1. Introduction
Despite the rapid growth of technologies and smart systems, certain problems remain unsolved or are solved with methods that deliver poor performance. One of these problems is the unexpected outbreak of a fire, an abnormal situation that can rapidly cause significant damage to lives and properties. According to the Korea Statistical Information Service, the National Fire Agency recordedthat, during the three years from 2016 to 2018, 129,929 fires occurred in South Korea, resulting in 1020 deaths, 5795 injuries, and damage to properties estimated at USD 2.4 billion [
1].
The latest technological advancements in sensors and sensing technologies have inspired businesses to determine whether these improvements can help to reduce the damage and harm caused by fire. This is the most frequent and widespread threat to public and social development as well as to individuals’ lives. Although fire prevention is the top priority to ensure fires do not occur in the first place, it is nonetheless essential to spot fires and to extinguish them before they have serious consequences. In this regard, a large number of methods were introduced and tested for early fire detection to reduce the number of fire accidents and the extent of the damage. Accordingly, different types of detection technologies in automated fire alarm systems have been formulated and are widely implemented in practice.
Two types of fire alarm systems are known: traditional fire alarm systems and computer vision-based fire detection systems. Traditional fire alarm systems employ physical sensors such as thermal detectors, flame detectors, and smoke detectors. These kinds of sensing devices require human intervention to confirm the occurrence of a fire in the case of an alarm. In addition, these systems require different kinds of tools to detect fire or fumes and alert humans by providing the location of the indicated place and extent of the flames. Furthermore, smoke detectors are often triggered accidentally, as they are unable to differentiate between smoke and fire. Fire detection sensors require a sufficient intensity of fire for clear detection, which can extend the time taken for detection, resulting in extensive damage and loss. An alternative solution, which could improve the robustness and safety of fire detection systems, is the implementation of visual fire detection techniques. In this regard, many researchers have endeavored to overcome the abovementioned limitations by investigating the combination of computer vision-based methods and sensors [
2,
3]. A vision-based detector is advantageous in that it can overcome the shortcomings of sensor-based methods. In addition, this type of system has several advantages, such as scalability, manageability of installation, and it does not demand any closedowns. Moreover, the use of computer vision for surveillance applications has become an attractive research area in which notable advances have been made in the last few years. Vision-based approaches also overcome various limitations of traditional fire alarm systems, such as the need for surveillance coverage, human intervention, response time, and detailed reports of the fire with particulars such as its intensity, rate of spread, and extent. However, the complexity and false triggering for diverse reasons continue to remain problematic. Accordingly, studies have been conducted to investigate and address these issues related to computer vision-based technology. Initially, computer vision-based fire detection applications focused on edgedetection [
3] or the color of the fire or smoke within the framework of rule-based systems. Rule-based systems are vulnerable to environmental conditions such as illumination, variation in lighting, perspective distortion, and inter-object occlusion. Solving the abovementioned problems using deep neural networks, such as convolutional neural networks (CNNs) and region-based CNNs, despite their robustness to lighting variations and different conditions, continue to present problems. In this case, without appropriate adjustment, a standard CNN is not effective under any possible circumstances. Creating a robust fire detection system requires sophisticated effort because of the dynamic and static behaviors of fire, smoke, and the large amount of domain knowledge that is required to solve the problem. Problems of this nature and extent could be solved by using machine/deep learning approaches [
4,
5]. However, solving these problems requires appropriately designed network architecture to be trained with a huge volume of data to eliminate the overfitting problem. The abovementioned smoke detection system [
4] relies on machine-learning-based image recognition software and a cloud-based workflow capable of scanning hundreds of cameras every minute.
In this study, we addressed the aforementioned issues by structuring a convolutional layer that uses a dilated convolution operator to detect a fire or smoke in a scene. The advantage of this model is that it can reduce false fire detections and misdetections. For this work, we collected a number of images containing diverse scenes of fire and smoke to enhance the capability of the fire and smoke detection model to generalize unseen data. In other words, the utilization of various fire and smoke images helps to make our approach more generalizable for unseen data. We used one subset of data for the learning process and evaluated it on a different subset. Several similar methods already exist, for example that proposed by Abdulaziz and Cho [
6], who implemented adaptive piecewise linear units (APL units). However, when we used their method to process the specific dataset we constructed, the experiments showed that our proposed method is more effective than theirs in terms of complexity and accuracy. The majority of the relevant researchers used common CNN architectures to compare their work, such as AlexNet [
7], VGG16, and VGG19 [
8]. Therefore, we evaluated our method in comparison to the abovementioned deep neural network structures.
