1. Introduction
The edible fungus industry is important in China’s agriculture and ranks sixth after grain, cotton, oil, fruit, and vegetables in agriculture proportion, which has a strong potential in promoting local economic development. As an edible fungus species, antler mushrooms have a variety of nutrients and pharmacological effects that attract many consumers. With various functions and good taste, antler mushroom is an agricultural product; thus, quality grading is an important part after harvesting. Traditional antler mushroom quality-grading operation uses manual contact grading, which produces a low production efficiency, large grading errors, and high labor training costs. Concurrently, fresh antler mushroom tissue is fragile and can be easily damaged during traditional manual grading, resulting in defects and browning on the antler mushroom surface [
1,
2]. Therefore, the traditional manual grading method cannot meet the needs of factory production. Size grading by machine vision technology in the factory production is significant in solving the above problems in traditional size grading.
With the rapid development of information technology, machine learning has extracted information from images through a computer simulation of human vision and then analyzed it to guide real production [
3,
4], which has become one of the hot topics of artificial intelligence research. Applying machine learning to modern agricultural production can effectively promote the development of modern agriculture [
5,
6] and the efficiency of agricultural production. Arthur et al. [
7] proposed a deep neural network classifier for tomato external defect detection, which overcame the challenge of a high variance in low sample defect classes. Jiang et al. [
8] used the deep learning method to classify apple images, studied and evaluated the deep neural networks with different convolution layers and different number of neurons, and proposed a method to detect apple fruit infection and timely prevent further infection caused by environmental factors. Xu et al. [
9] used a CNN model to automatically classify five kinds of corn seeds, which was significantly better than the traditional manual selection, and proposed a fast method for corn seed classification combining machine vision and deep learning. The above research shows that machine learning has a relatively wide range of applications in the agricultural field and has achieved good results.
Since 1991, in the field of edible mushrooms, scholars have been trying to apply deep learning methods in edible mushroom maturity detection and quality grading to change the hindered development of the edible mushroom industry [
10,
11]. Vooren et al. [
10] used image analysis technology to classify mushrooms according to their length, width, and other features and tested 460 sets of experimental images. Experiments showed that the recognition rate reached 80%. Heinemann et al. [
12] used the watershed method, the smart operator method, and the closed operator method to classify twin mushrooms and developed an automatic size-sorting system for fresh twin mushrooms. VıZhányó et al. [
13] used imaging methods to achieve the nondestructive detection of mushrooms according to features such as color, freshness, disease, size, and shape characteristics. Chen et al. [
14] studied an evaluation method to classify dried shiitake mushrooms according to their appearance features, such as size, color, and damage degree, and developed an automatic grading system to automatically classify dried shiitake mushroom by their character. A total of 250 dried shiitake mushrooms were detected during the experiments, and results showed that the accuracy rate was 97.6%. Yu et al. [
15] obtained mushroom location information on a cultivation bed by applying a localization algorithm and outline description of mushrooms, which provided a theoretical basis for image processing. Li et al. [
16] used computer vision technology to detect different degrees of damage in shiitake mushrooms, and experiments showed that the overall recognition rate of the recognition technology was 96.5%. Concha Meyer et al. [
17] developed a system for estimating mushroom volume using optical imaging technology. The measured mushroom volume obtained by this system was similar to the real mushroom volume, which had certain guiding importance in the evaluation and calculation of mushroom volume. In addition, Lu et al. [
18] proposed a system for image measurement based on YOLOv3 [
19], which improved the local accuracy through a position correction algorithm and used a bounding box to measure the size of mushrooms to obtain the growth data of mushrooms cultivated in greenhouses. Jiang et al. [
20] developed a system for online quality detection and sorting for fresh button mushrooms using machine vision. The system used the watershed algorithm, the speeded-up robust features (SURF) algorithm, and the conversion of RGB images to Lab images to obtain the size, defects, and browning degree of mushrooms. In an experiment with 100 mushrooms, the average sorting accuracy was 96.45%, achieving quality detection and classification results. Existing research has thus improved and upgraded neural networks in many ways. The classification ability of edible fungi has been improved, and a foundation has been set to apply computer vision technology to edible fungi classification.
