1. Introduction
Recently, many works on finite mixture models have been produced which support researchers in modelling and interpreting data stemming from unobserved (“latent”) sub-populations. Finite mixture models can handle heterogeneous data by providing a flexible representation in the form of a weighted sum of probability densities. Applications of such models include clustering, classification and data visualization, but mixture models are also used for simulation steps within evolutionary algorithms, or as a building block of advanced statistical models (for instance, multi-level models) in order to adequately account for the error structure of the problem at hand. Mixture models have furthermore been used as a tool to address over-dispersion, which in turn is related to the presence of long-tailed distributions. Examples for data situations which possess a mixture structure include industrial measurements of a certain quantity which, during the measurement process, underwent a slight, possibly unnoted, change of conditions. An explicit example within an industrial context, involving temperature measurements from a glass melter, is provided below.
A well-known problem with the typically employed Gaussian mixtures is that these are not able to deal well with outlying observations. If the Gaussian mixture components are allowed to have unequal variances, it has frequently been observed that specific outlying observations “capture” a mixture component for their own, which will be centered at that outlier and will approach zero variance as the expectation-maximization routine progresses [
1]. Since “zero variance” corresponds to “infinite likelihood” in the context of Gaussian distributions, one also talks here of likelihood spikes. Several methods have been proposed to deal with this problem in the literature, including the use of “smoothed” variances [
1], the use of a mixtures with an “improper” component which mops up the outliers [
2], and the use of mixtures of distributions with thicker tails, such as
t-distributions [
3].
However, these existing techniques come with some limitations. The first two approaches stabilize the estimation numerically, but, in doing so, they dismiss the possibility of the outliers actually being a genuine feature of some physically meaningful component, even if strongly outlying. In the third approach, one considers, for some univariate and i.i.d. response data a mixture of t-distributions, where each of the means, variances and degrees of freedom can be estimated from the data.
Fitting mixtures of
t-distributions is conceptually and computationally demanding, and it was left open by Peel et al. [
3] how stable this procedure behaves when the degrees of freedom,
q, approach the value 1. This limiting case, at
, defines the
distribution, also known as a Cauchy distribution. The Cauchy and Gaussian models can be seen as opposite ends of the spectrum of possible
distributions, ranging from
to
, respectively. Hence, this manuscript aims to complete this spectrum by proposing a mixture of Cauchy distributions.
The Cauchy distribution has several interesting properties. While being a symmetric distribution, its mean does not exist. The Cauchy distribution is well known for its propensity to produce massive outliers [
4] and hence can deal with observations which might be considered unreasonable or pathological. Interestingly, such outliers, which may (or may not) materialize on either side of the distribution, with potentially wildly varying degree of outlyingness, can break the symmetry of the
observed data, despite the symmetry property of their generating distribution. Allowing additionally for heterogeneity of location parameters through a mixture model, as motivated above, enables the data analyst to deal with highly asymmetric data patterns.
Asymmetry is a fundamental problem in financial and economic data modeling. Many papers have suggested approaches for capturing asymmetry in financial data. An ensemble system based on neural networks to predict intraday volatility is presented in [
5]. A comparison of centrality metrics’ performance on stock market datasets was made in [
6]. The asymmetric impact of prices and volatilities of gold and oil on emerging markets was considered in [
7]. However, all of these approaches focus on certain notions of skewness or (non-)centrality to describe asymmetry, rather than accounting for outliers and heterogeneity explicitly through a mixture model as considered herein.
