
Proactive Ransomware Detection Using Extremely Fast Decision Tree (EFDT) Algorithm: A Case Study


Abstract
:1. Introduction
- Analyzing six articles that involve proactive monitoring models to detect and prevent ransomware attacks;
- Determining Hoeffding trees classifier as one of the tree-based classification stream data mining techniques;
- Applying three Hoeffding trees classifier algorithms to the RISS research group ransomware dataset using MOA software as a testing framework;
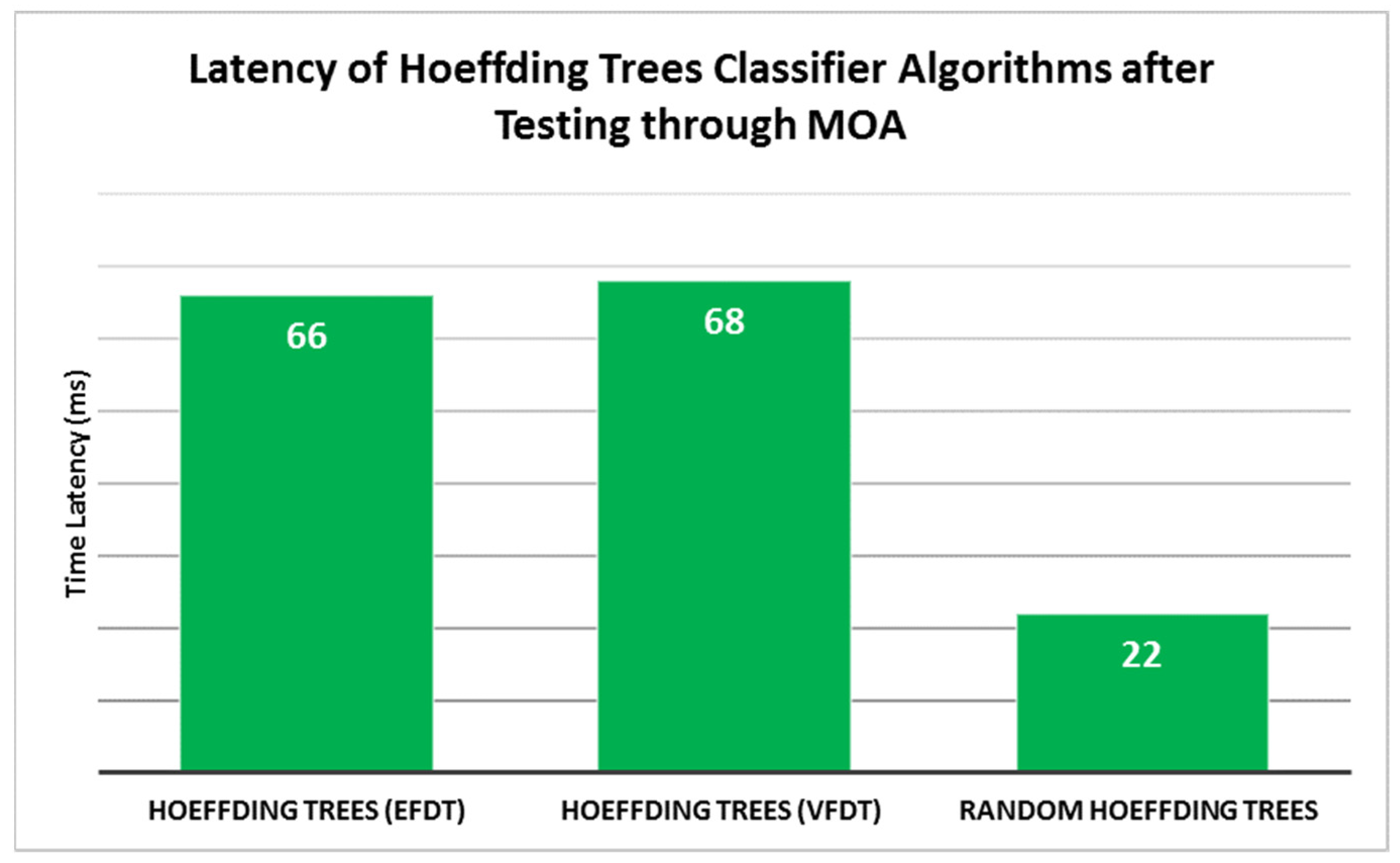
- EFDT algorithm achieves 99.41% classification accuracy as the highest result at the highest latency performance of 66 ms.
