
SE-YOLOv5x: An Optimized Model Based on Transfer Learning and Visual Attention Mechanism for Identifying and Localizing Weeds and Vegetables



Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Preparation
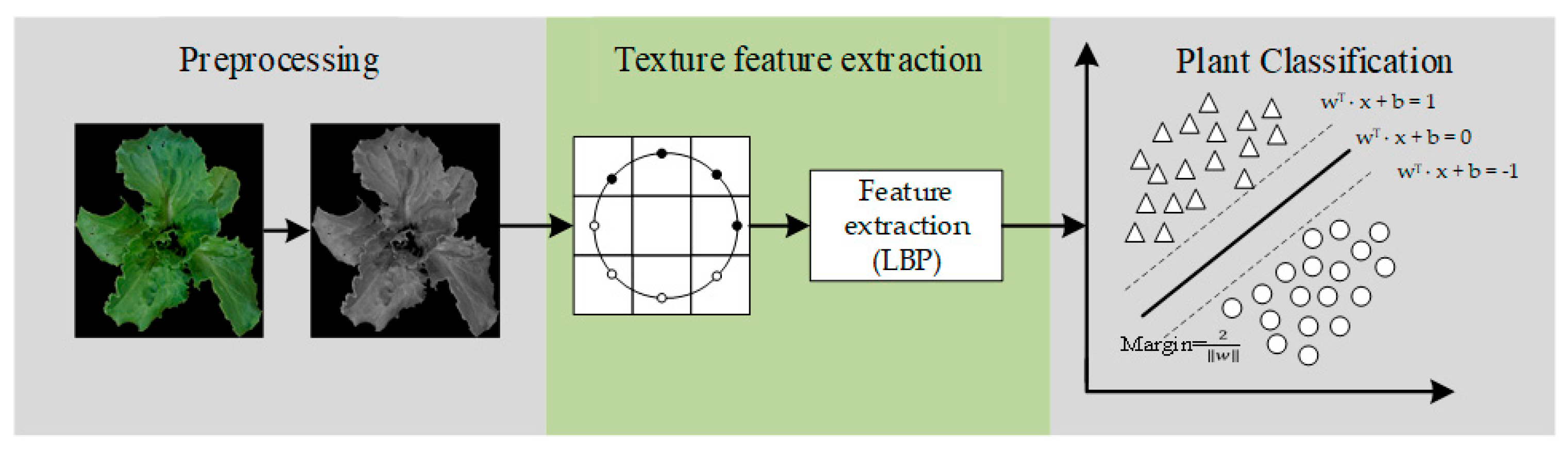
2.2. Texture Extraction
2.3. Support Vector Machine (SVM)
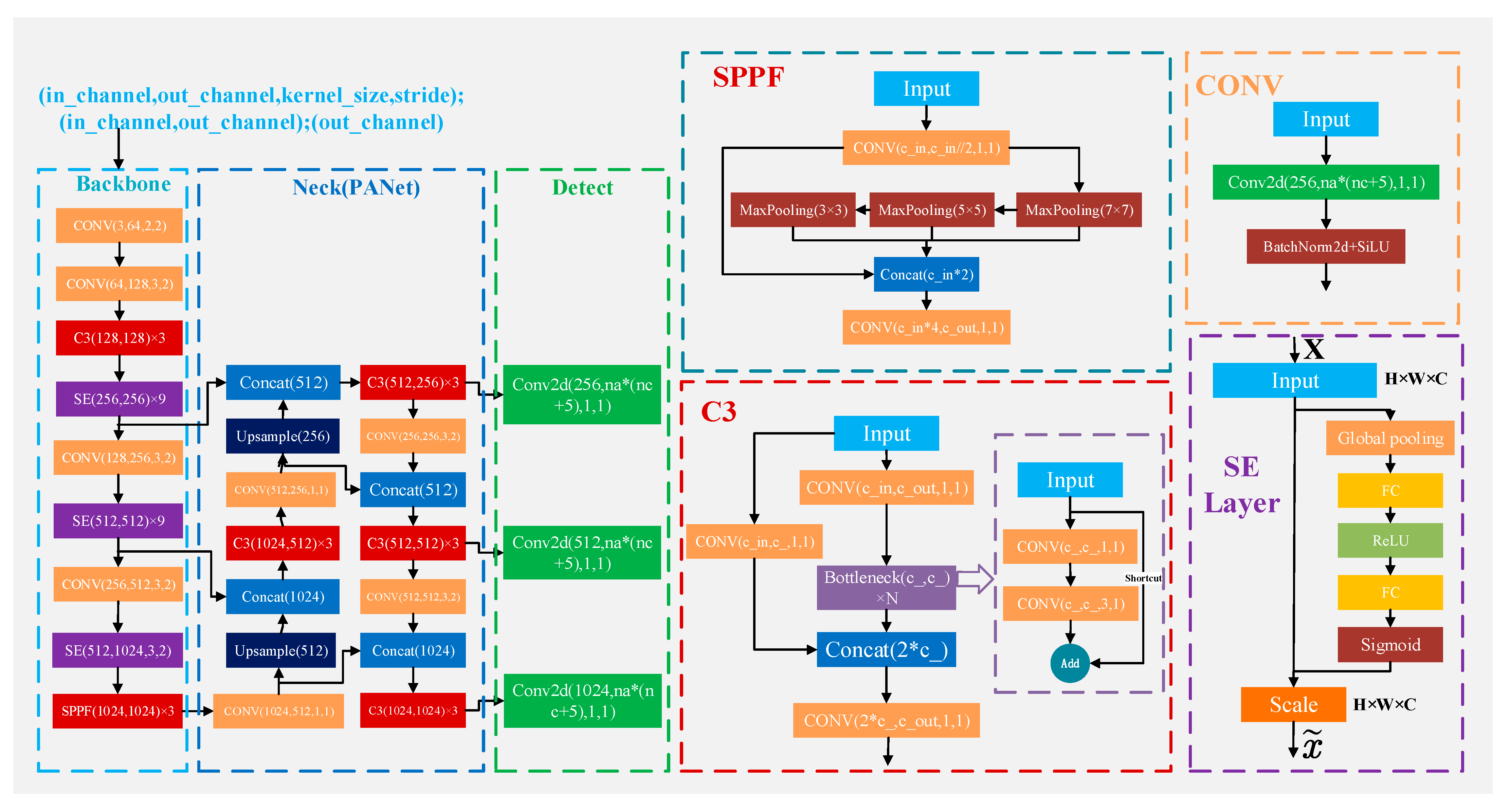
2.4. Deep Learning
2.4.1. Equipment
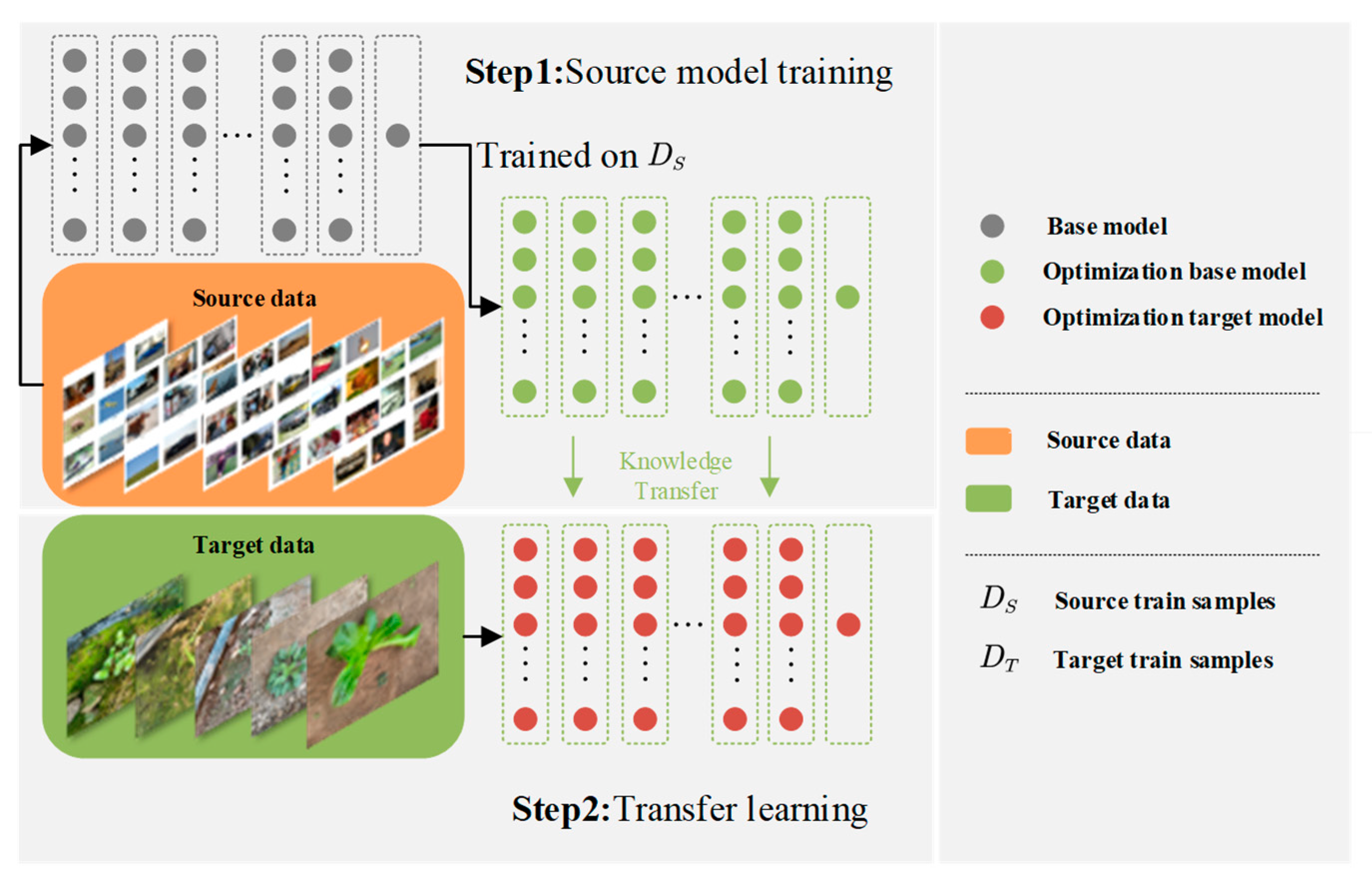
2.4.2. Transfer Learning
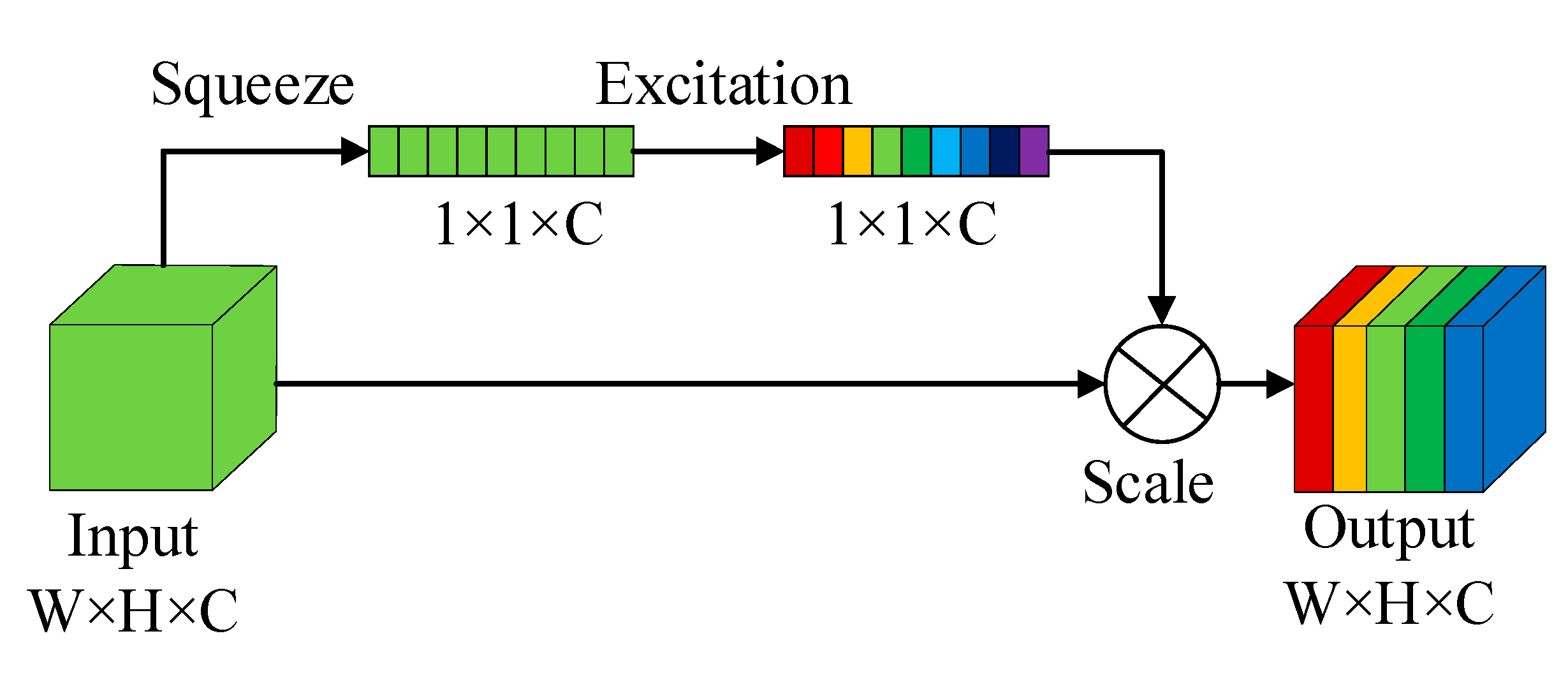
2.4.3. SE Network
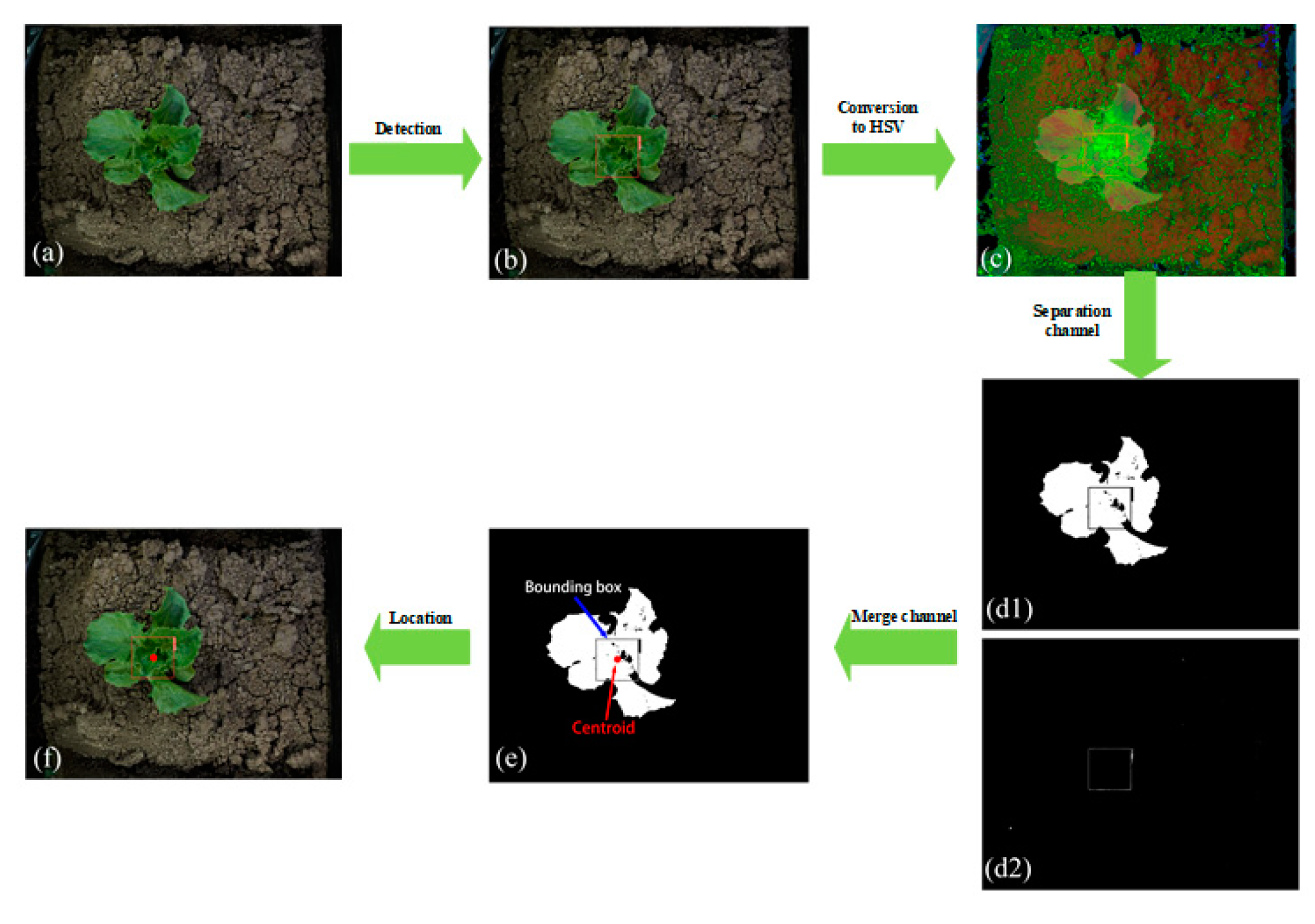
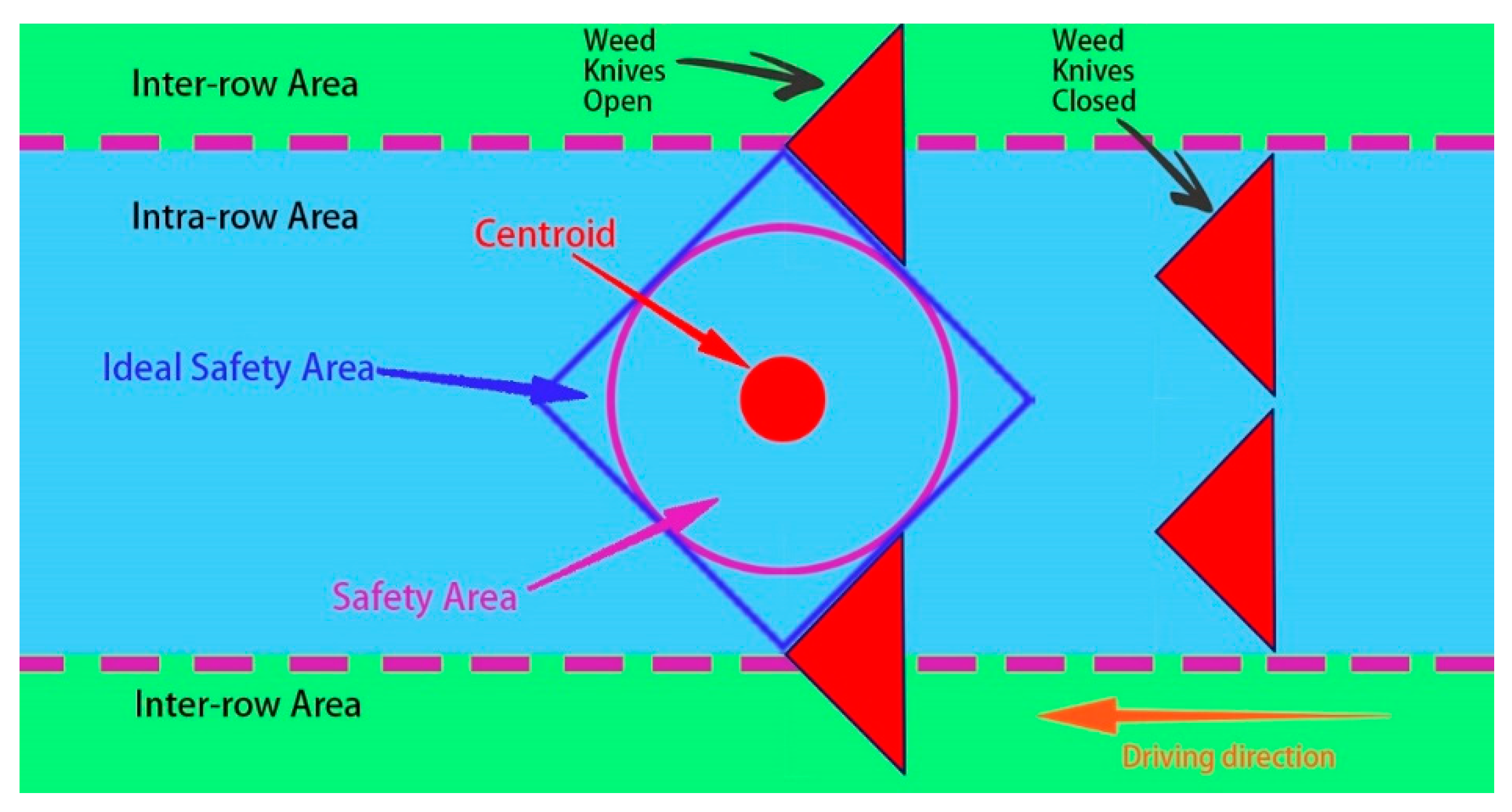
2.5. Localization of Lettuce Stem Emerging Point
2.6. Evaluation Indicators
3. Results
3.1. SVM for Plant Classification
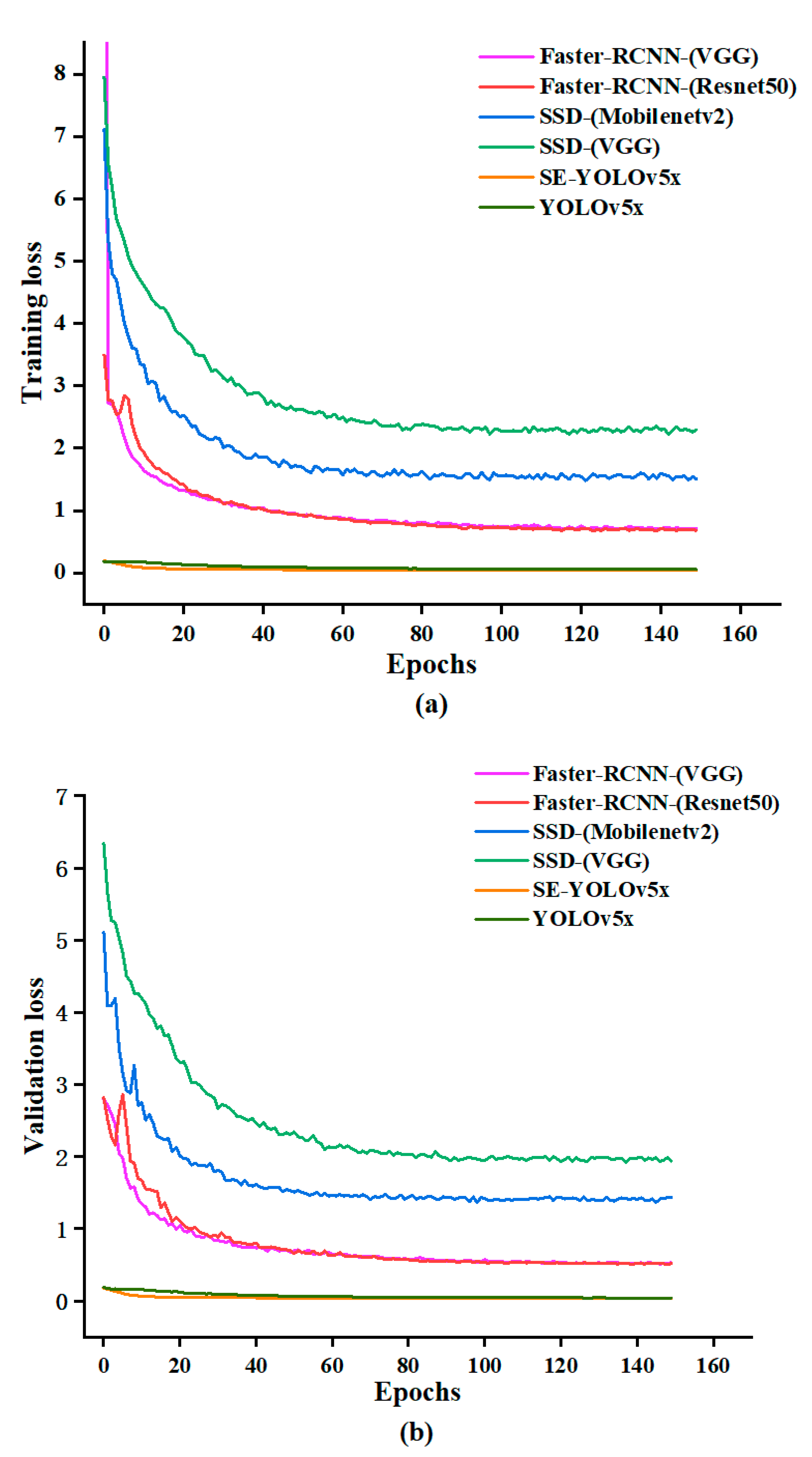
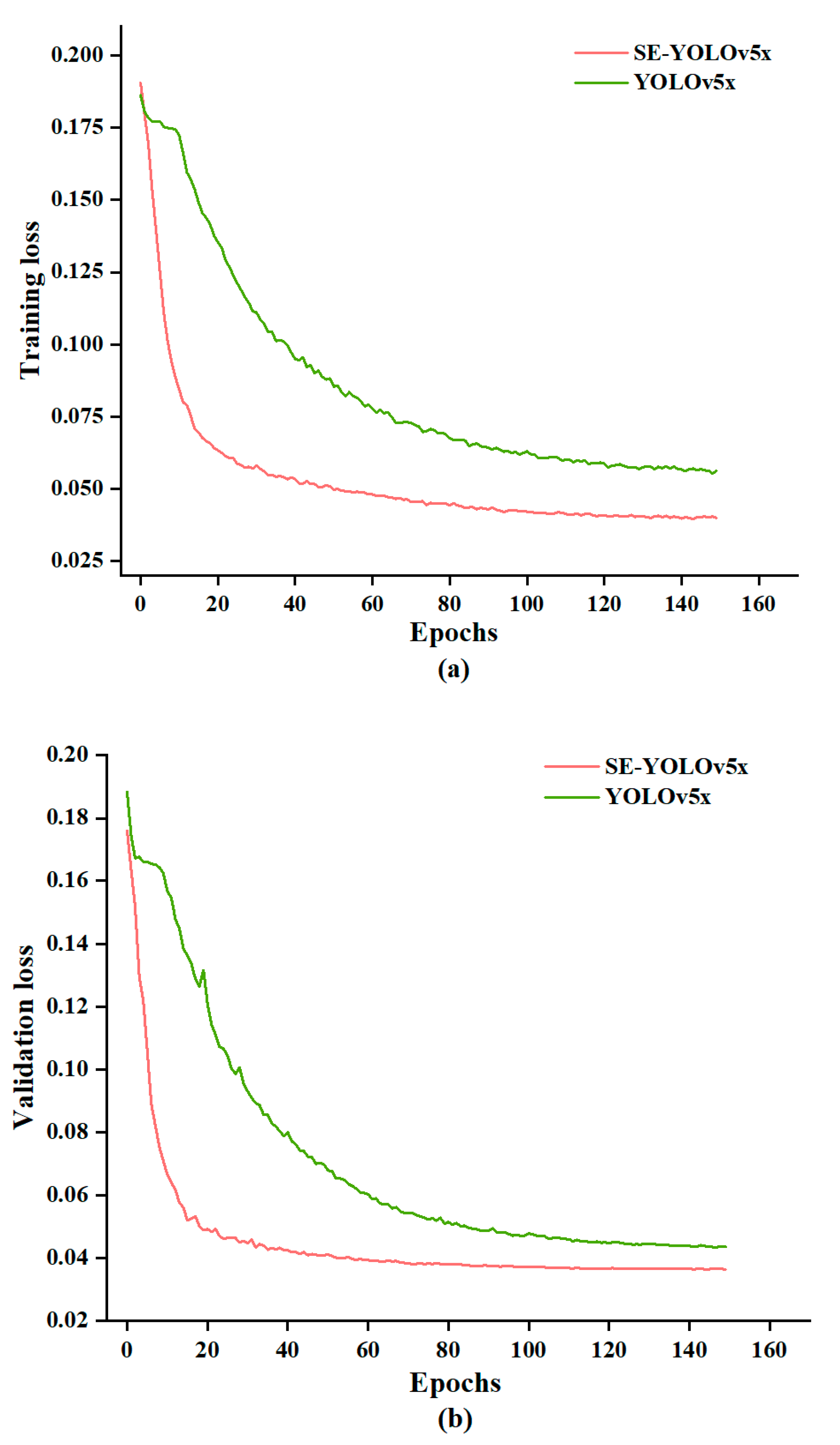
3.2. Training of Deep Learning Models
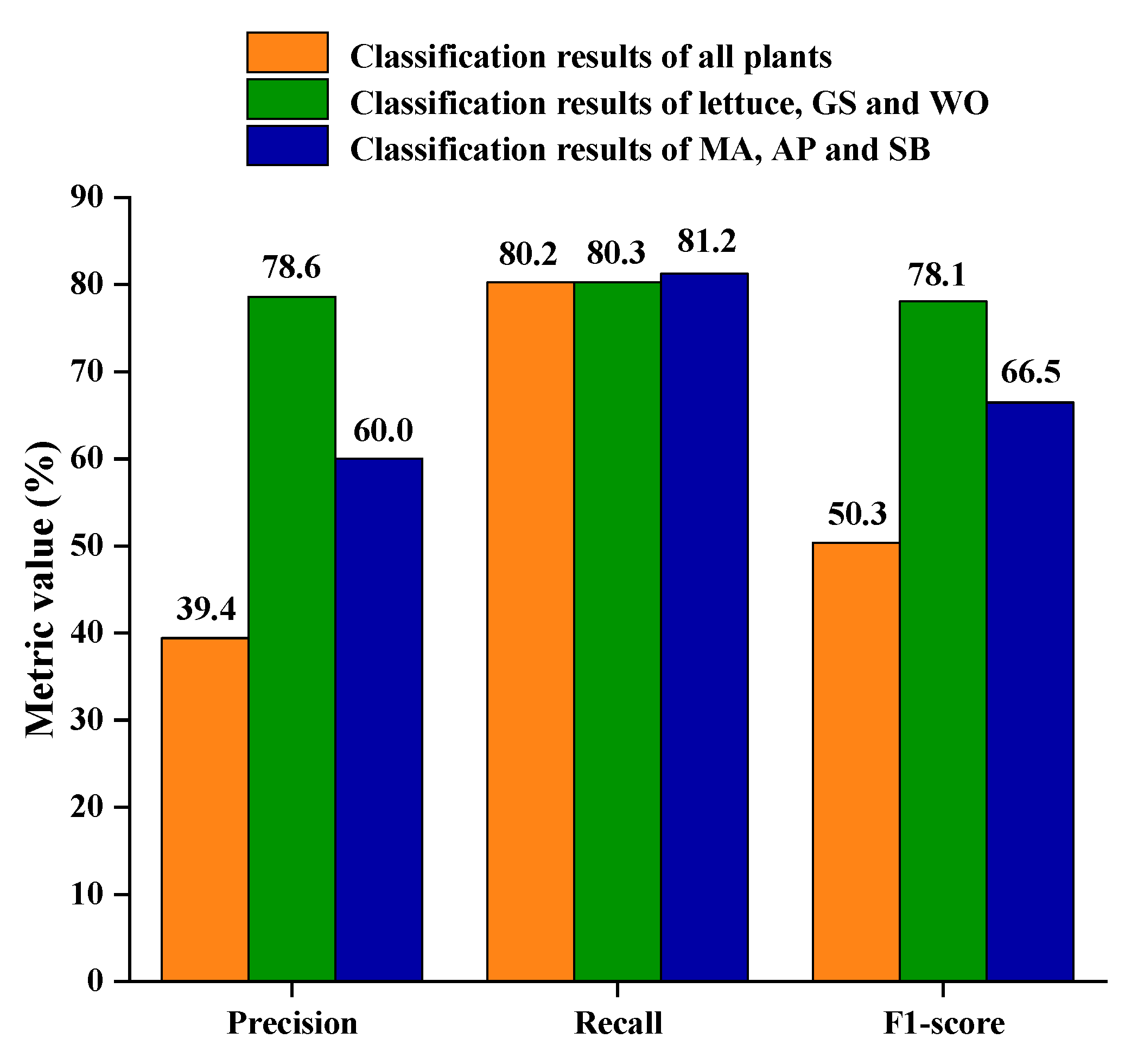
3.3. Deep Learning for Plant Classification
3.4. Performance Comparison of SVM and Deep Learning Models
3.5. Determination of Lettuce Stem Emerging Point
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, J.; Nuyttens, D.; Lootens, P.; He, Y.; Pieters, J.G. Recognising weeds in a maize crop using a random forest machine-learning algorithm and near-infrared snapshot mosaic hyperspectral imagery. Biosyst. Eng. 2018, 170, 39–50. [Google Scholar] [CrossRef]
