
Early Identification of Corn and Soybean Using Crop Growth Curve Matching Method

Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data and Processing
2.2.1. HLS Data Collection
2.2.2. CDL Data Collection
2.2.3. Data Processing
2.3. Methods
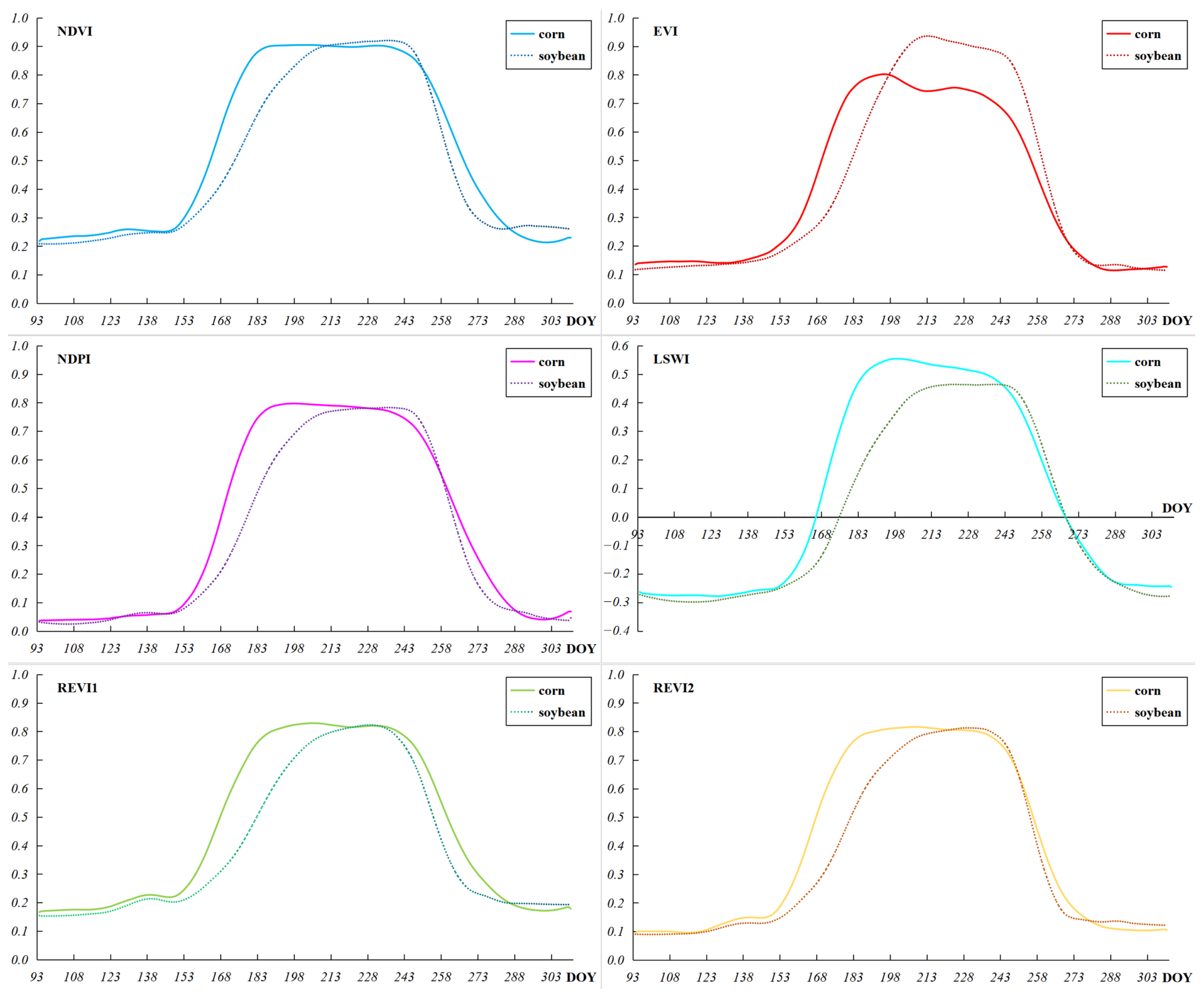
2.3.1. Construction of Vegetation Indices
2.3.2. Extraction of Crop Growth Curves
2.3.3. Classifier and Accuracy Assessment
3. Results
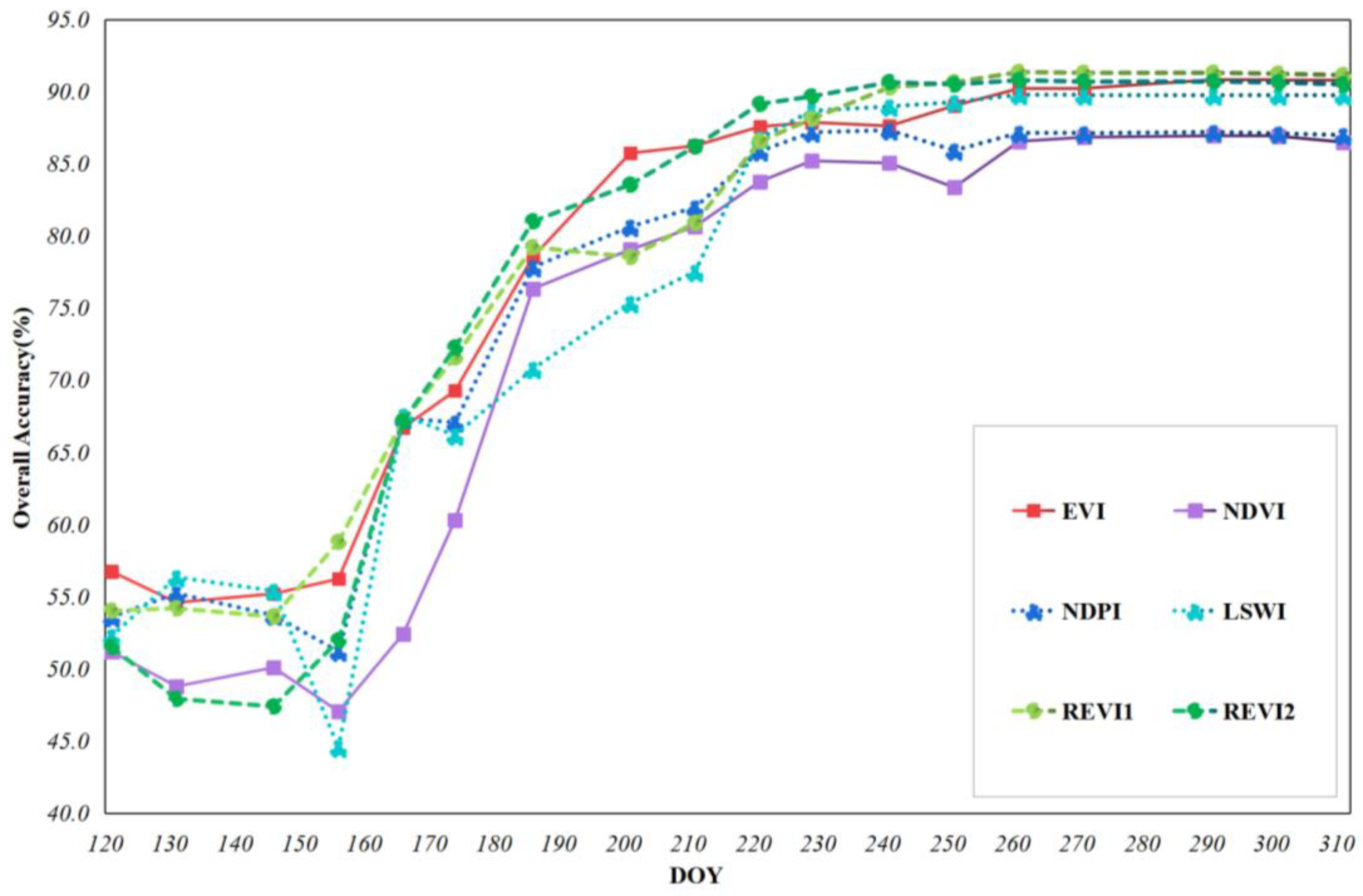
3.1. Identification Performance of the Six Indices
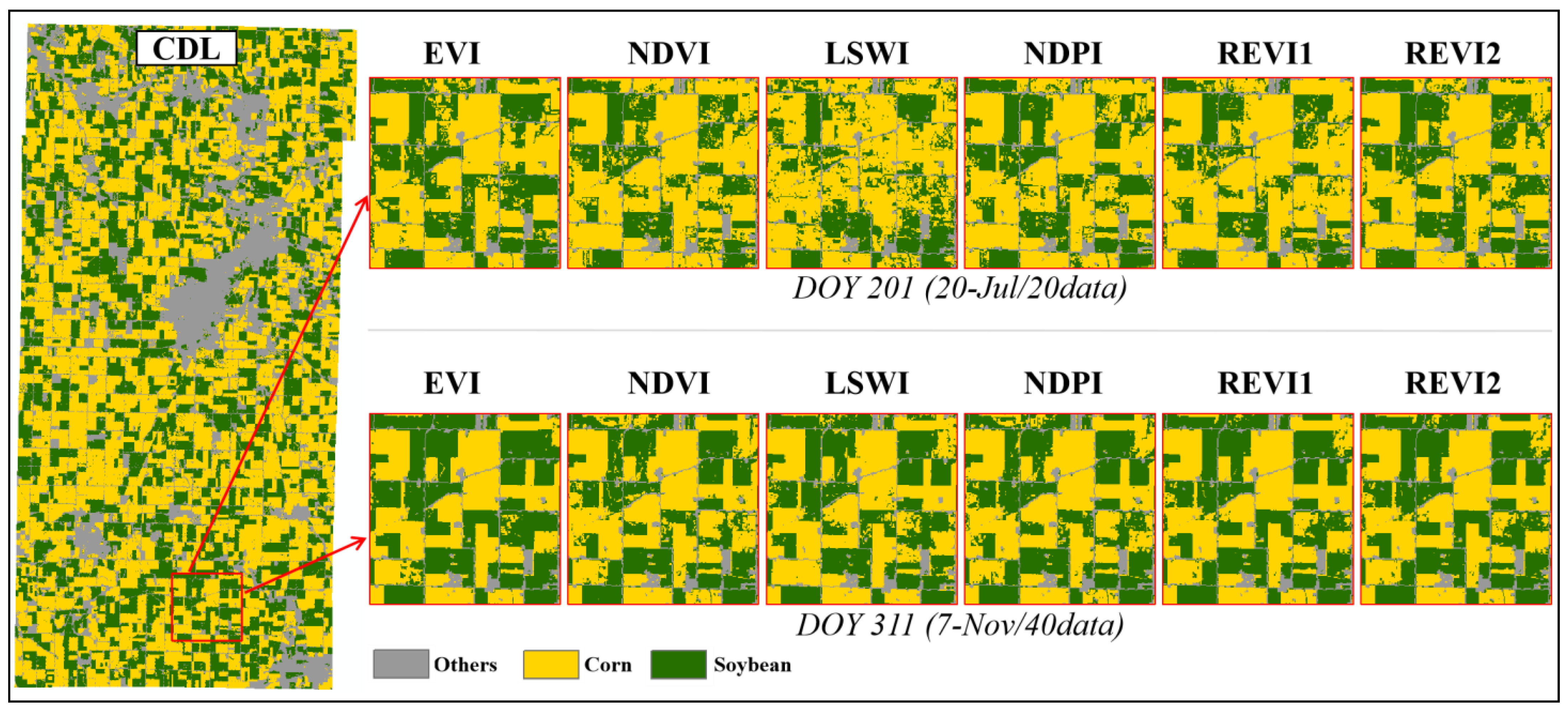
3.2. Comparison with Random Forest Mapping
3.3. Separability Index
4. Discussion
4.1. Performance of Crop Growth Curve Matching Method
4.2. Limitations and Recommendations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karthikeyan, L.; Chawla, I.; Mishra, A.K. A review of remote sensing applications in agriculture for food security: Crop growth and yield, irrigation, and crop losses. J. Hydrol. 2020, 586, 124905. [Google Scholar] [CrossRef]
- Toshihiro, S. Incorporating environmental variables into a MODIS-based crop yield estimation method for United States corn and soybeans through the use of a random forest regression algorithm. ISPRS J. Photogramm. Remote Sens. 2020, 160, 208–228. [Google Scholar]
- Wei, S.; Hong, Z.; Chao, W.; Wang, Y.; Xu, L. Multi-temporal SAR data large-scale crop mapping based on U-Net model. Remote Sens. 2019, 11, 68. [Google Scholar] [CrossRef]
- Shi, W.; Wang, M.; Liu, Y. Crop yield and production responses to climate disasters in China. Sci. Total Environ. 2021, 750, 141147. [Google Scholar] [CrossRef] [PubMed]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef] [PubMed]
- Lobell, D.B.; David, T.; Christopher, S.; Eric, E.; Bertis, L. A scalable satellite-based crop yield mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Wu, B.; Zhang, M.; Zeng, H.; Tian, F.; Potgieter, A.B.; Qin, X.; Yan, N.; Chang, S.; Zhao, Y.; Dong, Q.; et al. Challenges and opportunities in remote sensing-based crop monitoring: A review. Natl. Sci. Rev. 2023, 10, 290. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-optical fusion for crop type mapping using deep learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Chakhar, A.; Ortega-Terol, D.; Hernández-López, D.; Ballesteros, R.; Ortega, J.F.; Moreno, M.A. Assessing the accuracy of multiple classification algorithms for crop classification using Landsat-8 and Sentinel-2 Data. Remote Sens. 2020, 12, 1735. [Google Scholar] [CrossRef]
