
Towards an Efficient Rainfall–Runoff Model through Partitioning Scheme

Abstract
:1. Introduction
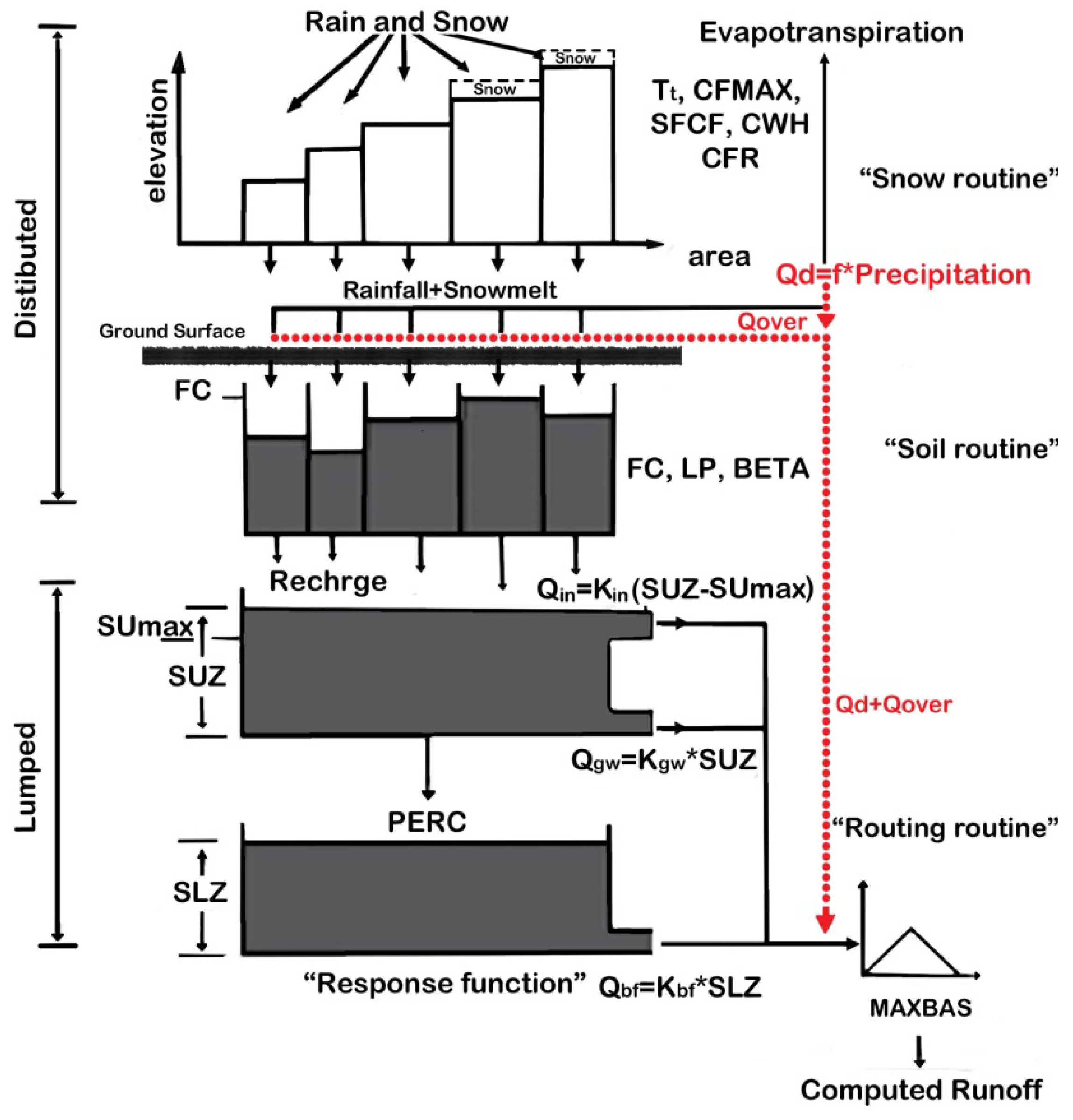
2. Improved HBV Model Description
3. Methodology
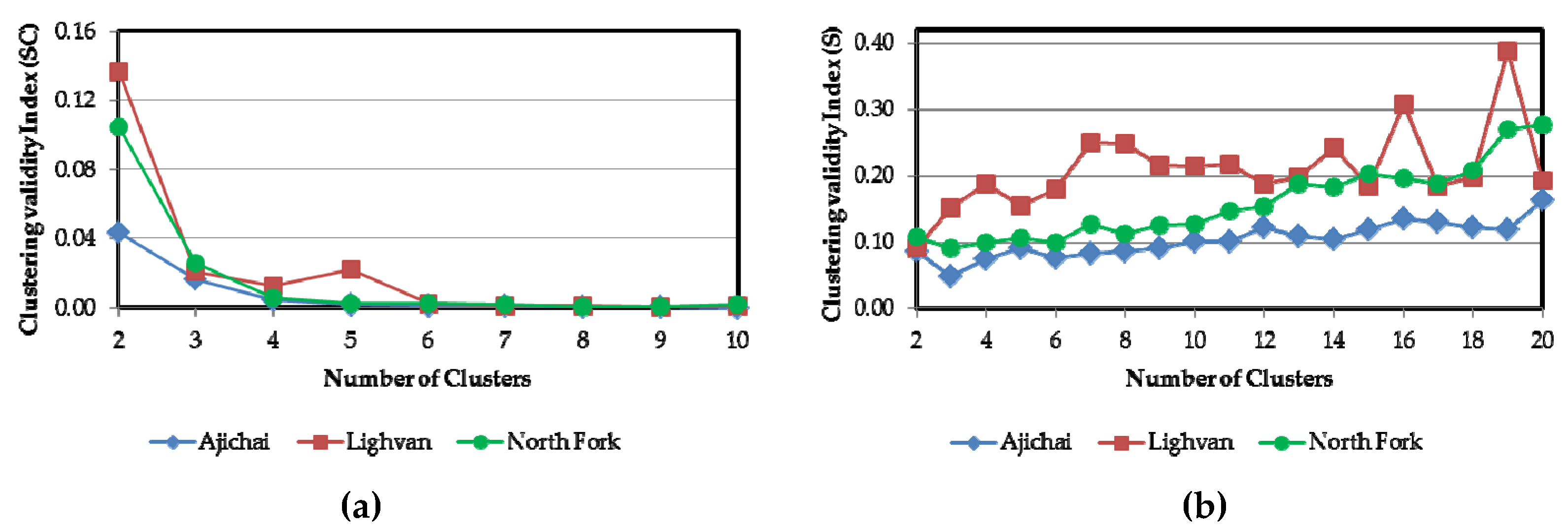
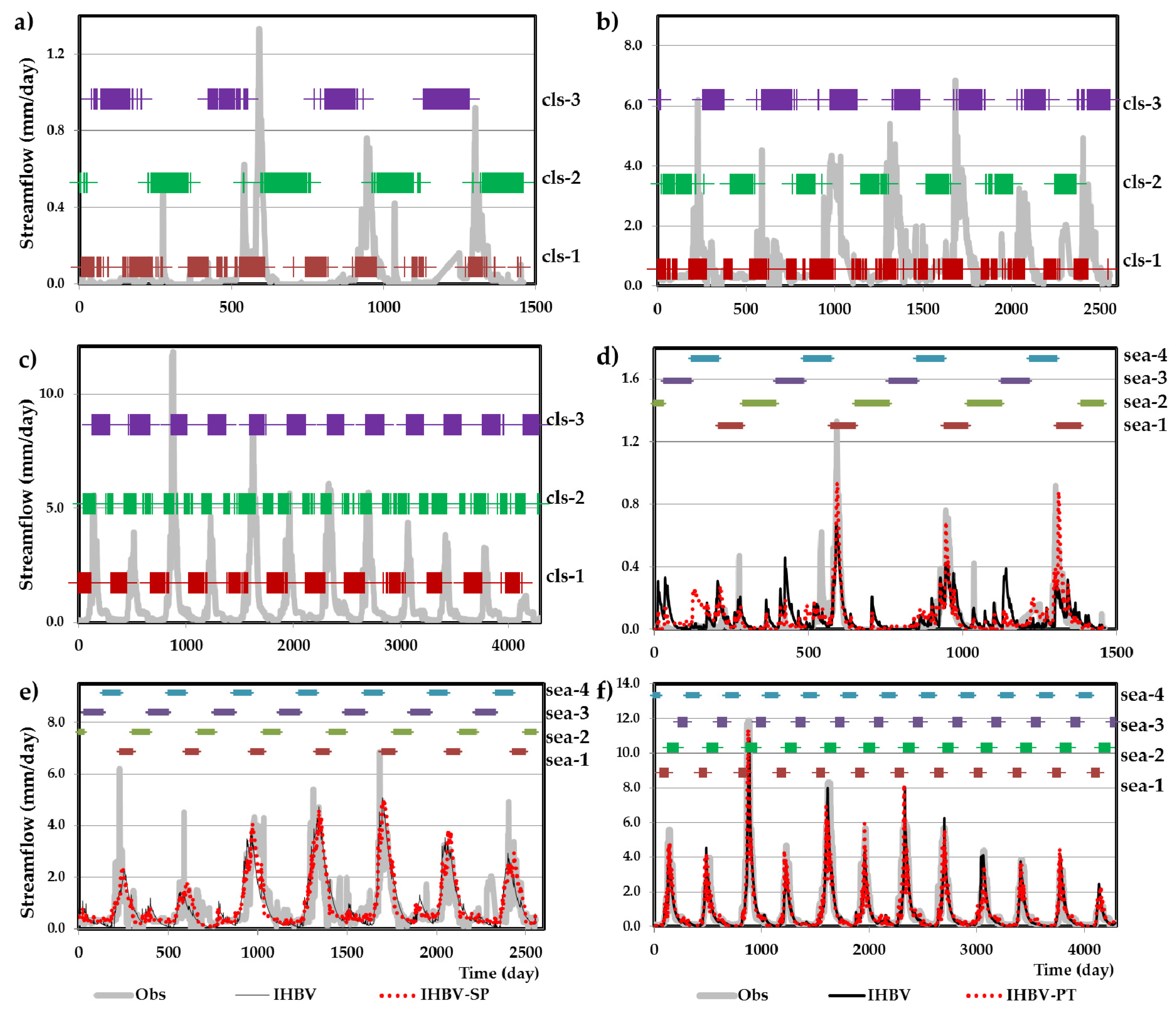
3.1. Clustering Analysis FCM
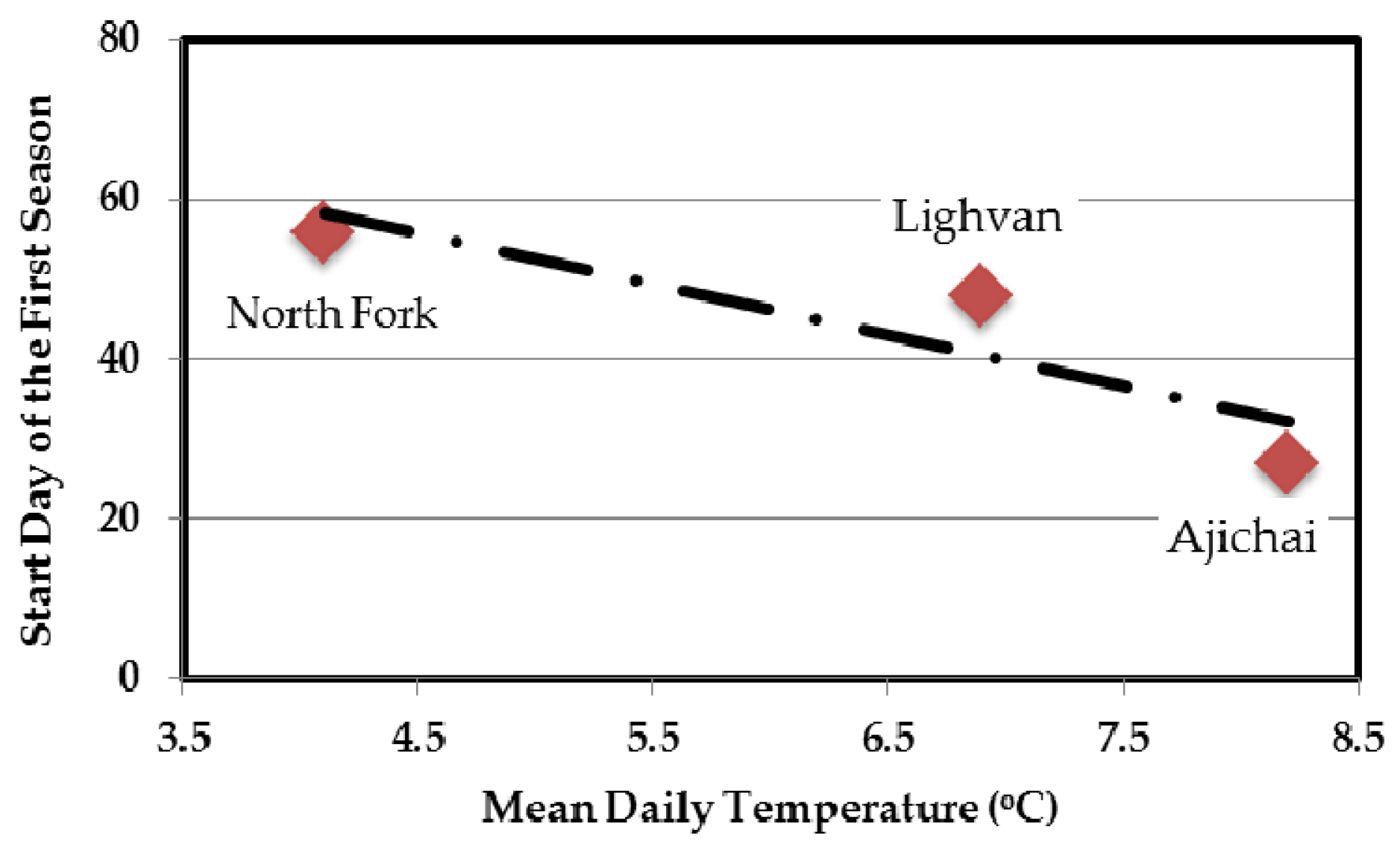
3.2. Seasonal Partitioning (SP) Scheme
3.3. Model Preparation Process
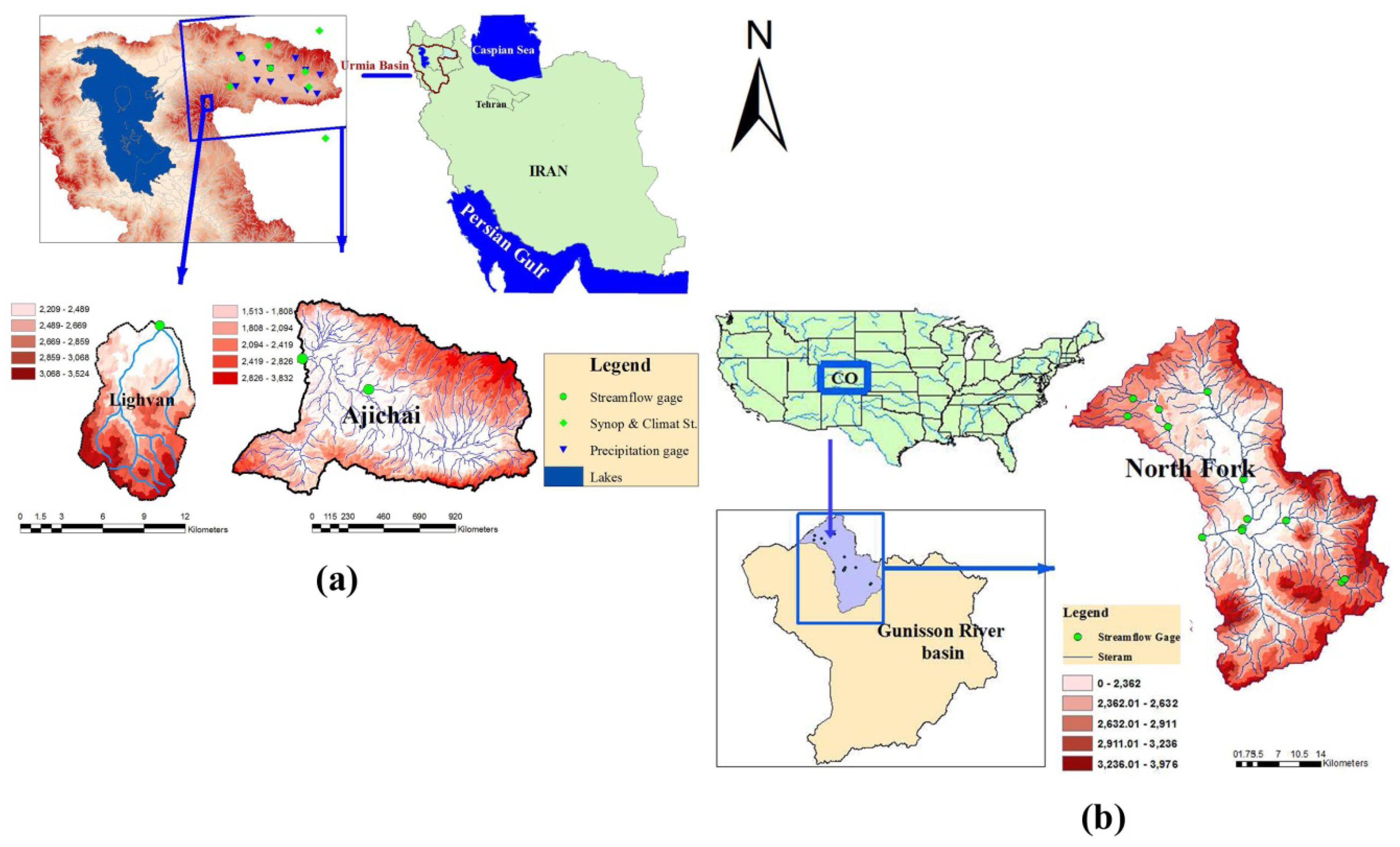
4. Study Areas
5. Results and Discussions
5.1. Sensitivity Analysis Results
5.2. Data Partitioning Through FCM and SP
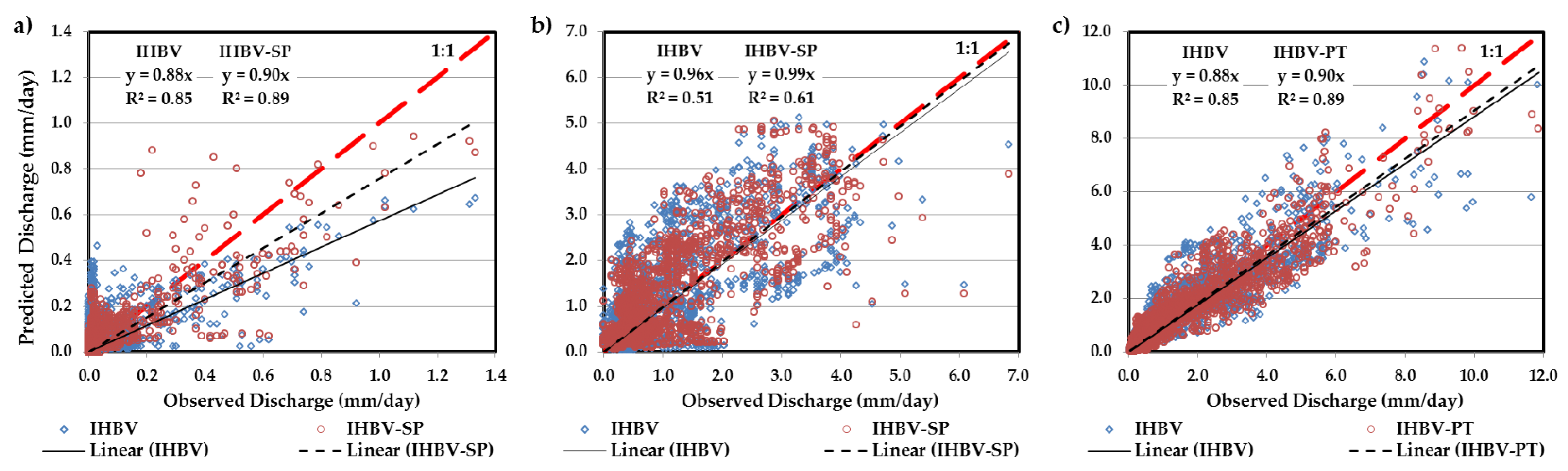
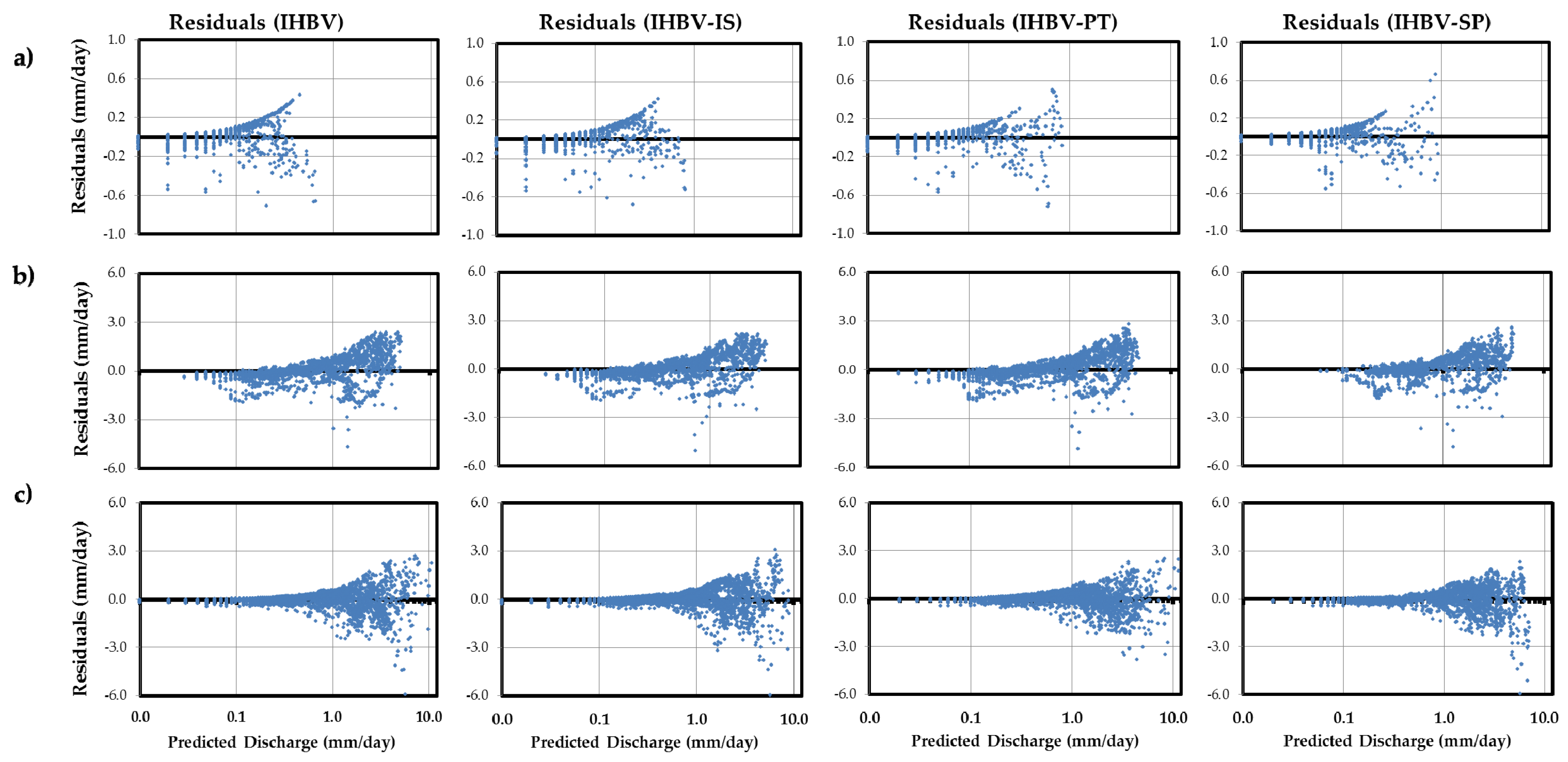
5.3. Comparison of Results
6. Conclusions
Acknowledgment
Author Contributions
Conflicts of Interest
References
- Wheater, H.; Sorooshian, S.; Sharma, K.D. Hydrological Modelling in Arid and Semi-Arid Areas; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Manley, R. Simulation of flows in ungauged basins/simulation d'écoulement sur les bassins versants non jaugés. Hydrol. Sci. J. 1978, 23, 85–101. [Google Scholar] [CrossRef]
- Wagener, T.; Wheater, H.S.; Gupta, H.V. Rainfall-Runoff Modelling in Gauged and Ungauged Catchments; Imperial College Press: Londen, UK, 2004. [Google Scholar]
- Loucks, D.P.; Van Beek, E.; Stedinger, J.R.; Dijkman, J.P.; Villars, M.T. Water Resources Systems Planning and Management: An Introduction to Methods, Models and Applications; United Nations Educational, Scientific and Cultural Organization (UNESCO): Paris, France, 2005. [Google Scholar]
