
A Big Data Grided Organization and Management Method for Cropland Quality Evaluation
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
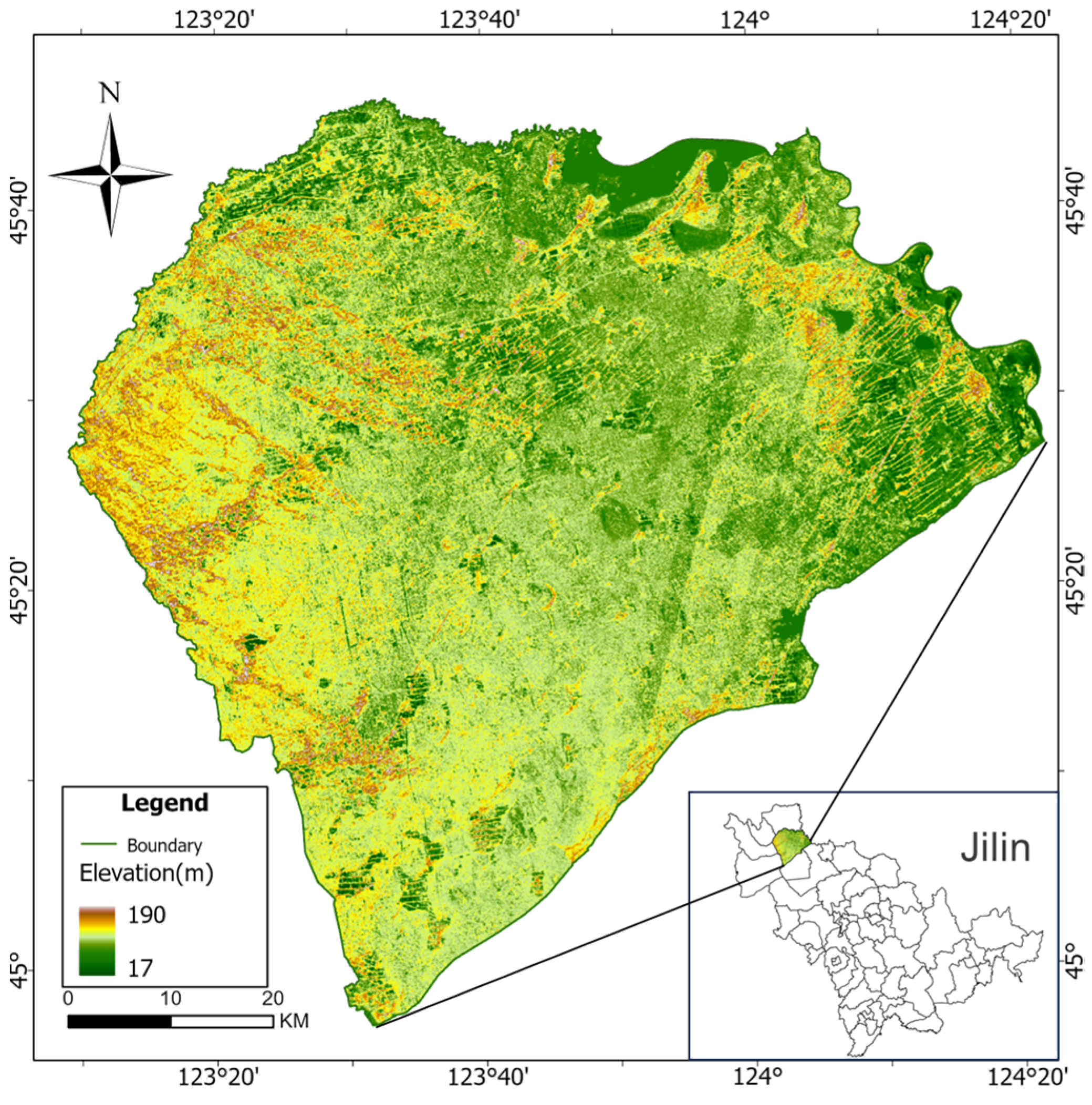
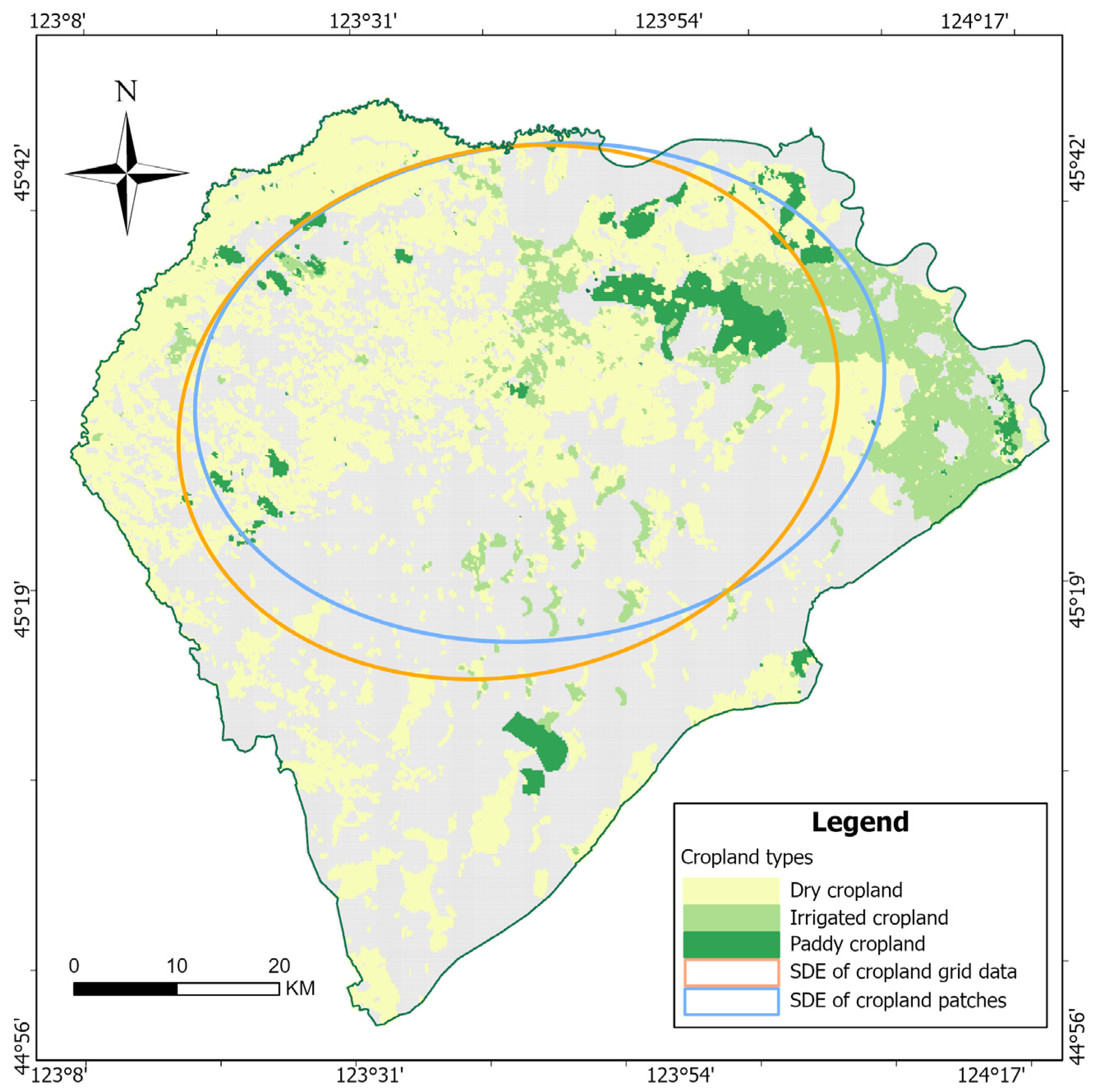
2.1. Study Area
2.2. Data Source
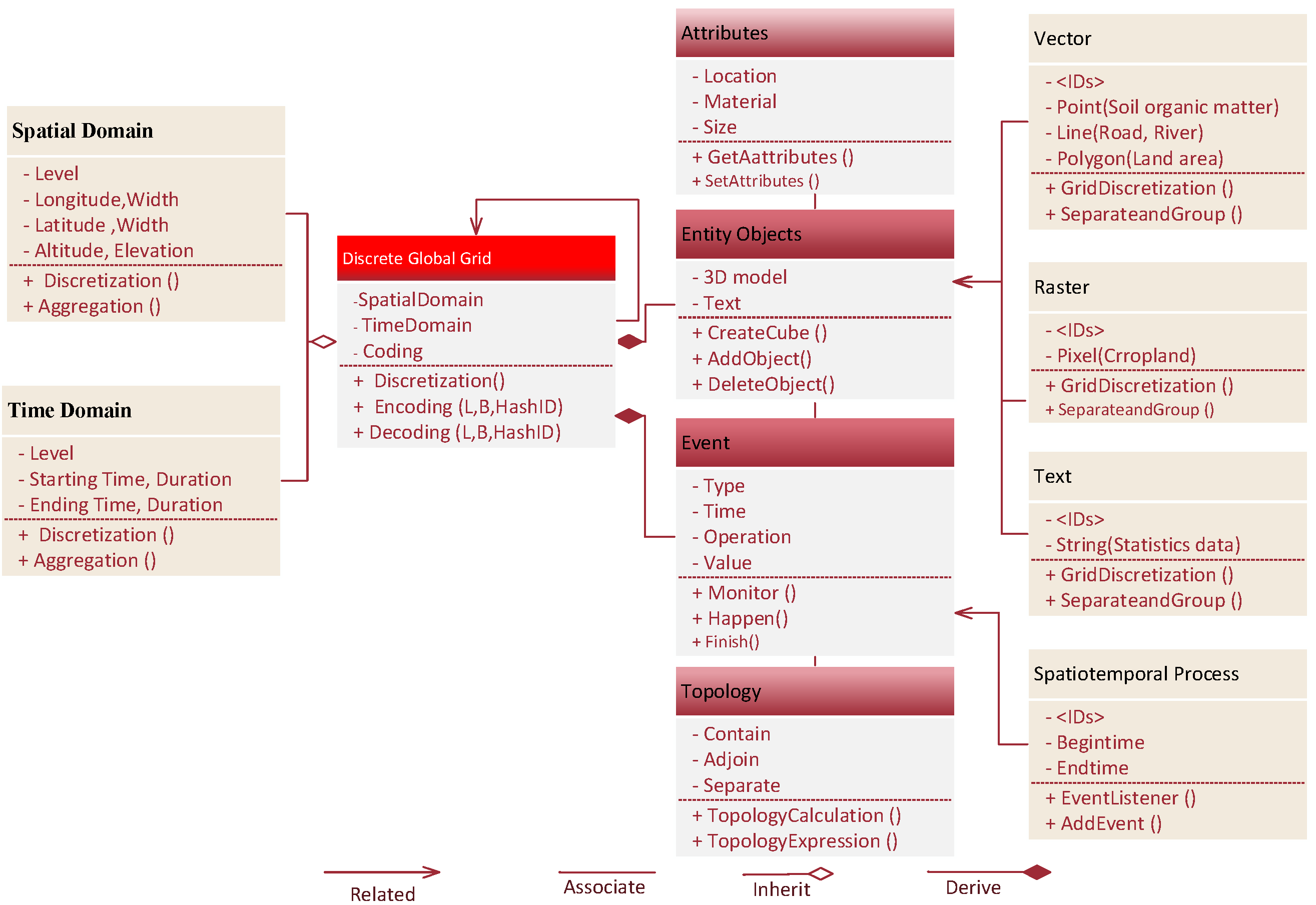
2.3. Establish Cropland Big Data Fusion Model
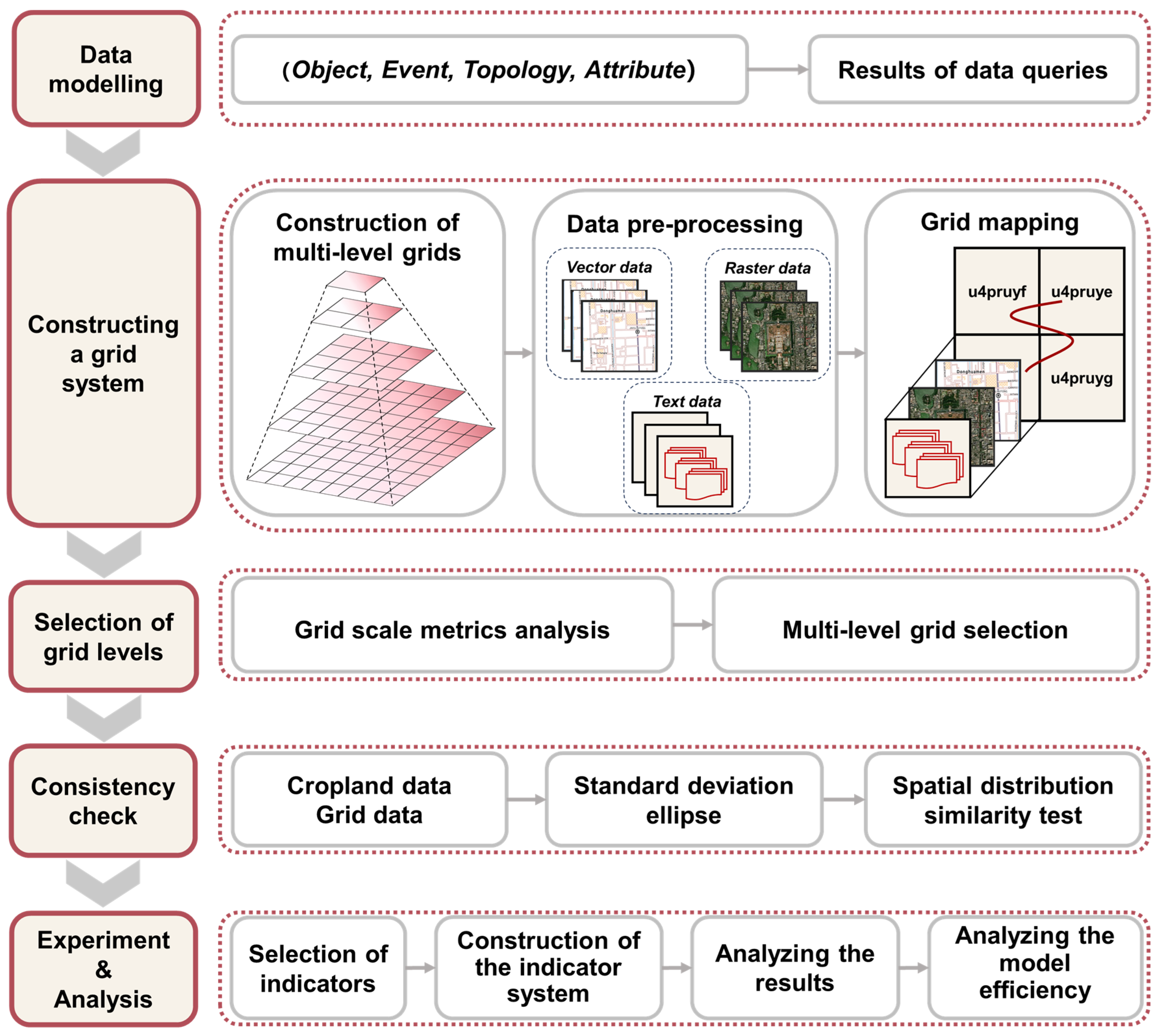
2.4. Establish a Multilevel Grid System for Cropland Big Data
2.4.1. Creation of Multilevel Grid
2.4.2. Preprocessing of Heterogeneous Cropland Big Data from Multiple Sources
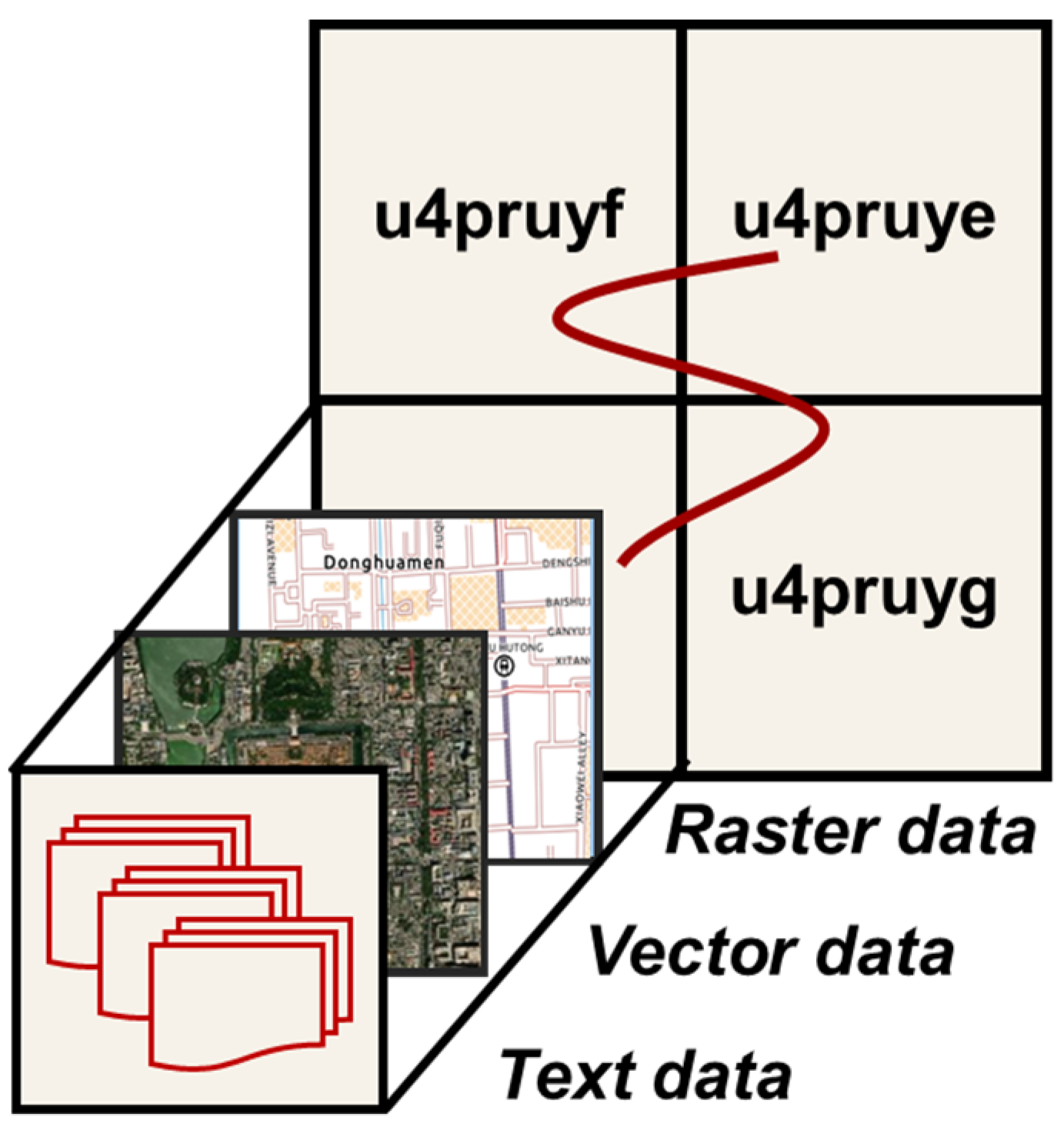
2.4.3. Grid Mapping of Heterogeneous Cropland Big Data from Multi-Sources
2.5. Selection of Cropland Quality Big Data Grid Levels
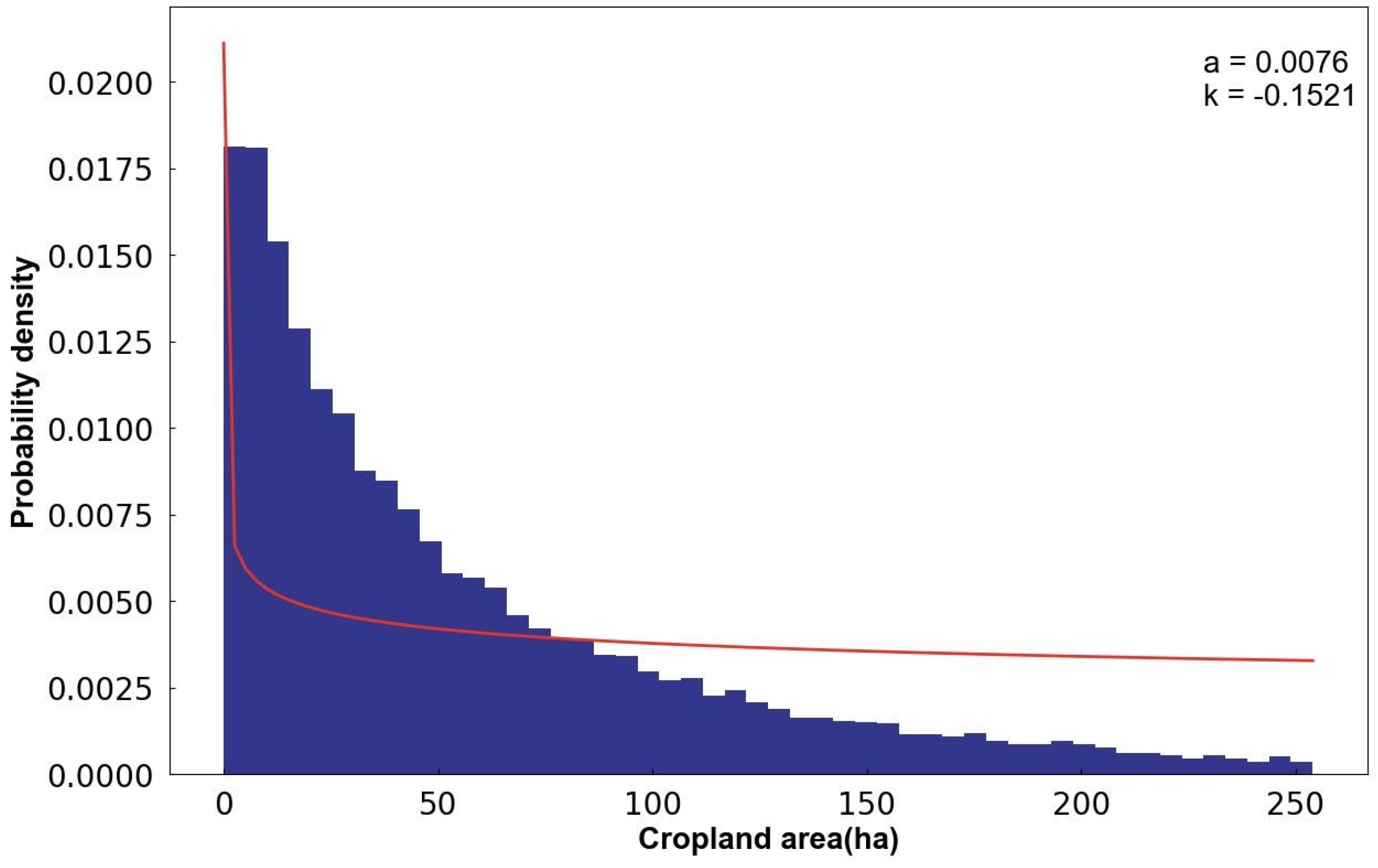
2.5.1. Adaptive Grid-Scale Indicator Analysis for Cropland Quality Evaluation
2.5.2. A Multilevel Grid Selection Method for Cropland Quality Evaluation
2.6. Evaluation of Grid Datasets Based on Similarity of Spatial Distribution
3. Results
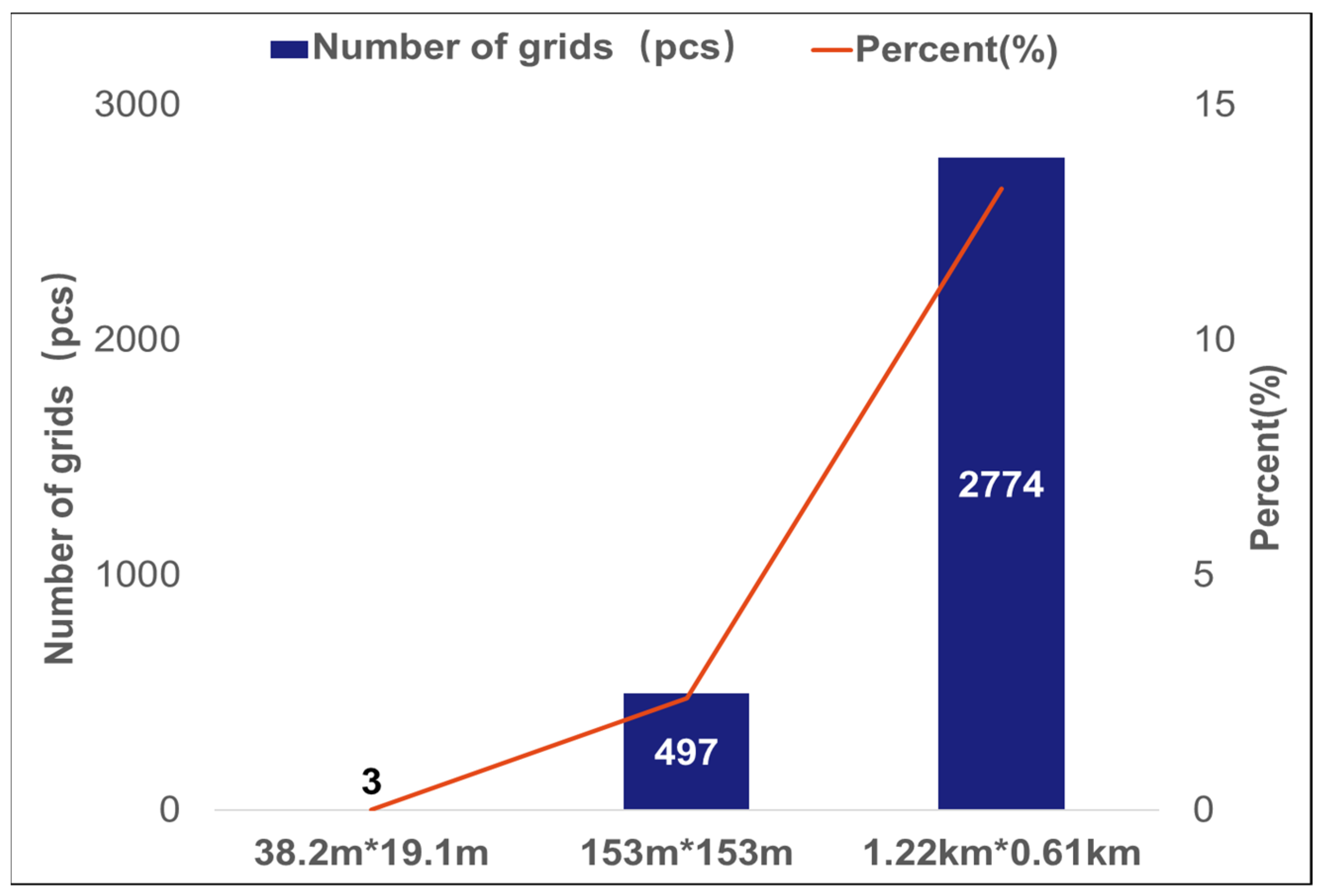
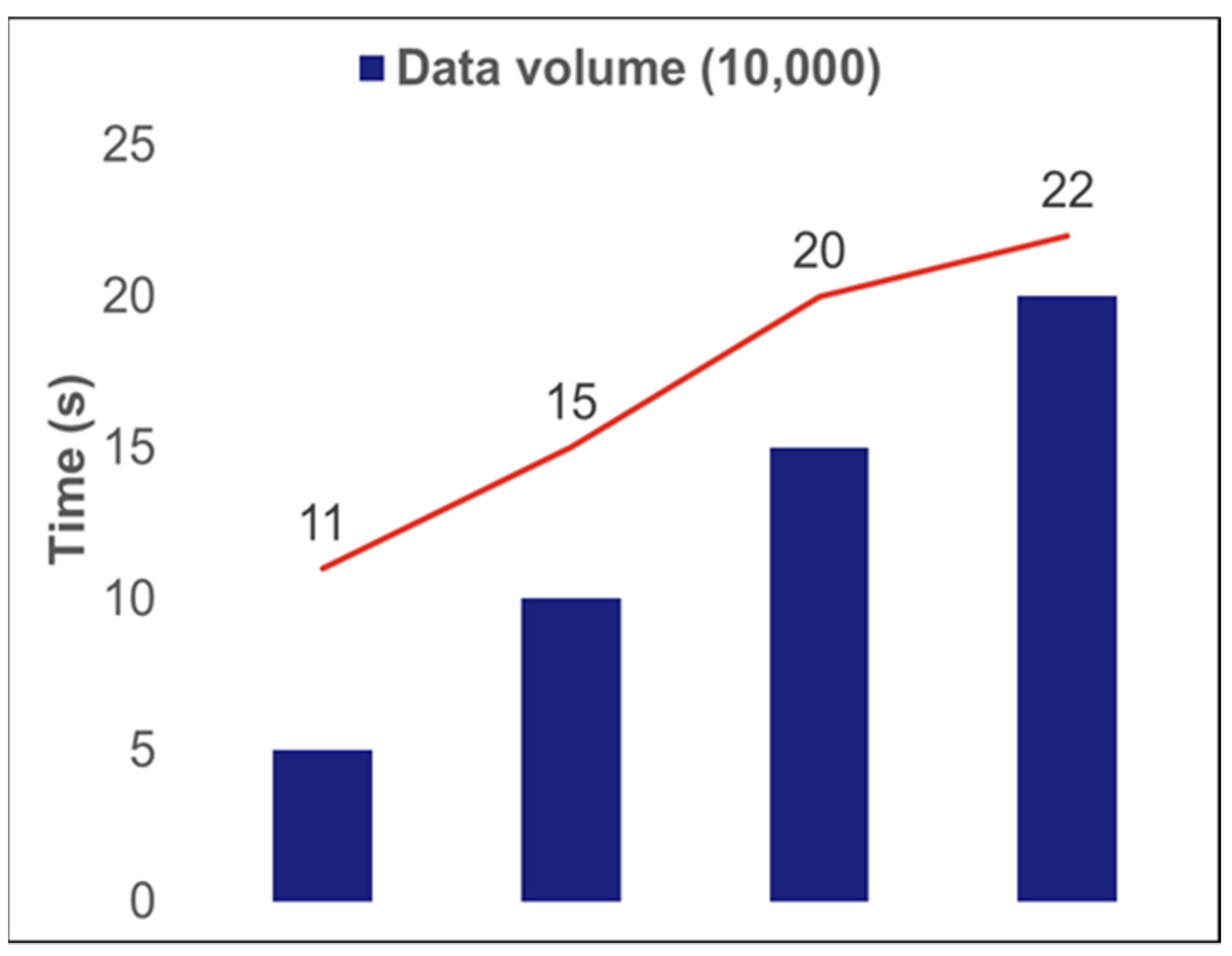
3.1. Results of Selecting the Level of Cropland Big Data Grid
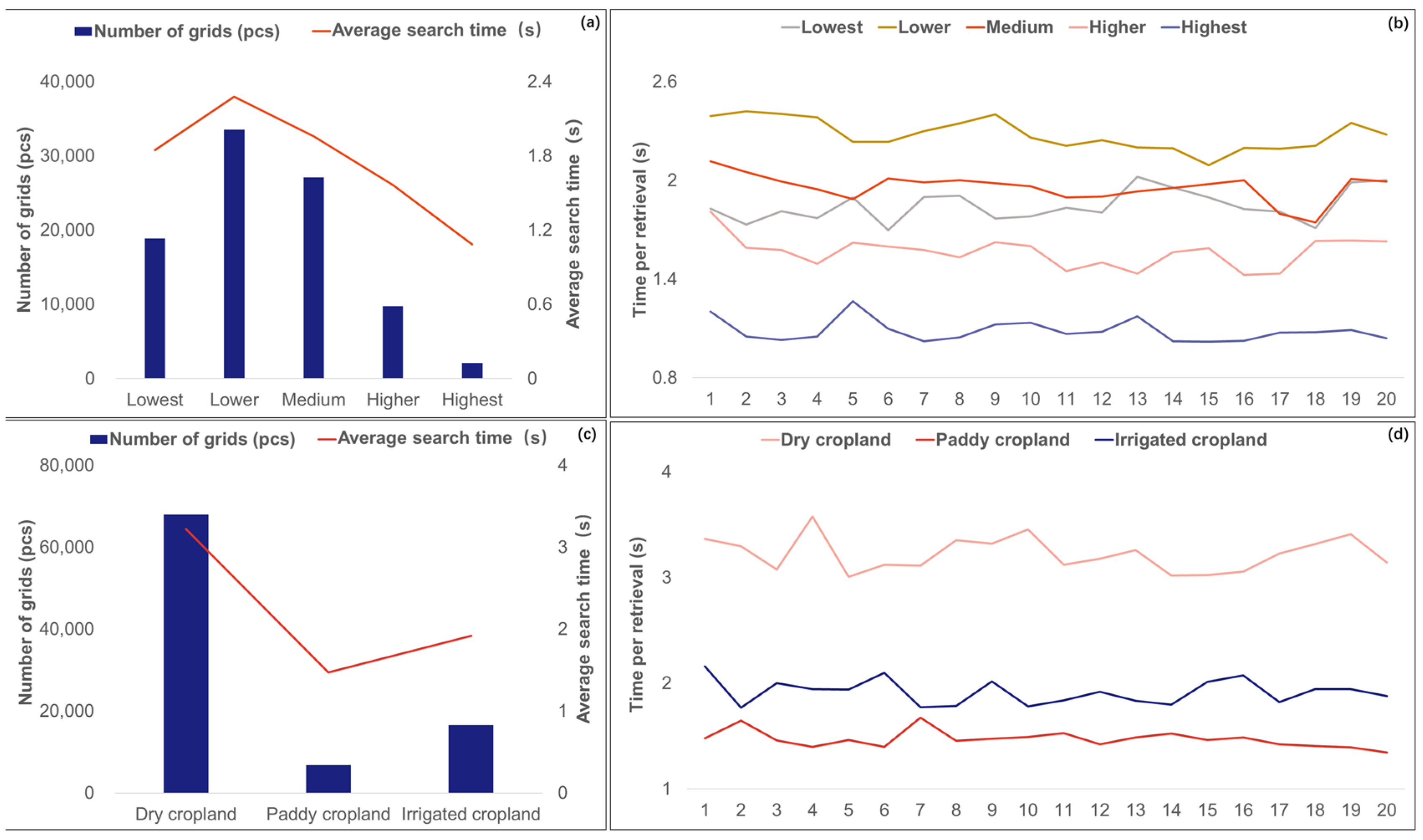
3.2. Spatial Distribution Similarity Test
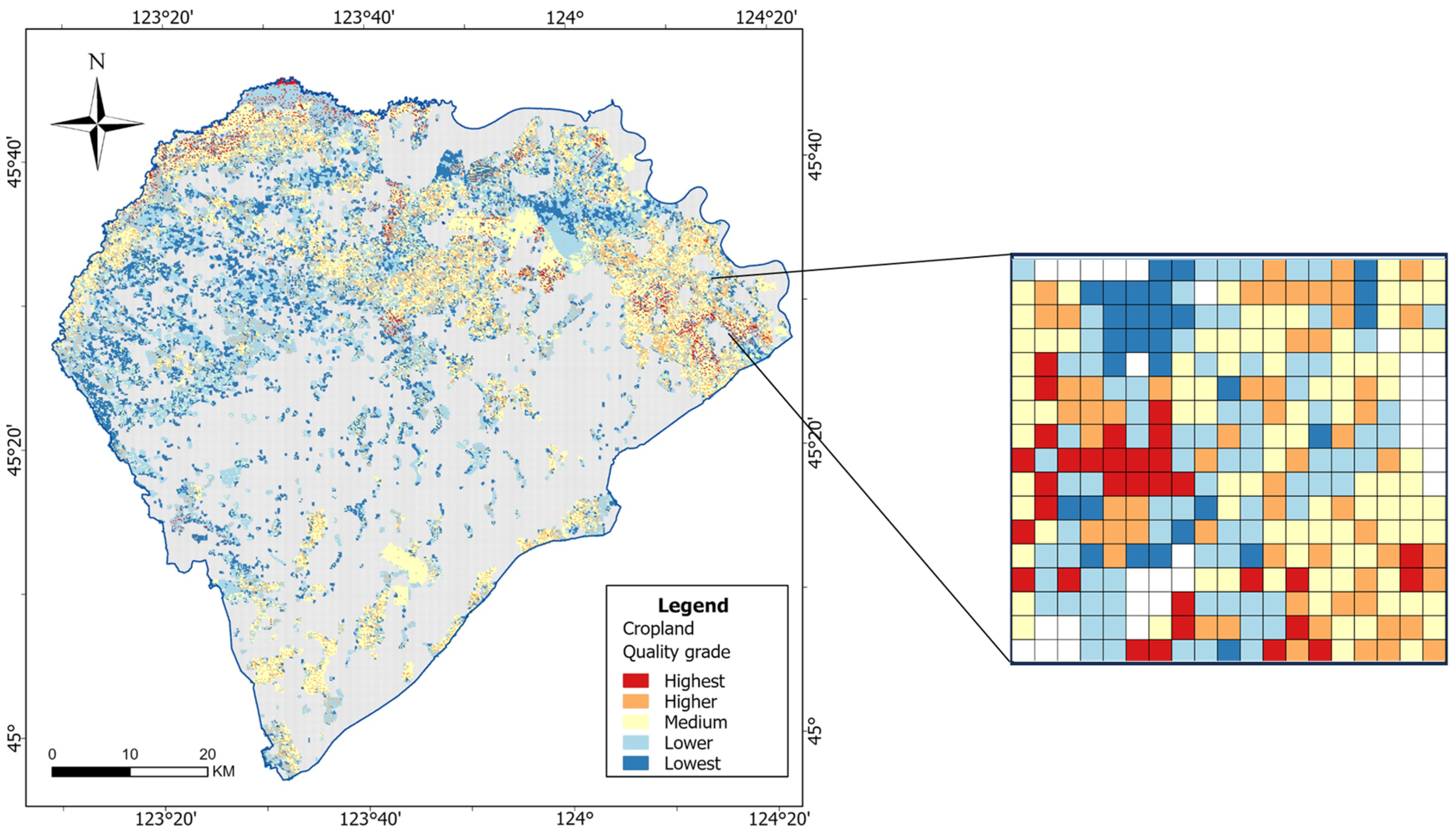
3.3. Cropland Quality Evaluation and Result Analysis
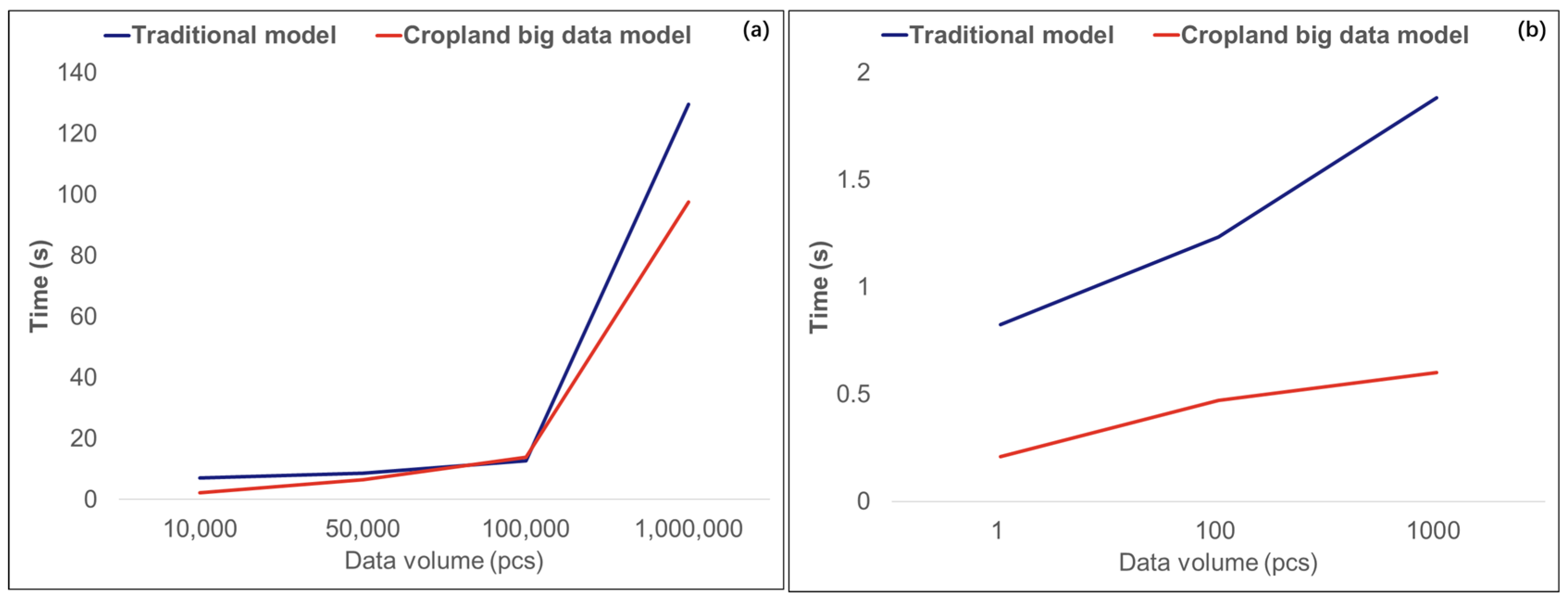
3.4. Effectiveness Analysis of Cropland Big Data Fusion Model
4. Discussion
4.1. Effectiveness of Cropland Big Data Fusion Model
4.2. Factors Affecting the Efficiency of Cropland Big Data Fusion Model
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Tao, F.; Liu, J. Changes in quantity and quality of cropland and the implications for grain production in the Huang-Huai-Hai Plain of China. Food Secur. 2013, 5, 69–82. [Google Scholar] [CrossRef]
- Löw, F.; Biradar, C.; Dubovyk, O.; Fliemann, E.; Akramkhanov, A.; Narvaez Vallejo, A.; Waldner, F. Regional-scale monitoring of cropland intensity and productivity with multi-source satellite image time series. GISci. Remote Sens. 2018, 55, 539–567. [Google Scholar] [CrossRef]