2. Related Work
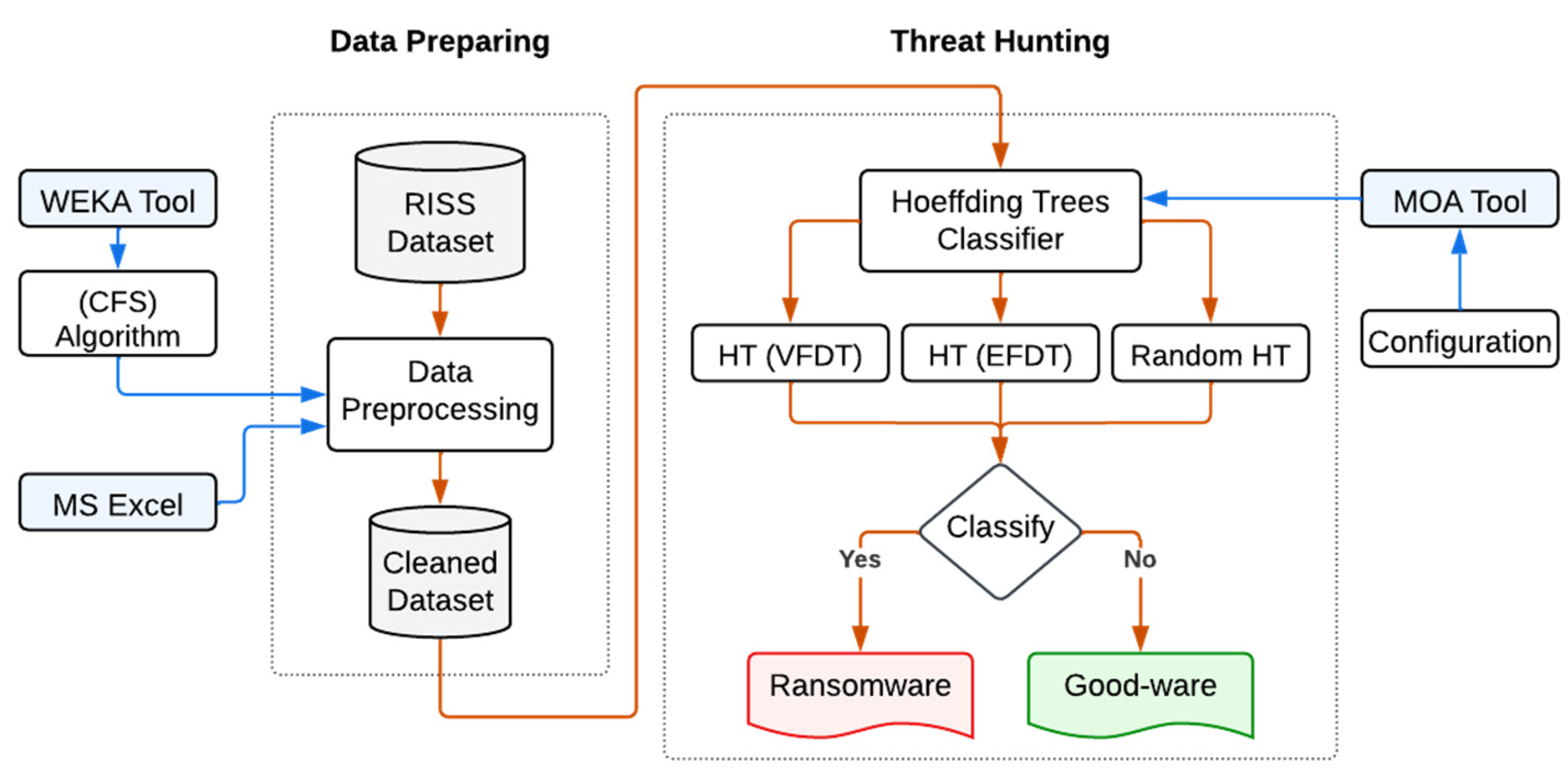
3. Methodology
3.1. Preparing the Ransomware Dataset
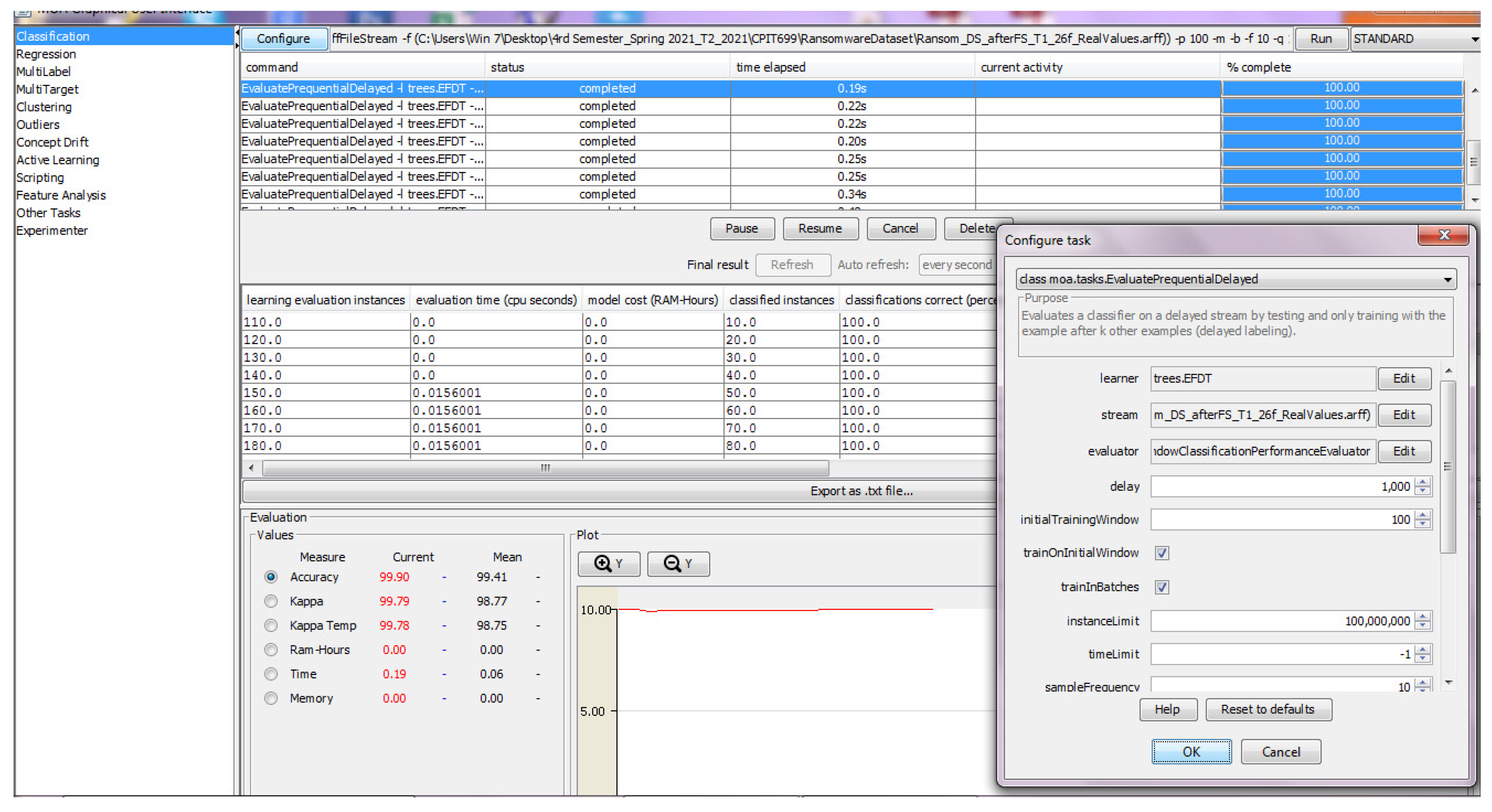
3.2. Configuring Massive Online Analysis (MOA) Software
3.3. Evaluating the Experimented Algorithms Accuracy and Latency
4. Proposed Solution
4.1. Hoeffding Trees Classifier
| Algorithm 1 Hoeffding Tree Classifier Pseudocode |
| 1: Let HT be a tree with a single leaf (the root) 2: for all training examples do 3: Sort