
Learning Calibration Functions on the Fly: Hybrid Batch Online Stacking Ensembles for the Calibration of Low-Cost Air Quality Sensor Networks in the Presence of Concept Drift


Abstract
:1. Introduction
2. Materials and Methods
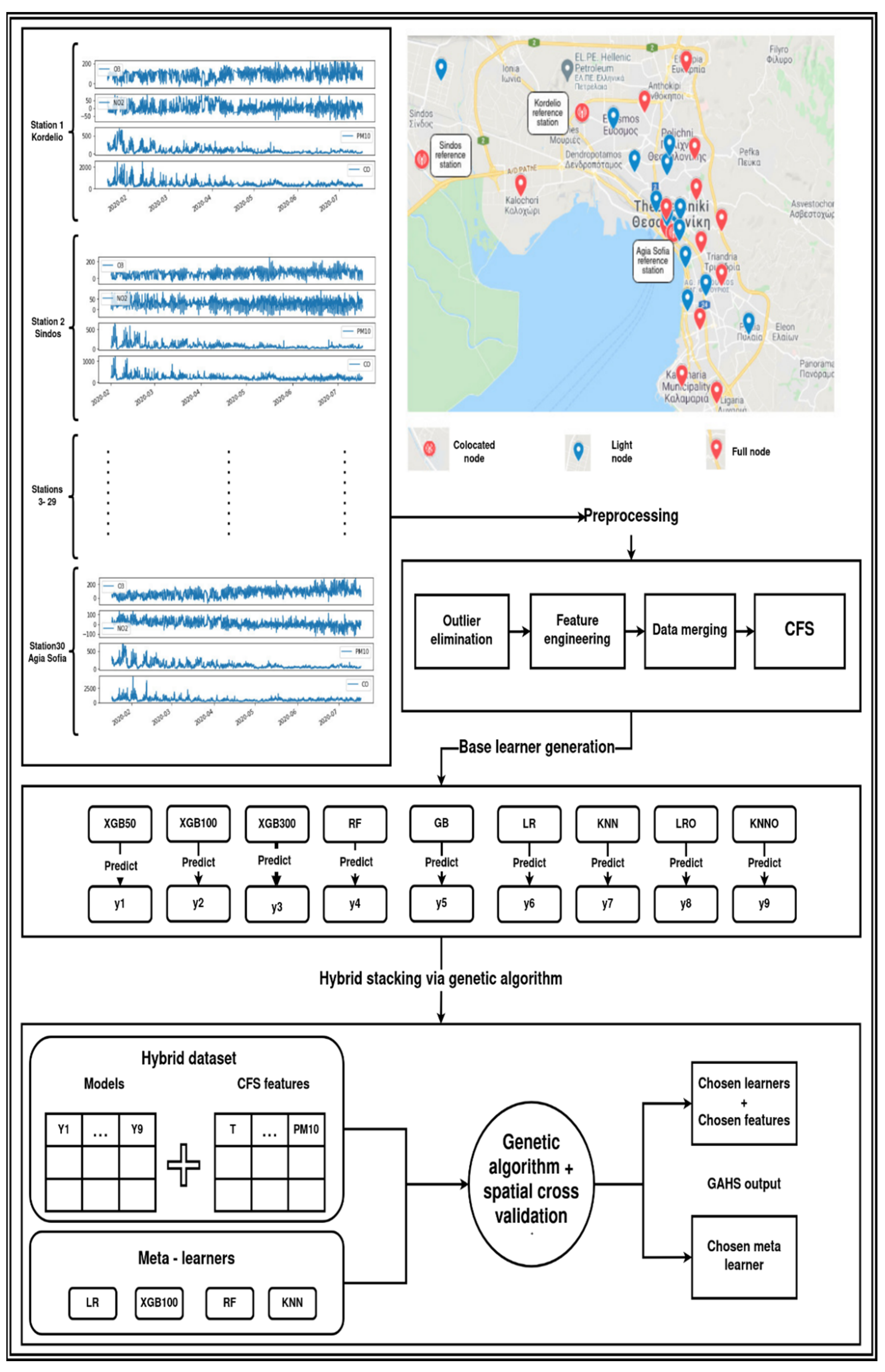
2.1. Experimental Design
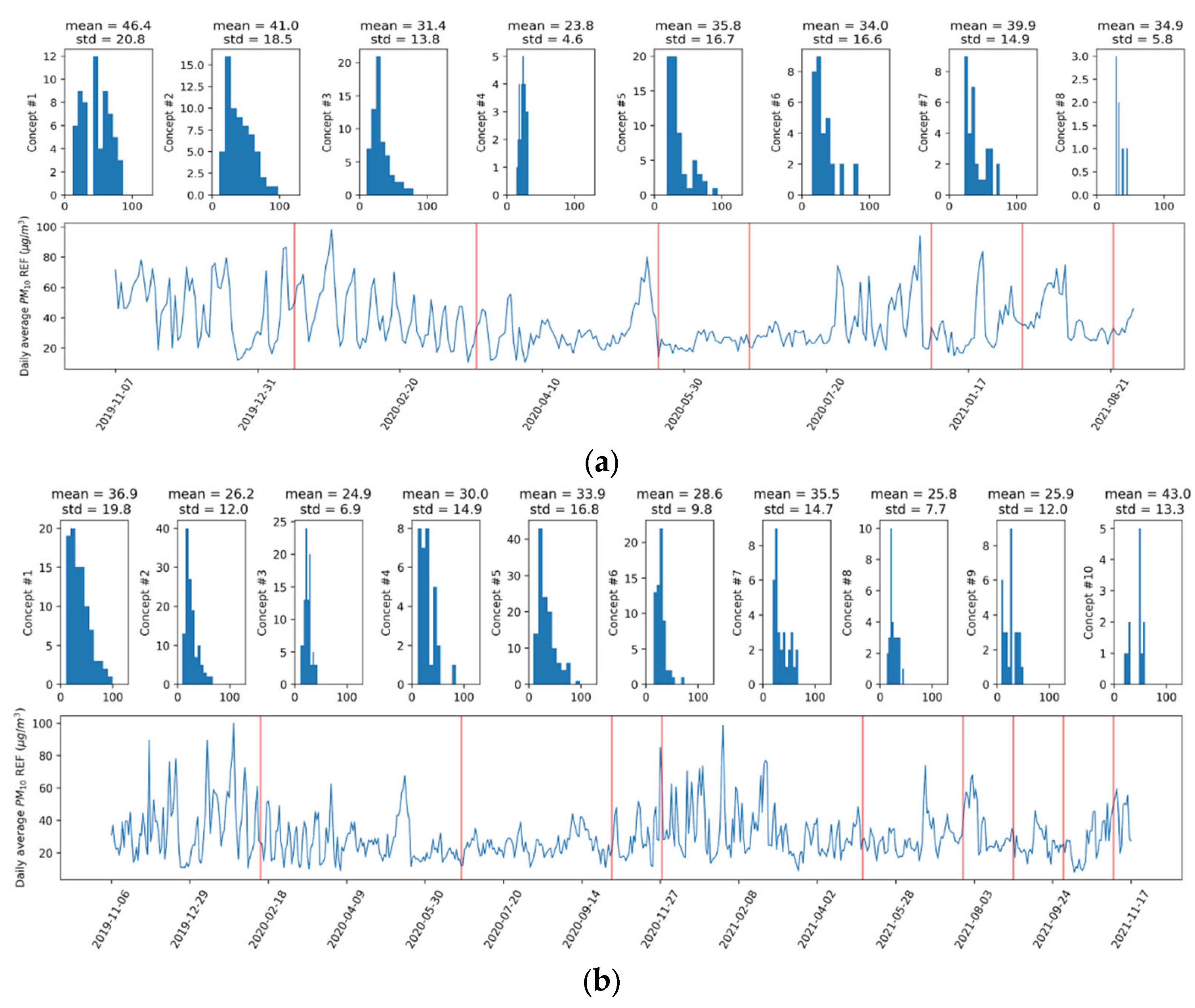
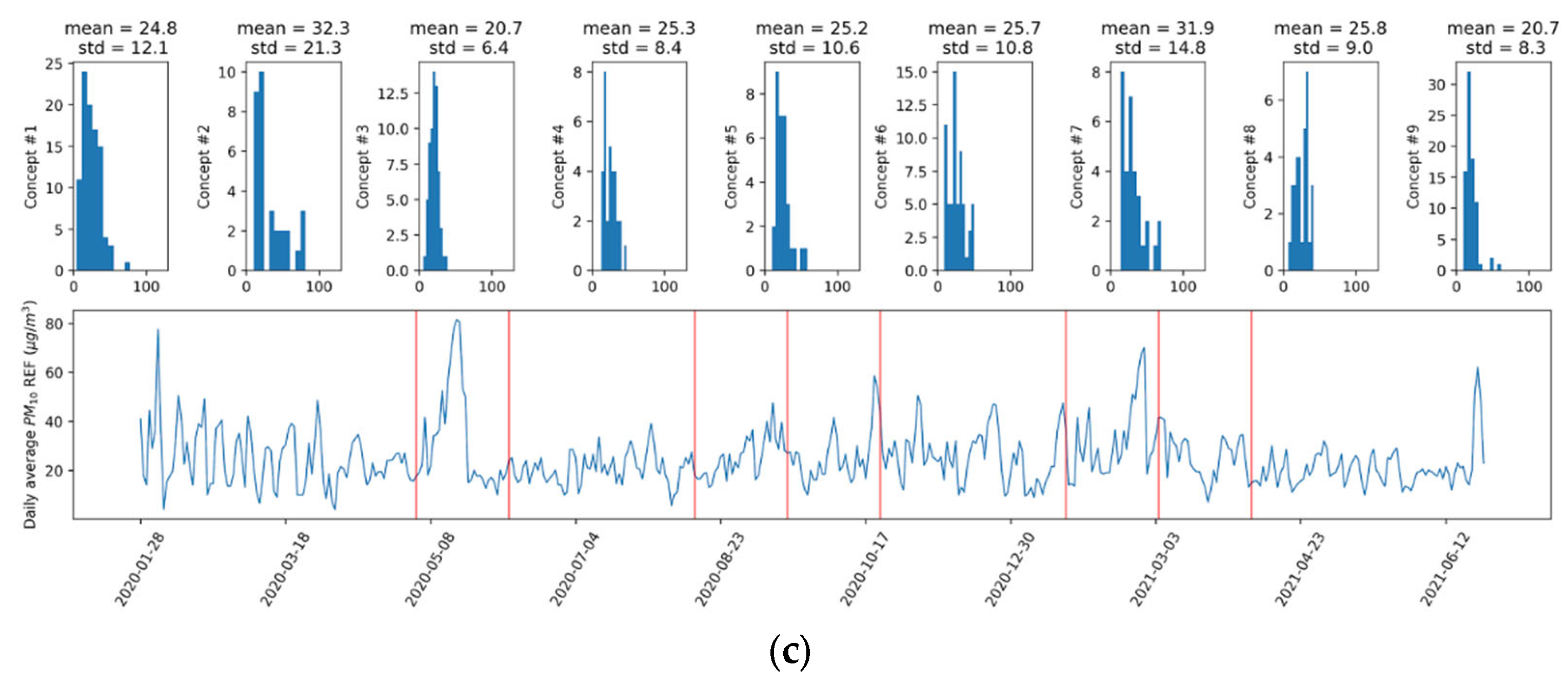
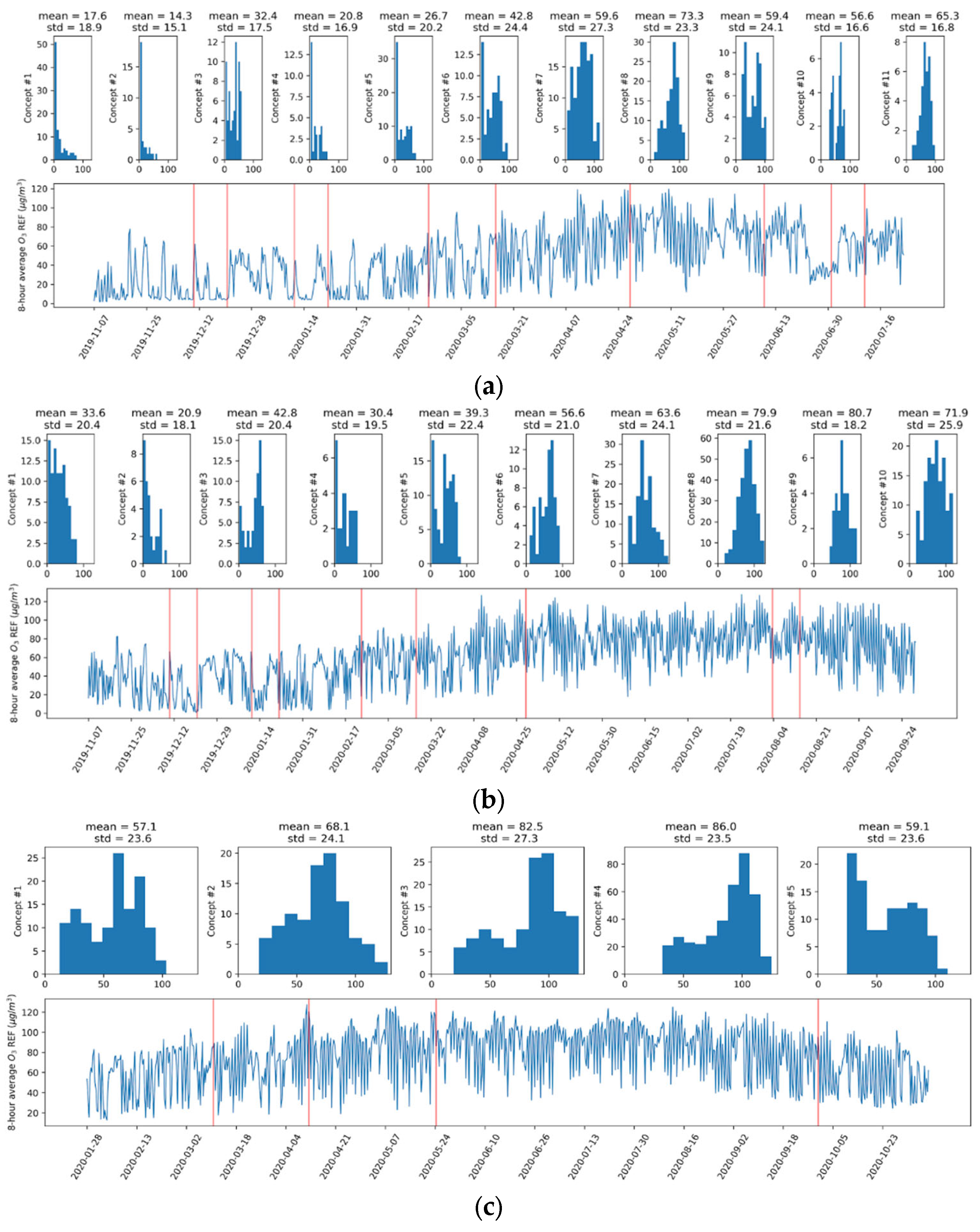
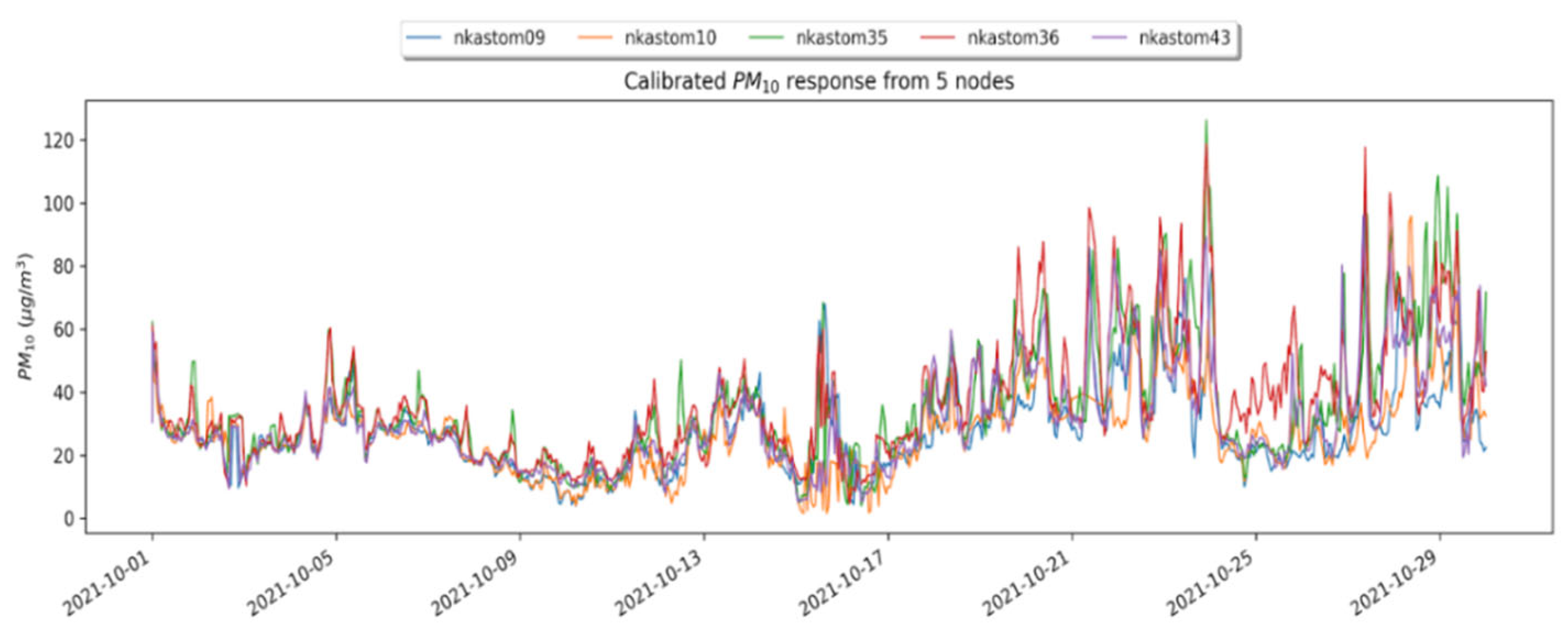
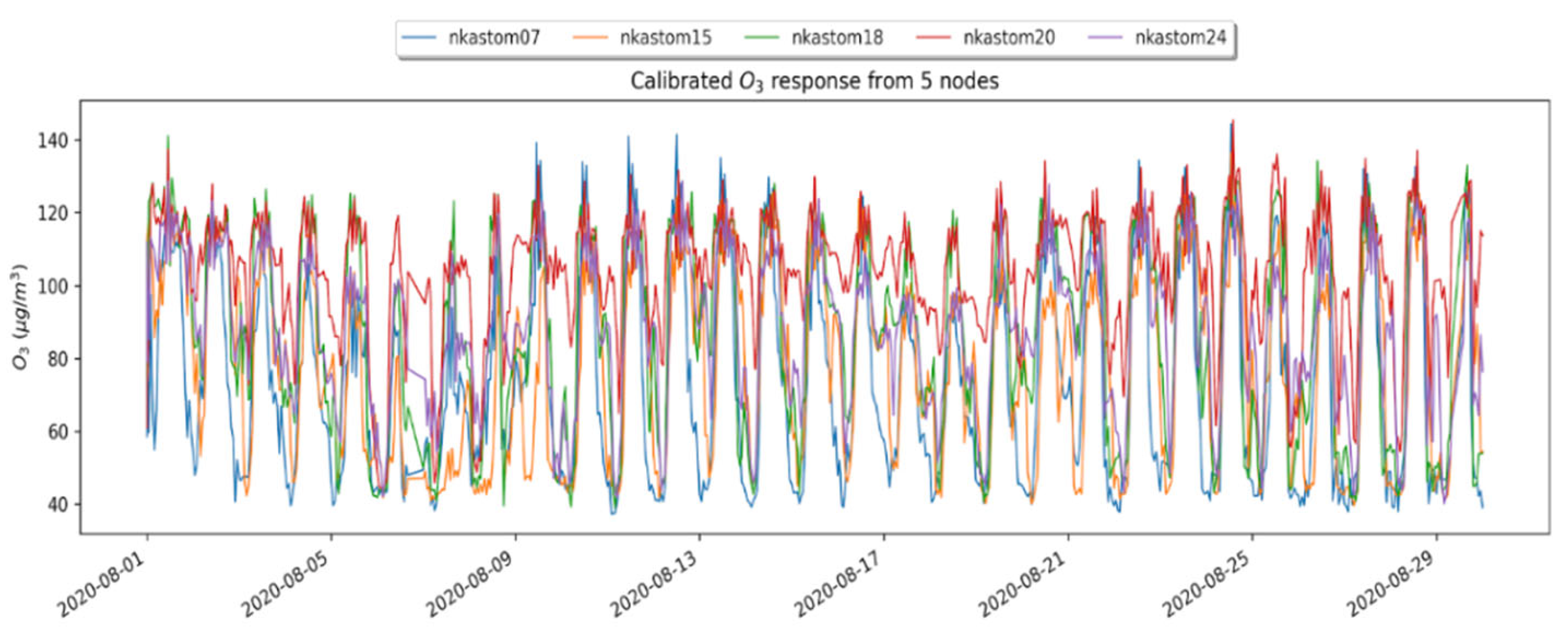
2.2. Concept Drift Definition and Detection
2.3. Spatial Online Learning
2.4. Preprocessing
2.5. Base Learners Generation
2.6. Hybrid Stacking Optimization via a Genetic Algorithm, the GAHS Framework
2.7. Evaluation of Operational Scenarios
3. Results
3.1. Drift Detection
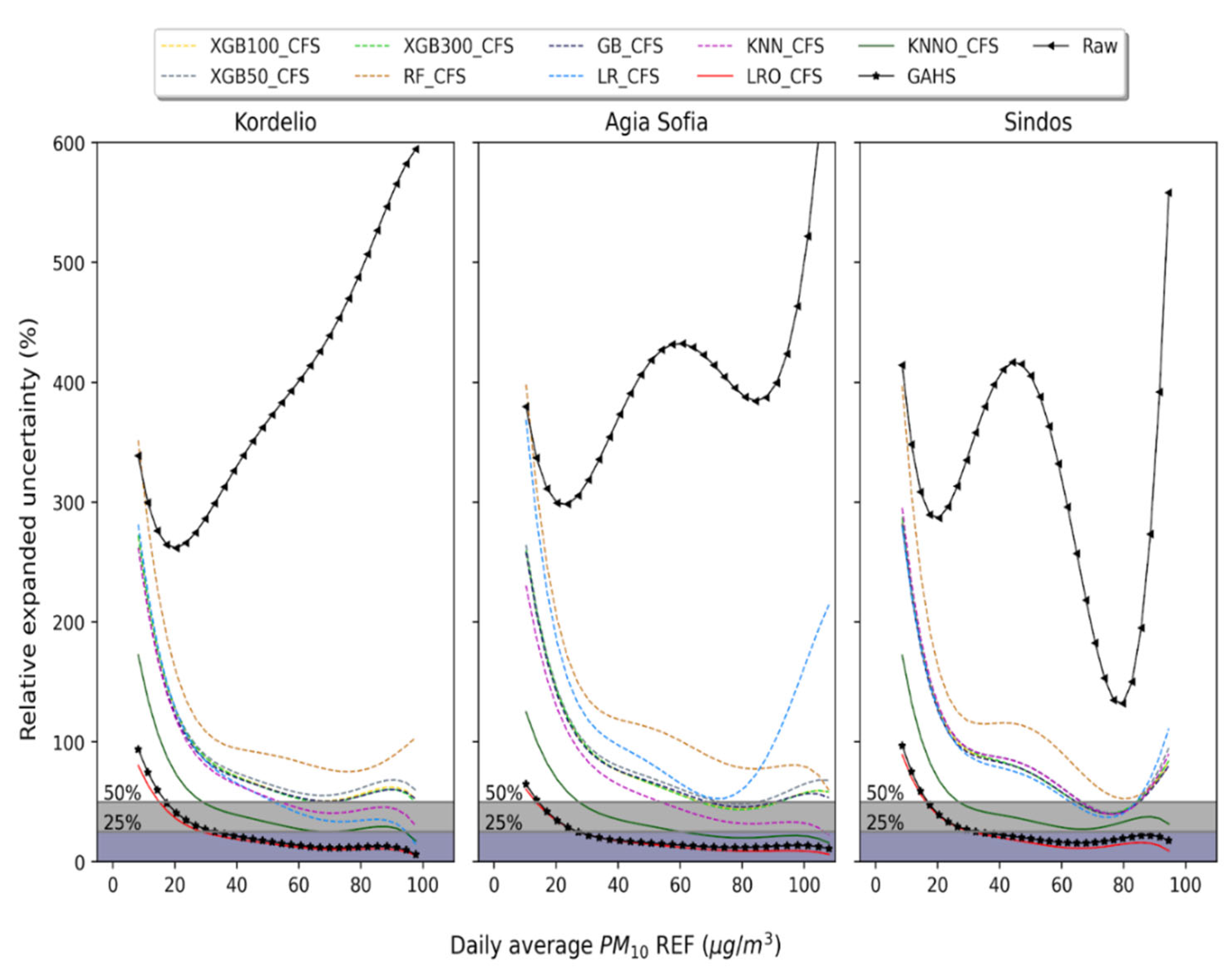
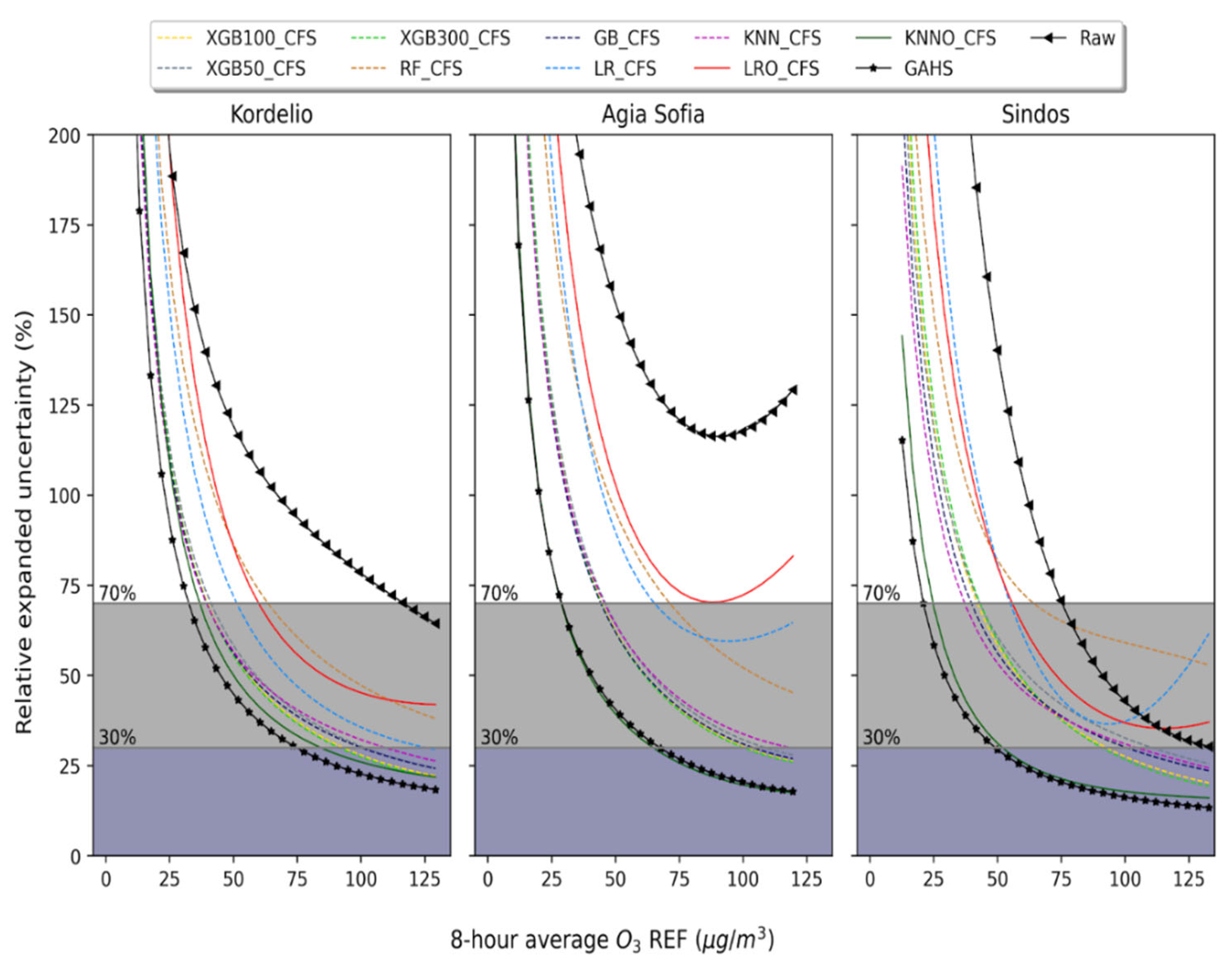
