Improving Accuracy of the Kalman Filter Algorithm in Dynamic Conditions Using ANN-Based Learning Module


Abstract
:1. Introduction
2. Related Work
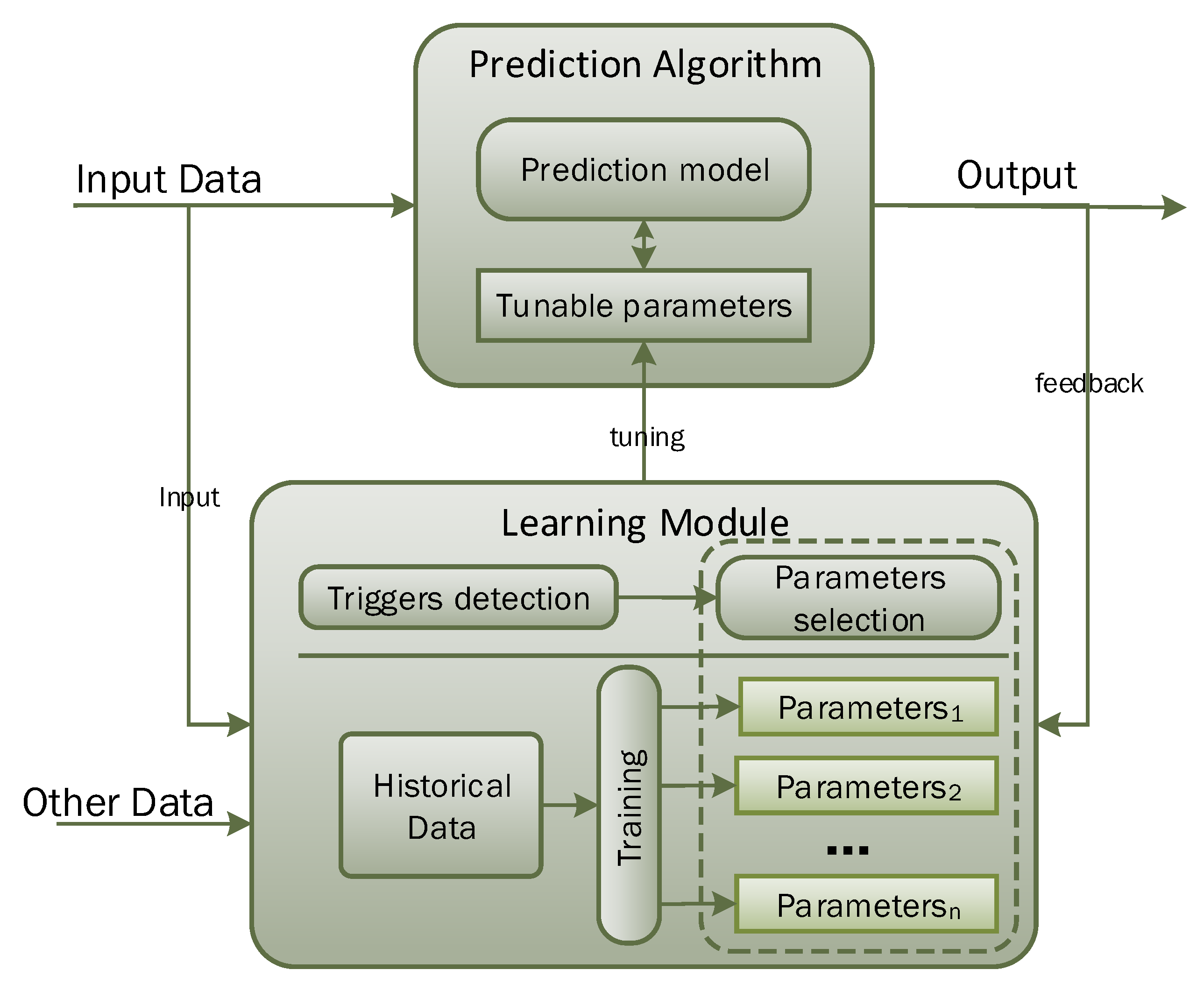
