampling and Undersampling methods.
- ∗
- Cost-sensitive: Combines the methods of Data level and Algorithm Level. It is considered the costs associated with misclassifying.
2. Related Work
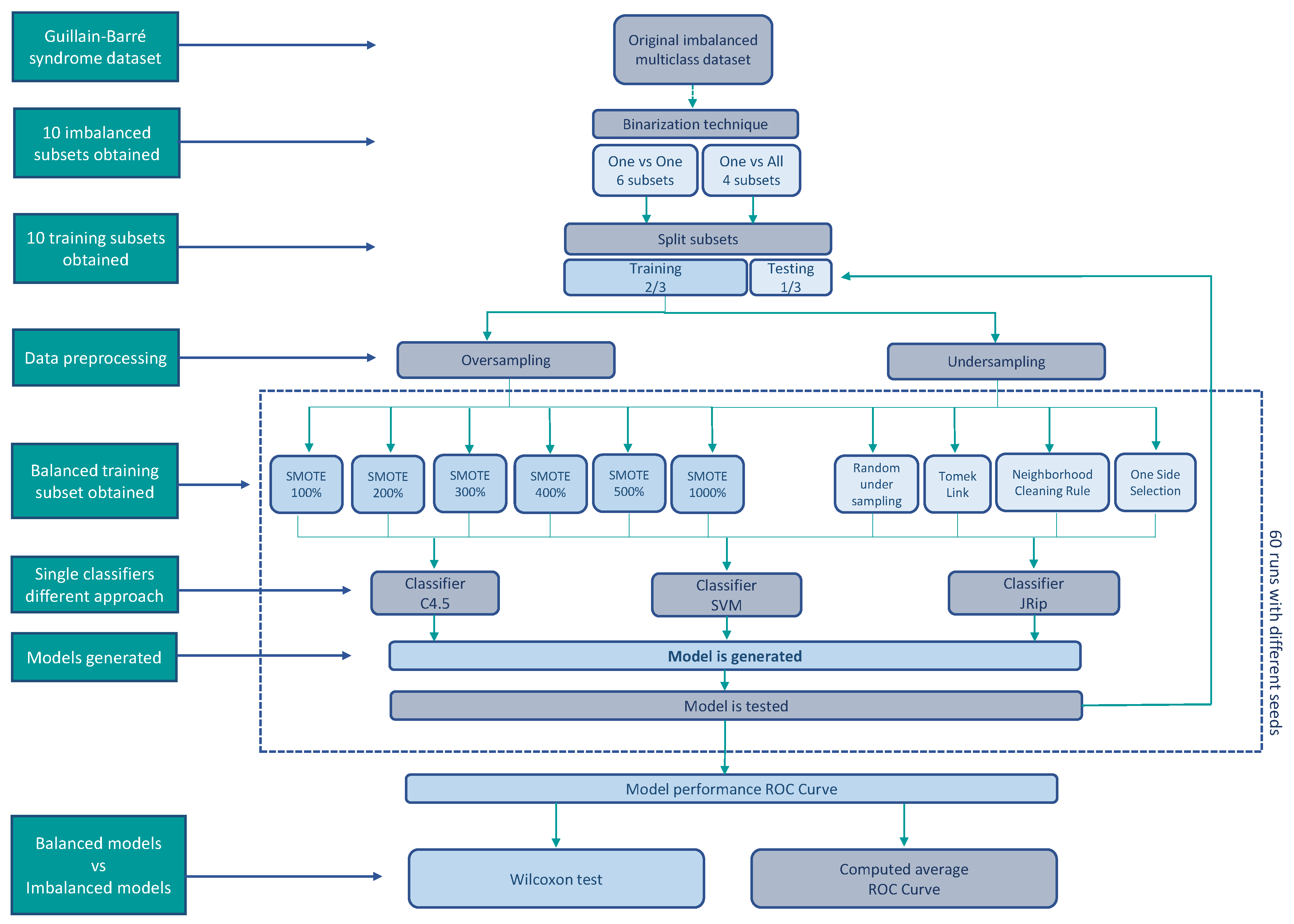
3. Materials and Methods
3.1. Dataset
3.2. Imbalance Ratio
3.3. Machine Learning Algorithms
3.3.1. Random Undersampling (RUS)
3.3.2. Tomek Link (TML)
3.3.3. One Side Selection (OSS)
| Algorithm 1: One Side Selection (OSS). |
 |
3.3.4. Neighborhood Cleaning Rule (NCR)
| Algorithm 2: Neighborhood Cleaning Rule (NCR). |
 |
3.3.5. Synthetic Minority Oversampling Technique (SMOTE)
| Algorithm 3: SMOTE. |
 |
3.3.6. Single Classifiers
- ☉
- Decision tree (C4.5): C4.5 divides the original problem into sub-groups. For each iteration, a tree with the best gain is constructed according to the selected feature. The decision tree is constructed top-down. The feature with the highest information gain is used to make the decision [51]. This method is one of the most popular of inductive algorithms. It has been successfully applied to diagnose medical cases [52].
- ☉
- Support Vector Machines (SVM): SVM is used in binary classification problems. Given a training set, SVM search for the optimal hyperplanes, with a maximum margin of the distance between them [53]. The larger the margin of the classes, the lower the error and accuracy increased of the classifier [54]. SVM is based-kernel.
- ☉
- RIPPER (JRip): JRip, a based-ruled approach, is one of the most popular algorithms for classification problems [55]. Classes are examined in increasing size. Then, a starting rule set for the class is created using incrementally reduced error. JRip creates a rule set for all the records of each class, one by one [56].
