

SmartWatcher©: A Solution to Automatically Assess the Smartness of Buildings
 , ,
, ,
Abstract
:1. Introduction
2. State of the Art
2.1. Natural Language Processing
- The linguistic part, which consists of preprocessing and transforming the input information into an exploitable dataset.
- The machine learning or data science part, which is based on the application of machine learning or deep learning models to that dataset with the aim of obtaining linguistic and domain expertise.
- Data cleaning. This is the process that refers to the practice of detecting and addressing mistakes, disparities and inaccuracies in data prior to an analysis. It is a vital component of data analysis, since the dependability and precision of the analysis are contingent on the quality of the data. The process of data cleaning includes a variety of responsibilities, such as eliminating duplicates, managing absent data, fixing errors, addressing outliers (i.e., values that are significantly different from the other values in a dataset) and resolving conflicts. One of the most common steps in data cleaning is to remove irrelevant information., e.g., stopwords, URLs, emojis, etc.
- Data normalisation [21] can be performed through:
- Tokenisation, which is the segmentation of text into several parts called tokens, which are words, numbers, symbols and punctuation marks.
- Stemming, which usually refers to the process of attempting to obtain the root of a word, i.e., its morphological root, by stripping it of the affixes that carry the word’s grammatical or lexical information, since the same word can be found in different forms depending on the person, gender, number, etc.
- Lemmatization, which is similar to stemming, uses the vocabulary and morphological analysis of the word and tries to eliminate inflectional endings, thus, returning words to their canonical form.
- Other operations in order to complete the data cleaning process, such as lower casing or removal of numbers, punctuation, symbols, etc.
- Transformation of textual data into digital data. There are several ways of conducting this; the TF-IDF (term frequency-inverse document frequency) algorithm is one of the most widely used methods and the one that was used in this work. This method consists of counting the number of occurrences of tokens in the corpus for each text, which is then divided by the total number of occurrences of the same tokens in the whole corpus [22].
2.2. NLP Applied to Buildings
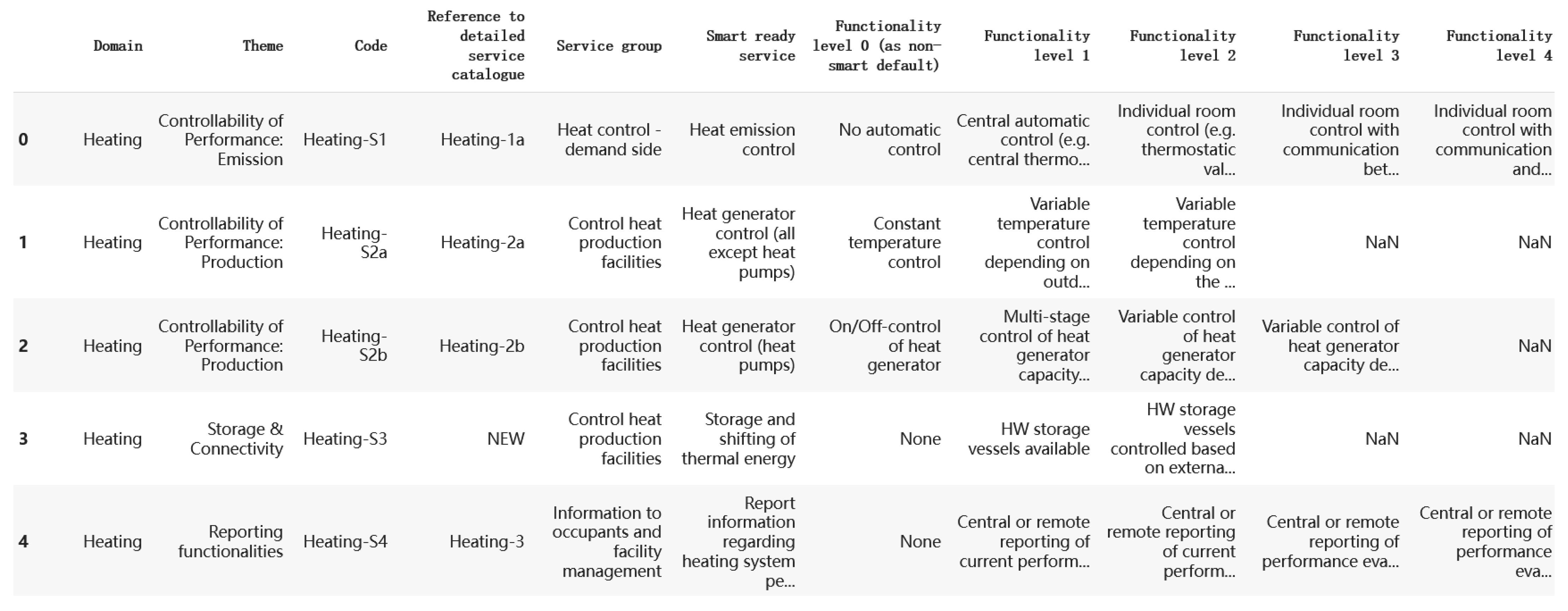
2.3. Smart Readiness Indicator of Buildings
3. Methodology
3.1. Problem Definition
- Human intervention leads to a subjective SRI score assignment;
- The cost to train a sufficient amount of professionals must be considerable;
- The cost faced by users to obtain the SRI certificate for their building would be higher.