- Moore, R. Real-Time Flood Forecasting Systems: Perspectives and Prospects; Springer: New York, NY, USA, 1999. [Google Scholar]
- Parkin, G.; O'donnell, G.; Ewen, J.; Bathurst, J.; O'Connell, P.; Lavabre, J. Validation of catchment models for predicting land-use and climate change impacts. 2. Case study for a mediterranean catchment. J. Hydrol. 1996, 175, 595–613. [Google Scholar] [CrossRef]
- Yu, P.-S.; Yang, T.-C.; Wu, C.-K. Impact of climate change on water resources in southern Taiwan. J. Hydrol. 2002, 260, 161–175. [Google Scholar] [CrossRef]
- Shrestha, D.L. Uncertainty Analysis in Rainfall-Runoff Modelling: Application of Machine Learning Techniques. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2009. [Google Scholar]
- Lee, H.; McIntyre, N.; Wheater, H.; Young, A. Selection of conceptual models for regionalisation of the rainfall-runoff relationship. J. Hydrol. 2005, 312, 125–147. [Google Scholar] [CrossRef]
- Gourley, J.J.; Vieux, B.E. A method for identifying sources of model uncertainty in rainfall-runoff simulations. J. Hydrol. 2006, 327, 68–80. [Google Scholar] [CrossRef]
- Straten, G.; Keesman, K.J. Uncertainty propagation and speculation in projective forecasts of environmental change: A lake-eutrophication example. J. For. 1991, 10, 163–190. [Google Scholar] [CrossRef]
- Efstratiadis, A.; Koutsoyiannis, D. One decade of multi-objective calibration approaches in hydrological modelling: A review. Hydrol. Sci. J. 2010, 55, 58–78. [Google Scholar] [CrossRef]