3.2. Relative Expanded Uncertainty
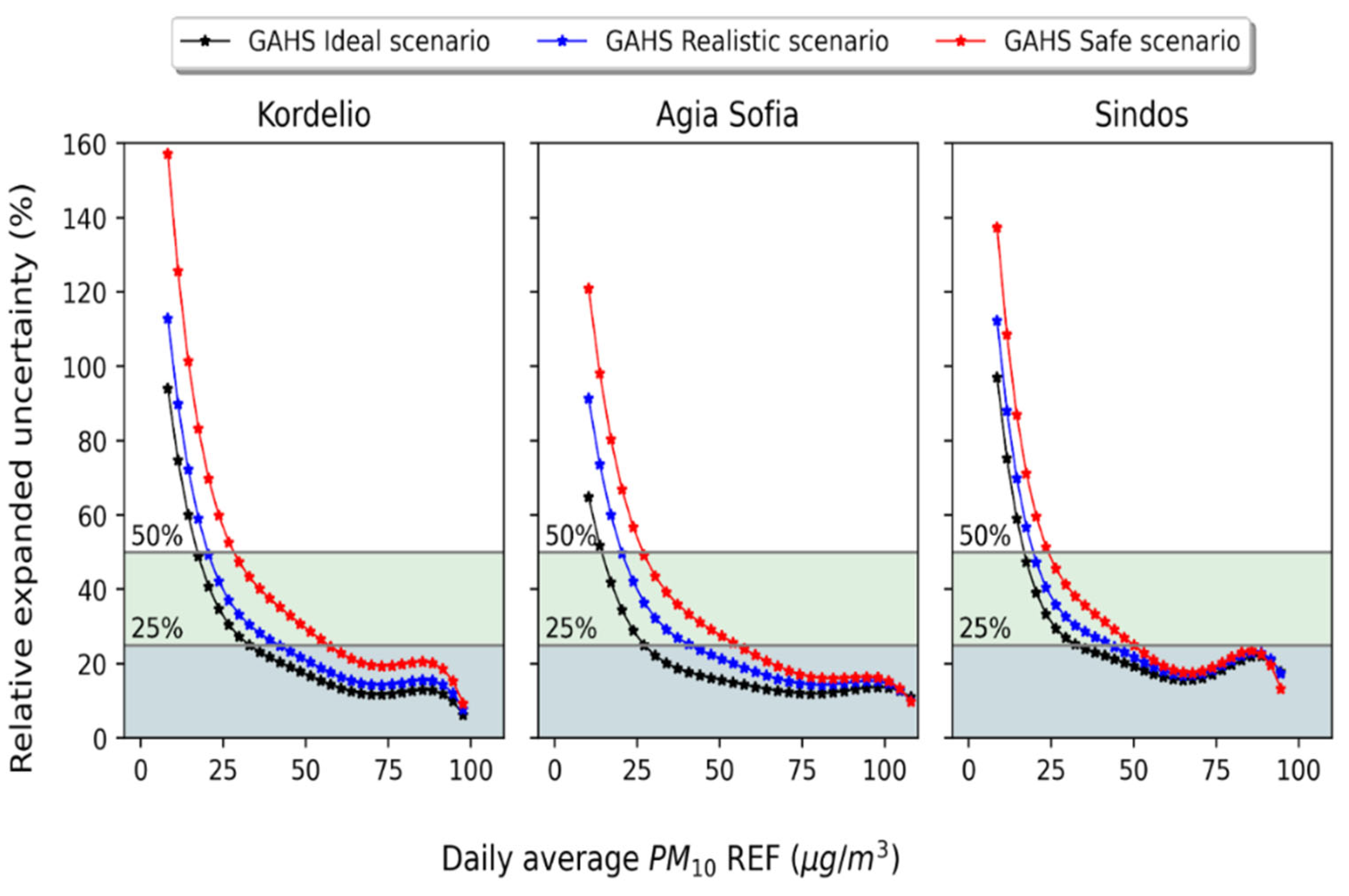
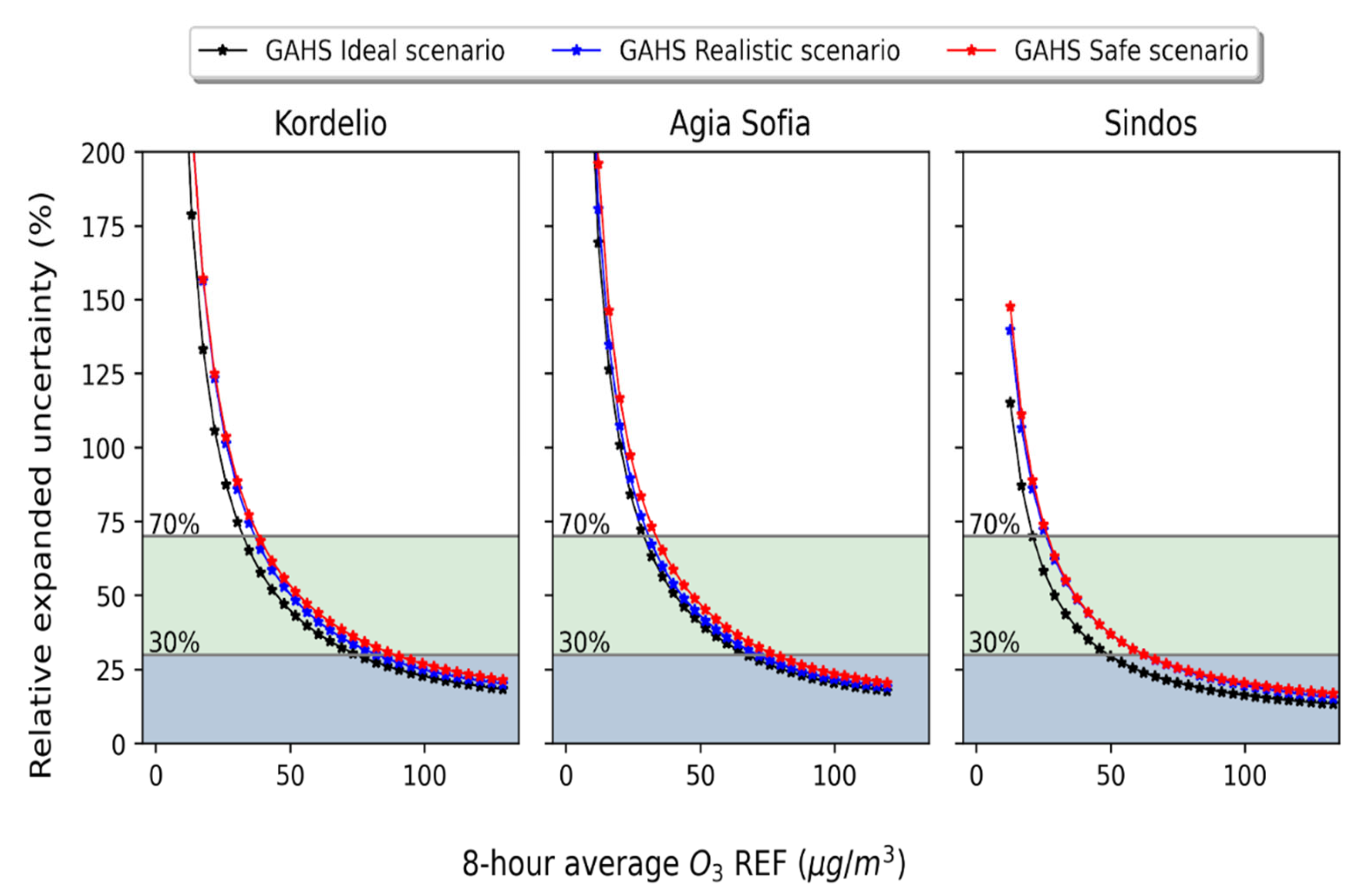
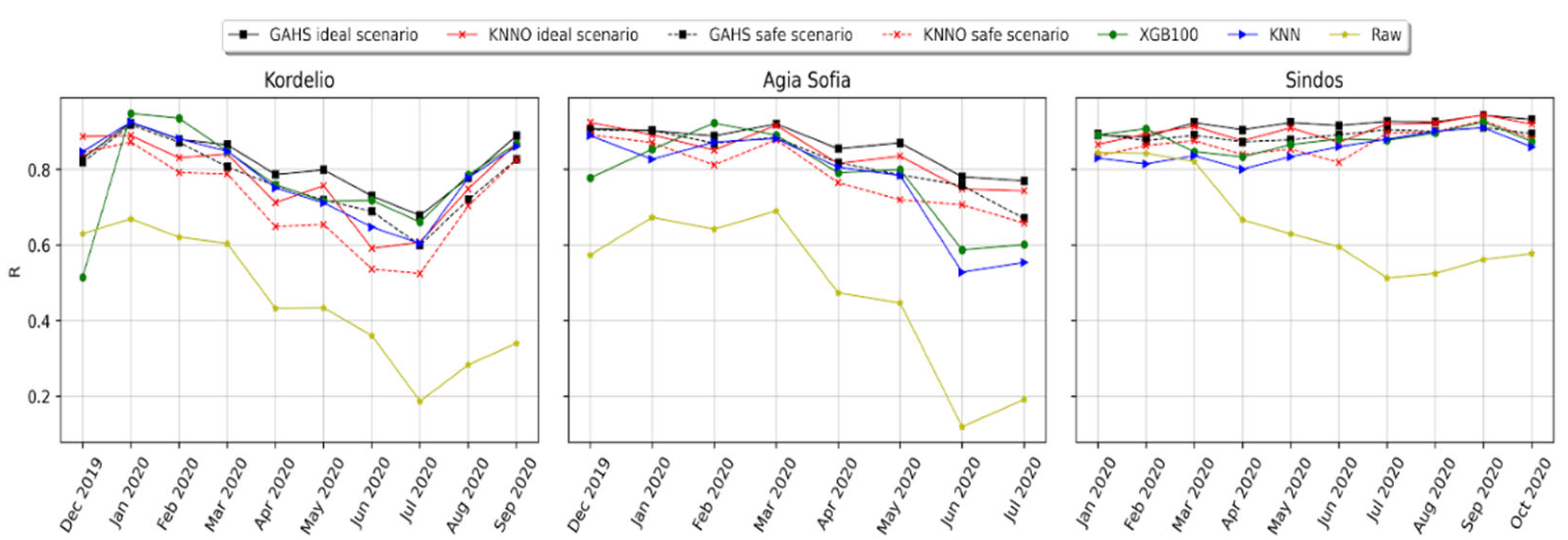
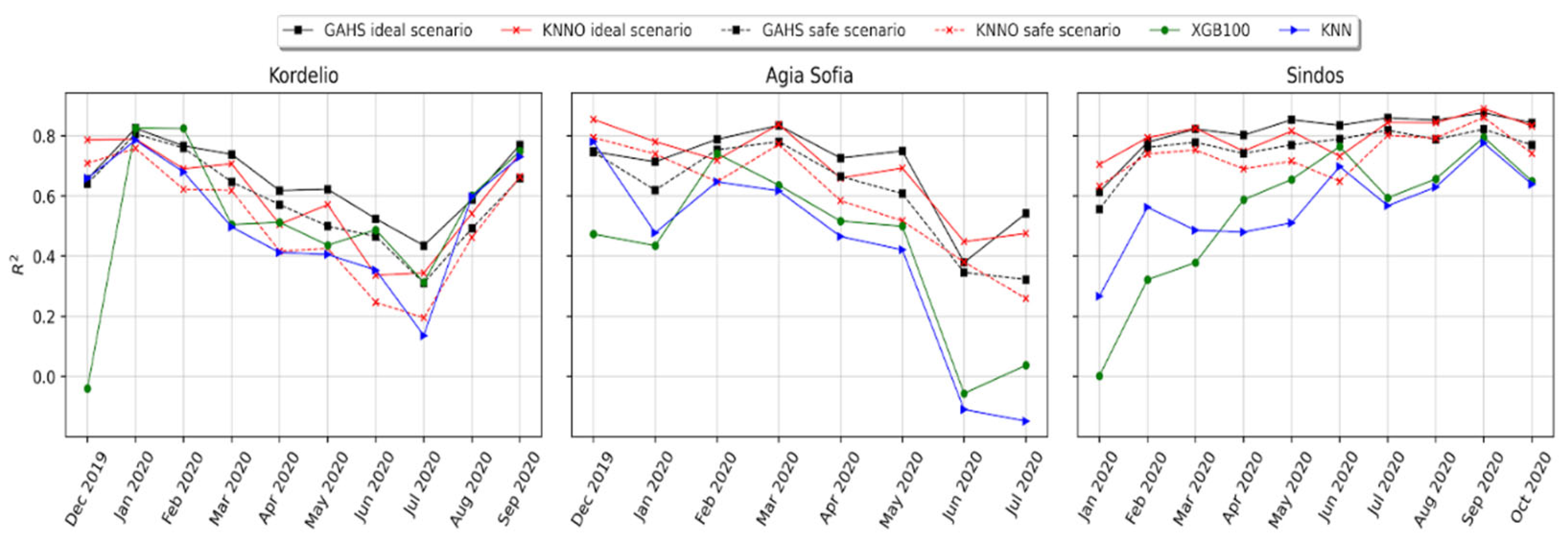
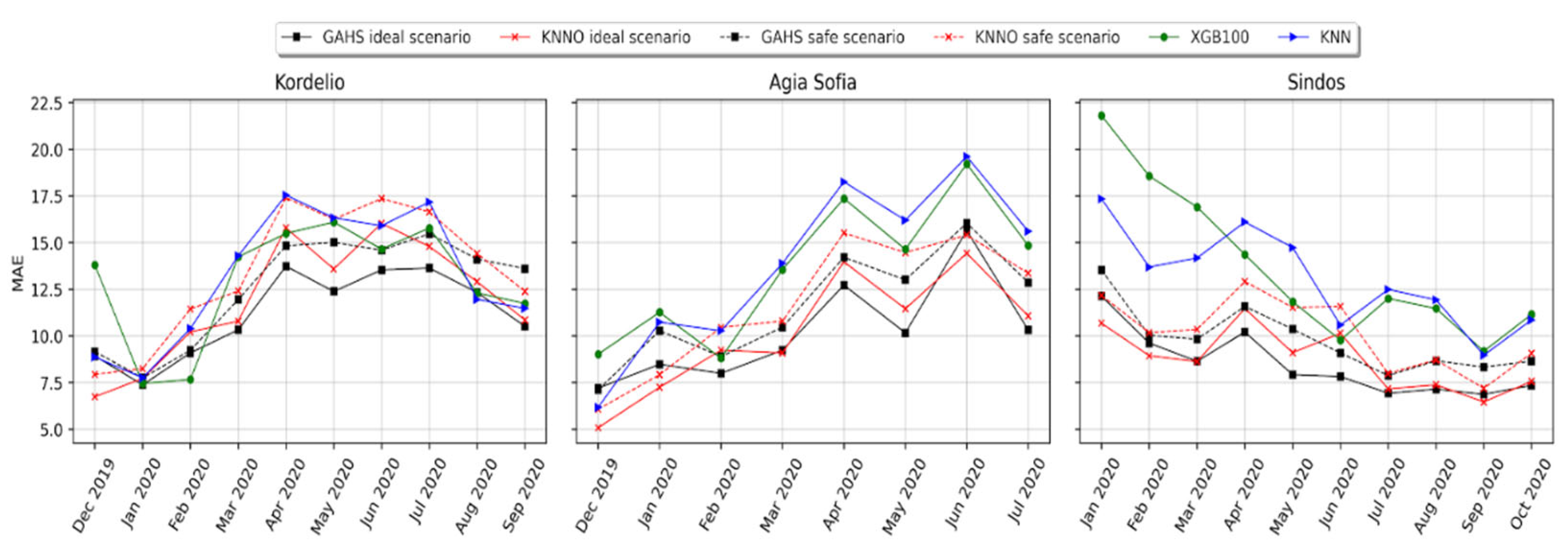
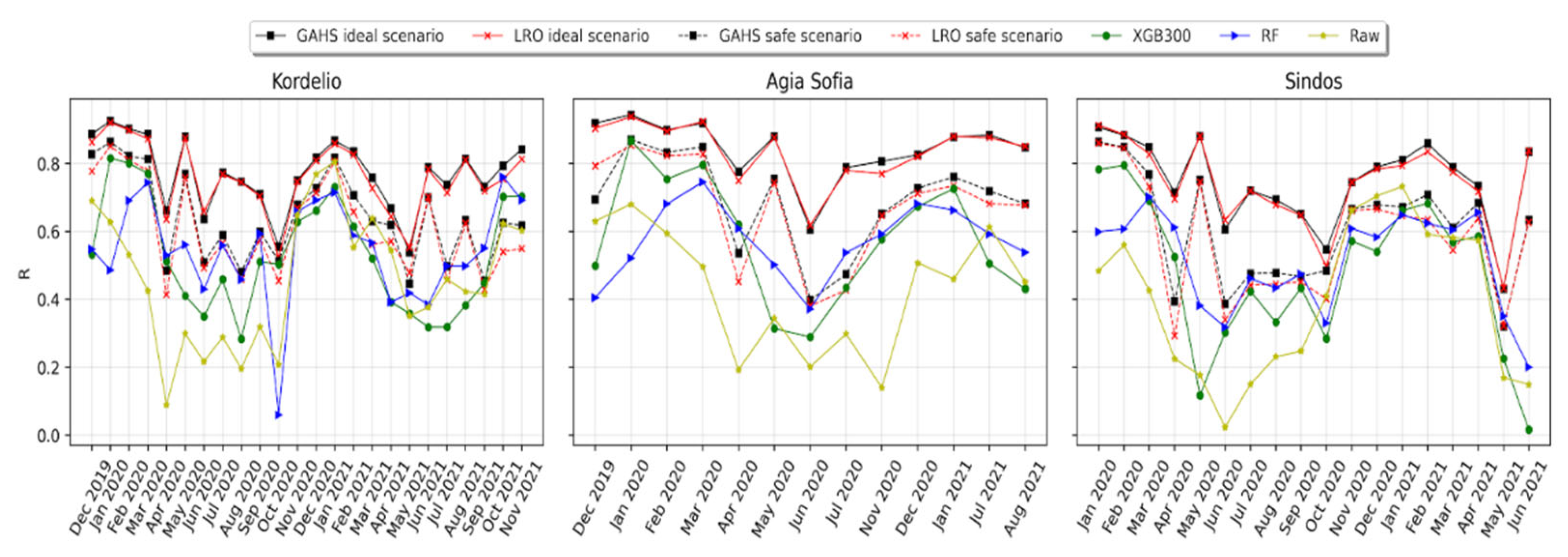
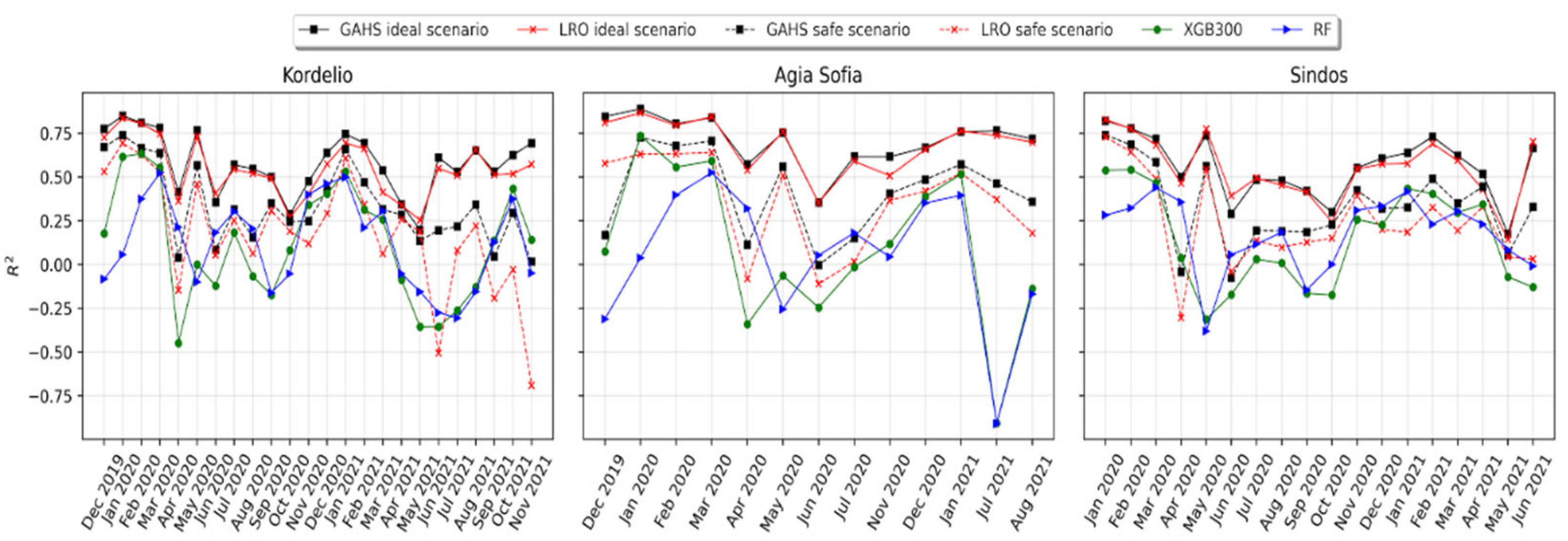
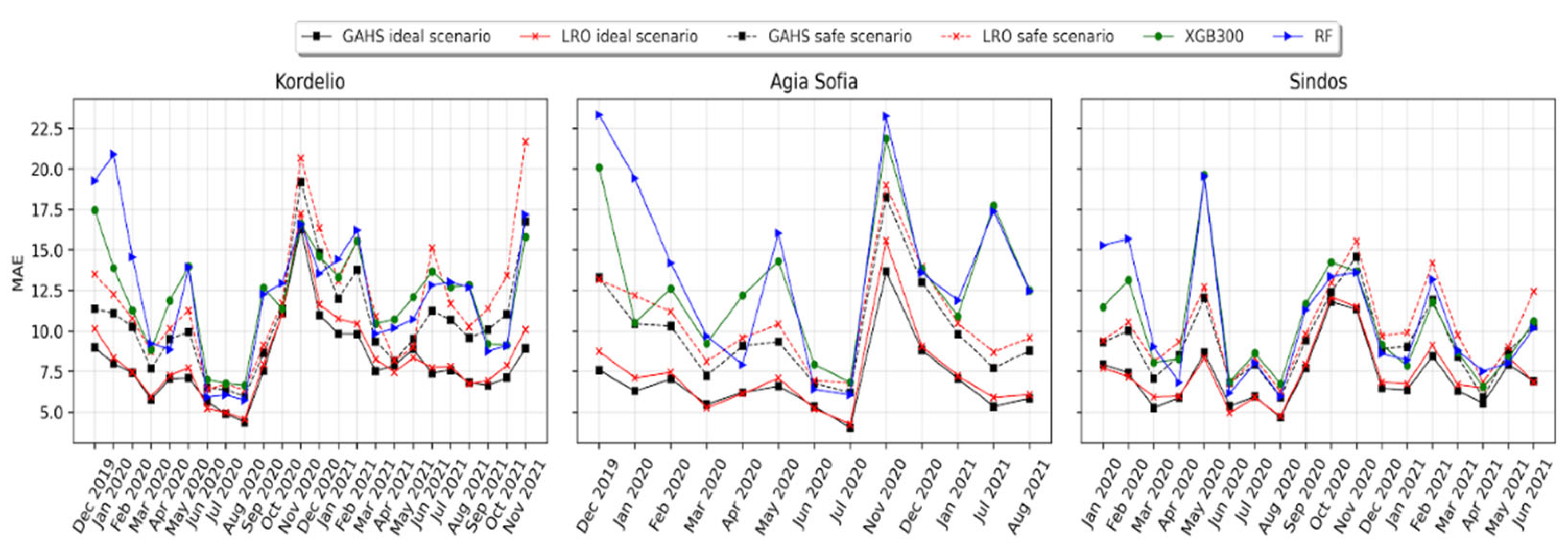
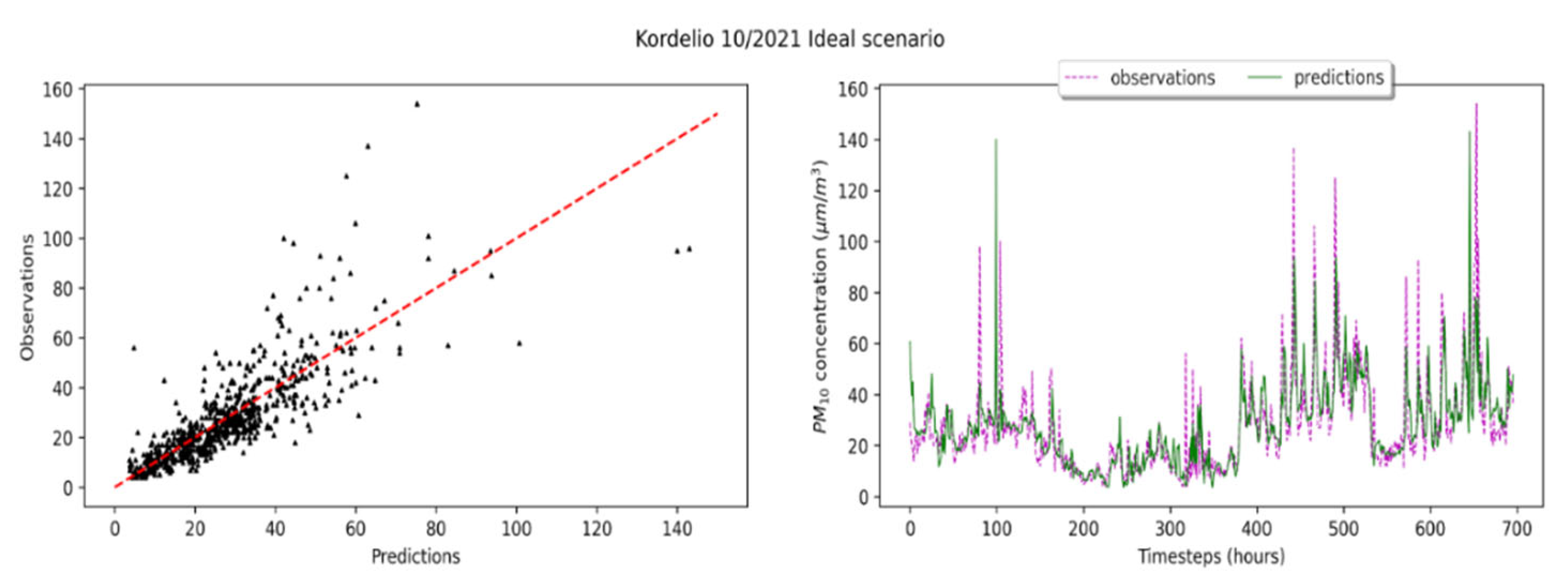
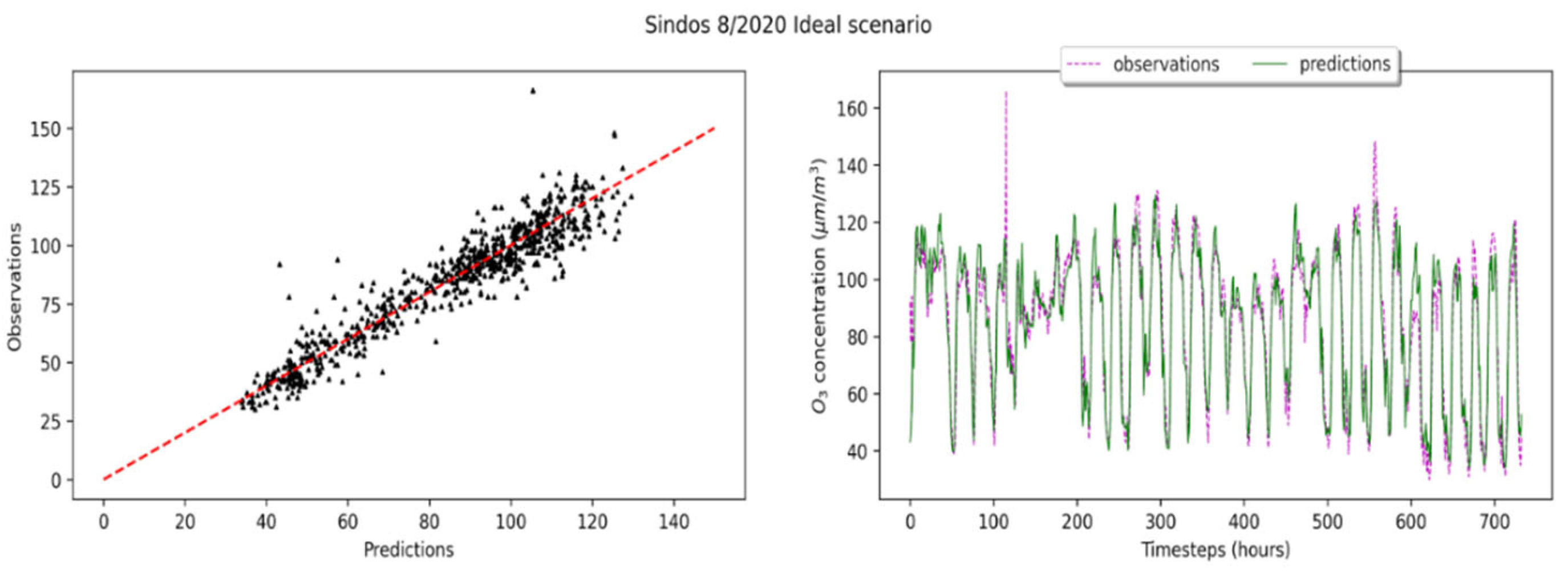
3.3. Forward Evaluation of the Calibration Framework
3.4. Comparison of the GAHS, SOL and Batch Algorithms
4. Discussion
4.1. The Relocation Problem
4.2. On-Site Continuous Evaluation
4.3. Limitations of the Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, S.; Hassan, Q. Review of developments in air quality modelling and air quality dispersion models. J. Environ. Eng. Sci. 2021, 16, 1–10. [Google Scholar] [CrossRef]