Accordingly, the following points outline our key contributions:
- (1)
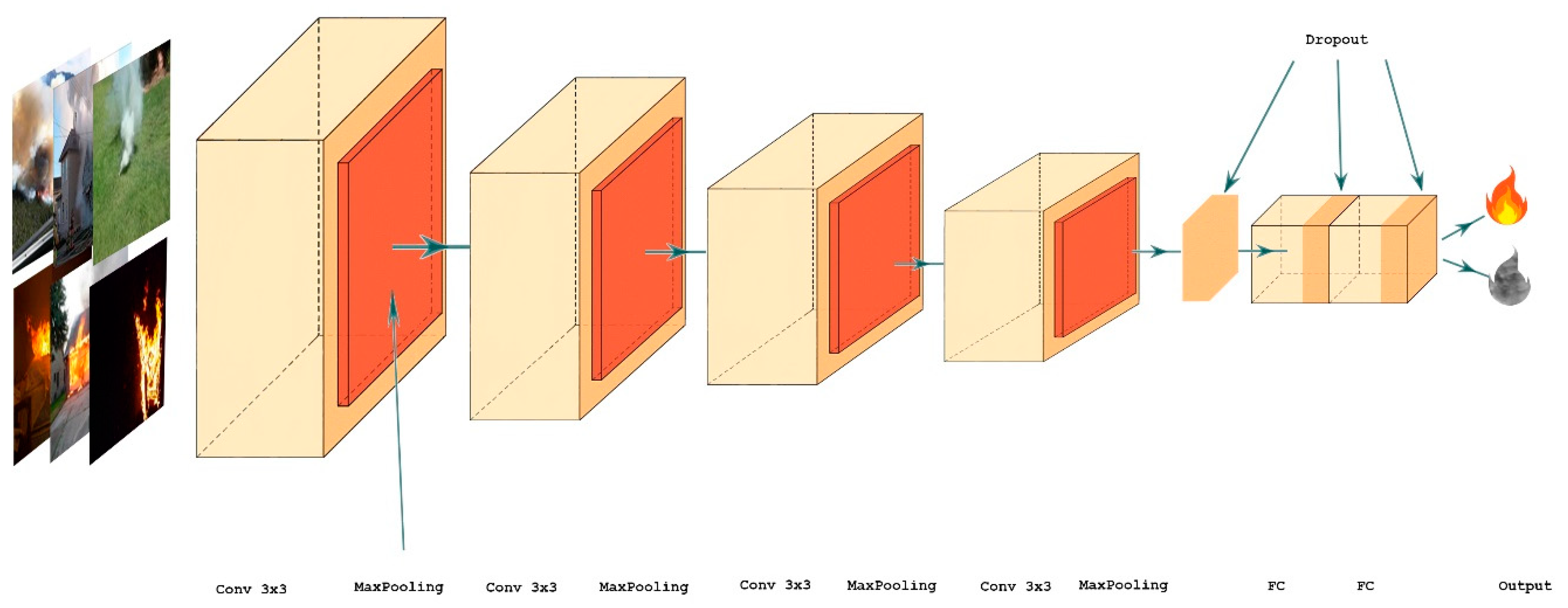
We propose a CNN-based approach that uses a dilated CNN to eliminate the time-consuming efforts dedicated to introducing handcrafted features because our method automatically extracts a group of practical features to train it. Asit is essential to use a sufficient amount of data for the training process, we assembled a large collection of images of different scenes depicting fire and smoke obtained from many sources. Images were selected from a well-known dataset [
9]. Our dataset is also available for further research.
