Supervised Reinforcement Learning via Value Function


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. RL Based on Value Function
2.2. Combining Expert Samples and RL Based on Value Function
3. Background
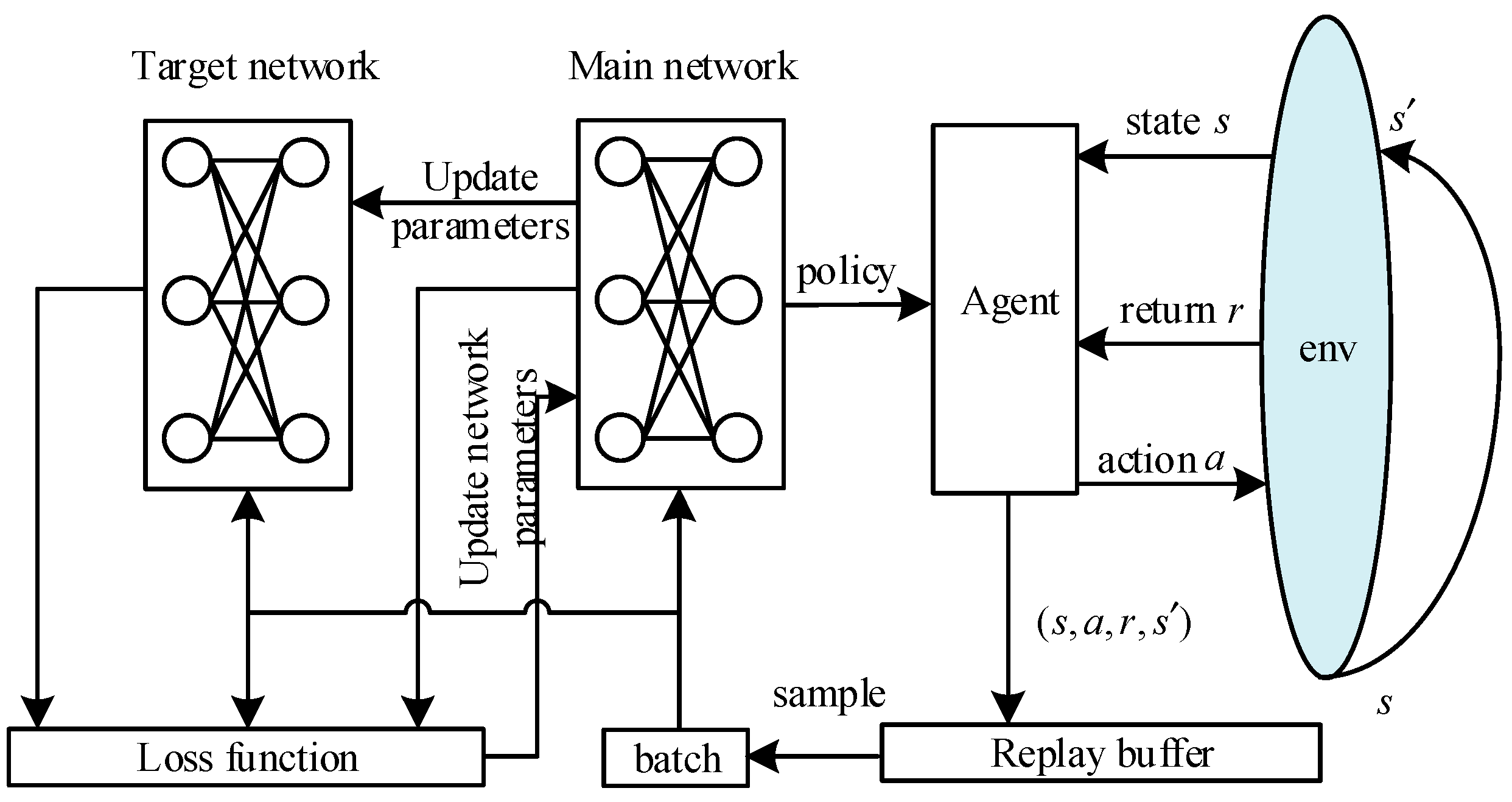
3.1. Reinforcement Learning via Value Function
3.2. Supervised Learning
4. Our Method
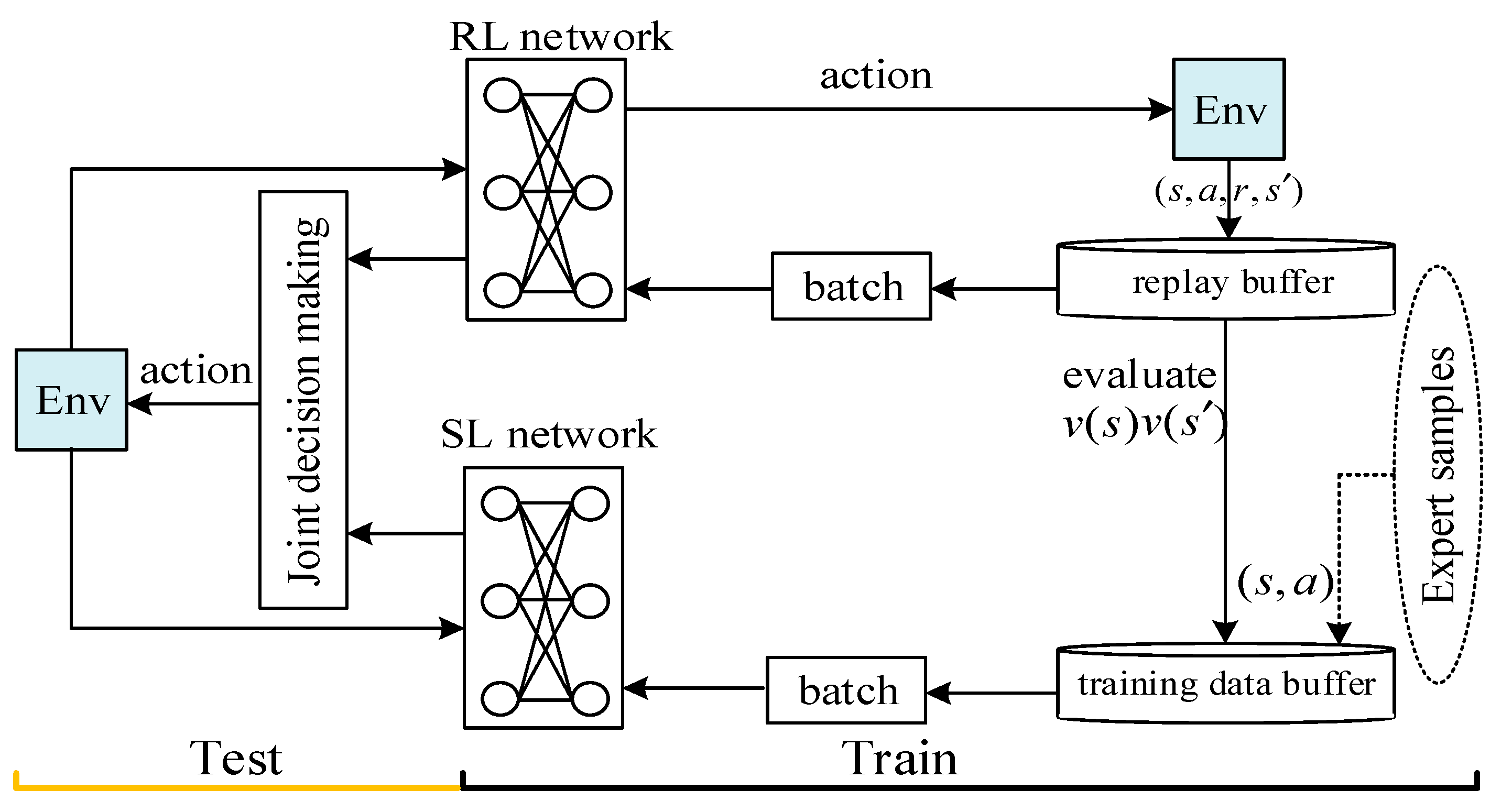
4.1. Supervised Reinforcement Learning via Value Function
4.2. Demonstration Sets for the SL Network
4.3. Generalization of SRLVF
5. Experiments
5.1. Experimental Setup
Algorithm and Hyperparameter
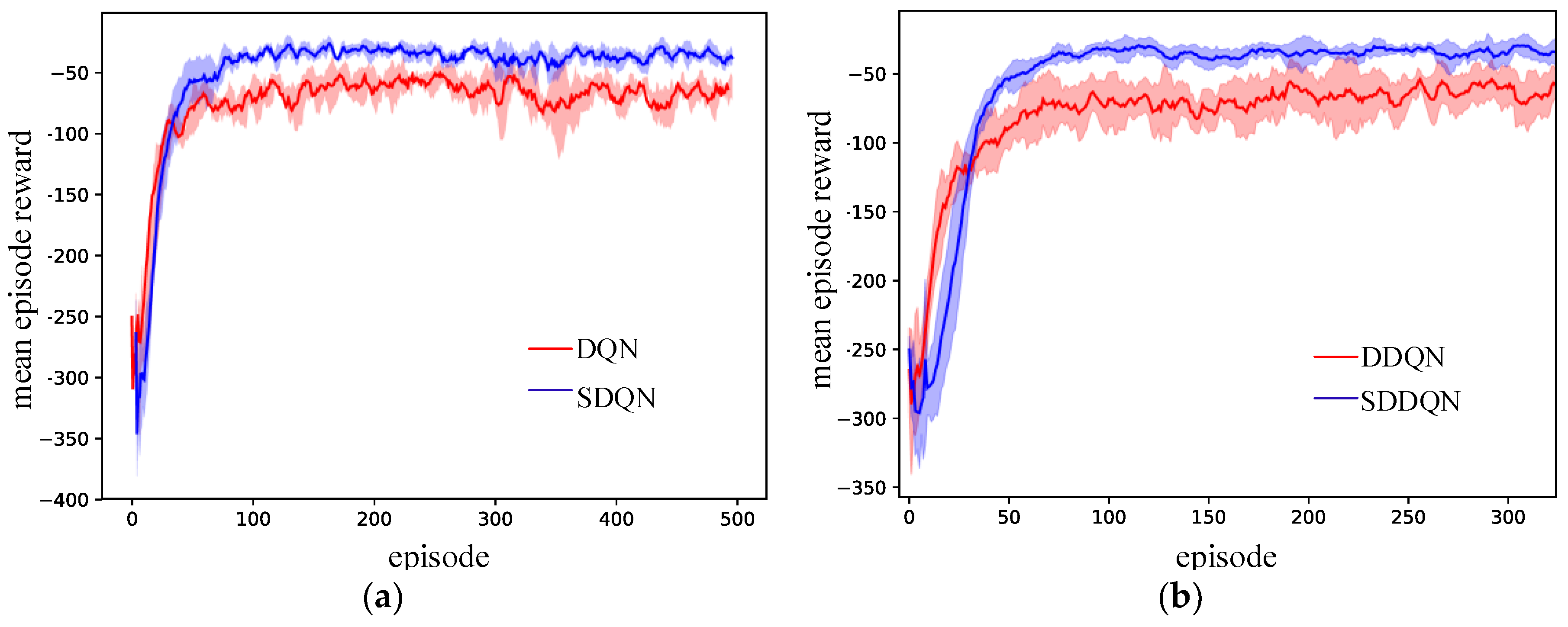
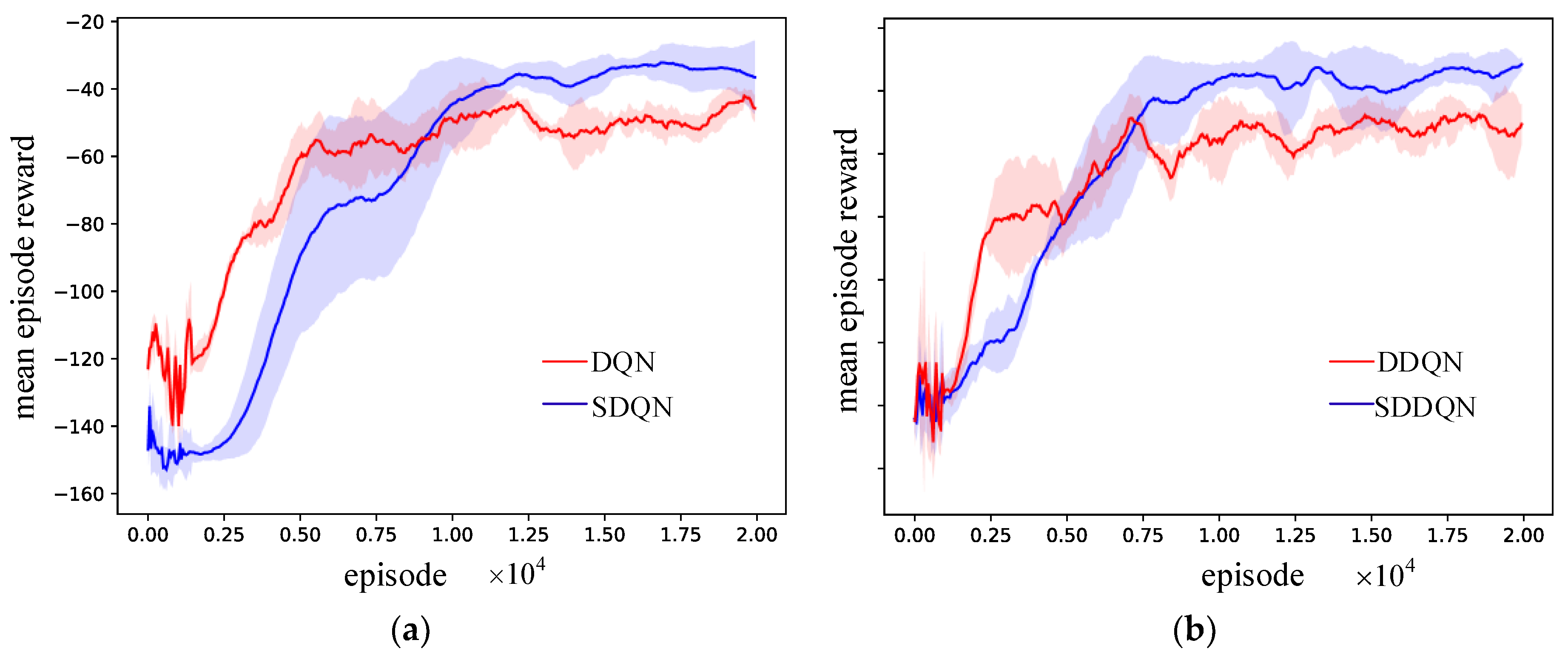
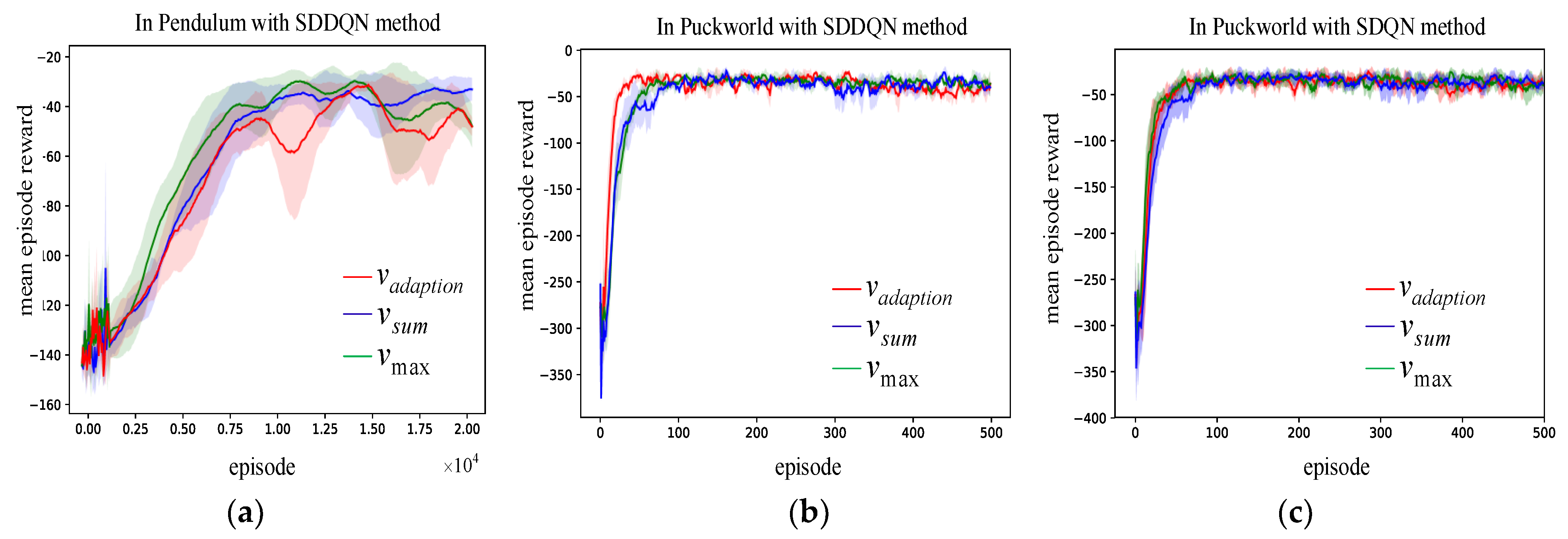
5.2. Result and Analysis
5.2.1. Testing the Performance of the SRLVF Method
5.2.2. Evaluating the Impact of Different Calculation Methods on the Performance of SRLVF
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A
| Algorithm 1 Supervised Reinforcement Learning via Value Function |
| Initialize environment, agent |