- Pérez-Ruiz, M.; Slaughter, D.C.; Gliever, C.J.; Upadhyaya, S.K. Automatic GPS-based intra-row weed knife control system for transplanted row crops. Comput. Electron. Agric. 2012, 80, 41–49. [Google Scholar] [CrossRef]
- Tang, J.; Wang, D.; Zhang, Z.; He, L.; Xin, J.; Xu, Y. Weed identification based on K-means feature learning combined with convolutional neural network. Comput. Electron. Agric. 2017, 135, 63–70. [Google Scholar] [CrossRef]
- Ahmed, F.; Al-Mamun, H.A.; Bari, A.S.M.H.; Hossain, E.; Kwan, P. Classification of crops and weeds from digital images: A support vector machine approach. Crop Prot. 2012, 40, 98–104. [Google Scholar] [CrossRef]
- Ferreira, A.D.; Freitas, D.M.; da Silva, G.G.; Pistori, H.; Folhes, M.T. Weed detection in soybean crops using ConvNets. Comput. Electron. Agric. 2017, 143, 314–324. [Google Scholar] [CrossRef]
- Ahmad, A.; Saraswat, D.; Aggarwal, V.; Etienne, A.; Hancock, B. Performance of deep learning models for classifying and detecting common weeds in corn and soybean production systems. Comput. Electron. Agric. 2021, 184, 106081. [Google Scholar] [CrossRef]
- Jiang, H.H.; Zhang, C.Y.; Qiao, Y.L.; Zhang, Z.; Zhang, W.J.; Song, C.Q. CNN feature based graph convolutional network for weed and crop recognition in smart farming. Comput. Electron. Agric. 2020, 174, 105450. [Google Scholar] [CrossRef]
- Osorio, K.; Puerto, A.; Pedraza, C.; Jamaica, D.; Rodríguez, L.J.A. A deep learning approach for weed detection in lettuce crops using multispectral images. AgriEngineering 2020, 2, 471–488. [Google Scholar] [CrossRef]