Mixture models are typically estimated through the Expectation-Maximization (EM) algorithm, which alternates between an E-step, in which one calculates, for each observation, probabilities of component membership, and an M-step, which maximizes an expected “complete” likelihood where these membership probabilities are assumed as fixed. This amounts, effectively, to the problem of maximizing a weighted version of the single-distribution likelihood. However, in the Cauchy case, this is not a trivial task. Even for the plain Cauchy model, the maximum likelihood estimator of the location parameter does usually not exist in analytical form, and, what is worse, the log likelihood itself suffers from the existence of inconsistent local maxima [
8]. However, it is well known that Cauchy parameters can be easily estimated through empirical quantiles of the data. The main objective of this paper is to investigate how this approach can be extended in order to fit Cauchy mixtures; using appropriately weighted quantiles in the Maximization step. It should be stated already now that, by following this line of thought, the resulting methodology will not constitute an EM-algorithm in the strict sense of its definition, and will not inherit its theoretical properties. Therefore, we use the weaker terminology EM-type to refer to this algorithm henceforth.
Of course, mixture models can also be used in conjunction with many other, discrete or continuous, or even mixed, distributions. More than half a century ago, foundations for estimating an extensive class of mixture models were laid by Boes [
9]. McLachlan and Peel [
10] presented a comprehensive account of finite mixture models and their properties. Contributions for specific distributions include, without claiming completeness, the work by Zhang et al. [
11] who studied a finite mixture Weibull distribution with two components to describe tree diameters for forest data, and Zaman et al. [
12] who studied chi-squared mixtures of the gamma distribution. Suksaengrakcharoen and Bodhisuwan [
13] proposed a mixture of generalized gamma and length biased generalized gamma distributions. Karim et al. [
14] studied mixtures of Rayleigh distributions by assuming that the weight functions follow chi-square, t and F sampling distributions. Sindhu and Feroze [
15] discussed parameter estimation of the Rayleigh mixture model using Bayesian methods. Applications of the mixture model are found in the environmental and natural sciences, education, psychology, business, and other fields.
This paper is organized as follows. In
Section 2, we discuss some preliminaries; specifically, in
Section 2.1, we explain the general concept of mixture models and the EM algorithm, and, in
Section 2.2, we recall the definition and properties of the Cauchy distribution. In
Section 3, we estimate the parameters of a Cauchy mixture model by applying an EM-type algorithm. The effectiveness of the proposed model is then demonstrated through simulated (
Section 4) and real data (
Section 5). In the last section, we contribute some remarks and present a conclusion.
3. An EM-Type Algorithm for the Cauchy Mixture Model
A (univariate) Cauchy mixture model is parameterized by two types of parameters; the component weights
of the mixture model, as well the component locations
and scale parameters
of the Cauchy distribution. For a Cauchy mixture model with
K components, the
jth component is parameterized by parameter vectors
. Together with the
, these component-specific vectors are bundled into the overall parameter vector
, as explained in
Section 2.1.
We assume that the data points
,
, are conditionally independent given the Cauchy mixture model with parameter vector
. In the notation of Equation (
3), the components
are now Cauchy densities.
Starting from some initial values, , we carry out iterative updates of . Each iteration consists of two steps: the expectation step (E-step) calculates the expectation of the component assignments for each data point according to current parameter estimates, while the maximization step (M-step) calculates a weighted estimator for model parameters given the expectations calculated in the E-step.
The steps to implement this algorithm are described in detail below.
The initializing step. Find initial parameter values, , as follows.
Set all prior component weight parameter estimates to the uniform distribution, ;
For the location parameters , do one of the following:
- i
find the empirical percentiles of the data, ;
- ii
draw a random sample of size K from the data;
- iii
place the values of , , symmetrically around the mean, in multiples of the standard deviation of the data D;
set all component scale parameter estimates to the half-interquartile range of the dataset, that is .
E-step. Using the current estimates
, compute the membership weights
of observations
as
M-step. Given the membership weights
from the E-step, we can use the data points to compute an updated parameter value. Let
, that is the sum of the membership weights for the
jth component. Then, the new estimate of the mixture weights is
The new estimates of location parameters are
where
is the cumulative sum of membership weights for component
j, that is the sum of all weights corresponding to observations which are less or equal than
x [
22].