3. Proposed Learning to Prediction Scheme
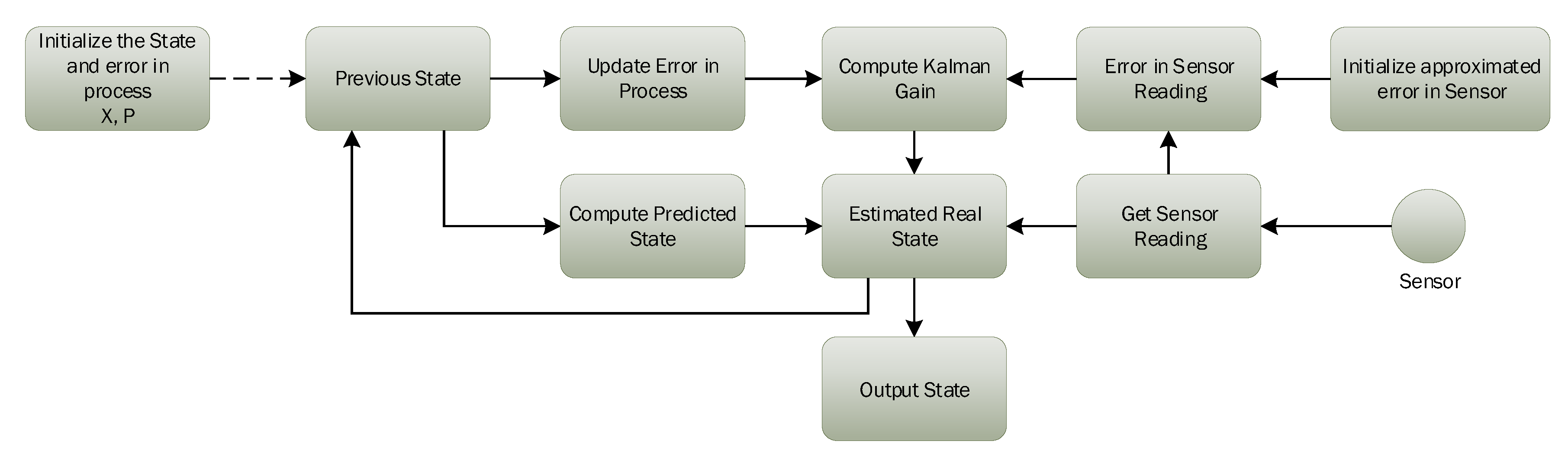
3.1. Kalman Filter Algorithm
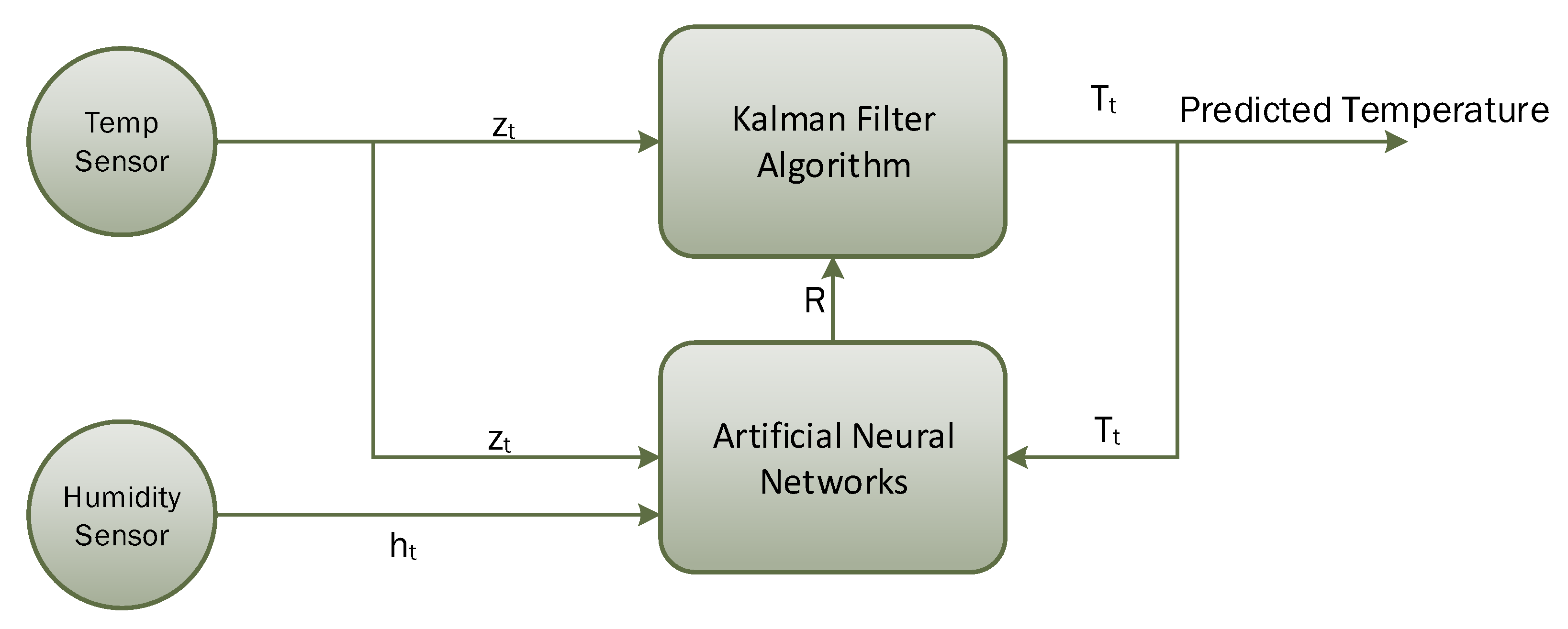
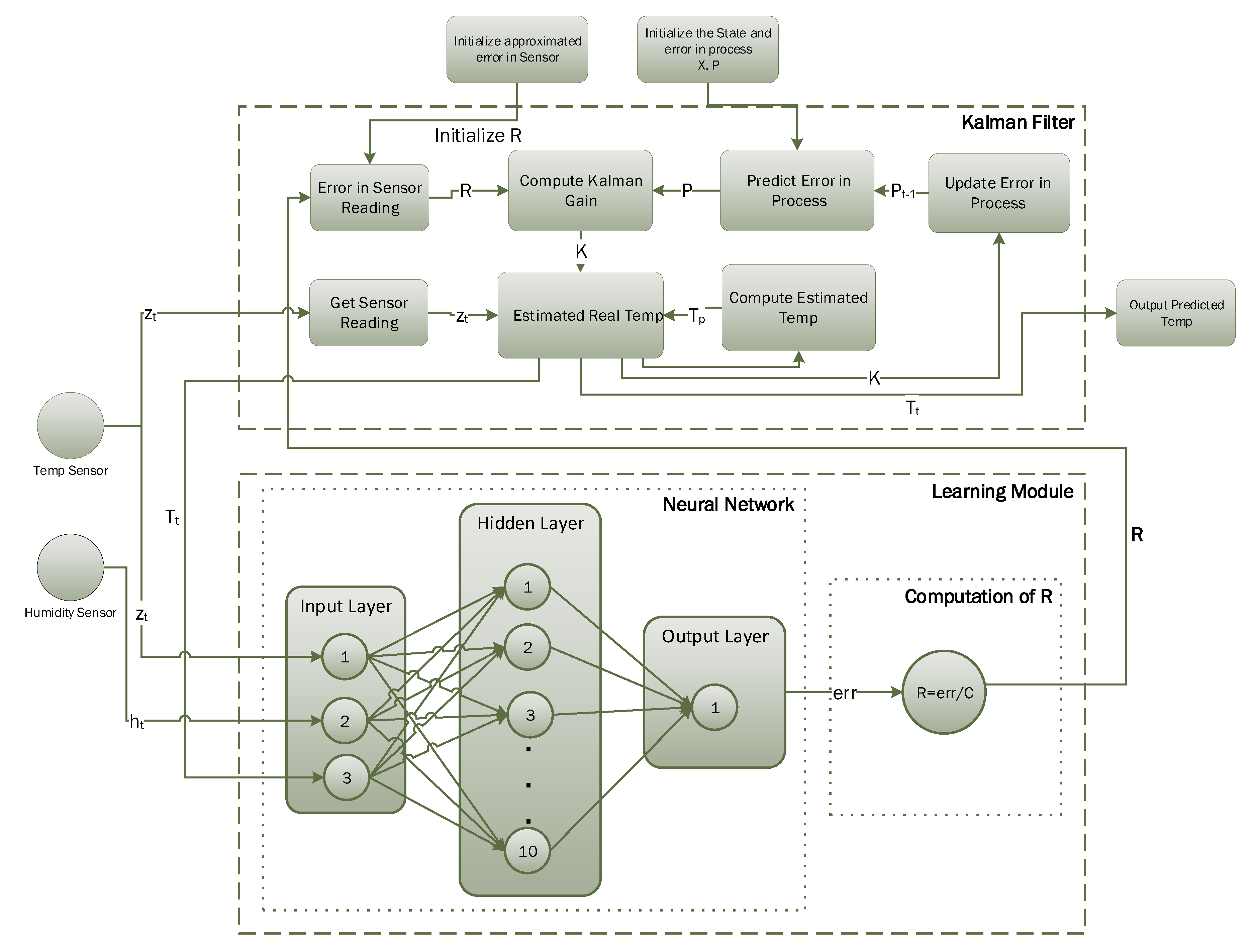