- Hu, K.; Coleman, G.; Zeng, S.; Wang, Z.; Walsh, M. Graph weeds net: A graph-based deep learning method for weed recognition. Comput. Electron. Agric. 2020, 174, 105520. [Google Scholar] [CrossRef]
- Abdalla, A.; Cen, H.; Wan, L.; Rashid, R.; Weng, H.; Zhou, W.; He, Y. Fine-tuning convolutional neural network with transfer learning for semantic segmentation of ground-level oilseed rape images in a field with high weed pressure. Comput. Electron. Agric. 2019, 167, 105091. [Google Scholar] [CrossRef]
- Picon, A.; San-Emeterio, M.G.; Bereciartua-Perez, A.; Klukas, C.; Eggers, T.; Navarra-Mestre, R. Deep learning-based segmentation of multiple species of weeds and corn crop using synthetic and real image datasets. Comput. Electron. Agric. 2022, 194, 106719. [Google Scholar] [CrossRef]
- Wang, Z.P.; Jin, L.Y.; Wang, S.; Xu, H.R. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Zhang, D.-Y.; Luo, H.-S.; Wang, D.-Y.; Zhou, X.-G.; Li, W.-F.; Gu, C.-Y.; Zhang, G.; He, F.-M. Assessment of the levels of damage caused by Fusarium head blight in wheat using an improved YoloV5 method. Comput. Electron. Agric. 2022, 198, 107086. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Le, V.N.T.; Apopei, B.; Alameh, K. Effective plant discrimination based on the combination of local binary pattern operators and multiclass support vector machine methods. Inf. Processing Agric. 