- (2)
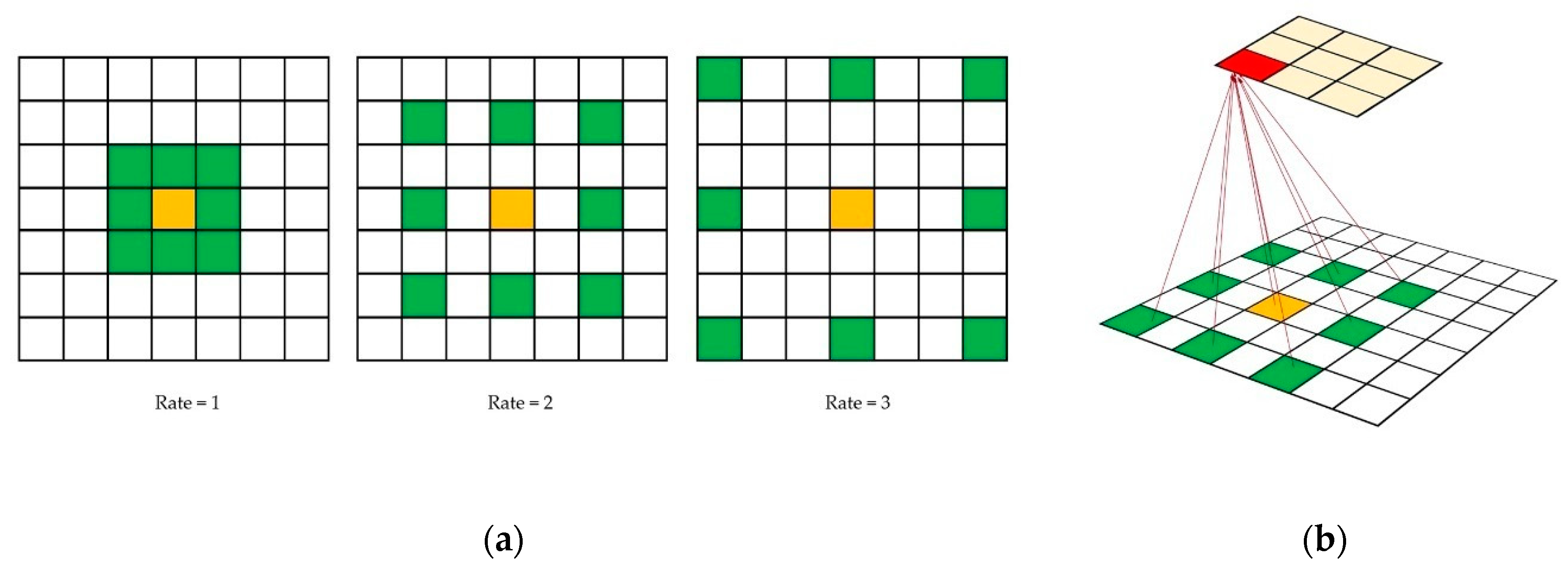
We used dilated convolutional layers to build our network architecture and briefly explain the principles thereof. Dilated convolution makes it possible to avoid learning much deeper, because it helps to learn larger features by ignoring smaller features.
- (3)
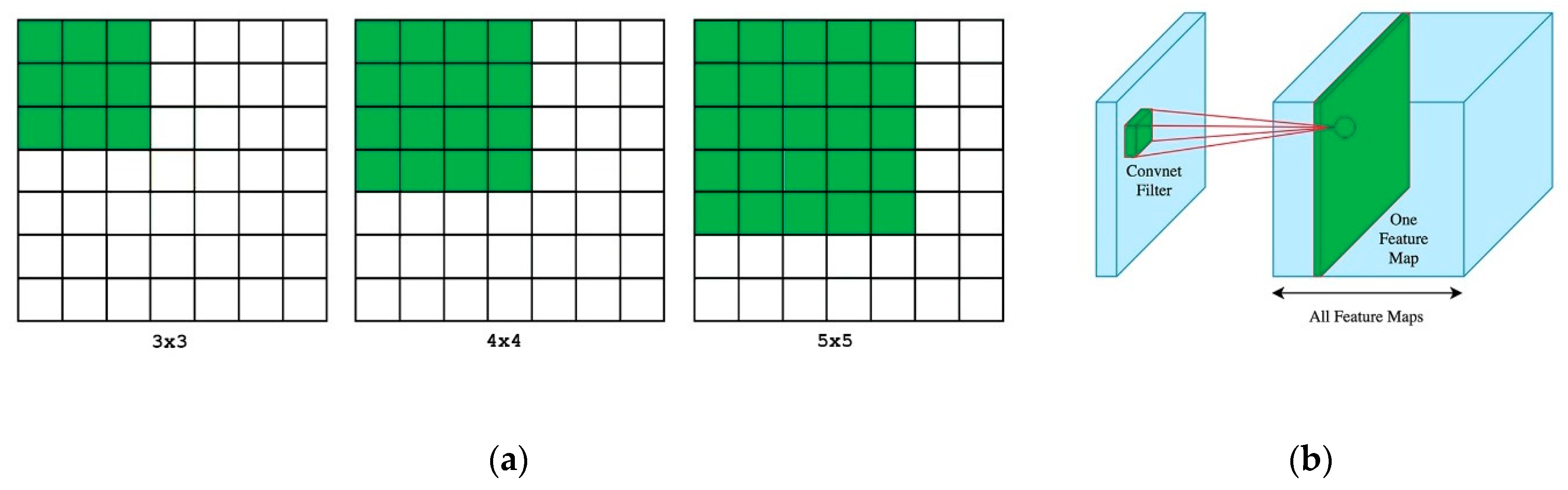