- Breunig, M.; Bradley, P.E.; Jahn, M.; Kuper, P.; Mazroob, N.; Rösch, N.; Al-Doori, M.; Stefanakis, E.; Jadidi, M. Geospatial data management research: Progress and future directions. ISPRS Int. J. Geo-Inf. 2020, 9, 95. [Google Scholar] [CrossRef]
- Robertson, C.; Chaudhuri, C.; Hojati, M.; Roberts, S.A. An integrated environmental analytics system (IDEAS) based on a DGGS. ISPRS J. Photogramm. Remote Sens. 2020, 162, 214–228. [Google Scholar] [CrossRef]
- Su, Y.; Zhong, Y.; Zhu, Q.; Zhao, J. Urban scene understanding based on semantic and socioeconomic features: From high-resolution remote sensing imagery to multi-source geographic datasets. ISPRS J. Photogramm. Remote Sens. 2021, 179, 50–65. [Google Scholar] [CrossRef]
- Gao, F.; Yue, P.; Cao, Z.; Zhao, S.; Shangguan, B.; Jiang, L.; Hu, L.; Fang, Z.; Liang, Z. A multi-source spatio-temporal data cube for large-scale geospatial analysis. Int. J. Geogr. Inf. Sci. 2022, 36, 1853–1884. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, C.; Miao, S. A Precise Urban Component Management Method Based on the GeoSOT Grid Code and BIM. ISPRS Int. J. Geo-Inf. 2019, 8, 159. [Google Scholar] [CrossRef]
- Zhu, J.; Liu, Z.; Qiao, D. Construction and Optimization of Spatial Indexing Model for Massive Geospatial Data Based on HBase. Geosci. Technol. Bull. 2019, 38, 253–260. [Google Scholar]
- Franch-Pardo, I.; Napoletano, B.M.; Rosete-Verges, F.; Billa, L. Spatial analysis and GIS in the study of COVID-19. A review. Sci. Total Environ. 2020, 739, 140033. [Google Scholar] [CrossRef]
- Chen, Y. Research on Cultivated Land Quality Evaluation Method Based on Multi-Scale Indicator System in Grid Environment; China Agricultural University: Beijing, China, 2015. [Google Scholar]
- Shen, L.; Zhang, C.; Sang, L.; Chen, Y.; Zhang, X.; Yang, J.; Zhu, D.; Yun, W. Prioritizing County Farmland Improvement Using a Grid Approach. J. Agric. Eng. 2012, 28, 241–247+296. [Google Scholar]
- Chen, Y.; Yang, J.; Xun, W.; Zhang, C.; Zhu, D.; Xiang, Q. A grid-based method for provincial aggregation of cropland quality grading results. J. Agric. Eng. 2014, 30, 280–287. [Google Scholar]
- Li, S.; He, F.; Zhang, X. A spatially explicit reconstruction of cropland cover in China from 1661 to 1996. Reg. Environ. Change 2016, 16, 417–428. [Google Scholar] [CrossRef]