2019, 6, 116–131. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C.; Detector, S.S.D.S.S.M.; Leibe, I.B.; Matas, J.; et al. (Eds.) Computer Vision—ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 11–12 December 2015. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Garibaldi-Marquez, F.; Flores, G.; Mercado-Ravell, D.A.; Ramirez-Pedraza, A.; Valentin-Coronado, L.M. Weed Classification from Natural Corn Field-Multi-Plant Images Based on Shallow and Deep Learning. Sensors 2022, 22, 3021. [Google Scholar] [CrossRef]
- Christopher, M.; Beighith, A.; Bowd, C.; Proudfoot, J.A.; Goldbaum, M.H.; Weinreb, R.N.; Girkin, C.A.; Liebmann, J.M.; Zangwill, L.M. Performance of Deep Learning Architectures and Transfer Learning for Detecting Glaucomatous Optic Neuropathy in Fundus Photographs. Sci. Rep. 2018, 8, 16685. [Google Scholar] [CrossRef]
- Qi, J. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, D.; Zeb, A.; Nanehkaran, Y.A. Identification of rice plant diseases using lightweight attention networks. Expert Syst. Appl. 2021, 169, 114514. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An Empirical Study of Spatial Attention Mechanisms in Deep Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Perez-Ruiz, M.; Slaughter, D.C.; Fathallah, F.A.; Gliever, C.J.; Miller, B.J. Co-robotic intra-row weed control system. Biosyst. Eng. 2014, 126, 45–55. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Wang, Q.; Cheng, M.; Xiao, X.; Yuan, H.; Zhu, J.; Fan, C.; Zhang, J. An image segmentation method based on deep learning for damage assessment of the invasive weed Solanum rostratum Dunal. Comput. Electron. Agric. 2021, 188, 106320. [Google Scholar] [CrossRef]
- Zou, K.; Chen, X.; Wang, Y.; Zhang, C.; Zhang, F. A modified U-Net with a specific data argumentation method for semantic segmentation of weed images in the field. Comput. Electron. Agric. 2021, 187, 106242. [Google Scholar] [CrossRef]
- Jin, X.; Che, J.; Chen, Y. Weed Identification Using Deep Learning and Image Processing in Vegetable Plantation. IEEE Access 2021, 9, 10940–10950. [Google Scholar] [CrossRef]
- Sivakumar, A.N.V.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Chen, D.; Lu, Y.; Li, Z.; Young, S. Performance evaluation of deep transfer learning on multi-class identification of common weed species in cotton production systems. Comput. Electron. Agric. 2022, 198, 107091. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Jin, X.; Sun, Y.; Che, J.; Bagavathiannan, M.; Yu, J.; Chen, Y. A novel deep learning-based method for detection of weeds in vegetables. Pest Manag. Sci. 2022, 78, 1861–1869. [Google Scholar]
- Su, W.-H. Advanced Machine Learning in Point Spectroscopy, RGB- and Hyperspectral-Imaging for Automatic Discriminations of Crops and Weeds: A Review. Smart Cities 2020, 3, 767–792. [Google Scholar] [CrossRef]
