The dynamic and uncertain nature of the Cloud Computing environment makes the tasks scheduling problem hard to solve. Therefore, a good tasks scheduling approach should be designed and implemented in the Cloud broker to not only satisfy the QoS constraints imposed by Cloud users, but also perform good load balancing among virtual machines in order to improve the resource utilization and maximize the profit earned by the Cloud provider. However, an efficient scheduling algorithm does not depend only on the tasks set received from users, but on the resources reserved by providers for processing these tasks as well. In this situation, many issues arise regarding the variety of the tasks which require a different Quality of Service (QoS) and various resource types which may exist either in homogeneous or in heterogeneous environments. Moreover, although the cloud is usually said to offer unlimited resources and can be practically huge, the available resources still have a limit, especially in private Clouds and free Cloud services. Therefore, due to a large number of users, which increases every day and the huge amount of requests sent at the same time to the cloud, the management and execution of all these tasks at the same time require a large number of resources. Therefore, with the growing demand for Cloud Computing, energy consumption has drawn enormous attention in the research community. This is due to the number of carbon footprints generated from the information and communication technology resources such as servers, network and storage [
16]. Therefore, the foremost goal is to minimize energy consumption without compromising users’ requests. The energy consumed by these requests strongly depends on CPU utilization and resource utilization. This means that the energy consumption will be high when CPUs are not properly utilized because idle power is not effectively used. Sometimes, the energy consumption becomes high due to the heavy demand of the resources, and this may reduce the performance especially if the rented resources are not used efficiently [
17].
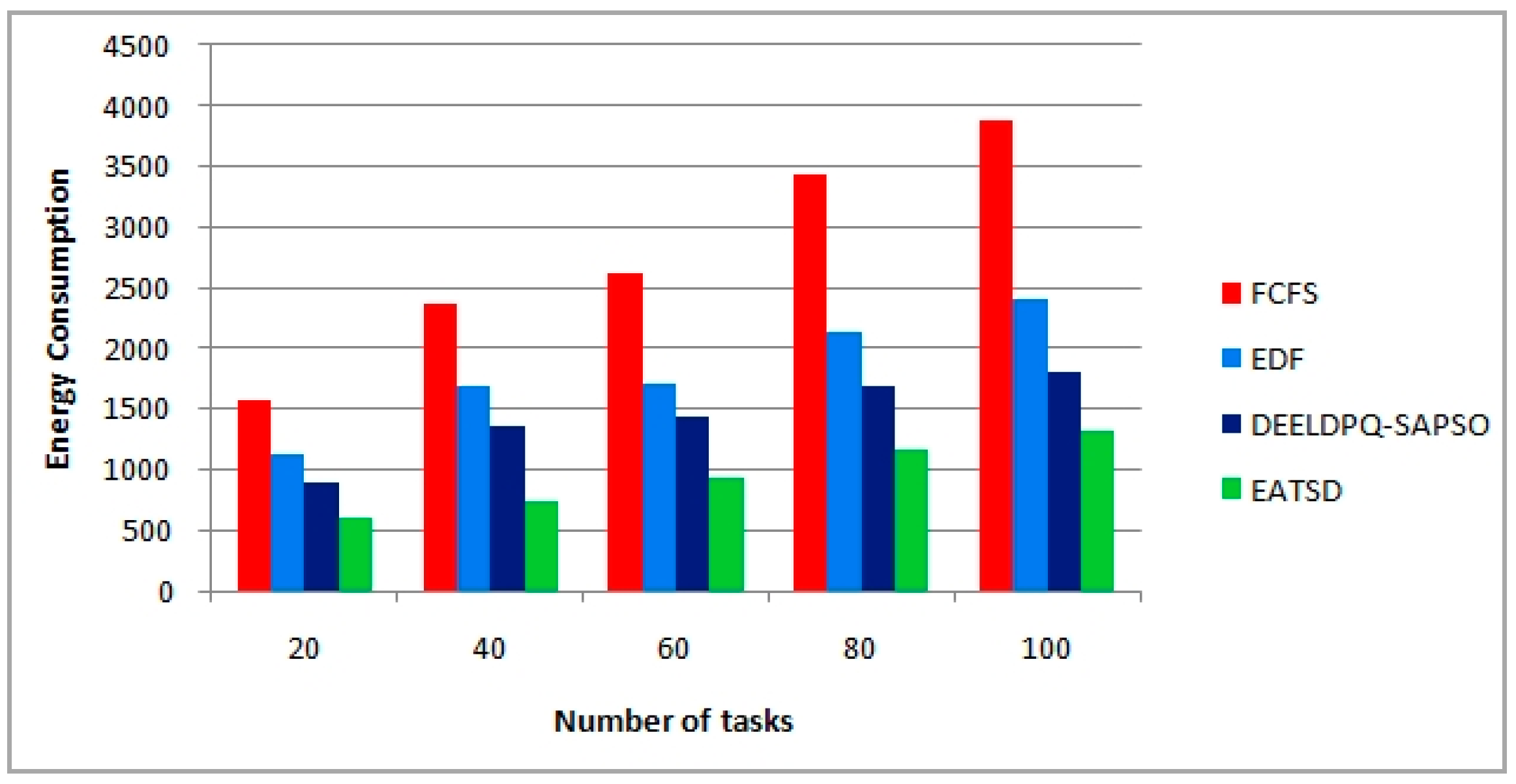
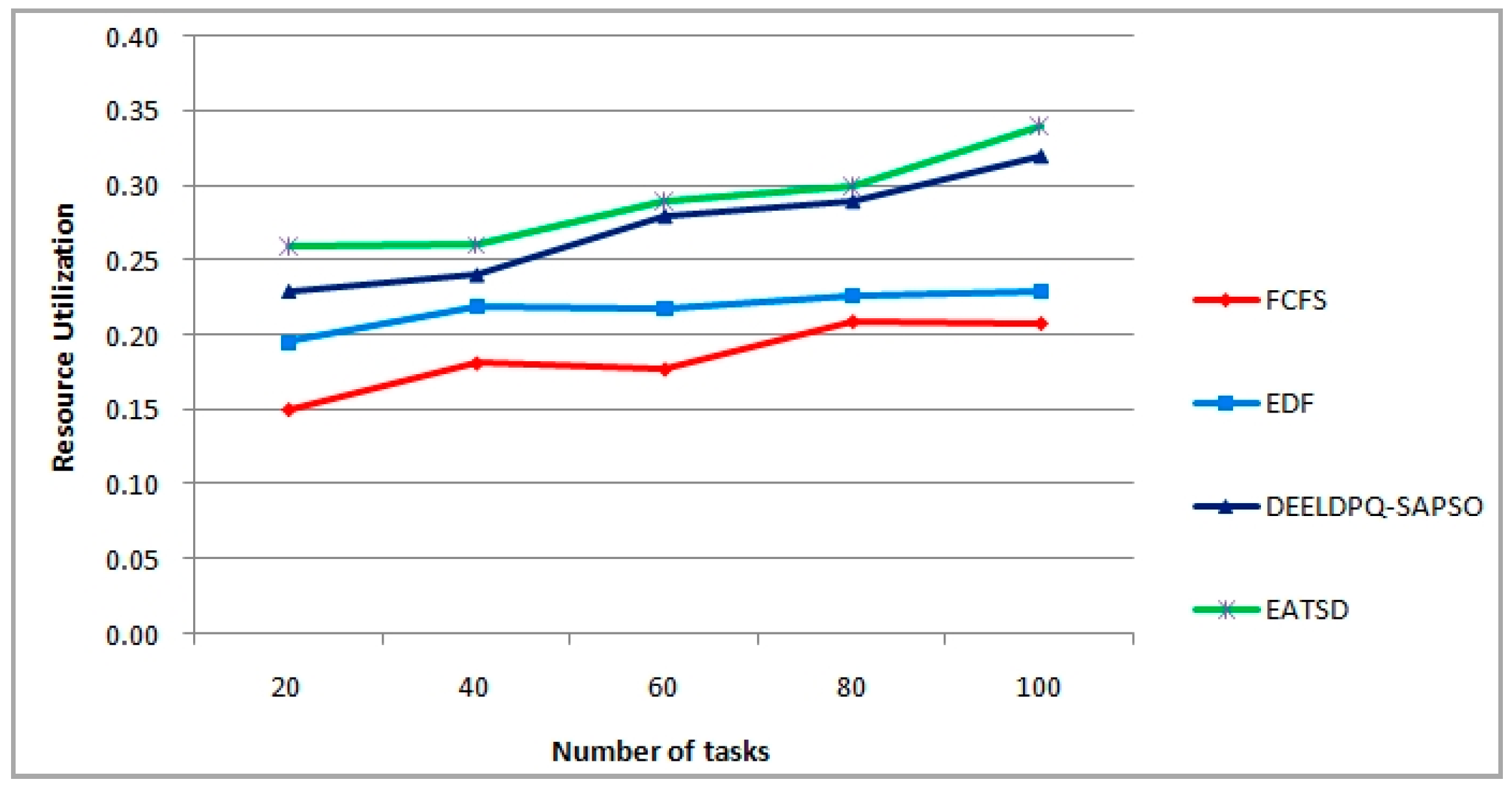
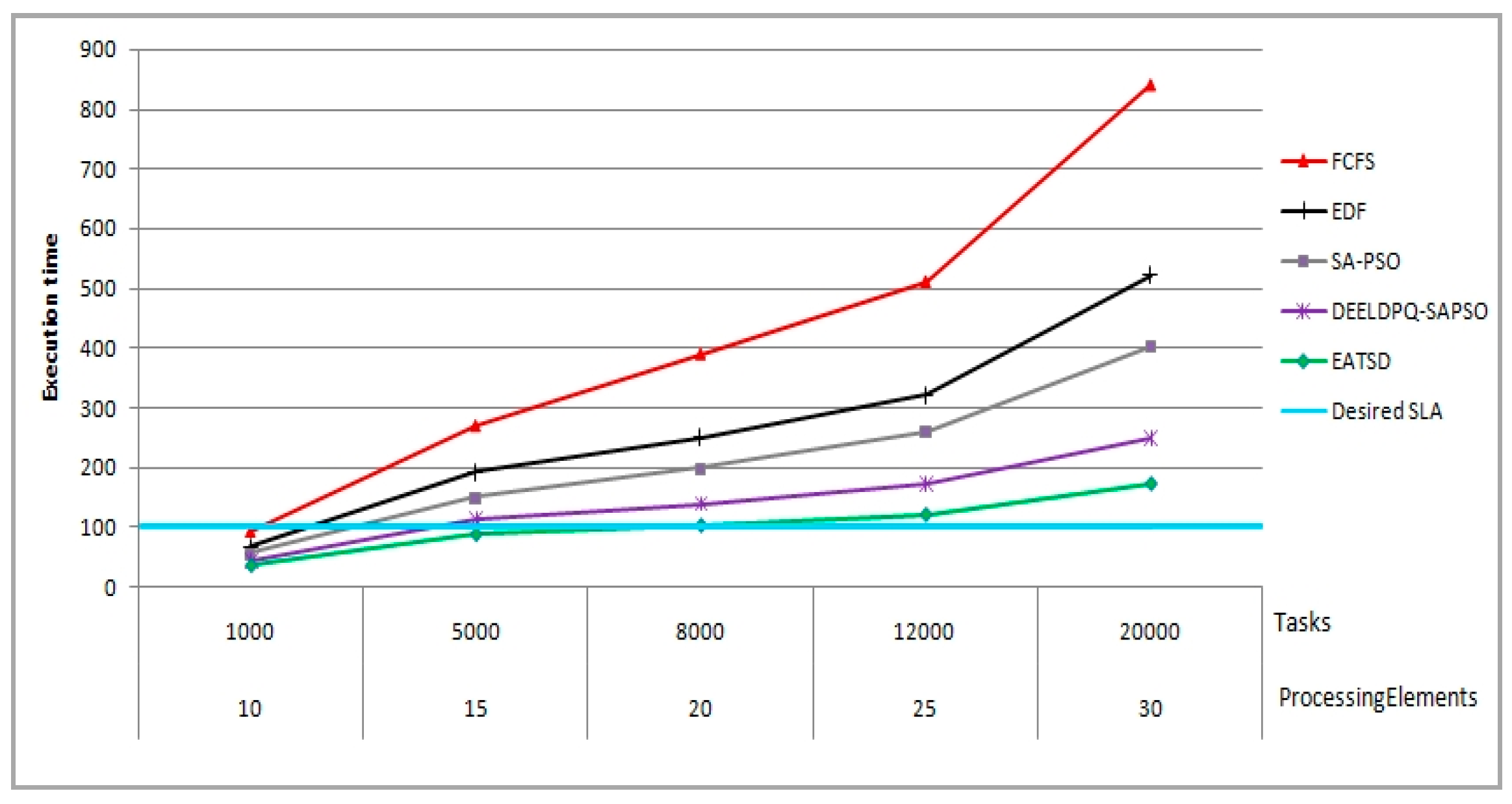
The objective function used in our work intends to minimize the makespan and energy consumption. Moreover, other metrics can be considered as measures of effectiveness such as load balancing, resource utilization and scalability. Therefore, our goal is to find a compromise between better execution time, lower energy, better resources utilization and good load balancing, because solving the problem in hand by only minimizing the energy consumption does not necessarily means that it can provide optimum scheduling in terms of other metrics such as the execution time, makespan or the resources utilization, etc. Therefore, based on these key performance parameters, the main objectives of the present work is