3.4. Performance Measure
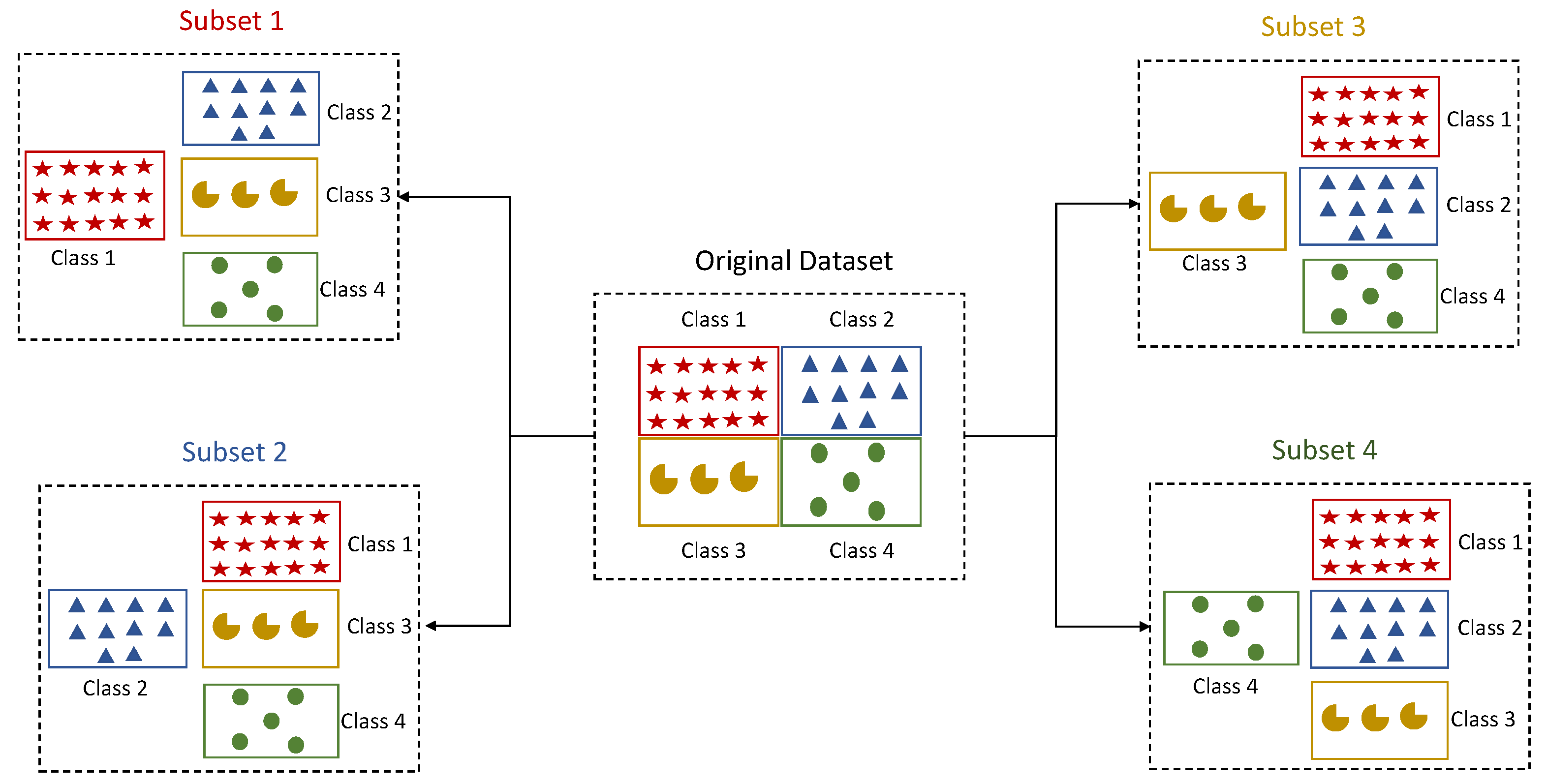
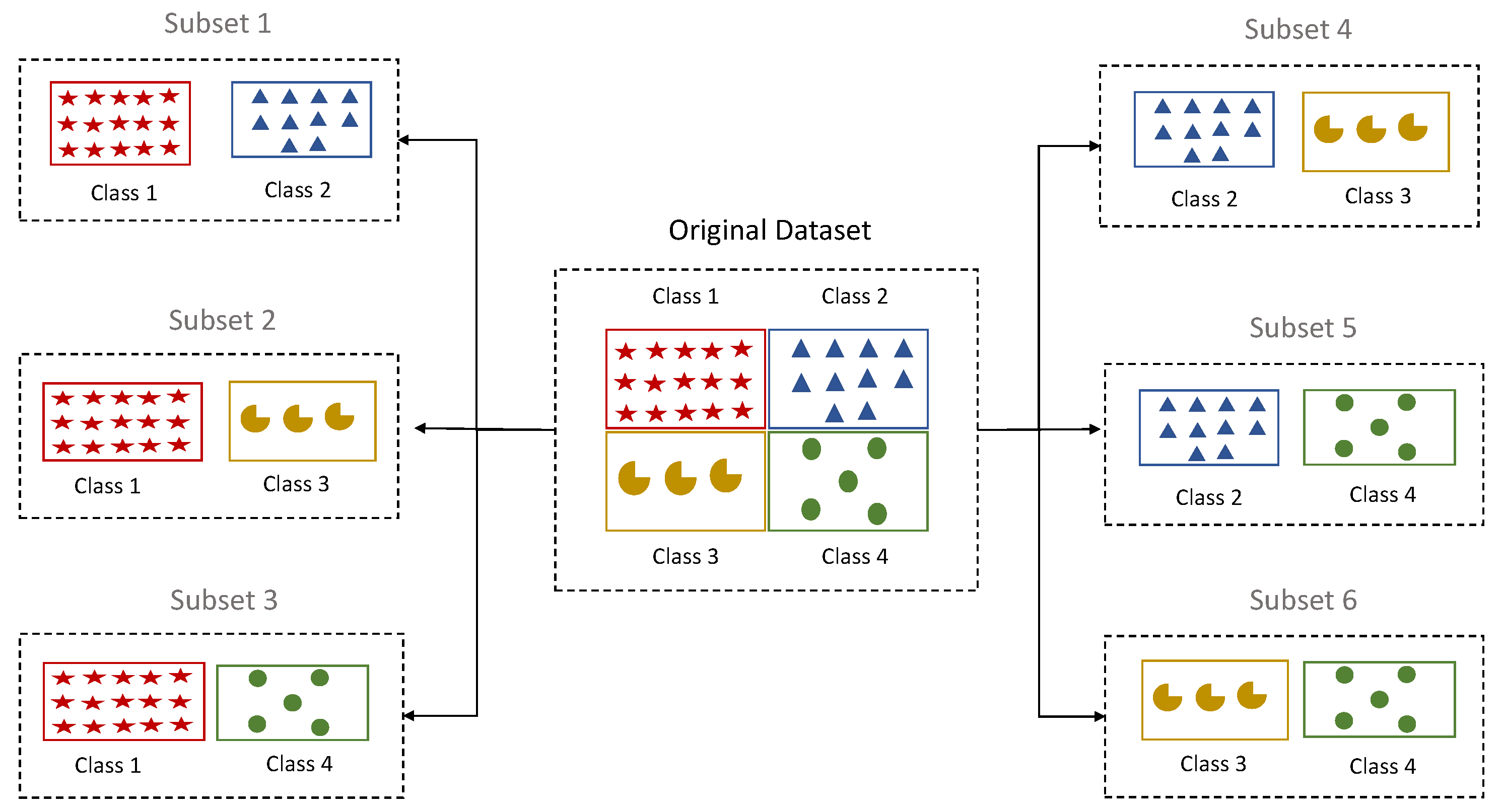
3.5. Binarization Techniques
3.6. Validation
4. Experimental Procedure
- GBS1 (129 instances): AIDP (20 instances) vs. ALL (109 instances).
- GBS2 (129 instances): AMAN (37 instances) vs. ALL (92 instances).
- GBS3 (129 instances): AMSAN (59 instances) vs. ALL (70 instances).
- GBS4 (129 instances): MF (13 instances) vs. ALL (116 instances).
- GBS1 (57 instances): AIDP (20 instances) vs. AMAN (37 instances).
- GBS2 (79 instances): AIDP (20 instances) vs. AMSAN (59 instances).
- GBS3 (33 instances): AIDP (20 instances) vs. MF (13 instances).
- GBS4 (96 instances): AMAN (37 instances) vs. AMSAN (59 instances).
- GBS5 (50 instances): AMAN (37 instances) vs. MF (13 instances).
- GBS6 (72 instances): AMSAN (59 instances) vs. MF (13 instances).
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Abbassi, N.; Ambegaonkar, G. Guillain-Barre syndrome: A review. Paediatr. Child Health 2019, 29, 459–462. [Google Scholar] [CrossRef]
- Elettreby, M.F.; Ahmed, E.; Safan, M. A simple mathematical model for Guillain–Barré syndrome. Adv. Differ. Equations 2019, 2019. [Google Scholar] [CrossRef]
- Pinto-Díaz, C.A.; Rodríguez, Y.; Monsalve, D.M.; Acosta-Ampudia, Y.; Molano-González, N.; Anaya, J.M.; Ramírez-Santana, C. Autoimmunity in Guillain-Barré syndrome associated with Zika virus infection and beyond. Autoimmun. Rev. 2017, 16, 327–334. [Google Scholar] [CrossRef] [PubMed]
- Kuwabara, S. Guillain-Barr?? Syndrome. Drugs 2004, 64, 597–610. [Google Scholar] [CrossRef]
- Panesar, K. Guillain-Barré Syndrome. US Pharm. 2014, 39, 35–38. [Google Scholar]
- Rodríguez, Y.; Chang, C.; González-Bravo, D.C.; Gershwin, M.E.; Anaya, J.M. Guillain-Barré Syndrome. In Neuroimmune Diseases; Springer International Publishing: Basel, Switzerland, 2019; pp. 711–736. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To combat multi-class imbalanced problems by means of over-sampling and boosting techniques. Soft Comput. 2014, 19, 3369–3385. [Google Scholar] [CrossRef]
- He, H.; Garcia, E. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Sáez, J.A.; Krawczyk, B.; Woźniak, M. Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets. Pattern Recognit. 2016, 57, 164–178. [Google Scholar] [CrossRef]
- Feng, W.; Huang, W.; Ren, J. Class Imbalance Ensemble Learning Based on the Margin Theory. Appl. Sci. 2018, 8, 815. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Zhou, J.; Wu, C.A. Imbalanced Learning Based on Data-Partition and SMOTE. Information 2018, 9, 238. [Google Scholar] [CrossRef] [Green Version]
- Lee, P. Resampling Methods Improve the Predictive Power of Modeling in Class-Imbalanced Datasets. Int. J. Environ. Res. Public Health 2014, 11, 9776–9789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Canul-Reich, J.; Frausto-Solís, J.; Hernández-Torruco, J. A Predictive Model for Guillain-Barré Syndrome Based on Single Learning Algorithms. Comput. Math. Methods Med. 2017, 2017, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Canul-Reich, J.; Hernández-Torruco, J.; Chávez-Bosquez, O.; Hernández-Ocaña, B. A Predictive Model for Guillain–Barré Syndrome Based on Ensemble Methods. Comput. Intell. Neurosci. 2018, 2018, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Huang, Z.; Li, S.; Jia, Y. Distribution-Sensitive Unbalanced Data Oversampling Method for Medical Diagnosis. J. Med. Syst. 2019, 43. [Google Scholar] [CrossRef] [PubMed]
- Bach, M.; Werner, A.; Żywiec, J.; Pluskiewicz, W. The study of under- and over-sampling methods’ utility in analysis of highly imbalanced data on osteoporosis. Inf. Sci. 2017, 384, 174–190. [Google Scholar] [CrossRef]