3.2. ANN-Based Learning to Prediction for the Kalman Filter
4. Experimental Results and Discussion
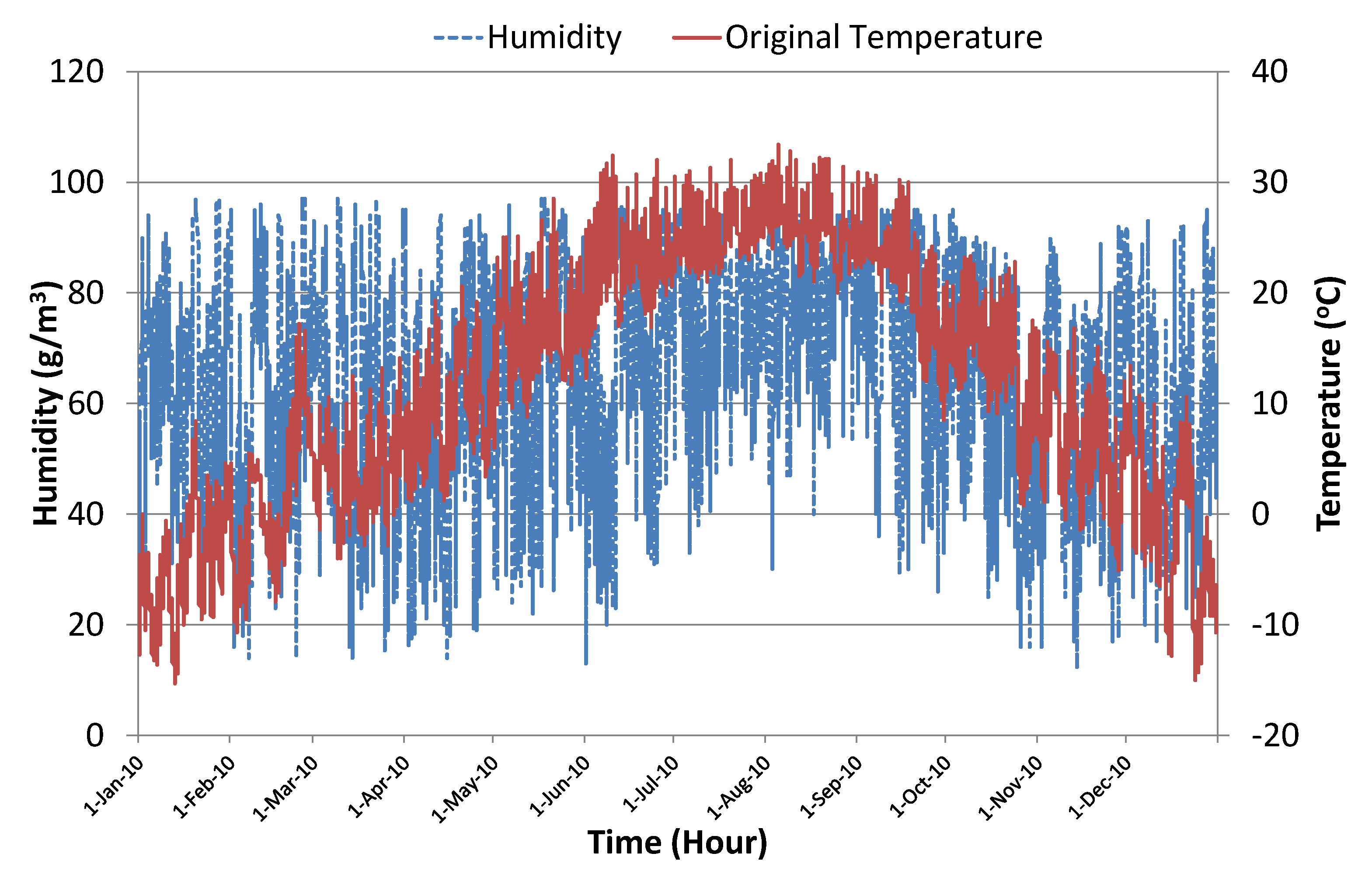
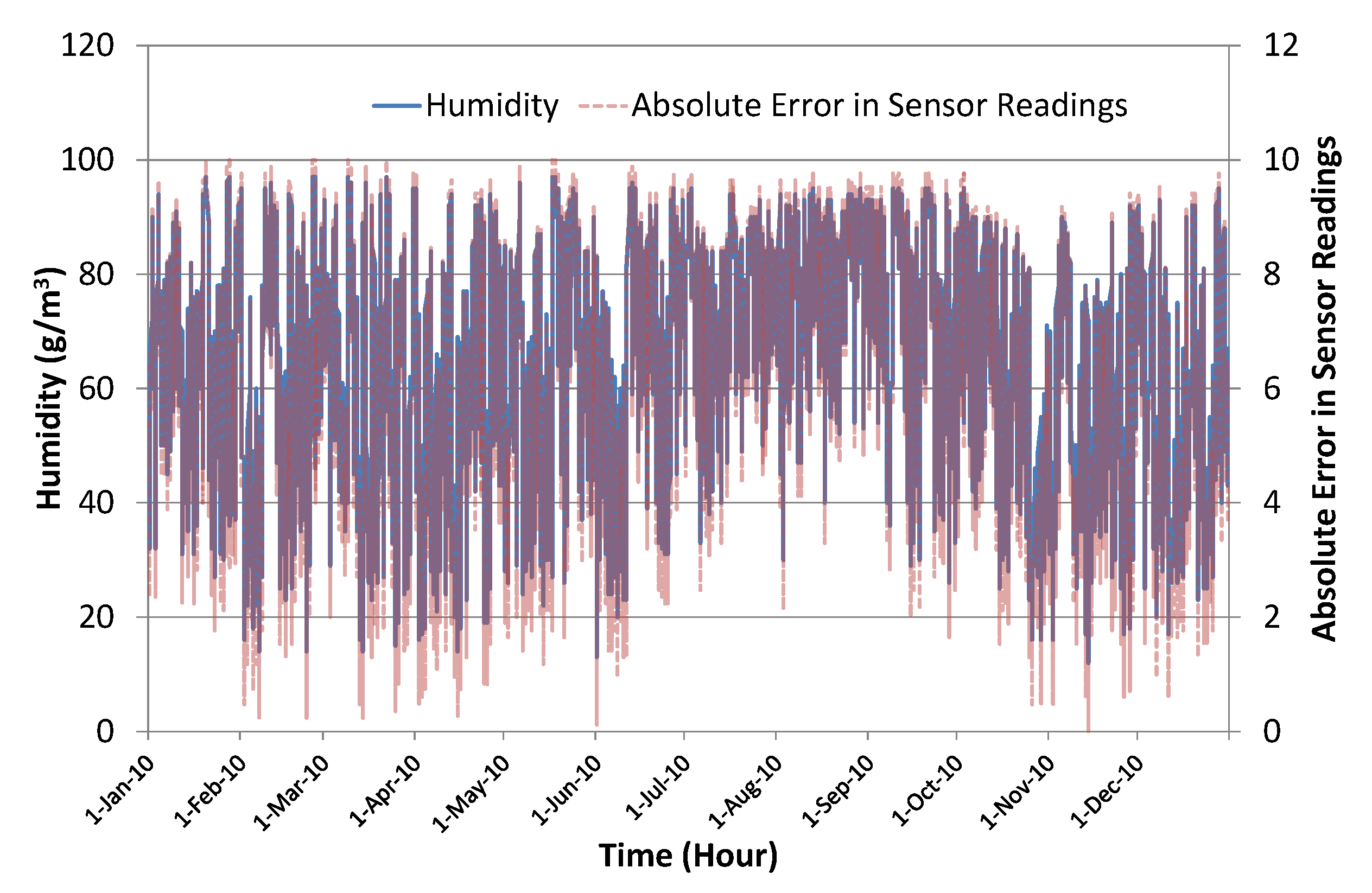
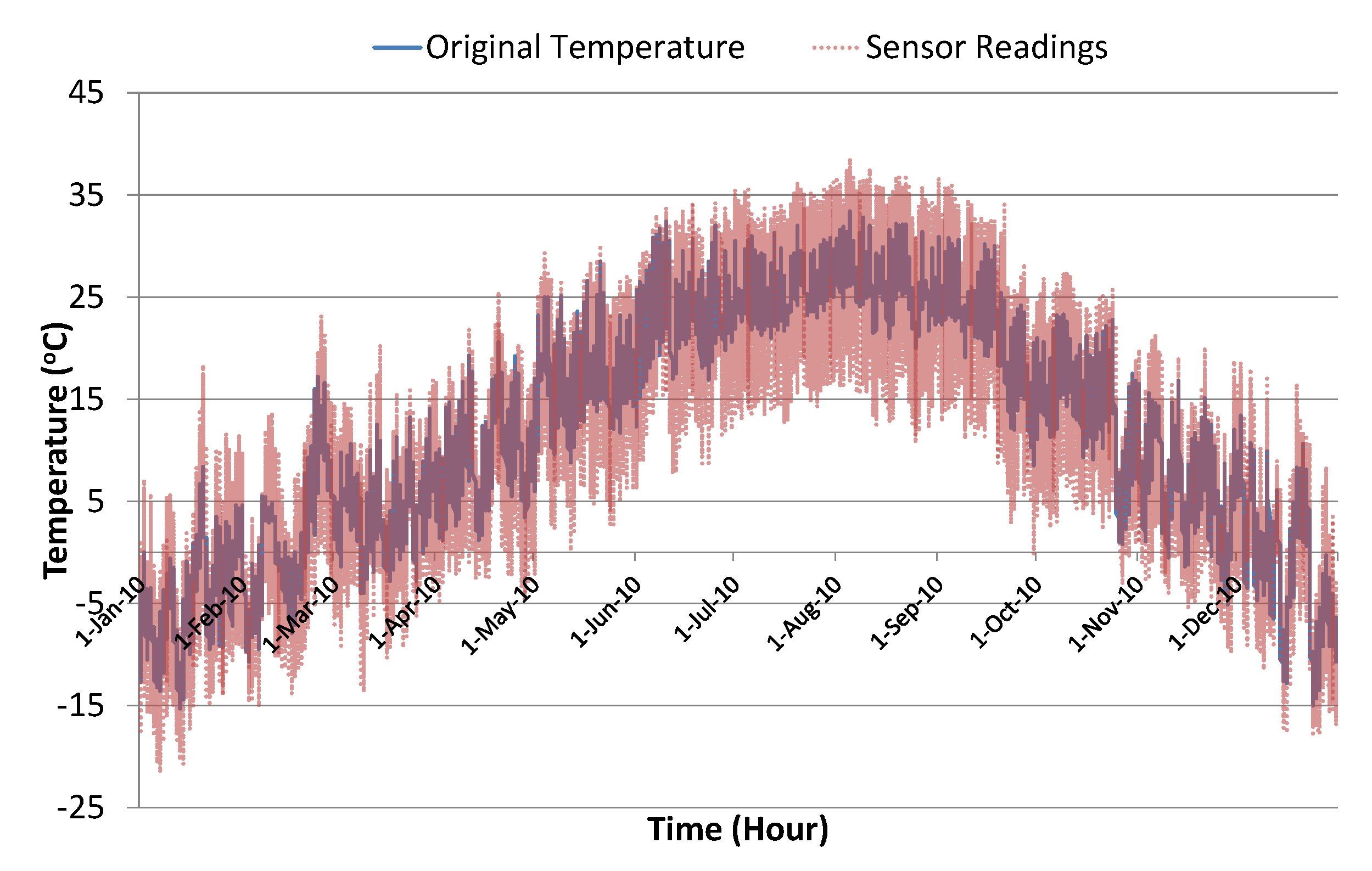
