
Assessing the Sentinel-2 Capabilities to Identify Abandoned Crops Using Deep Learning

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
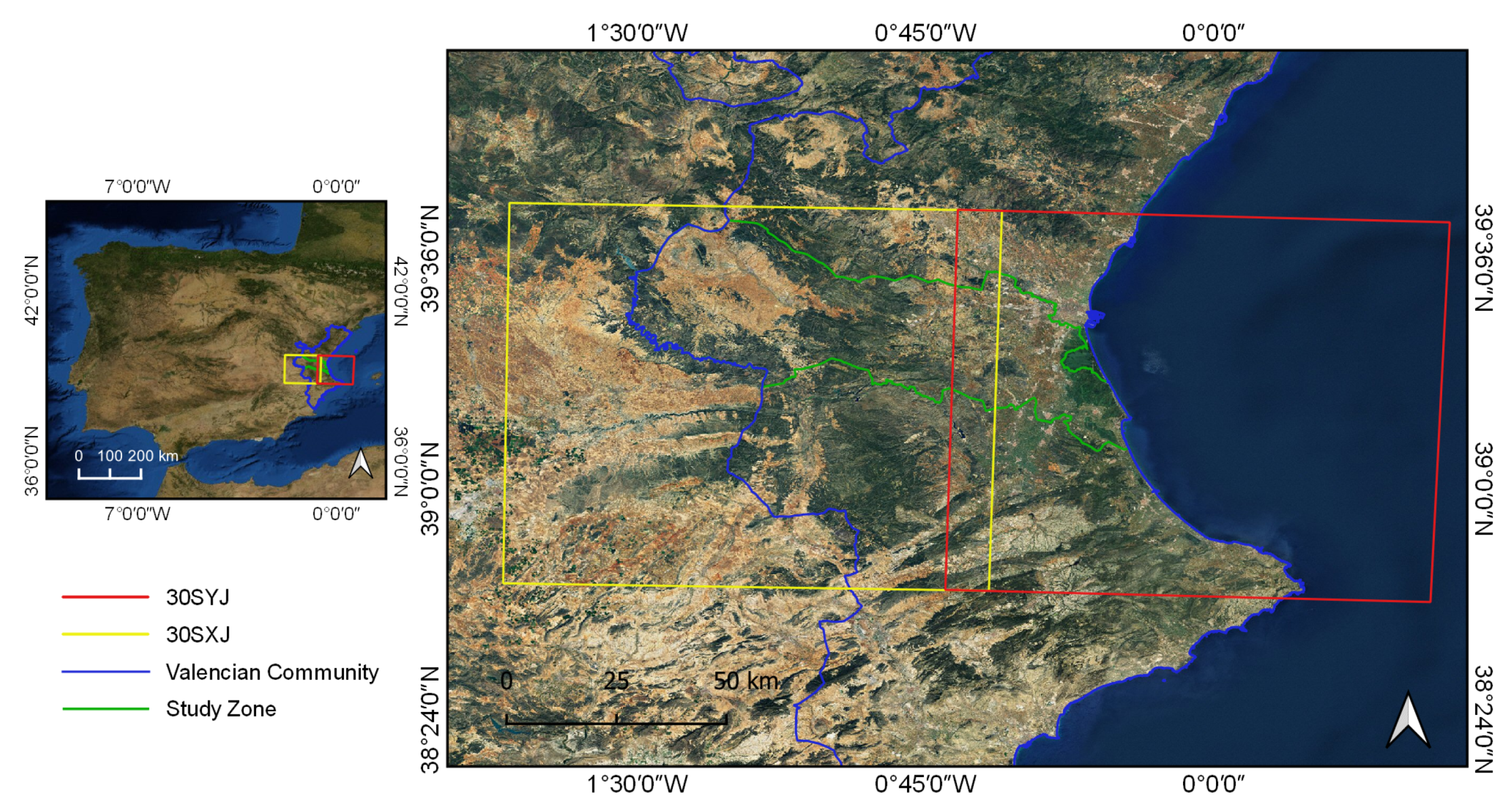
2.1. Study Area and Ground Truth
2.2. Sentinel-2 Data
2.3. Spectral Indices
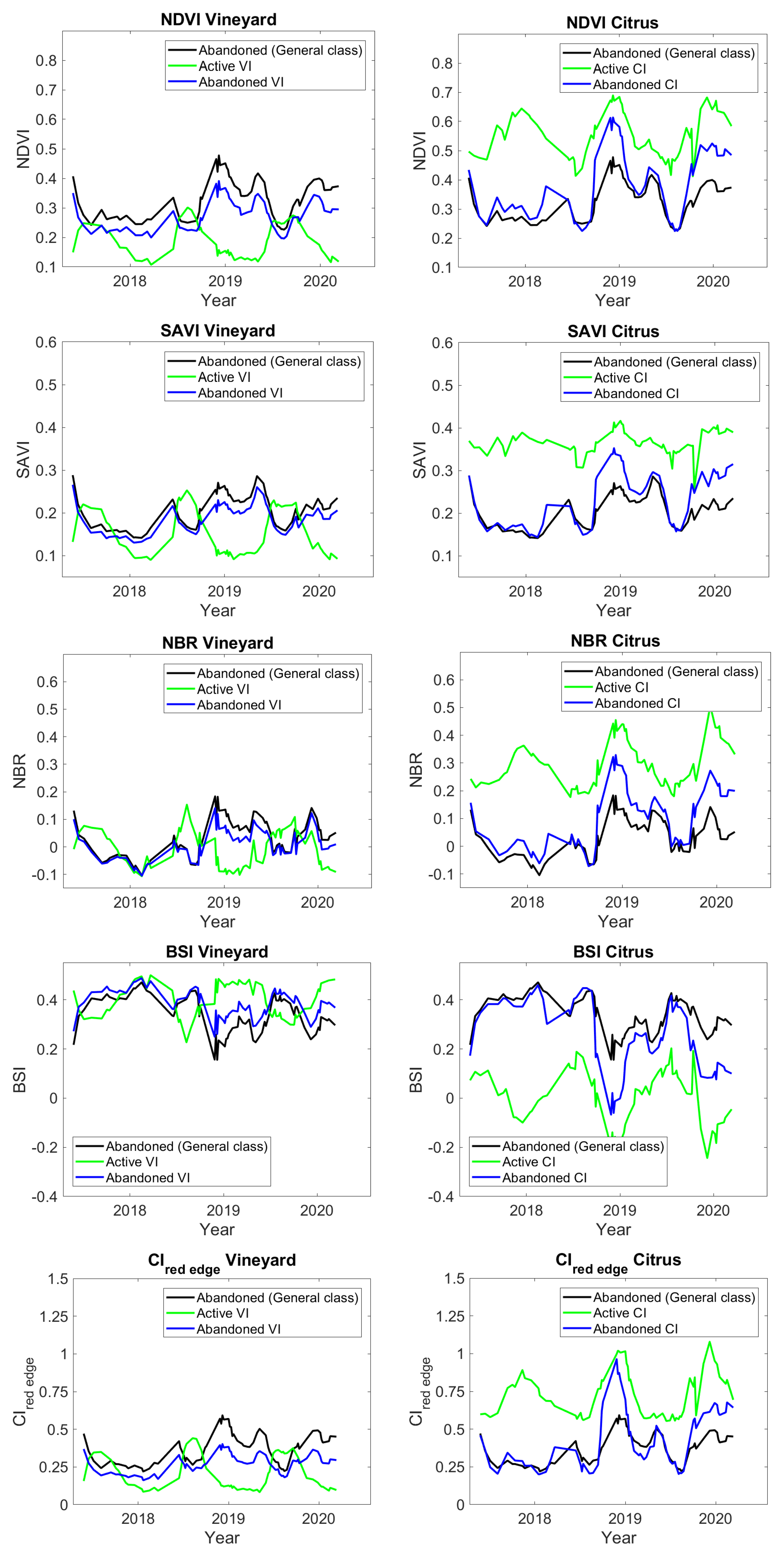
- Normalized Vegetation Difference Index (NDVI). This vegetation index is a normalized difference between near-infrared and red reflectance:It is sensitive to chlorophyll content, water content and vegetation fraction cover. Thus, it has been used for widely for remote sensing applications, including vegetation phenology monitoring [14], vegetation productivity, and also NDVI time series had been used before to distinguish cropland abandonment from fallow [8].
- Soil Adjusted Vegetation Index (SAVI) [15]. In scenarios with intermediate levels of vegetation coexisting with soil, the SAVI minimizes the brightness produced by the latter. SAVI is defined asand allows to describe a wider range of canopies with