- Kalwa, U.; Legner, C.; Kong, T.; Pandey, S. Skin Cancer Diagnostics with an All-Inclusive Smartphone Application. Symmetry 2019, 11, 790. [Google Scholar] [CrossRef] [Green Version]
- Le, T.; Baik, S. A Robust Framework for Self-Care Problem Identification for Children with Disability. Symmetry 2019, 11, 89. [Google Scholar] [CrossRef] [Green Version]
- Ijaz, M.; Alfian, G.; Syafrudin, M.; Rhee, J. Hybrid Prediction Model for Type 2 Diabetes and Hypertension Using DBSCAN-Based Outlier Detection, Synthetic Minority Over Sampling Technique (SMOTE), and Random Forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef] [Green Version]
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Devi, D.; kr. Biswas, S.; Purkayastha, B. Redundancy-driven modified Tomek-link based undersampling: A solution to class imbalance. Pattern Recognit. Lett. 2017, 93, 3–12. [Google Scholar] [CrossRef]
- Bach, M.; Werner, A.; Palt, M. The Proposal of Undersampling Method for Learning from Imbalanced Datasets. Procedia Comput. Sci. 2019, 159, 125–134. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- Kovács, G. An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets. Appl. Soft Comput. 2019, 83, 105662. [Google Scholar] [CrossRef]
- Gosain, A.; Sardana, S. Farthest SMOTE: A Modified SMOTE Approach. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2018; pp. 309–320. [Google Scholar] [CrossRef]
- Devi, D.; Biswas, S.K.; Purkayastha, B. Learning in presence of class imbalance and class overlapping by using one-class SVM and undersampling technique. Connect. Sci. 2019, 31, 105–142. [Google Scholar] [CrossRef]
- Halstead, S.K.; Kalna, G.; Islam, M.B.; Jahan, I.; Mohammad, Q.D.; Jacobs, B.C.; Endtz, H.P.; Islam, Z.; Willison, H.J. Microarray screening of Guillain-Barré syndrome sera for antibodies to glycolipid complexes. Neurol. Neuroimmunol. Neuroinflamm. 2016, 3, e284. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Li, H.; Fujita, H.; Fu, B.; Ai, W. Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Inf. Fusion 2020, 54, 128–144. [Google Scholar] [CrossRef]
- Sisodia, D.S.; Reddy, N.K.; Bhandari, S. Performance evaluation of class balancing techniques for credit card fraud detection. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017. [Google Scholar] [CrossRef]
- Ahsan, M.; Gomes, R.; Denton, A. SMOTE Implementation on Phishing Data to Enhance Cybersecurity. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018. [Google Scholar] [CrossRef]
- Hernández-Torruco, J.; Canul-Reich, J.; Frausto-Solís, J.; Méndez-Castillo, J.J. Feature Selection for Better Identification of Subtypes of Guillain-Barré Syndrome. Comput. Math. Methods Med. 2014, 2014, 1–9. [Google Scholar] [CrossRef]
- Zoldi, S. Using anti-fraud technology to improve the customer experience. Comput. Fraud Secur. 2015, 2015, 18–20. [Google Scholar] [CrossRef]
- Zarinabad, N.; Wilson, M.; Gill, S.K.; Manias, K.A.; Davies, N.P.; Peet, A.C. Multiclass imbalance learning: Improving classification of pediatric brain tumors from magnetic resonance spectroscopy. Magn. Reson. Med. 2016, 77, 2114–2124. [Google Scholar] [CrossRef]
- Zhu, R.; Wang, Z.; Ma, Z.; Wang, G.; Xue, J.H. LRID: A new metric of multi-class imbalance degree based on likelihood-ratio test. Pattern Recognit. Lett. 2018, 116, 36–42. [Google Scholar] [CrossRef]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl.-Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Loyola-González, O.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A.; García-Borroto, M. Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases. Neurocomputing 2016, 175, 935–947. [Google Scholar] [CrossRef]
