
Mapping of Soil pH Based on SVM-RFE Feature Selection Algorithm

Abstract
:1. Introduction
2. Materials and Methods
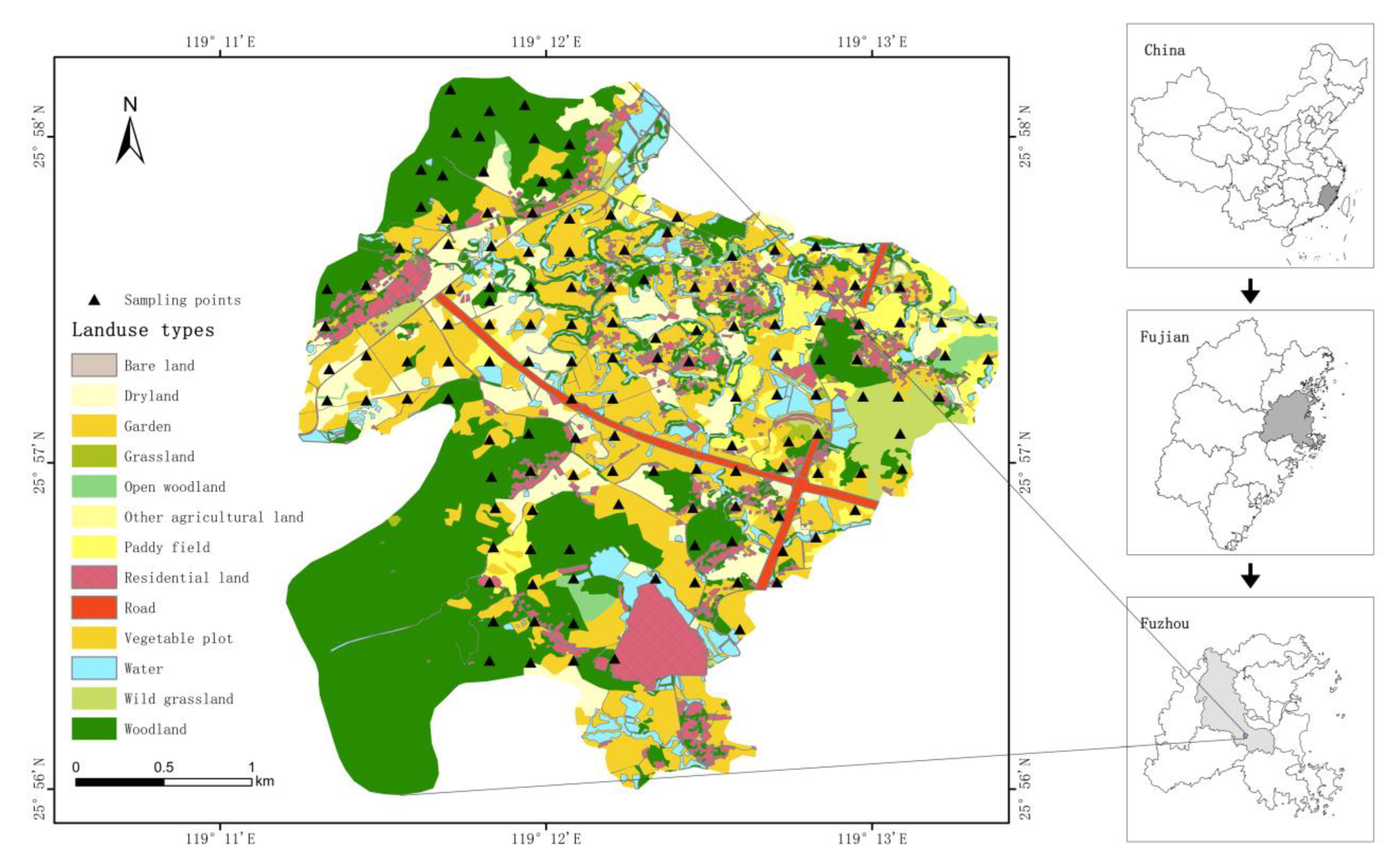
2.1. Study Area
2.2. Soil Sampling and Laboratory Analysis
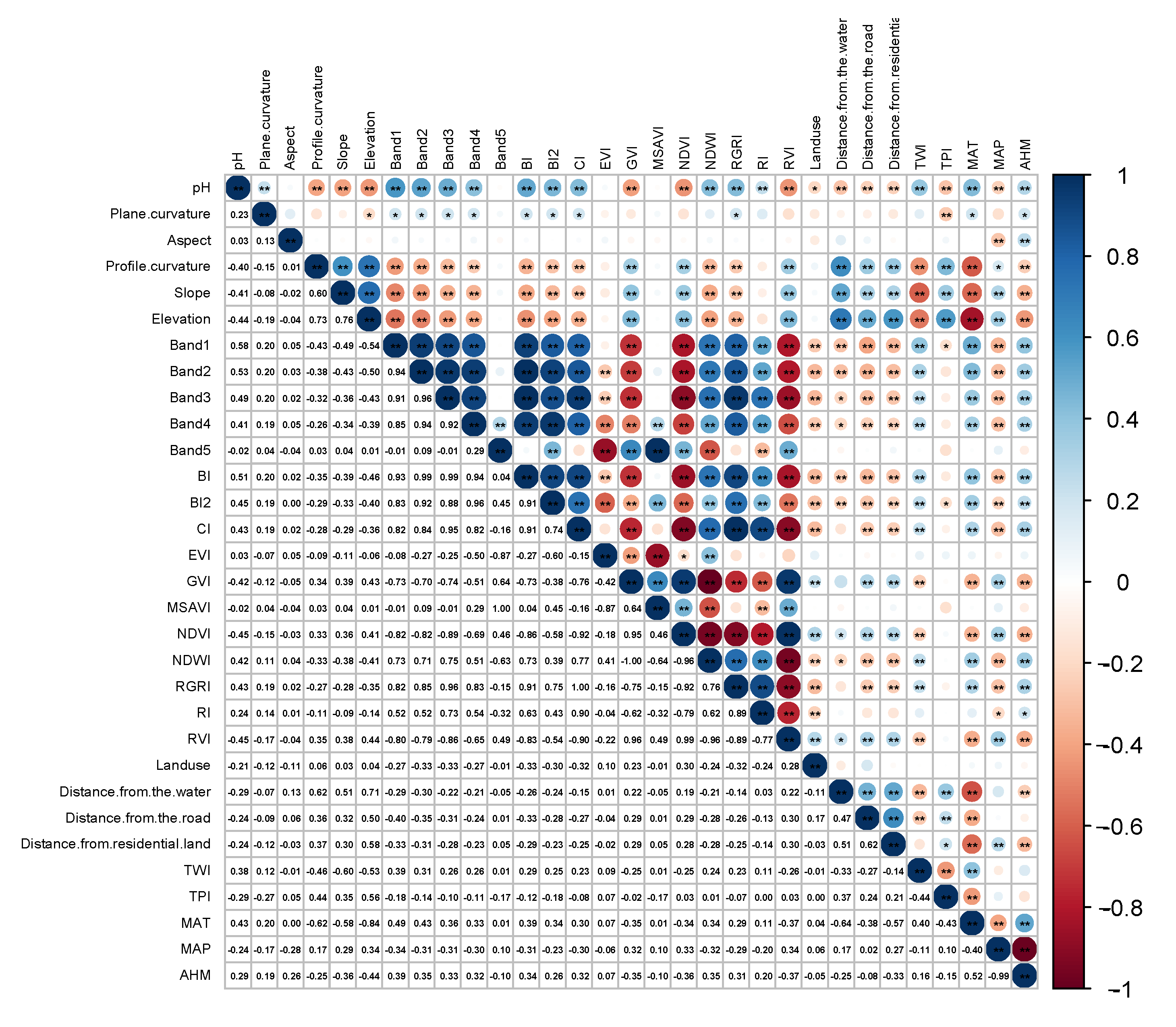
2.3. Environmental Covariates
2.4. Data Pre-Processing
2.5. Modeling Processes
2.6. Model Evaluation
3. Results
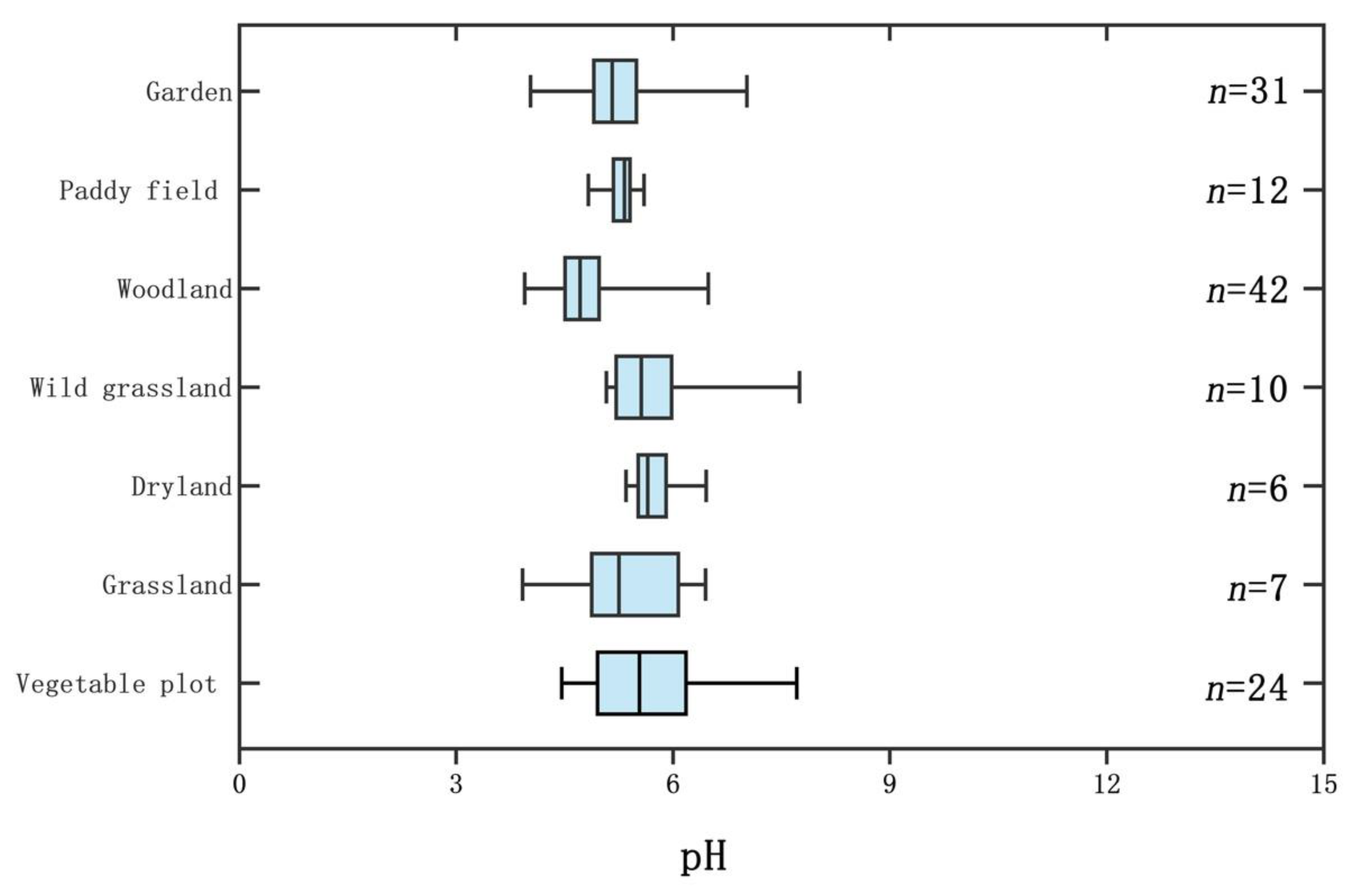
3.1. Descriptive Statistics of Soil pH
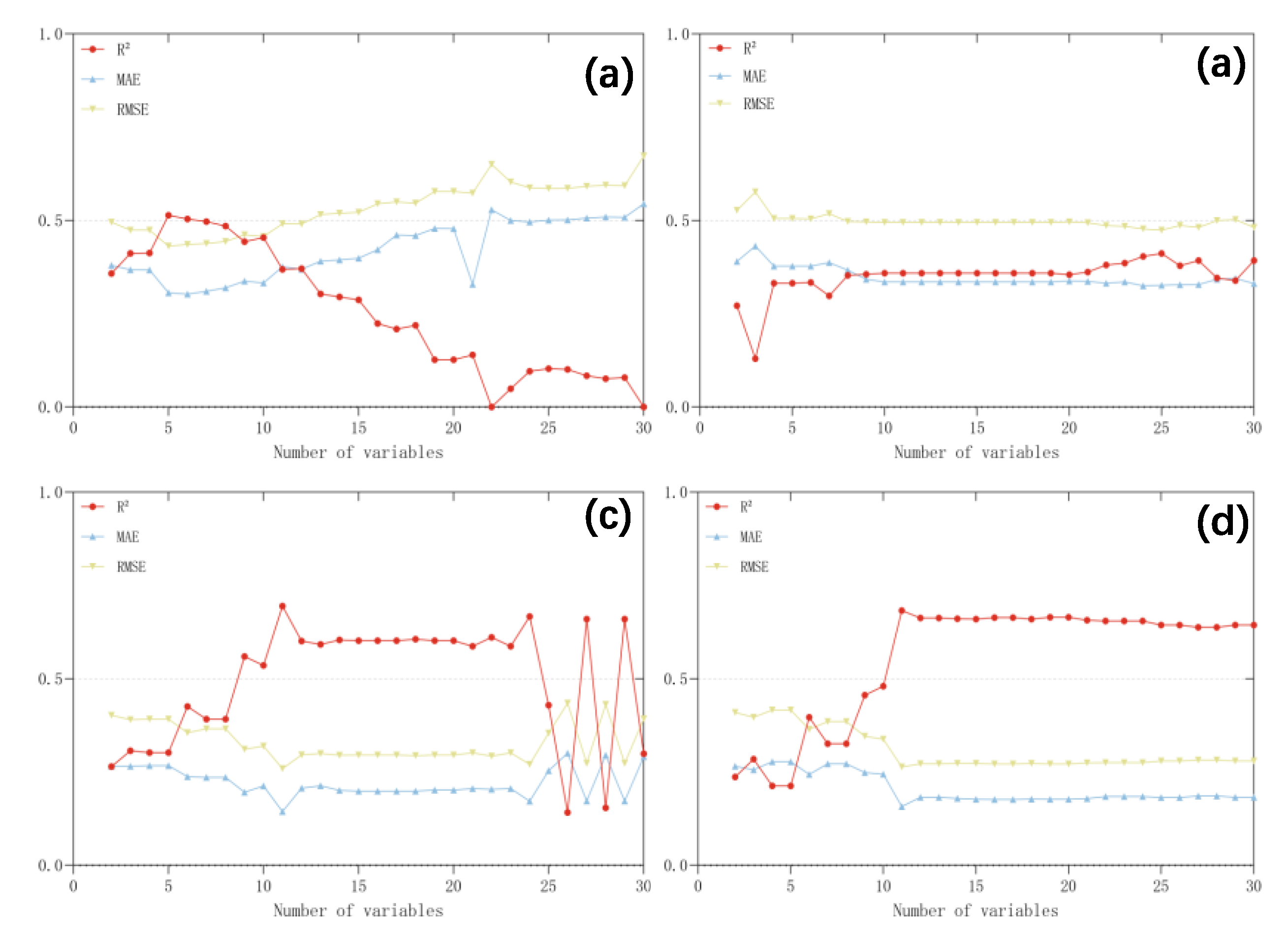
3.2. Feature Selection Procedures
3.3. Model Performance
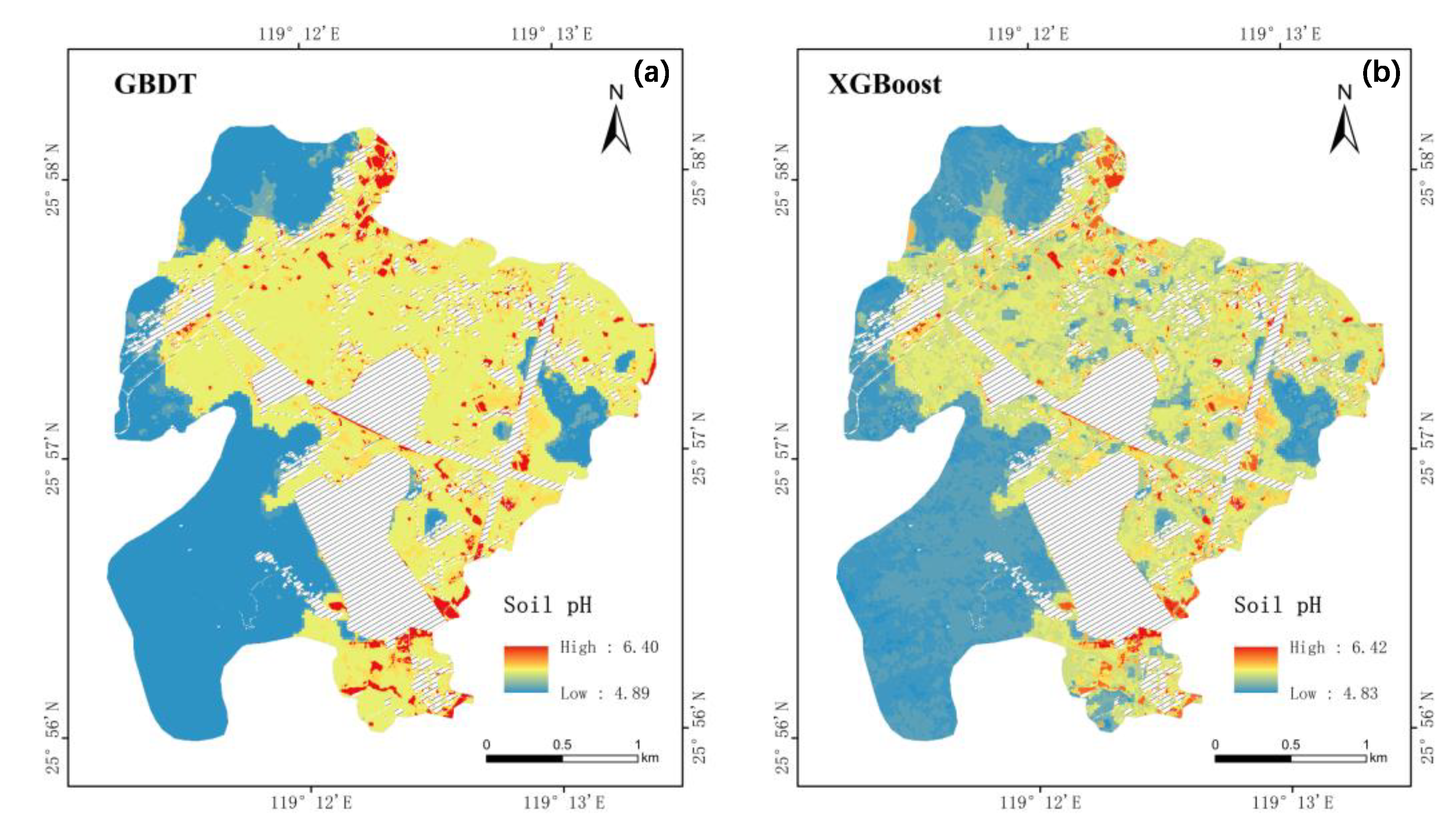
3.4. Spatial Predictive Mapping of Soil pH
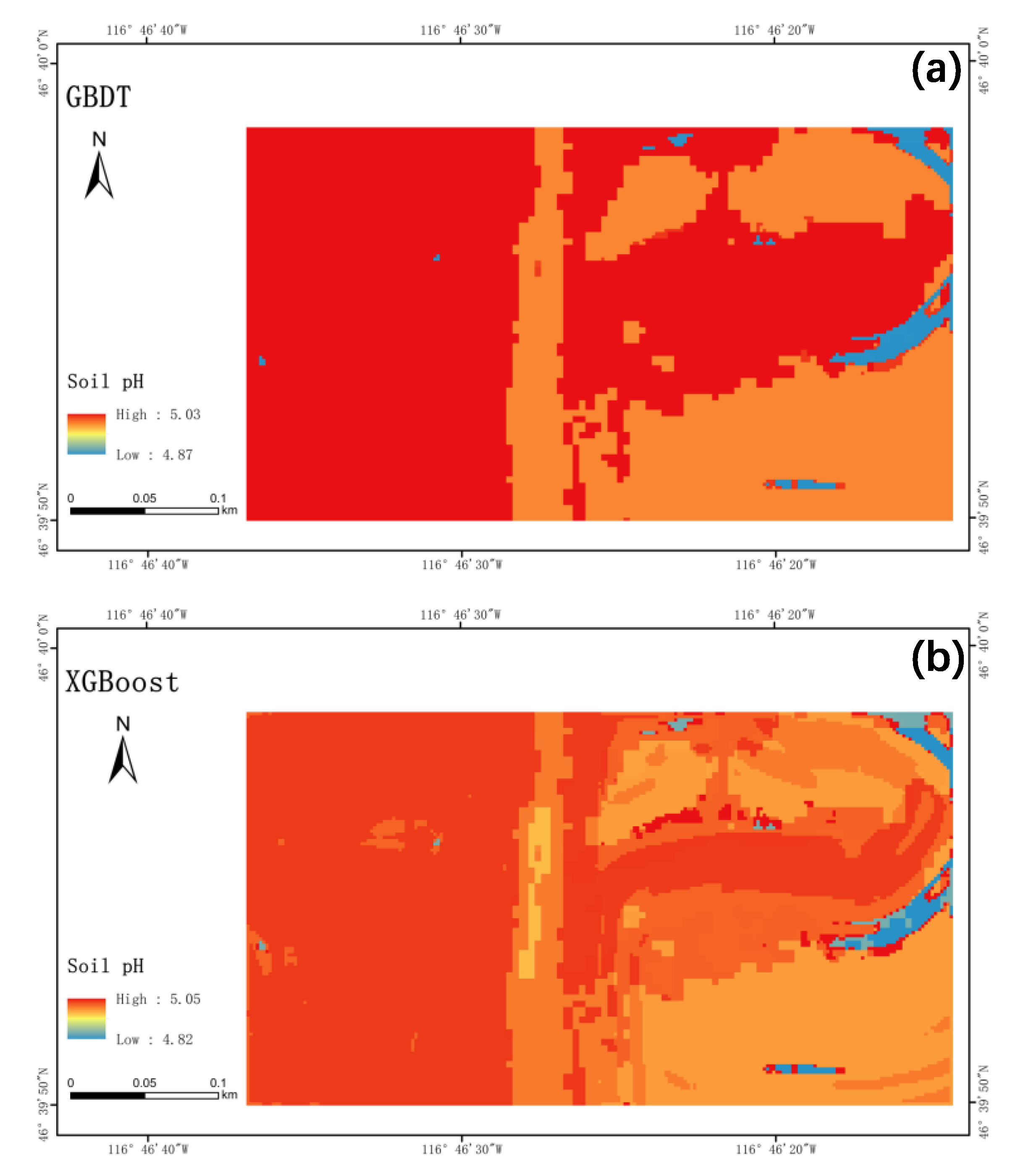
3.5. Assessment of the Generalizability of the Model
4. Discussion
4.1. Subsection Selected Features and Their Implications
4.2. Model Comparisons
4.3. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Shen, F.; Shen, D.; Jiang, Y.; Xiao, R. Immobilization of Cu2+ and Cd2+ by earthworm manure derived biochar in acidic circumstance. J. Environ. Sci. 2017, 53, 293–300. [Google Scholar] [CrossRef] [PubMed]
- Neina, D. The Role of Soil pH in Plant Nutrition and Soil Remediation. Appl. Environ. Soil Sci. 2019, 2019, 5794869. [Google Scholar] [CrossRef] [Green Version]
- Xiang, J.; Song, C.; Shi, Y.; Dong, Q.; Yang, Z. Spatial Variation Characteristics and Influencing Factors of Soil pH in the Lu′an Area of Anhui Province. Chin. J. Soil Sci. 2021, 52, 34–41. [Google Scholar]
- Mao, W.; Li, W.; Gao, H.; Chen, X.; Jiang, Y.; Hang, T.; Gong, X.; Chen, M.; Zhang, Y. pH variation and the driving factors of farmlands in Yangzhou for 30 years. J. Plant Nutr. Fertitizer 2017, 23, 883–893. [Google Scholar]
- Johnston, A.E.; Goulding, K.W.T.; Poulton, P.R. Soil acidification during more than 100 years under permanent grassland and woodland at rothamsted. Soil Use Manag. 1986, 2, 3–10. [Google Scholar] [CrossRef]
- Kopittke, G.R.; Tietema, A.; Verstraten, J.M. Soil acidification occurs under ambient conditions but is retarded by repeated drought: Results of a field-scale climate manipulation experiment. Sci. Total Environ. 2012, 439, 332–342. [Google Scholar] [CrossRef]
- Sun, F.; Lei, Q.; Liu, Y.; Li, H.; Wang, Q. The Progress and Prospect of Digital Soil Mapping Research. J. Soil Sci. 2011, 42, 1502–1507. [Google Scholar]
- Zeng, C.; Zhu, A.X.; Liu, F.; Yang, L.; Rossiter, D.G.; Liu, J.; Wang, D. The impact of rainfall magnitude on the performance of digital soil mapping over low-relief areas using a land surface dynamic feedback method. Ecol. Indic. 2017, 72, 297–309. [Google Scholar] [CrossRef]