The updated estimates of the scale parameters are
with
The current value of the log-likelihood,
, can be recorded by plugging
into Equation (
3). The E-step and the M-step are iterated until some pre-specified criterion is met. We do not advise to base this criterion on the difference between
values of two consecutive iterations. Firstly, this method has attracted some general criticism in the literature (being a measure of “lack of progress” rather than actual convergence [
23]). Secondly, since our estimates in the M-step are only approximations of the MLEs, we lose the theoretical guarantee of monotonicity and convergence that EM theory would otherwise have provided. Indeed, we have observed in some examples (illustrated in
Section 5) that, especially in the case
but sometimes also for
, the likelihood trajectories may be slightly decreasing for short sequences of iterations. Hence, for these reasons, the recommendation is to work with a fixed number,
S, of iterations (
has been sufficient in all examples and simulations considered), and chose subsequently the
best solution along this path (in terms of likelihood), rather than the final (“converged”) one.
4. Simulation Study
To assess the performance of the estimation procedure, a simulation study was carried out with different parameter settings. In what follows, we denote by , and the given, known, parameter vectors of size K of the respective simulation scenario, which we consider for ease of presentation as row vectors.
We consider three scenarios as follows:
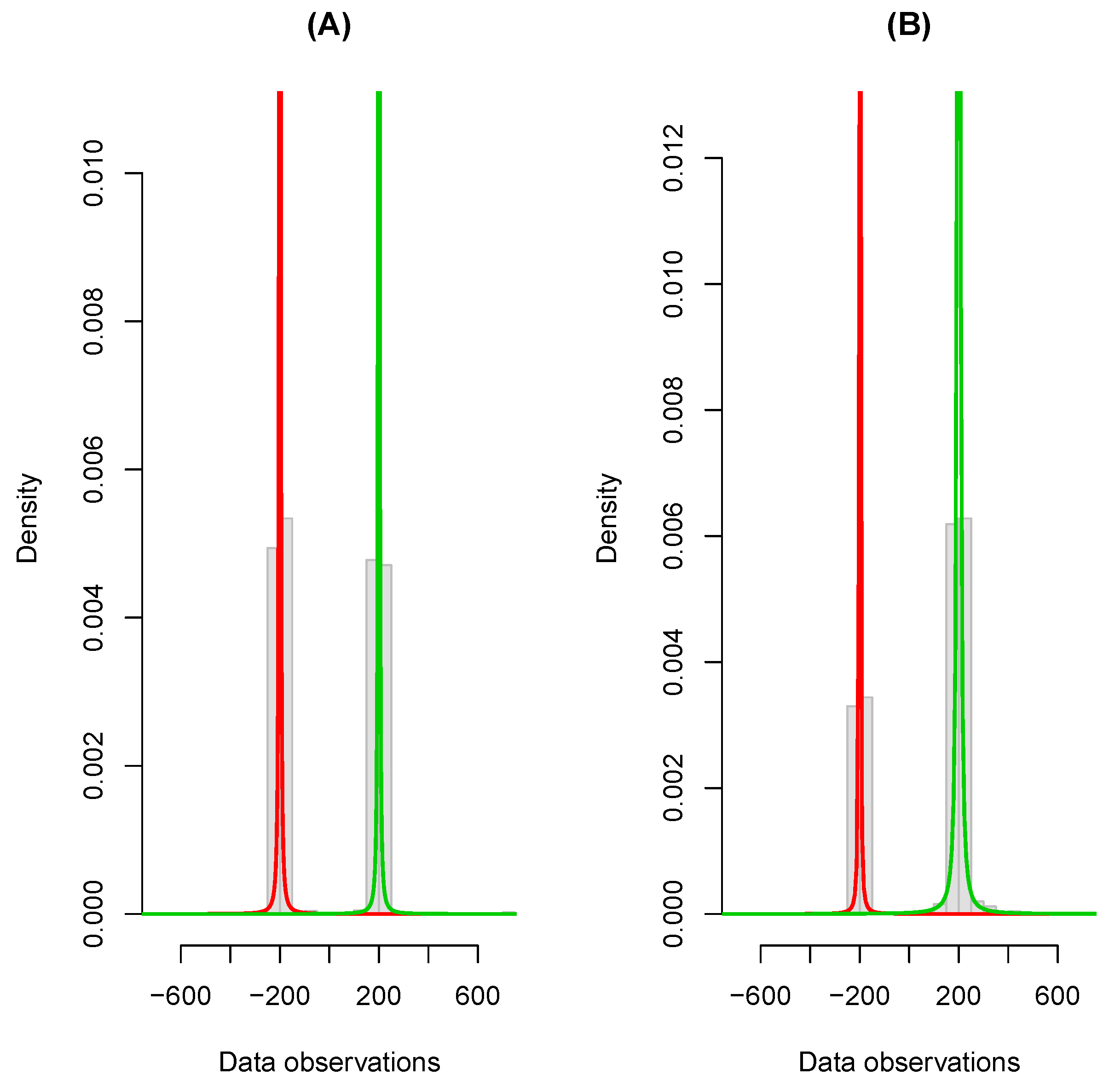
- (A)
a two-component Cauchy mixture model with mixing parameters equal to , location parameters and scale parameters ;
- (B)
a two-component Cauchy mixture model with mixing parameters equal to , location parameters and scale parameters ; and