- Kim, Y.; Chung, E.-S.; Won, K.; Gil, K. Robust parameter estimation framework of a rainfall-runoff model using Pareto optimum and minimax regret approach. Water 2015, 7, 1246. [Google Scholar] [CrossRef]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Toward improved calibration of hydrologic models: Multiple and noncommensurable measures of information. Water Resour. Res. 1998, 34, 751–763. [Google Scholar] [CrossRef]
- Yang, J.; Reichert, P.; Abbaspour, K.C.; Xia, J.; Yang, H. Comparing uncertainty analysis techniques for a SWAT application to the Chaohe basin in China. J. Hydrol. 2008, 358, 1–23. [Google Scholar] [CrossRef]
- Abbaspour, K.C.; Yang, J.; Maximov, I.; Siber, R.; Bogner, K.; Mieleitner, J.; Zobrist, J.; Srinivasan, R. Modelling hydrology and water quality in the pre-alpine/alpine Thur watershed using SWAT. J. Hydrol. 2007, 333, 413–430. [Google Scholar] [CrossRef]
- Choi, H.T.; Beven, K. Multi-period and multi-criteria model conditioning to reduce prediction uncertainty in an application of topmodel within the GLUE framework. J. Hydrol. 2007, 332, 316–336. [Google Scholar] [CrossRef]
- Beven, K.; Binely, A. The future of distributed model: Calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- Jung, Y.; Merwade, V.; Kim, S.; Kang, N.; Kim, Y.; Lee, K.; Kim, G.; Kim, H.S. Sensitivity of subjective decisions in the GLUE methodology for quantifying the uncertainty in the flood inundation map for Seymour reach in Indiana, USA. Water 2014, 6, 2104–2126. [Google Scholar] [CrossRef]
- Xiong, L.; Shamseldin, A.Y.; O'Connor, K.M. A non-linear combination of the forecastes of rainfall-runoff models by the first-order Takagi-Sugeno fuzzy system. J. Hydrol. 2001, 245, 196–217. [Google Scholar] [CrossRef]
