
Cucumber Picking Recognition in Near-Color Background Based on Improved YOLOv5
 ,
,
Abstract
:1. Introduction
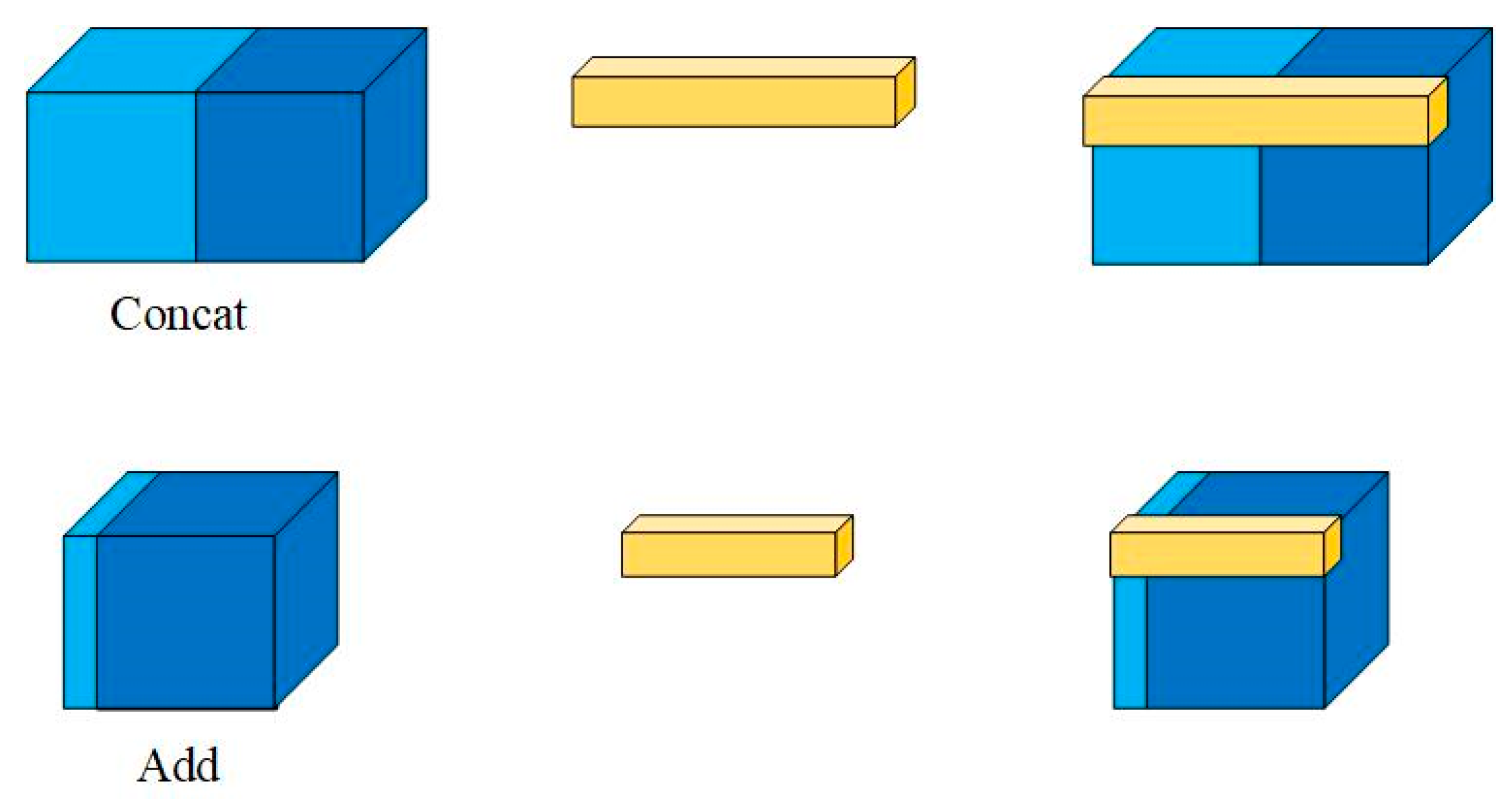
- BiFPN is introduced to achieve multi-scale feature fusion more efficiently. Moreover, the effect of two different feature fusion operations, Concat and Add, on the model performance is compared. And to facilitate result interpretation, the Gradient-weighted Class Activation Mapping (Grad-CAM) method is employed to provide a visual explanation for each model.
