
Wheat Lodging Direction Detection for Combine Harvesters Based on Improved K-Means and Bag of Visual Words

Abstract
:1. Introduction
2. Existing and Improved K-Means Algorithms
2.1. Existing K-Means Algorithm with Random Initial Centers and Experiential Number of Classes
2.2. Improved K-Means Algorithm Based on Cluster Validity Evaluation Function and Multichannel and Multidimensional Feature Vector
2.2.1. Determining the Number of Clustering Classes Based on Weighted Cluster Validity Evaluation Function
2.2.2. Determining Initial Clustering Centers Based on the Principle of Maximum and Minimum Distances
2.2.3. Distances between Samples Represented by Multichannel and Multidimensional Feature Vector
2.2.4. Simplifying Distance Calculations by Triangle Inequality
2.2.5. Improved K-Means Algorithm Process
3. Local Direction Detection of Wheat Lodging Based on BOVW
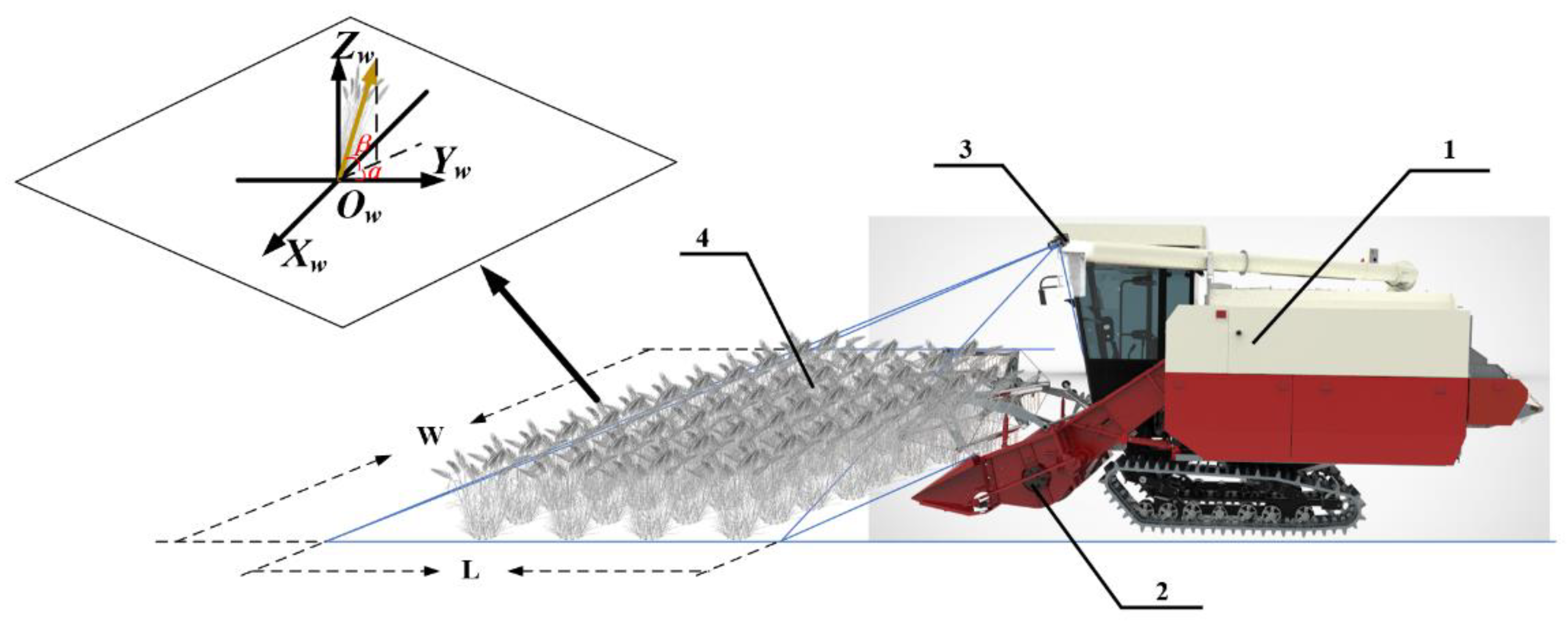
3.1. Wheat Lodging Direction Detection Model for Combine Harvesters Using Vehicle Vision
3.1.1. Model Construction
3.1.2. IPM and Correction
3.2. Dataset Constructed Using Adaptive Image Grid Division
3.2.1. The Local Region of Interest (ROI) for Wheat Lodging Direction Detection
3.2.2. Adaptive Image Grid Division Based on PM and IPM
3.2.3. Dataset Construction
3.3. The Construction of the BOVW Based on the Improved K-Means Algorithm
- Image feature point extraction based on SIFT
- 2.