intermediate vegetation, by introducing the soil correction factor L, which depends on the fractional vegetation cover. In this work, L was set to , an intermediate value that works well in the majority of scenarios.
- Normalized Burn Ratio (NBR) [16]. This SI is built as a normalized difference between near-infrared and short wave infrared reflectance:NBR is related with the vegetation water content. It has been widely used in wildfire severity mapping, but recently it has been also used to detect drastic reductions in vegetation biomass, for example when crops are harvested.
- Bare Soil Index (BSI) [17]. This spectral index results from a combination of NDVI and Normalized Built, which is a bare soil index. In terms of the bands of Sentinel-2,BSI varies from −1 to 1, taking higher values where there is higher soil bareness.
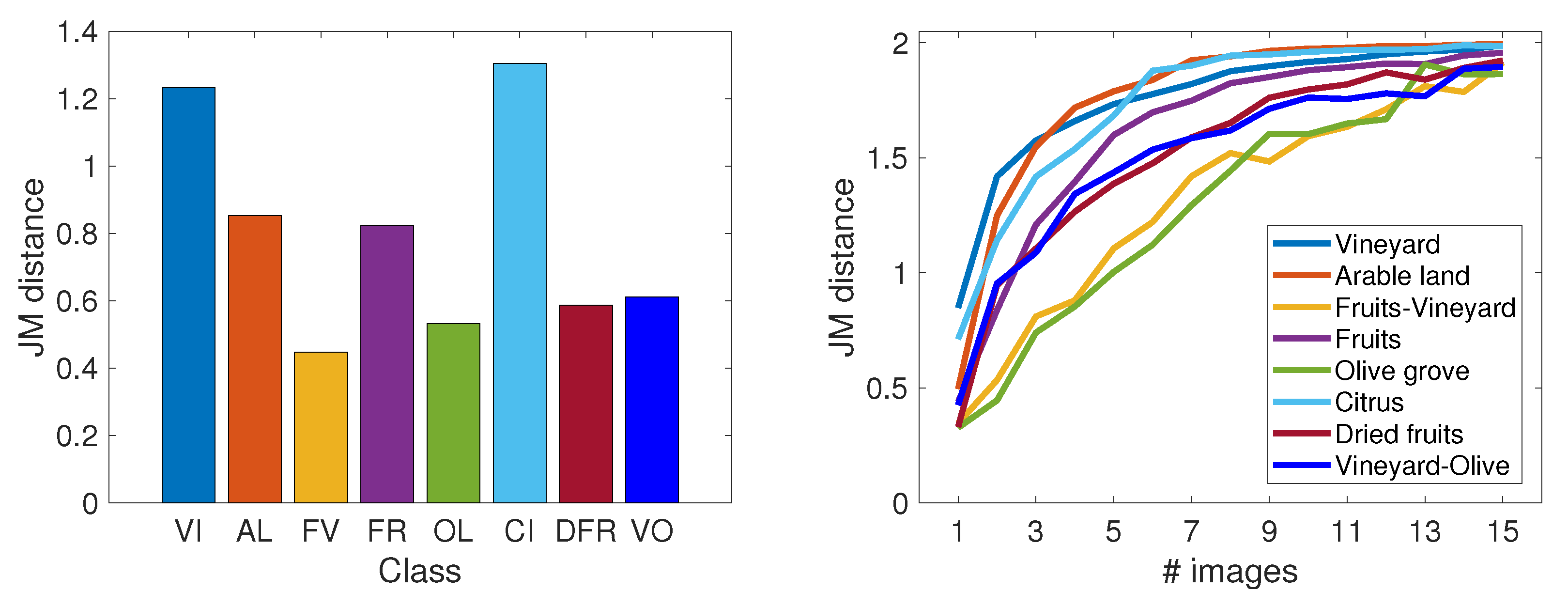
2.4. Interclass Separability
2.5. Machine Learning and Deep Learning
- One entry layer containing the 67 Sentinel-2 images with 13 predictors.