- C3CA module is added to enhance the feature extraction capability for cucumber shoulder detection. A non-parametric hybrid module based on the energy function, the C3SimAM module, is designed. Five hybrid modules, namely C3CA, C3CBAM, C3SE, C3ECA and C3SimAM, are compared.
- The Ghost module is added to speed up the inference time and floating-point computation speed of the model, to realize the operation of lightweight, and to facilitate the deployment of the model with low computing power.
- The contribution of the BiFPN, C3CA module, and Ghost module to model performance optimization is verified through ablation experiments, and the functional compatibility of the three modules is analyzed. The experimental results are compared with several mainstream single-stage detection models to validate the advantage in performance of the YOLOv5s-S models.
2. Materials and Methods
2.1. Acquisition and Annotation of Images
2.2. The Improved Model
2.2.1. YOLO5s-S Model
2.2.2. The Algorithm Principle of YOLOv5
2.2.3. The CA Module
2.2.4. Ghost Module
2.2.5. BiFPN
2.3. Environment Construction and Evaluation Indicators
2.3.1. Environment Construction
2.3.2. Evaluation Indicators
3. Results
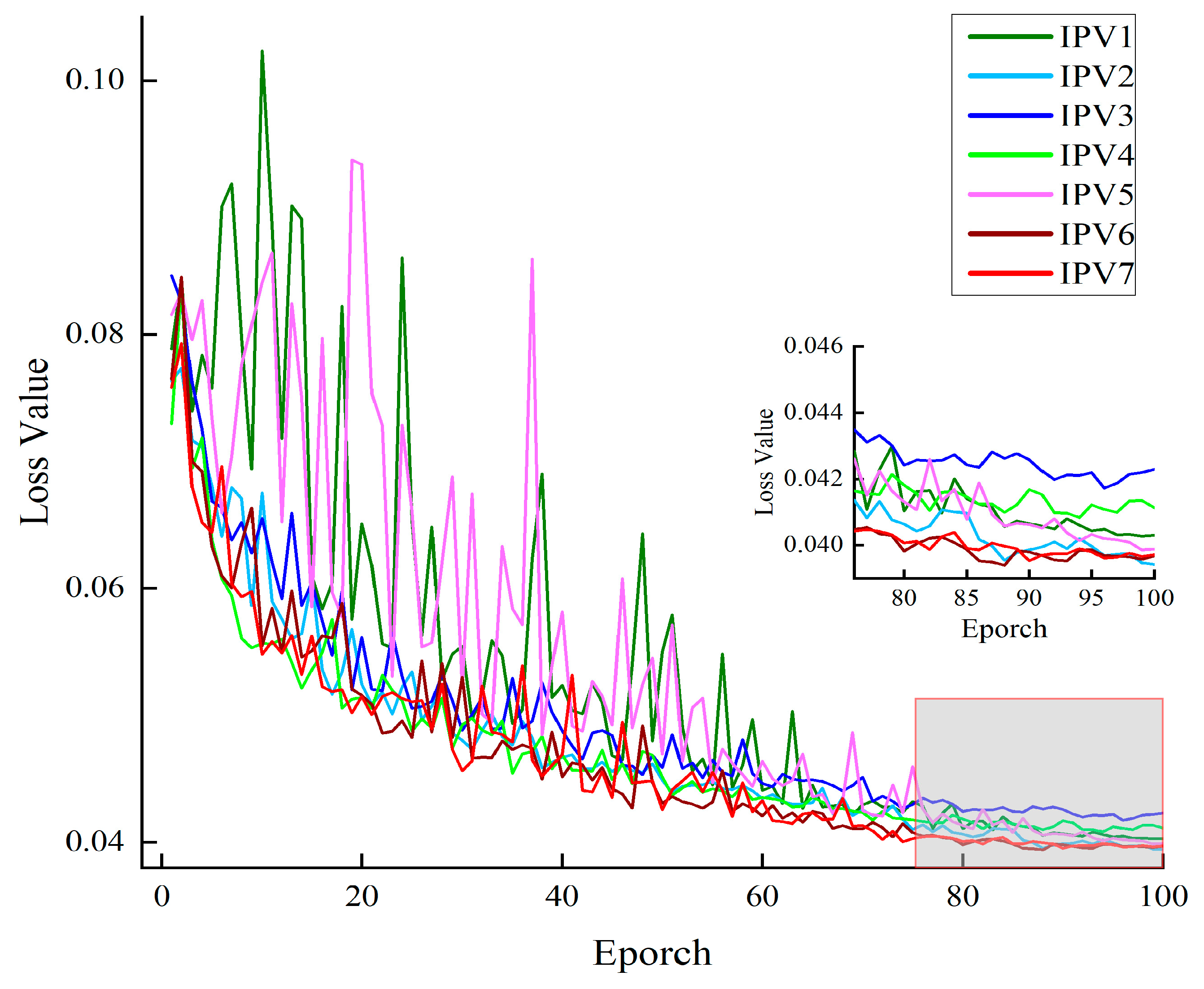
3.1. Comparison of Feature Fusion
3.2. Comparison of Attentional Mechanism
3.3. Ablation Experiment
3.4. Comparison of Traditional Network Models
3.5. Model Detection for Test Set
4. Discussion
- The improved model will be used in the subsequent keypoint study to realize the point-wise localization of the picked cucumber pixels in the 2D plane and to experimentally verify the accuracy of the picked point localization. Low computing power deployments, such as the Jetson nano platform, will be realized in the future.
- The YOLOv5s-S model will be used as a basis to carry out research on yield prediction, growth detection, and maturity detection of cucumber. The performance of the YOLOv5s-S model will be fully developed to improve the technical support for the intelligent cultivation of cucumbers.
5. Conclusions
- The YOLOv5s-S model with BiFPN_Concat outperformed both the YOLOv5s model with PAN and the YOLOv5s-S model with BiFPN_Add, as demonstrated through Grad-CAM visualization. It allowed better extraction of cucumber shoulder features and improved the robustness of the detection algorithm in multi-scale and near-color situations.