3.2. Case Study Definition
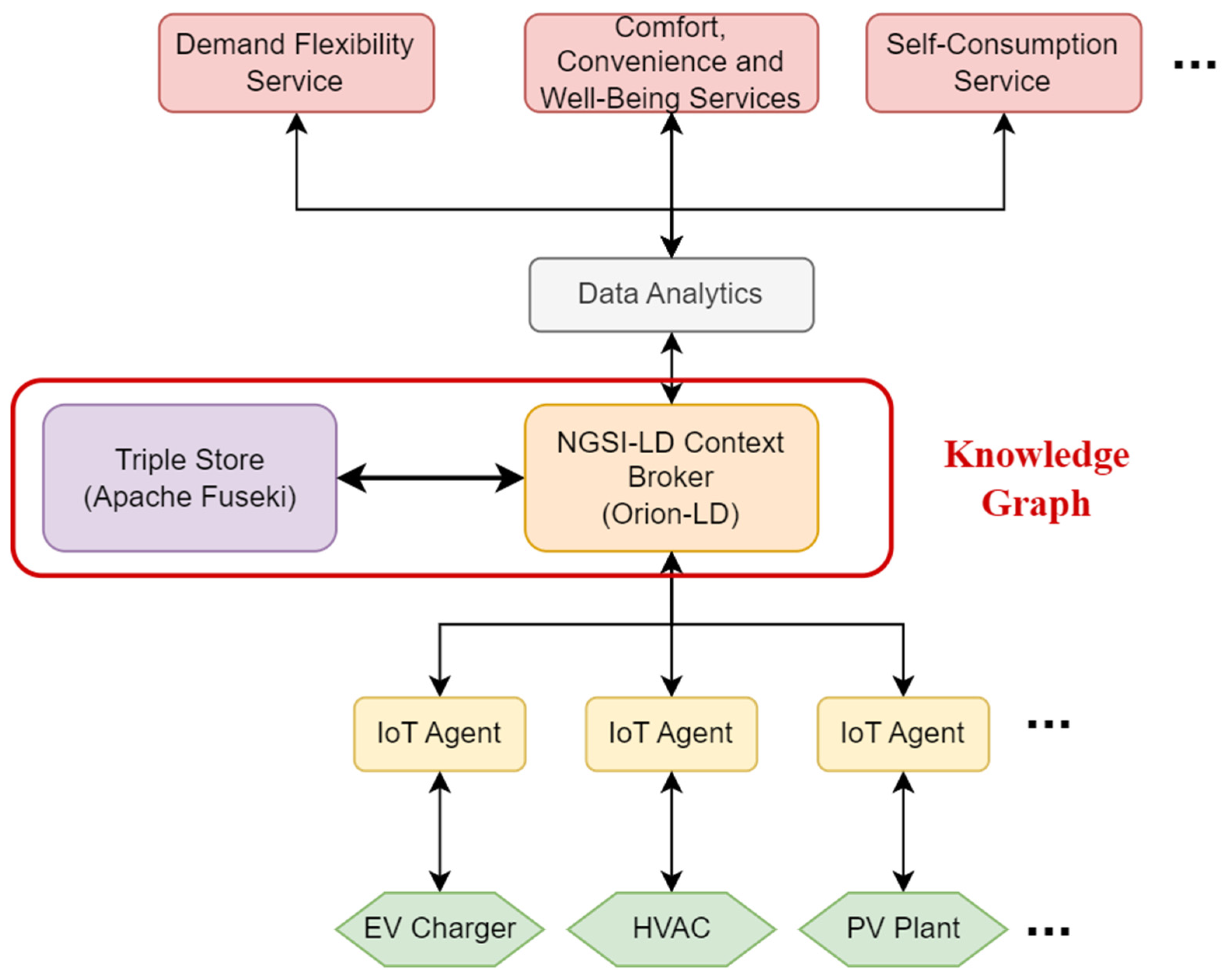
3.3. Smart Building ICT Platforms
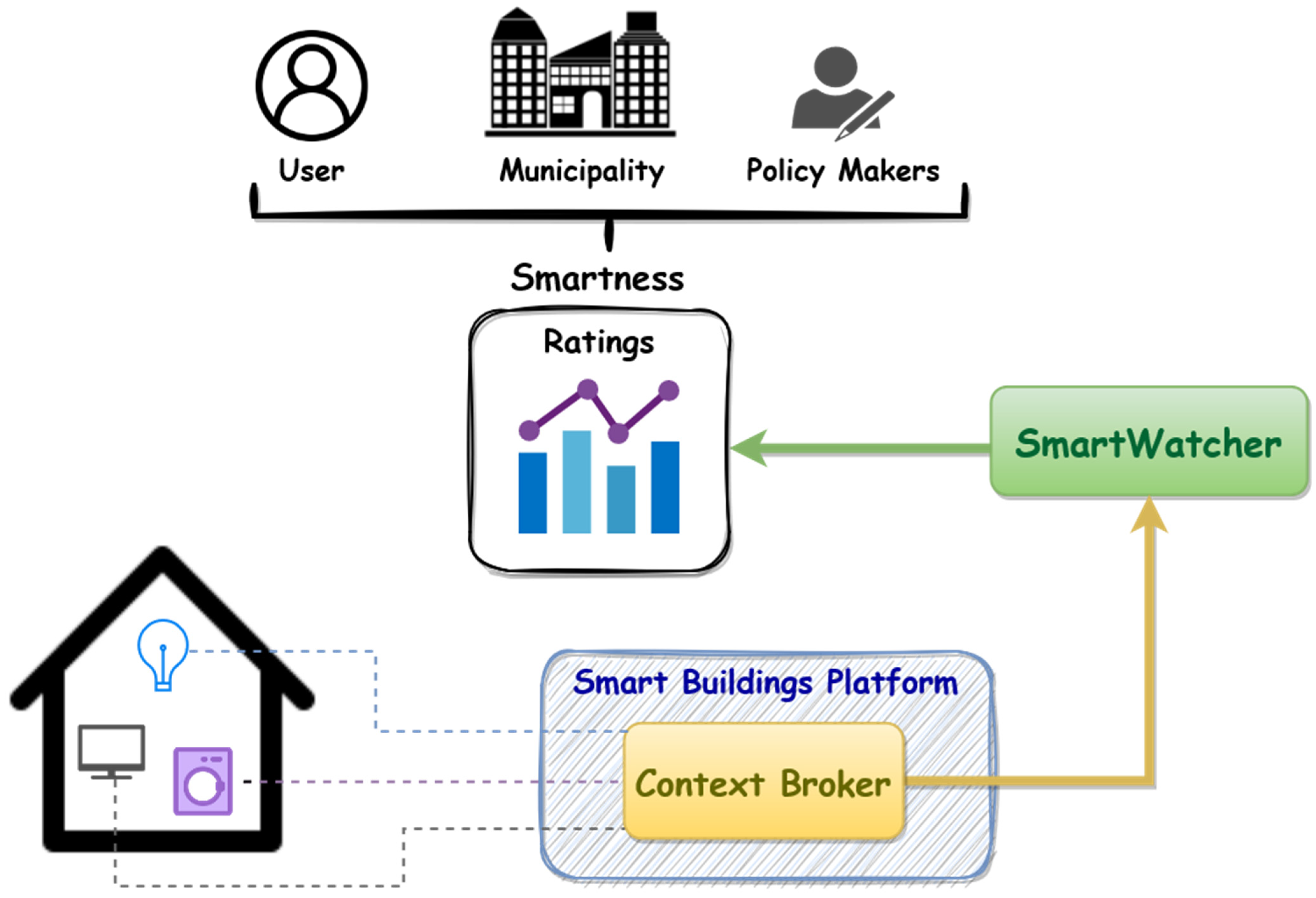
3.4. Automatic Building Smartness’ Assessment Framework
4. Results and Discussion
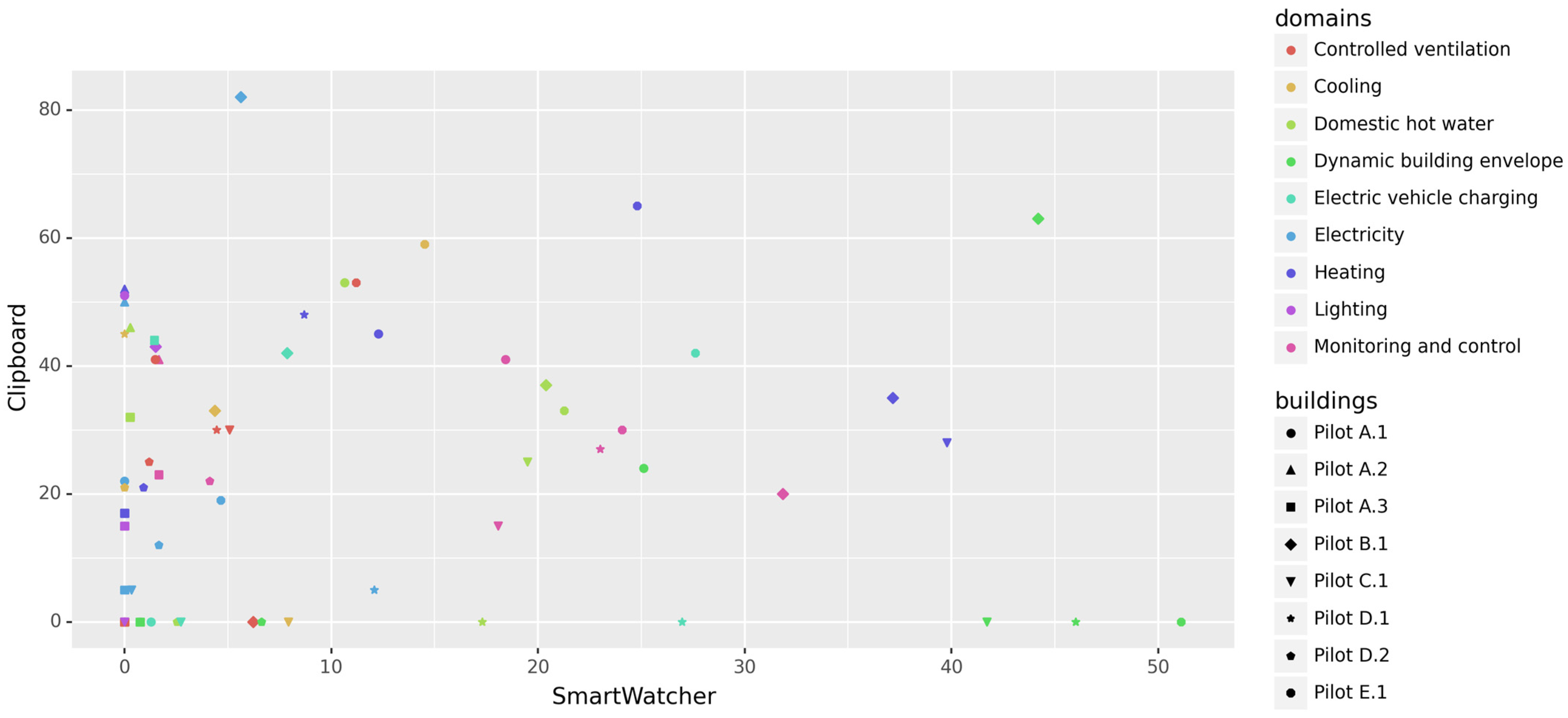
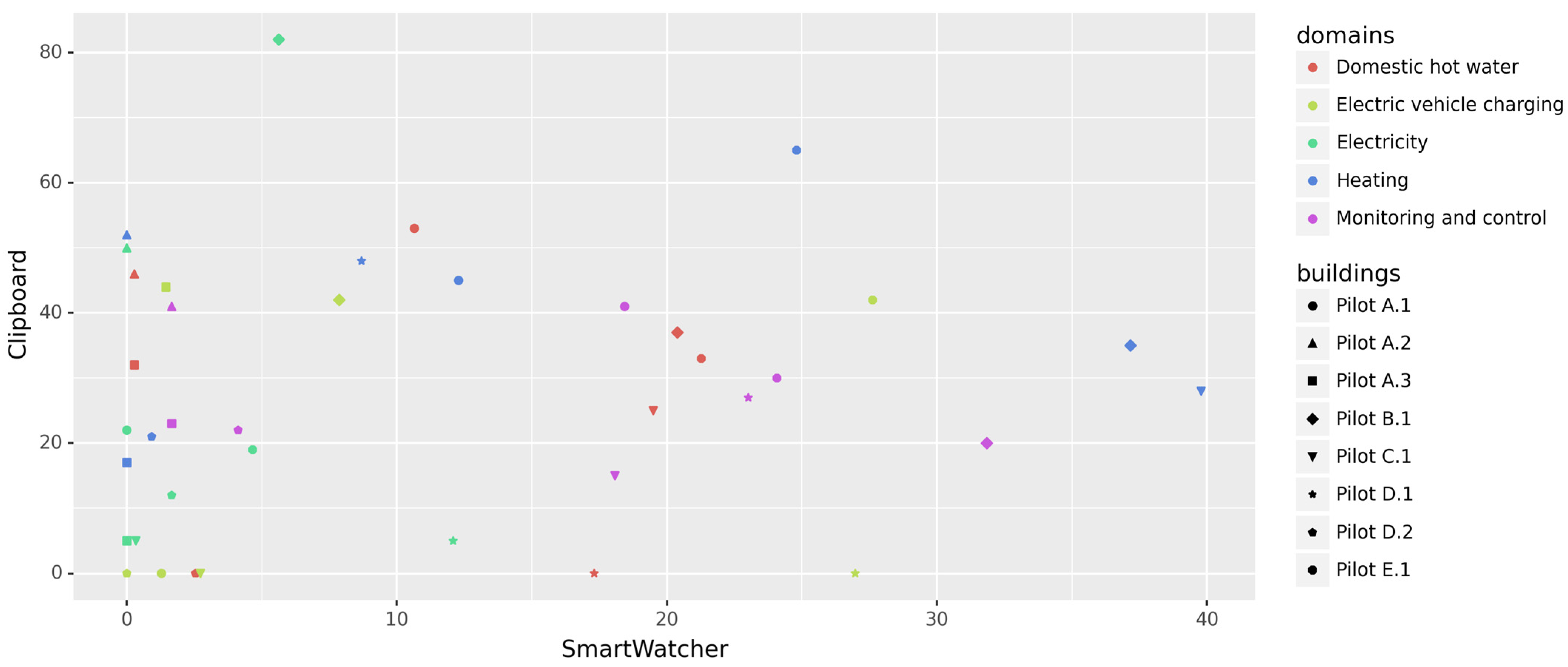
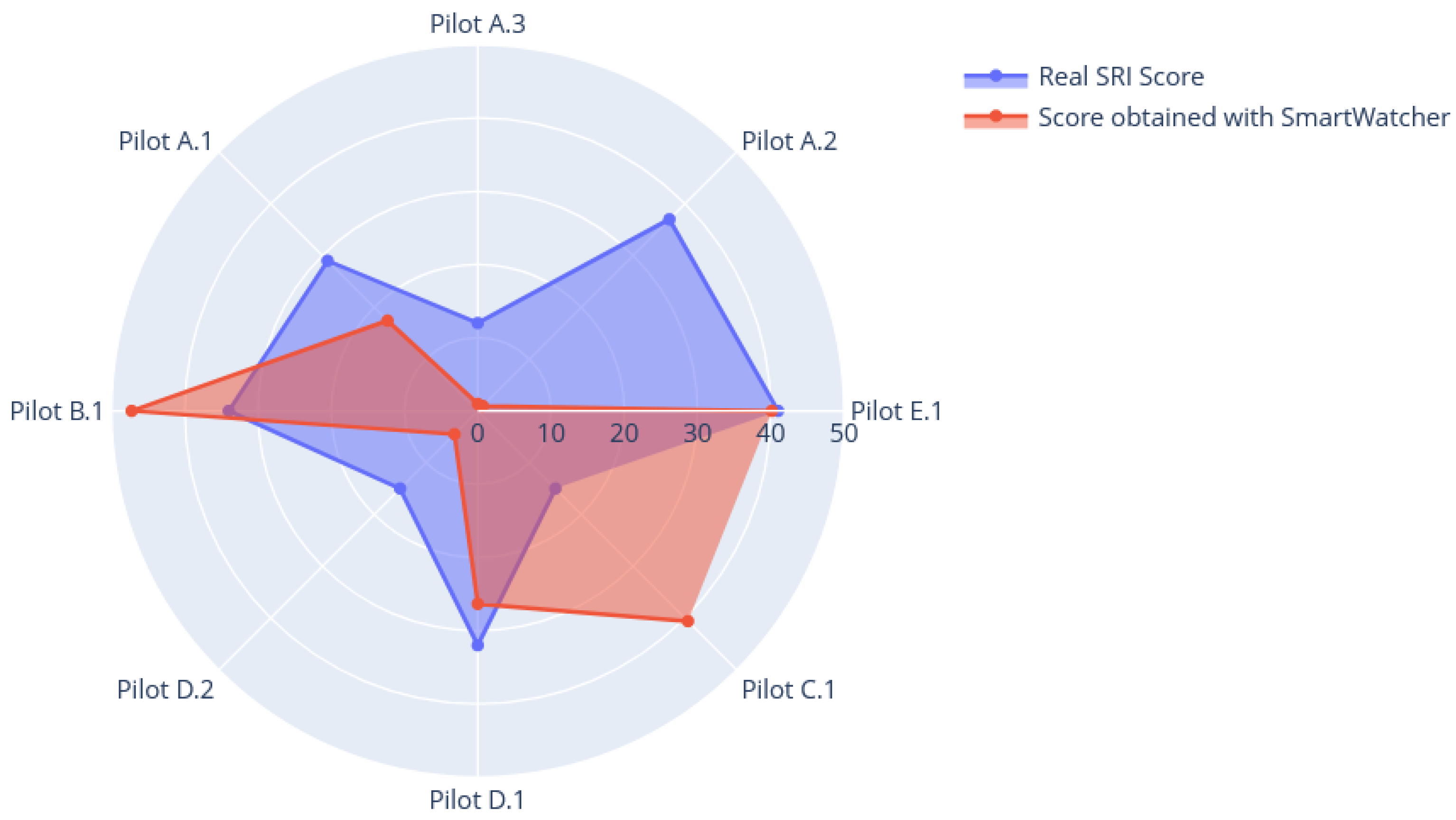
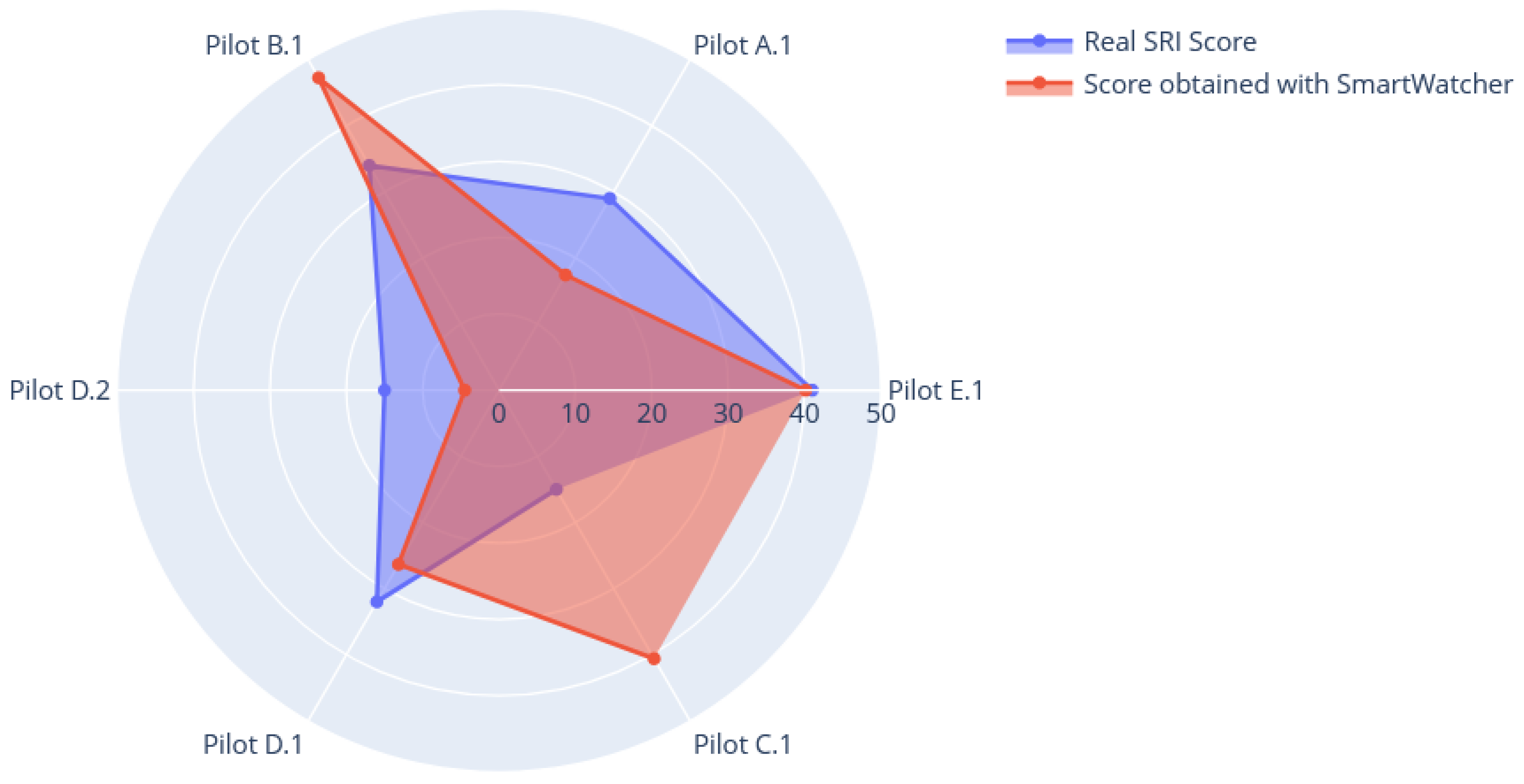
4.1. Applying SmartWatcher to the Case Study
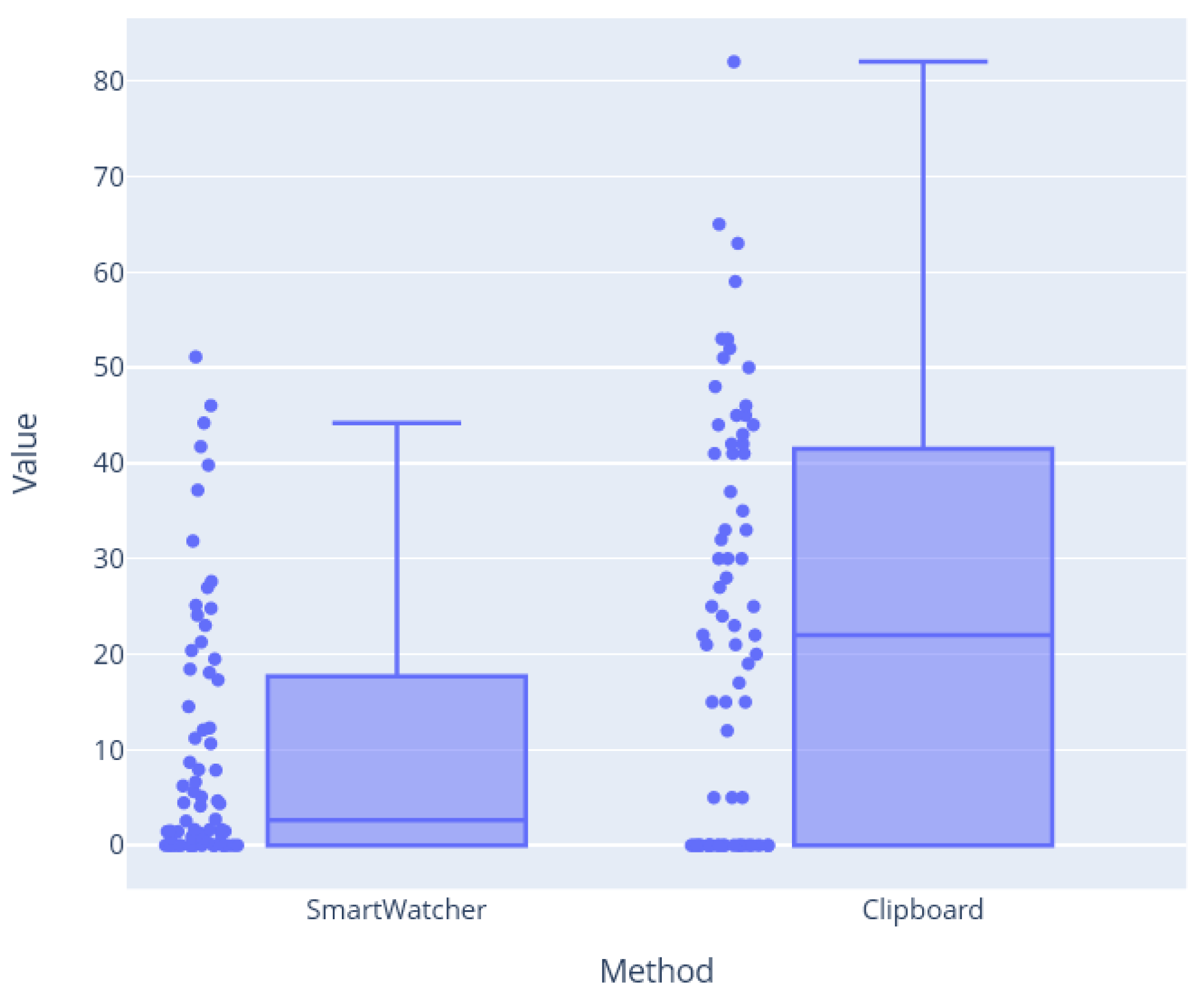
4.2. Analysis of Results and Improvements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- European Commission. COM(2011) 112 Final. A Roadmap for Moving to a Competitive Low Carbon Economy in 2050; European Commission: Brussels, Belgium, 2011. [Google Scholar]