- Two layers of neurons with 100 hidden units, each one followed by a 50% dropout layer to avoid overfitting.
- One fully connected layer connecting the activation functions from the hidden units to the following layer.
- One softmax layer that computes the probability assigned by the network for each class.
- Output layer with the final predictions.
2.6. Experiments
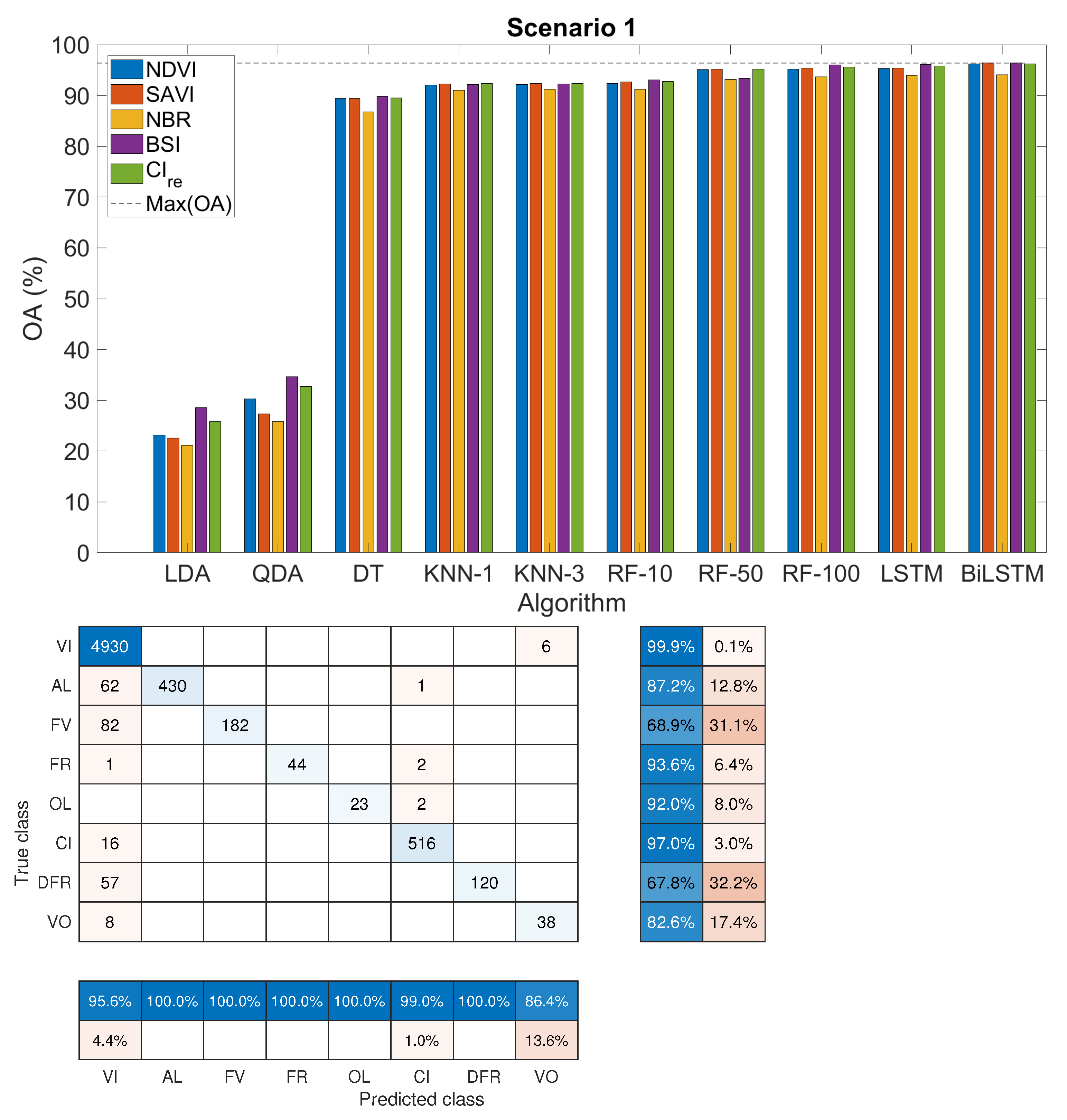
- Scenario 1: we considered only the eight subclasses for the abandoned parcels. This problem is related to the ability to identify the former crop type of the abandoned field.