- BOVW construction
3.4. Local Direction Detection of Wheat Lodging
4. Results
4.1. Experimental Platform
4.2. Experimental Methods
4.2.1. The Experiment Method for the Comparison of BOVW Construction Methods
4.2.2. The Experiment Method for the Comparison of Wheat Lodging Direction Detection Methods
4.3. Experimental Results and Discussion
4.3.1. Experiment Results for the Comparison of BOVW Construction Methods
4.3.2. Experiment Results for the Comparison of Wheat Lodging Direction Detection Methods
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, S.; Hao, J.; Li, H.; Zuo, C.; Geng, X.; Sun, X. Monitoring wheat lodging at various growth stages. Sensors 2022, 22, 6967. [Google Scholar] [CrossRef]
- Yang, S.; Wang, P.; Wang, S.; Tang, Y.; Ning, J.; Xi, Y. Detection of wheat lodging in UAV remote sensing images based on multi-head self-attention DeepLab v3+. Trans. Chin. Soc. Agric. Mach. 2022, 53, 213–219, 239. [Google Scholar]
- Wen, J.; Yin, Y.; Zhang, Y.; Pan, Z.; Fan, Y. Detection of wheat lodging by binocular cameras during harvesting operation. Agriculture 2023, 13, 120. [Google Scholar] [CrossRef]
- Chauhan, S.; Darvishzadeh, R.; Boschetti, M.; Pepe, M.; Nelson, A. Remote sensing-based crop lodging assessment: Current status and perspectives. ISPRS J. Photogramm. Remote Sens. 2019, 151, 124–140. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, L.; Pei, Z.; Sun, J.; Li, H.; Jiao, W.; You, J. A simple and robust spectral index for identifying lodged maize using Gaofen1 satellite data. Sensors 2022, 22, 989. [Google Scholar] [CrossRef]
- Guan, H.; Huang, J.; Li, L.; Li, X.; Ma, Y.; Niu, Q.; Huang, H. A novel approach to estimate maize lodging area with PolSAR data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Yang, X.; Song, X.; Xu, B.; Li, Z.; Wu, J.; Yang, H.; Wu, J. An explainable XGBoost model improved by SMOTE-ENN technique for maize lodging detection based on multi-source unmanned aerial vehicle images. Comput. Electron. Agric. 2022, 194, 106804. [Google Scholar] [CrossRef]
- Kang, G.; Wang, J.; Zeng, F.; Cai, Y.; Kang, G.; Yue, X. Lightweight detection system with global attention network (GloAN) for rice lodging. Plants 2023, 12, 1595. [Google Scholar] [CrossRef]
- Dai, X.; Chen, S.; Jia, K.; Jiang, H.; Sun, Y.; Li, D.; Zheng, Q.; Huang, J. A decision-tree approach to identifying paddy rice lodging with multiple pieces of polarization information derived from Sentinel-1. Remote Sens. 2023, 15, 240. [Google Scholar] [CrossRef]
- Murakami, T.; Yui, M.; Amaha, K. Canopy height measurement by photogrammetric analysis of aerial images: Application to buckwheat (Fagopyrum esculentum Moench) lodging evaluation. Comput. Electron. Agric. 2012, 89, 70–75. [Google Scholar] [CrossRef]
- Han, D.; Yang, H.; Yang, G.; Qiu, C. Monitoring model of corn lodging based on Sentinel-1 radar image. In 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA); IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Liu, T.; Li, R.; Zhong, X.; Jiang, M.; Jin, X.; Zhou, P.; Liu, S.; Sun, C.; Guo, W. Estimates of rice lodging using indices derived from UAV visible and thermal infrared images. Agric. For. Meteorol. 2018, 252, 144–154. [Google Scholar] [CrossRef]
- Zhao, X.; Yuan, Y.; Song, M.; Ding, Y.; Lin, F.; Liang, D.; Zhang, D. Use of unmanned aerial vehicle imagery and deep learning UNet to extract rice lodging. Sensors 2019, 19, 3859. [Google Scholar] [CrossRef] [PubMed]
- Wan, L.; Du, X.; Chen, S.; Yu, F.; Zhu, J.; Xu, T.; He, Y.; Cen, H. Rice panicle phenotyping using UAV-based multi-source spectral image data fusion. Trans. Chin. Soc. Agric. Eng. 2022, 38, 162–170. [Google Scholar]