- He, F.; Yang, F.; Zhao, C.; Li, S.; Li, M. Spatially explicit reconstruction of cropland cover for China over the past millennium. Sci. China Earth Sci. 2023, 66, 111–128. [Google Scholar] [CrossRef]
- Yang, T.; Siddique, K.H.; Liu, K. Cropping systems in agriculture and their impact on soil health-A review. Glob. Ecol. Conserv. 2020, 23, e01118. [Google Scholar] [CrossRef]
- Liu, C.; Song, C.; Ye, S.; Cheng, F.; Zhang, L.; Li, C. Estimate provincial-level effectiveness of the arable land requisition-compensation balance policy in mainland China in the last 20 years. Land Use Policy 2023, 131, 106733. [Google Scholar] [CrossRef]
- Li, X.; Li, H.; Yang, L.; Ren, Y. Assessment of soil quality of croplands in the Corn Belt of Northeast China. Sustainability 2018, 10, 248. [Google Scholar] [CrossRef]
- Kazemi, H.; Akinci, H. A land use suitability model for rainfed farming by Multi-criteria Decision-making Analysis (MCDA) and Geographic Information System (GIS). Ecol. Eng. 2018, 116, 1–6. [Google Scholar] [CrossRef]
- Kakkar, D.; Lewis, B.; Guan, W. Interactive analysis of big geospatial data with high-performance computing: A case study of partisan segregation in the United States. Trans. GIS 2022, 26, 1633–1641. [Google Scholar] [CrossRef]
- Mete, M.O.; Yomralioglu, T. Implementation of serverless cloud GIS platform for land valuation. Int. J. Digit. Earth 2021, 14, 836–850. [Google Scholar] [CrossRef]
- Cravero, A.; Pardo, S.; Galeas, P.; López Fenner, J.; Caniupán, M. Data Type and Data Sources for Agricultural Big Data and Machine Learning. Sustainability 2022, 14, 16131. [Google Scholar] [CrossRef]
- Yao, X.; Mokbel, M.F.; Ye, S.; Li, G.; Alarabi, L.; Eldawy, A.; Zhao, Z.; Zhao, L.; Zhu, D. LandQv2: A MapReduce-Based System for Processing Cropland Quality Big Data. ISPRS Int. J. Geo Inf. 2018, 7, 271. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, W.; Ma, L.; Xu, H.; Chen, Y. Application and Development of Big Data in Sustainable Utilization of Soil and Land Resources. IEEE Access 2020, 8, 152751–152759. [Google Scholar] [CrossRef]