To solve the problems produced by the traditional size grading of antler mushrooms, based on real-time segmentation technology [
21], this paper proposes a real-time object detection and image segmentation network (Y-PNet) combining YOLOv5 [
22] and PSPNet [
23], which realizes the detection, marking, and segmentation of antler mushroom. Y-PNet first reads and detects video through YOLOv5. When the image is detected, PSPNet is immediately called for a pixel-level contour segmentation, which realizes the purpose of real-time segmentation. In this paper, the Y-PNet real-time object detection and image segmentation algorithm is used to build the size-grading system, which realizes the noncontact size-grade detection of antler mushrooms.
The primary results of this study include the following:
(1) A real-time object detection and image segmentation network (Y-PNet) is proposed combining YOLOv5 and PSPNet and a detection system for real-time grading is established to create a noncontact operation method during the production process.
(2) The CSPDarknet backbone extraction network of YOLOv5 is replaced by MobileNetV3 [
24] and establishes a lightweight real-time detection network. The network can reduce the number of parameters in reasoning process, improve the performance of the algorithm and the efficiency of real-time detection, and solve the problem of missed detection.
(3) In order to make the segmentation ability more efficient and improve the accuracy of the feature extraction of PSPNet, CBAM [
25] is added after stages 1, 2, 3, and 4 of MobileNetV3. Then, the original Resnet50 network of PSPNet is replaced with the modified MobileNetV3 to build a lightweight semantic segmentation network.
2. Size Classification Algorithm
2.1. YOLOv5 Network Model
YOLOv5 is a single-stage object detection algorithm that has the advantages of a high detection accuracy and fast running speed. Its network includes four models: YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. The parameters and volumes of the four models increase accordingly. The primary difference between these models is the number of feature extraction modules and convolution kernels included at specific locations in the network. The YOLOv5s model uses the smallest network depth and feature map dimension as possible to ensure a small weight file and fast detection speed. While ensuring the accuracy of object detection, the model is conducive to operation on mobile devices to achieve real-time object detection. The basic YOLOv5 architecture is mainly based on YOLOv4 [
26], given in the PyTorch framework.
Figure 1 shows the network structure of YOLOv5.
The network structure of YOLOv5 primarily consists of four parts: input, backbone, neck, and head. The input primarily includes three parts: mosaic data augmentation, image size processing, and adaptive anchor box calculation. During mosaic data enhancement, four pictures are combined to enrich the background of the picture. During picture size processing, the smallest black boxes are adaptively added to the original images of different lengths and widths and uniformly scale them to a standard size, leaving the aspect ratio of the original images unchanged. During adaptive anchor box calculation, the output prediction box is compared with the real box based on the initial anchor box; the difference is calculated and then updated in reverse and the parameters are continuously iterated to obtain the most suitable one.
The backbone mainly contains CSP1_X with a residual structure, Focus, SPP, and CBL modules. Because the backbone network is deep, when backpropagating between layers, using CSP1_X with a residual structure can enhance the gradient value and effectively prevent the gradient disappearance caused by a deepening network, and the obtained feature granularity is finer. The focus module slices the image, expands the input channel by 4 times, and obtains the undersampling feature map after one convolution. Concurrently, the number of calculations is reduced, and the speed is improved. SPP achieves the fusion of local features and global feather map level. CBL is a convolutional module used to obtain features.
The neck uses the structure of combining FPN and PAN; combines the conventional FPN layer with the bottom-up feature pyramid; fuses the extracted semantic features and position features; and fuses the features of the backbone layer and the detection layer. The CSP2_X structure strengthens the network feature fusion ability, enabling the model to obtain richer feature information.