- Löw, F.; Knöfel, P.; Conrad, C. Analysis of uncertainty in multi-temporal object-based classification. ISPRS J. Photogramm. Remote Sens. 2015, 105, 91–106. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Liu, Z. Early-season crop mapping using improved artificial immune network (IAIN) and Sentinel data. PeerJ 2018, 6, e5431. [Google Scholar] [CrossRef] [PubMed]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using random forest: A case study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, B.; Ponce-Campos, G.E.; Zhang, M.; Chang, S.; Tian, F. Mapping up-to-date paddy rice extent at 10 m resolution in China through the integration of optical and synthetic aperture radar images. Remote Sens. 2018, 10, 1200. [Google Scholar] [CrossRef]
- Hao, P.; Wang, L.; Zhan, Y.; Niu, Z. Using moderate-resolution temporal NDVI profiles for high-resolution crop mapping in years of absent ground reference data: A case study of Bole and Manas counties in Xinjiang, China. ISPRS Int. J. Geo-Inf. 2016, 5, 67. [Google Scholar] [CrossRef]
- You, N.; Dong, J. Examining earliest identifiable timing of crops using all available Sentinel 1/2 imagery and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 161, 109–123. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, Z.; Jiang, H.; Jing, W.; Sun, L.; Feng, M. Evaluation of three deep learning models for early crop classification using Sentinel-1A imagery time series—A case study in Zhanjiang, China. Remote Sens. 2019, 11, 2673. [Google Scholar] [CrossRef]
- Yi, Z.; Li, J.; Chen, Q. Crop classification using multi-temporal Sentinel-2 data in the Shiyang river basin of China. Remote Sens. 2020, 12, 4052. [Google Scholar] [CrossRef]
- Luan, P.; Telmo, J.; Raí, A.; Geomar, M.; Ignacio, A. Satellite-based data fusion crop type classification and mapping in Rio Grande do Sul, Brazil. ISPRS J. Photogramm. Remote Sens. 2021, 176, 196–210. [Google Scholar]
- You, N.; Dong, J.; Li, J.; Huang, J.; Jin, Z. Rapid early-season maize mapping without crop labels. Remote Sens. Environ. 2023, 290, 113496. [Google Scholar] [CrossRef]
