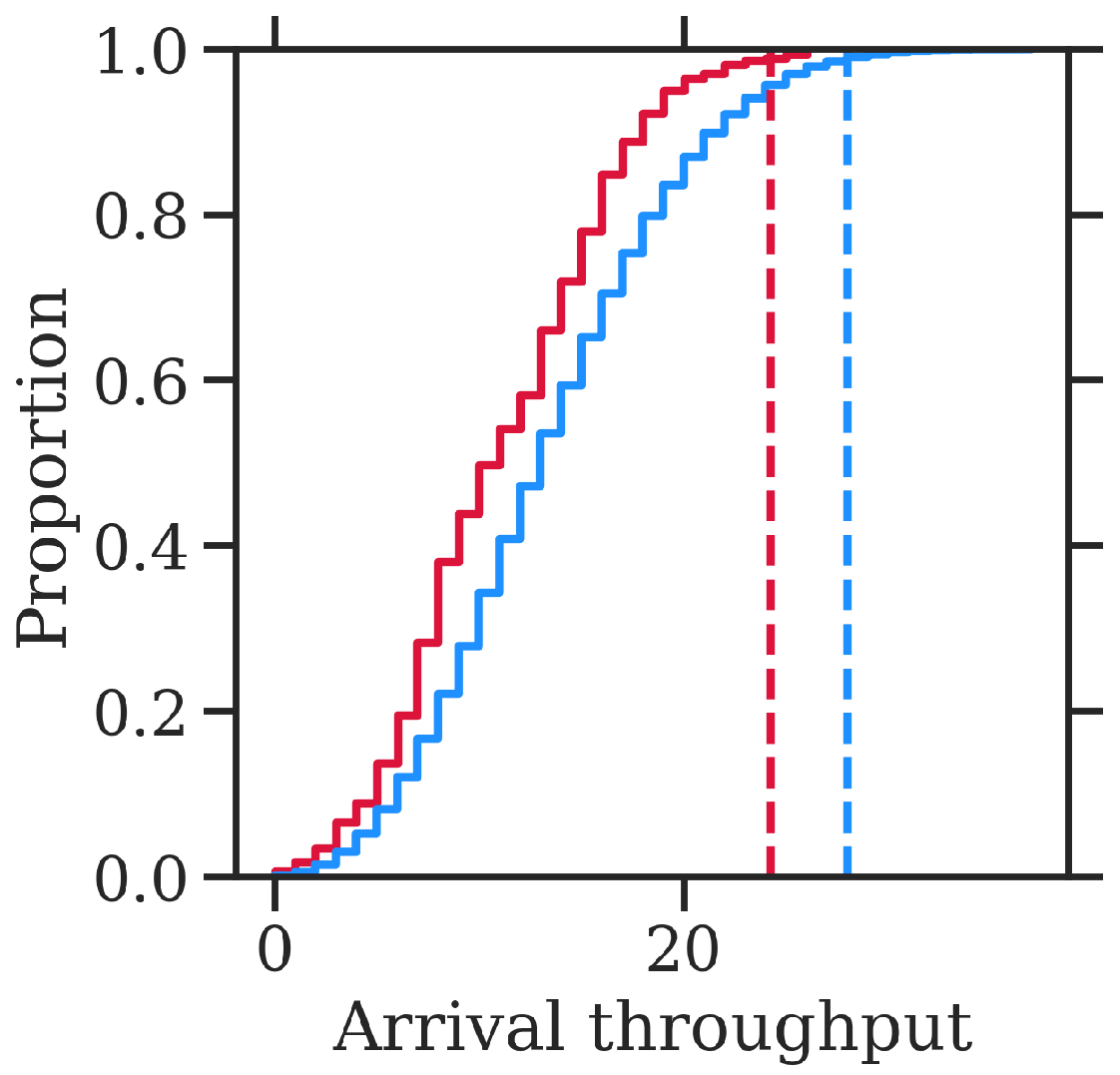
The target of each observation (
y) is the delivered throughput (i.e., the number of movements per hour), based on which the model attempts to learn the 99th percentile conditioned on the vector of input features.
Section 3.1.1 describes the calculation of the target from the traffic data. The vector of input features is composed of (1) the runway configuration in use during the time window of the observation and (2) various numerical and categorical features describing the weather conditions prevailing at that time.
Section 3.1.2 and
Section 3.1.3 describe the inference of the runway configuration from traffic data and the extraction of the weather conditions from meteorological reports, respectively.
