
Edge Device Detection of Tea Leaves with One Bud and Two Leaves Based on ShuffleNetv2-YOLOv5-Lite-E

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Production
2.1.1. Image Acquisition
2.1.2. VOC Dataset Production
2.2. YOLOv5 Algorithm and Lightweighting Improvement
2.2.1. YOLOv5 Neural Network
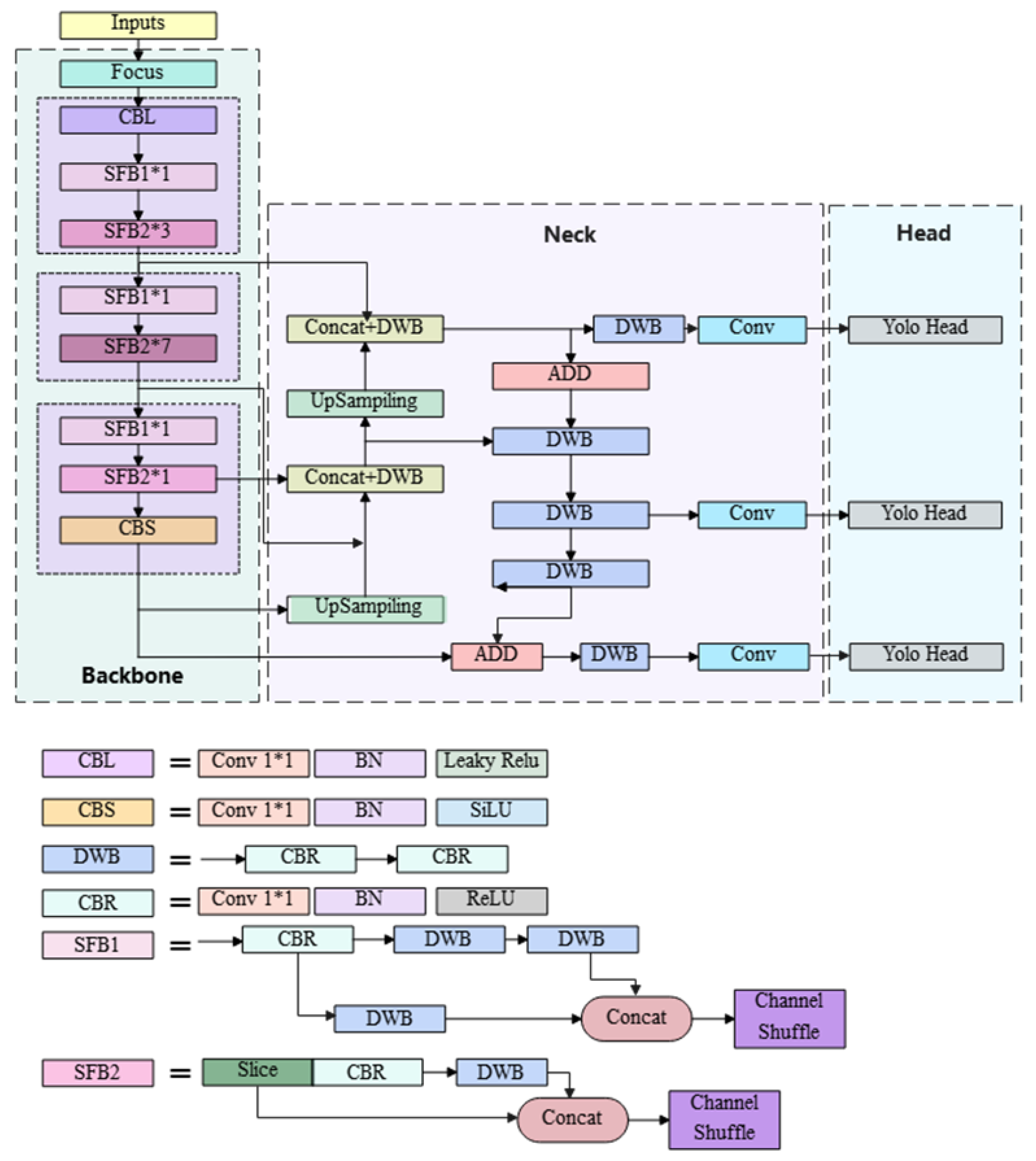
2.2.2. YOLOv5 Network Improvements
Extraction of Focus
Building a YOLOv5 Feature Extraction Network Using ShuffleNetv2 Series
Neck Layer Modification
2.3. Model Evaluation
3. Results and Analysis
3.1. Model Evaluation
3.2. Tea Identification Experiment
3.2.1. PC (Personal Computer)-Side Detection Experiment
3.2.2. Real-Time Detection Experiments for Edge Devices
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, X.J.; Chen, Y.; Guo, Y.Q.; Sun, Y.X.; Chen, J. Tea flushes identification based on machine vision for high-quality tea at harvest. Appl. Mech. Mater. 2013, 288, 214–218. [Google Scholar] [CrossRef]
- Wu, T.H.; Wang, T.W.; Liu, Y.Q. Real-time vehicle and distance detection based on improved yolo v5 network. WSAI IEEE 2021, 24–28. [Google Scholar] [CrossRef]
- Miaoting, C.; Guanglei, Y.; Pengtao, Q. SVM-based Automatic Segmentation Method of Famous Tea Sprout Image. Mod. Inf. Technol. 2021, 5, 89–92. [Google Scholar]
- Gaojian, X.; Yun, Z.; Xiaoyi, L. Image recognition method of tea buds based on Faster R-CNN deep network. J. Optoelectron. ·Laser 2020, 31, 1131–1139. [Google Scholar] [CrossRef]
- Ziyu, W. Research on tea bud detection technology based on image. Shenyang Univ. Technol. 2020. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, Y.; Xiong, Z.; Wang, S.; Li, Y.; Lan, Y. Fast and precise detection of litchi fruits for yield estimation based on the improved YOLOv5 model. Front. Plant Sci. 2022, 13, 965425. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Li, A.; Li, X.; Liang, D. Detection and Identification of Peach Leaf Diseases based on YOLO v5 Improved Model. In Proceedings of the 5th International Conference on Control and Computer Vision, Xiamen, China, 19–21 August 2022; pp. 79–84. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, C.; Ju, H.; Li, Z. Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5. Appl. Sci. 2022, 12, 7235. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2021, 1–12. [Google Scholar] [CrossRef]
- Liu, T.; Zhou, B.; Zhao, Y.; Yan, S. Ship detection algorithm based on improved YOLO V5. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 483–487. [Google Scholar]
- Chen, Z.; Wu, R.; Lin, Y.; Li, C.; Chen, S.; Yuan, Z.; Chen, S.; Zou, X. Plant disease recognition model based on improved YOLOv5. Agronomy 2022, 12, 365. [Google Scholar] [CrossRef]
