

Learning-Based Matched Representation System for Job Recommendation


Abstract
:1. Introduction
- Analyzing the skills required for a job, into which the user’s domain falls; using this as a parameter to compute the similarity between available job offers on Indeed and job seekers;
- A web-based application enabling recommendation job postings that match job seekers skills reflected in their resumes;
- The recommender system uses NLP (Natural language processing) to match skills between resumes and job descriptions.
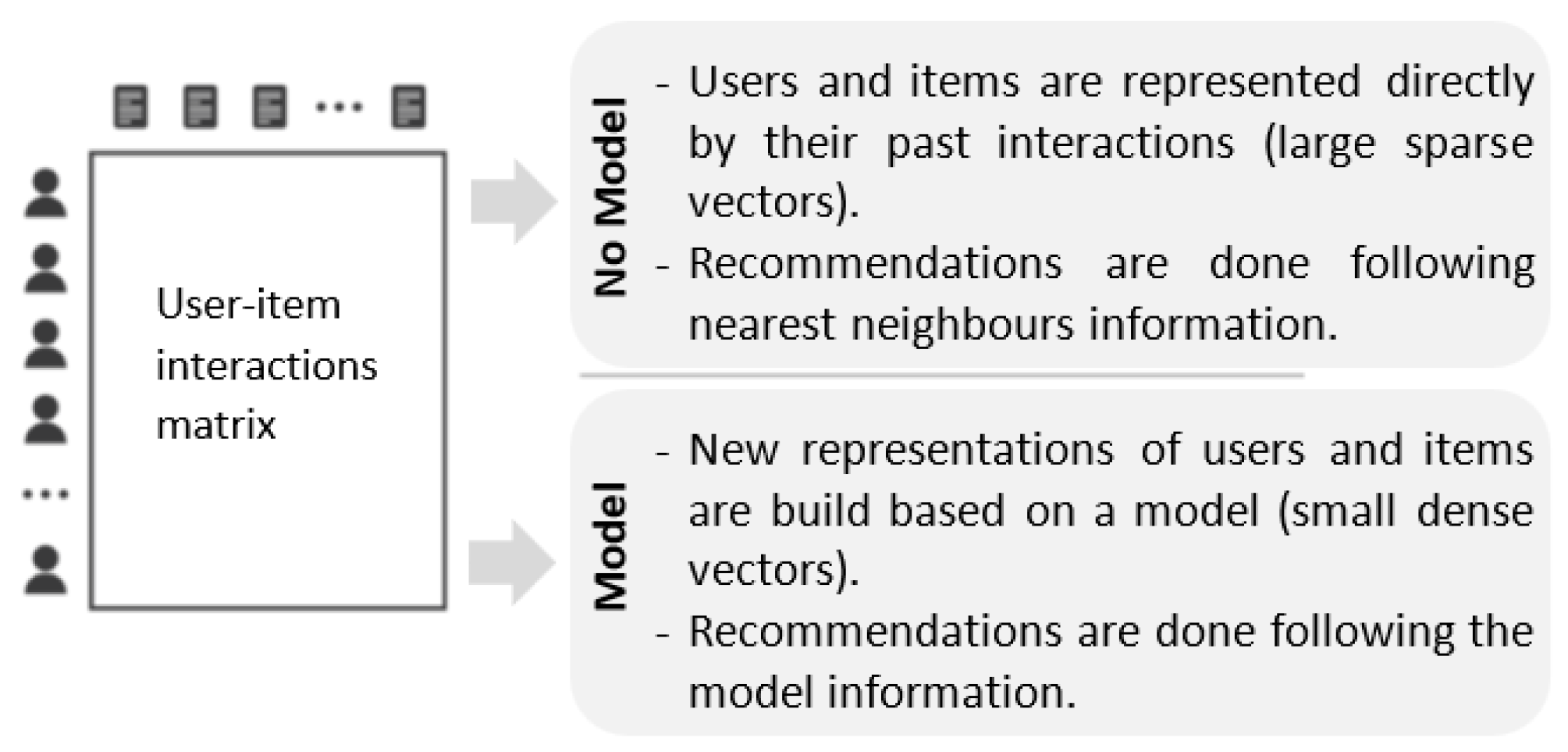
2. Recommender Systems Methods
- Analyzing explicit property of the content;
- Building a user profile and an item profile from user-rated content.