- Nejat, P.; Jomehzadeh, F.; Taheri, M.M.; Gohari, M.; Majid, M.Z.A. A global review of energy consumption, CO2 emissions and policy in the residential sector (with an interview of the top ten CO2 emitting countries). Renew. Sustain. Energy Rev. 2015, 43, 843–862. [Google Scholar] [CrossRef]
- Directive 2012/27/EU of the European Parliament and of the Council of 25 October 2012 on Energy Efficiency; L315/1-56; Official Journal of the European Union: Brussels, Belgium, 2012.
- Pan, J.; Jain, R.; Paul, S.; Vu, T.; Saifullah, A.; Sha, M. An Internet of Things Framework for Smart Energy in Buildings: Designs, Prototype, and Experiments. IEEE Internet Things J. 2015, 2, 527–537. [Google Scholar] [CrossRef] [Green Version]
- Directive (EU) 2018/844 of the European Parliament and of the Council of 30 May 2018 Amending Directive2010/31/EU on the Energy Performance of Buildings Directive 2012/27/EU on Energy Efficiency; L156/75; Official Journal of the European Union: Brussels, Belgium, 2018.
- European Commission; Directorate-General for Energy; Verbeke, S.; Aerts, D.; Reynders, G. Final Report on the Technical Support to the Development of a Smart Readiness Indicator for Buildings: Final Report; Publications Office: Brussels, Belgium, 2020. [Google Scholar]
- VITO. Support for Setting Up a Smart Readiness Indicator for Buildings and Related Impact Assessment (Tender Number ENER/C3/2016-554). 2020. Available online: https://smartreadinessindicator.eu/ (accessed on 14 September 2022).
- Vigna, I.; Pernetti, R.; Pasut, W.; Lollini, R. New domain for promoting energy efficiency: Energy Flexible Building Cluster. Sustain. Cities Soc. 2018, 38, 526–533. [Google Scholar] [CrossRef]
