
Soil Organic Carbon Prediction Based on Different Combinations of Hyperspectral Feature Selection and Regression Algorithms
 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
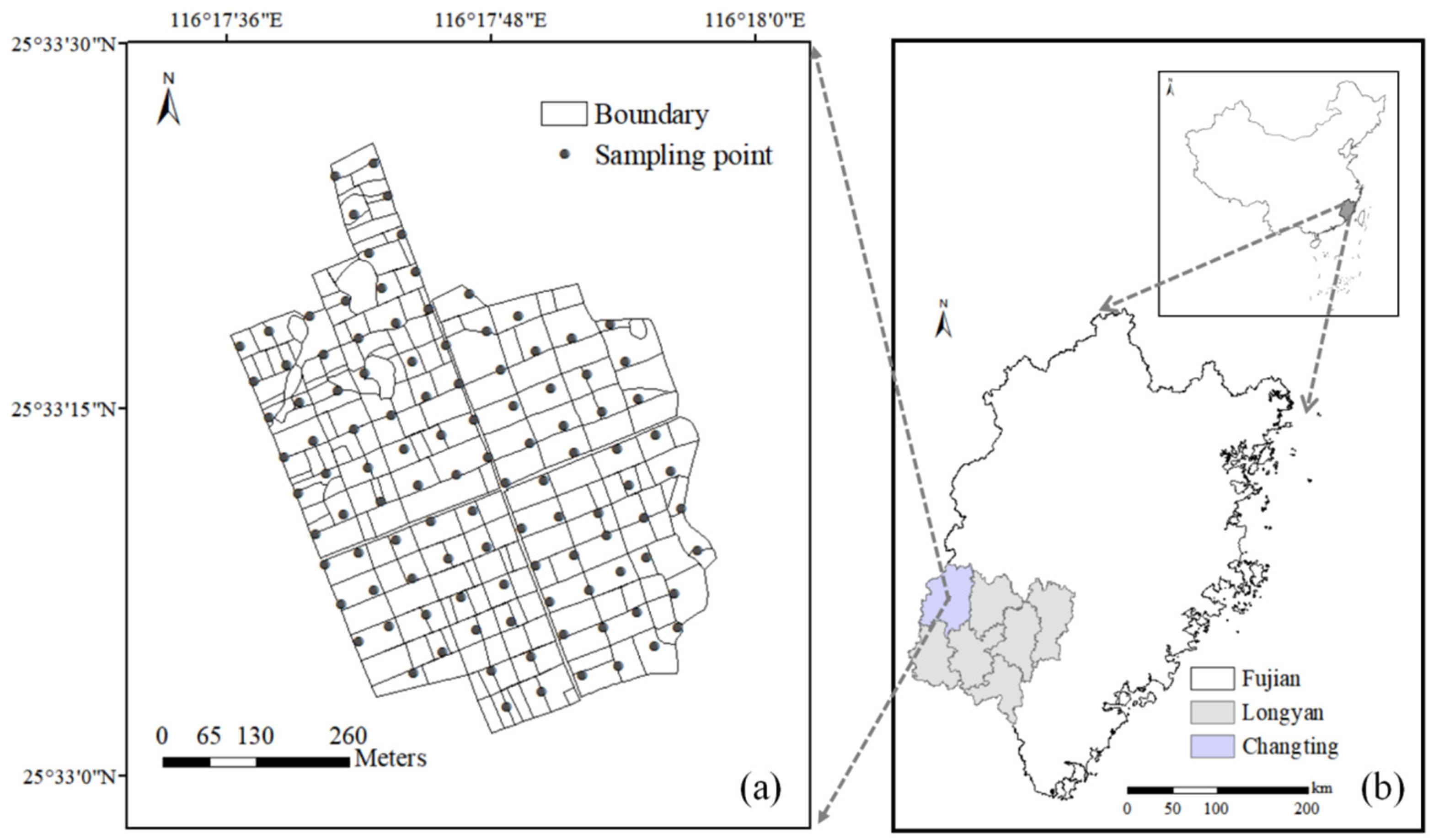
2.1. Study Area
2.2. Soil Sample Collection and Chemical Analysis
2.3. Hyperspectral Data Acquisition
2.4. Feature Selection Algorithms
2.5. SOC Regression Algorithms
2.6. Statistical Modeling and Accuracy Assessment
3. Results
3.1. Description of SOC Content and Hyperspectral Characteristics
3.2. Feature Selection of Soil Spectral Data
3.3. SOC Prediction Model Construction
4. Discussion
4.1. Comparison of Different Algorithms
4.2. SOC Characteristic Wavelengths
4.3. Limitations and Uncertainty
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Davidson, E.A.; Janssens, I.A. Temperature sensitivity of soil carbon decomposition and feedbacks to climate change. Nature 2006, 440, 165–173. [Google Scholar] [CrossRef] [Green Version]
- Chang, N.; Zhai, Z.; Li, H.; Wang, L.; Deng, J. Impacts of nitrogen management and organic matter application on nitrous oxide emissions and soil organic carbon from spring maize fields in the North China Plain. Soil Tillage Res. 2020, 196, 104441. [Google Scholar] [CrossRef]
- Song, J.; Gao, J.; Zhang, Y.; Li, F.; Man, W.; Liu, M.; Wang, J.; Li, M.; Zheng, H.; Yang, X.; et al. Estimation of Soil Organic Carbon Content in Coastal Wetlands with Measured VIS-NIR Spectroscopy Using Optimized Support Vector Machines and Random Forests. Remote Sens. 2022, 14, 4372. [Google Scholar] [CrossRef]
- Vitti, C.; Stellacci, A.M.; Leogrande, R.; Mastrangelo, M.; Cazzato, E.; Ventrella, D. Assessment of organic carbon in soils: A comparison between the Springer–Klee wet digestion and the dry combustion methods in Mediterranean soils (Southern Italy). Catena 2016, 137, 113–119. [Google Scholar] [CrossRef]
- Rossel, R.A.V.; Walvoort, D.J.J.; McBratney, A.B.; Janik, L.J.; Skjemstad, J.O. Visible, near infrared, mid infrared or combined diffuse reflectance spectroscopy for simultaneous assessment of various soil properties. Geoderma 2006, 131, 59–75. [Google Scholar] [CrossRef]
- Bartholomeus, H.M.; Schaepman, M.E.; Kooistra, L.; Stevens, A.; Hoogmoed, W.B.; Spaargaren, O.S.P. Spectral reflectance based indices for soil organic carbon quantification. Geoderma 2008, 145, 28–36. [Google Scholar] [CrossRef]
- Nocita, M.; Stevens, A.; Toth, G.; Panagos, P.; van Wesemael, B.; Montanarella, L. Prediction of soil organic carbon content by diffuse reflectance spectroscopy using a local partial least square regression approach. Soil Biol. Biochem. 2014, 68, 337–347. [Google Scholar] [CrossRef]
- Angelopoulou, T.; Balafoutis, A.; Zalidis, G.; Bochtis, D. From laboratory to proximal sensing spectroscopy for soil organic carbon estimation—A review. Sustainability 2020, 12, 443. [Google Scholar] [CrossRef] [Green Version]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature selection using joint mutual information maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]