- Ajami, N.K.; Duan, Q.; Sorooshian, S. An integrated hydrologic bayesian multimodel combination framework: Confronting input, parameter, and model structural uncertainty in hydrologic prediction. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Duan, Q.; Ajami, N.K.; Gao, X.; Sorooshian, S. Multi-model ensemble hydrologic prediction using bayesian model averaging. Adv. Water Resour. 2007, 30, 1371–1386. [Google Scholar] [CrossRef]
- Duan, Q.; Gupta, V.K.; Sorooshian, S. Shuffled complex evolution approach for effective and efficient global minimization. J. Optimization Theory Appl. 1993, 76, 501–521. [Google Scholar] [CrossRef]
- Liu, Y. Automatic calibration of a rainfall–runoff model using a fast and elitist multi-objective particle swarm algorithm. Expert Syst. Appl. 2009, 36, 9533–9538. [Google Scholar] [CrossRef]
- Seong, C.; Her, Y.; Benham, B.L. Automatic calibration tool for hydrologic simulation program-fortran using a shuffled complex evolution algorithm. Water 2015, 7, 503–527. [Google Scholar] [CrossRef]
- Gan, T.Y.; Biftu, G.F. Automatic calibration of conceptual rainfall-runoff models: Optimization algorithms, catchment conditions, and model structure. Water Resour. Res. 1996, 32, 3513–3524. [Google Scholar] [CrossRef]
- Abbaspour, K.; Johnson, C.; Van Genuchten, M.T. Estimating uncertain flow and transport parameters using a sequential uncertainty fitting procedure. Vadose Zone J. 2004, 3, 1340–1352. [Google Scholar] [CrossRef]