3. How to Evaluate a JRS
3.1. Accuracy Measurement: Predicting the Score
- Mean Absolute Error (MAE):it gives the average of the deviations between the predicted score and the actual score. It is given by the equation Equation (1).
3.2. Decision Support Measure: Classification Score
- Precision is the ratio between the number of true positives (TP) (i.e., the number of relevant recommended objects) and the number of produced recommendations (i.e., the TP plus the false positives (FP)) [36,37]. It estimates the probability that a recommended object is relevant. It is given by Equation (3).
- The ROC curve (receiver operating characteristic) visually compares the evolution of the relevance of recommendations according to the number of recommendations: on the x axis, the , in y axis, the (i.e., the recall), starting from the point and reaching when all jobs have been recommended. A recommender system is all the better if it maximizes the area under the ROC curve [39]. A random system corresponds to the first bisector, and a perfect system corresponds to a curve passing through the point , thus recommending all relevant objects before irrelevant objects.
3.3. Rank Measure
- Normalized Discounted Cumulative Gain (NDCG) [40] measures the quality of the order by essentially taking into account the rank assigned to the most relevant objects. This measure is essentially used in the case where there are several degrees of relevance, for example (not very relevant, somewhat relevant, very relevant. It thus measures the gain that each document according to its position in the list of results. It is given by Equation (6).
3.4. Other Measures
- The coverage corresponds to the fraction of the data for which the recommender system can predict recommendations. For example, collaborative filtering systems do not cover the case of new users and new objects;
