Fuzzy Attribute Expansion Method for Multiple Attribute Decision-Making with Partial Attribute Values and Weights Unknown and Its Applications

Abstract
:1. Introduction
2. Basic Definitions
- (a)
- (b)
- ,
- (c)
- ,
- (a)
- ,
- (b)
- ,,
- (a)
- ,
- (b)
- ,
- (c)
- ,,
3. Problem
- (a)
- The length of is , ;
- (b)
- The sequence of attribute weights is ;
- (c)
- Evaluation value of falls into the interval , the greater the evaluation value is, the higher the evaluation is.
- (d)
- The evaluation values are as similar to those obtained under the condition that some UFAs are given as possible.
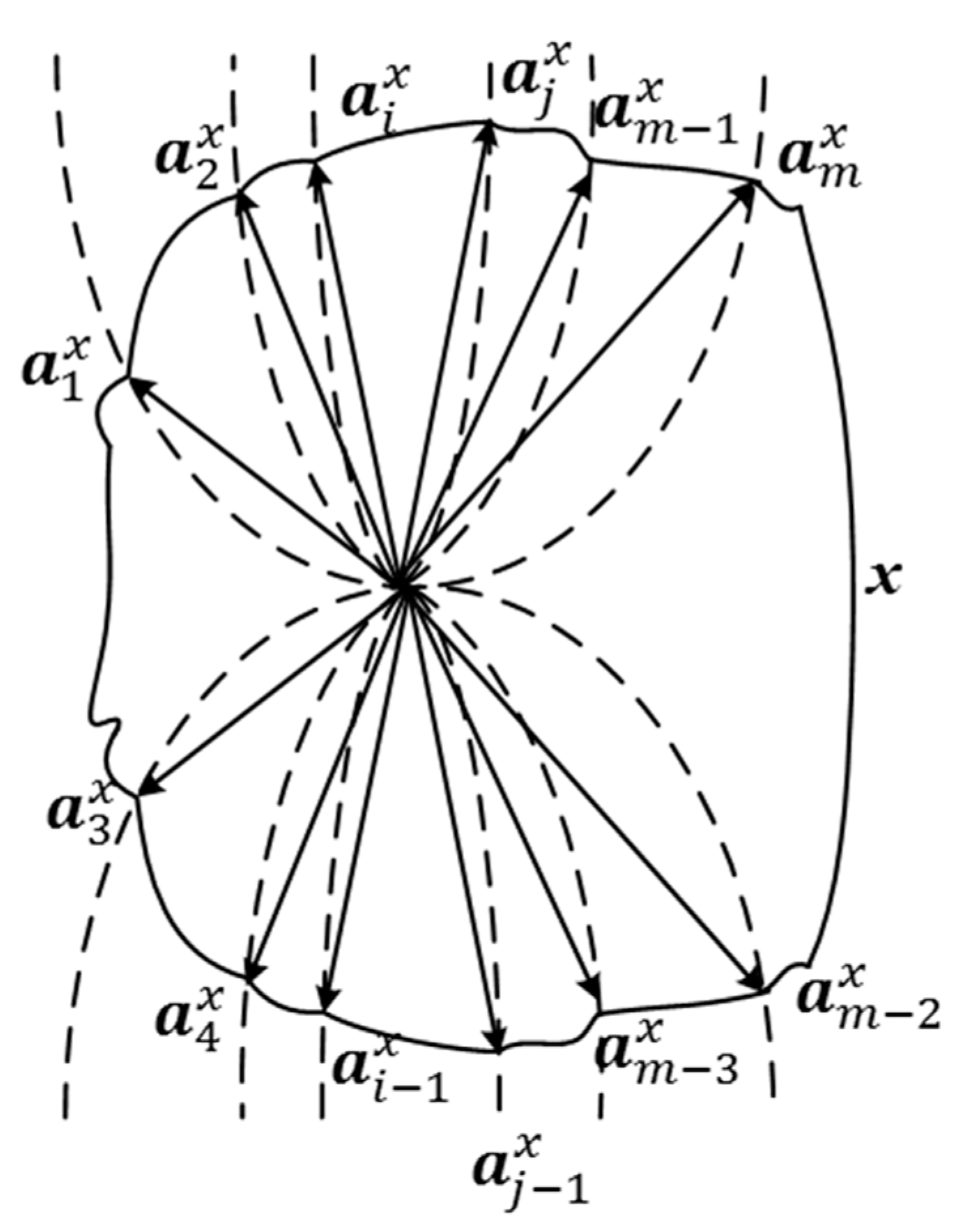
4. Geometric Analysis of PAS, MAS, and FAMS
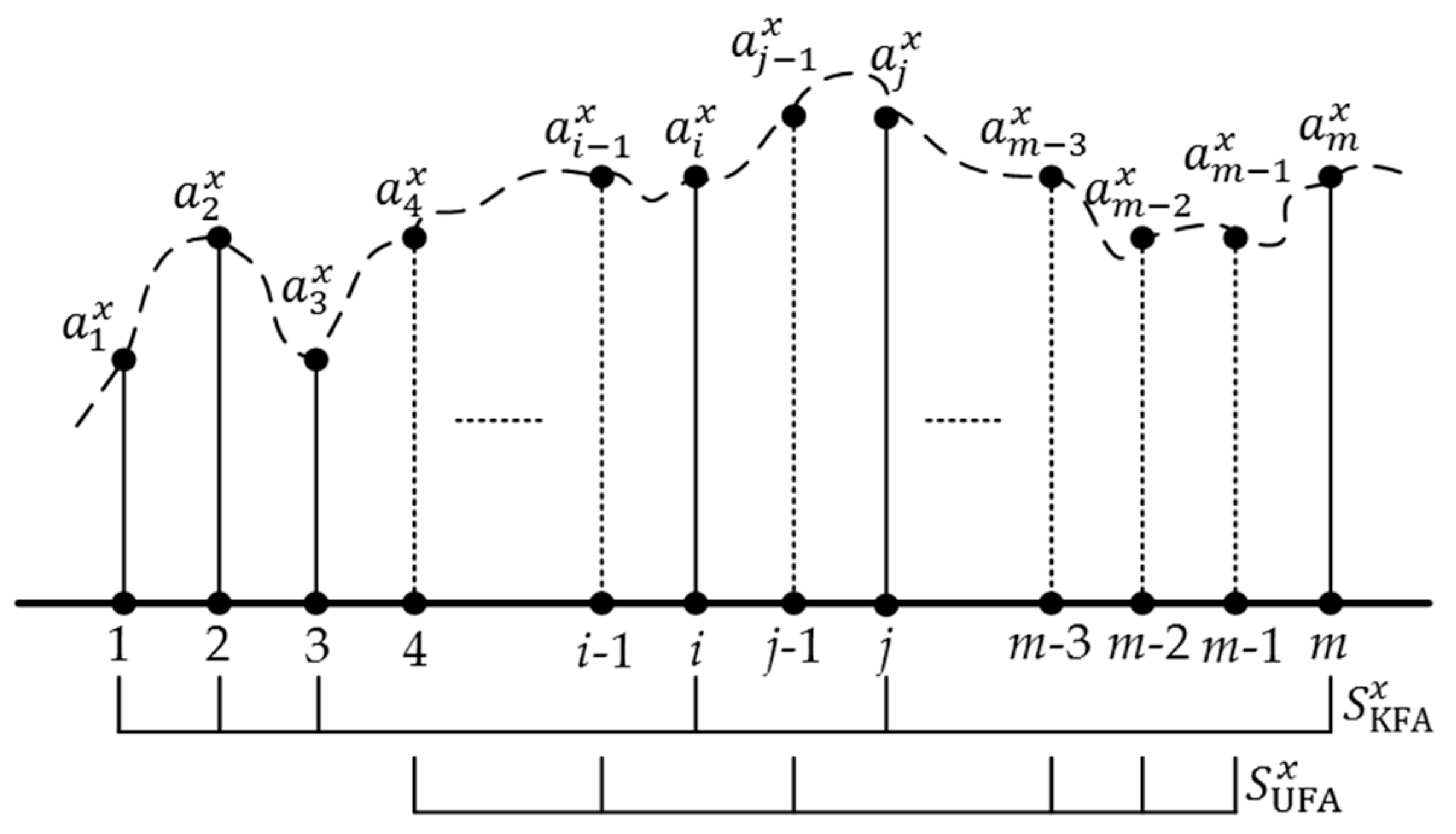
5. The Fuzzy Attribute Expansion Method
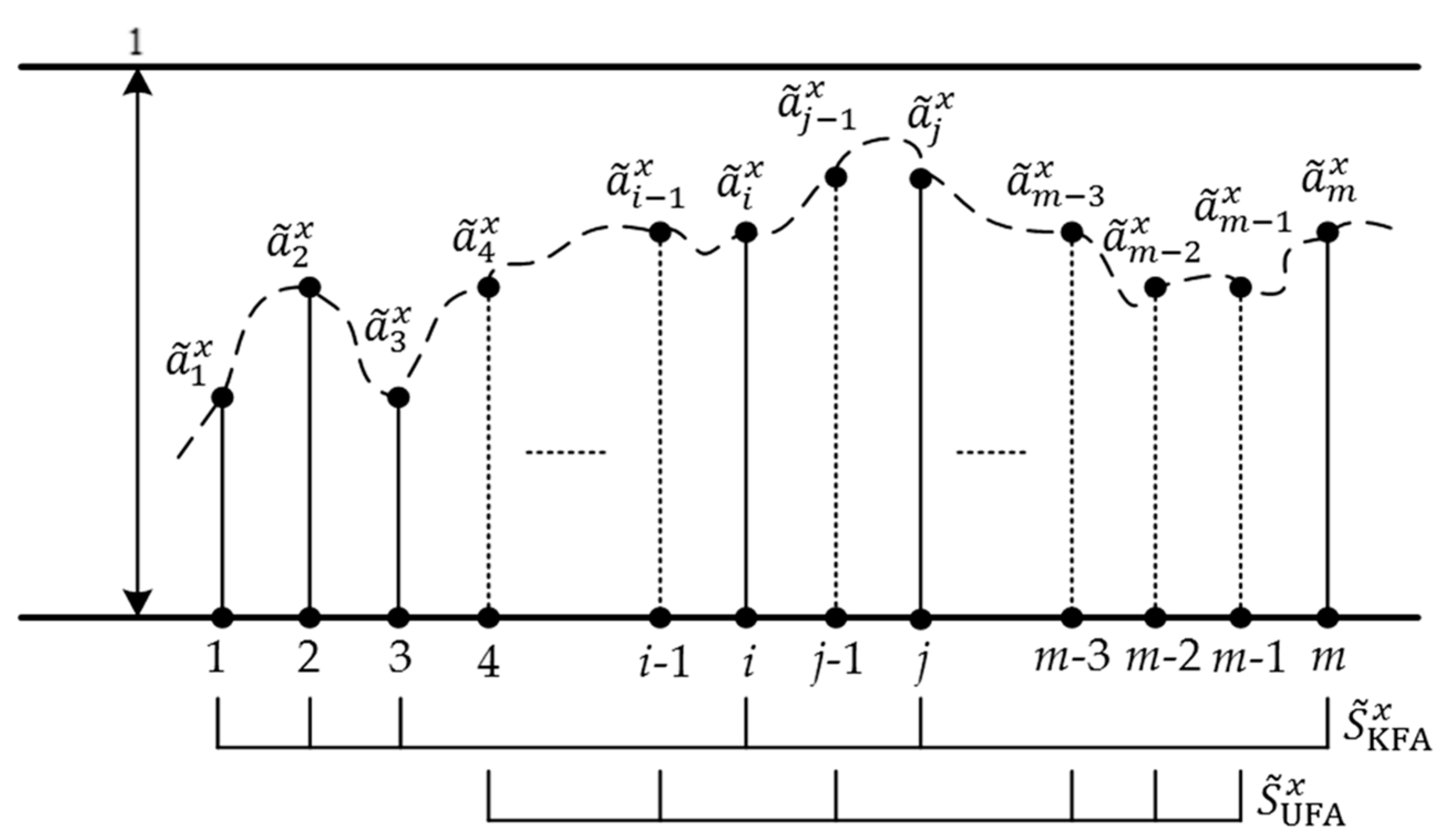
5.1. The Technique to Approximate Estimate UFAs Based on Interpolation
5.2. The Technique to Generate the Final Evaluation Based on Attribute Weight Reconfiguration
6. Applications
6.1. Applications for Regression
6.2. Applications for Clustering
6.3. Applications for Power Quality Evaluation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.D.; Zhang, Y.F. SQI quality evaluation mechanism of single-lead ECG signal based on simple heuristic fusion and fuzzy comprehensive evaluation. Front. Physiol. 2018, 9, 727. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.C.; Xu, K.; Lian, J.J.; Bin, L.L.; Ma, C. Multiple flood vulnerability assessment approach based on fuzzy comprehensive evaluation method and coordinated development degree model. J. Environ. Manag. 2018, 213, 440–450. [Google Scholar] [CrossRef] [PubMed]
- Zuo, R.G.; Cheng, Q.M.; Agterberg, F.P. Application of a hybrid method combining multilevel fuzzy comprehensive evaluation with asymmetric fuzzy relation analysis to mapping prospectivity. Ore Geol. Rev. 2009, 35, 101–108. [Google Scholar] [CrossRef]
- Bo, C.X.; Zhang, X.H. New operations of picture fuzzy relations and fuzzy comprehensive evaluation. Symmetry 2017, 9, 268. [Google Scholar] [CrossRef]