| or episode = 1 to max_episode do |
| for step = 1 to max_step do |
| ← agent execute a at state s |
| in replay buffer D |
| sample minibatch from D |
| update the RL network by RL algorithm |
| if then |
| in train data buffer T |
| end if |
| sample minibatch from T |
| update the SL network |
| end for |
| end for |
References
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. Available online: https://arxiv.org/pdf/1312.5602 (accessed on 15 March 2019).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A. Mastering the game of go without human knowledge. Nature 2017, 550, 354. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Oh, J.; Guo, X.; Lee, H.; Lewis, R.L.; Singh, S. Action-conditional video prediction using deep networks in atari games. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, ON, Canada, 7–12 December 2015; pp. 2863–2871. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Tesauro, G.; Das, R.; Chan, H.; Kephart, J.; Levine, D.; Rawson, F.; Lefurgy, C. Managing power consumption and performance of computing systems using reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. Available online: https://arxiv.org/pdf/1611.01578 (accessed on 15 March 2019).
- Duan, Y.; Schulman, J.; Chen, X.; Bartlett, P.L.; Sutskever, I.; Abbeel, P. RL2: Fast Reinforcement Learning via Slow Reinforcement Learning. Available online: https://arxiv.org/pdf/1611.02779 (accessed on 15 March 2019).
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming exploration in reinforcement learning with demonstrations. Available online: https://arxiv.org/pdf/1709.10089 (accessed on 15 March 2019).
- Lakshminarayanan, A.S.; Ozair, S.; Bengio, Y. Reinforcement learning with few expert demonstrations. In Proceedings of the NIPS Workshop on Deep Learning for Action and Interaction, Barcelona, Spain, 10 December 2016. [Google Scholar]
- Zhang, X.; Ma, H. Pretraining deep actor-critic reinforcement learning algorithms with expert demonstrations. Available online: https://arxiv.org/pdf/1801.10459 (accessed on 15 March 2019).