- Malone, B.P.; Mcbratney, A.B.; Minasny, B.; Laslett, G.M. Mapping continuous depth functions of soil carbon storage and available water capacity. Geoderma 2009, 154, 138–152. [Google Scholar] [CrossRef]
- Yang, R.-M.; Zhang, G.-L.; Liu, F.; Lu, Y.-Y.; Yang, F.; Yang, F.; Yang, M.; Zhao, Y.-G.; Li, D.-C. Comparison of boosted regression tree and random forest models for mapping topsoil organic carbon concentration in an alpine ecosystem. Ecol. Indic. Integr. Monit. Assess. Manag. 2016, 60, 870–878. [Google Scholar] [CrossRef]
- Cai, H.; Peng, J.; Liu, W.; Luo, D.; Wang, Y.; Bai, J.; Bai, Z. Inversion and Mapping of Soil pH Valve Based on In-situ Hyperspectral Data in Cotton field. Bull. Soil Water Conserv. 2021, 41, 189–195. [Google Scholar]
- Dharumarajan, S.; Hegde, R.; Singh, S.K. Spatial prediction of major soil properties using Random Forest techniques A case study in semi-arid tropics of South India. Geoderma Reg. 2017, 10, 154–162. [Google Scholar] [CrossRef]
- Pahlavan-Rad, M.R.; Akbarimoghaddam, A. Spatial variability of soil texture fractions and pH in a flood plain (case study from eastern Iran). Catena 2018, 160, 275–281. [Google Scholar] [CrossRef]
- Tumsavas, Z. Possibility of determining soil pH using visible and near-infrared (Vis-NIR) spectrophotometry. J. Environ. Biol. 2017, 38, 1095–1100. [Google Scholar] [CrossRef]
- Wang, K. Application of geographically weighted regression on the spatial prediction of soil pH. J. Hunan Agric. Univ. 2013, 39, 73–79. [Google Scholar] [CrossRef]
- Chen, S.; Liang, Z.; Webster, R.; Zhang, G.; Zhou, Y.; Teng, H.; Hu, B.; Arrouays, D.; Shi, Z. A high-resolution map of soil pH in China made by hybrid modelling of sparse soil data and environmental covariates and its implications for pollution. Sci. Total Environ. 2019, 655, 273–283. [Google Scholar] [CrossRef]
- Yang, L.; Lin, J.; Molder, E.; Gao, R.; Yu, H.; Lin, Y.; Wang, D.; Li, J. Effects of Climate Types and Slope Sections on the pH of Soil in the Unstable Slope with High-Frequency Debris Flow in Jiangjiagou Watershed of Yunnan Province. Res. Soil Water Conserv. 2022, 29, 105–112. [Google Scholar]
- Ma, B.; Wu, F.; Li, Z.; Wang, J. Interaction of Crop Cover and Slope Gradient on Runoff and Sediment Yield. J. Soil Water Conserv. 2013, 27, 33–38. [Google Scholar]
- Jin, P.; Li, P.; Wang, Q.; Pu, Z. Developing and applying novel spectral feature parameters for classifying soil salt types in arid land. Ecol. Indic. 2015, 54, 116–123. [Google Scholar] [CrossRef]