- Jin, C. Adaptive robust image watermark approach based on fuzzy comprehensive evaluation and analytic hierarchy process. Signal Image Video Process. 2012, 6, 317–324. [Google Scholar] [CrossRef]
- Zeng, D.Z.; He, Q.Y.; Yu, Z.M.; Jia, W.Y.; Zhang, S.; Liu, Q.P. Risk assessment of sustained casing pressure in gas wells based on the fuzzy comprehensive evaluation method. J. Nat. Gas Sci. Eng. 2017, 46, 756–763. [Google Scholar] [CrossRef]
- Liu, Y.L.; Huang, X.L.; Duan, J.; Zhang, H.M. The assessment of traffic accident risk based on grey relational analysis and fuzzy comprehensive evaluation method. Nat. Hazards 2017, 88, 1409–1422. [Google Scholar] [CrossRef]
- Li, Y.; Sun, Z.D.; Han, L.; Mei, N. Fuzzy comprehensive evaluation method for energy management systems based on an internet of things. IEEE Access 2017, 5, 21312–21322. [Google Scholar] [CrossRef]
- Wei, B.; Wang, S.; Li, L. Fuzzy comprehensive evaluation of district heating systems. Energy Policy 2010, 38, 5947–5955. [Google Scholar] [CrossRef]
- Medina, J.; Ojeda-Aciego, M. Multi-adjoint t-concept lattices. Inf. Sci. 2010, 180, 712–725. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Xu, Z.S. Models for multiple attribute decision making with intuitionistic fuzzy information. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2007, 15, 285–297. [Google Scholar] [CrossRef]
- Wan, S.P.; Wan, F.; Dong, J.Y. A novel risk attitudinal ranking method for intuitionistic fuzzy values and application to MADM. Appl. Soft Comput. 2016, 40, 98–112. [Google Scholar] [CrossRef]
- Qin, J.D.; Liu, X.W. An approach to intuitionistic fuzzy multiple attribute decision making based on Maclaurin symmetric mean operators. J. Intell. Fuzzy Syst. 2014, 27, 2177–2190. [Google Scholar] [CrossRef]
- Liu, P.D.; Mahmood, T.; Khan, Q. Multi-attribute decision-making based on prioritized aggregation operator under hesitant intuitionistic fuzzy linguistic environment. Symmetry 2017, 9, 270. [Google Scholar] [CrossRef]