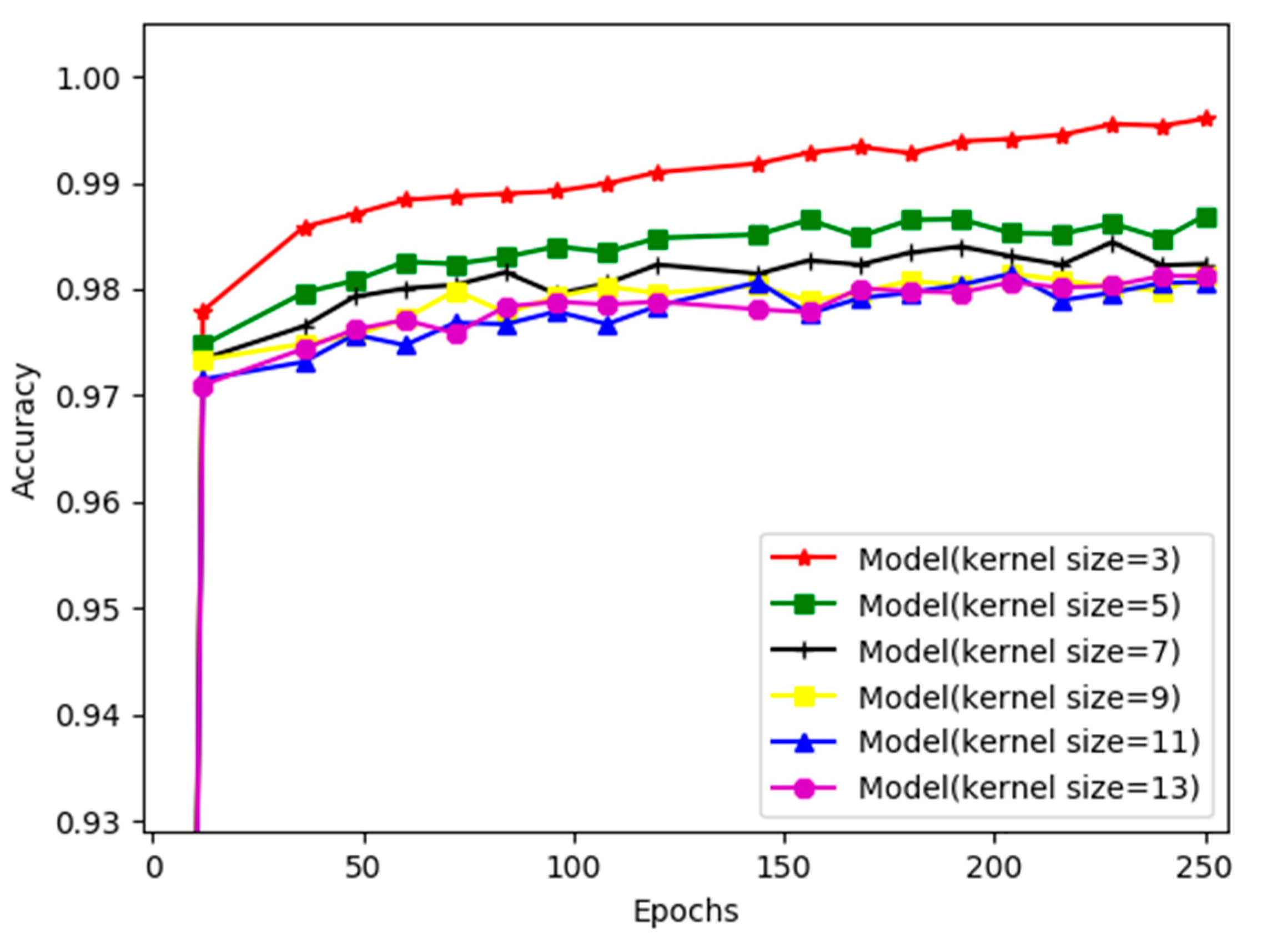
Small window sizes are used to aggregate valuable values from fire and smoke scenes. The use of smaller window sizes in deep learning is known to enable smaller but complex features in an image to be captured, and it offers improved weight sharing. Therefore, we decided to use a smaller kernel size for the training process.