- Berhanu, B.; Seleshi, Y.; Demisse, S.S.; Melesse, A.M. Flow regime classification and hydrological characterization: A case study of ethiopian rivers. Water 2015, 7, 3149–3165. [Google Scholar] [CrossRef]
- Ferket, B.V.A.; Samain, B.; Pauwels, V.R.N. Internal validation of conceptual rainfall–runoff models using baseflow separation. J. Hydrol. 2010, 381, 158–173. [Google Scholar] [CrossRef]
- Wagener, T.; McIntyre, N.; Lees, M.; Wheater, H.; Gupta, H. Towards reduced uncertainty in conceptual rainfall-runoff modelling: Dynamic identifiability analysis. Hydrol. Process. 2003, 17, 455–476. [Google Scholar] [CrossRef]
- Boyle, D.P.; Gupta, H.V.; Sorooshian, S. Toward improved calibration of hydrologic models: Combining the strengths of manual and automatic methods. Water Resour. Res. 2000, 36, 3663–3674. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.M. Refining Initial Points for K-Means Clustering. In Proceedings of the International Conference on Machine Learning (ICML 98), Madison, WI, USA, 1998; pp. 91–99.
- Vos, N.J.D.; Rientjes, T.H.M.; Gupta, H.V. Diagnostic evaluation of conceptual rainfall–runoff models using temporal clustering. Hydrol. Process. 2010, 24, 2840–2850. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W. Prediction of rainfall time series using modular soft computing methods. Eng. Appl. Artif. Intell. 2012, 26, 997–1007. [Google Scholar] [CrossRef]
- Bezdek, J.C. Cluster validity with fuzzy sets. J. Cybern. 1973, 3, 58–73. [Google Scholar] [CrossRef]