- Napierala, K.; Stefanowski, J. Types of minority class examples and their influence on learning classifiers from imbalanced data. J. Intell. Inf. Syst. 2015, 46, 563–597. [Google Scholar] [CrossRef]
- Abdoh, S.F.; Rizka, M.A.; Maghraby, F.A. Cervical Cancer Diagnosis Using Random Forest Classifier With SMOTE and Feature Reduction Techniques. IEEE Access 2018, 6, 59475–59485. [Google Scholar] [CrossRef]
- Yen, S.J.; Lee, Y.S. Under-Sampling Approaches for Improving Prediction of the Minority Class in an Imbalanced Dataset. In Intelligent Control and Automation; Springer: Berlin/Heidelberg, Germany, 2006; pp. 731–740. [Google Scholar] [CrossRef]
- García, S.; Herrera, F. Evolutionary Undersampling for Classification with Imbalanced Datasets: Proposals and Taxonomy. Evol. Comput. 2009, 17, 275–306. [Google Scholar] [CrossRef]
- Liu, C.; Wu, J.; Mirador, L.; Song, Y.; Hou, W. Classifying DNA Methylation Imbalance Data in Cancer Risk Prediction Using SMOTE and Tomek Link Methods. In Communications in Computer and Information Science; Springer: Singapore, 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Gu, Q.; Cai, Z.; Zhu, L.; Huang, B. Data Mining on Imbalanced Data Sets. In Proceedings of the 2008 International Conference on Advanced Computer Theory and Engineering, Phuket, Thailand, 20–22 December 2008. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection. Icml 1997, 97, 179–186. [Google Scholar]
- Jia, C.; Zuo, Y. S-SulfPred: A sensitive predictor to capture S-sulfenylation sites based on a resampling one-sided selection undersampling-synthetic minority oversampling technique. J. Theor. Biol. 2017, 422, 84–89. [Google Scholar] [CrossRef]
- Laurikkala, J. Improving Identification of Difficult Small Classes by Balancing Class Distribution. In Artificial Intelligence in Medicine; Springer: Berlin/Heidelberg, Germany, 2001; pp. 63–66. [Google Scholar] [CrossRef] [Green Version]
- Faris, H. Neighborhood Cleaning Rules and Particle Swarm Optimization for Predicting Customer Churn Behavior in Telecom Industry. Int. J. Adv. Sci. Technol. 2014, 68, 11–22. [Google Scholar] [CrossRef]
- Agustianto, K.; Destarianto, P. Imbalance Data Handling using Neighborhood Cleaning Rule (NCL) Sampling Method for Precision Student Modeling. In Proceedings of the 2019 International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Jember, Indonesia, 16–17 October 2019. [Google Scholar] [CrossRef]
- Junsomboon, N.; Phienthrakul, T. Combining Over-Sampling and Under-Sampling Techniques for Imbalance Dataset. In Proceedings of the 9th International Conference on Machine Learning and Computing—ICMLC 2017, Singapore, 24–26 February 2017; ACM Press: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Sánchez, L.C.; Briseño, A.P.; Rosas, R.M.V.; Garreta, J.S.S.; Jiménez, V.G.; Nieto, O.C.; Meana, H.P.; Miyatake, M.N. Empirical Study of the Associative Approach in the Context of Classification Problems. Comput. Y Sist. 2019, 23. [Google Scholar] [CrossRef]
- Polat, K.; Güneş, S. A novel hybrid intelligent method based on C4.5 decision tree classifier and one-against-all approach for multi-class classification problems. Expert Syst. Appl. 2009, 36, 1587–1592. [Google Scholar] [CrossRef]
- Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A.; Jauregui-Correa, J.C. Support Vector Machine-Based EMG Signal Classification Techniques: A Review. Appl. Sci. 2019, 9, 4402. [Google Scholar] [CrossRef] [Green Version]