- Bai, L.; Wang, C.; Zang, S.; Zhang, Y.; Hao, Q.; Wu, Y. Remote Sensing of Soil Alkalinity and Salinity in the Wuyu′er-Shuangyang River Basin, Northeast China. Remote Sens. 2016, 8, 163. [Google Scholar] [CrossRef] [Green Version]
- Reuter, H.I.; Nelson, A. Chapter 11 Geomorphometry in ESRI Packages. Dev. Soil Sci. 2009, 33, 269–291. [Google Scholar]
- Zhou, J.Y.; Zhang, L.M.; Yang, W.H.; Zhou, B.Q.; Xing, S.H. Dynamic and its driving factors of soil potential acid in croplands of Fujian Province, China. Ying Yong Sheng Tai Xue Bao J. Appl. Ecol. 2019, 30, 913–922. [Google Scholar]
- Fu, B.J.; Chen, L.D.; Ma, K.M.; Zhou, H.F.; Wang, J. The relationships between land use and soil conditions in the hilly area of the loess plateau in northern Shaanxi, China. Catena 2000, 39, 69–78. [Google Scholar] [CrossRef]
- Jolokhava, T.; Abdaladze, O.; Gadilia, S.; Kikvidze, Z. Variable soil pH can drive changes in slope aspect preference of plants in alpine desert of the Central Great Caucasus (Kazbegi district, Georgia). Acta Oecologica-Int. J. Ecol. 2020, 105, 103582. [Google Scholar] [CrossRef]
- Baltensweiler, A.; Heuvelink, G.B.M.; Hanewinkel, M.; Walthert, L. Microtopography shapes soil pH in flysch regions across Switzerland. Geoderma 2020, 380, 114663. [Google Scholar] [CrossRef]
- Wang, S.-H.; Lu, H.-L.; Zhao, M.-S.; Zhou, L.-M. Assessing soil pH in Anhui Province based on different features mining methods combined with generalized boosted regression models. Ying Yong Sheng Tai Xue Bao J. Appl. Ecol. 2020, 31, 3509–3517. [Google Scholar]
- Zhao, J.; Zhang, C.; Min, L.; Li, N.; Wang, Y. Retrieval for soil moisture in farmland using multi-source remote sensing data and feature selection with GA-BP neural network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 112–120. [Google Scholar]
- Zeraatpisheh, M.; Garosi, Y.; Owliaie, H.; Ayoubi, S.; Xu, M. Improving the spatial prediction of soil organic carbon using environmental covariates selection: A comparison of a group of environmental covariates. Catena 2022, 208, 105723. [Google Scholar] [CrossRef]
- International Union of Soil Sciences Working Group. World Reference Base for Soil Resources 2014: International Soil Classification System for Naming Soils and Creating Legends for Soil Maps; World Soil Resources Reports 106; FAO: Rome, Italy, 2014; Volume 106. [Google Scholar]
- Chen, Z.; Gong, Z.; Zhang, G.; Zhao, W. Correlation of soil taxa between chinese soil genetic classification and chinese soil taxonomy on various scales. Soils 2004, 36, 584–595. [Google Scholar]
