2.1. Literature Survey
Association rules, first introduced in 1993 [
1], are used to identify relationships among items in a database. These relationships are not based on inherent properties of the data themselves (as with functional dependencies) but rather based on the co-occurrence of the data items. The AIS algorithm was the first published algorithm developed to locate all large itemsets in a transaction database [
1]. The method generates a very large number of candidate sets and for the truly Big Data cases, it can cause the memory buffer to overflow. Therefore, a buffer management scheme is necessary to handle this problem for large databases.
The simplest and most commonly used method to reduce the number of rules is applying a threshold to the support metric. This threshold (denoted
) prevents variables with a small number of occurrences from being considered as part of any itemset and, therefore, part of any association rule. Thus, if the support of any itemset is less than the minimum support (
), we remove that itemset from any considerations of being part of some association rule [
1]. This way we eliminate rules and thus reduce the computation complexity of Equations (6) and (7) (
Section 2.2). On the other hand, the decision regarding the value of the minimum support remains questionable because eliminating itemsets of small support prevents us from discovering infrequent rules with high confidence.
Since the 1990s, a large number of algorithms have been developed and published. The following is a brief review of the literature most relevant to our method. The various algorithms presented below aim to improve accuracy and decrease the complexity and hence the execution time. However, there is usually a trade-off among these parameters.
The apriori algorithm [
2] is the most well-known association rule algorithm. This technique uses the property that any subset of a large itemset must be a large itemset. Also, it assumes that items within an itemset are kept in lexicographic order. The AIS algorithm generates too many candidate itemsets that turn out to be small. On the other hand, the apriori algorithm generates the candidate itemsets by joining the large itemsets and deleting small subsets of the previous pass. By only considering large itemsets of the previous pass, the number of candidate itemsets is substantially reduced. The authors also introduced two modified algorithms: Apriori TID and Apriori Hybrid. The Apriori TID algorithm [
2] is based on the argument that scanning the entire database may not be needed in all passes. The main difference from apriori is that it does not use the database for counting support after the first pass. Rather, it uses an encoding of the candidate itemsets used in the previous pass. The apriori approach performs better in earlier passes, and Apriori TID outperforms apriori in later passes. Based on the experimental observations, the Apriori Hybrid technique was developed. It uses apriori in the initial passes and switches later as needed to Apriori TID. The performance of this technique was also evaluated by conducting experiments for large datasets. It was observed that Apriori Hybrid performs better than apriori, except in the case when the switching occurs at the very end of the passes [
3].
The Direct Hashing and Pruning (DHP) algorithm was introduced by Park et al. [
4] to decrease the number of candidates in the early passes. DHP utilizes a hashing technique that attempts to restrict the number of candidate itemsets and efficiently generates large itemsets. These steps are designed to reduce the size of the database [
4]. An additional hash-based approach for mining frequent itemsets was introduced by Wang and Chen in 2009. It utilizes a hash table to summarize the data information and predicts the number of non-frequent itemsets [
5].
The Partitioning Algorithm [
6] attempts to find the frequent elements by partitioning the database. In this way, the memory issues of large databases are addressed because the database is divided into several components. This algorithm decreases database scans to generate frequent itemsets. However, the time for computing the frequency of the candidate generated in each partition increases. Nevertheless, it significantly reduces the I/O and CPU overheads (for most cases).
An additional method is the Sampling Algorithm [
7], where sample itemsets are taken from the database instead of utilizing the whole database. This algorithm reduces the database activity because it requires only a subsample of the database to be scanned [
7]. However, the disadvantage of this method is less accurate results. The Dynamic Itemset Counting (DIC) [
8] algorithm partitions the database into intervals of a fixed size. This algorithm aims to find large itemsets and uses fewer passes over the data in comparison to other traditional algorithms. In addition, the DIC algorithm presents a new method of generating association rules. These rules are standardized based on both the antecedent and the consequent [
8].
There are additional methods based on horizontal partition, such as works by Kantarcıoglu and Clifton [
9], Vasoya and Koli [
10], and Das et al. [
11]. These works attempt to partition the dataset, process each part separately, and then combine the results without the loss of small (with small minsupp) itemsets. Here, we have to emphasize that the horizontal partition utilized in the above-mentioned articles is not the same thing as the horizontal learning presented in our paper and is not as effective in addressing the complexity/memory requirements issues in comparison to our method.
The Continuous Association Rule Mining Algorithm (CARMA) [
12] is designed to compute large itemsets online. The CARMA [
12] shows the current association rules to the user and allows the user to change the parameters, minimum support, and minimum confidence at any transaction during the first scan of the database. It needs at most two database scans. Similar to DIC, the CARMA generates the itemsets in the first scan and finishes counting all the itemsets in the second scan. The CARMA outperforms apriori and DIC on low-support thresholds.