- Xie, B.; Wang, J.; Jiang, H.; Zhao, S.; Liu, J.; Jin, Y.; Li, Y. Multi-feature detection of in-field grain lodging for adaptive low-loss control of combine harvesters. Comput. Electron. Agric. 2023, 208, 107772. [Google Scholar] [CrossRef]
- Chauhan, S.; Darvishzadeh, R.; Boschetti, M.; Nelson, A. Discriminant analysis for lodging severity classification in wheat using RADARSAT-2 and Sentinel-1 data. ISPRS J. Photogramm. Remote Sens. 2020, 164, 138–151. [Google Scholar] [CrossRef]
- Chauhan, S.; Darvishzadeh, R.; Boschetti, M.; Nelson, A. Estimation of crop angle of inclination for lodged wheat using multi-sensor SAR data. Remote Sens. Environ. 2020, 236, 111488. [Google Scholar] [CrossRef]
- Yu, J.; Cheng, T.; Cai, N.; Lin, F.; Zhou, X.; Du, S.; Zhang, D.; Zhang, G.; Liang, D. Wheat lodging extraction using Improved_Unet network. Front. Plant Sci. 2022, 13, 1009835. [Google Scholar] [CrossRef]
- Biswal, S.; Chatterjee, C.; Mailapalli, D.R. Damage assessment due to wheat lodging using UAV-based multispectral and thermal imageries. J. Indian Soc. Remote Sens. 2023, 51, 935–948. [Google Scholar] [CrossRef]
- Hu, X.; Gu, X.; Sun, Q.; Yang, Y.; Qu, X.; Yang, X.; Guo, R. Comparison of the performance of multi-source three-dimensional structural data in the application of monitoring maize lodging. Comput. Electron. Agric. 2023, 208, 107782. [Google Scholar] [CrossRef]
- Cao, W.; Qiao, Z.; Gao, Z.; Lu, S.; Tian, F. Use of unmanned aerial vehicle imagery and a hybrid algorithm combining a watershed algorithm and adaptive threshold segmentation to extract wheat lodging. Phys. Chem. Earth 2021, 123, 103016. [Google Scholar] [CrossRef]
- Sun, Q.; Chen, L.; Xu, X.; Gu, X.; Hu, X.; Yang, F.; Pan, Y. A new comprehensive index for monitoring maize lodging severity using UAV-based multi-spectral imagery. Comput. Electron. Agric. 2022, 202, 107362. [Google Scholar] [CrossRef]
- Modi, R.U.; Chandel, A.K.; Chandel, N.S.; Dubey, K.; Subeesh, A.; Singh, A.K.; Jat, D.; Kancheti, M. State-of-the-art computer vision techniques for automated sugarcane lodging classification. Field Crops Res. 2023, 291, 108797. [Google Scholar] [CrossRef]
- Sun, J.; Zhou, J.; He, Y.; Jia, H.; Liang, Z. RL-DeepLabv3+: A lightweight rice lodging semantic segmentation model for unmanned rice harvester. Comput. Electron. Agric. 2023, 209, 107823. [Google Scholar] [CrossRef]
- Yu, J.; Cheng, T.; Cai, N.; Zhou, X.G.; Diao, Z.; Wang, T.; Du, S.; Liang, D.; Zhang, D. Wheat lodging segmentation based on Lstm_PSPNet deep learning network. Drones 2023, 7, 143. [Google Scholar] [CrossRef]
- Tang, Z.; Sun, Y.; Wan, G.; Zhang, K.; Shi, H.; Zhao, Y.; Chen, S.; Zhang, X. Winter wheat lodging area extraction using deep learning with GaoFen-2 satellite imagery. Remote Sens. 2022, 14, 4887. [Google Scholar] [CrossRef]
- Huang, X.; Xuan, F.; Dong, Y.; Su, W.; Wang, X.; Huang, J.; Li, X.; Zeng, Y.; Miao, S.; Li, J. Identifying corn lodging in the mature period using Chinese GF-1 PMS images. Remote Sens. 2023, 15, 894. [Google Scholar] [CrossRef]
- Zhu, H.; Luo, C.; Guan, H.; Zhang, X.; Yang, J.; Song, M.; Liu, H. Object-oriented extraction of maize fallen area based on multi-source satellite remote sensing images. Remote Sens. Technol. Appl. 2022, 37, 599–607. [Google Scholar]
- Shu, M.; Bai, K.; Meng, L.; Yang, X.; Li, B.; Ma, Y. Assessing maize lodging severity using multitemporal UAV-based digital images. Eur. J. Agron. 2023, 144, 126754. [Google Scholar] [CrossRef]
- Yu, M.; Liu, X.J. Computer image content retrieval considering k-means clustering algorithm. Math. Probl. Eng. 2022, 2022, 7. [Google Scholar] [CrossRef]