- (C)
a four-component Cauchy mixture with , , .
To illustrate the data scenarios, we initially sampled
observations from each dataset. Histograms of the generated data for Scenarios A and B are given in
Figure 1, along with the fitted Cauchy mixtures. The corresponding outcome for Scenario C is provided in
Figure 2.
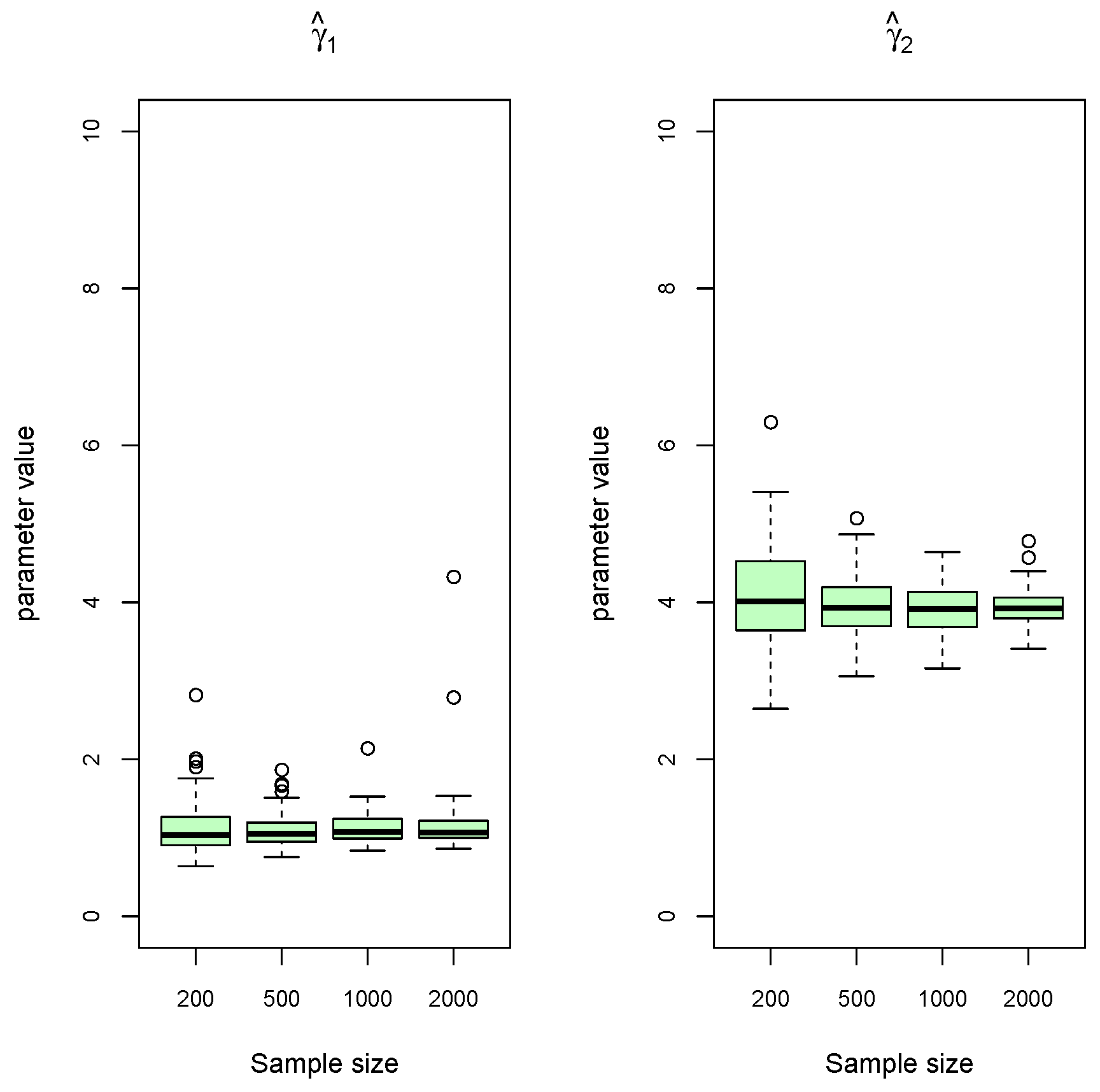
We next carroed out the actual simulation study in order to study the consistency properties of the proposed estimators. For each simulation scenario, we considered sample sizes of
and 2000; moreover, we replicated the process 200 times for each simulated mixture model. For the initialization of location parameters as described in
Section 3, we used Setting (iii) throughout.
For each model parameter, we produced box plots from the 200 estimates and display the results in
Figure 3,
Figure 4,
Figure 5 and
Figure 6. We see that the estimates become more accurate and precise as the sample size increases. There is no evidence to suggest that the estimation problem for unequal mixture probabilities and scale parameters (Scenario B) is much harder than for equal probabilities and scale parameters (Scenario A). Consistency also does not appear to be negatively affected when increasing
K (Scenario C).
6. Discussion and Conclusions
The Cauchy mixture provides a suitable model to fit heterogeneous data with outliers. The estimates of model parameters are successfully obtained using an EM-type algorithm, which cycles between the computation of component membership weights using Bayes’ theorem, and the update of component parameters using appropriately weighted quantiles.