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I. Deep q-learning from demonstrations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cruz, G.V., Jr.; Du, Y.; Taylor, M.E. Pre-training neural networks with human demonstrations for deep reinforcement learning. Available online: https://arxiv.org/pdf/1709.04083 (accessed on 15 March 2019).
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. Available online: https://arxiv.org/pdf/1709.10087 (accessed on 15 March 2019).
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; Springer Science & Business Media: Berlin, Germany, 1992. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. Available online: https://arxiv.org/pdf/1511.06581 (accessed on 15 March 2019).
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Lipton, Z.C.; Gao, J.; Li, L.; Li, X.; Ahmed, F.; Deng, L. Efficient Exploration for Dialog Policy Learning with Deep BBQ Networks & Replay Buffer Spiking. Available online: https://arxiv.org/pdf/1608.05081 (accessed on 15 March 2019).
- Li, Y. Deep reinforcement learning: An overview. Available online: https://arxiv.org/pdf/1701.07274 (accessed on 15 March 2019).
- Van Otterlo, M.; Wiering, M. Reinforcement Learning and Markov Decision Processes. Reinforc. Learn. 2012, 12, 3–42. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. Nature 2015, 518, 529–533. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Ye, Q. Reinforce. Available online: https://github.com/qqiang00/reinforce (accessed on 15 March 2019).






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Y.; Zhang, J.; Yuan, C.; Yang, H. Supervised Reinforcement Learning via Value Function. Symmetry 2019, 11, 590. https://doi.org/10.3390/sym11040590
Pan Y, Zhang J, Yuan C, Yang H. Supervised Reinforcement Learning via Value Function. Symmetry. 2019; 11(4):590. https://doi.org/10.3390/sym11040590
Chicago/Turabian StylePan, Yaozong, Jian Zhang, Chunhui Yuan, and Haitao Yang. 2019. "Supervised Reinforcement Learning via Value Function" Symmetry 11, no. 4: 590. https://doi.org/10.3390/sym11040590