- Miao, S.; Cheng, C.; Ren, F.; Chen, B.; Tong, X.; Pu, G. A GIS Data Model Based on Global Subdivision Grid. Journal of Spatio-temporal Information 2020, 27, 22–29. [Google Scholar]
- Zhou, C.; Lu, H.; Xiang, Y.; Wu, J.; Wang, F. GeohashTile: Vector geographic data display method based on geohash. ISPRS Int. J. Geo Inf. 2020, 9, 418. [Google Scholar] [CrossRef]
- Li, L.; Hu, W.; Zhu, H.; Li, Y.; Zhang, H. Tiled vector data model for the geographical features of symbolized maps. PLoS ONE 2017, 12, e0176387. [Google Scholar] [CrossRef]
- Ritter, N.; Ruth, M. The GeoTiff data interchange standard for raster geographic images. Int. J. Remote Sens. 1997, 18, 1637–1647. [Google Scholar] [CrossRef]
- Ming, W.; Luo, X.; Luo, X.; Long, Y.; Xiao, X.; Ji, X.; Li, Y. Quantitative Assessment of Cropland Exposure to Agricultural Drought in the Greater Mekong Subregion. Remote Sens. 2023, 15, 2737. [Google Scholar] [CrossRef]
- Mori, T.; Smith, T.E.; Hsu, W.T. Common power laws for cities and spatial fractal structures. Proc. Natl. Acad. Sci. USA 2020, 117, 6469–6475. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Yu, L.; Xin, Q.; Gong, P.; Xu, B. How does urban expansion interact with cropland loss? A comparison of 14 Chinese cities from 1980 to 2015. Landsc. Ecol. 2021, 36, 243–263. [Google Scholar] [CrossRef]
- Ma, W.; Wei, F.; Zhang, J.; Karthe, D.; Opp, C. Green water appropriation of the cropland ecosystem in China. Sci. Total Environ. 2022, 806, 150597. [Google Scholar] [CrossRef]
- Tan, Q.; Geng, J.; Fang, H.; Li, Y.; Guo, Y. Exploring the Impacts of Data Source, Model Types and Spatial Scales on the Soil Organic Carbon Prediction: A Case Study in the Red Soil Hilly Region of Southern China. Remote Sens. 2022, 14, 5151. [Google Scholar] [CrossRef]
- Deng, J.; Qiu, L.; Wang, K.; Yang, H.; Shi, Y.Y. An integrated analysis of urbanization-triggered cropland loss trajectory and implications for sustainable land management. Cities 2011, 28, 127–137. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, H.; Jiang, X.; He, J. Evaluation of development potential of cropland in Central Asia. Ecol. Indic. 2022, 142, 109250. [Google Scholar] [CrossRef]