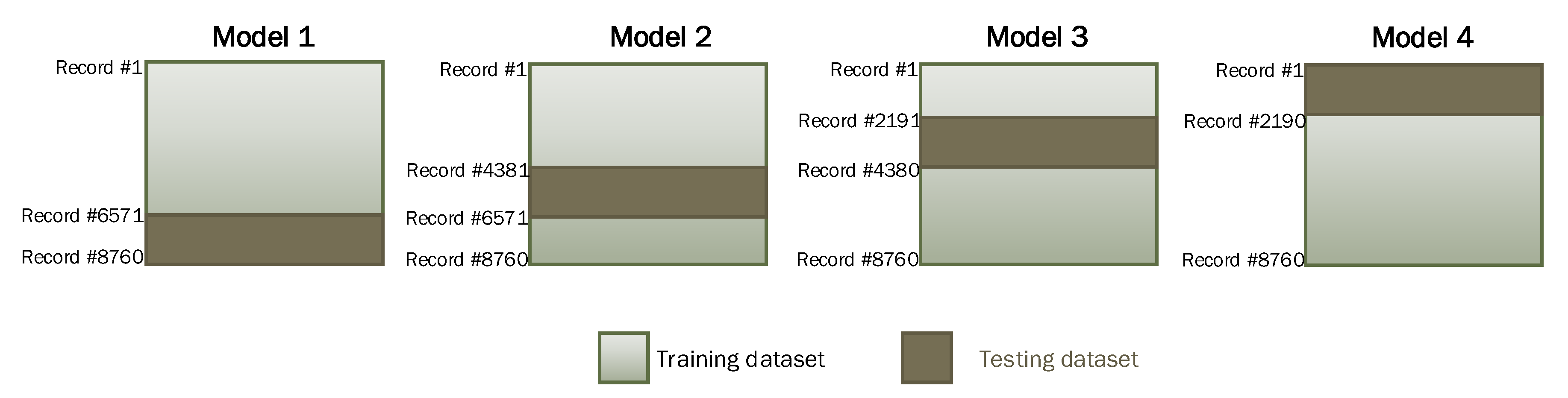
4.1. Experimental Setup
4.2. Implementation
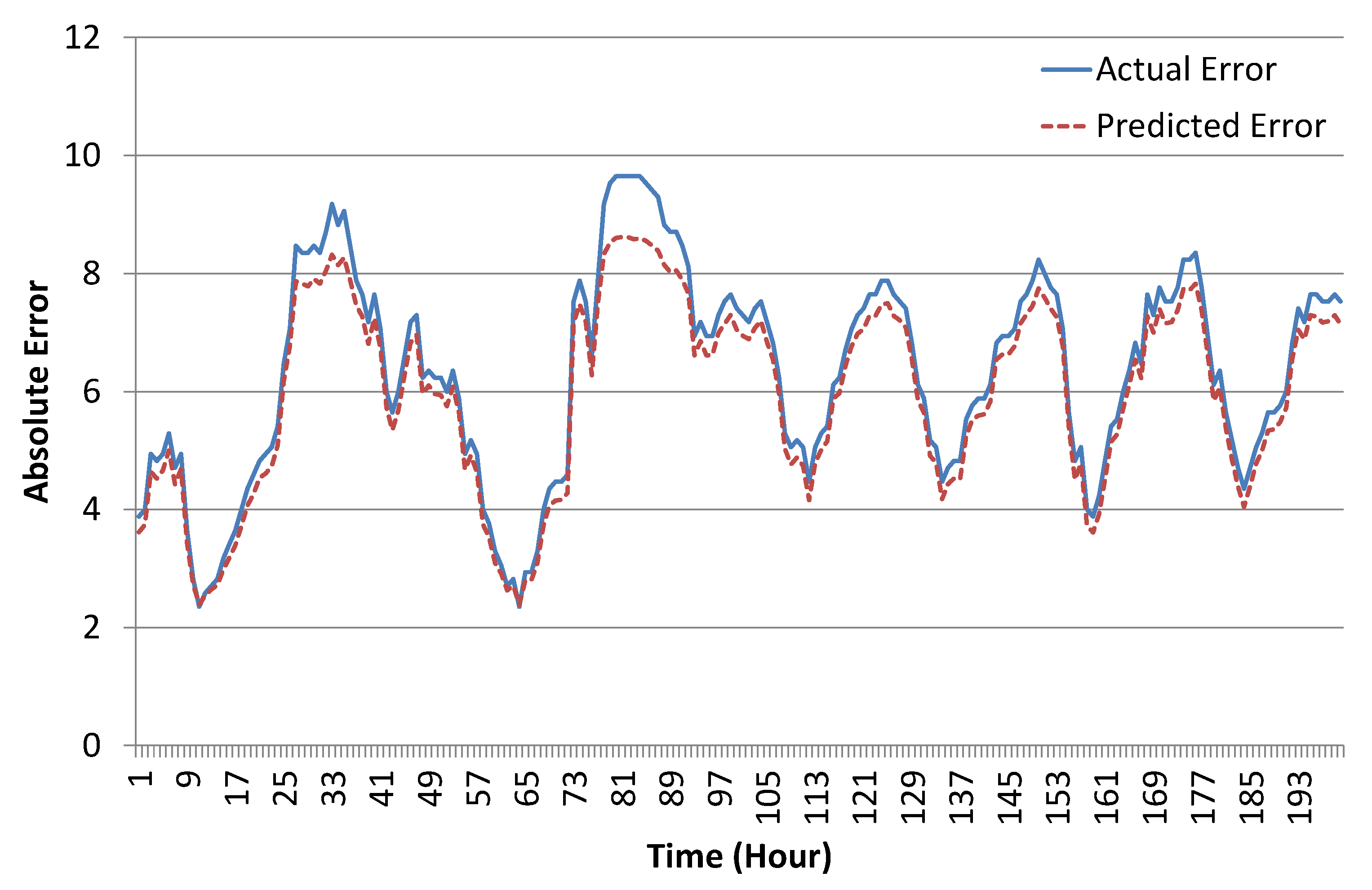
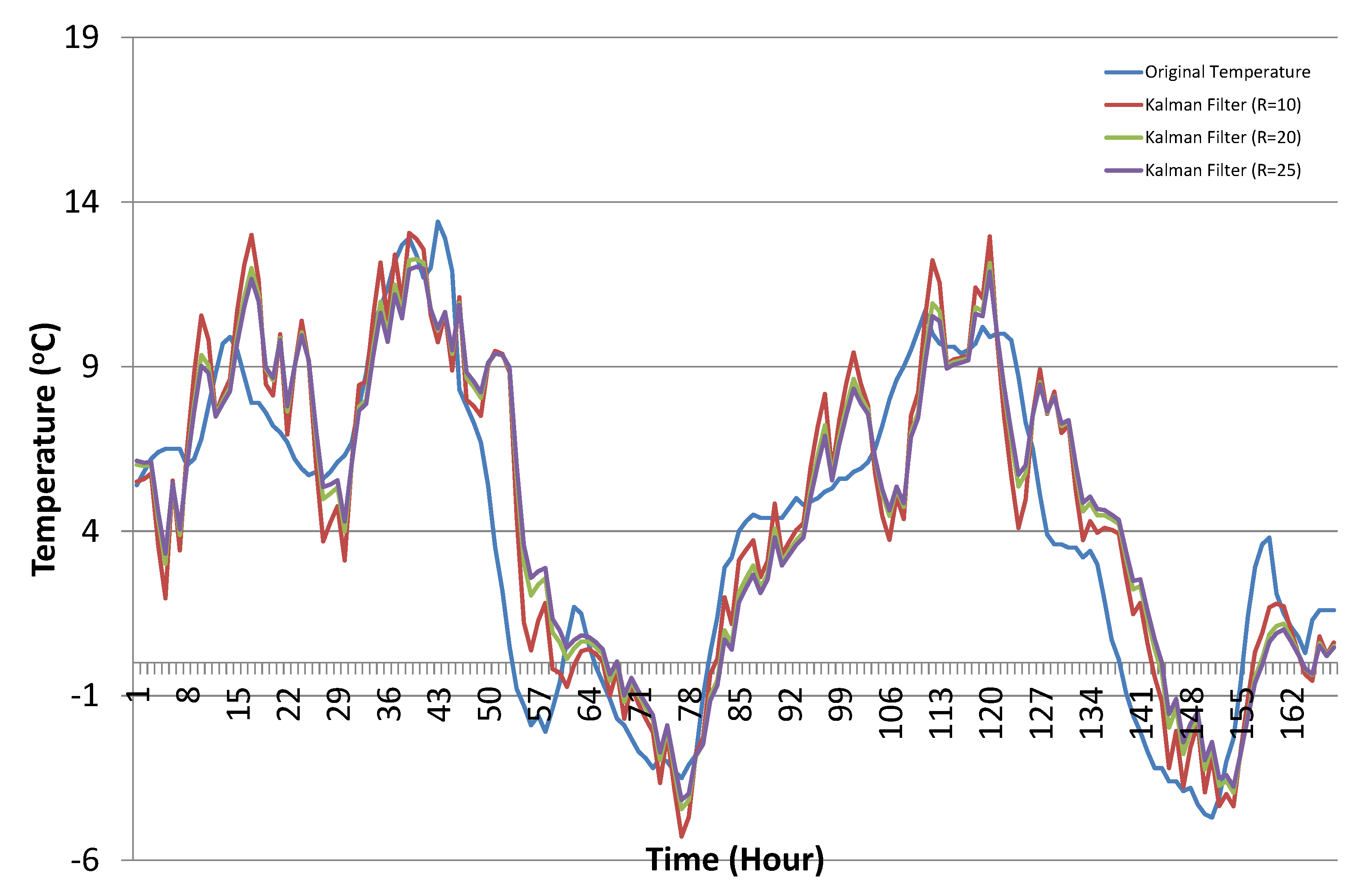
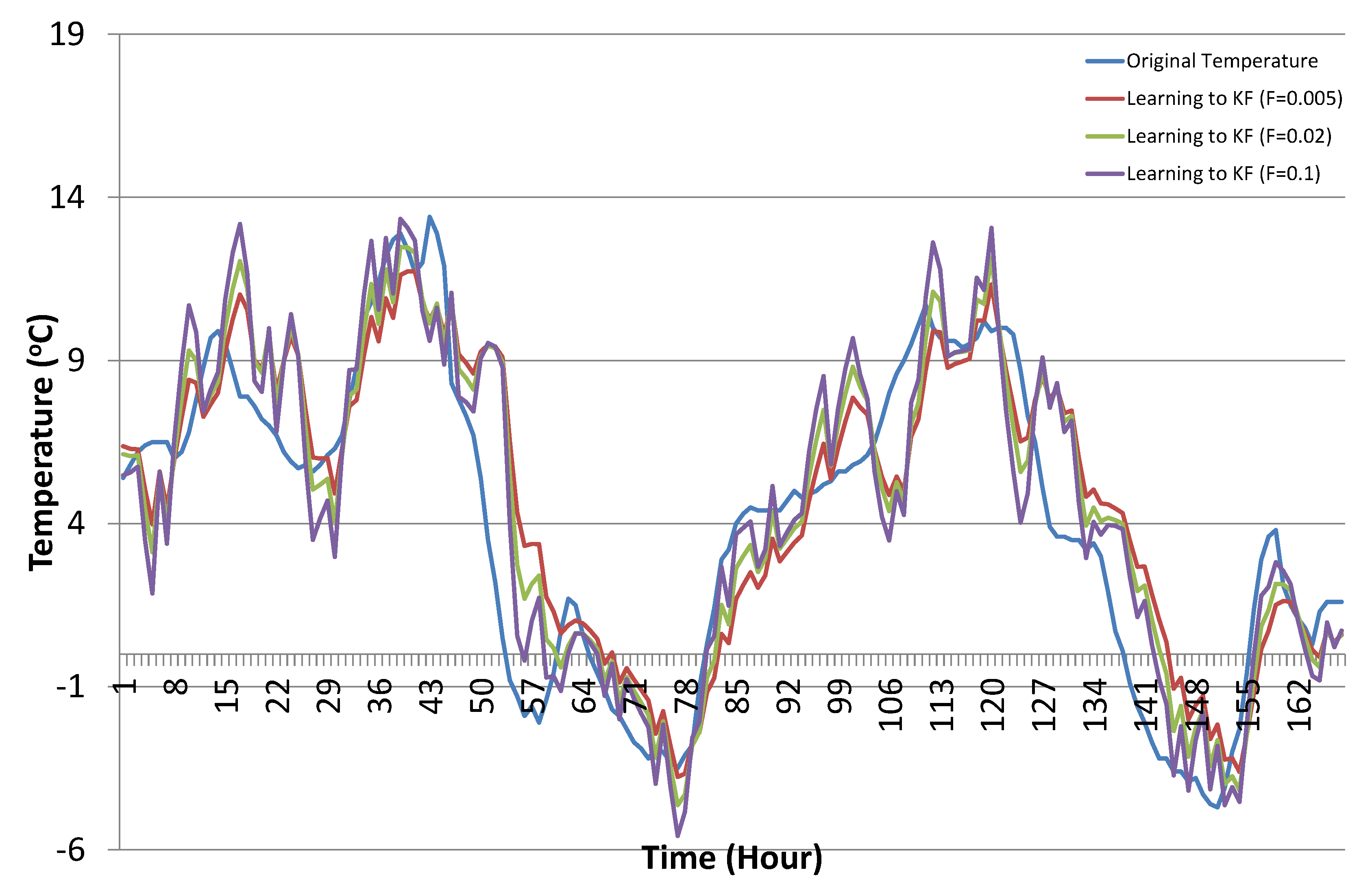