- Wang, T.; Wang, G.; Innes, J.; Nitschke, C.; Kang, H. Climatic niche models and their consensus projections for future climates for four major forest tree species in the Asia-Pacific region. For. Ecol. Manag. 2016, 360, 357–366. [Google Scholar] [CrossRef]
- Thu Thuy, N.; Tien Dat, P.; Chi Trung, N.; Delfos, J.; Archibald, R.; Kinh Bac, D.; Ngoc Bich, H.; Guo, W.; Huu Hao, N. A novel intelligence approach based active and ensemble learning for agricultural soil organic carbon prediction using multispectral and SAR data fusion. Sci. Total Environ. 2022, 804, 150187. [Google Scholar]
- Odhiambo, B.O.; Kenduiywo, B.K.; Were, K. Spatial prediction and mapping of soil pH across a tropical afro-montane landscape. Appl. Geogr. 2020, 114, 102129. [Google Scholar] [CrossRef]
- Mathieu, R.; Pouget, M.; Cervelle, B.; Escadafal, R. Relationships between satellite-based radiometric indices simulated using laboratory reflectance data and typic soil color of an arid environment. Remote Sens. Environ. 1998, 66, 17–28. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Schmidt, K.; Amirian-Chakan, A.; Rentschler, T.; Zeraatpisheh, M.; Sarmadian, F.; Valavi, R.; Davatgar, N.; Behrens, T.; Scholten, T. Improving the Spatial Prediction of Soil Organic Carbon Content in Two Contrasting Climatic Regions by Stacking Machine Learning Models and Rescanning Covariate Space. Remote Sens. 2020, 12, 1095. [Google Scholar] [CrossRef] [Green Version]
- Tajik, S.; Ayoubi, S.; Zeraatpisheh, M. Digital mapping of soil organic carbon using ensemble learning model in Mollisols of Hyrcanian forests, northern Iran. Geoderma Reg. 2020, 20, e00256. [Google Scholar] [CrossRef]
- Tao, H.; Al-Bedyry, N.K.; Khedher, K.M.; Shahid, S.; Yaseen, Z.M. River water level prediction in coastal catchment using hybridized relevance vector machine model with improved grasshopper optimization. J. Hydrol. 2021, 598, 126477. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Feature clustering based support vector machine recursive feature elimination for gene selection. Appl. Intell. 2018, 48, 594–607. [Google Scholar] [CrossRef]
- Williams, C.G.; Ojuri, O.O. Predictive modelling of soils’ hydraulic conductivity using artificial neural network and multiple linear regression. SN Appl. Sci. 2021, 3, 152. [Google Scholar] [CrossRef]
- Breiman, L. Random forests, machine learning 45. J. Clin. Microbiol. 2001, 2, 199–228. [Google Scholar]