- Duan, D.; Sun, X.; Liang, S.; Sun, J.; Fan, L.; Chen, H.; Xia, L.; Zhao, F.; Yang, W.; Yang, P. Spatiotemporal patterns of cultivated land quality integrated with multi-source remote sensing: A case study of Guangzhou, China. Remote Sens. 2022, 14, 1250. [Google Scholar] [CrossRef]
- Li, Z.; Wang, L.; Zhou, X.; Tang, L.; Zhang, X.; Li, Y. HBase-based vector spatial data storage and query method and its application. Geosciences 2022, 7, 1146–1154. [Google Scholar] [CrossRef]
- Awiti, A.O.; Walsh, M.G.; Shepherd, K.D.; Kinyamario, J. Soil condition classification using infrared spectroscopy: A proposition for assessment of soil condition along a tropical forest-cropland chrono sequence. Geoderma 2008, 143, 73–84. [Google Scholar] [CrossRef]
- Li, Y.; Chang, C.; Wang, Z.; Li, T.; Li, J.; Zhao, G. Identification of Cultivated Land Quality Grade Using Fused Multi-Source Data and Multi-Temporal Crop Remote Sensing Information. Remote Sens. 2022, 14, 2109. [Google Scholar] [CrossRef]
- Tang, Y.; Fan, A.; Wang, Y.; Yao, Y. mDHT: A multi-level-indexed DHT algorithm to extra-large-scale data retrieval on HDFS/Hadoop architecture. Pers. Ubiquitous Comput. 2014, 18, 1835–1844. [Google Scholar] [CrossRef]
- Lu, N.; Cheng, C.; Jin, A.; Ma, H. An index and retrieval method of spatial data based on GeoSOT global discrete grid system. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, Australia, 21–26 July 2013. [Google Scholar]
- Zhao, C.; He, F.; Yang, F.; Li, S. Uncertainties of global historical land use scenarios in past-millennium cropland reconstruction in China. Quat. Int. 2022, 641, 87–96. [Google Scholar] [CrossRef]
- Wu, Z.; Fang, X.; Jia, D.; Zhao, W. Reconstruction of cropland cover using historical literature and settlement relics in farming areas of Shangjing Dao during the Liao Dynasty, China, around 1100 AD. Holocene 2020, 30, 1516–1527. [Google Scholar] [CrossRef]
- Klein Goldewijk, K.; Beusen, A.; Doelman, J.; Stehfest, E. Anthropogenic land use estimates for the Holocene—HYDE 3.2. Earth Syst. Sci. Data 2017, 9, 927–953. [Google Scholar] [CrossRef]
- Kaplan, J.O.; Krumhardt, K.M.; Gaillard, M.J.; Sugita, S.; Trondman, A.K.; Fyfe, R.; Marquer, L.; Mazier, F.; Nielsen, A.B. Constraining the deforestation history of Europe: Evaluation of historical land use scenarios with pollen-based land cover reconstructions. Land 2017, 6, 91. [Google Scholar] [CrossRef]