- Doss, R.; Ramakrishnan, J.; Kavitha, S.; Ramkumar, S.; Charlyn Pushpa Latha, G.; Ramaswamy, K. Classification of Silicon (Si) Wafer Material Defects in Semiconductor Choosers using a Deep Learning ShuffleNet-v2-CNN Model. Adv. Mater. Sci. Eng. 2022, 2022, 1829792. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef] [PubMed]
- Boyd, K.; Eng, K.H.; Page, C.D. Area under the precision-recall curve: Point estimates and confidence intervals. ECML PKDD 2013, 451–466. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Wang, C.; Liu, F.; Lei, J.; Huang, Z.; Peng, Y.; Li, F. Learning environmental sounds with multi-scale convolutional neural network. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Chin, W.; Cheah, J.H.; Liu, Y.; Ting, H.; Lim, X.J.; Cham, T.H. Demystifying the role of causal-predictive modeling using partial least squares structural equation modeling in information systems research. Ind. Manag. Data Syst. 2020, 120, 2161–2209. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Kong, W.; Hong, J.; Jia, M.; Yao, J.; Cong, W.; Hu, H.; Zhang, H. YOLOv3-DPFIN: A dual-path feature fusion neural network for robust real-time sonar target detection. IEEE Sens. J. 2019, 20, 3745–3756. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, H.; Wang, L.; Zhang, Z.; Zhao, C. Improved YOLOv3 Model for miniature camera detection. Opt. Laser Technol. 2021, 142, 107133. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Model Size/M | mAP |
|---|---|---|
| ShuffleNetv2-YOLOv5-Lite-E | 90.1 | 97.43 |
| YOLOv5 | 334 | 98.75 |
| YOLOv4 | 244 | 93.56 |
| YOLOv3 | 237 | 70.43 |
| Model Name | Number of Photos Taken/Piece | Average Confidence/% | Detection Speed/Frame |
|---|---|---|---|
| ShuffleNetv2-YOLOv5-Lite-E | 100 | 94.52 | 8.6 |
| YOLOv5 | 100 | 96.27 | 2.7 |
| YOLOv4 | 100 | 93.56 | 3.2 |
| YOLOv3 | 100 | 70.43 | 3.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Yang, H.; Yang, C.; Yuan, W.; Li, X.; Wang, X.; Zhang, Y.; Cai, X.; Sheng, Y.; Deng, X.; et al. Edge Device Detection of Tea Leaves with One Bud and Two Leaves Based on ShuffleNetv2-YOLOv5-Lite-E. Agronomy 2023, 13, 577. https://doi.org/10.3390/agronomy13020577
Zhang S, Yang H, Yang C, Yuan W, Li X, Wang X, Zhang Y, Cai X, Sheng Y, Deng X, et al. Edge Device Detection of Tea Leaves with One Bud and Two Leaves Based on ShuffleNetv2-YOLOv5-Lite-E. Agronomy. 2023; 13(2):577. https://doi.org/10.3390/agronomy13020577
Chicago/Turabian StyleZhang, Shihao, Hekai Yang, Chunhua Yang, Wenxia Yuan, Xinghui Li, Xinghua Wang, Yinsong Zhang, Xiaobo Cai, Yubo Sheng, Xiujuan Deng, and et al. 2023. "Edge Device Detection of Tea Leaves with One Bud and Two Leaves Based on ShuffleNetv2-YOLOv5-Lite-E" Agronomy 13, no. 2: 577. https://doi.org/10.3390/agronomy13020577