- Abdullah, L.; Najib, L. A new preference scale of intuitionistic fuzzy analytic hierarchy process in multi-criteria decision making problems. J. Intell. Fuzzy Syst. 2014, 26, 1039–1049. [Google Scholar] [CrossRef]
- Atanassov, K.T. Interval-valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 1989, 31, 343–349. [Google Scholar] [CrossRef]
- Liu, P.D. Some hamacher aggregation operators based on the interval-valued intuitionistic fuzzy numbers and their application to group decision making. IEEE Trans. Fuzzy Syst. 2014, 22, 83–97. [Google Scholar] [CrossRef]
- Wei, G.W. Interval valued hesitant fuzzy uncertain linguistic aggregation operators in multiple attribute decision making. Int. J. Mach. Learn. Cybern. 2016, 7, 1093–1114. [Google Scholar] [CrossRef]
- Gupta, P.; Lin, C.T.; Mehlawat, M.K.; Grover, N. A new method for intuitionistic fuzzy multiattribute decision making. IEEE Trans. Syst. Man. Cybern. Syst. 2016, 46, 1167–1179. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.W.; Li, H. An approach for MADM problems with interval-valued intuitionistic fuzzy sets based on nonlinear functions. Technol. Econ. Dev. Econ. 2016, 22, 336–356. [Google Scholar] [CrossRef]
- Tang, X.A.; Fu, C.; Xu, D.L.; Yang, S.L. Analysis of fuzzy Hamacher aggregation functions for uncertain multiple attribute decision making. Inf. Sci. 2017, 387, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Hussain, S.A.I.; Mandal, U.K.; Mondal, S.P. Decision maker priority index and degree of vagueness coupled decision making method: A synergistic approach. Int. J. Fuzzy Syst. 2018, 20, 1551–1566. [Google Scholar] [CrossRef]
- Chen, S.M.; Han, W.H. A new multiattribute decision making method based on multiplication operations of interval-valued intuitionistic fuzzy values and linear programming methodology. Inf. Sci. 2018, 429, 421–432. [Google Scholar] [CrossRef]
- Dahooie, J.H.; Zavadskas, E.K.; Abolhasani, M.; Vanaki, A.; Turskis, Z. A novel approach for evaluation of projects using an interval-valued fuzzy additive ratio assessment (ARAS) method: A case study of oil and gas well drilling projects. Symmetry 2018, 10, 45. [Google Scholar] [CrossRef]