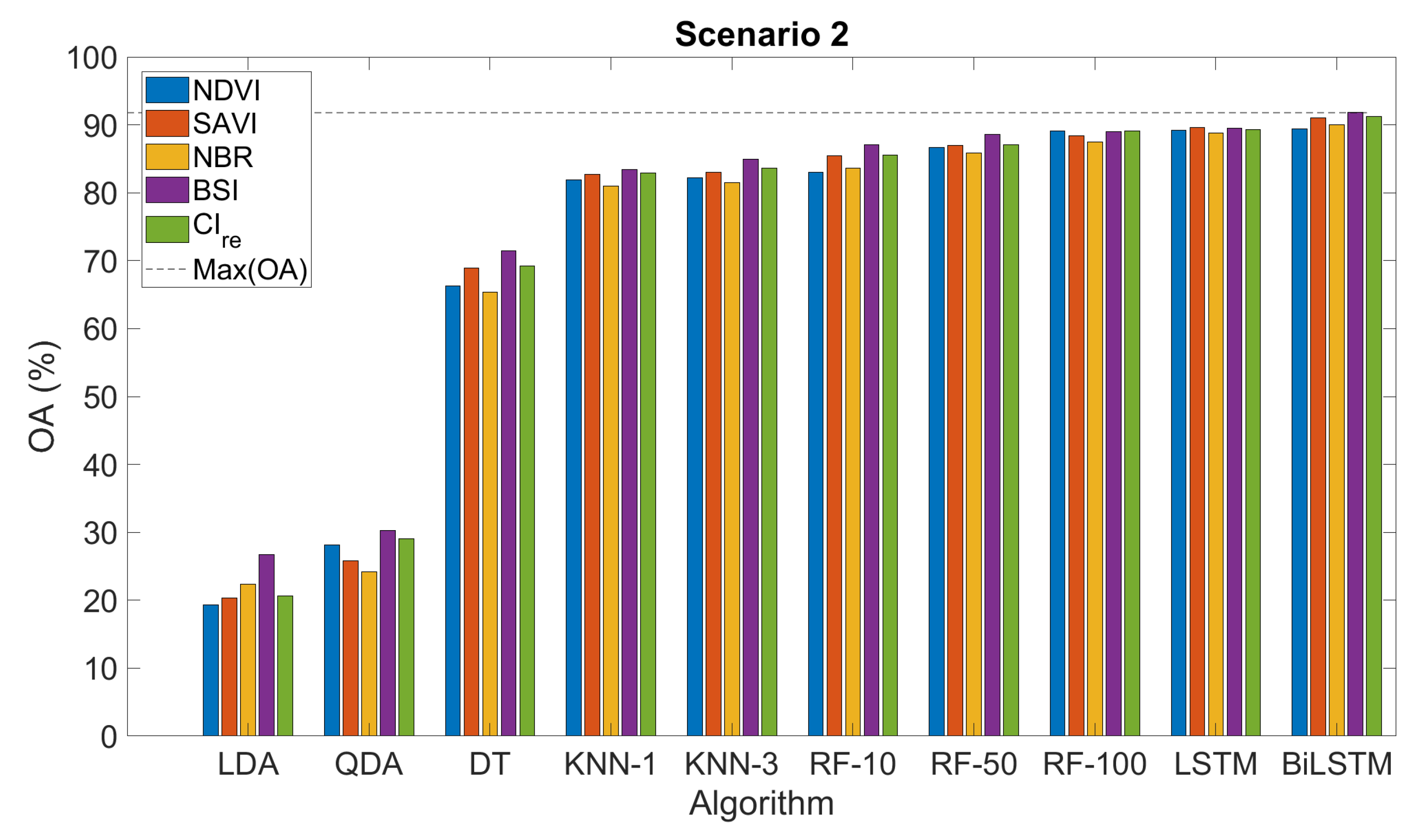
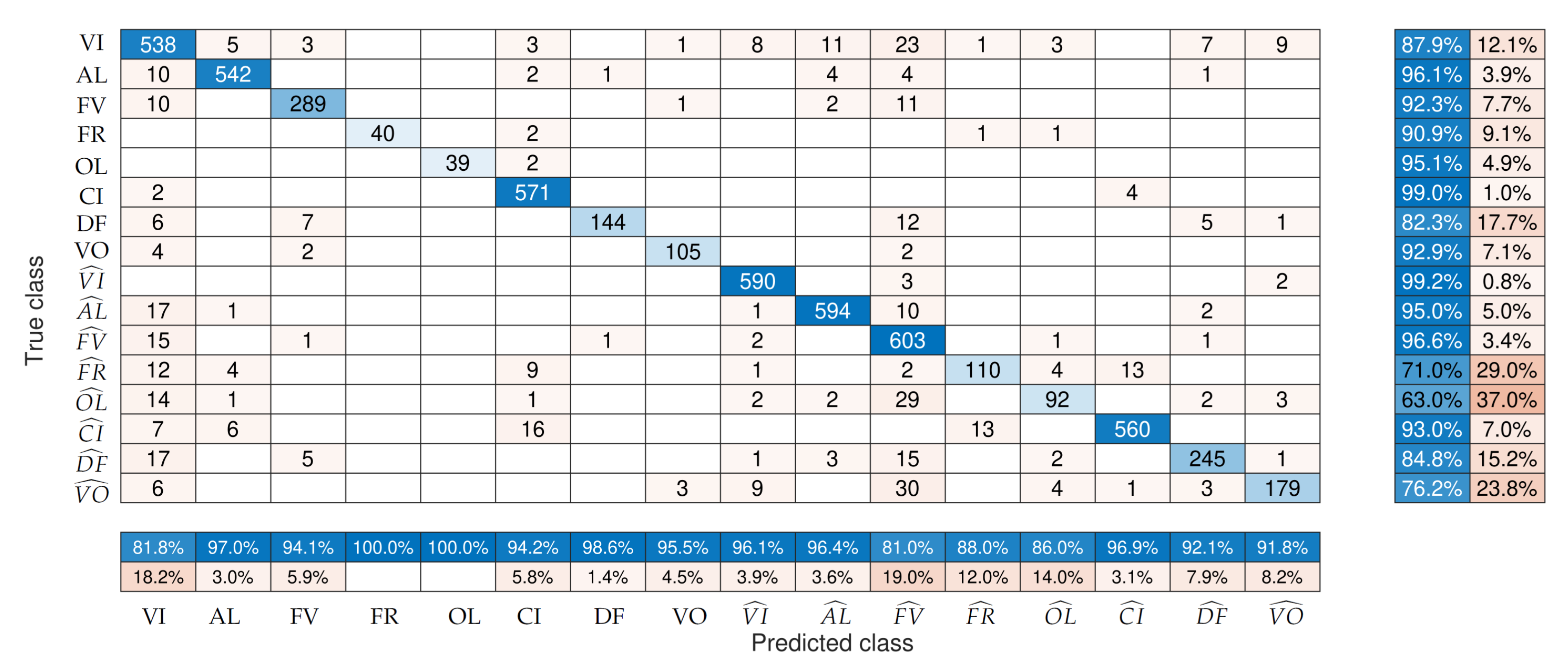
- Scenario 2: we considered all classes, i.e., eight classes of active parcels and their respective eight classes of abandoned fields. This is on paper the hardest