- Märzinger, T.; Österreicher, D. Supporting the smart readiness indicator—A methodology to integrate a quantitative assessment of the load shifting potential of smart buildings. Energies 2019, 12, 1955. [Google Scholar] [CrossRef] [Green Version]
- European Commission. C(2020) 6930 Final, Annexes 1 to 9. Supplementing Directive (EU) 2010/31/EU of the European Parliament and of the Council by Establishing an Optional Common European Union Scheme for Rating the Smart Readiness of Buildings; European Commission: Brussels, Belgium, 2020. [Google Scholar]
- BIQ. Building Intelligence Quotient. Available online: https://building-iq.com/ (accessed on 22 February 2023).
- HSBS. Honeywell Smart Building Score. Available online: https://buildingcontractorpro.secure.force.com/hsbs/MEhsbs_aboutus (accessed on 24 February 2023).
- Janhunen, E.; Pulkka, L.; Säynäjoki, A.; Junnila, S. Applicability of the Smart Readiness Indicator for Cold Climate Countries. Buildings 2019, 9, 102. [Google Scholar] [CrossRef] [Green Version]
- Ramezani, B.; Silva, M.G.D.; Simões, N. Application of smart readiness indicator for Mediterranean buildings in retrofitting actions. Energy Build. 2021, 249, 111173. [Google Scholar] [CrossRef]
- Vigna, I.; Pernetti, R.; Pernigotto, G.; Gasparella, A. Analysis of the building smart readiness indicator calculation: A comparative case-study with two panels of experts. Energies 2020, 13, 2796. [Google Scholar] [CrossRef]
- Fokaides, P.A.; Panteli, C.; Panayidou, A. How are the smart readiness indicators expected to affect the energy performance of buildings: First evidence and perspectives. Sustainability 2020, 12, 9496. [Google Scholar] [CrossRef]
- PHOENIX. Available online: https://eu-phoenix.eu/ (accessed on 16 September 2022).