- Chen, B.; Guo, Y.Y.; Gao, X.E.; Wang, Y.M. A novel multi-attribute decision making approach: Addressing the complexity of time dependent and interdependent data. IEEE Access 2018, 6, 55838–55849. [Google Scholar] [CrossRef]
- Yazici, I.; Kahraman, C. VIKOR method using interval type two fuzzy sets. J. Intell. Fuzzy Syst. 2015, 29, 411–421. [Google Scholar] [CrossRef]
- Yao, D.B.; Liu, X.X.; Zhang, X.; Wang, C.C. Type-2 fuzzy cross-entropy and entropy measures and their applications. J. Intell. Fuzzy Syst. 2016, 30, 2169–2180. [Google Scholar] [CrossRef]
- Keshavarz-Ghorabaee, M.; Amiri, M.; Zavadskas, E.K.; Turskis, Z.; Antucheviciene, J. An extended step-wise weight assessment ratio analysis with symmetric interval type-2 fuzzy sets for determining the subjective weights of criteria in multi-criteria decision-making problems. Symmetry 2018, 10, 91. [Google Scholar] [CrossRef]
- Yang, Y.; Lang, L.; Lu, L.L.; Sun, Y.M. A new method of multiattribute decision-making based on interval-valued hesitant fuzzy soft sets and its application. Math. Probl. Eng. 2017, 2017, 9376531. [Google Scholar] [CrossRef]
- Tong, X.; Yu, L.Y. MADM based on distance and correlation coefficient measures with decision-maker preferences under a hesitant fuzzy environment. Soft Comput. 2016, 20, 4449–4461. [Google Scholar] [CrossRef]
- Zhang, R.C.; Li, Z.M.; Liao, H.C. Multiple-attribute decision-making method based on the correlation coefficient between dual hesitant fuzzy linguistic term sets. Knowl. Based Syst. 2018, 159, 186–192. [Google Scholar] [CrossRef]
- Kahraman, C.; Onar, S.Ç.; Öztaysi, B. Fuzzy multicriteria decision-making: A literature review. Int. J. Comput. Intell. Syst. 2015, 8, 637–666. [Google Scholar] [CrossRef]
- Li, M.Z.; Du, Y.N.; Wang, Q.Y.; Sun, C.M.; Ling, X.; Yu, B.Y.; Tu, J.S.; Xiong, Y.R. Risk assessment of supply chain for pharmaceutical excipients with AHP-fuzzy comprehensive evaluation. Drug Dev. Ind. Pharm. 2016, 42, 676–684. [Google Scholar] [CrossRef]