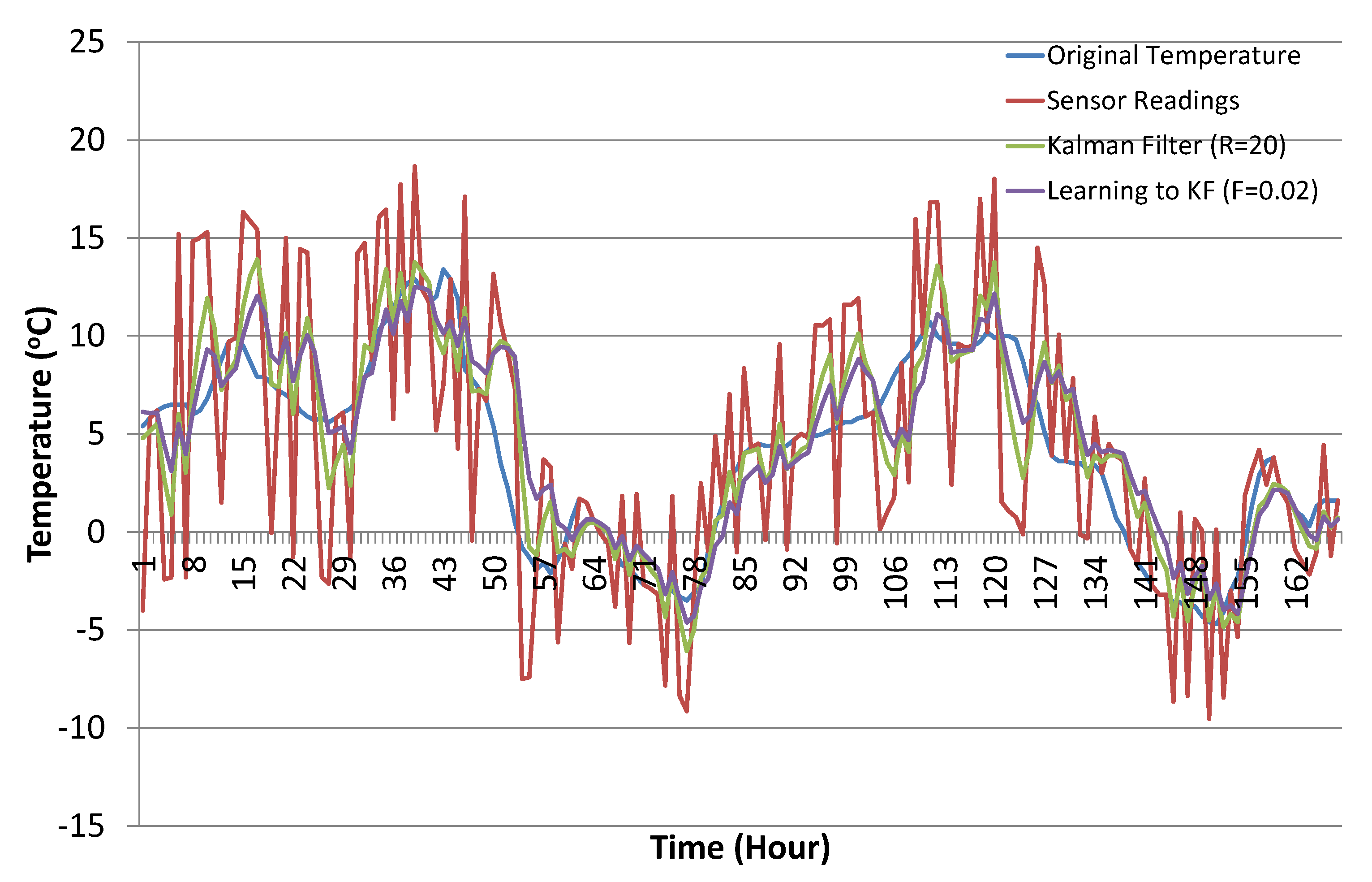
4.3. Results and Discussion
- Mean absolute deviation (MAD): This measure is used to compute an average deviation found in predicted values from actual values. MAD is calculated by dividing the sum of absolute differences between the actual temperature and predicted temperature by the Kalman filter with the total number of data items, i.e., n.