The head outputs a vector with the class probability of the target object, the object score and the object bounding box position. The detection network consists of three detection layers. Feature maps of different sizes are used to detect target objects of different sizes. Each detection layer outputs the corresponding vector and finally generates the predicted bounding box and category of the object in the original image and labels it.
2.2. PSPNet Network Model
The core idea of PSPNet (pyramid scene parsing network) is to use the global pyramid pooling module to divide the acquired feature layers into grids of different sizes, and average pooling is performed inside each grid. The scene analysis network built in this way can aggregate the context information of different regions to solve the problem of category confusion and discontinuity in the prediction results caused by the lack of utilization of the global scene in ordinary FCN, thus markedly improving the ability of the network to analyze the scene.
The pyramid pooling scale fusion structure is shown in
Figure 2. After the network model obtains a feature map, it first goes through a network for feature extraction. The original author of this part used the ResNet network model of atrous convolutions [
27], and the role of atrous convolution was primarily to increase the receptive field and obtain sufficient global information on the target. Then, the extracted features are input to the spatial pyramid pooling module, and four pooling kernels of different scales, such as
,
,
, and
, are used for average pooling. Then, to maintain the weights of the global features, the number of channels is reduced to 1/4 of the original through a
convolution layer, and all pooled feature maps are upsampled to the preinput size to connect the input feature maps. Then, the pyramid pooling global feature map with twice the number of channels can be obtained. The process of combining features is actually the process of merging the shallow features of the target with the deep features processed and output by the feature extraction network, the process of fully considering the context information. Finally, the
Conv performs the fusion and dimensionality reduction of multiscale information, and then, the final feature layer is constructed. The structure of the pyramid pooling scale fusion is pooled at multiple scales, which improves the feature information of each scale in the final feature map, making it easier for the network to capture the global information in the image. The algorithm proposed fully solves the problem that the FCN-based semantic segmentation model lacks a suitable strategy to use the category cues in the global scene, and the segmentation results have contextual relationship mismatch, category confusion, and an inability to pay attention to insignificant targets [
23].
2.3. Arithmetic Optimization
2.3.1. Improvement of Backbone Network for Feature Extraction
Considering that the industrial cultivation of antler mushrooms must ensure a high-efficiency fruiting and that the images collected by industrial cameras are of high resolution, the primary feature extraction networks of the original YOLOv5 algorithm and PSPNet algorithm, are CSPDarknet and ResNet, respectively. The network model has many parameters and calculations, and exhibits a high complexity, and is thus not suitable for real-time detection and model deployment [
28]. When the transmission speed of the production line cannot match the detection speed, missed detections may also occur, which will cause the detection results to deviate from the real results, resulting in inaccurate detection.
Taking ResNet as an example, its primary goal is to extract features by first reducing, then convoluting, and finally increasing the dimension. ResNet typically solves the problem of information loss and gradient disappearance of traditional convolutional neural networks or fully connected networks during information transmission to ensure that the deep network can be trained smoothly. ResNet introduces diversity into the receptive field through skip connection. However, the high-dimensional features become increasingly abstract after several feature extractions. Although this process is beneficial for object classification, too many model parameters are required, which leads to information loss and a loss of accuracy in the segmentation results.