- Su, W.-H.; Fennimore, S.A.; Slaughter, D.C. Fluorescence imaging for rapid monitoring of translocation behaviour of systemic markers in snap beans for automated crop/weed discrimination. Biosyst. Eng. 2019, 186, 156–167. [Google Scholar] [CrossRef]
- Su, W.-H.; Fennimore, S.A.; Slaughter, D.C. Development of a systemic crop signalling system for automated real-time plant care in vegetable crops. Biosyst. Eng. 2020, 193, 62–74. [Google Scholar]
- Su, W.-H.; Slaughter, D.C.; Fennimore, S.A. Non-destructive evaluation of photostability of crop signaling compounds and dose effects on celery vigor for precision plant identification using computer vision. Comput. Electron. Agric. 2020, 168, 105155. [Google Scholar] [CrossRef]
- Su, W.-H. Crop plant signalling for real-time plant identification in smart farm: A systematic review and new concept in artificial intelligence for automated weed control. Artif. Intelli. Agric. 2020, 4, 262–271. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | mAP@0.5% (%) | F1-Score (%) |
|---|---|---|---|---|
| SE-YOLOv5x | 97.6 | 95.6 | 97.1 | 97.3 |
| YOLOv5x | 96.7 | 95.0 | 96.2 | 95.8 |
| SSD (VGG) | 89.4 | 77.2 | 86.2 | 80.7 |
| SSD (Mobilenetv2) | 94.8 | 87.1 | 95.1 | 90.6 |
| Faster-RCNN (Resnet50) | 54.0 | 89.0 | 81.5 | 65.7 |
| Faster-RCNN (VGG) | 50.5 | 88.9 | 83.8 | 62.8 |