- Mean squared error (MSE): MSE is considered the most widely-used statistical measure in the performance evaluation of prediction algorithms. Squaring the error magnitude not only removes the negative and positive error problems, but it also gives more penalty for higher mispredictions as compared to low errors. The MSE is calculated using the following formula.
- Root mean squared error (RMSE): The problem with MSE is that it magnifies the actual error, which sometimes makes it difficult to realize and comprehend the actual error amount. This problem is resolved by the RMSE measure, which is obtained by simply taking the square root of MSE.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Carpenter, M.; Erdogan, B.; Bauer, T. Principles of Management. Flat World Knowledge. Inc. USA 2009, 2, 424. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Kuala Lumpur, Malaysia, 2016. [Google Scholar]
- Pomerol, J.C. Artificial intelligence and human decision making. Eur. J. Oper. Res. 1997, 99, 3–25. [Google Scholar] [CrossRef]
- Weigend, A.S. Time Series Prediction: Forecasting the Future and Understanding the Past; Routledge: Abington, UK, 2018. [Google Scholar]
- Xu, L.; Lin, W.; Kuo, C.C.J. Fundamental Knowledge of Machine Learning. In Visual Quality Assessment by Machine Learning; Springer: Berlin, Germany, 2015; pp. 23–35. [Google Scholar]
- Rajagopalan, B.; Lall, U. A k-nearest-neighbor simulator for daily precipitation and other weather variables. Water Resour. Res. 1999, 35, 3089–3101. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues 2012, 9, 272. [Google Scholar]
- Zhang, Z. Artificial neural network. In Multivariate Time Series Analysis in Climate and Environmental Research; Springer: Berlin, Germany, 2018; pp. 1–35. [Google Scholar]
- Zhou, Z.H.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef]
- Hu, Y.H.; Palreddy, S.; Tompkins, W.J. A patient-adaptable ECG beat classifier using a mixture of experts approach. IEEE Trans. Biomed. Eng. 1997, 44, 891–900. [Google Scholar]
- Yates, D.; Gangopadhyay, S.; Rajagopalan, B.; Strzepek, K. A technique for generating regional climate scenarios using a nearest-neighbor algorithm. Water Resour. Res. 2003, 39. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.L.; Zhou, Z.H. A k-nearest neighbor based algorithm for multi-label classification. In Proceedings of the 2005 IEEE International Conference on Granular Computing, Beijing, China, 25–27 July 2005; Volume 2, pp. 718–721. [Google Scholar]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Suthaharan, S. Decision tree learning. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin, Germany, 2016; pp. 237–269. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: Abington, UK, 2017. [Google Scholar]
- Slocum, M. Decision making using id3 algorithm. Insight River Acad. J 2012, 8, 2. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: New York, NY, USA, 2014. [Google Scholar]
- Van Diepen, M.; Franses, P.H. Evaluating chi-squared automatic interaction detection. Inf. Syst. 2006, 31, 814–831. [Google Scholar] [CrossRef]
- Batra, M.; Agrawal, R. Comparative analysis of decision tree algorithms. In Nature Inspired Computing; Springer: Berlin, Germany, 2018; pp. 31–36. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks:: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Merkel, G.; Povinelli, R.; Brown, R. Short-term load forecasting of natural gas with deep neural network regression. Energies 2018, 11, 2008. [Google Scholar] [CrossRef]
- Baykan, N.A.; Yılmaz, N. A mineral classification system with multiple artificial neural network using k-fold cross validation. Math. Comput. Appl. 2011, 16, 22–30. [Google Scholar] [CrossRef]
- Genikomsakis, K.N.; Lopez, S.; Dallas, P.I.; Ioakimidis, C.S. Simulation of wind-battery microgrid based on short-term wind power forecasting. Appl. Sci. 2017, 7, 1142. [Google Scholar] [CrossRef]
- Afolabi, D.; Guan, S.U.; Man, K.L.; Wong, P.W.; Zhao, X. Hierarchical Meta-Learning in Time Series Forecasting for Improved Interference-Less Machine Learning. Symmetry 2017, 9, 283. [Google Scholar] [CrossRef]
- Sathyanarayana, S. A gentle introduction to backpropagation. Numeric Insight 2014, 7, 1–15. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. AAAI 2015, 333, 2267–2273. [Google Scholar]
- Zhang, X.; LeCun, Y. Text understanding from scratch. arXiv, 2015; arXiv:1502.01710. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Chang, F.J.; Chang, Y.T. Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv. Water Resour. 2006, 29, 1–10. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef] [Green Version]
- Jacobs, R.A. Methods for combining experts’ probability assessments. Neural Comput. 1995, 7, 867–888. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Kang, C.W.; Park, C.G. Attitude estimation with accelerometers and gyros using fuzzy tuned Kalman filter. In Proceedings of the 2009 European Control Conference (ECC), Budapest, Hungary, 23–26 August 2009; pp. 3713–3718. [Google Scholar]
- Ibarra-Bonilla, M.N.; Escamilla-Ambrosio, P.J.; Ramirez-Cortes, J.M. Attitude estimation using a Neuro-Fuzzy tuning based adaptive Kalman filter. J. Intell. Fuzzy Syst. 2015, 29, 479–488. [Google Scholar] [CrossRef]
- Rong, H.; Peng, C.; Chen, Y.; Zou, L.; Zhu, Y.; Lv, J. Adaptive-Gain Regulation of Extended Kalman Filter for Use in Inertial and Magnetic Units Based on Hidden Markov Model. IEEE Sens. J. 2018, 18, 3016–3027. [Google Scholar] [CrossRef]
- Havlík, J.; Straka, O. Performance evaluation of iterated extended Kalman filter with variable step-length. J. Phys. Conf. Ser. 2015, 659, 012022. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; McBratney, A.B.; Minasny, B.; Triantafilis, J. Monitoring and modelling soil water dynamics using electromagnetic conductivity imaging and the ensemble Kalman filter. Geoderma 2017, 285, 76–93. [Google Scholar] [CrossRef]
- Połap, D.; Winnicka, A.; Serwata, K.; Kęsik, K.; Woźniak, M. An Intelligent System for Monitoring Skin Diseases. Sensors 2018, 18, 2552. [Google Scholar] [CrossRef]
- Zhao, S.; Shmaliy, Y.S.; Shi, P.; Ahn, C.K. Fusion Kalman/UFIR filter for state estimation with uncertain parameters and noise statistics. IEEE Trans. Ind. Electron. 2017, 64, 3075–3083. [Google Scholar] [CrossRef]
- Woźniak, M.; Połap, D. Adaptive neuro-heuristic hybrid model for fruit peel defects detection. Neural Netw. 2018, 98, 16–33. [Google Scholar] [CrossRef] [PubMed]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. New extension of the Kalman filter to nonlinear systems. In Proceedings of the AeroSense 97 Conference on Photonic Quantum Computing, Orlando, FL, USA, 20–25 April 1997; Volume 3068, pp. 182–194. [Google Scholar]
- Souza, C.R. The Accord. NET Framework. 2014. Available online: http://accord-framework.net (accessed on 20 August 2018).