Our contribution in this dimension aims at achieving energy reduction for cloud providers and payment saving for cloud users, and at the same time, without introducing VM migration overhead and without compromising deadline guarantees for user tasks. Thus, the goal of our technique is to define a multi-objective function for optimal scheduling and allocation of resources by not only reducing the two-dimensional aspects such as makespan and energy under deadline constraints, but also achieving a good load balancing and high utilization optimization without overloading VMs/Hosts and degrading the performance. In order to design our model, we consider that N tasks (i.e.,
) are received from cloud users to be scheduled to M VMs (i.e.,
). We assume that the tasks are non-preemptive in nature, which means that will be executed only once in a particular VM. We assume also that the VMs are heterogeneous (i.e., VMs have different computing capabilities) [
18].
3.1.2. Energy Model
where
E(x) is the total energy consumption which can be calculated by
where
is the energy consumption produced by the task T
i running on the virtual machine V
j,
is the power needed to operate a data center,
represents the energy consumption rate of the virtual machine,
represents the maximal latency that cloud users can tolerate (e.g., users’ time constraint).
From the user perspective, our method performs efficient tasks execution within the specified deadlines. These tasks are prioritized and classified in order to reduce the number of tasks violating their deadline and also to increase the performance of the system. From the provider perspective, energy efficiency is attained by reducing energy consumption. Additionally, a good load balancing strategy can ensure maximum utilization of resources. As a result, this helps to minimize energy-related costs and prevent system performance degradation. Therefore, the proposed work tackles the energy and deadline dimension based on our previous work [
9] in which we have introduced a novel hybrid MCDM method called DEEL based on the Differential Evolution (DE) algorithm and the Multiple Criteria Decision Making (MCDM) method namely ELECTRE III. We propose a new method which intends to prioritize dynamically the tasks and schedule them to the best suitable resource selected using a hybrid meta-heuristic algorithm based on Fuzzy Logic and Particle Swarm Optimization algorithms (FLPSO) [
19]. Therefore, the priority of each task is defined based on different parameters and different levels. The parameters considered for the priority assignment are the task length (size), waiting time, burst time and deadline. These metrics are arguably the most important metrics that can meet the user’s requirements and improve overall system performances. The ELECTRE III method aims to generate a priority score for each task. After calculating all the scores, the tasks ranking is made and the tasks are sorted based on the score values in descending order. In our model, we consider different levels of priorities (Very High, High, Medium and Low) to address the task priority, the queue priority and the VM priority.
