1. Introduction
The capacity to accurately estimate the yield of a vineyard in the early stages of development can be extremely advantageous for the winegrower, with impacts on the whole vine and wine production chain. In the vineyard, it can help plan strategies of grape thinning as a yield regulation practice or to plan harvest in terms of logistics, scheduling, workforce and machinery requirements [
1,
2]. In the cellar, it helps planning for tank space allocation, crusher intake scheduling and oenological products. Furthermore, it provides advantages in terms of marketing and wine stock management [
3]. Current conventional methods of yield estimation consist of manually sampling grapevine yield components using randomized vine segments in the field [
4]. This sampling can be performed at various phenological stages, and yield potential can be estimated using historical data (e.g., average bunch weight at harvest). Early forecasts are important and can help the winegrower adopt strategies to adjust their production in that season [
5]. However, if performed too early, yield estimation can be inaccurate as there are numerous factors, such as climatic events and other abiotic and biotic stresses, that can affect yield components after the estimation date. Therefore, conventional yield estimates are usually performed close to the veraison phenological stage (BBCH 81; [
6]) and generalized for the whole vineyard plot [
7]. This method, described in Equation (1), is easy to perform and independent of any technology, as it is based only on historical bunch weight and on bunch counts, a yield component that can explain, on average, about 60% of the total yield variation [
8]. It allows for early estimations, as bunch counts can be performed before fruit set. However, the dependency on historical data regarding bunch weight at harvest is a disadvantage of this method. An alternative manual method consists of weighing a sample of bunches at the lag phase (just before veraison) while considering a growth factor until full maturation (Equation (2)). Berry lag phase is the phenological stage just before the onset of the veraison stage (between BBCH 79 and 81), corresponding to the phase where berry growth slows down as seeds begin to harden. Either the lag phase or the veraison phenological stage are stages not far from harvest, presenting a lower risk of unpredictable events but early enough to allow the farmer to make use of most adaptation strategies mentioned above. However, both of these manual methods are dependent on manual counting or sampling in the field, making them sensitive to spatial variability. These tasks require a significant amount of labor, especially in highly variable vineyards where a higher number of samples is required for an accurate yield estimation [
9,
10]. Moreover, the lag phase method, apart from being based on destructive samples, is dependent on a historical berry growth factor, which is largely affected by growth conditions, cultivar and management practices [
11,
12,
13].
where the growth factor consists of the ratio between bunch weight at the lag phase and at harvest (historical data). Manual yield estimation methods are known to have an average accuracy error between 10% and 40% relative to real yield at harvest [
8,
14,
15,
16]. Some authors consider an error ranging between 5% [
4] and 10% [
15] as ideal.
Considering the disadvantages of the manual methods regarding their cost, possible destructiveness and unreliable estimation error, recently, several efforts have been made to replace them with automatic non-invasive approaches. Several alternatives to manual vineyard yield estimation have been recently reported [
17], for example, based on the use of vegetation indexes obtained via aerial imaging [
18], airborne pollen samples obtained using Crus pollen traps [
19,
20], trellis tension sensors deployed across the vineyard [
21], crop simulation models using environmental and physiological data [
22] and sensor technology such as radar or ultrasonic for bunch detection in dense canopies [
23,
24]. Overall, all methods present advantages and disadvantages when compared to manual approaches. While all are independent of bunch sampling, some are limited to region-wide estimations (e.g., airborne pollen). Others are dependent on well-maintained trellis systems and on a good distribution of sensors across the whole vineyard (e.g., trellis tension). Others depend on vegetative parameters that may not always be related to yield as well as expert-dependent technology that is not always readily available (e.g., sensor-based methods).
Out of the mentioned alternative yield estimation approaches, the most explored ones in recent research have been data driven-models based on computer vision and image processing [
17]. Such approaches, besides being non-invasive, by scanning extensive amounts of individual plants, can reduce the errors related to spatial and temporal variability while also collecting information regarding their geographical position.
The most common computer vision-based approaches consider the automatic recognition of either bunch overall pixels or single berries as they represent the main estimators of yield in 2D image scenarios [
25]. Image analysis has been used to accurately identify the number of visible berries in vine images, using supervised learning algorithms [
26]. Different approaches have been explored to identify the same yield component, such as hedge detection using Hough transform [
27], Boolean models [
28] and random forests [
29]. Average berry size has also been automatically estimated using computer vision techniques [
30,
31]. Recently, grape bunch projected area has been detected with an unmanned aerial vehicle using photogrammetric point clouds and color filtering [
32]. Other works explored the automatic detection of bunches on ground images using support vector machines [
33] and artificial neural networks [
34]. Furthermore, 3D imaging has also been explored for bunch detection (e.g., [
35,
36]), where it has been explored as only outperforming 2D analysis in laboratory conditions.
Overall, yield components automatic recognition in vine images has proven successful in the above-referenced works, as most of them focus on the effectiveness of the automatic algorithms and their accuracy in identifying key vine image features that allow estimations of yield. In fact, several referenced works also perform yield estimations (e.g., [
27,
28,
29,
36]); however, apart from early-stage approaches (e.g., [
37]), the majority of these research works apply their methods after some canopy manipulation. They do it by defoliating vines at the bunch zone prior to image collection (e.g., [
3,
33,
34]) to surpass one of the main challenges of yield estimation via image analysis: bunch occlusion by leaves. In fact, most research does not account for the yield components that are occluded by leaves, woody material and neighboring bunches, previously referred to as vine-occlusions and self or cluster-occlusions [
38]. Furthermore, vineyards with very dense canopies are not usually considered. In such cases, only a small fraction of bunches is visible and not necessarily correlated with vine yield [
39], and defoliation is not always a common practice (e.g., warm climate viticulture). The visibility of yield components along the vine growing cycle has been previously explored [
40], and bunch occlusion ratios between 50% and 75% at the veraison stage were observed. Artificially generated vine images were recently explored to develop an algorithm capable of estimating berry numbers behind the leaves [
41]. This work showed promising results in their synthetic data but inconclusive in real vine images. In recent research, our team showed that bunch occlusion by leaves could be surpassed by considering other canopy traits, besides yield components, such as canopy porosity [
42]. Previously, canopy porosity has been estimated via image analysis [
43] and presents results similar to the ones obtained via classical approaches [
44]. Visible bunch area and canopy porosity have been used to estimate the percentage of exposed bunches [
42]. This percentage was then used to compute the total bunch area, which, in turn, was used as a proxy of vine yield by means of a simplified area-to-mass conversion.