- Johansson, L.; Epitropou, V.; Karatzas, K.; Karppinen, K.; Wanner, L.; Vrochidis, S.; Bassoukos, A.; Kukkonen, J.; Kompatsiaris, I. Fusion of meteorological and air quality data extracted from the web for personalized environmental information services. Environ. Model. Softw. 2015, 64, 143–155. [Google Scholar] [CrossRef]
- Rai, A.C.; Kumar, P.; Pilla, F.; Skouloudis, A.N.; Di Sabatino, S.; Ratti, C.; Yasar, A.; Rickerby, D. End-user perspective of low-cost sensors for outdoor air pollution monitoring. Sci. Total Environ. 2017, 607–608, 691–705. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- UIA HOPE Helsinki Air Quality Digital Twin. Available online: https://ilmanlaatu.eu/wp-content/uploads/UIA-HOPE-Helsinki-Air-Quality-Digital-Twin-20201029.pdf (accessed on 27 January 2022).
- World Health Organization. World Health Statistics 2021: Monitoring Health for the SDGs, Sustainable Development Goals. License: CC BY-NC-SA 3.0 IGO. 2021. Available online: https://apps.who.int/iris/bitstream/handle/10665/342703/9789240027053-eng.pdf (accessed on 27 January 2022).
- Munir, S.; Mayfield, M.; Coca, D.; Jubb, S.; Osammor, O. Analysing the performance of low-cost air quality sensors, their drivers, relative benefits and calibration in cities—A case study in Sheffield. Environ. Monit. Assess. 2019, 191, 504–518. [Google Scholar] [CrossRef] [Green Version]
- Karagulian, F.; Barbiere, M.; Kotsev, A.; Spinelle, L.; Gerboles, M.; Lagler, F.; Redon, N.; Crunaire, S.; Borowiak, A. Review of the Performance of Low-Cost Sensors for Air Quality Monitoring. Atmosphere 2019, 10, 506. [Google Scholar] [CrossRef] [Green Version]