- Complexity, calculation time, and response time measure how quickly recommendations are generated. In some applications, especially for online recommendations, response time can be a critical parameter;
- Novelty or Serendipity measures how well the recommender system suggests new or unfamiliar items; this corresponds to the exploration factor of the recommendation.
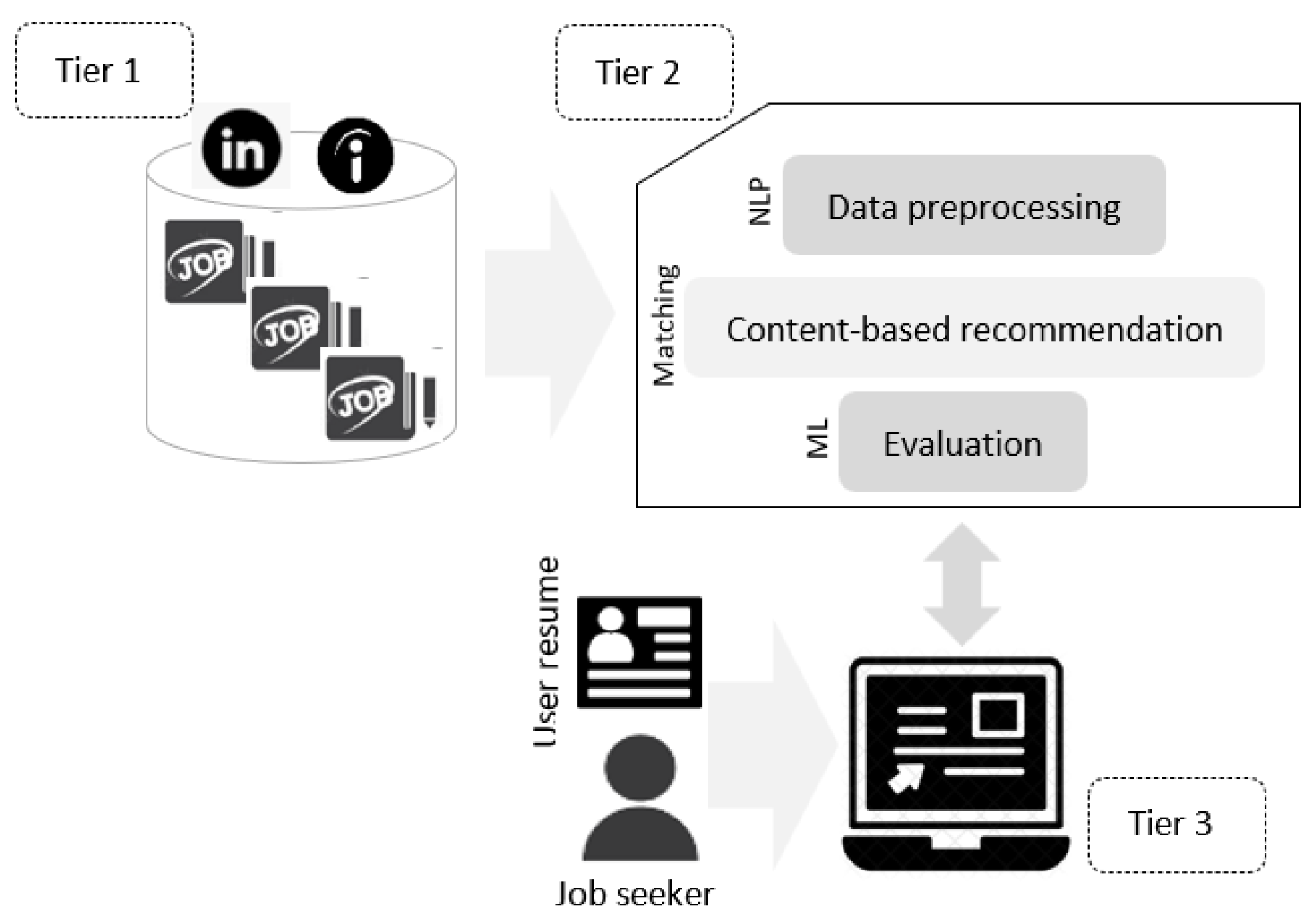
4. Methodology
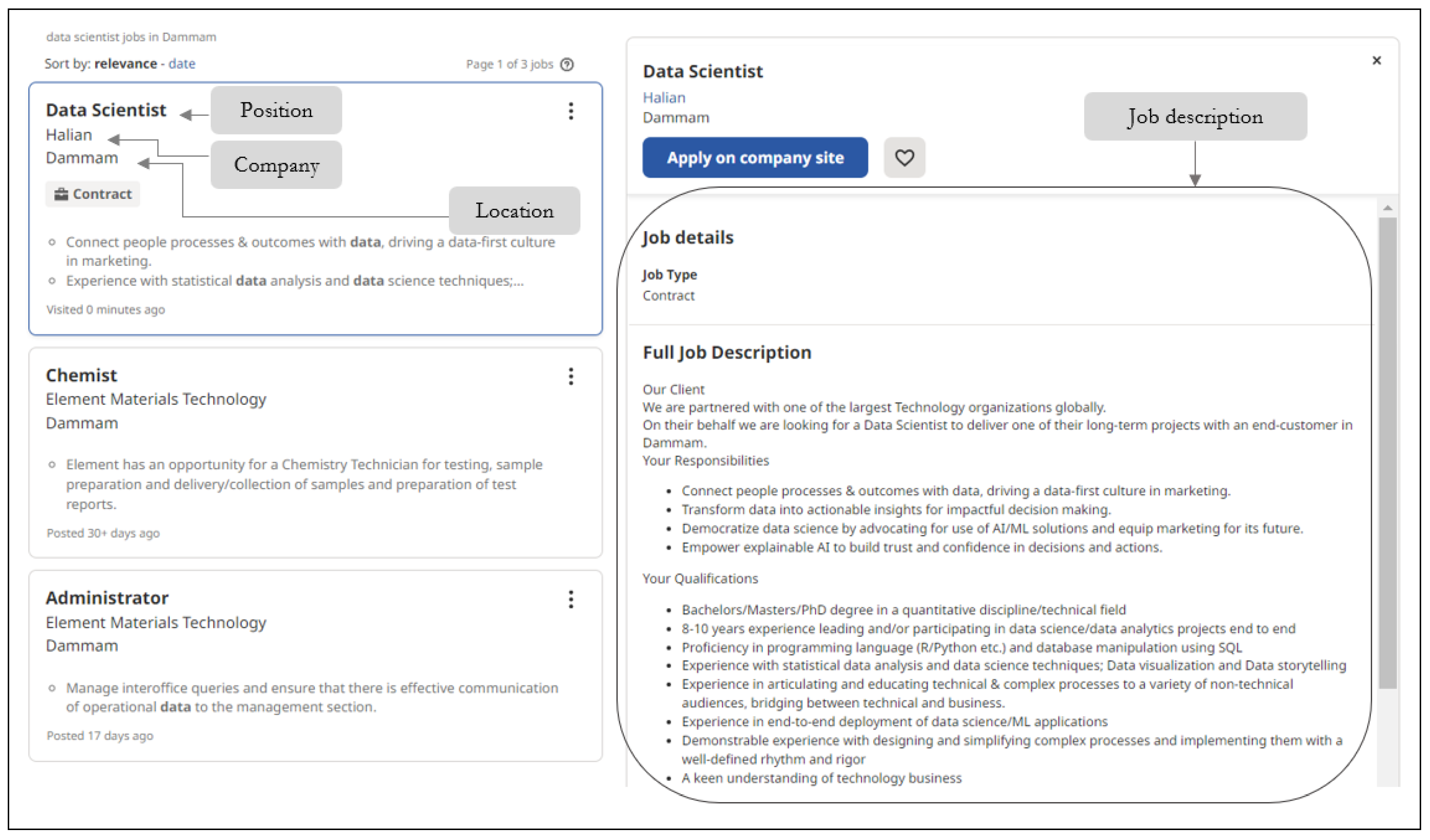
- Web scrapping: job offers are scrapped from sa.indeed.com (Three major cities were considered: Jeddah, Riyadh, and Dammam).
- Data pre-processing: Tokenization and keywords extraction.
- Matched job recommendations: similarity is used to rank recommended job offers for a job seeker’s resume.
4.1. Data Source
4.2. Data Pre-Processing: Tokenization and Keywords Extraction
- Clean tags: remove special, unrecognized characters, and HTML tags.
- Tokenization: segmentation of data into meaningful units—terms, sometimes called tokens. Words are character strings separated by spaces and punctuation marks. A term is defined as a word or a series of consecutive words. More generally, n-gram designates a term formed of n consecutive words.
- Lemmatization: Normalization of terms to disregard variations in inflection (essentially related to conjugation, capital letters, and declension). We retain the masculine singular for an adjective and the infinitive for a conjugated verb.
- Stop words: filtering of terms containing no semantic information (e.g., “of”, “and”, “or”, “but”, “we”, “for”); the list of these tool words is determined manually for each language. The pruning of the most frequent terms (terms present on all the texts and therefore without impact on their characterization) is also performed; the only frequency is a hyper-parameter of the approach.
4.3. Matched Jobs Recommendation