- Ai, X.; Wang, H.; Sun, B. Automatic Identification of Sedimentary Facies Based on a Support Vector Machine in the Aryskum Graben, Kazakhstan. Appl. Sci. 2019, 9, 4489. [Google Scholar] [CrossRef] [Green Version]
- Asadi, S. Evolutionary fuzzification of RIPPER for regression: Case study of stock prediction. Neurocomputing 2019, 331, 121–137. [Google Scholar] [CrossRef]
- Milosevic, N.; Dehghantanha, A.; Choo, K.K.R. Machine learning aided Android malware classification. Comput. Electr. Eng. 2017, 61, 266–274. [Google Scholar] [CrossRef] [Green Version]
- Gu, Q.; Zhu, L.; Cai, Z. Evaluation Measures of the Classification Performance of Imbalanced Data Sets. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 461–471. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer International Publishing: Basel, Switzerland, 2018. [Google Scholar] [CrossRef]
- Lutu, P.E.; Engelbrecht, A.P. Using OVA modeling to improve classification performance for large datasets. Expert Syst. Appl. 2012, 39, 4358–4376. [Google Scholar] [CrossRef]
- Quost, B.; Destercke, S. Classification by pairwise coupling of imprecise probabilities. Pattern Recognit. 2018, 77, 412–425. [Google Scholar] [CrossRef]
- Marrocco, C.; Tortorella, F. Exploiting coding theory for classification: An LDPC-based strategy for multiclass-to-binary decomposition. Inf. Sci. 2016, 357, 88–107. [Google Scholar] [CrossRef]
- Cuzick, J. A wilcoxon-type test for trend. Stat. Med. 1985, 4, 543–547. [Google Scholar] [CrossRef] [PubMed]
- Torgo, L. Datamining with R Learning with Case Studies; Chapman & Hall/CRC: Boca Raton, FL, USA, 2011. [Google Scholar]
- Pozzolo, A.D.; Caelen, O.; Bontempi, G. Unbalanced: Racing for Unbalanced Methods Selection; R Package Version 2.0; 2015. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pañ, C. Data Mining, Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien; R Package Version 1.7-0; 2018. [Google Scholar]
- Urbanek, S. rJava: Low-Level R to Java Interface; R Package Version 0.9-10; 2018. [Google Scholar]
- Kuhn, M. caret: Classification and Regression Training; R Package Version 6.0-81; 2018. [Google Scholar]
- Cordón, I.; García, S.; Fernández, A.; Herrera, F. imbalance: Preprocessing Algorithms for Imbalanced Datasets; R Package Version 1.0.0; 2018. [Google Scholar]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Muller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, D. Lattice: Multivariate Data Visualization with R; Springer: New York, NY, USA, 2008; ISBN 978-0-387-75968-5. [Google Scholar]
- Therneau, T.; Atkinson, B. rpart: Recursive Partitioning and Regression Trees; R Package Version 4.1-13; 2018. [Google Scholar]
- Milborrow, S. rpart.plot: Plot ‘rpart’ Models: An Enhanced Version of ‘plot.rpart’; R Package Version 3.0.5; 2018. [Google Scholar]
- Kaur, P.; Gosain, A. Issues and challenges of class imbalance problem in classification. Int. J. Inf. Technol. 2018. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Symptoms | Pathology |
|---|---|---|
| AIDP | Most common variant (85% of cases). Primarily motor inflammatory demyelination ± secondary axonal damage. Maximum of four weeks of progression. | Macrophages invade intact myelin sheaths and denude the axons. |
| AMAN | Motor only with early and severe respiratory involvement. Primary axonal degeneration. Often affects children, young adults. Up to 75% positive Campylobacter jejuni serology. Often positive for anti-GM1, anti-GD1a antibodies. | Macrophages invade the nodes of Ranvier where they insert between the axon and the surrounding Schwann-cell axolemma, leaving the myelin sheath intact. |