- Saidi, R.; Bouaguel, W.; Essoussi, N. Hybrid feature selection method based on the genetic algorithm and pearson correlation coefficient. In Machine Learning Paradigms: Theory and Application; Springer: Cham Switzerland, 2019; pp. 3–24. [Google Scholar]
- Liu, F.; He, Y. Application of successive projections algorithm for variable selection to determine organic acids of plum vinegar. Food Chem. 2009, 115, 1430–1436. [Google Scholar] [CrossRef]
- Xing, Z.; Du, C.; Shen, Y.; Ma, F.; Zhou, J. A method combining FTIR-ATR and Raman spectroscopy to determine soil organic matter: Improvement of prediction accuracy using competitive adaptive reweighted sampling (CARS). Comput. Electron. Agric. 2021, 191, 106549. [Google Scholar] [CrossRef]
- Su, J.; Yi, D.; Coombes, M.; Liu, C.; Zhai, X.; McDonald-Meier, K.; Chen, W.-H. Spectral analysis and mapping of blackgrass weed by leveraging machine learning and UAV multispectral imagery. Comput. Electron. Agric. 2022, 192, 106621. [Google Scholar] [CrossRef]
- Geladi, P. Chemometrics in spectroscopy. Part 1. Classical chemometrics. Spectrochim. Acta Part B At. Spectrosc. 2003, 58, 767–782. [Google Scholar] [CrossRef]
- Stenberg, B.; Rossel, R.A.V.; Mouazen, A.M.; Wetterlind, J. Visible and near infrared spectroscopy in soil science. Adv. Agron. 2010, 107, 163–215. [Google Scholar]
- Vohland, M.; Besold, J.; Hill, J.; Fründ, H.C. Comparing different multivariate calibration methods for the determination of soil organic carbon pools with visible to near infrared spectroscopy. Geoderma 2011, 166, 198–205. [Google Scholar] [CrossRef]
- Wetterlind, J.; Stenberg, B.; Rossel, R.A.V. Soil analysis using visible and near infrared spectroscopy. In Plant Mineral Nutrients; Humana Press: Totowa, NJ, USA, 2013; pp. 95–107. [Google Scholar]
- Peng, X.; Shi, T.; Song, A.; Chen, Y.; Gao, W. Estimating soil organic carbon using VIS/NIR spectroscopy with SVMR and SPA methods. Remote Sens. 2014, 6, 2699–2717. [Google Scholar] [CrossRef] [Green Version]
- de Santana, F.B.; de Souza, A.M.; Poppi, R.J. Visible and near infrared spectroscopy coupled to random forest to quantify some soil quality parameters. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 191, 454–462. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning to predict soil properties from regional spectral data. Geoderma Reg. 2019, 16, e00198. [Google Scholar] [CrossRef]
- Nawar, S.; Buddenbaum, H.; Hill, J.; Kozak, H.; Mouazen, A.M. Estimating the soil clay content and organic matter by means of different calibration methods of vis-NIR diffuse reflectance spectroscopy. Soil Tillage Res. 2016, 155, 510–522. [Google Scholar] [CrossRef] [Green Version]