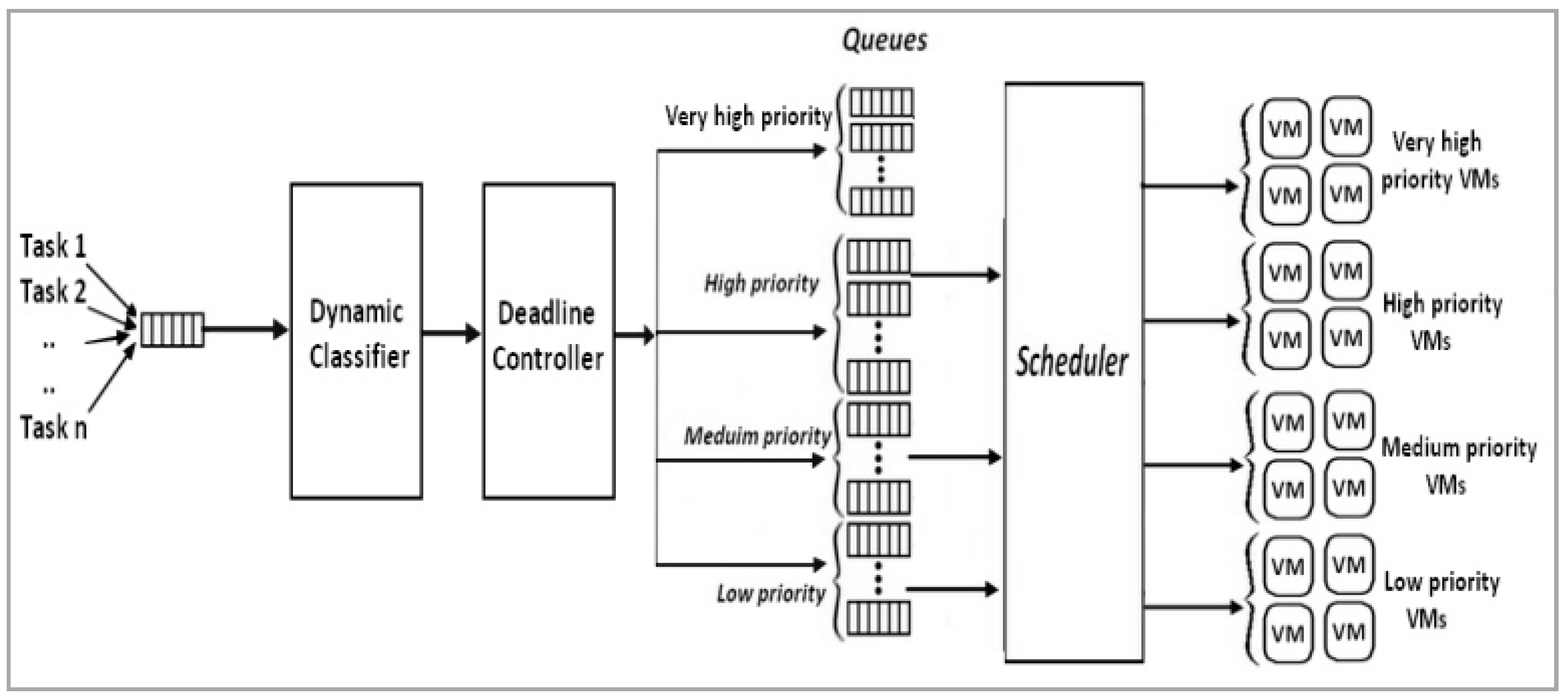
In
Figure 1, independent tasks are submitted from n users. Next, these tasks are stored in the global waiting queue according to their arrival time. Then, to manage the tasks received, we apply a Dynamic classifier algorithm. This algorithm in general aims at managing the global queue by using the DE algorithm and ELECTRE III model in order to rank and prioritize the tasks. Next, tasks classification and deadline controller are applied to dispatch and classify the ranked tasks. Based on the DEEL model, the proposed algorithm seeks to find an optimal compromise between the defined parameters such as length, deadline, waiting time and burst time. These ranked tasks are dispatched into three level priorities (Low, Medium, and High). However, some tasks have a very critical deadline and they could miss their deadline. To solve this issue, the tasks which miss their deadline should be firstly and immediately scheduled. As a result, this strategy helps to not only prioritize the tasks dynamically, but also to guarantee no deadline violation when the worst-case scenario really happens. For this, all the tasks which have a critical deadline after the classification process are considered as the most urgent tasks and are assigned as a very high priority. Therefore, this group of tasks should be immediately scheduled to VMs group with a very high priority, and then dispatched among dynamic priority-queues into four levels, such as the very high, high, medium and low priority queues respectively. The tasks can be dispatched in priority levels using static or dynamic strategy. We define three thresholds
for the tasks, queues and VMs prioritization. In this paper, these thresholds are determined by simulation. Therefore, after ranking the tasks, they are dispatched among four priority levels as follows:
Low priority level task (Lpt) =
Medium priority level task (Mpt) =
High priority level task (Hpt) =
Very High priority level task (VHpt) = , where is the expected finish time if the task i and is its deadline.