- Jaccard Coefficient (JC): JC is a method to compare elements of two sets to identify which elements are shared between two sets and which are distinct. It is a similarity measure for two sets of data with results ranging from 0% to 100%. Two sets can be said to be similar when the result is close to 100%. JC is given as follows [50]:
- Cosine similarity (CS): CS is also a measure which finds the similarity between two sets of a non-zero vector. It is a weighted vector space model utilized in the process of information retrieval. The similarity is measured by using the Euclidean cosine rule, i.e., by taking the inner product space of two non-zero vectors that measures the cosine of the angle between the two vectors. If the angle between two vectors is 0 deg, then the cosine of 0 is 1; this indicates that the two non-zero vectors are similar to each other. To weight the words, we used the well-known word2vec vector space model [51,52].
5. Results
5.1. Validating the Recommendation
- Twenty-eight resumes classified as belonging to the Data Scientist job class out of a total of twenty-eight resumes, which is very satisfactory;
- For the Civil Engineer job class, 20 out of 28 were identified as belonging to this job class, which is quite satisfactory;
- For the Network Security Engine job class, 25 out of 31 resumes were identified, which is very satisfactory;
- For the Sales job class, 40 out of 44 resumes were classified as belonging to it, which is very satisfactory;
- Twenty-four resumes have been classified as belonging to the Electrical Engineering job class out of a total of twenty-eight, which is also quite satisfactory.
5.2. Data Analysis
6. 3-Tier Design for RS
- Percentage of required skills for the required job;
- Percentage of required education degree required for the required job;
- Percentage of the recommended job in major Saudi cities.