- Rossel, R.A.V.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Raj, A.; Chakraborty, S.; Duda, B.M.; Weindorf, D.C.; Li, B.; Roy, S.; Sarathjith, M.C.; Das, B.S.; Paulette, L. Soil mapping via diffuse reflectance spectroscopy based on variable indicators: An ordered predictor selection approach. Geoderma 2018, 314, 146–159. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Ravindranath, N.H.; Ostwald, M. Carbon Inventory Methods: Handbook for Greenhouse Gas Inventory, Carbon Mitigation and Roundwood Production Projects; Springer Science & Business Media: Dordrecht, The Netherlands, 2007. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Soares, S.F.C.; Gomes, A.A.; Araujo, M.C.U.; Galvão Filho, A.R.; Galvão, R.K.H. The successive projections algorithm. TrAC Trends Anal. Chem. 2013, 42, 84–98. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Chang, N.; Xiao, J.; Zhou, Q.; Wu, W. Mapping dynamics of soil organic matter in croplands with MODIS data and machine learning algorithms. Sci. Total Environ. 2019, 669, 844–855. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Brereton, R.G.; Lloyd, G.R. Support vector machines for classification and regression. Analyst 2010, 135, 230–267. [Google Scholar] [CrossRef]
- Huang, X.; Wang, X.; Baishan, K.; An, B. Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China. Sustainability 2023, 15, 2587. [Google Scholar] [CrossRef]
- Schoonover, J.E.; Crim, J.F. An introduction to soil concepts and the role of soils in watershed management. J. Contemp. Water Res. Educ. 2015, 154, 21–47. [Google Scholar] [CrossRef] [Green Version]
- Ludwig, B.; Murugan, R.; Parama, V.R.R.; Vohland, M. Use of different chemometric approaches for an estimation of soil properties at field scale with near infrared spectroscopy. J. Plant Nutr. Soil Sci. 2018, 181, 704–713. [Google Scholar] [CrossRef]
- Lee, S.Y.; Mediani, A.; Maulidiani, M.; Khatib, A.; Ismail, I.S.; Zawawi, N.; Abas, F. Comparison of partial least squares and random forests for evaluating relationship between phenolics and bioactivities of Neptunia oleracea. J. Sci. Food Agric. 2018, 98, 240–252. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Zhao, Y.; Wang, M.; Shi, X. Comparison of multivariate methods for estimating selected soil properties from intact soil cores of paddy fields by Vis–NIR spectroscopy. Geoderma 2018, 310, 29–43. [Google Scholar] [CrossRef]
- Chen, H.; Liu, X.; Jia, Z.; Liu, Z.; Shi, K.; Cai, K. A combination strategy of random forest and back propagation network for variable selection in spectral calibration. Chemom. Intell. Lab. Syst. 2018, 182, 101–108. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Saberioon, M.; Carmon, N.; Boruvka, L.; Ben-Dor, E. Examining the performance of PARACUDA-II data-mining engine versus selected techniques to model soil carbon from reflectance spectra. Remote Sens. 2018, 10, 1172. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhang, Y.; Li, Z.; Liu, Q.; Feng, W.; Chen, Y.; Jiang, H.; Liang, H.; Chang, N. Fourier-Transform Infrared Spectral Inversion of Soil Available Potassium Content Based on Different Dimensionality Reduction Algorithms. Agronomy 2023, 13, 617. [Google Scholar] [CrossRef]