After yield components recognition and estimation considering their occlusion, it is necessary to convert that information into vine yield, which is a challenging step as it can be highly cultivar-dependent [
25,
45]. Bunch morphology can vary greatly among cultivars and even between sites for the same cultivar [
46]. The bunch compactness trait has been explored, considering its variability between cultivars and its importance regarding grape quality and bunch health [
47,
48]. Our research team also demonstrated that bunch morphology is a key feature when attempting to achieve a multicultivar bunch weight estimation model [
45]. Furthermore, we also proved that when converting bunch image features into weight, several image-based traits (e.g., visible berries, bunch area, average berry size) from one single bunch image are not redundant and present better results than when using single predictors on bunch images [
25,
45].
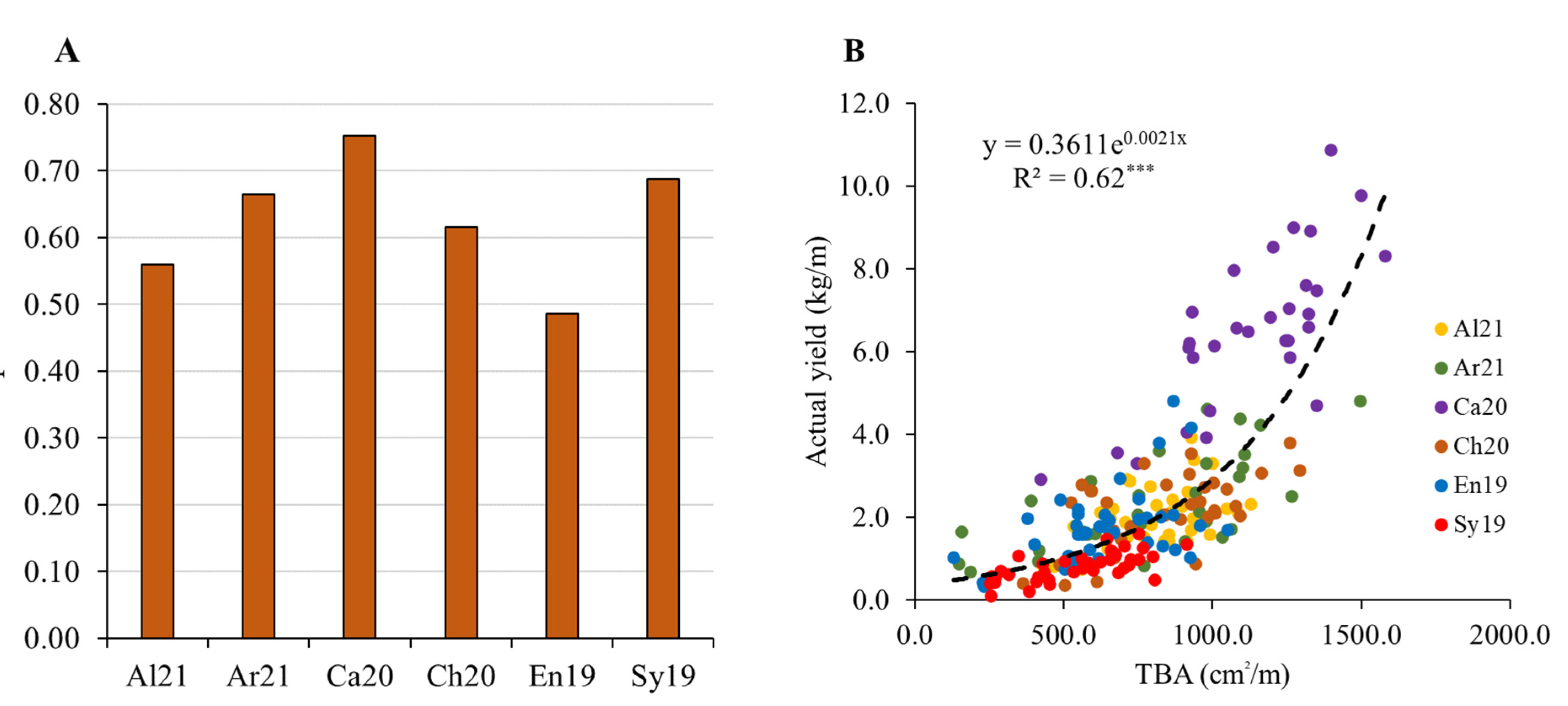
Today, the advantages that an image-based yield estimation approach has, compared to a manual one, are clear, especially considering its potential to be completely non-destructive, faster and labor free. However, its estimation errors in real field conditions, with high magnitudes of occlusion, are still difficult to be accepted by the growers. The aim of this paper is to compare the accuracy of a non-invasive and multicultivar, image-based yield estimation approach, in real field conditions, with a manual method based on bunch counts and historical bunch weight at harvest.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}