| Plant Species | Precision (%) | Recall (%) | mAP@0.5 (%) | F1-Score (%) |
|---|---|---|---|---|
| GS 1 | 100.0 | 98.3 | 99.5 | 99.1 |
| WO 2 | 98.0 | 88.6 | 92.0 | 93.1 |
| MA 3 | 89.8 | 90.2 | 92.7 | 90.0 |
| AP 4 | 98.7 | 99.1 | 99.4 | 98.9 |
| SB 5 | 99.5 | 97.6 | 99.3 | 98.5 |
| Lettuce | 99.6 | 100.0 | 99.5 | 99.8 |
| Model | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| SE-YOLOv5x | 97.6 | 95.6 | 97.3 |
| YOLOv5x | 96.7 | 95.0 | 95.8 |
| SSD (VGG) | 89.4 | 77.2 | 80.7 |
| SSD (Mobilenetv2) | 94.8 | 87.1 | 90.6 |
| Faster-RCNN (Resnet50) | 54.0 | 89.0 | 65.7 |
| Faster-RCNN (VGG) | 50.5 | 88.9 | 62.8 |
| SVM | 39.4 | 80.2 | 50.3 |
| Model | Total Samples | The Number of Detected Samples | Accuracy (%) |
|---|---|---|---|
| Faster-RCNN (Resnet50) | 175 | 140 | 80.00 |
| Faster-RCNN (VGG) | 175 | 152 | 86.86 |
| SSD (Mobilenetv2) | 175 | 121 | 69.14 |
| SSD (VGG) | 175 | 124 | 70.86 |
| YOLOv5x | 175 | 168 | 96.00 |
| SE-YOLOv5x | 175 | 170 | 97.14 |
| Reference | Model | Plant | F1-Score (%) | Test Time (ms) |
|---|---|---|---|---|
| Wang et al. [29] | DeepSolanum-Net | Solanum rostratum dunal | 90.1 | 131.88 |
| Zou et al. [30] | Modified U-Net | Green bristlegrass | 93.6 | 51.71 |
| Jin et al. [31] | Centernet + image processing | Bok choy and Chinese white cabbage (various growth stages) | 95.3 | 8.38 |
| Garibaldi-Marquez et al. [20] | VGG16 + ROI detection algorithms | Zea mays, narrow-leaf weeds, and broadleaf weeds | 97.7 | 194.56 |