scenario, where we aimed to distinguish abandoned from active cropland and distinguish every crop type.
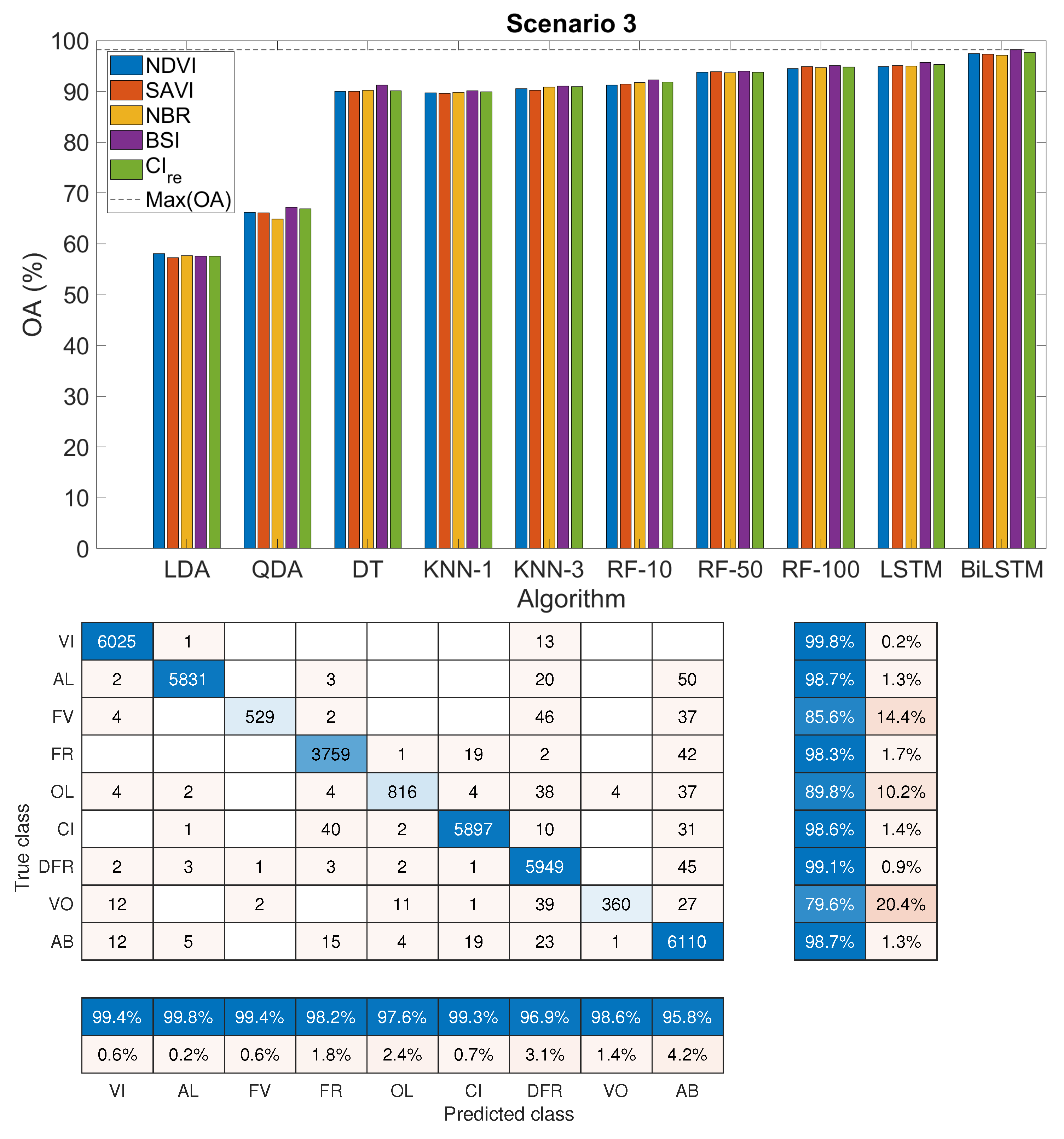
- Scenario 3: we considered eight classes of active land and one major class containing all the abandoned samples.