3.1.2. Runway Configuration
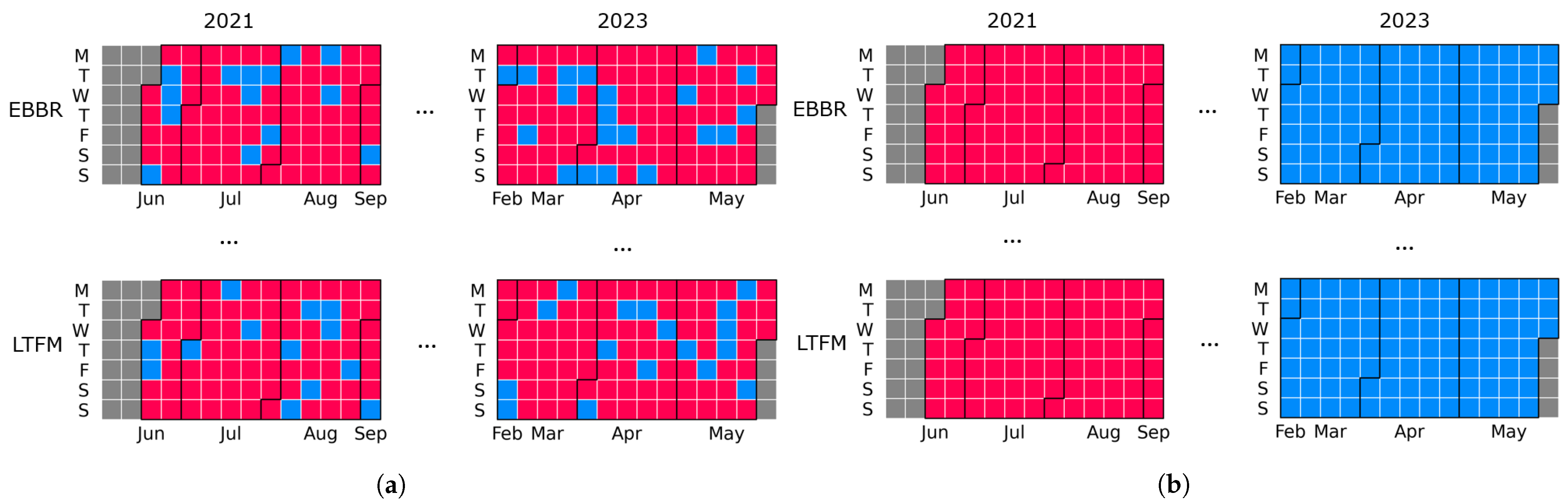
Let the term runways in use refer to the set of runways where movements were observed during a specific time window and runway configuration refer to an official combination of runways that can be utilised according to the airport. For instance, when the runway configuration is 14/16 and 28, runway 14 can be utilised for arrivals, and runways 16 and 28 can be used for departures. However, there might be situations in which, during a specific time window with the runway configuration 14/16 of 28, no movement is observed on runway 28; that is, the runways in use are 14/16, while the runway configuration is 14/16 and 28.
The identification of the runways in use is a straightforward process when the arrival and departure runways of each flight are included in the traffic data. In cases in which such information is not readily available, it can be extracted from trajectory data (like ADS-B) using the
takeoff_from_runway and
aligned_on_ils methods implemented in
traffic [
12]. Thanks to this open-source tool, runway identification becomes feasible even in situations in which explicit runway information per movement is not available.
Assuming the runway used for each movement at the airport (arrival or departure) is known, the next step is to identify the runways in use during the time window of each observation. The following process can be applied to determine the runways in use for each type of movement. If a runway is utilised (at least one movement is observed) within a given 15 min interval and is also used in at least two of the next three intervals, the runway use is considered sustained and associated with the runways in use for that type of movement in the rolling hour starting from the first interval.
The observed runways in use could be utilised to infer the most frequent runway configurations and to condition the machine learning model on them. However, it is essential to acknowledge that the observed runway configurations may not precisely match those officially defined by the airport. For instance, consider the previous example with runway 28 being consistently underutilised when the airport configuration is specified as 14/16 and 28. In such cases, this data-driven method may identify 14 and 16 as a new runway configuration, which actually corresponds to 14/16 and 28. Moreover, data-driven runway configurations might not align perfectly with those defined in the Airport Corner. Consequently, a direct comparison between the predicted capacities based on data-driven configurations and those specified in the Airport Corner may not be feasible. To address these issues, the observed combination of runways in use within each time window is matched to the most likely runway configuration as defined in the Airport Corner.