- Pham, T.D.; Yokoya, N.; Nguyen, T.T.T.; Le, N.N.; Ha, N.T.; Xia, J.; Takeuchi, W.; Pham, T.D. Improvement of Mangrove Soil Carbon Stocks Estimation in North Vietnam Using Sentinel-2 Data and Machine Learning Approach. Giscience Remote Sens. 2021, 58, 68–87. [Google Scholar] [CrossRef]
- Teng, H.; Rossel, R.A.V.; Shi, Z.; Behrens, T. Updating a national soil classification with spectroscopic predictions and digital soil mapping. Catena 2018, 164, 125–134. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Jin, X.; Zhu, X.; Li, S.; Wang, W.; Qi, H. Predicting Soil Available Phosphorus by Hyperspectral Regression Method Based on Gradient Boosting Decision Tree. Laser Optoelectron. Prog. 2019, 56, 141–150. [Google Scholar]
- Song, Y.; Niu, R.; Xu, S.; Ye, R.; Peng, L.; Guo, T.; Li, S.; Chen, T. Landslide Susceptibility Mapping Based on Weighted Gradient Boosting Decision Tree in Wanzhou Section of the Three Gorges Reservoir Area (China). ISPRS Int. J. Geo-Inf. 2019, 8, 4. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C.; Assoc Comp, M. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Jia, Y.; Jin, S.; Savi, P.; Gao, Y.; Tang, J.; Chen, Y.; Li, W. GNSS-R Soil Moisture Retrieval Based on a XGboost Machine Learning Aided Method: Performance and Validation. Remote Sens. 2019, 11, 1655. [Google Scholar] [CrossRef] [Green Version]
- Nam Thang, H.; Manley-Harris, M.; Tien Dat, P.; Hawes, I. The use of radar and optical satellite imagery combined with advanced machine learning and metaheuristic optimization techniques to detect and quantify above ground biomass of intertidal seagrass in a New Zealand estuary. Int. J. Remote Sens. 2021, 42, 4716–4742. [Google Scholar]
- Nielsen, D.R.; Bouma, J. Soil Spatial Variability: Proceedings of a Workshop of the ISSS and the SSSA, Las Vegas, USA/Pdc296; Center Agricultural Pub and Document: Wageningen, The Netherlands, 1985. [Google Scholar]
- Rao, B.R.M.; Sharma, R.C.; Ravi Sankar, T.; Das, S.N.; Dwivedi, R.S.; Thammappa, S.S.; Venkataratnam, L. Spectral behaviour of salt-affected soils. Int. J. Remote Sens. 1995, 16, 2125–2136. [Google Scholar] [CrossRef]
- Roudier, P.; Burge, O.R.; Richardson, S.J.; McCarthy, J.K.; Grealish, G.J.; Ausseil, A.-G. National Scale 3D Mapping of Soil pH Using a Data Augmentation Approach. Remote Sens. 2020, 12, 2872. [Google Scholar] [CrossRef]