example into leaf l using HT 4: Update sufficient statistics in l 5: Increment , the number of examples seen at l 6: if and examples seen at l not all of same class then 7: Compute for each attribute 8: Let be attribute with highest 9: Let be attribute with second-highest 10: Compute Hoeffding bound 11: if and then 12: Replace l with an internal node that splits on 13: for all branches of the split do 14: Add a new leaf with initialized sufficient statistics 15: end for 16: end if 17: end if 18: end for |
4.2. Tools
4.2.1. Microsoft Excel
4.2.2. Waikato Environment of Knowledge Analysis (WEKA)
4.2.3. Massive Online Analysis (MOA)
4.3. Dataset Preparing
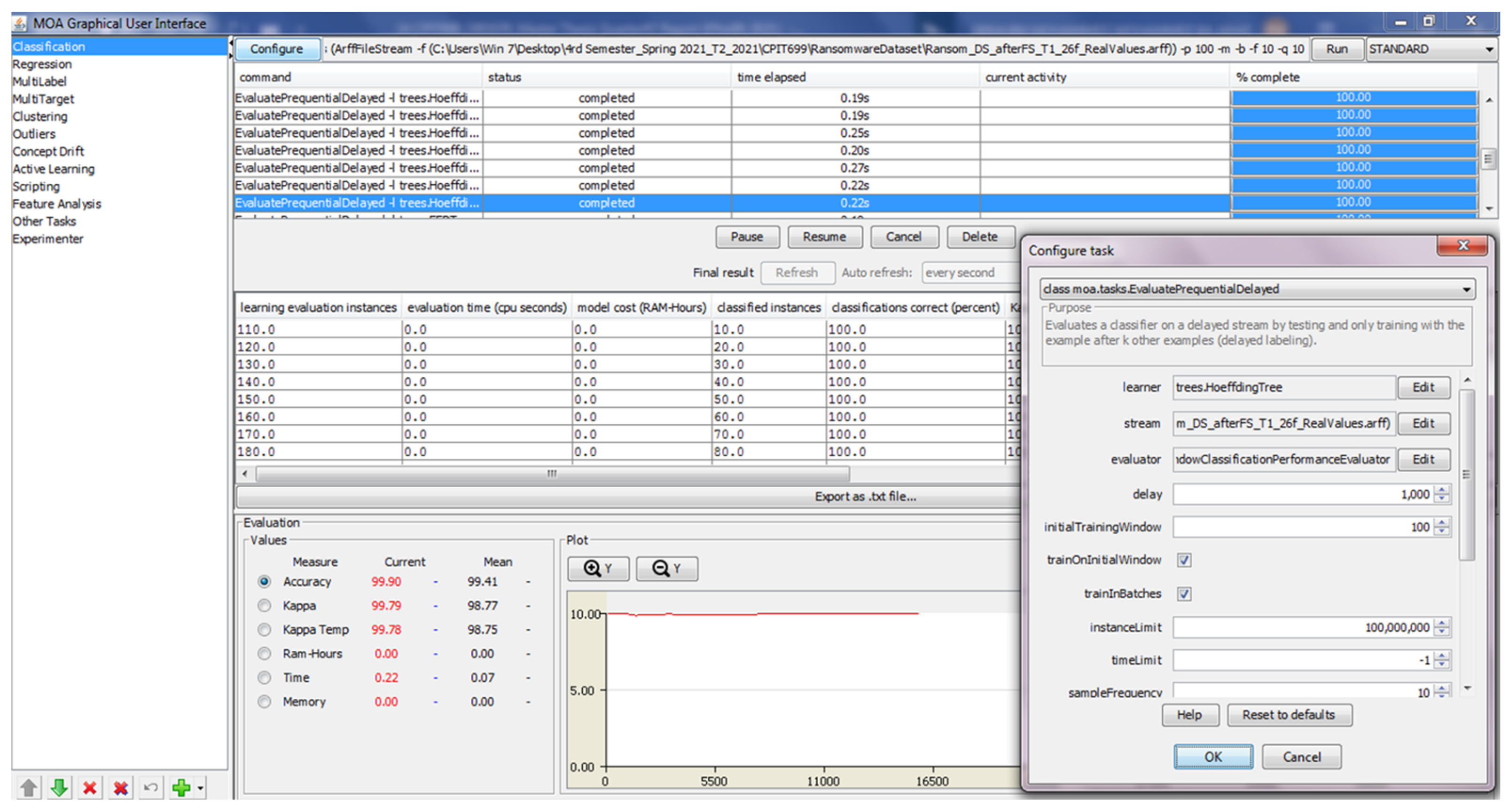
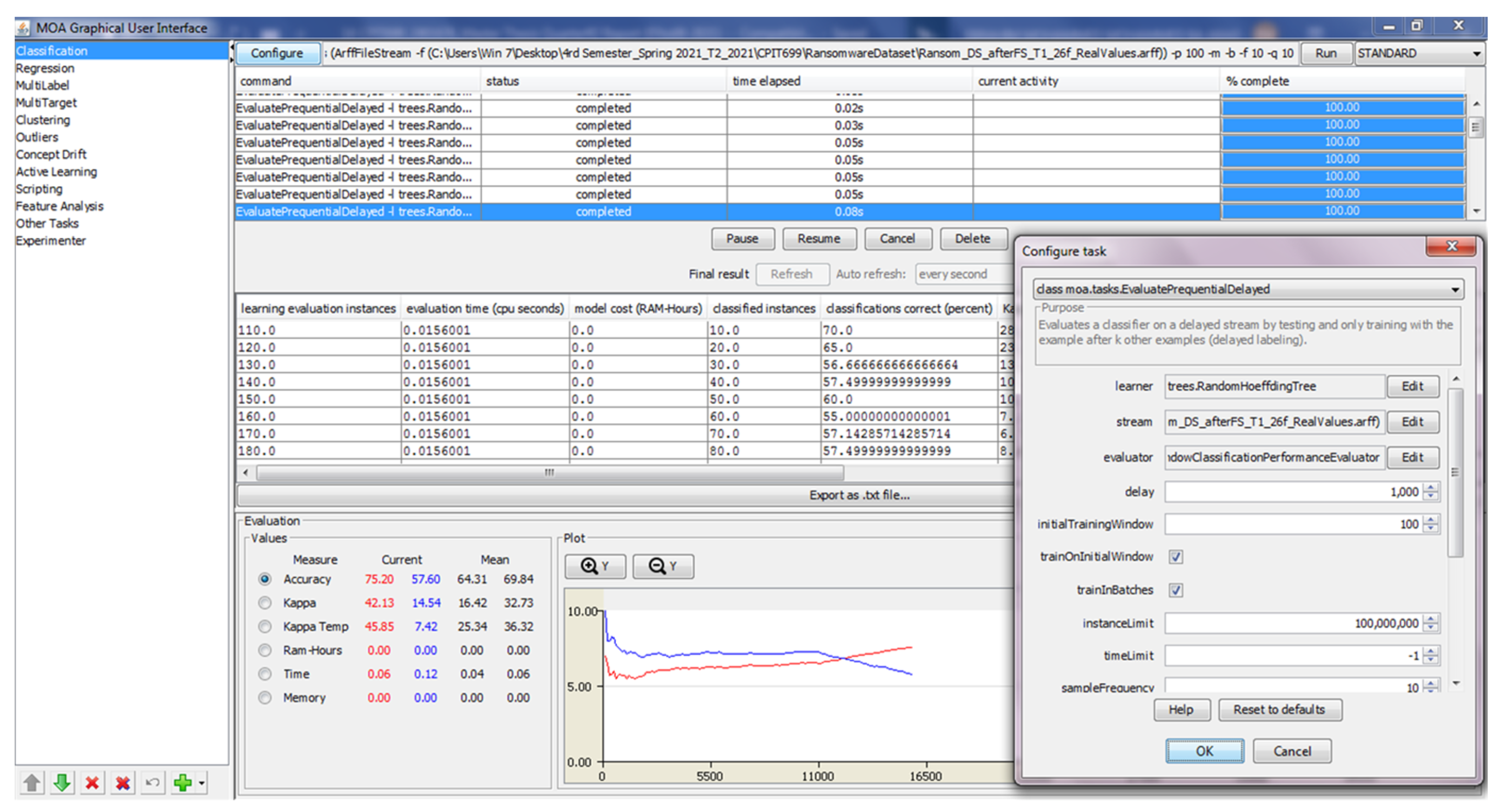
4.4. MOA Software Configuration
5. Results and Discussion
5.1. Results
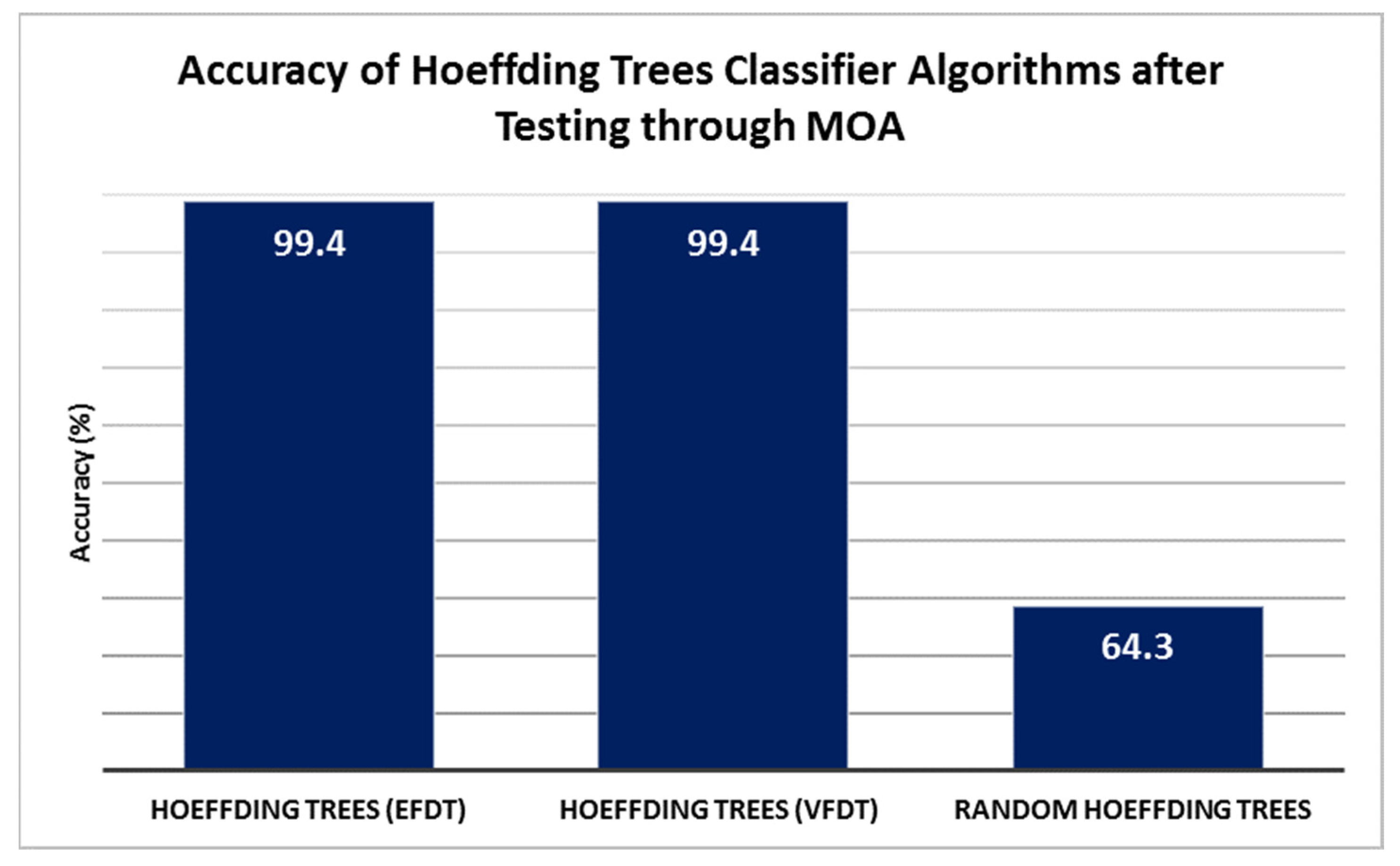
- Accuracy: Both Hoeffding trees classifier algorithms (EFDT, and VFDT) consistently achieved an accuracy of 99.4% across all ten tests (T1 to T10). This indicates that the algorithms performed consistently well in accurately classifying instances in the RISS dataset. On the other hand, the random Hoeffding trees algorithm receives 64.3% because the starting root node was chosen at random. The Hoeffding tree algorithms use the Hoeffding bound, a statistical inequality, to make early decisions and avoid unnecessary computations, making them efficient.