The frequent pattern mining algorithm (which is based on the apriori concept) was extended and applied to the sequential pattern analysis [
13], resulting in the candidate generation-and-test approach, thus leading to the development of the following two major methods:
The Generalized Sequential Patterns Algorithm (GSP) [
14], a horizontal data format-based sequential pattern mining algorithm. It involves time constraints, a sliding time window, and user-defined parameters [
14];
The Sequential Pattern Discovery Using Equivalent Classes Algorithm (SPADE) [
15], an Apriori-Based Vertical Data Format algorithm. This algorithm divides the original problem into sub-problems of substantially smaller size and complexity that are small enough to be handled in main memory while utilizing effective lattice search techniques and simple join operations [
15].
Additional techniques that should be mentioned are based on the pattern–Growth-based approaches, and they provide efficient mining of sequential patterns in large sequence databases without candidate generation. Two main pattern–growth algorithms are frequent pattern-projected sequential pattern mining (FREESPAN) [
13] and prefix-projected sequential pattern mining (PrefixSpan) [
16]. The FREESPAN algorithm was introduced by Han et al. [
17] with the objective of reducing workload during candidate subsequence generation. This algorithm utilizes frequent items and recursively transforms sequence databases into a set of smaller databases. The authors demonstrated that FREESPAN runs more efficiently and faster than an apriori-based GSP algorithm [
13]. The PrefixSpan algorithm [
16] is a pattern–growth approach to sequential pattern mining, and it is based on a divide-and-conquer method. This algorithm divides recursively a sequence database into a set of smaller projected databases and reduces the number of projected databases using a pseudo projection technique [
16]. PrefixSpan performs better in comparison to GSP, FREESPAN, and SPADE and consumes less memory space than GSP and SPADE [
16].
Another approach is the FP growth [
17], which compresses a large database into a compact frequent pattern tree (FP tree) structure. The FP growth method has been devised for mining the complete set of frequent itemsets without candidate generation. The algorithm utilizes a directed graph to identify possible rule candidates within a dataset. It is very efficient and fast. The FP growth method is an efficient tool to mine long- and short-frequency patterns. An extension of the FP growth algorithm was proposed in [
18,
19] utilizing array-type data structures to reduce the traversal time. Additionally, Deng proposed in [
20] the PPV, PrePost, and FIN algorithms, facilitating new data structures called node list and node set. They are based on an FP tree, with each node encoding with pre-order traversal and post-order traversal.
The Eclat algorithm introduced in [
21] looks at each variable (attribute, item) and stores the row number that has the value of
(list of transactions). Then, it intersects the columns to obtain a new column containing the common IDs, and so on. This process continues until the intersection yields an empty result. For example, let the original matrix be as follows (
Table 1).
Now, as a next step, if we intersect columns
and
, we obtain set
, and so on. Each time, the result is added to the matrix (see
Table 2).
In [
22,
23,
24], Manjit improved the Eclat algorithm by reducing escape time and the number of iterations via a top-down approach and by transposing the original dataset.
Refs. [
6,
11,
25] describe algorithms that partition the database, find frequent itemsets in each partition, and combine the itemsets in each partition to obtain the global candidate itemsets, as well as the global support for the items. The approaches described above reduce the computation time and memory requirements and make the process of searching for candidates simple and efficient. However, they all compare columns in their quest to find the proper itemsets.
Prithiviraj and Porkodi [
26] wrote a very comprehensive article in which they compare some of the most popular algorithms in the field. They concluded their research by creating a table that compares the algorithms by some criteria. This table (
Table 3) is presented below.
Győrödi and Gyorodi [
27] also studied some association rules algorithms. They compared several algorithms and concluded that the dynamic one (DynFP growth) is the best. Hence, in order to evaluate the performance of our horizontal learning algorithm, we compared the performance of horizontal learning to DynFP growth. The comparison is presented in
Table 4.
The comparison above clearly demonstrates that horizonal learning performs better than other algorithms that were studied.