- (4)
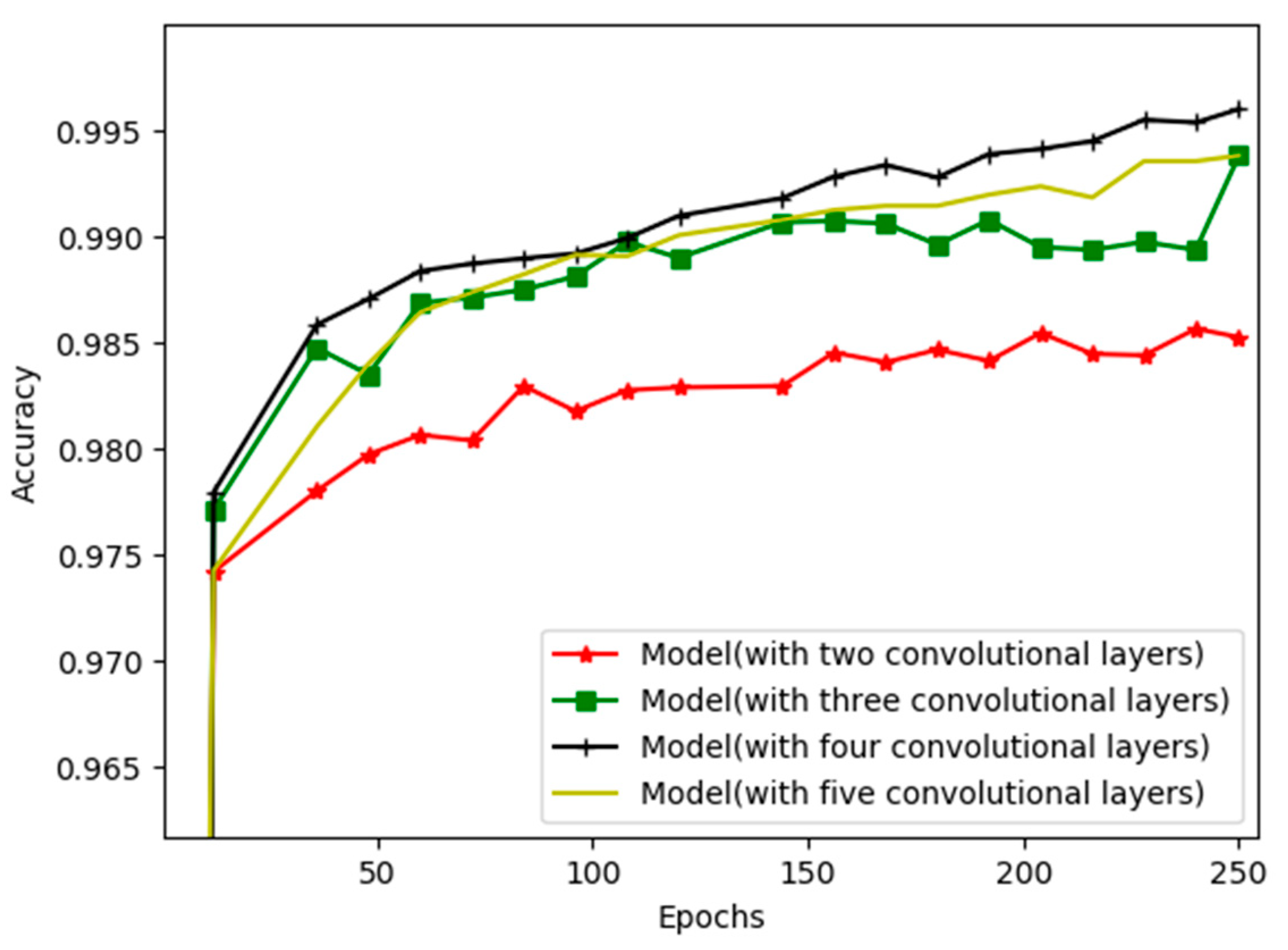
We determined the number of layers that are well suited to solve this task. Four convolutional layers were employed because an excessive number of layers allow the model to learn much deeper. This approach considers that, rather than having to classify a very large number of classes, the task is a simple binary classification. Therefore, employing many layers will exacerbate the overfitting problem. In
Section 5, overfitting is demonstrated to occur. However, the latter studies used a larger number of layers, mostly six layers [
6].