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBR | Content-Based Recommender systems |
| CF | Collaborative Filtering |
| CS | Cosine similarity |
| FP | False Positives |
| HRS | Hybrid Recommender Systems |
| IR | Information retrieval |
| JC | Jaccard Coefficient |
| JRS | Job Recommender Systems |
| KNN | K-Nearest Neighbor |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| NDCG | Normalized Discounted Cumulative Gain |
| NLP | Natural Language Processing |
| RMSE | Root Mean Square Error |
| ROC | Receiver Operating Characteristic |
| RS | Recommender Systems |
| TP | True Positives |
References
- Lu, Y.; El Helou, S.; Gillet, D. A Recommender System for Job Seeking and Recruiting Website. In Proceedings of the 22nd International Conference on WWW. Association for Computing Machinery, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 963–966. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Gupta, A.; Bugdayci, A.; Bhasin, A. Modeling Professional Similarity by Mining Professional Career Trajectories. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1945–1954. [Google Scholar] [CrossRef]
- Junior, J.; Vilasbôas, F.; De Castro, L. The Influence of Feature Selection on Job Clustering for an E-recruitment Recommender System. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 12–14 October 2020; Springer: Cham, Switzerland, 2020; pp. 176–187. [Google Scholar] [CrossRef]
- Mohmmadzadeh, H.; Gharehchopogh, F.S. An efficient binary chaotic symbiotic organisms search algorithm approaches for feature selection problems. J. Supercomput. 2021, 77, 9102–9144. [Google Scholar] [CrossRef]
- Mohammadzadeh, H.; Gharehchopogh, F.S. Feature Selection with Binary Symbiotic Organisms Search Algorithm for Email Spam Detection. Int. J. Inf. Technol. Decis. Mak. 2021, 20, 469–515. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S. A Multi-Objective Optimization Algorithm for Feature Selection Problems. Eng. Comput. 2022, 38, 1845–1863. [Google Scholar] [CrossRef]
- Naseri, T.S.; Gharehchopogh, F.S. A Feature Selection Based on the Farmland Fertility Algorithm for Improved Intrusion Detection Systems. J. Netw. Syst. Manag. 2022, 30, 40. [Google Scholar] [CrossRef]
- Goldanloo, M.J.; Gharehchopogh, F.S. A hybrid OBL-based firefly algorithm with symbiotic organisms search algorithm for solving continuous optimization problems. J. Supercomput. 2022, 78, 3998–4031. [Google Scholar] [CrossRef]
- Abedi, M.; Gharehchopogh, F.S. An Improved Opposition Based Learning Firefly Algorithm with Dragonfly Algorithm for Solving Continuous Optimization Problems. Intell. Data Anal. 2020, 24, 309–338. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Gholizadeh, H. A comprehensive survey: Whale Optimization Algorithm and its applications. Swarm Evol. Comput. 2019, 48, 1–24. [Google Scholar] [CrossRef]
- Ntioudis, D.; Masa, P.; Karakostas, A.; Meditskos, G.; Vrochidis, S.; Kompatsiaris, I. Ontology-Based Personalized Job Recommendation Framework for Migrants and Refugees. Big Data Cogn. Comput. 2022, 6, 120. [Google Scholar] [CrossRef]
- Mishra, R.; Rathi, S. Enhanced DSSM (Deep Semantic Structure Modelling) Technique for Job Recommendation. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 7790–7802. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, Y.C.; Hong, J.; Kim, S.W. Exploiting job transition patterns for effective job recommendation. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 2414–2419. [Google Scholar] [CrossRef]
- Sun, N.; Chen, T.; Guo, W.; Ran, L. Enhanced Collaborative Filtering for Personalized E-Government Recommendation. Appl. Sci. 2021, 11, 12119. [Google Scholar] [CrossRef]
- Hu, B.; Long, Z. Collaborative Filtering Recommendation Algorithm Based on User Explicit Preference. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; pp. 1041–1043. [Google Scholar] [CrossRef]
- Wu, L. Collaborative Filtering Recommendation Algorithm for MOOC Resources Based on Deep Learning. Complexity 2021, 2021, 5555226. [Google Scholar] [CrossRef]