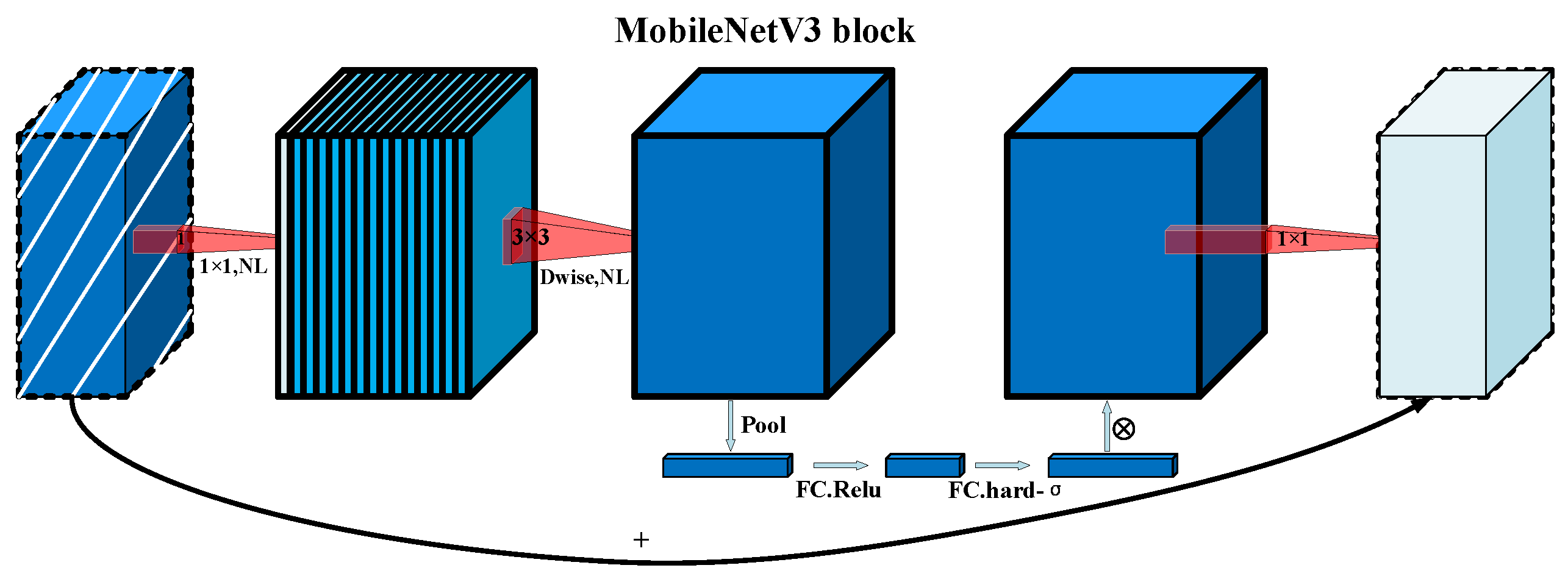
Aiming at the above problems, the MobileNet network model was introduced into the backbone feature extraction network of the traditional YOLOv5 algorithm and PSPNet algorithm. This model is a lightweight deep neural network proposed by Google for embedded devices such as mobile terminals. It is the result of a comprehensive consideration of training accuracy and network model performance, and its core idea is the separable convolution operation [
29]. MobileNetV3 in this series of models was built upon the first two generations of V1 and V2, and includes new improvements, achieving excellent performance and speed among existing lightweight models. MobileNetV3 is mainly improved from MnasNet [
30], and the main improvements include the following aspects:
(1) A redesigned time-consuming layer structure, including the reduction of the number of convolution kernels in the first layer from 32 to 16 and the last-stage streamlining, which ensures the accuracy and improves the speed of the operation, saving 14% of the total inference time;
(2) The NetAdapt algorithm, which obtains the optimal number of filters used by the expansion layer and the optimal number of channels output by the bottleneck layer, and automatically simplifies the pretraining model while maintaining a high accuracy;
(3) An inherited depthwise separable convolution of V1 and the residual structure with the linear bottleneck of V2;
(4) In the structure containing SE, the number of channels in the expansion layer is reduced by a quarter, which not only improves the accuracy, but also saves time;
(5) Relu6 is replaced by
h-swish (
x). Formula (
1) is given below;
(6) For the SE module, Relu6(x + 3)/6 is used to approximate a sigmoid.