The matching process can be conducted by considering the runway configurations as defined in the Airport Corner as predictions of a hypothetical classifier (), while the observed runways in use are the ground truth (y). Each observation is then assigned the most similar prediction (i.e., runway configuration) that corresponds to the observed combination of runways in use. To determine the similarity between the observed runways in use and a runway configuration, multilabel classification metrics are employed.
Each combination of runways, whether runways in use or a runway configuration, can be represented as a binary vector. Each element in the vector represents the use (1) or non-use (0) of a specific runway for a particular type of movement. For example, consider the airport in Zurich, where the possible runways for arrivals are 14, 16, 28, 32, and 34, while runways 14, 28, and 34 can be used for departures. In this case, a combination of runways can be expressed as a binary vector of eight elements. The first element represents whether runway 14 was used for arrivals, the second nd element indicates whether runway 16 was used for arrivals, …, the sixth element indicates whether runway 14 was used for departures, etc. Then, basic metrics can be used to quantify the similarity between two vectors.
The precision and recall are two well-known metrics for assessing the quality of a classification task. In a multilabel classification task, the precision determines the ratio between the number of matched labels and the number of predicted labels:
whereas the recall is the ratio between the number of matched labels and the number of actual (observed) labels.
These two metrics can be combined using the
score, which is the weighted harmonic mean of precision and recall, reaching its optimal value at 1 and its worst value at 0:
where the
parameter represents the ratio of recall importance to precision importance. Specifically,