- Sousan, S.; Regmi, S.; Park, Y.M. Laboratory Evaluation of Low-Cost Optical Particle Counters for Environmental and Occupational Exposures. Sensors 2021, 21, 4146. [Google Scholar] [CrossRef]
- Borrego, C.; Ginja, J.; Coutinho, M.; Ribeiro, C.; Karatzas, K.; Sioumis, T.; Katsifarakis, N.; Konstantinidis, K.; de Vito, S.; Esposito, E.; et al. Assessment of air quality microsensors versus reference methods: The EuNetAir Joint Exercise—Part II. Atmos. Environ. 2018, 193, 127–142. [Google Scholar] [CrossRef]
- Maag, B.; Zhou, Z.; Thiele, L. A survey on sensor calibration in Air Pollution Monitoring deployments. IEEE Internet Things J. 2018, 5, 4857–4870. [Google Scholar] [CrossRef] [Green Version]
- Kang, Y.; Aye, L.; Ngo, T.; Zhou, J. Performance evaluation of low-cost air quality sensors: A review. Sci. Total. Environ. 2021; (in press). [Google Scholar] [CrossRef]
- Topalović, D.B.; Davidović, M.D.; Jovanović, M.; Bartonova, A.; Ristovski, Z.; Jovašević-Stojanović, M. In search of an optimal in-field calibration method of low-cost gas sensors for ambient air pollutants: Comparison of linear, multilinear and artificial neural network approaches. Atmos. Environ. 2019, 213, 640–658. [Google Scholar] [CrossRef]
- Becnel, T.; Sayahi, T.; Kelly, K.; Gaillardon, P.E. A Recursive Approach to Partially Blind Calibration of a Pollution Sensor Network. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019. [Google Scholar] [CrossRef]
- Kizel, F.; Etzion, Y.; Shafran-Nathan, R.; Levy, I.; Fishbain, B.; Bartonova, A.; Broday, D.M. Node-to-node field calibration of Wireless Distributed Air Pollution Sensor Network. Environ. Pollut. 2018, 233, 900–909. [Google Scholar] [CrossRef]
- Cordero, J.M.; Borge, R.; Narros, A. Using statistical methods to carry out in field calibrations of low cost air quality sensors. Sens. Actuators B Chem. 2018, 267, 245–254. [Google Scholar] [CrossRef]
- French National Institute for Industrial Environment and Risks (INERIS). Available online: https://prestations.ineris.fr/sites/prestation.ineris.fr/files/PrestaWeb/Pages-Solution/DSC/Certification%20syst%C3%A8mes%20capteurs%20surveillance%20qt%C3%A9%20air/en_gb_NEW%20MO1347AAapplicable.pdf (accessed on 27 January 2022).
- Standard CEN/TS 17660-1:2021: Air Quality—Performance Evaluation of Air Quality Sensor Systems—Part 1: Gaseous Pollutants in Ambient Air. Available online: https://standards.iteh.ai/catalog/standards/cen/5bdb236e-95a3-4b5b-ba7f-62ab08cd21f8/cen-ts-17660-1-2021 (accessed on 27 January 2022).