The remainder of this paper is organized as follows. In
Section 2, information about fire and smoke detection approaches is introduced. The features of our custom dataset are presented in
Section 3. A comprehensive explanation of our proposed method is provided in
Section 4. In
Section 5, we discuss all the experimental results.
Section 6 highlights a few limitations of the proposed method. Finally,
Section 7 concludes the manuscript with final remarks.
2. Related Work
2.1. Computer Vision Approaches for Fire and Smoke Detection
Many researchers who studied traditional fire and smoke detection systems focused on extracting crucial features from images. Many of these investigations focused on detecting geometrical characteristics of flames [
10,
11] and fires in the images [
12,
13]. For example, Bheemul et al. [
11] suggested an efficient approach for extracting edges by detecting changes in the brightness of an image of a fire. Jian et al. [
13] presented an enhanced edge detection operator, a Canny edge detector, which uses a multi-stage algorithm. However, the abovementioned computer vision-based methods were only applicable to images of simple and steady fires and flames. Other researchers applied new methods based on FFT (Fast Fourier Transform) and wavelet transform to analyze the contours of forest fires in video scenes [
14]. Previous research has indicated that these approaches are suitable only under certain conditions.
Changes in fires were analyzed using red-green-blue (RGB) and (hue, saturation, intensity) HSI color models. For example, Chen [
15] used a color-based approach to detect the discrepancy among sequential images. Celik et al. [
16] proposed a generic rule-based approach that uses the YCbCr color space to discriminate luminance from chrominance to identify a variety of smoke and fires in images. Yu et al. [
17] also used simultaneous motion and color features for detection purposes. The use of YCbCr can increase the detection rate of fire in images compared to RGB, because it can separate luminance more effectively than RGB color space [
18]. However, color-based fire and smoke detection methods are not feasible, because these approaches are not independent from environmental factors such as lighting, shadows, and other distortions. In addition, color-based approaches are vulnerable to the dynamic behavior of fire and smoke, even though fire and smoke have a longer-term dynamic behavior.
The disadvantage of these methods is that they require specific knowledge to extract and explore the features of fire and smoke in images. In addition, almost all conventional fire detection methods use color-based, edgedetection, or motion-based techniques, and these approaches are infeasible for analyzing tiny and noisy images. Therefore, these methods are limited, because they rely on limited characteristics of fire and smoke in images such as the motion, color, and edge of the fire or smoke. Furthermore, extracting these characteristics is also challenging because of the quality of the video or image.
2.2. Deep Learning Approaches for Fire and Smoke Detection
In recent years, deep learning has emerged significantly because of advances in hardware, the ability to process large-scale data, and substantial advances in the design of network structures and training strategies. Additionally, deep learning has been effectively implemented in various fields such as natural language processing (NLP), network filtering, games, medicine, and vision. Several deep learning applications have been shown to outperform human experts in certain cases [
7,
19,
20]. In vision-related tasks, computers have already achieved human-level performance. Several studies have been carried out to detect fire and smoke in images using deep learning approaches to enhance the reliability and results of these methods.
These approaches for fire and smoke detection differ from those based on computer vision in various ways. First, deep learning performs automatic feature extraction using a massive amount of data for training and discriminative features learned by the neural network to detect a fire or smoke. Another advantage is that deep neural networks can be flexibly and successfully implemented in various fields, and instead of spending time on feature extraction, they can be changed to construct a robust dataset and appropriate network structure.
Recently, Abdulaziz [
6] introduced a fire and smoke detection network with limited data based on CNNs and used it with a generative adversarial network (GAN) [
21] for augmentation purposes. Instead of using the traditional activation function, Abdulazizet al. employed adaptive piecewise linear units as an activation function. Abdulaziz [
6] conducted a number of experiments to show an increase in detection. Sebastien et al. [
22] also suggested a model that uses a multilayer perceptron-type neural network to learn features by an iterative process of learning. In addition, Muhammad et al. [
23] experimented with different fine-tuned versions of various CNN models, such as AlexNet [
7], SqueezeNet [
24], GoogleNet [
25], and MobileNetV2 [
26]. Our proposed model, which allows fire scenes to be semantically understood, is based on the SqueezeNet architecture. However, the abovementioned deep-learning-based models improved the fire detection accuracy, with minimum false alarms, but the complexity and size of the model are comparatively large, that is, 238MB [
23]. All of these studies utilized Foggia’s dataset [
9] as the main source of their training data.Ba et al. [
27] proposed a new convolutional neural network (CNN) model, SmokeNet, which incorporates spatial and channel-wise attention in CNN to enhance feature representation for scene classification. In this study, we proved that using a small kernel size and a small number of layers can improve the performance and generalizability of the current task. In fact, by conducting a number of experiments, we proved that this approach could overcome the overfitting problem for a small number of data samples.