- Lin, C.; Zhong, L.; Song, X.; Dong, J.; Lobell, D.B.; Jin, Z. Early- and in-season crop type mapping without current-year ground truth: Generating labels from historical information via a topology-based approach. Remote Sens. Environ. 2022, 274, 112994. [Google Scholar] [CrossRef]
- Mao, M.; Zhao, H.; Tang, G.; Ren, J. In-season crop type detection by combing Sentinel-1A and Sentinel-2 imagery based on the CNN model. Agronomy 2023, 13, 1723. [Google Scholar] [CrossRef]
- McNairn, H.; Kross, A.; Lapen, D.; Caves, R.; Shang, J. Early season monitoring of corn and soybeans with TerraSAR-X and RADARSAT-2. Int. J. Appl. Earth Obs. 2014, 28, 252–259. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Yu, L.; Gong, P.; Biging, G.S. Automated mapping of soybean and corn using phenology. ISPRS J. Photogramm. Remote Sens. 2016, 119, 151–164. [Google Scholar] [CrossRef]
- Skakun, S.; Franch, B.; Vermote, E.; Jean-Claude, R.; Inbal, B.; Christopher, J.; Nataliia, K. Early season large-area winter crop mapping using MODIS NDVI data, growing degree days information and a Gaussian mixture model. Remote Sens. Environ. 2017, 195, 244–258. [Google Scholar] [CrossRef]
- Xun, L.; Wang, P.; Li, L.; Wang, L.; Kong, Q. Identifying crop planting areas using Fourier-transformed feature of time series MODIS leaf area index and sparse-representation-based classification in the North China Plain. Int. J. Remote Sens. 2019, 40, 2034–2052. [Google Scholar] [CrossRef]
- Guo, Y.; Xia, H.; Zhao, X.; Qiao, L.; Du, Q.; Qin, Y. Early-season mapping of winter wheat and garlic in Huaihe Basin using Sentinel-1/2 and Landsat-7/8 imagery. IEEE J.-STARS 2023, 16, 8809–8817. [Google Scholar] [CrossRef]
- Tian, H.; Wang, Y.; Chen, T.; Zhang, L.; Qin, Y. Early-Season Mapping of Winter Crops Using Sentinel-2 Optical Imagery. Remote Sens. 2021, 13, 3822. [Google Scholar] [CrossRef]
- Wei, P.; Ye, H.; Qiao, S.; Liu, R.; Nie, C.; Zhang, B.; Song, L.; Huang, S. Early Crop Mapping Based on Sentinel-2 Time-Series Data and the Random Forest Algorithm. Remote Sens. 2023, 15, 3212. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.; Daughtry, C.; Karnieli, A.; Hively, D.; Kustas, W. A within-season approach for detecting early growth stages in corn and soybean using high temporal and spatial resolution imagery. Remote Sens. Environ. 