Next, to prioritize the queues, we consider four different queue priority levels, described as follows:
Low priority level queue (Lpq): each queue contains the tasks with Lpt.
Medium priority level queue (Mpq): = each queue contains the tasks with Mpt.
High priority level of queue (Hpq): = each queue contains the tasks with Hpt.
Very High priority level of queue (VHpq): = each queue contains the tasks with VHpt.
Then, for the prioritization of the virtual machines, all available VMs are sorted in ascending order based on their processing power. The same method as the prioritization of tasks is used to divide all VMs into four priority levels based on three thresholds . Thus, we create four priority levels such as Low priority level VM (Lpv), Medium priority level VM (Mpv), High priority level VM (Hpv) and Very High priority level VM (VHpv). The pseudo-code of the proposed work is described in Algorithm 1.
| Algorithm 1. pseudo-code of the proposed work |
| Create the list of tasks |
| Create the list of Hosts |
| Create the list of VMs |
| Put the tasks in the global queue |
| Calculate the priority for each task in {Ltask} using DE and ELECTRE III method |
| Get the final ranking score Pr(t) |
| Classification of tasks (tasks classifier) |
| Control the tasks’ deadline constraint (Deadline Controller) |
| Define the group of the tasks (Low, Medium, High, Very High) |
| Calculate the capacity of VMs |
| Calculate the priority for each VM |
| Get the final ranking score Pr(v) |
| Classification of VMs |
| Define the group of VMs (Low, Medium, High, Very High) |
| Get List of all queues {LQueue} by DPQ Algorithm |
| Sort the LQueue in descending order according to Pr(q) |
| For lv_pr in level_priority |
| Create {Lvms’} = {Lvms(lv_pr)} |
| For queue Q(lv_pr) inLQueue do |
| Call FLPSO algorithm |
| Keep track of thebest solution of scheduling tasks among VMs |
| End for |
| End for |
Subsequently, the DPQ algorithm is applied in order to dispatch the tasks among dynamic queues taking into consideration the ranking order and the priority group of tasks. This algorithm starts to calculate the sum of the tasks length under the same priority level, until a threshold is reached, then makes the decision to create a new queue with the same priority level as tasks under dispatching, then dispatch the appropriate tasks to the corresponding queue, and restart the calculus again until it dispatches all the tasks stored in the global priority queue. Applying the DPQ will create dynamic queues with different priority levels on the basis of a decision threshold and dispatched task priority. Moreover, in order to achieve a good load balancing among different available resources, we need to classify and prioritize the VMs in the next step, taking into consideration the computing capabilities of each VM. Therefore, a priority order is assigned for each VM based on the obtained order (e.g., the higher the order number, the higher the priority). Next, VMs are classified into different priority group in a way to have the same number of tasks group. This classification uses the obtained thresholds in the tasks grouping step to determine all VMs which can be classified and grouped in the same group priority. Then for each group priority, all queues are selected to search for the optimal mapping of tasks to the VMs. Next, a scheduling algorithm is applied based on the queue Q and VMGroup which refers to the VMs corresponding to the same group of selected queue. This process is repeated for the same queue by adding the next VMGroup i+1 to the initial VMGroup in order to increase the number of VMs. In this stage, the algorithm calculates the execution time of tasks and returns the maximum execution time among VMGroup. Then, it keeps track of the best solution for mapping the tasks to VMs. The pseudo-code of the VMs classification algorithm is presented in Algorithm 2.
| Algorithm 2. pseudo-code of VMs classification algorithm |
| Initialize Best_solution, I, j; |
| Create the list of VMs and determine all required parameters |
| Calculate the capacity of all VM. |
| Sort the list of VMs in descending order. |
| Define the priority order of each VM |
| Group VMs based on the thresholds into the Priority Group PG (high, medium, low)/(Group 1,.., Group n) |
| For each PG do |
| For each Qin LQueue(PG) |
| VMGroup = VM_ PG |
| BestSolution = CallScheduling_Algorithm (Q, VMGroup) |
| Fori = 0 to k do |
| VMGroup += VM_PCi |
| NewSolution = CallScheduling_Algorithm (Q, VMGroup) |
| If (NewSolution > Best_Solution) then |
| Best_Solution = NewSolution |
| End if |
| End for |
| End for |
| End for |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}