In the image/video classification fields, CNN has outpaced and showed superior performance compared with other approaches because of its powerful feature extraction techniques and robust model structure. Consequently, in terms of performance, traditional computer vision methods are being replaced by deep learning methods. Our proposed method adopts a model to classify fire or smoke in images/videos. Misclassification of images or videos leads to an increase in false fire alarms because of variations in perspective distortions, shadows, and brightness. We detected images showing fire and smoke using a model based on dilated CNNs to learn and extract the robust features of a frame.
7. Conclusions
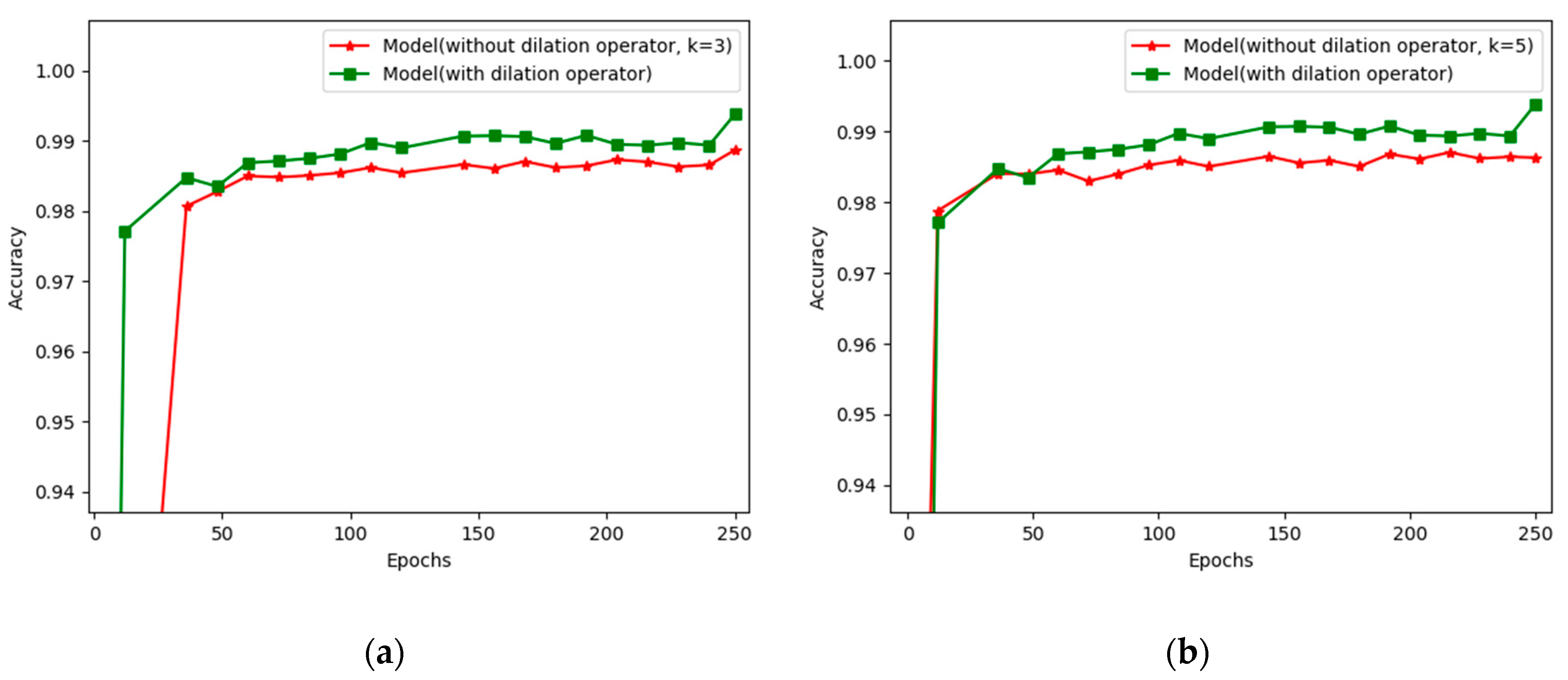
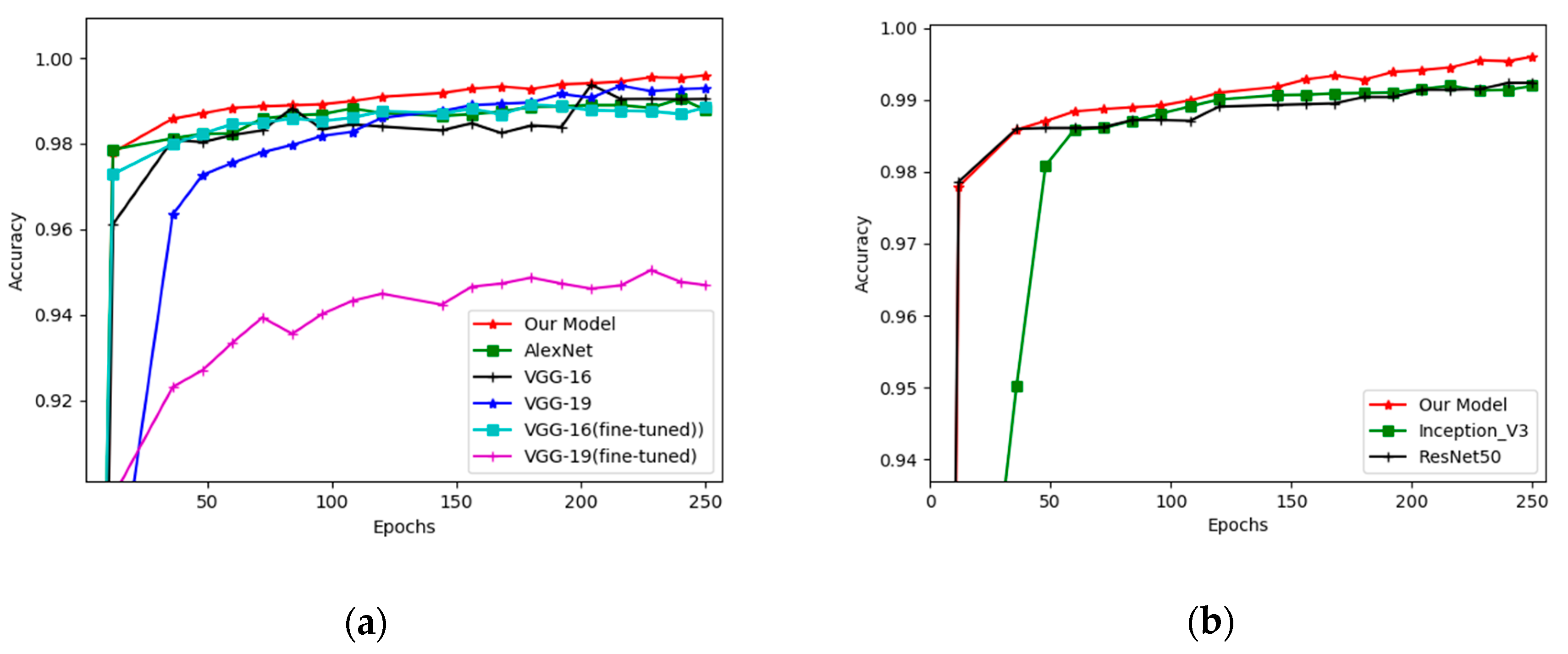
We presented new robust deep learning model architecture for classifying fire and smoke images captured by a camera or nearby surveillance systems. The proposed method is fully automatic, requires no manual intervention, and is designed to be well generalizable for unseen data. It offers effective generalization and reduces the number of false alarms. Based on the proposed fire detection method, our contributions include the following four main features: the use of dilation filters, a small number of layers, small kernel sizes, and a custom-built dataset, which was used in our experiments. This dataset is expected to be a useful asset for future research that requires images of fire and smoke. However, we are far from concluding that this is the best solution for this task, because all experiments were conducted on our custom dataset. We verified our method experimentally by conducting several experiments to demonstrate that employing a dilation operator and a small number of layers can boost the performance of the method by extracting valuable features. Moreover, using a small number of layers and less deep networks would allow the model to be used in devices with low computational power. During the experiments, we assessed the performances and generalizing abilities of well-known CNN architectures in comparison with those of our proposed method. The experimental results proved that the performance of our proposed method on our dataset was slightly superior to that of well-known neural network architectures.
Our future projection is to build a lightweight model with robust detection performance that would allow us to set up embedded devices, which have low computational capabilities.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}