- Latency: The latency values varied for each algorithm and across different tests. The EFDT algorithm had an average latency of 66 ms, VFDT had an average latency of 68 ms, and random Hoeffding trees had the lowest average latency of 22 ms. Latency refers to the time taken to process and classify each instance. The variations in latency can be attributed to the different splitting criteria and tree construction strategies employed by each algorithm. With its lower latency, the random Hoeffding trees algorithm may have a more efficient decision-making process due to its randomization-based approach, which allows for faster classification. This proposes that it very well might be more effective regarding handling time contrasted with EFDT and VFDT. In any case, further examination is expected to decide whether this distinction in latency is measurably significant. In addition, the standard deviation (S) values indicate the variation in latency across the ten tests, with VFDT having the lowest deviation of 8.7 ms and EFDT having the highest deviation of 16.2 ms.
- Performance Consistency: The high accuracy achieved by EFDT and VFDT algorithms indicates their consistency in correctly classifying instances in the RISS dataset. The similar accuracy values obtained across all tests suggest that the algorithms are robust and perform consistently under varying conditions. This consistency can be attributed to the adaptive nature of Hoeffding tree algorithms, which can update their models incrementally and adapt to changes in the data distribution.
- Stability: The low standard deviation values for latency indicate relatively stable performance across the tests for each algorithm. This suggests that the algorithms are relatively sensitive to variations in the dataset or testing conditions.
5.2. Discussion
6. Conclusions and Future Work
- Incorporating real-life network traffic datasets from the industry as input streams will validate and support our model’s effectiveness;
- Considering classification latency alongside accuracy when evaluating ransomware detection and prevention models will offer a more comprehensive performance assessment;
- Exploring the accuracy and latency performance of other stream data mining classification algorithms, including rule-based, ensemble-based, nearest neighbors, and statistical-based approaches, will enable a broader comparison and evaluation of techniques;
- Developing a hybrid model that combines the accuracy levels of the EFDT algorithm with the rapid response capabilities of the random Hoeffding trees algorithm could significantly enhance the performance of the cyber threat hunting technique;
- Utilizing machines with advanced specifications will further optimize the model’s performance and scalability;
- Extending the applicability of our model to accurately and promptly identify other types of cyber attacks beyond ransomware will enhance its versatility and practicality;
- Implementing our model as standalone software will facilitate its adoption and usage by end users, offering a comprehensive solution for protecting systems against ransomware attacks and preventing data loss.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. MOA Software Screenshots


References
- Kok, S.H.; Abdullah, A.; Jhanjhi, N. Early Detection of Crypto-Ransomware Using Pre-Encryption Detection Algorithm. J. King Saud Univ. Comput. Inf. Sci. 2020, 34, 1984–1999. [Google Scholar] [CrossRef]
- Nguyen, G.; Dlugolinsky, S.; Tran, V.; Lopez Garcia, A. Deep Learning for Proactive Network Monitoring and Security Protection. IEEE Access 2020, 8, 19696–19716. [Google Scholar] [CrossRef]
- AbdulsalamYa’u, G.; Job, G.K.; Waziri, S.M.; Jaafar, B.; SabonGari, N.A.; Yakubu, I.Z. Deep Learning for Detecting Ransomware in Edge Computing Devices Based on Autoencoder Classifier. In Proceedings of the 2019 4th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), Mysuru, India, 13–14 December 2019; IEEE: New York, NY, USA, 2019; pp. 240–243. [Google Scholar] [CrossRef]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.K.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy of Network Threats and the Effect of Current Datasets on Intrusion Detection Systems. IEEE Access 2020, 8, 104650–104675. [Google Scholar] [CrossRef]
- Hulten, G.; Domingos, P.; Spencer, L. Mining Massive Data Streams; ProQuest Information and Learning Company: Ann Arbor, MI, USA, 2005. [Google Scholar]
- Zhang, X.; Wang, J.; Zhu, S. Dual Generative Adversarial Networks Based Unknown Encryption Ransomware Attack Detection. IEEE Access 2022, 10, 900–913. [Google Scholar] [CrossRef]
- Homayoun, S.; Dehghantanha, A.; Ahmadzadeh, M.; Hashemi, S.; Khayami, R.; Choo, K.-K.R.; Newton, D.E. DRTHIS: Deep Ransomware Threat Hunting and Intelligence System at the Fog Layer. Future Gener. Comput. Syst. 2019, 90, 94–104. [Google Scholar] [CrossRef]
- Berrueta, E.; Morato, D.; Magaña, E.; Izal, M. Crypto-Ransomware Detection Using Machine Learning Models in File-Sharing Network Scenarios with Encrypted Traffic. Expert Syst. Appl. 2022, 209, 118299. [Google Scholar] [CrossRef]
- Adamu, U.; Awan, I. Ransomware Prediction Using Supervised Learning Algorithms. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud (FiCloud), Istanbul, Turkey, 26–28 August 2019; IEEE: New York, NY, USA, 2019; pp. 57–63. [Google Scholar] [CrossRef]
- Homayoun, S.; Dehghantanha, A.; Ahmadzadeh, M.; Hashemi, S.; Khayami, R. Know Abnormal, Find Evil: Frequent Pattern Mining for Ransomware Threat Hunting and Intelligence. IEEE Trans. Emerg. Top. Comput. 2020, 8, 341–351. [Google Scholar] [CrossRef]
- Adewole, K.S.; Salau-Ibrahim, T.T.; Imoize, A.L.; Oladipo, I.D.; AbdulRaheem, M.; Awotunde, J.B.; Balogun, A.O.; Isiaka, R.M.; Aro, T.O. Empirical Analysis of Data Streaming and Batch Learning Models for Network Intrusion Detection. Electronics 2022, 11, 3109. [Google Scholar] [CrossRef]
- Ransomware Dataset—RISS. Available online: http://rissgroup.org/ransomware-dataset/ (accessed on 4 February 2023).