| AMSAN | Motor and sensory affection with critical course of respiratory and bulbar involvement. Primary axonal degeneration with poorer prognosis. | Similar to AMAN but also involving vetral and dorsal roots. |
| MF | Ophthalmoplegia, sensory ataxia, areflexia. 5% of all cases. 96% positive for anti-GQ1b antibodies. | Abnormality in sensory conduction, although the underlying pathology is not clear. |
| Dataset | Number of | Number of | Number of | Class 1 | Class 2 | Class 3 | Class 4 |
|---|---|---|---|---|---|---|---|
| Name | Classes | Instances | Attributes | AIDP | AMAN | AMSAN | MF |
| GBS | 4 | 129 | 16 | 20 | 37 | 59 | 13 |
| Feature Label | Feature Name | Feature Type |
|---|---|---|
| v22 | Symmetry (in weakness) | Clinical |
| v29 | Extraocular muscles involvement | ✓ |
| v30 | Ptosis | ✓ |
| v31 | Cerebellar involvement | ✓ |
| v63 | Amplitude of left median motor nerve | Nerve conduction test |
| v106 | Area under the curve of left ulnar motor nerve | ✓ |
| v120 | Area under the curve of right ulnar motor nerve | ✓ |
| v130 | Amplitude of left tibial motor nerve | ✓ |
| v141 | Amplitude of right tibial motor nerve | ✓ |
| v161 | Area under the curve of right peroneal motor nerve | ✓ |
| v172 | Amplitude of left median sensory nerve | ✓ |
| v177 | Amplitude of right median sensory nerve | ✓ |
| v178 | Area under the curve of right median sensory nerve | ✓ |
| v186 | Latency of right ulnar sensory nerve | ✓ |
| v187 | Amplitude of right ulnar sensory nerve | ✓ |
| v198 | Area under the curve of right sural sensory nerve | ✓ |
| Subset | Original | Training | Random | Neighborhood | One Side | Tomek |
|---|---|---|---|---|---|---|
| Undersampling | Cleaning Rule | Selection | Link | |||
| GBS1 | 109 | 73 | 14 | 62 | 63 | 67 |
| GBS2 | 92 | 62 | 25 | 59 | 28 | 59 |
| GBS3 | 70 | 47 | 40 | 41 | 24 | 43 |
| GBS4 | 116 | 78 | 9 | 64 | 39 | 70 |
| Subset | Original | Training | Random | Neighborhood | One Side | Tomek |
|---|---|---|---|---|---|---|
| Undersampling | Cleaning Rule | Selection | Link | |||
| GBS1 | 37 | 25 | 14 | 16 | 17 | 22 |
| GBS2 | 59 | 40 | 14 | 35 | 14 | 38 |
| GBS3 | 20 | 14 | 9 | 9 | 7 | 8 |
| GBS4 | 59 | 40 | 25 | 39 | 16 | 39 |
| GBS5 | 37 | 25 | 9 | 19 | 20 | 23 |
| GBS6 | 59 | 40 | 9 | 34 | 35 | 37 |
| Subset | Original | Training | SMOTE | SMOTE | SMOTE | SMOTE | SMOTE | SMOTE |
|---|---|---|---|---|---|---|---|---|
| 100% | 200% | 300% | 400% | 500% | 1000% | |||
| GBS1 | 20 | 14 | 28 | 42 | 56 | 70 | 84 | 154 |
| GBS2 | 37 | 25 | 50 | 75 | 100 | 125 | 150 | 275 |
| GBS3 | 59 | 40 | 80 | 120 | 160 | 200 | 240 | 440 |
| GBS4 | 13 | 9 | 18 | 27 | 36 | 45 | 54 | 99 |
| Subset | Original | Training | SMOTE | SMOTE | SMOTE | SMOTE | SMOTE | SMOTE |
|---|---|---|---|---|---|---|---|---|
| 100% | 200% | 300% | 400% | 500% | 1000% | |||
| GBS1 | 20 | 11 | 22 | 33 | 44 | 55 | 66 | 121 |
| GBS2 | 20 | 14 | 28 | 42 | 56 | 70 | 84 | 154 |
| GBS3 | 13 | 9 | 18 | 27 | 36 | 45 | 54 | 99 |
| GBS4 | 37 | 24 | 48 | 72 | 96 | 120 | 144 | 264 |
| GBS5 | 13 | 9 | 18 | 27 | 36 | 45 | 54 | 99 |
| GBS6 | 13 | 10 | 20 | 30 | 40 | 50 | 60 | 110 |
| SGB | Minority | Majority | Imbalance |
|---|---|---|---|
| Class | Class | Ratio | |
| GBS1 | 20 | 109 | 5.4500 |
| GBS2 | 37 | 92 | 2.4865 |
| GBS3 | 59 | 70 | 1.1864 |
| GBS4 | 13 | 116 | 8.9231 |
| SGB | Minority | Majority | Imbalance |
|---|---|---|---|
| Class | Class | Ratio | |
| GBS1 | 20 | 37 | 1.8500 |
| GBS2 | 20 | 59 | 2.9500 |
| GBS3 | 13 | 20 | 1.5385 |
| GBS4 | 37 | 59 | 1.5946 |
| GBS5 | 13 | 37 | 2.8462 |
| GBS6 | 13 | 59 | 4.5385 |