- Lu, H.; Zhao, M.; Liu, B.; Zhang, P.; Lu, L. Predictive Mapping of Soil pH in Anhui Province Based on Boruta-Support Vector Regression. Geogr. Geo-Inf. Sci. 2019, 35, 66–72. [Google Scholar]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Hong, S.; Gan, P.; Chen, A. Environmental controls on soil pH in planted forest and its response to nitrogen deposition. Environ. Res. 2019, 172, 159–165. [Google Scholar] [CrossRef] [PubMed]
- Binkley, D.; Richter, D.D. Nutrient Cycles and H+ Budgets of Forest Ecosystems. Adv. Ecol. Res. 1987, 16, 1–51. [Google Scholar]
- Hogberg, P.; Fan, H.B.; Quist, M.; Binkley, D.; Tamm, C.O. Tree growth and soil acidification in response to 30 years of experimental nitrogen loading on boreal forest. Glob. Chang. Biol. 2006, 12, 489–499. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, X.; Guo, X.; Zhu, Q.; Luo, J.; Xu, Z.; Zhong, L.; Ye, Y. Inversion of soil properties in rare earth mining areas (southern Jiangxi, China) based on visible-near-infrared spectroscopy. J. Soils Sediments 2022, 22, 2406–2421. [Google Scholar] [CrossRef]
- Ye, Z.; Sheng, Z.; Liu, X.; Ma, Y.; Wang, R.; Ding, S.; Liu, M.; Li, Z.; Wang, Q. Using Machine Learning Algorithms Based on GF-6 and Google Earth Engine to Predict and Map the Spatial Distribution of Soil Organic Matter Content. Sustainability 2021, 13, 14055. [Google Scholar] [CrossRef]
- Li, Y.; Li, M.; Li, C.; Liu, Z. Forest aboveground biomass estimation using Landsat 8 and Sentinel-1A data with machine learning algorithms. Sci. Rep. 2020, 10, 9952. [Google Scholar] [CrossRef]
- Brown, I.; Mues, C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 2012, 39, 3446–3453. [Google Scholar] [CrossRef]
- Rong, G.; Alu, S.; Li, K.; Su, Y.; Zhang, J.; Zhang, Y.; Li, T. Rainfall Induced Landslide Susceptibility Mapping Based on Bayesian Optimized Random Forest and Gradient Boosting Decision Tree Models-A Case Study of Shuicheng County, China. Water 2020, 12, 3066. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Q.; Wang, C.; Yuan, D.; Lou, Y.; Zhang, X.; Jia, L. Spatail variability of soil ph and its influence factors at a county scale in hilly area of mid-sichuan basin a case study from renshou in sichuan. Resour. Environ. Yangtze Basin 2015, 24, 1192–1199. [Google Scholar]
- Xie, E.; Zhao, Y.; Li, H.; Shi, X.; Lu, F.; Zhang, X.; Peng, Y. Spatio-temporal changes of cropland soil pH in a rapidly industrializing region in the Yangtze River Delta of China, 1980–2015. Agric. Ecosyst. Environ. 2019, 272, 95–104. [Google Scholar] [CrossRef]