- Liu, X.; Li, S. Collaborative Filtering Recommendation Algorithm Based on Similarity of Co-Rating Sequence. In Proceedings of the International Symposium on Electrical, Electronics and Information Engineering, Seoul, Korea, 19–21 February 2021; pp. 458–463. [Google Scholar] [CrossRef]
- Reusens, M.; Lemahieu, W.; Baesens, B.; Sels, L. A Note on Explicit versus Implicit Information for Job Recommendation. Decis. Support Syst. 2017, 98, 26–35. [Google Scholar] [CrossRef]
- Ahmed, S.; Hasan, M.; Hoq, M.N.; Adnan, M.A. User interaction analysis to recommend suitable jobs in career-oriented social networking sites. In Proceedings of the International Conference on Data and Software Engineering (ICoDSE), Denpasar, Indonesia, 26–27 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, K.; Shi, X.; Kumar, A.; Zhu, L.; Natarajan, P. Temporal Learning and Sequence Modeling for a Job Recommender System. In Proceedings of the Recommender Systems Challenge, New York, NY, USA, 15 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 7:1–7:4. [Google Scholar] [CrossRef]
- Lacic, E.; Reiter-Haas, M.; Kowald, D.; Reddy Dareddy, M.; Cho, J.; Lex, E. Using autoencoders for session-based job recommendations. User Model.-User-Adapt. Interact. 2020, 30, 617–658. [Google Scholar] [CrossRef]
- Li, L.; Wang, Z.; Li, C.; Chen, L.; Wang, Y. Collaborative filtering recommendation using fusing criteria against shilling attacks. Connect. Sci. 2022, 34, 1678–1696. [Google Scholar] [CrossRef]
- Javed, U.; Shaukat, K.; Hameed, I.A.; Iqbal, F.; Alam, T.M.; Luo, S. A Review of Content-Based and Context-Based Recommendation Systems. Int. J. Emerg. Technol. Learn. (iJET) 2021, 16, 274–306. [Google Scholar] [CrossRef]
- Joseph, A.; Benjamin, M.J. Movie Recommendation System Using Content-Based Filtering And Cosine Similarity. In Proceedings of the National Conference on Emerging Computer Applications (NCECA), Online, 2 July 2022; Amal Jyothi College of Engineering: Kanjirapally, India, 2022; pp. 405–408. [Google Scholar] [CrossRef]
- Pérez-Almaguer, Y.; Yera, R.; Alzahrani, A.A.; Martínez, L. Content-based group recommender systems: A general taxonomy and further improvements. Expert Syst. Appl. 2021, 184, 115444. [Google Scholar] [CrossRef]
- Forestiero, A.P.G. Recommendation platform in Internet of Things leveraging on a self-organizing multiagent approach. Neural Comput. Appl. 2022, 34, 16049–16060. [Google Scholar] [CrossRef]
- Forestiero, A. Heuristic recommendation technique in Internet of Things featuring swarm intelligence approach. Expert Syst. Appl. 2022, 187, 115904. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model.-User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Rhanoui, M.; Mikram, M.; Yousfi, S.; Kasmi, A.; Zoubeidi, N. A hybrid recommender system for patron driven library acquisition and weeding. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 2809–2819. [Google Scholar] [CrossRef]
- Çano, E. Hybrid Recommender Systems: A Systematic Literature Review. Intell. Data Anal. 2017, 21, 1487–1524. [Google Scholar] [CrossRef]
- Guia, M.; Silva, R.; Bernardino, J. A Hybrid Ontology-Based Recommendation System in e-Commerce. Algorithms 2019, 12, 239. [Google Scholar] [CrossRef] [Green Version]
- Pande, C.; Witschel, H.F.; Martin, A. New Hybrid Techniques for Business Recommender Systems. Appl. Sci. 2022, 12, 4804. [Google Scholar] [CrossRef]
- Kohavi, R.; Longbotham, R. Online Controlled Experiments and A/B Testing. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2017; pp. 922–929. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Error. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; p. 652. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Ting, K.M. Precision. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; p. 780. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and f-measure to roc., informedness, markedness & correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Ferjani, I.; Sassi Hidri, M.; Frihida, A. SiNoptiC: Swarm intelligence optimisation of convolutional neural network architectures for text classification. Int. J. Comput. Appl. Technol. 2002, 68, 82–100. [Google Scholar] [CrossRef]