The inverse residual structure with a linear bottleneck inherited from V2 by MobileNetV3 is exactly opposite to that of ResNet. During feature extraction, this method first increases the dimension, then perform convolution, and finally perform a dimensionality reduction operation, which guarantees that the detailed features of the target are not lost. Concurrently, a deep convolution kernel is only performed on one channel of the feature layer; thus, the number of calculations are not too high:
The network structure of MobileNetV3 is shown in
Figure 3.
2.3.2. Introduction of the CBAM Module
Bottled antler mushrooms grow randomly, even in the same matrix. Therefore, more details are required when using antler mushrooms as detection objects. The traditional PSPNet semantic segmentation simply uses atrous convolution to increase the receptive field to downsample the object, which neglects some features of the detected object, resulting in incomplete image partial details and making the segmentation edges rough. Therefore, a lightweight attention mechanism (CBAM [
25]) module that combines spatial and channel dimensions was embedded in the improved PSPNet semantic segmentation algorithm to improve the computation speed of the algorithm and the contour segmentation accuracy of antler mushrooms.
A CBAM (convolutional block attention module) is a lightweight convolutional attention module that sequentially derives attention maps along two independent dimensions of channel and space from a given intermediate feature map. Then, the attention map is multiplied by the input feature map for adaptive feature refinement. The structure of the CBAM is shown in
Figure 4. Because the CBAM is a widely used lightweight attention module, it can be easily embedded into the basic CNN for end-to-end training, and only a small amount of computation is added. To calculate channel attention effectively, it is necessary to compress the spatial dimension of the input feature map. To aggregate spatial information, average pooling is typically used, but maximum pooling can collect unique object feature information and can infer more detailed channel attention. Therefore, the features of both average pooling and max pooling are used in the spatial information aggregation. The structure of the channel attention mechanism is shown in
Figure 4, and the final channel attention mapping expression
is shown in Formula (
2):
where
and
represent the average pooling feature and max pooling feature, respectively. These two descriptors are then transformed to a shared network to produce the proposed channel attention map
. The shared network consists of a multilayer perceptron (MLP) with one hidden layer. To reduce the number of parameters, the hidden layer size is set to R/C = r
, where R is the drop rate. After applying the shared network to each descriptor, the output feature vectors are merged using elementwise summation. ⊗ represents the sigmoid function.
is obtained by element multiplication of F and Mc(F), where
is the weighted result of F through the channel attention mechanism. The formula is shown in Formula (
3):
Spatial attention focuses on the question of where the most informative parts are located. To compute spatial attention, average pooling and max pooling are performed along the channel axis. Then, they are integrated into an efficient feature descriptor and applied to a convolutional layer to generate a spatial attention map of size R × H × W, where R, H, and W are the number of channels, height, and width of the input feature map, respectively. This process encodes locations that require attention or suppression, which is a supplement to the channel attention. The structure of the spatial attention mechanism is shown in
Figure 4. The final output spatial attention mapping expression
is shown in Formula (
4):
where the channel information of one feature map is aggregated using two pooling operations to generate two 2D maps: the size of
is
H × W, and the size of
is
H × W.
is the sigmoid function, and
is a convolution operation with a filter size of
.
In this paper, we introduced MobileNetV3-large into PSPNet in order to retain a good detection accuracy after the introduction of the lightweight network [
24]. In addition, the improved PSPNet tends to ignore the feature maps of different levels in the feature extraction stage, resulting in the loss of some image details and poor segmentation effect. We added a CBAM attention mechanism to a stage of MobileNetV3-large, and the improved MobileNetV3-large network structure is shown in
Table 1.