- Zeng, M.; de Vries, W.; Bonten, L.T.C.; Zhu, Q.; Hao, T.; Liu, X.; Xu, M.; Shi, X.; Zhang, F.; Shen, J. Model-Based Analysis of the Long-Term Effects of Fertilization Management on Cropland Soil Acidification. Environ. Sci. Technol. 2017, 51, 3843–3851. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; de Vries, W.; Thomas, B.W.; Hao, X.; Shi, X. Impacts of long-term nitrogen fertilization on acid buffering rates and mechanisms of a slightly calcareous clay soil. Geoderma 2017, 305, 92–99. [Google Scholar] [CrossRef]
- Shekofteh, H.; Ramazani, F.; Shirani, H. Optimal feature selection for predicting soil CEC: Comparing the hybrid of ant colony organization algorithm and adaptive network-based fuzzy system with multiple linear regression. Geoderma 2017, 298, 27–34. [Google Scholar] [CrossRef]
- Meng, X.; Bao, Y.; Ye, Q.; Liu, H.; Zhang, X.; Tang, H.; Zhang, X. Soil Organic Matter Prediction Model with Satellite Hyperspectral Image Based on Optimized Denoising Method. Remote Sens. 2021, 13, 2273. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Source |
|---|---|
| Climate | |
| Mean annual temperature (MAT) | ClimateAP |
| Mean annual precipitation (MAP) | ClimateAP |
| Annual humidity-heat index (AHM) | ClimateAP |
| Remote sensing image | |
| Band1 (Blue) | RapidEye-3A (440–510 nm) |
| Band2 (Green) | RapidEye-3A (520–590 nm) |
| Band3 (Red) | RapidEye-3A (630–685 nm) |
| Band4 (Red edge) | RapidEye-3A (690–730 nm) |
| Band5 (NIR) | RapidEye-3A (760–850 nm) |
| Vegetation Index | |
| NDVI | |
| RVI | |
| MSAVI | |
| EVI | |
| RGRI | |
| GVI | |
| BI [32] | |
| BI2 [32] | |
| RI [34] | |
| CI [34] | |
| NDWI | |
| DEM derivatives | |
| Elevation | |
| Slope | The degree of steepness of a surface element. |
| Aspect | The degree to which the ground tilts. |
| Plane curvature | The surface shape is viewed in a horizontal plane that has sliced through the surface at the target point. |
| Profile curvature | The shape of the surface in the immediate neighborhood of the sample point was contained within the vertical plane. |
| TWI | Topographic Wetness Index. |
| TPI | Topographic position index. |
| Human factors | |
| Land-use map | |
| Distance from the road | |
| Distance from the water | |
| Distance from residential land |
| Parameter | Min | Max | Mean | SD | CV |
|---|---|---|---|---|---|
| pH | 3.92 | 7.75 | 5.25 | 0.75 | 14.22% |
| Strong Acid (<5.0) | Acid (5.0~<6.5) | Neutral (6.5~<7.5) | Alkaline (7.5~<8.5) | Strong Alkaline (>8.5) | |
|---|---|---|---|---|---|
| Frequency of sample point distribution | 37.12% | 58.33% | 2.27% | 2.27% | 0.00% |
| Feature Name | Feature Ranking | Feature Name | Feature Ranking | Feature Name | Feature Ranking |