3. Results
3.1. Spectral Indices Time Series
3.2. Separability
3.3. Classification Accuracy
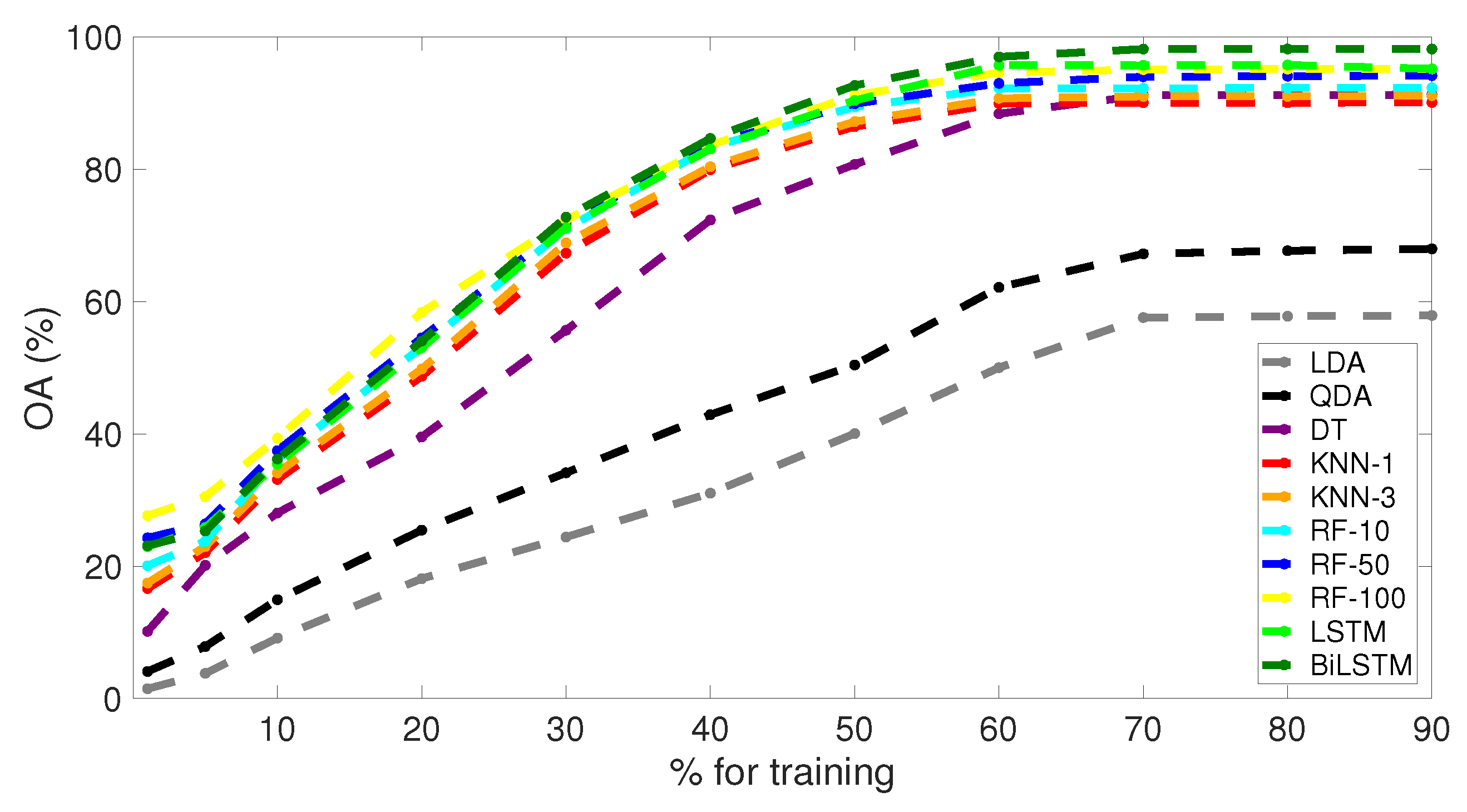
3.4. Effect of Dataset Training Size
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- European Union. Commission Implementing Regulation (EU) No 1306/2013 of the European Parliament and of the Council of 17 December 2013 on the financing, management and monitoring of the common agricultural policy and repealing Council Regulations (EEC) No 352/78, (EC) No 165/94, (EC) No 2799/98, (EC) No 814/2000, (EC) No 1290/2005 and (EC) No 485/2008. Off. J. Eur. Union 2013, 56, 1–59. [Google Scholar]
- European Union. Commission Implementing Regulation (EU) 2018/746 of 18 May 2018 amending Implementing Regulation (EU) No 809/2014 as regards modification of single applications and payment claims and checks. Off. J. Eur. Union 2018, 61, 1–7. [Google Scholar]
- Estrada, J.; Sánchez, H.; Hernanz, L.; Checa, M.J.; Roman, D. Enabling the Use of Sentinel-2 and LiDAR Data for Common Agriculture Policy Funds Assignment. ISPRS Int. J. Geo-Inf. 2017, 6, 255. [Google Scholar] [CrossRef] [Green Version]
- Sitokonstantinou, V.; Papoutsis, I.; Kontoes, C.; Lafarga Arnal, A.; Armesto Andrés, A.P.; Garraza Zurbano, J.A. Scalable parcel-based crop identification scheme using Sentinel-2 data time-series for the monitoring of the common agricultural policy. Remote Sens. 2018, 10, 911. [Google Scholar] [CrossRef] [Green Version]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Sánchez-Ruíz, S.; Gilabert, M.A. A copernicus Sentinel-1 and Sentinel-2 classification framework for the 2020+ European common agricultural policy: A case study in València (Spain). Agronomy 2019, 9, 556. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Prishchepov, A.V.; Kuemmerle, T.; Bleyhl, B.; Buchner, J.; Radeloff, V.C. Mapping agricultural land abandonment from spatial and temporal segmentation of Landsat time series. Remote Sens. Environ. 2018, 210, 12–24. [Google Scholar] [CrossRef]
- Foerster, S.; Kaden, K.; Foerster, M.; Itzerott, S. Crop type mapping using spectral–temporal profiles and phenological information. Comput. Electron. Agric. 2012, 89, 30–40. [Google Scholar] [CrossRef] [Green Version]
- Estel, S.; Kuemmerle, T.; Alcántara, C.; Levers, C.; Prishchepov, A.; Hostert, P. Mapping farmland abandonment and recultivation across Europe using MODIS NDVI time series. Remote Sens. Environ. 2015, 163, 312–325. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; Romero-Soriano, A.; Gatta, C.; Camps-Valls, G.; Lagrange, A.; Le Saux, B.; Beaupere, A.; Boulch, A.; Chan-Hon-Tong, A.; Herbin, S.; et al. Processing of extremely high-resolution Lidar and RGB data: Outcome of the 2015 IEEE GRSS data fusion contest—Part A: 2-D contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5547–5559. [Google Scholar] [CrossRef] [Green Version]
- Rußwurm, M.; Körner, M. Multi-temporal land cover classification with long short-term memory neural networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 551. [Google Scholar] [CrossRef] [Green Version]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Ruiz, L.; Almonacid-Caballer, J.; Crespo-Peremarch, P.; Recio, J.; Pardo-Pascual, J.; Sánchez-García, E. Automated classification of crop types and condition in a mediterranean area using a fine-tuned convolutional neural network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1061–1068. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Izquierdo-Verdiguier, E.; Atzberger, C.; Camps-Valls, G.; Gilabert, M.A. Understanding deep learning in land use classification based on Sentinel-2 time series. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef]