- Goyal, R.K.; Kaushal, S.; Sangaiah, A.K. The utility based non-linear fuzzy AHP optimization model for network selection in heterogeneous wireless networks. Appl. Soft Comput. 2018, 67, 800–811. [Google Scholar] [CrossRef]
- Selvachandran, G.; Quek, S.G.; Smarandache, F.; Broumi, S. An extended technique for order preference by similarity to an ideal solution (TOPSIS) with maximizing deviation method based on integrated weight measure for single-valued neutrosophic sets. Symmetry 2018, 10, 236. [Google Scholar] [CrossRef]
- Sun, G.D.; Guan, X.; Yi, X.; Zhou, Z. An innovative TOPSIS approach based on hesitant fuzzy correlation coefficient and its applications. Appl. Soft Comput. 2018, 68, 249–267. [Google Scholar] [CrossRef]
- Baykasoglu, A.; Golcuk, I. Development of an interval type-2 fuzzy sets based hierarchical MADM model by combining DEMATEL and TOPSIS. Expert Syst. Appl. 2017, 70, 37–51. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Amiri, M.; Zavadskas, E.K.; Antucheviciene, J. Supplier evaluation and selection in fuzzy environments: A review of MADM approaches. Econ. Res. Ekon. Istraž. 2017, 30, 1073–1118. [Google Scholar] [CrossRef]
- Park, K.S.; Kim, S.H. Tools for interactive multiattribute decisionmaking with incompletely identified information. Eur. J. Oper. Res. 1997, 98, 111–123. [Google Scholar] [CrossRef]
- Xu, Z.S.; Zhang, X.L. Hesitant fuzzy multi-attribute decision making based on TOPSIS with incomplete weight information. Knowl. Based Syst. 2013, 52, 53–64. [Google Scholar] [CrossRef]
- Wei, G.W. GRA method for multiple attribute decision making with incomplete weight information in intuitionistic fuzzy setting. Knowl. Based Syst. 2010, 23, 243–247. [Google Scholar] [CrossRef]
- Bao, T.T.; Xie, X.L.; Long, P.Y.; Wei, Z.K. MADM method based on prospect theory and evidential reasoning approach with unknown attribute weights under intuitionistic fuzzy environment. Expert Syst. Appl. 2017, 88, 305–317. [Google Scholar] [CrossRef]