In this paper, in order to replace the Resnet network with MobileNetV3 in PSPNet and ensure a high detection accuracy, MobileNetV3-large with higher accuracy than MobileNetV3-small was added [
24]. Then, to solve the problem that the improved PSPNet tends to ignore the feature maps of different levels in the feature extraction stage, which leads to the loss of some image details and the poor segmentation effect, we improved MobileNetV3-large by adding a CBAM attention mechanism, and the improved network structure of MobileNetV3-large is shown in
Table 1. MobileNetV3 was divided into five stages by downsampling multiple times. As shown in
Table 1, we added a CBAM attention mechanism behind a stage on the 1st, 2nd, 3rd and 4th layers of MobileNetV3-large to improve the feature extraction ability of PSPNet. Moreover, the first column, Input, in
Table 1 represents shape changes for each feature layer of MobileNetV3. The second column, Operator, represents the block structure that each feature layer experiences. In MobileNetV3, feature extraction goes through many bneck structures. The exp size represents the number of channels in bneck after the inverse residual structure rises. #
out indicates the number of channels in a feature layer when input into bneck. SE indicates whether to add the SE attention mechanism. NL represents the type of the activation function, HS represents h-swish, and RE represents Relu.
s represents the step size used for each block structure.
2.4. Y-PNet Algorithm for Real-Time Object Detection and Image Segmentation
The original PSPNet model exhibits a high computational complexity, which is not conducive to mobile platform deployment and cannot perform real-time segmentation. This paper comprehensively considered the characteristics of YOLOv5 real-time detection and PSPNet image segmentation. The two algorithms, YOLOv5 and PSPNet, were improved and fused deeply, and a real-time object detection and image segmentation network Y-PNet was constructed whose network structure is shown in
Figure 5. The improvements over the original YOLOv5 and PSPNet are as follows:
(1) The CSPDarknet backbone extraction network of YOLOv5 was replaced by MobileNetV3 [
24], and we established a lightweight real-time detection network. The network could reduce the number of parameters in the reasoning process, improve the performance of the algorithm and the efficiency of real-time detection, and solve the problem of missed detection.
(2) In order to make the segmentation ability more efficient and improve the accuracy of the feature extraction of PSPNet, a CBAM [
25] was added after stages 1, 2, 3, and 4 of MobileNetV3. Then, the original Resnet50 network of PSPNet was replaced with the modified MobileNetV3 to build a lightweight semantic segmentation network.
By improving the traditional model to ensure that the Y-PNet real-time object detection and image segmentation algorithm had a high detection rate, the accuracy of the detection results met the high-efficiency and high-quality requirements of assembly-line antler mushroom size classification. The network detection process was as follows:
The Y-PNet real-time object detection and image segmentation network obtained the captured real-time video via a camera’s IP address. Once the camera had obtained the real-time video of the antler mushroom transported by the factory assembly line, the video image was transmitted to the network. First, the real-time video is processed by the Y-PNet first-stage network, YOLOv5. When the network detected an antler mushroom, it automatically identified the antler mushroom and obtained the location and coordinates of the antler mushroom in the video. Then, when the mushroom reached a fixed position, the obtained information was passed to the Y-PNet second-stage network, the PSPNet semantic segmentation algorithm. At this stage, the contour of the antler mushroom image was segmented, and the overall pixel area of the antler mushroom was calculated to represent the real area of the antler mushroom, which was basic for grading.
The antler mushrooms of different sizes provided by the antler mushroom production factory were divided into three grades: I, II, and III. The algorithm in this paper was used to detect the pixel area corresponding to the three different grades of antler mushrooms at a fixed distance. The size evaluation criterion for antler mushrooms corresponding to the grading network (Y-PNet) was obtained: when the pixel area of the entire mushroom body was greater than or equal to 50,000, the antler mushroom maturity was defined as level I; when the pixel area was between 30,000 and 50,000, the maturity was defined as level II; and the pixel area below 30,000 was defined as class III. With this evaluation criterion, the mushroom was segmented, the average area of the bottled mushroom was output, and different mushroom size grades were defined according to the detected pixel average area size.