- Moseley, P. EU Support for Innovation and Market Uptake in Smart Buildings under the Horizon 2020 Framework Programme. Buildings 2017, 7, 105. [Google Scholar] [CrossRef] [Green Version]
- Ly, A.; Uthayasooriyar, B.; Wang, T. A survey on natural language processing (nlp) and applications in insurance. arXiv 2020, arXiv:2010.00462. [Google Scholar]
- Chowdhary, K. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 603–649. [Google Scholar]
- Arellano, A.; Carney, E.; Austin, M.A. Natural language processing of textual requirements. In Proceedings of the Tenth International Conference on Systems (ICONS 2015), Barcelona, Spain, 19–24 April 2015; pp. 93–97. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; Volume 242, pp. 29–48. [Google Scholar]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Bilal, M.; Oyedele, L.O.; Qadir, J.; Munir, K.; Ajayi, S.O.; Akinade, O.O.; Owolabi, H.A.; Alaka, H.A.; Pasha, M. Big Data in the construction industry: A review of present status, opportunities, and future trends. Adv. Eng. Inform. 2016, 30, 500–521. [Google Scholar] [CrossRef]
- Hassan, F.U.; Le, T. Automated requirements identification from construction contract documents using natural language processing. J. Leg. Aff. Disput. Resolut. Eng. Constr. 2020, 12, 04520009. [Google Scholar] [CrossRef]
- Zhang, J.; El-Gohary, N.M. Semantic NLP-based information extraction from construction regulatory documents for automated compliance checking. J. Comput. Civ. Eng. 2016, 30, 04015014. [Google Scholar] [CrossRef] [Green Version]
- Baby, C.J.; Khan, F.A.; Swathi, J.N. Home automation using IoT and a chatbot using natural language processing. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017; pp. 1–6. [Google Scholar]
- Märzinger, T.; Österreicher, D. Extending the Application of the Smart Readiness Indicator—A Methodology for the Quantitative Assessment of the Load Shifting Potential of Smart Districts. Energies 2020, 13, 3507. [Google Scholar] [CrossRef]
- Horák, O.; Kabele, K. Testing of pilot buildings by the SRI method. Vytap. Vetr. Instal. 2019, 28, 331–334. [Google Scholar]
- Dorizas, P.V.; de Grooe, M.; Volt, J. Indoor environmental quality as a mean to catalyse the acceptance and implementation of the major new EPBD provisions. In Eceee Summer Study Proceedings; European Commission: Brussels, Belgium, 2019; pp. 1237–1242. [Google Scholar]
- Markoska, E.; Jakica, N.; Lazarova-Molnar, S.; Kragh, M.K. Assessment of Building Intelligence Requirements for Real Time Performance Testing in Smart Buildings. In Proceedings of the 2019 4th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 18–21 June 2019; pp. 1–6. [Google Scholar]
- Markoska, E.; Johansen, A.; Lazarova-Molnar, S. A Framework for Fully Automated Performance Testing for Smart Buildings. In Proceedings of the International Congress on Information and Communication Technology, Xiamen, China, 27–28 January 2018. [Google Scholar]
- Newsletter Smart Readiness Indicator. Available online: https://ec.europa.eu/newsroom/ener/newsletter-archives/37893 (accessed on 28 February 2023).
- Third Plenary Meeting Smart Readiness Indicator. Available online: https://energy.ec.europa.eu/events/smart-readiness-indicator-third-plenary-meeting-2023-03-22_en (accessed on 24 March 2023).
- FIWARE. Available online: https://www.fiware.org/ (accessed on 2 March 2023).
- NGSI-LD. Available online: https://www.etsi.org/deliver/etsi_gs/CIM/001_099/009/01.04.01_60/gs_cim009v010401p.pdf (accessed on 2 March 2023).
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, SciPy 2010, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Scikit-Learn Algorithm Feature Extraction. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html (accessed on 16 September 2022).
- SPARQL Wrapper. Available online: https://sparqlwrapper.readthedocs.io/en/latest/ (accessed on 16 September 2022).
- Plotly Library. Available online: https://plotly.com/python/ (accessed on 7 October 2022).
- Plotline Library. Available online: https://plotnine.readthedocs.io/en/stable/index.html (accessed on 7 October 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case Study | Pilot A | Pilot B | Pilot C | Pilot D | Pilot E | |||
|---|---|---|---|---|---|---|---|---|
 |  |  |  |  | ||||
| Location | Dublin, Ireland West Europe | Thessaloniki, Greece South Europe | Skellefteå, Sweden North Europe | Region of Murcia, Spain South Europe | Murcia, Spain South Europe | |||
| Building name | Pilot A.1 | Pilot A.2 | Pilot A.3 | Pilot B.1 | Pilot C.1 | Pilot D.1 | Pilot D.2 | Pilot E.1 |