- Xu, H. Research on mass monitoring data Retrieval Technology based on HBase. In Proceedings of the 2021 6th International Symposium on Advances in Electrical, Nanjing, China, 12–14 March 2021. [Google Scholar]
- Firozjaei, M.K.; Sedighi, A.; Firozjaei, H.K.; Kiavarz, M.; Homaee, M.; Arsanjani, J.J.; Makki, M.; Naimi, B.; Alavipanah, S.K. A historical and future impact assessment of mining activities on surface biophysical characteristics change: A remote sensing-based approach. Ecol. Indic. 2021, 122, 107264. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, Y.; Li, Q.; Xu, T.; Wu, Z.; Liu, J. Application of three deep machine-learning algorithms in a construction assessment model of farmland quality at the county scale: Case study of Xiangzhou, Hubei Province, China. Agriculture 2021, 11, 72. [Google Scholar] [CrossRef]
- Chen, D.; Chang, N.; Xiao, J.; Zhou, Q.; Wu, W. Mapping dynamics of soil organic matter in croplands with MODIS data and machine learning algorithms. Sci. Total Environ. 2019, 669, 844–855. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yu, L.; Wang, W. Hilbert space filling curve based scould-order for point cloud attribute compression. IEEE Trans. Image Process. 2022, 31, 4609–4621. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Wang, Y.; Liu, Z.; Dai, S. Improving NoSQL storage schema based on Z-curve for spatial vector data. IEEE Access 2019, 7, 78817–78829. [Google Scholar] [CrossRef]
- Zhou, J.; Ben, J.; Wang, R.; Zheng, M.; Du, L. Lattice quad-tree indexing algorithm for a hexagonal discrete global grid system. ISPRS Int. J. Geo Inf. 2020, 9, 83. [Google Scholar] [CrossRef]
- Sun, L.; Jin, B. Improving NoSQL Spatial-Query Processing with Server-Side In-Memory R*-Tree Indexes for Spatial Vector Data. Sustainability 2023, 15, 2442. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Data | Data Format |
|---|---|---|
| Farming conditions | Cropland patch | Shapefile (Polygons) |
| Topographic slope | Raster | |
| Soil fertility | Soil type | Shapefile (Polygons) |