| Case Instances | Classifier | Imbalanced Dataset | Random Undersampling | Wilcoxon Test | Tomek Link | Wilcoxon Test | One Side Selection | Wilcoxon Test | Neighborhood Cleaning Rule | Wilcoxon Test |
|---|---|---|---|---|---|---|---|---|---|---|
| ROC | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ||
| GBS1 | C4.5 | 0.8130 | 0.7940 | NC | 0.8287 | 0.8192 | 0.8273 | |||
| AIDP-ALL | SVM | 0.7477 | 0.7734 | 0.7553 | 0.7618 | 0.7632 | ||||
| 20-109 | JRip | 0.7826 | 0.8150 * | 0.7949 | 0.7766 | NC | 0.8074 * | |||
| SGB2 | C4.5 | 0.9003 | 0.8924 | NC | 0.9088 | 0.9182 * | 0.8939 | NC | ||
| AMAN-ALL | SVM | 0.8594 | 0.8832 * | 0.8575 | NC | 0.8611 | 0.8557 | NC | ||
| 37-92 | JRip | 0.8608 | 0.8656 | 0.8668 | 0.8601 | NC | 0.8414 | NC | ||
| SGB3 | C4.5 | 0.8632 | 0.8582 | NC | 0.8579 | NC | 0.8496 | NC | 0.8644 | |
| AMSAN-ALL | SVM | 0.7898 | 0.7906 | 0.7911 | 0.7870 | NC | 0.7981 | |||
| 59-70 | JRip | 0.8470 | 0.8440 | NC | 0.8639 | NC | 0.8288 | NC | 0.8444 | NC |
| SGB4 | C4.5 | 0.7662 | 0.8906 * | 0.7935 | 0.8103 * | 0.8033 | ||||
| MF-ALL | SVM | 0.6846 | 0.7099 | 0.7323 | 0.7709 * | 0.7319 | ||||
| 13-116 | JRip | 0.8319 | 0.8781 * | 0.8577 | 0.8633 | 0.8498 |
| Case Instaces | Classifier | Imbalanced Dataset | Random Undersampling | Wilcoxon Test | Tomek Link | Wilcoxon Test | One Side Selection | Wilcoxon Test | Neighborhood Cleaning Rule | Wilcoxon Test |
|---|---|---|---|---|---|---|---|---|---|---|
| ROC | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ||
| GBS1 | C4.5 | 0.9604 | 0.9264 | NC | 0.9319 | NC | 0.8972 | NC | 0.9458 | NC |
| AIDP-AMAN | SVM | 0.9674 | 0.9639 | NC | 0.9590 | NC | 0.9528 | NC | 0.9660 | NC |
| 20-37 | JRip | 0.9563 | 0.9479 | NC | 0.9500 | NC | 0.9146 | NC | 0.9438 | NC |
| GBS2 | C4.5 | 0.8585 | 0.8251 | NC | 0.8541 | NC | 0.8266 | NC | 0.8496 | NC |
| AIDP-AMSAN | SVM | 0.8490 | 0.8292 | NC | 0.8458 | NC | 0.8242 | NC | 0.8447 | NC |
| 20-59 | JRip | 0.8260 | 0.8220 | NC | 0.8308 | 0.8471 | 0.8289 | |||
| GBS3 | C4.5 | 0.8132 | 0.8667 * | 0.8840 * | 0.8854 * | 0.8604 * | ||||
| AIDP-MF | SVM | 0.7097 | 0.6465 | NC | 0.6667 | NC | 0.6354 | NC | 0.6542 | NC |
| 20-13 | JRip | 0.8556 | 0.8757 | 0.8771 | 0.8590 | 0.8507 | ||||
| GBS4 | C4.5 | 0.9258 | 0.9102 | NC | 0.9270 | 0.9260 | 0.9178 | NC | ||
| AMAN-AMSAN | SVM | 0.8783 | 0.8976 * | 0.8721 | NC | 0.8647 | NC | 0.8823 | ||
| 37-59 | JRip | 0.8782 | 0.8966 | 0.8973 * | 0.9098 * | 0.8758 | NC | |||
| GBS5 | C4.5 | 0.8736 | 0.8813 | 0.8847 | 0.8632 | NC | 0.8847 | |||
| AMAN-MF | SVM | 0.8910 | 0.8743 | NC | 0.8840 | NC | 0.8569 | NC | 0.8785 | NC |
| 37-13 | JRip | 0.8854 | 0.8736 | NC | 0.8792 | NC | 0.8771 | NC | 0.8854 | NC |
| GBS6 | C4.5 | 0.8007 | 0.8753 * | 0.8679 * | 0.8582 * | 0.8401 * | ||||
| AMSAN-MF | SVM | 0.7388 | 0.7724 | 0.7784 * | 0.7538 | 0.7701 | ||||
| 59-13 | JRip | 0.8580 | 0.8811 | 0.8635 | 0.8640 | 0.8385 | NC |
| Case Instances | Classifier | Imbalanced Dataset | SMOTE 100% | Wilcoxon Test | SMOTE 200% | Wilcoxon Test | SMOTE 300% | Wilcoxon Test | SMOTE 400% | Wilcoxon Test | SMOTE 500% | Wilcoxon Test | SMOTE 1000% | Wilcoxon Test |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ||
| GBS1 | C4.5 | 0.8130 | 0.8042 | NC | 0.7951 | NC | 0.7905 | NC | 0.7986 | NC | 0.7877 | NC | 0.7951 | NC |
| AIDP-ALL | SVM | 0.7477 | 0.7750 | 0.7544 | 0.7407 | NC | 0.7498 | 0.7428 | NC | 0.7556 | ||||
| 20-109 | JRip | 0.7826 | 0.8102 * | 0.7993 | 0.8030 * | 0.8046 | 0.7891 | 0.7993 | ||||||
| GBS2 | C4.5 | 0.9003 | 0.8900 | NC | 0.8972 | NC | 0.8915 | NC | 0.8890 | NC | 0.8890 | NC | 0.8939 | NC |
| AMAN-ALL | SVM | 0.8594 | 0.8490 | NC | 0.8417 | NC | 0.8411 | NC | 0.8401 | NC | 0.8417 | NC | 0.8379 | NC |