2020, 242, 111752. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Xuan, F.; Dong, Y.; Li, J.; Li, X.; Su, W.; Huang, X.; Huang, J.; Xie, Z.; Li, Z.; Liu, H.; et al. Mapping crop type in Northeast China during 2013–2021 using automatic sampling and tile-based image classification. Int. J. Appl. Earth Obs. 2023, 117, 103178. [Google Scholar] [CrossRef]
- Luo, K.; Lu, L.; Xie, Y.; Chen, F.; Yin, F.; Li, Q. Crop type mapping in the central part of the North China Plain using Sentinel-2 time series and machine learning. Comput. Electron. Agric. 2023, 205, 107577. [Google Scholar] [CrossRef]
- Blickensdörfer, L.; Schwieder, M.; Pflugmacher, D.; Nendel, C.; Erasmi, S.; Hostert, P. Mapping of crop types and crop sequences with combined time series of Sentinel-1, Sentinel-2 and Landsat 8 data for Germany. Remote Sens. Environ. 2022, 269, 112831. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Zhou, Q.; Rover, J.; Brown, J.; Worstell, B.; Howard, D.; Wu, Z.; Gallant, A.L.; Rundquist, B.; Burke, M. Monitoring landscape dynamics in Central U.S. grasslands with Harmonized Landsat-8 and Sentinel-2 time series data. Remote Sens. 2019, 11, 328. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Yu, L.; Wu, M. High resolution crop intensity mapping using harmonized Landsat-8 and Sentinel-2 data. J. Integr. Agric. 2019, 18, 2883–2897. [Google Scholar] [CrossRef]
- Amini, S.; Saber, M.; Rabiei-Dastjerdi, H.; Homayouni, S. Urban land use and land cover change analysis using random forest classification of Landsat time series. Remote Sens. 2022, 14, 2654. [Google Scholar] [CrossRef]
- Daryaei, A.; Sohrabi, H.; Atzberger, C.; Immitzer, M. Fine-scale detection of vegetation in semi-arid mountainous areas with focus on riparian landscapes using Sentinel-2 and UAV data. Comput. Electron. Agric. 2020, 177, 105686. [Google Scholar] [CrossRef]
- Albarrak, K.; Gulzar, Y.; Hamid, Y.; Mehmood, A.; Soomro, A.B. A deep learning-based model for date fruit classification. Sustainability 2022, 14, 6339. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit image classification model based on MobileNetV2 with deep transfer learning technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Lin, L.; Zhao, H.; Li, H.; Yang, A.; Guo, L.; Yang, Z. Cyberinformatics tool for in-season crop-specific land cover monitoring: Design, implementation, and applications of iCrop. Comput. Electron. Agric. 