- Singh, J.P.; Bouguila, N. Proportional data clustering using k-means algorithm: A comparison of different distances. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Lin, J.T.; Peng, J.W. Adaptive inverse perspective mapping transformation method for ballasted railway based on differential edge detection and improved perspective mapping model. Digit. Signal Process. 2023, 135, 11. [Google Scholar] [CrossRef]
- Hu, M.; Tsang, E.C.C.; Guo, Y.; Zhang, Q. An improved k-means algorithm with spatial constraints for image segmentation. In Proceedings of the 20th International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 4–5 December 2021. Electr Network. [Google Scholar]
- Yu, L.; Chang, Z.; Xue, S.; Quan, Z. Hyperspectral image classification algorithm based on entropy weighted K-means with global information. J. Image Graph. 2019, 24, 630–638. [Google Scholar]
- Xiaotian, M.; Yanlei, X.; Xindong, W.; Run, H.; Yuting, Z. Crop line detection based on improved k-means feature point clustering algorithm. J. Agric. Mech. Res. 2020, 42, 26–30. [Google Scholar]
- Chunhui, Z.; Ying, W.; Kaneko, M. Improved k-means clustering method for codebook generation. Chin. J. Sci. Instrum. 2012, 33, 2380–2386. [Google Scholar]
- Zhang, Q.; Gao, G.Q. Hand-eye calibration and grasping pose calculation with motion error compensation and vertical-component correction for 4-R(2-SS) parallel robot. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420909012. [Google Scholar] [CrossRef]
- Luo, Y.; Wei, L.; Xu, L.; Zhang, Q.; Liu, J.; Cai, Q.; Zhang, W. Stereo-vision-based multi-crop harvesting edge detection for precise automatic steering of combine harvester. Biosyst. Eng. 2022, 215, 115–128. [Google Scholar] [CrossRef]
- Zhang, Q.; Hu, J.; Xu, L.; Cai, Q.; Yu, X.; Liu, P. Impurity/breakage assessment of vehicle-mounted dynamic rice grain flow on combine harvester based on improved Deeplabv3+ and YOLOv4. IEEE Access 2023, 11, 49273–49288. [Google Scholar] [CrossRef]
- Zhang, Q.; Gao, G. Prioritizing robotic grasping of stacked fruit clusters based on stalk location in RGB-D images. Comput. Electron. Agric. 2020, 172, 105359. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 0 /% | 1 /% | 2 /% | 3 /% | 4 /% | 5 /% | 6 /% | 7 /% | 8 /% | mAP/% |
|---|---|---|---|---|---|---|---|---|---|---|
| SWF-EK | 93.62 | 89.25 | 90.70 | 89.77 | 89.53 | 85.42 | 87.64 | 90.11 | 95.40 | 90.16 |
| SWF-IK | 95.74 | 96.77 | 98.84 | 97.83 | 97.67 | 94.74 | 95.40 | 95.51 | 97.73 | 96.69 |
| PWF-IK | 95.74 | 98.89 | 98.85 | 97.83 | 97.70 | 95.74 | 95.45 | 96.55 | 96.70 | 97.05 |
| Methods | 0 /% | 1 /% | 2 /% | 3 /% | 4 /% | 5 /% | 6 /% | 7 /% | 8 /% | mAP/% |
|---|---|---|---|---|---|---|---|---|---|---|
| SWF-EK | 97.78 | 92.22 | 86.67 | 87.78 | 85.56 | 91.11 | 86.67 | 91.11 | 92.22 | 90.12 |
| SWF-IK | 100 | 100 | 94.44 | 100 | 93.33 | 100 | 92.22 | 94.44 | 95.56 | 96.67 |
| PWF-IK | 100 | 98.89 | 95.56 | 100 | 94.44 | 100 | 93.33 | 93.33 | 97.78 | 97.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Chen, Q.; Xu, L.; Xu, X.; Liang, Z. Wheat Lodging Direction Detection for Combine Harvesters Based on Improved K-Means and Bag of Visual Words. Agronomy 2023, 13, 2227. https://doi.org/10.3390/agronomy13092227
Zhang Q, Chen Q, Xu L, Xu X, Liang Z. Wheat Lodging Direction Detection for Combine Harvesters Based on Improved K-Means and Bag of Visual Words. Agronomy. 2023; 13(9):2227. https://doi.org/10.3390/agronomy13092227
Chicago/Turabian StyleZhang, Qian, Qingshan Chen, Lizhang Xu, Xiangqian Xu, and Zhenwei Liang. 2023. "Wheat Lodging Direction Detection for Combine Harvesters Based on Improved K-Means and Bag of Visual Words" Agronomy 13, no. 9: 2227. https://doi.org/10.3390/agronomy13092227