3. Dataset Construction and Evaluation Criterion of Algorithm
3.1. Dataset Processing and Training
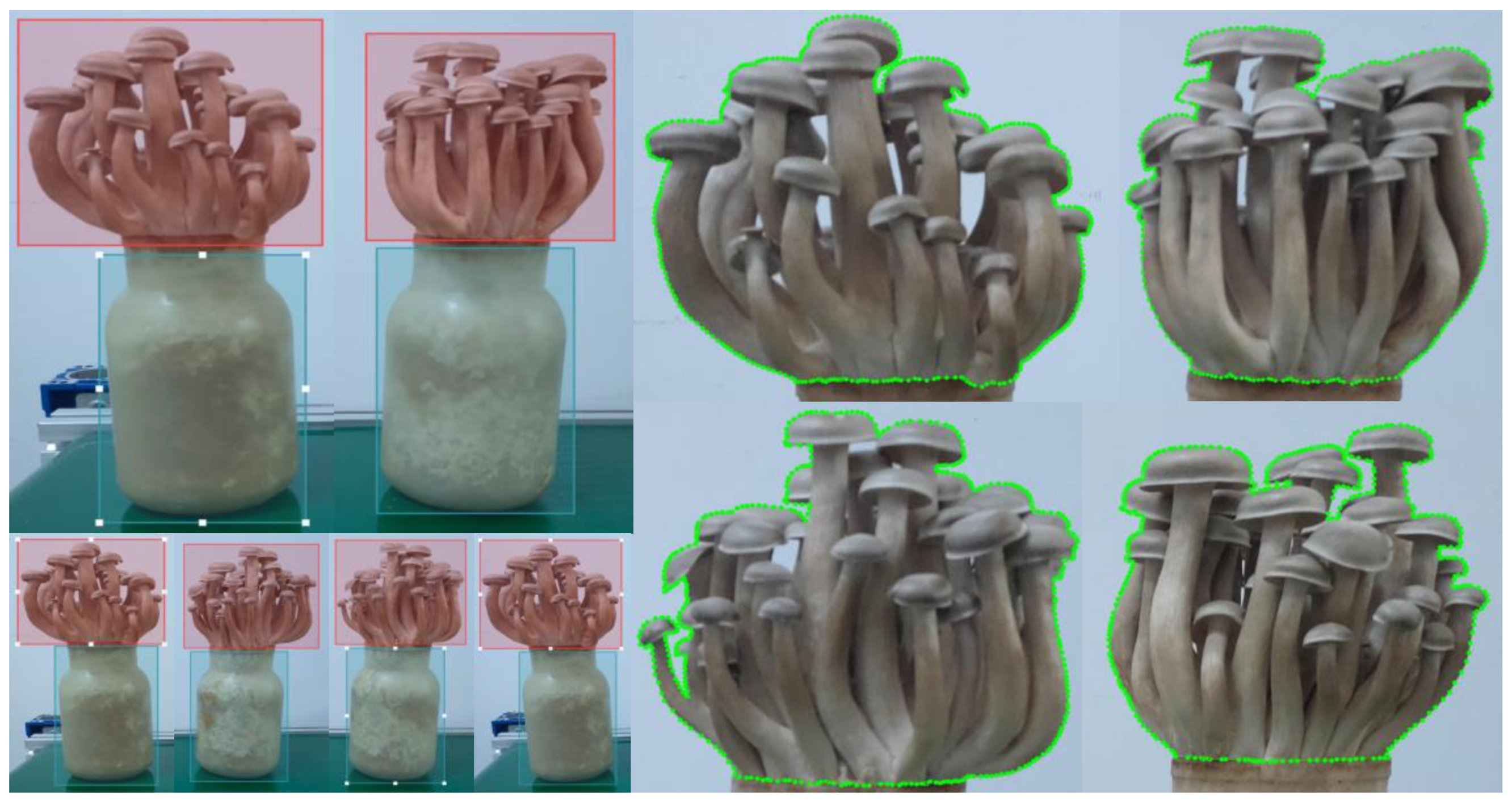
The image data used in this paper were collected from the antler mushroom production base of Shandong Nongfa Fungi Industry Group Ltd, Dongying City, Shandong Province, China. Photos were taken on 11 March 2022 using a Hikvision MV-CE200-10GC industrial camera. Bottled antler mushrooms were shot at a fixed distance of 0.3–0.4 m from the camera, and the images were saved in JPG format with a resolution of 5472 pixels × 3672 pixels. A total of 2359 pictures of bottled antler mushrooms of different sizes were taken. To reduce the sensitivity of the network model to the image and the problem of unbalanced samples, we used flipping, rotating, cropping, mirroring, and other methods to enhance the data and improve the model generalizability, and we finally obtained 8351 sample images of bottled antler mushrooms.