- Fleming, M.; Neary, V. Continuous hydrologic modeling study with the hydrologic modeling system. J. Hydrol. Eng. 2004, 9, 175–183. [Google Scholar] [CrossRef]
- Nilsson, P.; Uvo, C.B.; Berndtsson, R. Monthly runoff simulation: Comparing and combining conceptual and neural network models. J. Hydrol. 2006, 321, 344–363. [Google Scholar] [CrossRef]
- Garbrecht, J.D. Comparison of three alternative ann designs for monthly rainfall-runoff simulation. J. Hydrol. Eng. 2006, 11, 502–505. [Google Scholar] [CrossRef]
- Seasholtz, M.B.; Kowalski, B. The parsimony principle applied to multivariate calibration. Anal. Chim. Acta 1993, 277, 165–177. [Google Scholar] [CrossRef]
- Lindström, G.; Johansson, B.; Persson, M.; Gardelin, M.; Bergström, S. Development and test of the distributed HBV-96 hydrological model. J. Hydrol. 1997, 201, 272–288. [Google Scholar] [CrossRef]
- Abebe, N.A.; Ogden, F.L.; Pradhan, N.R. Sensitivity and uncertainty analysis of the conceptual HBV rainfall–runoff model: Implications for parameter estimation. J. Hydrol. 2010, 389, 301–310. [Google Scholar] [CrossRef]
- Seibert, J. Regionalisation of parameters for a conceptual rainfall-runoff model. Agric. For. Meteorol. 1999, 98, 279–293. [Google Scholar] [CrossRef]
- Seibert, J. HBV Light, Version 2, User’s Manual; Department of Physical Geography and Quaternary Geology, Stockholm University: Stockholm, Sweden, 2005. [Google Scholar]
- HBV Light Model; software for catchment runoff simulation; University of Zurich (UZH): Zurich, Switherland. Available online: http://www.geo.uzh.ch/en/units/h2k/services/hbv-model (accessed on 5 July 2014).