2023, 213, 108199. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, X.; Yang, Z. Mapping corn and soybean phenometrics at field scales over the United States Corn Belt by fusing time series of Landsat 8 and Sentinel-2 data with VIIRS data. ISPRS J. Photogramm. Remote Sens. 2022, 186, 55–69. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Meng, Q.; Kang, Y. Early-season crop type mapping using 30-m reference time series. J. Integr. Agric. 2020, 19, 1897–1911. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Wardlow, B.D.; Keydan, G.P.; Leavitt, B. An evaluation of MODIS 250-m data for green LAI estimation in crops. Geophys. Res. Lett. 2007, 34, L20403. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. A comparison of MODIS 250-m EVI and NDVI data for crop mapping: A case study for southwest Kansas. Int. J. Remote Sens. 2010, 31, 805–830. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Kou, W.; Qin, Y.; Zhang, G.; Li, L.; Jin, C.; Zhou, Y.; Wang, J.; Biradar, C.; et al. Tracking the dynamics of paddy rice planting area in 1986–2010 through time series Landsat images and phenology-based algorithms. Remote Sens. Environ. 2015, 160, 99–113. [Google Scholar] [CrossRef]
- Wang, C.; Chen, J.; Wu, J.; Tang, Y.; Shi, P.; Black, T.A.; Zhu, K. A snow-free vegetation index for improved monitoring of vegetation spring green-up date in deciduous ecosystems. Remote Sens. Environ. 2017, 196, 1–12. [Google Scholar] [CrossRef]
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near real-time agriculture monitoring at national scale at parcel resolution: Performance assessment of the Sen2-Agri automated system in various cropping systems around the world. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Sun, Y.; Qin, Q.; Ren, H.; Zhang, T.; Chen, S. Red-Edge Band Vegetation Indices for Leaf Area Index Estimation from Sentinel-2/MSI Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 826–840. [Google Scholar] [CrossRef]