- Kumar, A.; Kaur, P.; Sharma, P. A Survey on Hoeffding Tree Stream Data Classification Algorithms. CPUH-Res. 2015, 5, 28–32. [Google Scholar]
- Garcia-Martin, E.; Bifet, A.; Lavesson, N.; König, R.; Linusson, H. Green Accelerated Hoeffding Tree. arXiv 2022, arXiv:2205.03184. [Google Scholar]
- Brownlee, J. How to Choose the Right Test Options when Evaluating Machine Learning Algorithms. MachineLearningMastery.com. Available online: https://machinelearningmastery.com/how-to-choose-the-right-test-options-when-evaluating-machine-learning-algorithms/ (accessed on 31 January 2023).
- Srimani, P.K.; Patil, M.M. Performance Analysis of Hoeffding Trees in Data Streams by Using Massive Online Analysis Framework. Int. J. Data Min. Model. Manag. 2015, 7, 293. [Google Scholar] [CrossRef] [Green Version]
- Domingos, P.; Hulten, G. Mining High-Speed Data Streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’00, Boston, MA, USA, 20–23 August 2000; ACM Press: Boston, MA, USA, 2000; pp. 71–80. [Google Scholar] [CrossRef]
- Yang, H.; Xu, A.; Chen, H.; Yuan, C. A Review: The Effects of Imperfect Data on Incremental Decision Tree. In Proceedings of the 2014 Ninth International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Guangdong, China, 8–10 November 2014; IEEE: New York, NY, USA, 2014; pp. 34–41. [Google Scholar] [CrossRef]
- da Costa, V.G.T.; Carvalho, A.C.P.D.L.F.D.; Junior, S.B. Strict Very Fast Decision Tree: A Memory Conservative Algorithm for Data Stream Mining. Pattern Recognit. Lett. 2018, 116, 22–28. [Google Scholar] [CrossRef] [Green Version]
- Lomte, V.M.; Deorukhakar, H.B. A Survey of Random Decision Tree Framework Privacy Preserving Data Mining. Int. J. Sci. Res. (IJSR) 2012, 3, 11, 3135–3139. [Google Scholar]
- Manapragada, C.; Webb, G.I.; Salehi, M. Extremely Fast Decision Tree. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; ACM: London, UK, 2018; pp. 1953–1962. [Google Scholar] [CrossRef] [Green Version]
- Divisi, D.; Di Leonardo, G.; Zaccagna, G.; Crisci, R. Basic Statistics with Microsoft Excel: A Review. J. Thorac. Dis. 2017, 9, 1734–1740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, E.; Hall, M.; Holmes, G.; Kirkby, R.; Pfahringer, B.; Witten, I.H.; Trigg, L. Weka-A Machine Learning Workbench for Data Mining. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer US: Boston, MA, USA, 2009; pp. 1269–1277. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning; Department of Computer Science, The University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Parameter | Chosen Value |