- Jeon, J.-H.; Park, C.-G.; Engel, B.A. Comparison of performance between genetic algorithm and SCE-UA for calibration of SCS-CN surface runoff simulation. Water 2014, 6, 3433–3456. [Google Scholar] [CrossRef]
- Rawls, W.J.; Brakensiek, D.L.; Miller, N. Green-Ampt infiltration parameters from soils data. J. Hydraulic Eng. 1983, 109, 62–70. [Google Scholar] [CrossRef]
- Hock, R. Temperature index melt modelling in mountain areas. J. Hydrol. 2003, 282, 104–115. [Google Scholar] [CrossRef]
- Li, X.; William, M.W. Snowmelt runoff modelling in an arid mountain watershed, Tarim Basin, China. Hydrol. Process. 2008, 22, 3931–3940. [Google Scholar] [CrossRef]
- Braun, L.N.; Renner, C.B. Application of a conceptual runoff model indifferent physiographic regions of Switzerland. Hydrol. Sci. J. 1992, 37, 217–231. [Google Scholar] [CrossRef]
- Seibert, J. Conceptual Runoff Models—Fiction or Representation of Reality? Ph.D. Thesis, Uppsala University, Uppsala, Sweden, 1999. [Google Scholar]
- Vis, M.; Knight, R.; Pool, S.; Wolfe, W.; Seibert, J. Model calibration criteria for estimating ecological flow characteristics. Water 2015, 7, 2358–2381. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Bensaid, A.M.; Hall, L.O.; Bezdek, J.C.; Clarke, L.P.; Silbiger, M.L.; Arrington, J.A.; Murtagh, R.F. Validity-guided (re) clustering with applications to image segmentation. IEEE Trans.Fuzzy Syst. 1996, 4, 112–123. [Google Scholar] [CrossRef]
- Xie, X.L.; Beni, G. A validity measure for fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Shrestha, D.L.; Solomatine, D.P. Data-driven approaches for estimating uncertainty in rainfall-runoff modelling. Intl. J. River Basin Manag. 2008, 6, 109–122. [Google Scholar] [CrossRef]
- Schaake, J.; Cong, S.; Duan, Q. The USA MOPEX data set. IAHS Publ. 2006, 307, 9. [Google Scholar]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting throligh conceptual models part I—A disclission of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of "goodness-of-fit" measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Scharffenberg, W.; Ely, P.; Daly, S.; Fleming, M.; Pak, J. Hydrologic modeling system (HEC-HMS): Physically-based simulation components. In Proceedings of the 2nd Joint Federal Interagency Conference, Las Vegas, NV, USA, 27 June–1 July 2010; p. 8.
- Her, Y.; Chaubey, I. Impact of the numbers of observations and calibration parameters on equifinality, model performance, and output and parameter uncertainty. Hydrol. Process. 2015, 29, 4220–4237. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K.P. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Sorooshian, S.; Dracup, J.A. Stochastic parameter estimation procedures for hydrologie rainfall-runoff models: Correlated and heteroscedastic error cases. Water Resour. Res. 1980, 16, 430–442. [Google Scholar] [CrossRef]
- Xu, C. Statistical analysis of parameters and residuals of a conceptual water balance model—Methodology and case study. Water Resour. Manag. 2001, 15, 75–92. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Ashrafi, S.; Dariane, A. Performance evaluation of an improved harmony search algorithm for numerical optimization: Melody Search (MS). Eng. Appl. Artif. Intell. 2013, 26, 1301–1321. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Kossieris, P.; Efstratiadis, A.; Makropoulos, C. Surrogate-enhanced evolutionary annealing simplex algorithm for effective and efficient optimization of water resources problems on a budget. Environ. Model. Softw. 2016, 77, 122–142. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Unit | Range |
|---|---|---|---|
| Snow Routine: | |||
| Tt | Threshold Temperature | [°C] | −2.0–3.0 |
| Cfmax | Degree-Day factor | [mm/(°C day)] | 0.0–10.0 |
| SFCF | Snowfall correction factor | [-] | 0.5–1.5 |
| CFR | Refreezing coefficient | [-] | 0.0–1.0 |
| CWH | Water holding capacity | [-] | 0.0–6.0 |
| gama | Correction factor | [-] | 0.0–0.5 |
| Soil Routine: | |||
| Ks | Conductivity coefficient | [mm/day] | 0.0–200 |
| ns | = | [mm] | 0.1–0.6 |
| FC | Maximum of soil moisture (SM) | [mm] | 0.1–900.0 |
| cep | Evaporation correction factor | [-] | 0.0–1.0 |
| beta | Shape coefficient | [-] | 0.0–7.5 |
| LP | Threshold for reduction of evaporation (SM/FC) | [-] | 0.0–1.0 |
| Response Routine: | |||
| SUmax | Threshold for Kin-outflow | [mm] | 5.0–1000.0 |
| Perc | Maximal flow from upper to lower box | [mm/day] | 0.0–15.0 |
| Kin | Recession coefficient (Upper storage) | [1/day] | 0.0–10.0 |