- Eum, Y.S.; Park, K.S.; Kim, S.H. Establishing dominance and potential optimality in multi-criteria analysis with imprecise weight and value. Comput. Oper. Res. 2001, 28, 397–409. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Regression Model | A 1 | HL (Train/Test) | MSE (Train/Test) | EI (Train/Test) | NUFA2 |
|---|---|---|---|---|---|
| SVMR | 0 | 2.6426/2.5052 | 18.4283/18.3963 | 2.3938/2.3395 | / |
| 1 | 2.6427/2.4991 | 18.3377/18.3808 | 2.3949/2.3379 | <1.08:0.08:2.92> | |
| GKR-1 | 0 | 2.1724/2.2637 | 15.5750/17.2569 | 1.9958/2.0781 | / |
| 1 | 2.1362/2.1400 | 15.4048/16.1185 | 1.9793/1.9573 | <1.08:0.8:2.68> | |
| GKR-2 | 0 | 2.0406/2.2523 | 12.8566/17.0757 | / | / |
| 1 | 1.9960/2.0937 | 12.5828/15.6837 | / | <1.08:0.8:2.68> |
| Regression Model | A 1 | HL (Train/Test) | MSE (Train/Test) | EI (Train/Test) | NUFA2 |
|---|---|---|---|---|---|
| SVMR | 0 | 2.0199/1.8340 | 12.5788/10.6975 | 1.8338/1.6461 | / |
| 1 | 2.0220/1.8295 | 12.4889/10.5811 | 1.8323/1.6459 | <1.08:0.08:3.96> | |
| GKR-1 | 0 | 1.7104/1.7270 | 11.0732/13.1882 | 1.5813/1.6434 | / |
| 1 | 1.5242/1.5924 | 10.5474/10.5426 | 1.4230/1.4778 | <1.8:1:3.8> | |
| GKR-2 | 0 | 1.4146/1.7246 | 7.1309/11.8654 | / | / |
| 1 | 1.1562/1.5241 | 5.9034/9.0240 | / | <1.8:1:3.8> |
| Clustering Method | A 1 | AR (Worst/Mean/Best) | RI (Worst/Mean/Best) | NMI (Worst/Mean/Best) | NUFA |
|---|---|---|---|---|---|
| FCM | 0 | 0.8800/0.8879/0.8933 | 0.8679/0.8748/0.8797 | 0.7225/0.7328/0.743 | / |
| 1 | 0.9200/0.9200/0.9200 | 0.9055/0.9055/0.9055 | 0.7855/0.7855/0.785 | <1.8:0.5:3.8> | |
| K-means | 0 | 0.5800/0.7822/0.8867 | 0.7214/0.8210/0.8737 | 0.5927/0.6830/0.741 | / |
| 1 | 0.5067/0.8373/0.9533 | 0.7204/0.8648/0.9417 | 0.6011/0.7653/0.846 | <1.8:0.5:3.8> | |
| K-medoids | 0 | 0.9000/0.9040/0.9067 | 0.8859/0.8897/0.8923 | 0.7578/0.7596/0.761 | / |
| 1 | 0.9333/0.9333/0.9333 | 0.9195/0.9195/0.9135 | 0.8038/0.8038/0.804 | <1.8:0.5:3.8> |
| Measurable Attributes | Node1 | Node2 | Node3 | Node4 | Node5 |