|---|---|---|
| 1 | Classification Task | Evaluate Prequential Delayed |
| 2 | k | 1000 instances |
| 3 | Initial window | 100 instances |
| 4 | Training on initial window | Enable |
| 5 | Training in batches | Enable |
| 6 | Sample frequency | 10 instances |
| 7 | Memory check Frequency | 10 instances |
| Test No. | Hoeffding Trees (EFDT) | Hoeffding Trees (VFDT) | Random Hoeffding Trees | |||
|---|---|---|---|---|---|---|
| Acc (%) | T (ms) | Acc (%) | T (ms) | Acc (%) | T (ms) | |
| T1 | 99.41 | 60 | 99.41 | 70 | 64.31 | 40 |
| T2 | 99.41 | 80 | 99.41 | 70 | 64.31 | 30 |
| T3 | 99.41 | 70 | 99.41 | 90 | 64.31 | 30 |
| T4 | 99.41 | 60 | 99.41 | 60 | 64.31 | 30 |
| T5 | 99.41 | 40 | 99.41 | 70 | 64.31 | 30 |
| T6 | 99.41 | 90 | 99.41 | 60 | 64.31 | 20 |
| T7 | 99.41 | 40 | 99.41 | 70 | 64.31 | 10 |
| T8 | 99.41 | 60 | 99.41 | 60 | 64.31 | 10 |
| T9 | 99.41 | 80 | 99.41 | 60 | 64.31 | 10 |
| T10 | 99.41 | 80 | 99.41 | 70 | 64.31 | 10 |
| Avg | 99.4 | 66 | 99.4 | 68 | 64.3 | 22 |
| S | 0 | 16.2 | 0 | 8.7 | 0 | 10.8 |
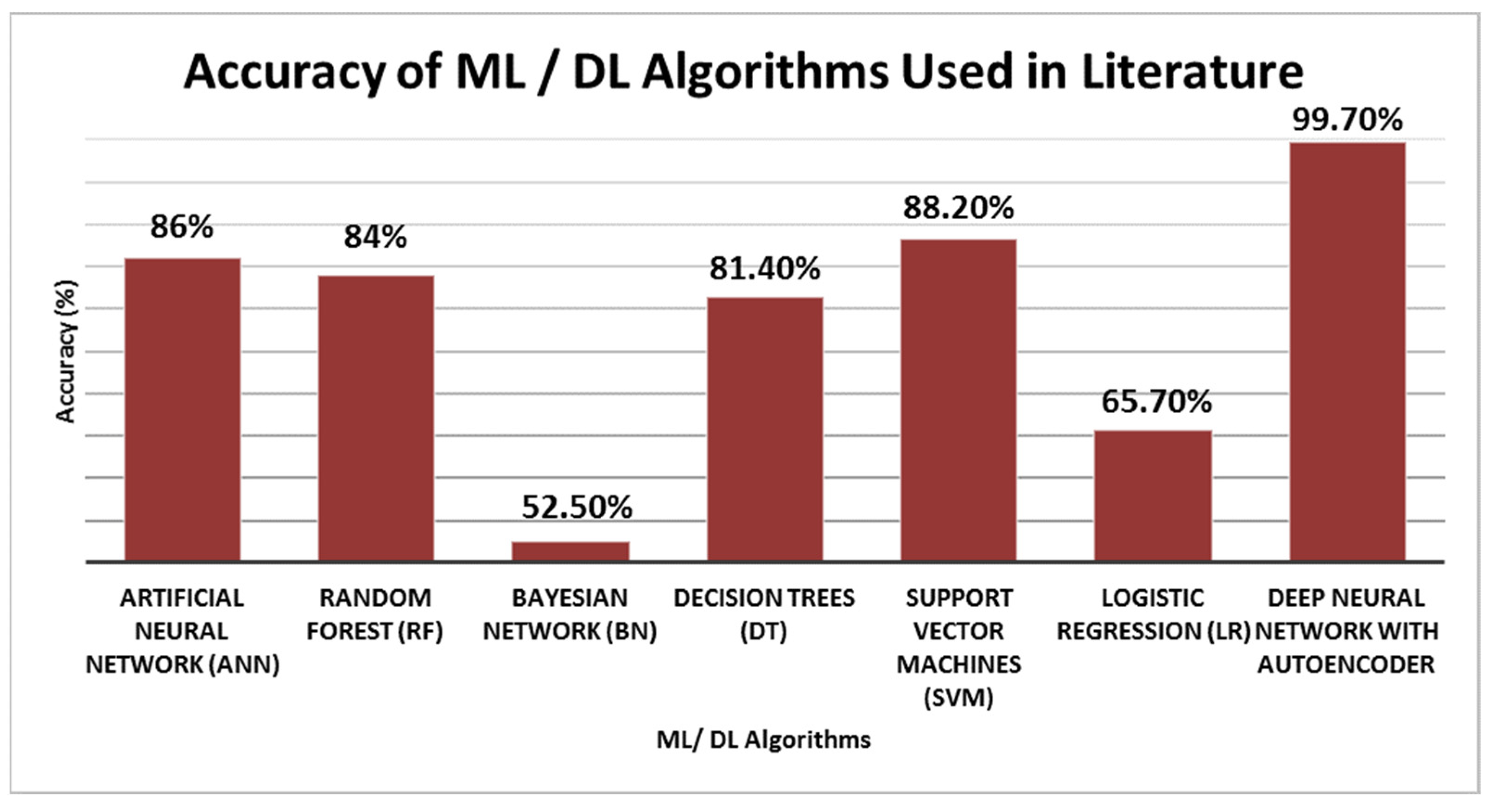
| No. | Algorithms (ML/DL) | Accuracy (%) |
|---|---|---|
| 1 | Support Vector Machines (SVM) | 88.2 |
| 2 | Random Forest (RF) | 84.0 |
| 3 | Decision Trees (DT) | 81.4 |
| 4 | Bayesian Network (BN) | 52.5 |
| 5 | Artificial Neural Network (ANN) | 86.0 |
| 6 | Logistic Regression (LR) | 65.7 |
| 7 | Deep Neural Network with Autoencoder | 99.7 |
| No. | Hoeffding Trees Classifier Algorithms | Accuracy (%) | Latency (ms) |
|---|---|---|---|
| 1 | Hoeffding Trees (EFDT) | 99.4 | 66 |
| 2 | Hoeffding Trees (VFDT) | 99.4 | 68 |
| 3 | Random Hoeffding Trees | 64.3 | 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ba’abbad, I.; Batarfi, O. Proactive Ransomware Detection Using Extremely Fast Decision Tree (EFDT) Algorithm: A Case Study. Computers 2023, 12, 121. https://doi.org/10.3390/computers12060121
Ba’abbad I, Batarfi O. Proactive Ransomware Detection Using Extremely Fast Decision Tree (EFDT) Algorithm: A Case Study. Computers. 2023; 12(6):121. https://doi.org/10.3390/computers12060121
Chicago/Turabian StyleBa’abbad, Ibrahim, and Omar Batarfi. 2023. "Proactive Ransomware Detection Using Extremely Fast Decision Tree (EFDT) Algorithm: A Case Study" Computers 12, no. 6: 121. https://doi.org/10.3390/computers12060121