- Ranganathan, A. The levenberg-marquardt algorithm. Tutor. LM Algorithm 2004, 11, 101–110. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Temperature (C) | Temperature Sensor Readings (C) | Humidity (g/m) | Absolute Error in Temperature Sensor Readings |
|---|---|---|---|---|
| Minimum | −15.30 | −21.36 | 12.00 | 0.00 |
| Maximum | 33.40 | 38.58 | 97.00 | 10.00 |
| Average | 12.14 | 12.16 | 62.90 | 5.99 |
| Stdev | 11.39 | 12.58 | 19.89 | 2.34 |
| ANN Configuration | Experiment ID | Model 1 | Model 2 | Model 3 | Model 4 | Models Average (Test Cases) | Experiments Average (Test Cases) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hidden Layers | Activation Function | Learning Rate | Training | Test | Training | Test | Training | Test | Training | Test | |||
| 5 | Linear | 0.1 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 5 | Linear | 0.1 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 5 | Linear | 0.1 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.57 |
| 5 | Linear | 0.2 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 3.28 | |
| 5 | Linear | 0.2 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 5 | Linear | 0.2 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.14 |
| 5 | Sigmoid | 0.1 | 1 | 0.30 | 0.28 | 0.22 | 0.24 | 0.22 | 0.23 | 0.35 | 0.35 | 0.27 | |
| 5 | Sigmoid | 0.1 | 2 | 0.21 | 0.18 | 0.22 | 0.25 | 0.22 | 0.23 | 0.06 | 0.09 | 0.19 | |
| 5 | Sigmoid | 0.1 | 3 | 0.23 | 0.21 | 0.10 | 0.12 | 0.15 | 0.15 | 0.24 | 0.27 | 0.19 | 0.22 |
| 5 | Sigmoid | 0.2 | 1 | 0.16 | 0.15 | 0.18 | 0.18 | 0.22 | 0.24 | 0.22 | 0.25 | 0.21 | |
| 5 | Sigmoid | 0.2 | 2 | 0.22 | 0.24 | 0.14 | 0.18 | 0.18 | 0.22 | 0.19 | 0.22 | 0.22 | |
| 5 | Sigmoid | 0.2 | 3 | 0.11 | 0.20 | 0.22 | 0.23 | 0.23 | 0.23 | 0.24 | 0.26 | 0.23 | 0.22 |
| 10 | Linear | 0.1 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 10 | Linear | 0.1 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 10 | Linear | 0.1 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.57 |
| 10 | Linear | 0.2 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 10 | Linear | 0.2 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 10 | Linear | 0.2 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.57 |
| 10 | Sigmoid | 0.1 | 1 | 0.24 | 0.21 | 0.10 | 0.10 | 0.24 | 0.24 | 0.21 | 0.24 | 0.20 | |
| 10 | Sigmoid | 0.1 | 2 | 0.26 | 0.22 | 0.20 | 0.22 | 0.27 | 0.27 | 0.52 | 0.36 | 0.27 | |
| 10 | Sigmoid | 0.1 | 3 | 0.28 | 0.23 | 0.11 | 0.13 | 0.08 | 0.08 | 0.31 | 0.33 | 0.19 | 0.22 |
| 10 | Sigmoid | 0.2 | 1 | 0.20 | 0.16 | 0.09 | 0.10 | 0.23 | 0.25 | 0.24 | 0.27 | 0.19 | |
| 10 | Sigmoid | 0.2 | 2 | 0.25 | 0.27 | 0.20 | 0.22 | 0.19 | 0.20 | 0.18 | 0.21 | 0.22 | |
| 10 | Sigmoid | 0.2 | 3 | 0.24 | 0.19 | 0.15 | 0.16 | 0.24 | 0.24 | 0.22 | 0.23 | 0.21 | 0.21 |
| 15 | Linear | 0.1 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 15 | Linear | 0.1 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 15 | Linear | 0.1 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.57 |
| 15 | Linear | 0.2 | 1 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 15 | Linear | 0.2 | 2 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | |
| 15 | Linear | 0.2 | 3 | 4.45 | 5.19 | 5.04 | 3.18 | 4.50 | 5.05 | 4.56 | 4.88 | 4.57 | 4.57 |
| 15 | Sigmoid | 0.1 | 1 | 1.15 | 0.91 | 0.27 | 0.34 | 0.34 | 0.33 | 0.24 | 0.27 | 0.46 | |
| 15 | Sigmoid | 0.1 | 2 | 0.13 | 0.11 | 0.23 | 0.25 | 0.23 | 0.20 | 0.31 | 0.31 | 0.21 | |
| 15 | Sigmoid | 0.1 | 3 | 0.57 | 0.45 | 0.34 | 0.36 | 0.22 | 0.22 | 0.19 | 0.23 | 0.31 | 0.33 |
| 15 | Sigmoid | 0.2 | 1 | 0.27 | 0.23 | 0.56 | 0.91 | 0.19 | 0.22 | 0.40 | 0.40 | 0.44 | |
| 15 | Sigmoid | 0.2 | 2 | 0.24 | 0.20 | 0.22 | 0.25 | 0.26 | 0.29 | 0.20 | 0.23 | 0.24 | |
| 15 | Sigmoid | 0.2 | 3 | 0.25 | 0.19 | 0.20 | 0.24 | 0.21 | 0.22 | 0.21 | 0.24 | 0.22 | 0.30 |
| Metric | Sensing Data | Kalman Filter | Kalman Filter with Learning Module | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R = 5 | R = 10 | R = 15 | R = 20 | R = 25 | F = 0.005 | F = 0.008 | F = 0.01 | F = 0.02 | F = 0.05 | F = 0.1 | ||
| MAD | 0.348 | 0.178 | 0.166 | 0.163 | 0.163 | 0.164 | 0.159 | 0.157 | 0.156 | 0.156 | 0.160 | 0.165 |
| MSE | 27.204 | 7.224 | 6.388 | 6.224 | 6.222 | 6.274 | 5.914 | 5.807 | 5.770 | 5.701 | 5.844 | 6.157 |
| RMSE | 5.216 | 2.688 | 2.527 | 2.495 | 2.494 | 2.505 | 2.432 | 2.410 | 2.402 | 2.388 | 2.417 | 2.481 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, I.; Fayaz, M.; Kim, D. Improving Accuracy of the Kalman Filter Algorithm in Dynamic Conditions Using ANN-Based Learning Module. Symmetry 2019, 11, 94. https://doi.org/10.3390/sym11010094
Ullah I, Fayaz M, Kim D. Improving Accuracy of the Kalman Filter Algorithm in Dynamic Conditions Using ANN-Based Learning Module. Symmetry. 2019; 11(1):94. https://doi.org/10.3390/sym11010094
Chicago/Turabian StyleUllah, Israr, Muhammad Fayaz, and DoHyeun Kim. 2019. "Improving Accuracy of the Kalman Filter Algorithm in Dynamic Conditions Using ANN-Based Learning Module" Symmetry 11, no. 1: 94. https://doi.org/10.3390/sym11010094