The LabelMe tool was used to label each image manually. To train the YOLOv5 object detection algorithm in the first stage, the rectangular annotation tool was used to mark the dataset of the bottle body and antler mushroom body. To train the second stage, the PSPNet semantic segmentation network model, the polygon annotation tool was used to label the dataset, and the labels were divided into the antler mushroom body and background. Finally, we divided the two sets into a training set, validation set, and test set at a ratio of 7:2:1. The training set was used for model training, the validation set was used for real-time feedback on the model training during the training process, and the test set was used to evaluate the model performance. The number of samples of each dataset is shown in
Table 2, and the annotation example diagram of the dataset is shown in
Figure 6.
The computer configuration of the experimental platform was as follows: the CPU was an Intel Core i7-8700, the operating system was Windows 10, the Python version was 3.8.8, and the deep learning framework and version were PyTorch 1.10.1. We set the training epochs to 300, the learning rate to 0.01, and the batch size to 16. During training with the mosaic data enhancement method, images were randomly cropped and scaled, and then randomly arranged and spliced to form a single image. While enriching the dataset, a small sample target was added to improve the training speed of the network. Concurrently, the training set and the validation set were used for cross-validation after each iteration so that problems in the training process could be identified and solved quickly to reduce computation time. Finally, the model performance was tested using the test set.
3.2. Different Evaluation Criteria
To verify the effectiveness of the proposed method, different evaluation criteria were used for the two deep learning algorithm models. First, for the YOLOv5 single-stage object detection algorithm, the precision, recall, and mean average precision (mAP) were used as evaluation criteria to evaluate the model, which included the following three aspects [
31]:
(1) Precision is the proportion of correctly classified samples to all samples:
(2) Recall is the proportion of correctly classified positive classes in all positive classes:
(3) The mean average precision (mAP) is the mean of the average precision of all categories in the dataset:
The number of true positives (TP) is the number of positive samples that are detected correctly; the number of true negatives (TN) is the number of negative samples that are detected correctly; the number of false-positives (FP) is the number of positive samples that are detected incorrectly; the number of false negatives (FN) is the number of false negative samples that are detected; and m is the number of samples in the test set.
For the PSPNet semantic segmentation algorithm, the model performance was evaluated from four perspectives: mean pixel accuracy (MPA), mean intersection over union (MIoU), pixel accuracy (PA), and training time. The relevant formulae are as follows:
(1) MPA is the average pixel accuracy of all classes in the image, and Formula (
8) is as follows:
(2) The mean intersection over union (MIoU) is the average of the accumulated IoU values of each class of image pixels, as shown in Formula (
9):
where
k is the number of classes of pixels;
is the number of pixels that are real and predicted to be class
i;
is the number of pixels that are real class
i but predicted to be class
j; and
is the number of pixels that are real class
j but predicted to be class
i.
(3) The pixel accuracy (PA) is the ratio of correctly marked pixels to the total pixels and Formula (
10) is shown as follows:
(4) The training time is the time from the start to the end of the training, and the running speed of the model can be evaluated and calculated in minutes (min).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}