- Sun, L.; Gao, F.; Xie, D.; Anderson, M.; Chen, R.; Yang, Y.; Yang, Y.; Chen, Z. Reconstructing daily 30 m NDVI over complex agricultural landscapes using a crop reference curve approach. Remote Sens. Environ. 2021, 253, 112156. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Hu, Q.; Sulla-Menashe, D.; Xu, B.; Yin, H.; Tang, H.; Yang, P.; Wu, W. A phenology-based spectral and temporal feature selection method for crop mapping from satellite time series. Int. J. Appl. Earth Obs. 2019, 80, 218–229. [Google Scholar] [CrossRef]
- Somers, B.; Asner, G.P. Multi-temporal hyperspectral mixture analysis and feature selection for invasive species mapping in rainforests. Remote Sens. Environ. 2013, 136, 14–27. [Google Scholar] [CrossRef]
- Becker-Reshef, I.; Justice, C.; Barker, B.; Humber, M.; Rembold, F.; Bonifacio, R.; Zappacosta, M.; Budde, M.; Magadzire, T.; Shitote, C.; et al. Strengthening agricultural decisions in countries at risk of food insecurity: The GEOGLAM crop monitor for early warning. Remote Sens. Environ. 2020, 237, 111553. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input image number | 5 | 7 | 8 | 10 | 13 | 16 |
| DOY | 121 | 131 | 146 | 156 | 166 | 174 |
| Date | 1-May | 11-May | 26-May | 5-Jun | 15-Jun | 23-Jun |
| Input image number | 18 | 20 | 23 | 26 | 28 | 30 |
| DOY | 186 | 201 | 211 | 221 | 229 | 241 |
| Date | 5-Jul | 20-Jul | 30-Jul | 9-Aug | 17-Aug | 29-Aug |
| Input image number | 32 | 34 | 36 | 37 | 38 | 40 |
| DOY | 251 | 261 | 271 | 291 | 301 | 311 |
| Date | 8-Sep | 18-Sep | 28-Sep | 18-Oct | 28-Oct | 7-Nov |
| HLS-S30 Band Code Name | Wavelength (Micrometers) | Band |
|---|---|---|
| B02 | 0.45–0.51 | Blue |
| B04 | 0.64–0.67 | Red |
| B05 | 0.69–0.71 | Red-Edge 1 |
| B07 | 0.77–0.79 | Red-Edge 3 |
| B8A | 0.85–0.88 | NIR Narrow |
| B11 | 1.57–1.65 | SWIR 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Sun, L.; Chen, Z.; Wuyun, D.; Sun, Z. Early Identification of Corn and Soybean Using Crop Growth Curve Matching Method. Agronomy 2024, 14, 146. https://doi.org/10.3390/agronomy14010146
Chen R, Sun L, Chen Z, Wuyun D, Sun Z. Early Identification of Corn and Soybean Using Crop Growth Curve Matching Method. Agronomy. 2024; 14(1):146. https://doi.org/10.3390/agronomy14010146
Chicago/Turabian StyleChen, Ruiqing, Liang Sun, Zhongxin Chen, Deji Wuyun, and Zheng Sun. 2024. "Early Identification of Corn and Soybean Using Crop Growth Curve Matching Method" Agronomy 14, no. 1: 146. https://doi.org/10.3390/agronomy14010146