|---|---|---|---|---|---|
| (Frequency deviation) | 0.0922 | 0.1562 | 0.1180 | 0.1787 | 0.1892 |
| (Voltage deviation) | 3.2120 | 6.6800 | 4.3500 | 5.3300 | 4.2200 |
| (Voltage sag) | 79.6300 | 15.8900 | 51.5600 | 58.5600 | 48.6300 |
| (Three phase imbalance) | 0.8300 | 1.3600 | 1.3500 | 1.7400 | 1.8300 |
| (Voltage fluctuation) | 1.3300 | 1.5300 | 1.9500 | 1.3700 | 1.5800 |
| (Voltage flicker) | 0.4730 | 0.8470 | 0.6340 | 0.8260 | 0.8280 |
| (Voltage harmonics) | 1.7200 | 4.3800 | 2.6700 | 3.3600 | 4.5700 |
| (Unreliability index) | 0.1670 | 0.2380 | 0.2040 | 0.2600 | 0.2360 |
| (Unserviceable index) | 0.1680 | 0.2870 | 0.1360 | 0.3160 | 0.2170 |
| Node1 | Node2 | Node3 | Node4 | Node5 |
|---|---|---|---|---|
| 0.1309 | 0.6720 | 0.4262 | 0.7405 | 0.7054 |
| Methods | Node1 | Node2 | Node3 | Node4 | Node5 | Hamming Distance |
|---|---|---|---|---|---|---|
| Traditional | 0.2000 | 0.5025 | 0.5347 | 0.6293 | 0.6415 | 0.8 |
| Proposed | 0.1063 | 0.6281 | 0.4757 | 0.6884 | 0.6436 | 0 |
| Methods | Node1 | Node2 | Node3 | Node4 | Node5 | Hamming Distance |
|---|---|---|---|---|---|---|
| Traditional | 0 | 0.6281 | 0.5285 | 0.6192 | 0.6735 | 0.6 |
| Proposed | 0 | 0.6650 | 0.5133 | 0.6242 | 0.6354 | 0.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuo, J.; Shi, W.; Lan, Y. Fuzzy Attribute Expansion Method for Multiple Attribute Decision-Making with Partial Attribute Values and Weights Unknown and Its Applications. Symmetry 2018, 10, 717. https://doi.org/10.3390/sym10120717
Zhuo J, Shi W, Lan Y. Fuzzy Attribute Expansion Method for Multiple Attribute Decision-Making with Partial Attribute Values and Weights Unknown and Its Applications. Symmetry. 2018; 10(12):717. https://doi.org/10.3390/sym10120717
Chicago/Turabian StyleZhuo, Jinbao, Weifeng Shi, and Ying Lan. 2018. "Fuzzy Attribute Expansion Method for Multiple Attribute Decision-Making with Partial Attribute Values and Weights Unknown and Its Applications" Symmetry 10, no. 12: 717. https://doi.org/10.3390/sym10120717