| Building typology | Nonresidential | Residential | Residential | Residential | Residential | Nonresidential | Residential | Nonresidential |
| SRI score (clipboard) | 29% | 37% | 12% | 34% | 15% | 32% | 15% | 40% |
| Domain | Pilot E.1 | Pilot A.2 | Pilot A.3 | Pilot A.1 | Pilot B.1 | Pilot D.2 | Pilot D.1 | Pilot C.1 |
|---|---|---|---|---|---|---|---|---|
| Heating | 0.240 | 0.245 | 0.245372 | 0.224 | 0.230 | 0.230 | 0.240 | 0.230 |
| Domestic hot water | 0.090 | 0.067 | 0.067258 | 0.074 | 0.080 | 0.080 | 0.09 | 0.077 |
| Cooling | 0.140 | 0.097 | 0.096654 | 0.148 | 0.110 | 0.110 | 0.140 | 0.082 |
| Controlled ventilation | 0.110 | 0.133 | 0.133454 | 0.126 | 0.110 | 0.110 | 0.110 | 0.137 |
| Lighting | 0.050 | 0.039 | 0.039236 | 0.052 | 0.040 | 0.040 | 0.050 | 0.042 |
| Dynamic building envelope | 0.040 | 0.084 | 0.083944 | 0.041 | 0.100 | 0.100 | 0.040 | 0.097 |
| Electricity | 0.100 | 0.096 | 0.096327 | 0.096 | 0.100 | 0.100 | 0.100 | 0.097 |
| Electric vehicle | 0.040 | 0.038 | 0.037755 | 0.038 | 0.040 | 0.040 | 0.040 | 0.038 |
| Monitoring and control | 0.200 | 0.200 | 0.200 | 0.200 | 0.200 | 0.200 | 0.200 | 0.200 |
| EX. Time (Second) | Pilot E.1 | Pilot A.2 | Pilot A.3 | Pilot A.1 | Pilot B.1 | Pilot D.2 | Pilot D.1 | Pilot C.1 | Mean EX. Time |
|---|---|---|---|---|---|---|---|---|---|
| Heating | 16.17 | 15.38 | 15.39 | 15.57 | 16.10 | 15.56 | 16.20 | 15.59 | 15.75 |
| Domestic hot water | 11.41 | 10.71 | 10.72 | 11.05 | 11.28 | 10.80 | 11.36 | 10.80 | 11.02 |
| Cooling | 15.78 | 15.18 | 14.90 | 15.16 | 15.81 | 15.13 | 15.93 | 15.01 | 15.36 |
| Controlled ventilation | 8.31 | 7.93 | 7.97 | 7.99 | 8.27 | 7.92 | 8.43 | 7.97 | 8.10 |
| Lighting | 2.74 | 2.63 | 2.63 | 2.65 | 2.72 | 2.66 | 2.81 | 2.63 | 2.69 |
| Dynamic building envelope | 6.76 | 6.44 | 6.43 | 6.53 | 6.76 | 6.39 | 6.71 | 6.50 | 6.57 |
| Electricity | 11.14 | 10.57 | 10.51 | 10.70 | 10.93 | 10.64 | 11.15 | 10.61 | 10.78 |
| Electric vehicle | 8.05 | 7.66 | 7.67 | 7.80 | 8.04 | 7.96 | 8.22 | 7.82 | 7.90 |
| Monitoring and control | 9.46 | 9.01 | 9.00 | 9.24 | 9.37 | 9.03 | 9.61 | 9.17 | 9.24 |
| Total time (minute) | 1.497 | 1.425 | 1.420 | 1.445 | 1.488 | 1.435 | 1.507 | 1.435 | 1.456 |
| Domain | Heating | DHW | Cooling | CV | Lighting | DBE | Electricity | EV | MC |
|---|---|---|---|---|---|---|---|---|---|
| Number of terms | 70 | 49 | 68 | 36 | 12 | 29 | 48 | 35 | 41 |
| Standard deviation | 0.35 | 0.30 | 0.41 | 0.20 | 0.07 | 0.16 | 0.26 | 0.20 | 0.23 |
| Domain | Pilot E.1 | Pilot A.2 | Pilot A.3 | Pilot A.1 | Pilot B.1 | Pilot D.2 | Pilot D.1 | Pilot C.1 |
|---|---|---|---|---|---|---|---|---|
| Heating | 5.9528 | 0.0000 | 0.0000 | 2.7561 | 8.5492 | 0.2111 | 2.0858 | 9.1779 |
| Domestic hot water | 1.9146 | 0.0187 | 0.0187 | 0.7847 | 1.6312 | 0.2034 | 1.5577 | 1.4959 |
| Cooling | 2.0329 | 0.0000 | 0.0000 | 0.0000 | 0.4806 | 0.0000 | 0.0000 | 0.6505 |
| Controlled ventilation | 1.2328 | 0.0000 | 0.0000 | 0.1875 | 0.6849 | 0.1307 | 0.4902 | 0.6961 |
| Lighting | 0.0376 | 0.0000 | 0.0000 | 0.0000 | 0.0601 | 0.0000 | 0.0000 | 0.0000 |
| Dynamic building envelope | 2.0447 | 0.0634 | 0.0634 | 1.0449 | 4.4199 | 0.6629 | 1.8407 | 4.0509 |
| Electricity | 0.4658 | 0.0000 | 0.0000 | 0.0000 | 0.5627 | 0.1658 | 1.2083 | 0.0324 |
| Electric vehicle charging | 1.1047 | 0.0545 | 0.0546 | 0.0485 | 0.3147 | 0.0000 | 1.0790 | 0.1029 |
| Monitoring and control | 4.8149 | 0.3321 | 0.3321 | 3.6870 | 6.3702 | 0.8244 | 4.6030 | 3.6155 |
| Success | Hit | Miss | Both Zero |
|---|---|---|---|
| 53 | 39 | 10 | 9 |
| Building | Slope | R2 |
|---|---|---|
| Pilot E.1 | 1.762037 | 0.428398 |
| Pilot A.2 | 29.343110 | 0.838263 |
| Pilot A.3 | 22.481704 | 0.359750 |
| Pilot A.1 | 3.091685 | 0.568483 |
| Pilot B.1 | 1.199217 | 0.545561 |
| Pilot D.2 | 4.800807 | 0.172023 |
| Pilot D.1 | 0.617941 | 0.238251 |
| Pilot C.1 | 0.815796 | 0.823083 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Y.; Ramallo-González, A.P.; Tomat, V.; Valverde, J.S.; Skarmeta-Gómez, A. SmartWatcher©: A Solution to Automatically Assess the Smartness of Buildings. Computers 2023, 12, 76. https://doi.org/10.3390/computers12040076
Ye Y, Ramallo-González AP, Tomat V, Valverde JS, Skarmeta-Gómez A. SmartWatcher©: A Solution to Automatically Assess the Smartness of Buildings. Computers. 2023; 12(4):76. https://doi.org/10.3390/computers12040076
Chicago/Turabian StyleYe, Yu, Alfonso P. Ramallo-González, Valentina Tomat, Juan Sanchez Valverde, and Antonio Skarmeta-Gómez. 2023. "SmartWatcher©: A Solution to Automatically Assess the Smartness of Buildings" Computers 12, no. 4: 76. https://doi.org/10.3390/computers12040076