- The C3CA module outperformed the C3SE, C3CBAM and C3ECA modules. It also outperformed C3SimAM in terms of detection accuracy, which is a parameter-free attention mechanism. The C3CA module gave better attention to the cucumber shoulder.
- All three improvement terms contributed to the model performance improvement, as verified by ablation experiments. There was also some mutual compatibility among the three models.
- The YOLOv5s-S model surpassed lightweight models like YOLOv7-tiny and YOLOv8s in terms of performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, N.; Qian, T.; Yang, J.; Li, L.; Zhang, Y.; Zheng, X.; Xu, Y.; Zhao, H.; Zhao, J. An Enhanced YOLOv5 Model for Greenhouse Cucumber Fruit Recognition Based on Color Space Features. Agriculture 2022, 12, 1556. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Ruan, C.; Sun, Y. Cucumber Fruits Detection in Greenhouses Based on Instance Segmentation. IEEE Access 2019, 7, 139635–139642. [Google Scholar] [CrossRef]
- Bai, Y.; Guo, Y.; Zhang, Q.; Cao, B.; Zhang, B. Multi-network fusion algorithm with transfer learning for green cucumber segmentation and recognition under complex natural environment. Comput. Electron. Agric. 2022, 194, 106789. [Google Scholar] [CrossRef]
- Wenan, Y. Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification. AgriEngineering 2023, 5, 413–424. [Google Scholar] [CrossRef]
- Khan, F.; Zafar, N.; Tahir, M.N.; Aqib, M.; Saleem, S.; Haroon, Z. Deep Learning-Based Approach for Weed Detection in Potato Crops. Environ. Sci. Proc. 2022, 23, 6. [Google Scholar] [CrossRef]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Yang, W.; Ma, X.; Hu, W.; Tang, P. Lightweight Blueberry Fruit Recognition Based on Multi-Scale and Attention Fusion NCBAM. Agronomy 2022, 12, 2354. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Rajan, S.K.S.; Damodaran, N. MAFFN_YOLOv5: Multi-Scale Attention Feature Fusion Network on the YOLOv5 Model for the Health Detection of Coral-Reefs Using a Built-In Benchmark Dataset. Analytics 2023, 2, 77–104. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. arXiv 2019, arXiv:1908.05900. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q.H. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Zou, X.; Wu, C.; Liu, H.; Yu, Z. Improved ResNet-50 model for identifying defects on wood surfaces. Signal Image Video Process. 2023, 17, 3119–3126. [Google Scholar] [CrossRef]
- Zhang, L.-Q.; Liu, Z.-T.; Jiang, C.-S. An Improved SimAM Based CNN for Facial Expression Recognition. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; pp. 582–586. [Google Scholar] [CrossRef]