| Veeranampalayam Sivakumar et al. [32] | Faster-RCNN | Waterhemp, Palmer amaranthus, common lambsquarters, velvetleaf, foxtail species | 66.0 | 230.00 |
| Wang et al. [34] | YOLO-CBAM | Solanum rostratum dunal seedlings | 92.4 | 10.51 |
| Chen et al. [33] | ResNeXt | Morning glory, Carpetweed, Palmer amaranth, Waterhemp, Purslane, and so on | 98.93 ± 0.34 | 338.5 ± 0.1 |
| Jin et al. [35] | YOLOv3 + image processing | Bok choy | 97.1 | 18.0 |
| Proposed method | SE-YOLOv5x | GS, WO, MA, AP, SB, lettuce | 97.3 | 19.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.-L.; Su, W.-H.; Zhang, H.-Y.; Peng, Y. SE-YOLOv5x: An Optimized Model Based on Transfer Learning and Visual Attention Mechanism for Identifying and Localizing Weeds and Vegetables. Agronomy 2022, 12, 2061. https://doi.org/10.3390/agronomy12092061
Zhang J-L, Su W-H, Zhang H-Y, Peng Y. SE-YOLOv5x: An Optimized Model Based on Transfer Learning and Visual Attention Mechanism for Identifying and Localizing Weeds and Vegetables. Agronomy. 2022; 12(9):2061. https://doi.org/10.3390/agronomy12092061
Chicago/Turabian StyleZhang, Jian-Lin, Wen-Hao Su, He-Yi Zhang, and Yankun Peng. 2022. "SE-YOLOv5x: An Optimized Model Based on Transfer Learning and Visual Attention Mechanism for Identifying and Localizing Weeds and Vegetables" Agronomy 12, no. 9: 2061. https://doi.org/10.3390/agronomy12092061