- de Oliveira Morais, P.A.; de Souza, D.M.; Madari, B.E.; da Silva Soares, A.; de Oliveira, A.E. Using image analysis to estimate the soil organic carbon content. Microchem. J. 2019, 147, 775–781. [Google Scholar] [CrossRef]
- Guo, P.; Li, T.; Gao, H.; Chen, X.; Cui, Y.; Huang, Y. Evaluating calibration and spectral variable selection methods for predicting three soil nutrients using Vis-NIR spectroscopy. Remote Sens. 2021, 13, 4000. [Google Scholar] [CrossRef]
- Hu, T.; Qi, K. Using vis-nir spectroscopy to estimate soil organic content. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 8263–8266. [Google Scholar]
- Clark, R.N.; Roush, T.L. Reflectance spectroscopy: Quantitative analysis techniques for remote sensing applications. J. Geophys. Res. Solid Earth 1984, 89, 6329–6340. [Google Scholar] [CrossRef]
- Ben-Dor, E.; Inbar, Y.; Chen, Y. The reflectance spectra of organic matter in the visible near-infrared and short wave infrared region (400–2500 nm) during a controlled decomposition process. Remote Sens. Environ. 1997, 61, 1–15. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, J.; Yao, X.; Cao, W.; Zhu, Y. Laboratory assessment of three quantitative methods for estimating the organic matter content of soils in China based on visible/near-infrared reflectance spectra. Geoderma 2013, 202, 161–170. [Google Scholar] [CrossRef]
- Nayak, P.S.; Singh, B.K. Instrumental characterization of clay by XRF, XRD and FTIR. Bull. Mater. Sci. 2007, 30, 235–238. [Google Scholar] [CrossRef] [Green Version]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, N.; Jing, X.; Zeng, W.; Zhang, Y.; Li, Z.; Chen, D.; Jiang, D.; Zhong, X.; Dong, G.; Liu, Q. Soil Organic Carbon Prediction Based on Different Combinations of Hyperspectral Feature Selection and Regression Algorithms. Agronomy 2023, 13, 1806. https://doi.org/10.3390/agronomy13071806
Chang N, Jing X, Zeng W, Zhang Y, Li Z, Chen D, Jiang D, Zhong X, Dong G, Liu Q. Soil Organic Carbon Prediction Based on Different Combinations of Hyperspectral Feature Selection and Regression Algorithms. Agronomy. 2023; 13(7):1806. https://doi.org/10.3390/agronomy13071806
Chicago/Turabian StyleChang, Naijie, Xiaowen Jing, Wenlong Zeng, Yungui Zhang, Zhihong Li, Di Chen, Daibing Jiang, Xiaoli Zhong, Guiquan Dong, and Qingli Liu. 2023. "Soil Organic Carbon Prediction Based on Different Combinations of Hyperspectral Feature Selection and Regression Algorithms" Agronomy 13, no. 7: 1806. https://doi.org/10.3390/agronomy13071806