- Raimundo, A.; Pavia João, P.; Sebastião, P.; Postolache, O. YOLOX-Ray: An Efficient Attention-Based Single-Staged Object Detector Tailored for Industrial Inspections. Sensors 2023, 23, 4681. [Google Scholar] [CrossRef] [PubMed]
- Qian, J.; Lin, J.; Bai, D.; Xu, R.; Lin, H. Omni-Dimensional Dynamic Convolution Meets Bottleneck Transformer: A Novel Improved High Accuracy Forest Fire Smoke Detection Model. Forests 2023, 14, 838. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Liu, J.; Cai, Q.; Zou, F.; Zhu, Y.; Liao, L.; Guo, F. BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving. Electronics 2023, 12, 2745. [Google Scholar] [CrossRef]
- Pan, L.; Duan, Y.; Zhang, Y.; Xie, B.; Zhang, R. A lightweight algorithm based on YOLOv5 for relative position detection of hydraulic support at coal mining faces. J. Real-Time Image Process. 2023, 20, 40. [Google Scholar] [CrossRef]
- Zhu, F.; Wang, Y.; Cui, J.; Liu, G.; Li, H. Target detection for remote sensing based on the enhanced YOLOv4 with improved BiFPN. Egypt. J. Remote Sens. Space Sci. 2023, 26, 351–360. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Feng, Y.; Li, Y.; Zhao, L.; Wang, X.; Han, D. Prediction of obstructive sleep apnea using deep learning in 3D craniofacial reconstruction. J. Thorac. Dis. 2023, 15, 90–100. [Google Scholar] [CrossRef]
- Moujahid, H.; Cherradi, B.; Al-Sarem, M.; Bahatti, L.; Bakr Assedik Mohammed Yahya Eljialy, A.; Alsaeedi, A.; Saeed, F. Combining CNN and Grad-Cam for COVID-19 Disease Prediction and Visual Explanation. Intell. Autom. Soft Comput. 2022, 32, 723–745. [Google Scholar] [CrossRef]
- Li, G.; Suo, R.; Zhao, G.; Gao, C.; Fu, L.; Shi, F.; Dhupia, J.; Li, R.; Cui, Y. Real-time detection of kiwifruit flower and bud simultaneously in orchard using YOLOv4 for robotic pollination. Comput. Electron. Agric. 2022, 193, 106641. [Google Scholar] [CrossRef]
- MacEachern, C.B.; Esau, T.J.; Schumann, A.W.; Hennessy, P.J.; Zaman, Q.U. Detection of fruit maturity stage and yield estimation in wild blueberry using deep learning convolutional neural networks. Smart Agric. Technol. 2023, 3, 100099. [Google Scholar] [CrossRef]
- Zhong, Z.; Xiong, J.; Zheng, Z.; Liu, B.; Liao, S.; Huo, Z.; Yang, Z. A method for litchi picking points calculation in natural environment based on main fruit bearing branch detection. Comput. Electron. Agric. 2021, 189, 106398. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Configure | Environment | Version |
|---|---|---|---|
| System | Windows 10 | Python | 3.8.5 |