gives more weight to recall, while
favours precision.
In the problem being addressed, prioritising recall over precision is crucial. The assigned runway configuration must capture as many runways in use as possible, even if some of the predicted runways are not actually utilised. For this study, a value of
is proposed, giving recall twice the importance of precision. By using
, the matching process attempts to identify a larger proportion of the actual runways used while still taking precision into account in the overall assessment.
Table 3 shows the
score with
for the different runway configurations in
Table 1 when the observed combination of runways in use is runway 14 for arrivals and runway 16 for departures (i.e., 14/16).
In the process of identifying typical runway configurations, a minimum share (e.g., 5%) of the analysed time windows should be taken into account, as rare runway configurations are likely to be under-represented in the dataset; therefore, the estimation of the 99th percentile may not be reliable. The time window (i.e., observation) associated with rare runway configurations could be assigned the closest frequent runway configuration.
3.1.3. Weather Conditions
The weather conditions must be extracted from weather observations, as the objective of this paper is to model the cause–effect relationship. There is a common misunderstanding that machine models must always be trained with the same kind of data that will be used during prediction. For instance, when predicting the airport capacity several hours in advance, one might argue that weather observations are unsuitable for training because the actual weather will only be known in the future. In such cases, only the expected weather can be available from TAFs at the time of prediction. Therefore, training a model with the TAFs available at the time of prediction may seem to be a more appropriate approach.