- Di Antonio, A.; Popoola, O.A.M.; Ouyang, B.; Saffell, J.; Jones, R.L. Developing a Relative Humidity Correction for Low-Cost Sensors Measuring Ambient Particulate Matter. Sensors 2018, 18, 2790. [Google Scholar] [CrossRef] [Green Version]
- Connolly, R.E.; Yu, Q.; Wang, Z.; Chen, Y.-H.; Liu, J.Z.; Collier-Oxandale, A.; Papapostolou, V.; Polidori, A.; Zhu, Y. Long-term evaluation of a low-cost Air Sensor Network for monitoring indoor and outdoor air quality at the Community Scale. Sci. Total Environ. 2022, 807, 150797. [Google Scholar] [CrossRef]
- Cross Validated. Available online: https://stats.stackexchange.com/questions/213464/on-the-importance-of-the-i-i-d-assumption-in-statistical-learning (accessed on 27 January 2022).
- Ryu, Y.; Hodzic, A.; Barre, J.; Descombes, G.; Minnis, P. Quantifying Errors in Surface Ozone Predictions Associated with Clouds Over the CONUS: A WRF-Chem modeling study using satellite cloud retrievals. Atmos. Chem. Phys. 2018, 18, 7509–7525. [Google Scholar] [CrossRef] [Green Version]
- Ang, H.H.; Gopalkrishnan, V.; Zliobaite, I.; Pechenizkiy, M.; Hoi, S.C.H. Predictive Handling of Asynchronous Concept Drifts in Distributed Environments. IEEE Trans. Knowl. Data Eng. 2013, 25, 2343–2355. [Google Scholar] [CrossRef]
- Nishida, K.; Yamauchi, K.; Omori, T. Ace: Adaptive Classifiers-Ensemble system for concept-drifting environments. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2005; pp. 176–185. [Google Scholar] [CrossRef]
- Puschmann, D.; Barnaghi, P.; Tafazolli, R. Adaptive clustering for dynamic IOT data streams. IEEE Internet Things J. 2017, 4, 64–74. [Google Scholar] [CrossRef] [Green Version]
- Boiko Ferreira, L.E.; Murilo Gomes, H.; Bifet, A.; Oliveira, L.S. Adaptive Random Forests with resampling for Imbalanced Data Streams. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- KASTOM. Available online: http://app.air4me.eu/ (accessed on 28 January 2022).
- Tancev, G.; Toro, F. Variational Bayesian calibration of low-cost gas sensor systems in air quality monitoring. Meas. Sens. 2022, 19, 100365. [Google Scholar] [CrossRef]
- Lange, M.; Suominen, H.; Kurppa, M.; Järvi, L.; Oikarinen, E.; Savvides, R.; Puolamäki, K. Machine-learning models to replicate large-eddy simulations of air pollutant concentrations along boulevard-type streets. Geosci. Model Dev. 2021, 14, 7411–7424. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under Concept Drift: A Review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef] [Green Version]
- Tsymbal, A. The problem of concept drift: Definitions and related work. Comput. Sci. Dep. Trinity Coll. Dublin 2004, 106, 58. [Google Scholar]
- Bifet, A.; Gavaldà, R. Learning from Time-Changing Data with Adaptive Windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007. [Google Scholar] [CrossRef] [Green Version]
- Read, J.; Bifet, A.; Pfahringer, B.; Holmes, G. Batch-Incremental Versus Instance-Incremental Learning in Dynamic and Evolving Data. In International Symposium on Intelligent Data Analysis; Springer: Berlin/Heidelberg, Germany, 2012; pp. 313–323. [Google Scholar] [CrossRef]
- Hall, M. Correlation Based Feature Selection for Machine Learning. Ph.D. Dissertation, University of Waikato, Hamilton, New Zealand, 1999. Available online: https://www.cs.waikato.ac.nz/~mhall/thesis.pdf (accessed on 28 January 2022).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- Montiel, J.; Halford, M.; Mastelini, S.M.; Bolmier, G.; Sourty, R.; Vaysse, R.; Zouitine, A.; Gomes, H.M.; Read, J.; Abdessalem, T.; et al. River: Machine learning for streaming data in Python. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Eslami, E.; Salman, A.K.; Choi, Y.; Sayeed, A.; Lops, Y. A data ensemble approach for real-time air quality forecasting using extremely randomized trees and deep neural networks. Neural Comput. Appl. 2019, 32, 7563–7579. [Google Scholar] [CrossRef]
- Ghomeshi, H.; Gaber, M.; Kovalchuk, Y. EACD: Evolutionary adaptation to concept drifts in data streams. Data Min. Knowl. Discov. 2019, 33, 663–694. [Google Scholar] [CrossRef] [Green Version]
- Pohjankukka, J.; Pahikkala, T.; Nevalainen, P.; Heikkonen, J. Estimating the prediction performance of spatial models via spatial K-fold cross validation. Int. J. Geogr. Inf. Sci. 2017, 31, 2001–2019. [Google Scholar] [CrossRef]
- European Parliament. Directive 2008/50/EC of the European Parliament and of the Council of 21 May 2008 on ambient air quality and cleaner air for Europe. Off. J. Eur. Union 2008, L152, 1–44. [Google Scholar]
- Spinelle, L.; Gerboles, M.; Villani, M.G.; Aleixandre, M.; Bonavitacola, F. Field calibration of a cluster of low-cost available sensors for air quality monitoring. part A: Ozone and Nitrogen Dioxide. Sens. Actuators B Chem. 2015, 215, 249–257. [Google Scholar] [CrossRef]
- Li, J.; Hauryliuk, A.; Malings, C.; Eilenberg, S.R.; Subramanian, R.; Presto, A.A. Characterizing the aging of Alphasense No2 sensors in long-term field deployments. ACS Sens. 2021, 6, 2952–2959. [Google Scholar] [CrossRef]
- Kuula, J.; Mäkelä, T.; Aurela, M.; Teinilä, K.; Varjonen, S.; González, Ó.; Timonen, H. Laboratory evaluation of particle-size selectivity of optical low-cost particulate matter sensors. Atmos. Meas. Tech. 2020, 13, 2413–2423. [Google Scholar] [CrossRef]
- Concas, F.; Mineraud, J.; Lagerspetz, E.; Varjonen, S.; Liu, X.; Puolamäki, K.; Nurmi, P.; Tarkoma, S. Low-Cost Outdoor Air Quality Monitoring and Sensor Calibration: A Survey and Critical Analysis. ACM Trans. Sens. Netw. 2021, 17, 1–44. [Google Scholar] [CrossRef]
- Zusman, M.; Schumacher, C.S.; Gassett, A.J.; Spalt, E.W.; Austin, E.; Larson, T.V.; Carvlin, G.; Seto, E.; Kaufman, J.D.; Sheppard, L. Calibration of low-cost particulate matter sensors: Model Development for a multi-city epidemiological study. Environ. Int. 2020, 134, 105329. [Google Scholar] [CrossRef]
- Bigi, A.; Mueller, M.; Grange, S.K.; Ghermandi, G.; Hueglin, C. Performance of no, no2 low cost sensors and three calibration approaches within a real world application. Atmos. Meas. Tech. 2018, 11, 3717–3735. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, L. Validation approaches for satellite-based PM2.5 estimation: Assessment and a new approach. arXiv 2018, arXiv:1812.00135. [Google Scholar]
- Bagkis, E.; Kassandros, T.; Karteris, M.; Karteris, A.; Karatzas, K. Analyzing and Improving the Performance of a Particulate Matter Low Cost Air Quality Monitoring Device. Atmosphere 2021, 12, 251. [Google Scholar] [CrossRef]
- De Vito, S.; Esposito, E.; Castell, N.; Schneider, P.; Bartonova, A. On the robustness of field calibration for Smart Air Quality Monitors. Sens. Actuators B Chem. 2020, 310, 127869. [Google Scholar] [CrossRef]
- Laref, R.; Losson, E.; Sava, A.; Siadat, M. Empiric unsupervised drifts correction method of electrochemical sensors for in field nitrogen dioxide monitoring. Sensors 2021, 21, 3581. [Google Scholar] [CrossRef]
- Van Heeswijk, M.; Miche, Y.; Lindh-Knuutila, T.; Hilbers, P.A.; Honkela, T.; Oja, E.; Lendasse, A. Adaptive Ensemble models of Extreme Learning Machines for time series prediction. In International Conference on Artificial Neural Networks; Alippi, C., Polycarpou, M., Panayiotou, C., Ellinas, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5769, pp. 305–314. [Google Scholar] [CrossRef] [Green Version]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Symbol | Formula |
|---|---|---|
| Coefficient of determination | ||
| Mean absolute error | MAE |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bagkis, E.; Kassandros, T.; Karatzas, K. Learning Calibration Functions on the Fly: Hybrid Batch Online Stacking Ensembles for the Calibration of Low-Cost Air Quality Sensor Networks in the Presence of Concept Drift. Atmosphere 2022, 13, 416. https://doi.org/10.3390/atmos13030416
Bagkis E, Kassandros T, Karatzas K. Learning Calibration Functions on the Fly: Hybrid Batch Online Stacking Ensembles for the Calibration of Low-Cost Air Quality Sensor Networks in the Presence of Concept Drift. Atmosphere. 2022; 13(3):416. https://doi.org/10.3390/atmos13030416
Chicago/Turabian StyleBagkis, Evangelos, Theodosios Kassandros, and Kostas Karatzas. 2022. "Learning Calibration Functions on the Fly: Hybrid Batch Online Stacking Ensembles for the Calibration of Low-Cost Air Quality Sensor Networks in the Presence of Concept Drift" Atmosphere 13, no. 3: 416. https://doi.org/10.3390/atmos13030416