| 37-92 | JRip | 0.8608 | 0.8699 | 0.8718 | 0.8606 | 0.8689 | 0.8892 * | 0.8767 | ||||||
| GBS3 | C4.5 | 0.8632 | 0.8795 * | 0.8592 | 0.8689 | 0.8699 | 0.8747 | 0.8792 | ||||||
| AMSAN-ALL | SVM | 0.7898 | 0.7881 | NC | 0.7863 | NC | 0.7888 | NC | 0.7909 | 0.7917 | 0.7887 | NC | ||
| 59-70 | JRip | 0.8470 | 0.8442 | NC | 0.8603 * | 0.8640 * | 0.8632 | 0.8616 * | 0.8678 * | |||||
| GBS4 | C4.5 | 0.7662 | 0.8951 * | 0.8588 * | 0.8292 * | 0.8180 | 0.8340 * | 0.8007 | ||||||
| MF-ALL | SVM | 0.6846 | 0.7516 * | 0.7590 * | 0.7409 | 0.7568 * | 0.7604 * | 0.7679 * | ||||||
| 13-116 | JRip | 0.8319 | 0.8826 * | 0.8447 | 0.8339 | 0.8466 | 0.8469 | 0.8198 | NC |
| Case Instances | Classifier | Imbalanced Dataset | SMOTE 100% | Wilcoxon Test | SMOTE 200% | Wilcoxon Test | SMOTE 300% | Wilcoxon Test | SMOTE 400% | Wilcoxon Test | SMOTE 500% | Wilcoxon Test | SMOTE 1000% | Wilcoxon Test |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ROC | RESULT | ||
| GBS1 | C4.5 | 0.9563 | 0.9576 | 0.9438 | NC | 0.9493 | NC | 0.9528 | NC | 0.9556 | NC | 0.9576 | ||
| AIDP-AMAN | SVM | 0.9618 | 0.9618 | NC | 0.9632 | NC | 0.9639 | NC | 0.9625 | NC | 0.9632 | NC | 0.9632 | NC |
| 20-37 | JRip | 0.9507 | 0.9403 | NC | 0.9424 | NC | 0.9403 | NC | 0.9382 | NC | 0.9319 | NC | 0.9389 | NC |
| GBS2 | C4.5 | 0.8656 | 0.8551 | NC | 0.8485 | NC | 0.8375 | NC | 0.8502 | NC | 0.8607 | NC | 0.8551 | NC |
| AIDP-AMSAN | SVM | 0.8557 | 0.8333 | NC | 0.8328 | NC | 0.8428 | NC | 0.8381 | NC | 0.8338 | NC | 0.8333 | NC |
| 20-59 | JRip | 0.8472 | 0.8549 | 0.8285 | NC | 0.8480 | 0.8561 | 0.8480 | 0.8549 | |||||
| GBS3 | C4.5 | 0.8132 | 0.7965 | NC | 0.7986 | NC | 0.7889 | NC | 0.7729 | NC | 0.7958 | NC | 0.7965 | NC |
| AIDP-MF | SVM | 0.7097 | 0.6535 | NC | 0.6486 | NC | 0.6472 | NC | 0.6465 | NC | 0.6563 | NC | 0.6535 | NC |
| 20-13 | JRip | 0.8458 | 0.7382 | NC | 0.7778 | NC | 0.7750 | NC | 0.7646 | NC | 0.7292 | NC | 0.7382 | NC |
| GBS4 | C4.5 | 0.9132 | 0.9093 | NC | 0.9096 | NC | 0.9172 | 0.9062 | NC | 0.9207 | 0.9093 | NC | ||
| MF-ALL | SVM | 0.8863 | 0.8827 | NC | 0.8844 | NC | 0.8843 | NC | 0.8840 | NC | 0.8821 | NC | 0.8827 | NC |
| 13-116 | JRip | 0.8809 | 0.9065 * | 0.9042 * | 0.9019 * | 0.9043 * | 0.9071 * | 0.9065 * | ||||||
| GBS5 | C4.5 | 0.8736 | 0.8868 | 0.8792 | 0.8833 | 0.8701 | NC | 0.8861 | 0.8868 | |||||
| AMAN-NF | SVM | 0.8910 | 0.8847 | NC | 0.8715 | NC | 0.8792 | NC | 0.8840 | NC | 0.8847 | NC | 0.8847 | NC |
| 37-13 | JRip | 0.8799 | 0.8889 | 0.8799 | NC | 0.8875 | 0.8903 | 0.8861 | 0.8889 | |||||
| GBS6 | C4.5 | 0.8007 | 0.7839 | NC | 0.8185 | 0.8287 | 0.8084 | 0.8041 | 0.7839 | NC | ||||
| AMSAN-MF | SVM | 0.7388 | 0.7534 | 0.7646 | 0.7651 | 0.7522 | 0.7469 | 0.7534 | ||||||
| 59-13 | JRip | 0.8430 | 0.8720 * | 0.8393 | NC | 0.8306 | NC | 0.8213 | NC | 0.8111 | NC | 0.8061 | NC |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres-Vásquez, M.; Chávez-Bosquez, O.; Hernández-Ocaña, B.; Hernández-Torruco, J. Classification of Guillain–Barré Syndrome Subtypes Using Sampling Techniques with Binary Approach. Symmetry 2020, 12, 482. https://doi.org/10.3390/sym12030482
Torres-Vásquez M, Chávez-Bosquez O, Hernández-Ocaña B, Hernández-Torruco J. Classification of Guillain–Barré Syndrome Subtypes Using Sampling Techniques with Binary Approach. Symmetry. 2020; 12(3):482. https://doi.org/10.3390/sym12030482
Chicago/Turabian StyleTorres-Vásquez, Manuel, Oscar Chávez-Bosquez, Betania Hernández-Ocaña, and José Hernández-Torruco. 2020. "Classification of Guillain–Barré Syndrome Subtypes Using Sampling Techniques with Binary Approach" Symmetry 12, no. 3: 482. https://doi.org/10.3390/sym12030482