- Reed, B.C.; Brown, J.F.; VanderZee, D.; Loveland, T.R.; Merchant, J.W.; Ohlen, D.O. Measuring phenological variability from satellite imagery. J. Veg. Sci. 1994, 5, 703–714. [Google Scholar] [CrossRef]
- Huete, A. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Key, C.H.; Benson, N.C. Landscape assessment (LA). In FIREMON: Fire Effects Monitoring and Inventory System; Gen. Tech. Rep. RMRS-GTR-164; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; Volume 164. [Google Scholar]
- Rikimaru, A.; Roy, P.; Miyatake, S. Tropical forest cover density mapping. J. Trop. Ecol. 2002, 43, 39–47. [Google Scholar]
- Gitelson, A.A.; Gritz, Y.; Merzlyak, M.N. Relationships between leaf chlorophyll content and spectral reflectance and algorithms for non-destructive chlorophyll assessment in higher plant leaves. J. Plant Physiol. 2003, 160, 271–282. [Google Scholar] [CrossRef]
- Pasqualotto, N.; D’Urso, G.; Bolognesi, S.F.; Belfiore, O.R.; Van Wittenberghe, S.; Delegido, J.; Pezzola, A.; Winschel, C.; Moreno, J. Retrieval of evapotranspiration from Sentinel-2: Comparison of vegetation indices, semi-empirical models and SNAP biophysical processor approach. Agronomy 2019, 9, 663. [Google Scholar] [CrossRef] [Green Version]
- Kailath, T. The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Marcal, A.R.; Mendonca, T.; Silva, C.S.; Pereira, M.A.; Rozeira, J. Evaluation of the Menzies method potential for automatic dermoscopic image analysis. CompIMAGE 2012, 2012, 103–108. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Sutton, C.D. Classification and regression trees, bagging, and boosting. Handb. Stat. 2005, 24, 303–329. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Löw, F.; Prishchepov, A.V.; Waldner, F.; Dubovyk, O.; Akramkhanov, A.; Biradar, C.; Lamers, J. Mapping cropland abandonment in the Aral Sea Basin with MODIS time series. Remote Sens. 2018, 10, 159. [Google Scholar] [CrossRef] [Green Version]
- Morell-Monzó, S.; Sebastiá-Frasquet, M.T.; Estornell, J. Land Use Classification of VHR Images for Mapping Small-Sized Abandoned Citrus Plots by Using Spectral and Textural Information. Remote Sens. 2021, 13, 681. [Google Scholar] [CrossRef]
- Punalekar, S.M.; Verhoef, A.; Quaife, T.L.; Humphries, D.; Bermingham, L.; Reynolds, C.K. Application of Sentinel-2A data for pasture biomass monitoring using a physically based radiative transfer model. Remote Sens. Environ. 2018, 218, 207–220. [Google Scholar] [CrossRef]
- Amin, E.; Verrelst, J.; Rivera-Caicedo, J.P.; Pipia, L.; Ruiz-Verdú, A.; Moreno, J. Prototyping Sentinel-2 green LAI and brown LAI products for cropland monitoring. Remote Sens. Environ. 2021, 255, 112168. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Xie, J.; Jonas, T.; Rixen, C.; de Jong, R.; Garonna, I.; Notarnicola, C.; Asam, S.; Schaepman, M.E.; Kneubühler, M. Land surface phenology and greenness in Alpine grasslands driven by seasonal snow and meteorological factors. Sci. Total Environ. 2020, 725, 138380. [Google Scholar] [CrossRef] [PubMed]