| Kgw | Recession coefficient 1 (Lower storage) | [1/day] | 0.0–0.2 |
| Kbf | Recession coefficient 2 (Lower storage) | [1/day] | 0.0–0.2 |
| MaxBas | Routing, length of weighting function | [day] | 1.0–10.0 |
| Description | Basin Name | ||
|---|---|---|---|
| Ajichai | Lighvan | North Fork | |
| Locations | Urmia Basin, East Azerbaijan, Iran | Urmia Basin, East Azerbaijan, Iran | North Fork Gunnison River, CO, USA |
| Latitude | 37°45’–38°19’ N | 37°45’–37°50’ N | 38°42’–39°15’ N |
| Longitude | 46°48’–47°52’ E | 46°25’–46°26’ E | 107°05’–107°41’ W |
| Minimum Altitude | 1513 | 2140 | 1914 |
| Maximum Altitude | 3832 | 3620 | 3976 |
| Area, km2 | 5660.0 | 76.5 | 1362.3 |
| Annual Precipitation, mm | 410.8 | 396.1 | 674.6 |
| Annual Runoff, mm | 25.5 | 329.4 | 278.3 |
| Annual Pot. Evaporation, mm | 988.9 | 1201.8 | 1015.7 |
| Mean Annual Temperature, °C | 8.2 | 6.9 | 4.1 |
| Data Period | 1 Oct 1999–30 Sep 2012 | 1 Oct 1979–30 Sep 2006 | 1 Oct 1948–30 Sep 2002 |
| Calibration Period | 1 Oct 1999–30 Sep 2008 | 1 Oct 1979–30 Sep 1998 | 1 Oct 1948–31 Dec 1990 |
| Validation Period | 1 Oct 2008–30 Sep 2012 | 1 Oct 1999–30 Sep 2006 | 1 Jan 1991–30 Sep 2002 |
| Name | Equation | Range | |
|---|---|---|---|
| 1 | Nash-Sutcliffe Efficiency | -∞ To 1 | |
| 2 | Root Mean Square Error | 0 To +∞ | |
| 3 | Peak-Weighted Root Mean Square Error | 0 To +∞ | |
| 4 | High Flow Weighted NSE | -∞ To 1 | |
| 5 | Low Flow Weighted NSE | -∞ To 1 | |
| 6 | Determination Coefficient | 0 To 1 | |
| Clusters | FCMMethod | Calibration NSE | Test NSE | ||||
|---|---|---|---|---|---|---|---|
| Ajichai | Lighvan | North Fork | Ajichai | Lighvan | North Fork | ||
| 2 | IS | 0.42 | 0.67 | 0.81 | 0.58 | 0.13 | 0.87 |
| 2 | PT | 0.51 | 0.68 | 0.83 | 0.49 | 0.39 | 0.87 |
| 3 | IS | 0.52 | 0.68 | 0.82 | 0.58 | 0.44 | 0.85 |
| 3 | PT | 0.58 | 0.64 | 0.85 | 0.53 | 0.41 | 0.89 |
| 4 | IS | 0.57 | 0.68 | 0.80 | 0.31 | 0.41 | 0.85 |
| 4 | PT | 0.54 | 0.67 | 0.87 | 0.57 | 0.34 | 0.87 |
| Evaluation Index | Ajichai | Lighvan | North Fork | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HBV-Light | IHBV | IHBV-IS | IHBV-PT | IHBV-SP | HBV-Light | IHBV | IHBV-IS | IHBV-PT | IHBV-SP | HBV-Light | IHBV | IHBV-IS | IHBV-PT | IHBV-SP | |
| I. Calibration Period | |||||||||||||||
| NSE | 0.56 | 0.42 | 0.52 | 0.60 | 0.73 | 0.57 | 0.66 | 0.68 | 0.64 | 0.72 | 0.76 | 0.79 | 0.82 | 0.85 | 0.83 |
| RMSE | 0.12 | 0.13 | 0.12 | 0.11 | 0.09 | 0.67 | 0.59 | 0.58 | 0.61 | 0.54 | 0.66 | 0.62 | 0.57 | 0.53 | 0.56 |
| RMSE-PW | 0.30 | 0.35 | 0.34 | 0.27 | 0.22 | 0.90 | 0.81 | 0.81 | 0.87 | 0.76 | 1.16 | 1.05 | 0.98 | 0.88 | 1.00 |
| NSE-HFW | −1.88 | -3.02 | -2.65 | -1.38 | −0.50 | 0.22 | 0.37 | 0.37 | 0.28 | 0.44 | 0.27 | 0.40 | 0.47 | 0.57 | 0.45 |
| NSE-LFW | 0.63 | 0.51 | 0.60 | 0.65 | 0.77 | 0.63 | 0.71 | 0.73 | 0.70 | 0.76 | 0.80 | 0.82 | 0.85 | 0.86 | 0.85 |
| R2 | 0.57 | 0.42 | 0.52 | 0.60 | 0.73 | 0.63 | 0.67 | 0.70 | 0.66 | 0.73 | 0.76 | 0.79 | 0.82 | 0.85 | 0.83 |
| II. Test Period | |||||||||||||||
| NSE | 0.33 | 0.42 | 0.56 | 0.58 | 0.65 | 0.28 | 0.36 | 0.44 | 0.41 | 0.50 | 0.83 | 0.85 | 0.85 | 0.89 | 0.87 |
| RMSE | 0.12 | 0.11 | 0.09 | 0.09 | 0.08 | 0.76 | 0.71 | 0.67 | 0.68 | 0.63 | 0.56 | 0.51 | 0.51 | 0.45 | 0.48 |
| RMSE-PW | 0.23 | 0.19 | 0.16 | 0.18 | 0.15 | 0.89 | 0.88 | 0.85 | 0.84 | 0.80 | 1.01 | 0.88 | 0.87 | 0.74 | 0.86 |
| NSE-HFW | −1.57 | -0.91 | −0.31 | −0.71 | −0.17 | 0.00 | 0.02 | 0.10 | 0.10 | 0.20 | 0.44 | 0.57 | 0.58 | 0.69 | 0.59 |
| NSE-LFW | 0.42 | 0.48 | 0.61 | 0.65 | 0.69 | 0.32 | 0.41 | 0.49 | 0.46 | 0.54 | 0.86 | 0.87 | 0.87 | 0.90 | 0.89 |
| R2 | 0.35 | 0.43 | 0.57 | 0.60 | 0.66 | 0.60 | 0.53 | 0.60 | 0.57 | 0.62 | 0.83 | 0.85 | 0.85 | 0.89 | 0.87 |
| Basin | K | H-test | ||||
|---|---|---|---|---|---|---|
| IHBV | IHBV-IS | IHBV-PT | IHBV-SP | |||
| Ajichai | 5 | 9.49 | 134.0 | 138.4 | 56.4 | 8.0 |
| Lighvan | 5 | 9.49 | 546.4 | 547.1 | 484.8 | 662.8 |
| North Fork | 3 | 5.99 | 20.3 | 33.5 | 1.4 | 1.0 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dariane, A.B.; Javadianzadeh, M.M. Towards an Efficient Rainfall–Runoff Model through Partitioning Scheme. Water 2016, 8, 63. https://doi.org/10.3390/w8020063
Dariane AB, Javadianzadeh MM. Towards an Efficient Rainfall–Runoff Model through Partitioning Scheme. Water. 2016; 8(2):63. https://doi.org/10.3390/w8020063
Chicago/Turabian StyleDariane, Alireza B., and Mohamad M. Javadianzadeh. 2016. "Towards an Efficient Rainfall–Runoff Model through Partitioning Scheme" Water 8, no. 2: 63. https://doi.org/10.3390/w8020063