Nevertheless, a model trained on TAFs does not effectively learn the impact of weather on capacity, the reason being that it was not the weather forecast that directly impacted the capacity but the actual weather conditions prevailing at that specific time. To accurately capture the relationship between weather and capacity, it is necessary to train the model using the actual weather observations (e.g., as reported in METARs) that were in effect during the times when capacity measurements were taken. Training the model on TAFs would result in a model that attempts to capture the forecast error of TAFs.
The raw METARs can be processed using
metafora (
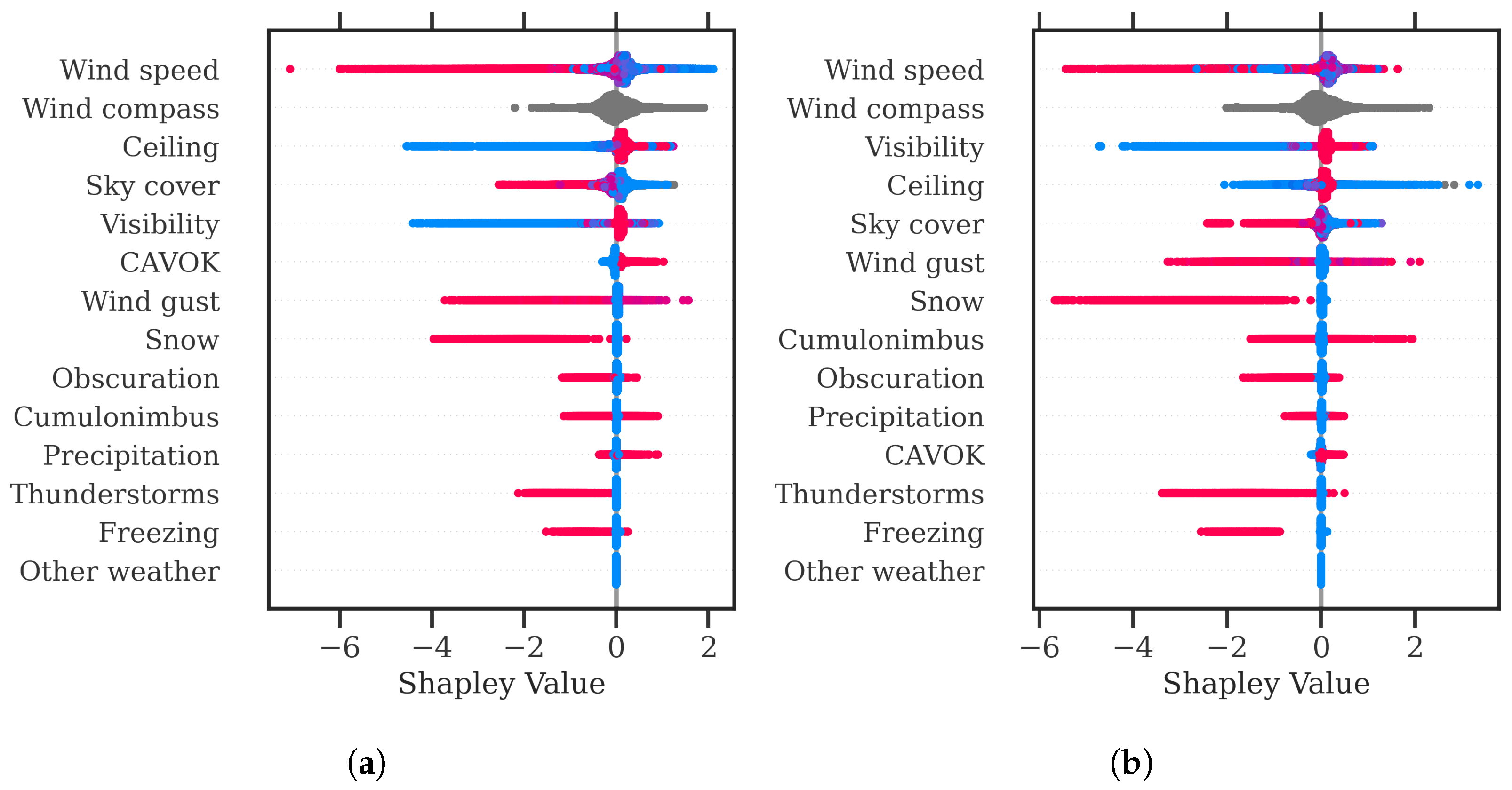
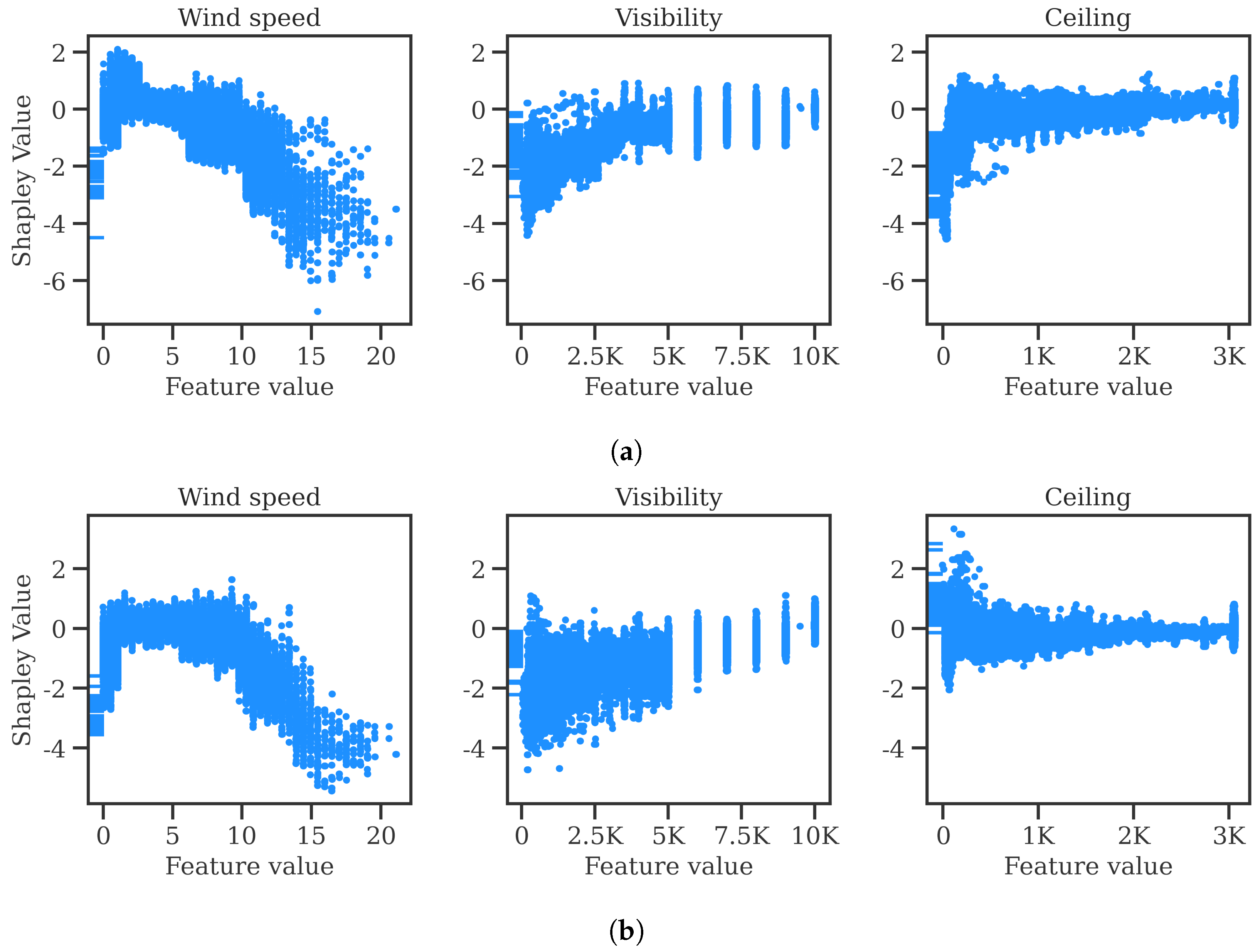
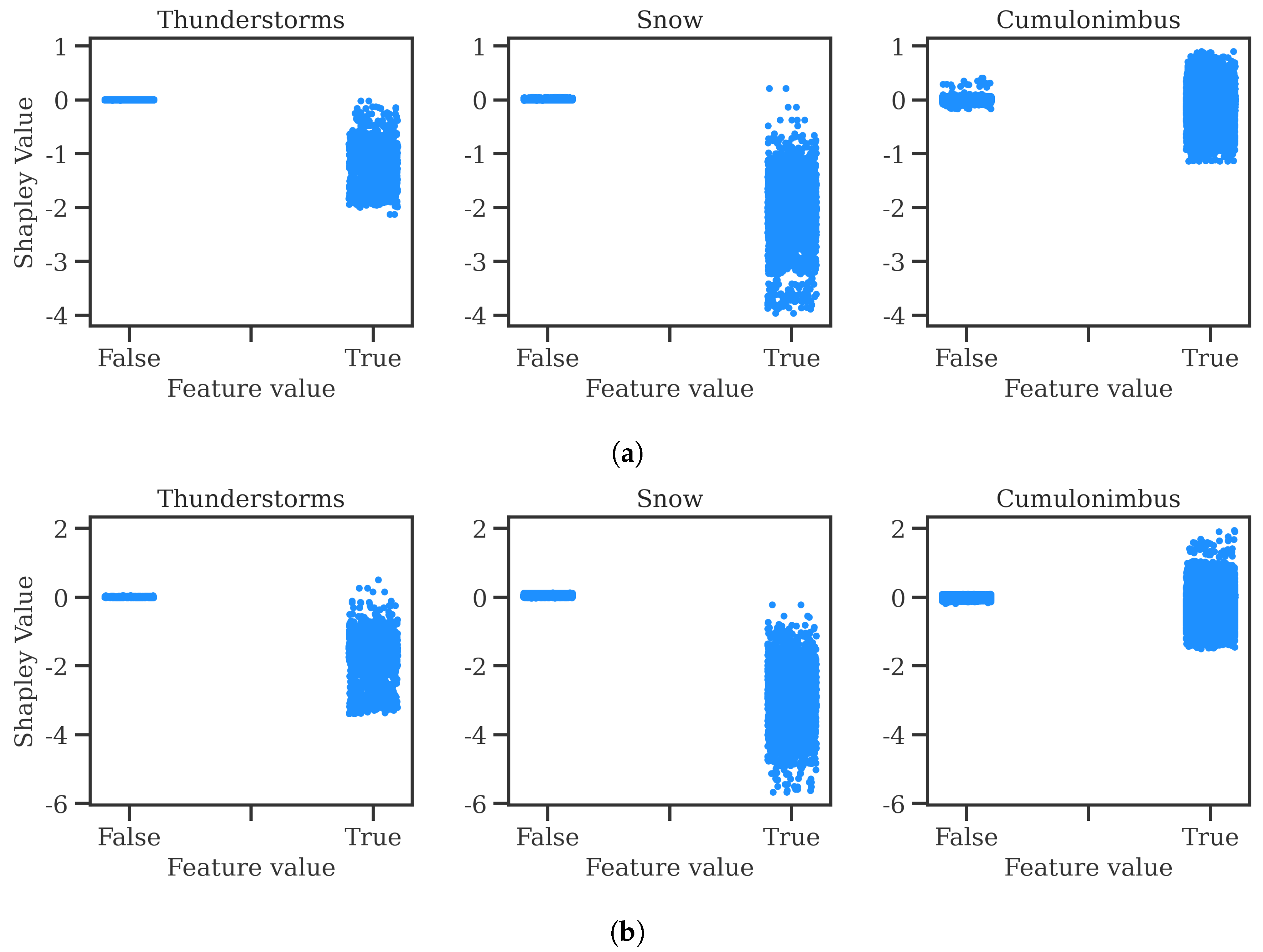
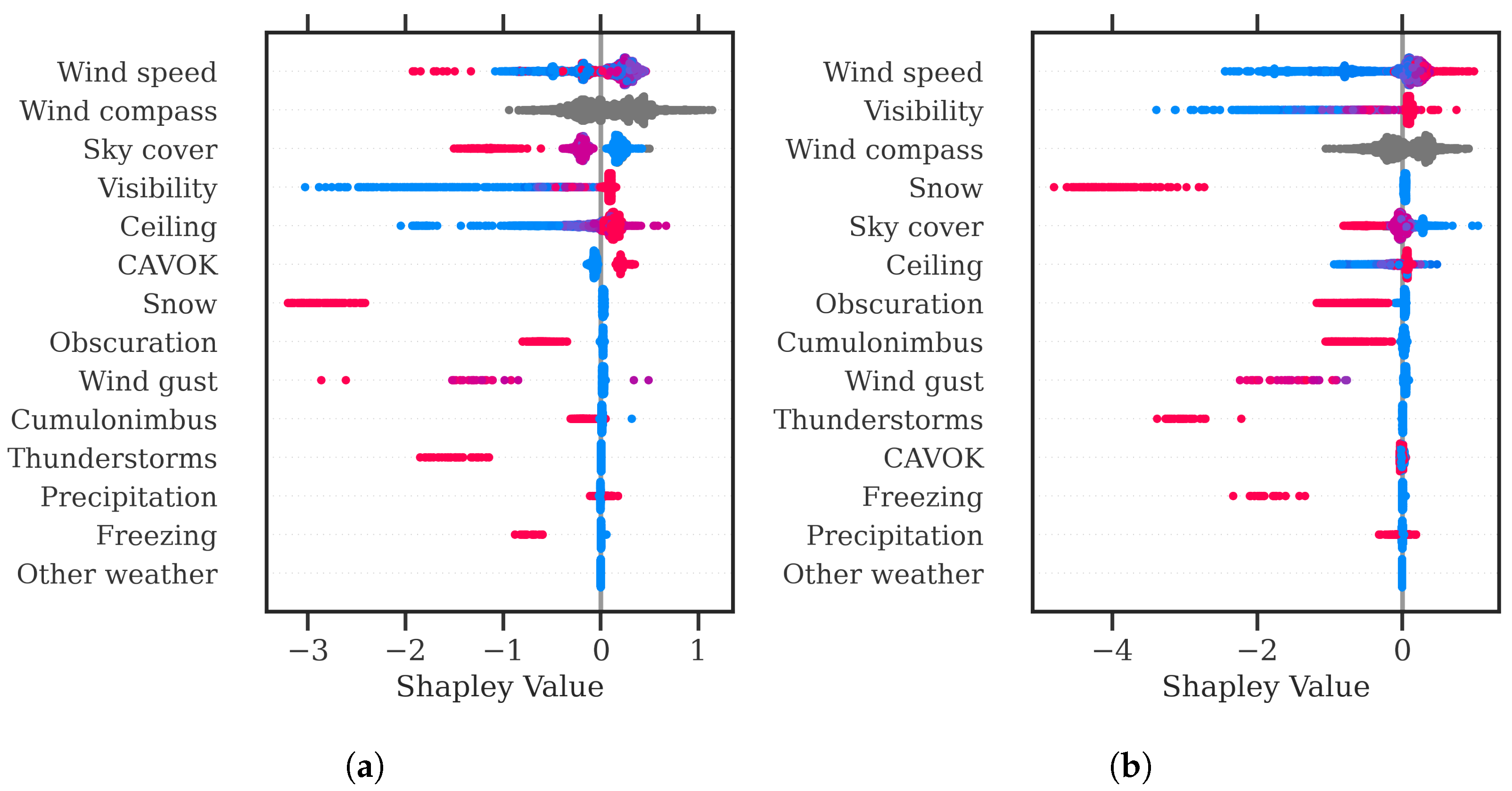
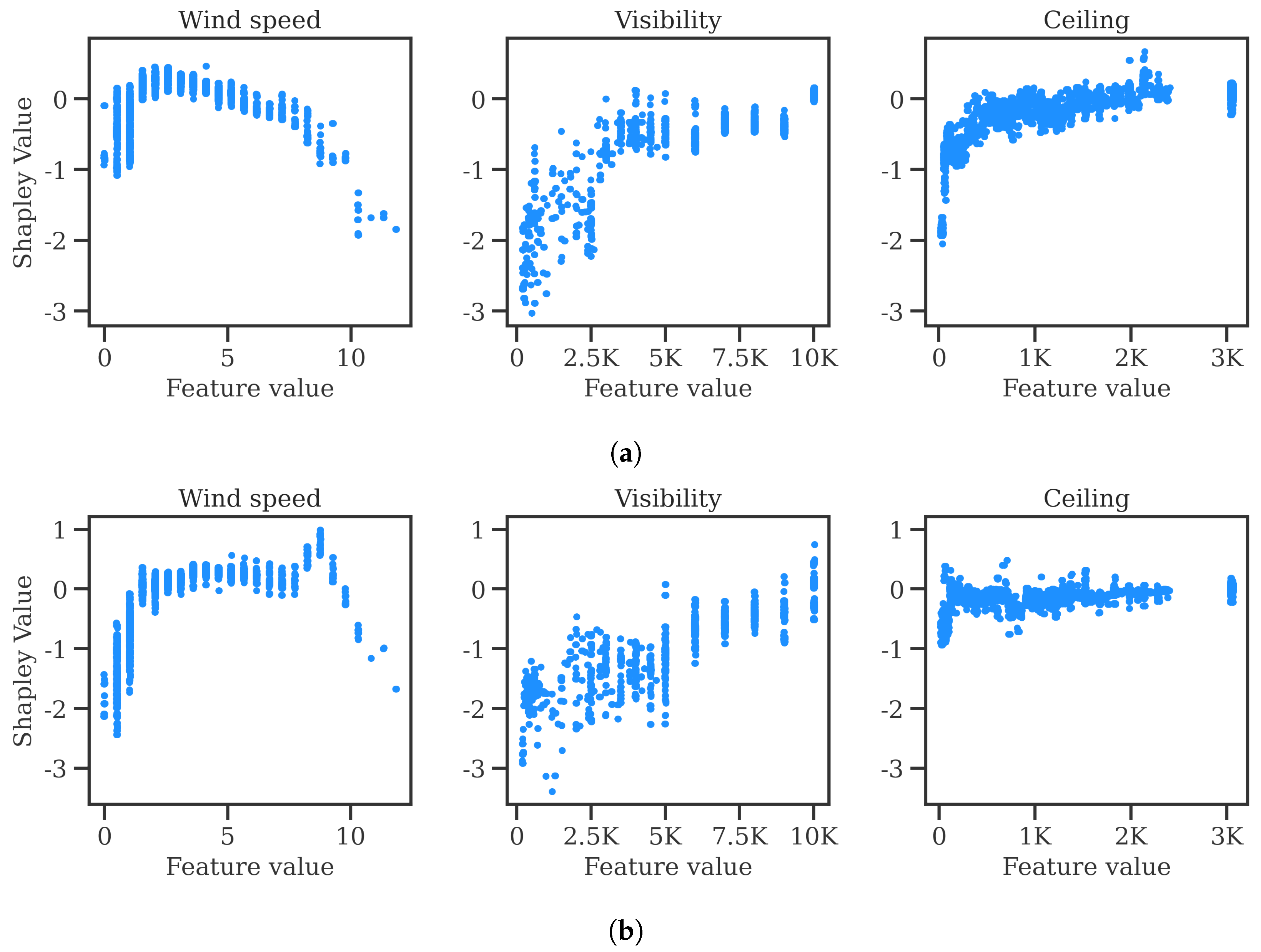
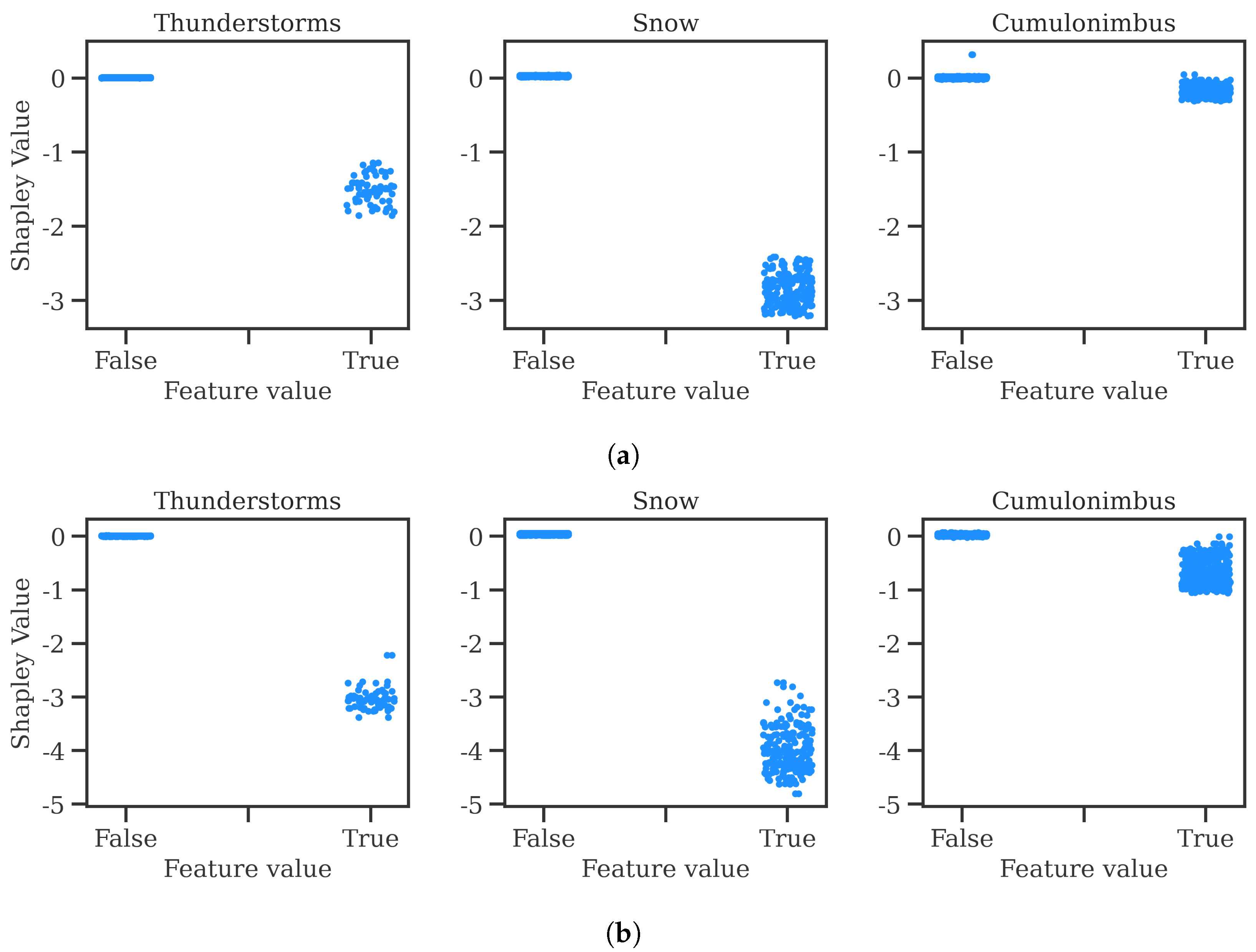
https://github.com/ramondalmau/metafora, accessed on 28 July 2023), an open-source tool specifically designed to transform textual meteorological reports into a vector representation including numerical and categorical features suitable for machine learning. For each METAR, the following features can be extracted: wind compass, speed, and gust; presence/absence of precipitation, obscuration, thunderstorms, freezing phenomena, snow, cumulonimbus, or other (rare) weather phenomena such as tornadoes or volcanic hash; CAVOK status; sky cover in oktas; and the specific visibility and ceiling in meters.
Finally, each observation must be assigned the vector representing the weather conditions of the METAR report released after and closest to the start time of the corresponding 1 h time window. This approach ensures that each observation is associated with the most relevant weather information available at the time of the corresponding time window.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}