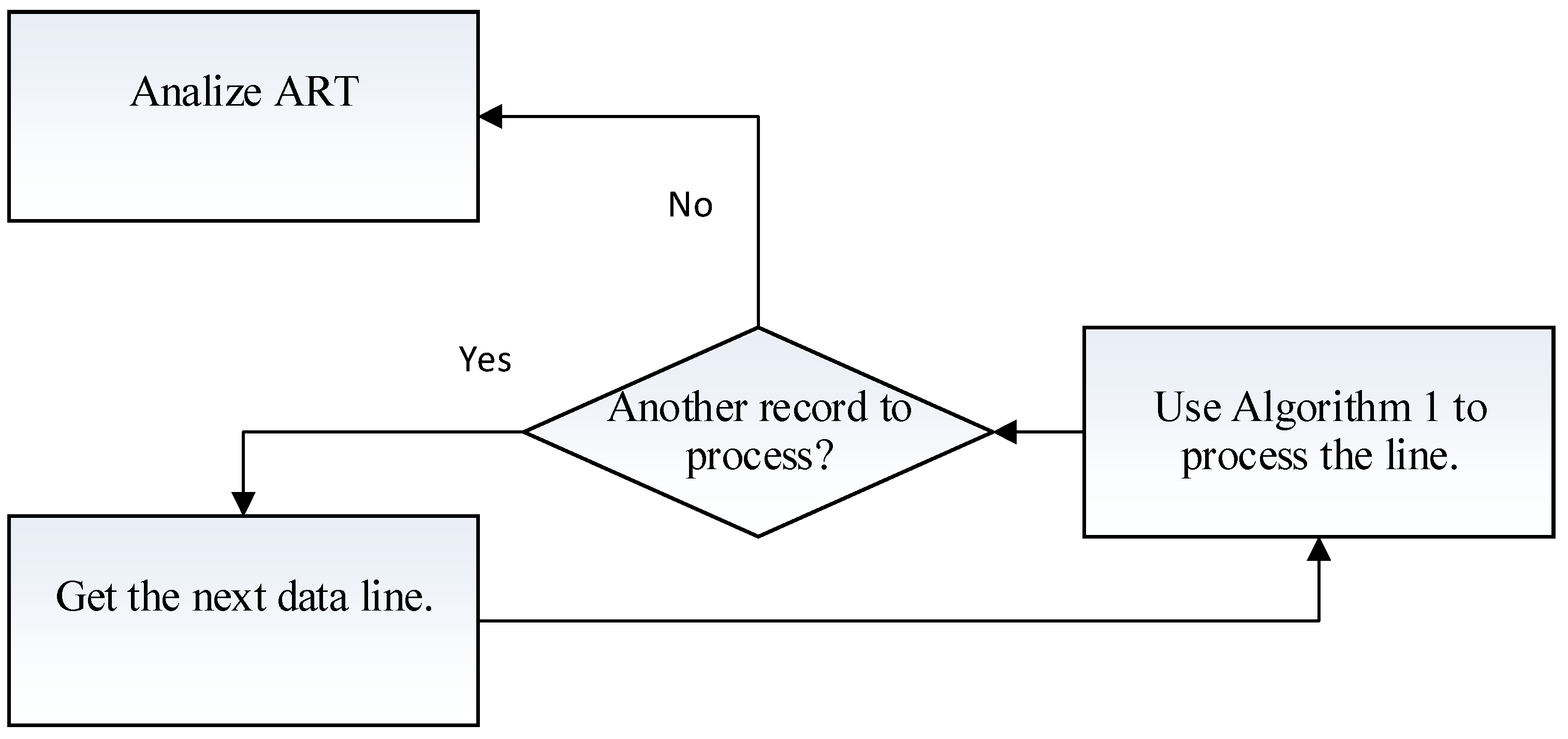
2.2. The Horizontal Learning Approach
When comparing columns, we need to count all
itemsets,
itemsets, and
itemsets. In addition, the dataset must be scanned once (each scan requires n comparisons) in order to compute the support. Let
be the traditional approach to computing the itemsets. Then, the total number of operations required for computing the itemsets is as follows:
The horizontal learning approach (HL) is quite different. We analyze each record (row) in the dataset by extracting all the possible non-zero (non-blank for non-numerical data) values in that record. The possible values are stored in temporary set . Then, we compute all possible subsets of excluding the subset. For example, let a record contain the following data . Here, we have non-zero values, so the possible subsets that can be generated will be , , and . These subsets will be stored in the special matrix , and the counters for each string will be set to . Later, we will present the formal algorithm for generating the subsets, but for simplicity, we will use a binary dataset.
Making an exaggerated (and very conservative) assumption that on average, half of the values in each row have a non-zero value and the number of variables in the dataset is
, this would yield
comparisons. Since there are
rows in the original database
, the execution time will be
. So, if we denote
as the itemset count (based on the horizontal learning approach), then
To compute the complexity of the algorithm, we define the number of variables (items) as
and the number of records as
. To be as conservative as possible, we assume that on average, the number of non-zero values in each record is
. Under this assumption, the complexity of the process is as follows:
and the memory requirement of the process is as follows:
where
is the processing complexity and
is the memory requirement. For example, for
and
, then
and
.
When comparing Equations (6) and (7), we can erase coefficient .
Figure 3 compares the two equations for
, where
is the number of variables. The
X-axis represents the number of variables, while the
Y-axis represents the number of operations needed to generate association rules (computational complexity).






{kind=link}
{kind=link}
{kind=link}