- Tan, P.N. Receiver Operating Characteristic. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 2349–2352. [Google Scholar] [CrossRef]
- Järvelin, K.; Kekäläinen, J. Cumulated Gain-Based Evaluation of IR Techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Voorhees, E.M.; Tice, D.M. The TREC-8 Question Answering Track. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC), Athens, Greece, 31 May–2 June 2000; pp. 77–82. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Egger, R.; Kroner, M.; Stöckl, A. Web Scraping. In Applied Data Science in Tourism: Interdisciplinary Approaches, Methodologies, and Applications; Egger, R., Ed.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 67–82. [Google Scholar] [CrossRef]
- Salunke, S.S. Selenium Webdriver in Python: Learn with Examples, 1st ed.; CreateSpace Independent Publishing Platform: North Charleston, SC, USA, 2014. [Google Scholar]
- Kenter, T.; de Rijke, M. Short Text Similarity with Word Embeddings. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1411–1420. [Google Scholar] [CrossRef] [Green Version]
- Mihalcea, R.; Corley, C.; Strapparava, C. Corpus-Based and Knowledge-Based Measures of Text Semantic Similarity. In Proceedings of the Twenty-First National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; pp. 775–780. [Google Scholar] [CrossRef]
- Pakray, P.; Bandyopadhyay, S.; Gelbukh, A. Textual entailment using lexical and syntactic similarity. Int. J. Artif. Intell. Appl. 2011, 2, 43–58. [Google Scholar] [CrossRef]
- Barzilay, R.; Elhadad, N. Sentence Alignment for Monolingual Comparable Corpora. In Proceedings of the Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 25–32. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Sternitzke, C.; Bergmann, I. Similarity measures for document mapping: A comparative study on the level of an individual scientist. Scientometrics 2007, 78, 113–130. [Google Scholar] [CrossRef]
- Rong, X. Word2vec Parameter Learning Explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Herremans, D.; Chuan, C. Modeling Musical Context with Word2vec. arXiv 2017, arXiv:1706.09088. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Job Class |
|---|---|
| 0 | Data Scientist |
| 1 | Civil Engineer |
| 2 | Network Security Engineer |
| 3 | Sales |
| 4 | Electrical Engineering |
| Job Class | Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|---|
| JC | Data Scientist | 1.0 | 0.40 | 0.57 | 40 |
| Civil Engineer | 0.35 | 0.67 | 0.46 | 24 | |
| Network Security Engineer | 0.68 | 1.0 | 0.81 | 25 | |
| Sales | 0.57 | 0.40 | 0.47 | 40 | |
| Electrical Engineering | 0.75 | 0.80 | 0.77 | 30 | |
| Macro AVG | 0.67 | 0.65 | 0.62 | 159 | |
| Weighted AVG | 0.70 | 0.61 | 0.60 | 159 | |
| CS | Data Scientist | 1.0 | 0.7 | 0.82 | 40 |
| Civil Engineer | 0.71 | 0.83 | 0.77 | 24 | |
| Network Security Engineer | 0.81 | 1.0 | 0.89 | 25 | |
| Sales | 0.91 | 1.0 | 0.95 | 40 | |
| Electrical Engineering | 0.86 | 0.80 | 0.83 | 30 | |
| Macro AVG | 0.86 | 0.87 | 0.85 | 159 | |
| Weighted AVG | 0.88 | 0.86 | 0.86 | 159 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsaif, S.A.; Sassi Hidri, M.; Eleraky, H.A.; Ferjani, I.; Amami, R. Learning-Based Matched Representation System for Job Recommendation. Computers 2022, 11, 161. https://doi.org/10.3390/computers11110161
Alsaif SA, Sassi Hidri M, Eleraky HA, Ferjani I, Amami R. Learning-Based Matched Representation System for Job Recommendation. Computers. 2022; 11(11):161. https://doi.org/10.3390/computers11110161
Chicago/Turabian StyleAlsaif, Suleiman Ali, Minyar Sassi Hidri, Hassan Ahmed Eleraky, Imen Ferjani, and Rimah Amami. 2022. "Learning-Based Matched Representation System for Job Recommendation" Computers 11, no. 11: 161. https://doi.org/10.3390/computers11110161