| CPU | AMD Ryzen 7 5700× | PyTorch | 1.10.0 |
| GPU | RTX3060 Ti | labelImg | 1.8.6 |
| RAM | 16 G | CUDA | 11.0 |
| Hard-disk | 1.5 T | CUDNN | 8.4.0 |
| Model | mAP (%) | F1 (%) | Parameters (106 M) | FLOPs (G) | Size (MB) |
|---|---|---|---|---|---|
| C3SE | 86.0 | 83.4 | 5.9 | 13.6 | 11.6 |
| C3ECA | 86.6 | 84.0 | 5.9 | 13.6 | 11.7 |
| C3CBAM | 86.3 | 83.4 | 5.9 | 13.7 | 11.7 |
| C3SimAM | 85.8 | 83.0 | 5.1 | 12.8 | 10.2 |
| C3CA | 87.6 | 84.7 | 5.8 | 13.5 | 11.6 |
| Model | C | G | B | P (%) | R (%) | mAP (%) | Parameter (106 M) | FLOPs (G) | Size (MB) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 86.5 | 78.4 | 83.9 | 7.0 | 15.8 | 13.8 | |||
| IPV 1 | √ | × | × | 84.5 | 81.0 | 86.4 | 7.0 | 15.8 | 14.0 |
| IPV 2 | × | √ | × | 86.6 | 78.6 | 86.2 | 5.8 | 13.4 | 11.5 |
| IPV 3 | × | × | √ | 84.1 | 81.3 | 85.5 | 7.0 | 16.0 | 13.9 |
| IPV 4 | × | √ | √ | 85.5 | 79.5 | 85.4 | 5.9 | 13.6 | 11.6 |
| IPV 5 | √ | × | √ | 89.9 | 79.7 | 87.7 | 7.1 | 16.1 | 14.0 |
| IPV 6 | √ | √ | × | 88.8 | 81.6 | 87.3 | 5.9 | 13.9 | 11.6 |
| IPV 7 | √ | √ | √ | 88.5 | 81.2 | 87.6 | 5.8 | 13.5 | 11.6 |
| Model | P (%) | R (%) | mAP (%) | F1 (%) | Parameter (106 M) | FLOPs (G) | Size (MB) |
|---|---|---|---|---|---|---|---|
| YOLOv3-tiny | 82.6 | 74.1 | 76.7 | 78.1 | 8.7 | 12.9 | 16.6 |
| YOLOv4-tiny | 63.4 | 86.5 | 84.0 | 73.1 | 5.9 | l6.2 | 23.6 |
| YOLOv7-tiny | 82.3 | 79.1 | 83.4 | 80.7 | 6.0 | 13.2 | 12.3 |
| YOLOv8s | 86.0 | 80.1 | 85.4 | 82.9 | 11.1 | 28.4 | 21.5 |
| YOLOv5s | 86.5 | 78.4 | 83.9 | 82.3 | 7.0 | 15.8 | 13.8 |
| YOLOv5m | 82.5 | 79.5 | 84.9 | 80.9 | 20.9 | 49.7 | 40.3 |
| YOLOv5x | 83.7 | 79.5 | 83.9 | 81.5 | 86.2 | 203.8 | 165.1 |
| YOLOv5l | 86.1 | 80.1 | 86.1 | 83.0 | 47.4 | 115.7 | 91.0 |
| YOLOv5s-S | 88.5 | 81.2 | 87.6 | 84.7 | 5.8 | 13.5 | 11.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, L.; Sun, H.; Zhang, S.; Lu, X.; Wang, R.; Wang, L.; Wang, N. Cucumber Picking Recognition in Near-Color Background Based on Improved YOLOv5. Agronomy 2023, 13, 2062. https://doi.org/10.3390/agronomy13082062
Su L, Sun H, Zhang S, Lu X, Wang R, Wang L, Wang N. Cucumber Picking Recognition in Near-Color Background Based on Improved YOLOv5. Agronomy. 2023; 13(8):2062. https://doi.org/10.3390/agronomy13082062
Chicago/Turabian StyleSu, Liyang, Haixia Sun, Shujuan Zhang, Xinyuan Lu, Runrun Wang, Linjie Wang, and Ning Wang. 2023. "Cucumber Picking Recognition in Near-Color Background Based on Improved YOLOv5" Agronomy 13, no. 8: 2062. https://doi.org/10.3390/agronomy13082062