|---|---|---|---|---|---|
| MAT | 1 | Profile curvature | 11 | Band1 | 21 |
| Slope | 2 | BI2 | 12 | NDWI | 22 |
| TWI | 3 | BI. | 13 | RGRI | 23 |
| MSAVI | 4 | MAP | 14 | RI | 24 |
| Band5 | 5 | Band3 | 15 | Distance from the water | 25 |
| Land use | 6 | Band2 | 16 | CI | 26 |
| AHM | 7 | Band4 | 17 | Distance from the road | 27 |
| TPI | 8 | Plane curvature | 18 | EVI | 28 |
| RVI | 9 | GVI | 19 | Distance from residential land | 29 |
| Elevation | 10 | Aspect | 20 | NDVI | 30 |
| Models | The Optimal Set of Environment Variables | Number of Variables |
|---|---|---|
| MLR | MAT, slope, TWI, MSAVI, Band5. | 5 |
| RF | MAT, slope, TWI, MSAVI, Band5, land use, AHM, TPI, RVI, elevation, profile curvature, BI2, BI, MAP, Band3, Band2, Band4, plane curvature, GVI, aspect, NDWI, RGRI, RI, distance from the water. | 25 |
| GBDT | MAT, slope, TWI, MSAVI, Band5, land use, AHM, TPI, RVI, elevation, profile curvature. | 11 |
| XGBoost | MAT, slope, TWI, MSAVI, Band5, land use, AHM, TPI, RVI, elevation, profile curvature. | 11 |
| Models | Data Sets with Different Characteristic Variables | R2 | MAE | RMSE |
|---|---|---|---|---|
| MLR | Raw feature variable dataset | 0.00 | 0.55 | 0.67 |
| SVM-RFE feature selection after feature variable dataset | 0.51 | 0.31 | 0.43 | |
| RF | Raw feature variable dataset | 0.39 | 0.33 | 0.48 |
| SVM-RFE feature selection after feature variable dataset | 0.41 | 0.33 | 0.47 | |
| GBDT | Raw feature variable dataset | 0.30 | 0.29 | 0.39 |
| SVM-RFE feature selection after feature variable dataset | 0.68 | 0.16 | 0.27 | |
| XGBoost | Raw feature variable dataset | 0.64 | 0.18 | 0.28 |
| SVM-RFE feature selection after feature variable dataset | 0.68 | 0.16 | 0.26 |
| Study Area | Models | R2 | MAE | RMSE |
|---|---|---|---|---|
| Palouse region | GBDT | 0.55 | 0.01 | 0.03 |
| XGBoost | 0.62 | 0.01 | 0.02 | |
| The Study area of this paper | GBDT | 0.68 | 0.16 | 0.27 |
| XGBoost | 0.68 | 0.16 | 0.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Wang, K.; Jin, S. Mapping of Soil pH Based on SVM-RFE Feature Selection Algorithm. Agronomy 2022, 12, 2742. https://doi.org/10.3390/agronomy12112742
Guo J, Wang K, Jin S. Mapping of Soil pH Based on SVM-RFE Feature Selection Algorithm. Agronomy. 2022; 12(11):2742. https://doi.org/10.3390/agronomy12112742
Chicago/Turabian StyleGuo, Jia, Ku Wang, and Shaofei Jin. 2022. "Mapping of Soil pH Based on SVM-RFE Feature Selection Algorithm" Agronomy 12, no. 11: 2742. https://doi.org/10.3390/agronomy12112742