| Organic matter | Shapefile (Point) | |
| Convenience of farming | Rural roads, highways, rivers, ditches | Shapefile (Polylines) |
| Level of agricultural production capacity | Crop production in 2019 | CSV |
| Level of agricultural construction | Level of mechanization in 2019 | CSV |
| Level of modernization in 2019 | CSV |
| Accuracy | Scale | Area (ha) | Number of Grids (Pcs) |
|---|---|---|---|
| Geohash4 | 39.1 km × 19.5 km | 76,245 | 12 |
| Geohash5 | 4.89 km × 4.89 km | 2391.21 | 230 |
| Geohash6 | 1.22 km × 0.61 km | 744.42 | 6882 |
| Geohash7 | 153 m × 153 m | 2.3409 | 209,805 |
| Geohash8 | 38.2 m × 19.1 m | 0.0729 | 6,689,053 |
| Geohash9 | 4.77 m × 4.77 m | 0.002275 | ≈200,000.000 |
| Indicator | Minimum | Maximum | Mean | Standard Deviation | First Quartile | Median | Third Quartile | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|
| Cropland area (ha) | 0.000122 | 812.728446 | 6.946133 | 14.813213 | 1.492834 | 3.963701 | 8.856711 | 28.2 | 1205.4 |
| Terrain slope (%) | 0.000674 | 37.98 | 3.03 | 2.37 | 1.38 | 2.39 | 3.9 | 2.05 | 10.2 |
| Organic matter (g·kg−1) | 5 | 45 | 15.09 | 6.86 | 16 | 16 | 16 | 0.5 | 5.1 |
| Distance of rural roads from cropland (m) | 0 | 11,355.87 | 1332.27 | 1697.85 | 226.02 | 724.34 | 1714.11 | 2.15 | 8 |
| Distance of highway from cropland (m) | 0 | 24,049.08 | 5371.09 | 5019.89 | 1103.8 | 3983.14 | 8351.14 | 0.94 | 3 |
| Distance of ditch from cropland (m) | 0 | 24,495.1 | 2802.74 | 3472.35 | 663.56 | 1640.08 | 3533.7 | 2.7 | 12.2 |
| Distance of river from cropland (m) | 0 | 26,281.53 | 10,337.91 | 6955.96 | 4083.51 | 9409.12 | 15,857.45 | 0.38 | 2 |
| Indicator Layer | Weight | Indicator | Weight | Hierarchy | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||||
| Farming conditions | 0.24347 | Cropland area (ha) | 0.875 | Range | 0–1.4928 | 1.4928–3.9637 | 3.9637–8.8567 | 8.8567–812.7284 |
| Terrain slope (%) | 0.125 | >20 | 10–20 | 5–10 | 0–5 | |||
| Soil fertility | 0.5251 | Soil type | 0.143 | Wind sand and sandy soil | Soda and salted soil | Calcareous soil | Meadow soils and black calcareous soils | |
| Organic matter (g·kg−1) | 0.857 | 0–5 | 5–16 | 16–45 | - | |||