- Kanjir, U.; Durić, N.; Veljanovski, T. Sentinel-2 based temporal detection of agricultural land use anomalies in support of common agricultural policy monitoring. ISPRS Int. J. Geo-Inf. 2018, 7, 405. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VI | AL | FV | FR | OL | CI | DF | VO | Total | |
|---|---|---|---|---|---|---|---|---|---|
| Abandoned | 16,547 | 1619 | 812 | 159 | 86 | 1756 | 566 | 188 | 21,733 |
| Active | 20,000 | 20,000 | 2023 | 12,707 | 3083 | 20,000 | 20,000 | 1555 | 119,742 |
| Band | Central (nm) | Bandwidth (nm) | Spatial Resolution (m) |
|---|---|---|---|
| B1 | 443 | 21 | 60 |
| B2 | 492 | 66 | 10 |
| B3 | 560 | 35 | 10 |
| B4 | 665 | 31 | 10 |
| B5 | 705 | 15 | 20 |
| B6 | 740 | 15 | 20 |
| B7 | 783 | 20 | 20 |
| B8 | 842 | 106 | 10 |
| B8A | 865 | 21 | 20 |
| B9 | 945 | 20 | 60 |
| B11 | 1610 | 90 | 20 |
| B12 | 2190 | 180 | 20 |
| VI | AL | FV | FR | OL | CI | DF | VO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VI | 1.96 | 1.97 | 2.00 | 2.00 | 1.99 | 1.91 | 2.00 | 1.96 | 2.00 | 1.84 | 1.97 | 1.83 | 1.98 | 1.90 | 1.87 | |
| AL | 0.59 | 1.99 | 2.00 | 2.00 | 1.98 | 1.99 | 2.00 | 2.00 | 2.00 | 1.97 | 1.97 | 1.98 | 1.99 | 1.99 | 1.99 | |
| FV | 0.50 | 0.98 | 2.00 | 2.00 | 2.00 | 1.93 | 1.97 | 2.00 | 2.00 | 1.87 | 2.00 | 1.99 | 2.00 | 1.99 | 1.99 | |
| FR | 1.29 | 1.46 | 1.40 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | |
| OL | 0.99 | 1.24 | 1.15 | 1.18 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | |
| CI | 1.00 | 1.04 | 1.33 | 1.19 | 1.12 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 1.99 | 2.00 | 2.00 | |
| DF | 0.58 | 0.86 | 0.44 | 1.50 | 1.27 | 1.42 | 1.99 | 2.00 | 2.00 | 1.89 | 2.00 | 1.99 | 2.00 | 1.98 | 1.98 | |
| VO | 0.79 | 1.26 | 0.71 | 1.57 | 1.29 | 1.51 | 0.80 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | |
| 1.18 | 1.55 | 1.34 | 1.89 | 1.75 | 1.77 | 1.36 | 1.36 | 2.00 | 1.98 | 2.00 | 1.99 | 2.00 | 1.97 | 1.97 | ||
| 0.89 | 0.97 | 1.16 | 1.70 | 1.49 | 1.43 | 1.11 | 1.38 | 1.34 | 2.00 | 2.00 | 2.00 | 2.00 | 1.99 | 1.99 | ||
| 0.45 | 0.87 | 0.49 | 1.56 | 1.30 | 1.39 | 0.47 | 0.89 | 1.11 | 1.03 | 2.00 | 1.76 | 1.99 | 1.89 | 1.88 | ||
| 0.91 | 0.82 | 1.30 | 1.58 | 1.36 | 0.95 | 1.28 | 1.46 | 1.52 | 1.06 | 1.14 | 1.99 | 1.96 | 1.99 | 1.99 | ||
| 0.60 | 0.77 | 0.79 | 1.49 | 1.21 | 1.17 | 0.72 | 1.09 | 1.30 | 0.98 | 0.38 | 0.93 | 1.99 | 1.96 | 1.93 | ||
| 1.38 | 1.23 | 1.61 | 1.75 | 1.60 | 1.13 | 1.58 | 1.69 | 1.74 | 1.42 | 1.49 | 0.68 | 1.22 | 2.00 | 2.00 | ||
| 0.59 | 0.96 | 0.67 | 1.60 | 1.35 | 1.39 | 0.61 | 0.98 | 0.98 | 0.86 | 0.45 | 1.18 | 0.66 | 1.51 | 1.93 | ||
| 0.60 | 1.03 | 0.78 | 1.63 | 1.37 | 1.41 | 0.74 | 0.89 | 0.94 | 1.08 | 0.32 | 1.14 | 0.46 | 1.46 | 0.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Portalés-Julià, E.; Campos-Taberner, M.; García-Haro, F.J.; Gilabert, M.A. Assessing the Sentinel-2 Capabilities to Identify Abandoned Crops Using Deep Learning. Agronomy 2021, 11, 654. https://doi.org/10.3390/agronomy11040654
Portalés-Julià E, Campos-Taberner M, García-Haro FJ, Gilabert MA. Assessing the Sentinel-2 Capabilities to Identify Abandoned Crops Using Deep Learning. Agronomy. 2021; 11(4):654. https://doi.org/10.3390/agronomy11040654
Chicago/Turabian StylePortalés-Julià, Enrique, Manuel Campos-Taberner, Francisco Javier García-Haro, and María Amparo Gilabert. 2021. "Assessing the Sentinel-2 Capabilities to Identify Abandoned Crops Using Deep Learning" Agronomy 11, no. 4: 654. https://doi.org/10.3390/agronomy11040654