Through experimental results, we have shown that the proposed methodology provides sensible model fits, with the estimated location parameters always centered at the data peaks, and which are robust to the presence of the extreme values. We also observed that Cauchy mixtures tend to need less components than Gaussian mixtures in order to achieve a comparable goodness-of-fit.
The properties of the algorithm deserve further discussion. As mentioned above, our M-step does not maximize the expected complete log-likelihood, and there is no mathematical guarantee that it moves the estimated parameters into the direction of its gradient. Indeed, we did observe at some occasions (especially for
) that both the expected complete likelihood, as well as the incomplete data likelihood slightly decrease for a few iterations (that is, the disparities increase), before returning into the direction of the original trend, and eventually always settling into convergence. While the temporary decrease of the expected complete log-likelihood is not a concern (this can happen in every EM algorithm), the decrease of the likelihood itself is more of an issue, as it lays bare the fact that our methodology is not strictly an EM algorithm [
30]. EM algorithms with this rather undesired property have sometimes been referred to as “pseudo-EM” in the literature; we prefer the simpler term “EM-type”. Despite not being strictly an EM algorithm, the methodology has demonstrated to behave convincingly in application and simulation, with excellent robustness properties. From this perspective, one may speculate that a certain resistance of the methodology to “always following the gradient of the likelihood” may in fact be desirable, and it is in this spirit that our method behaves. Further theoretical analysis of these issues appears desirable for future work.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}