| Convenience of farming | 0.13373 | Distance from rural road to cropland (m) | 0.554 | 1714.11–11,355.87 | 724.34–1714.11 | 226.02–724.34 | 0–226.02 | |
| Distance from highway to cropland (m) | 0.089 | 8351.14–24,049.08 | 3983.14–8351.14 | 1103.8–3983.14 | 0–1103.8 | |||
| Distance from river to cropland (m) | 0.308 | 15857.45–26,281.53 | 9409.12–15,857.45 | 4083.51–9409.12 | 0–4083.51 | |||
| Distance from ditch to cropland (m) | 0.049 | 3533.7–24,495.1 | 1640.08–3533.7 | 663.56–1640.08 | 0–663.56 | |||
| Level of agricultural production capacity | 0.06622 | Level of modernization in 2019 | 1 | - | - | - | - | - |
| Level of agricultural construction | 0.03149 | Level of modernization in 2019 | 0.8 | - | - | - | - | - |
| Level of modernization in 2019 | 0.2 | - | - | - | - | - | ||
| Type | Highest | Higher | Medium | Lower | Lowest | Total | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Number (pcs) | Proportion (%) | Number (pcs) | Proportion (%) | Number (pcs) | Proportion (%) | Number (pcs) | Proportion (%) | Number (pcs) | Proportion (%) | ||
| Dry cropland | 1362 | 2 | 6700 | 9.85 | 18,386 | 27.04 | 25874 | 38.05 | 15682 | 23.06 | 68,004 |
| Irrigated cropland | 535 | 3.24 | 2584 | 15.65 | 5544 | 33.58 | 5343 | 32.36 | 2506 | 15.18 | 16,512 |
| Paddy cropland | 181 | 2.65 | 464 | 6.83 | 3179 | 46.78 | 2290 | 33.7 | 682 | 10.04 | 6796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, S.; Wang, S.; Huang, C.; Xia, X.; Sang, L.; Huang, J.; Liu, H.; Zhang, Z.; Zhang, J.; Huang, X.; et al. A Big Data Grided Organization and Management Method for Cropland Quality Evaluation. Land 2023, 12, 1916. https://doi.org/10.3390/land12101916
Miao S, Wang S, Huang C, Xia X, Sang L, Huang J, Liu H, Zhang Z, Zhang J, Huang X, et al. A Big Data Grided Organization and Management Method for Cropland Quality Evaluation. Land. 2023; 12(10):1916. https://doi.org/10.3390/land12101916
Chicago/Turabian StyleMiao, Shuangxi, Shuyu Wang, Chunyan Huang, Xiaohong Xia, Lingling Sang, Jianxi Huang, Han Liu, Zheng Zhang, Junxiao Zhang, Xu Huang, and et al. 2023. "A Big Data Grided Organization and Management Method for Cropland Quality Evaluation" Land 12, no. 10: 1916. https://doi.org/10.3390/land12101916