
Integrating Artificial Intelligence for Advancing Multiple-Cancer Early Detection via Serum Biomarkers: A Narrative Review

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
1.1. Background and Motivation
1.2. Role of Artificial Intelligence in MCED
2. Trajectory of Early Cancer Detection Methods
2.1. Evolutionary Overview of Multiple-Cancer Early Detection
2.2. Advancements in Imaging and Endoscopic Tools
2.3. Emergence of Liquid Biopsy-Based Approaches
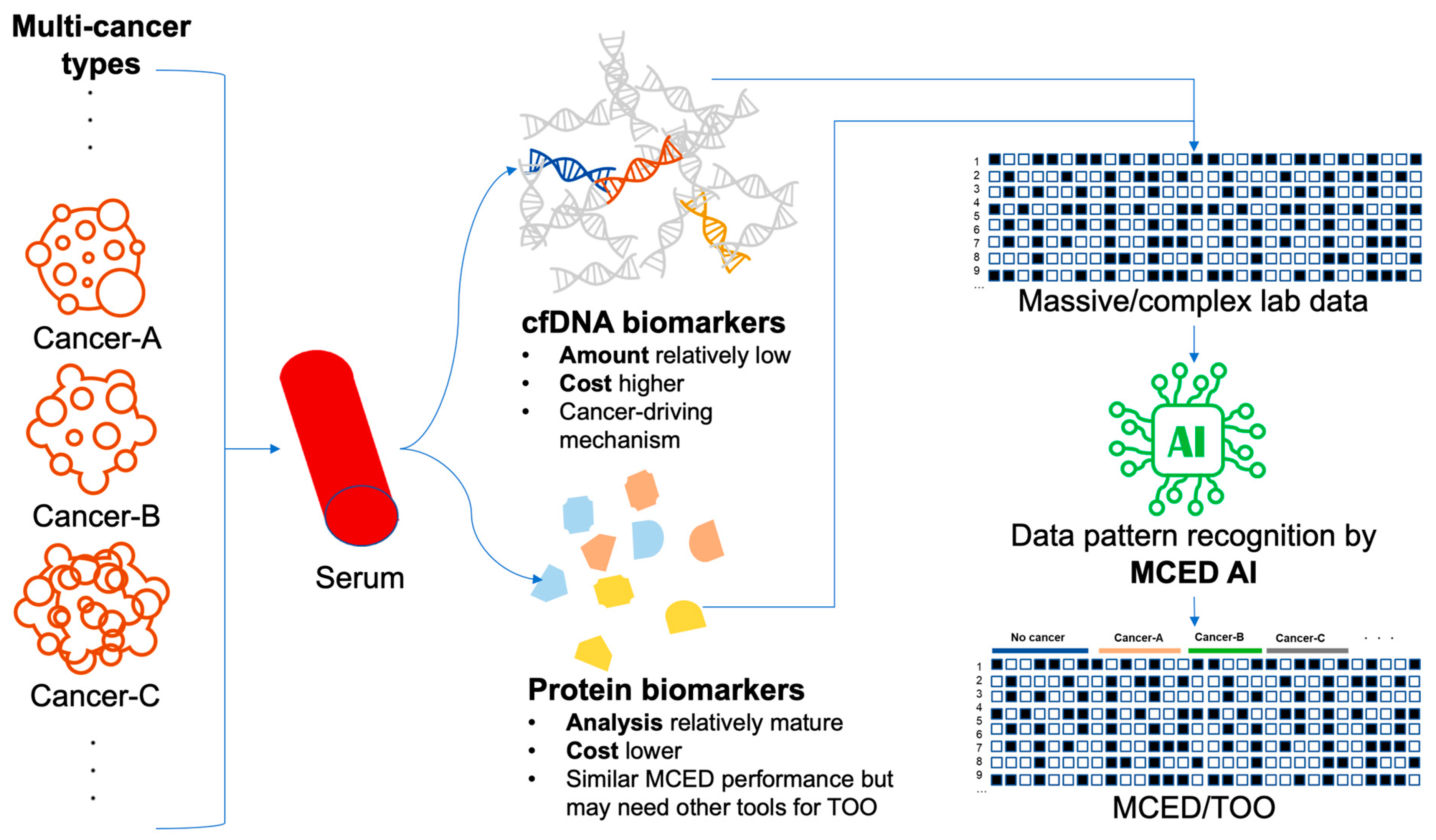
3. Serum Biomarkers as Critical Indicators
3.1. Protein Biomarkers: Unveiling Diagnostic Potential
3.2. Cell-Free DNA Biomarkers: Unleashing Genomic Clues
4. Synergizing AI Algorithms for Biomarker Analysis
4.1. Classical Machine-Learning Techniques in Biomarker Interpretation
4.2. Unveiling Deep Learning’s Potential in Biomarker Analysis
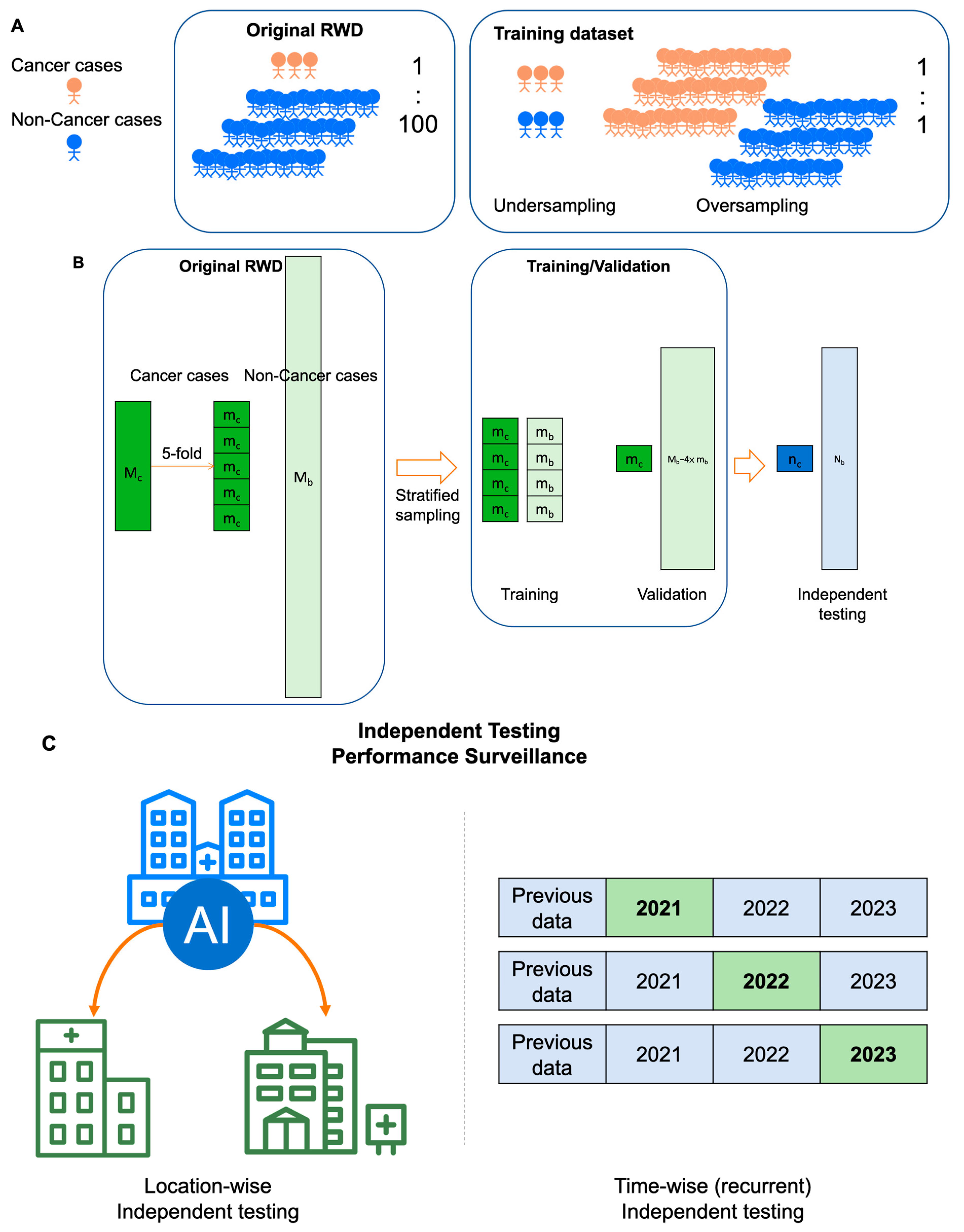
5. Training and Validation of AI Models for MCED
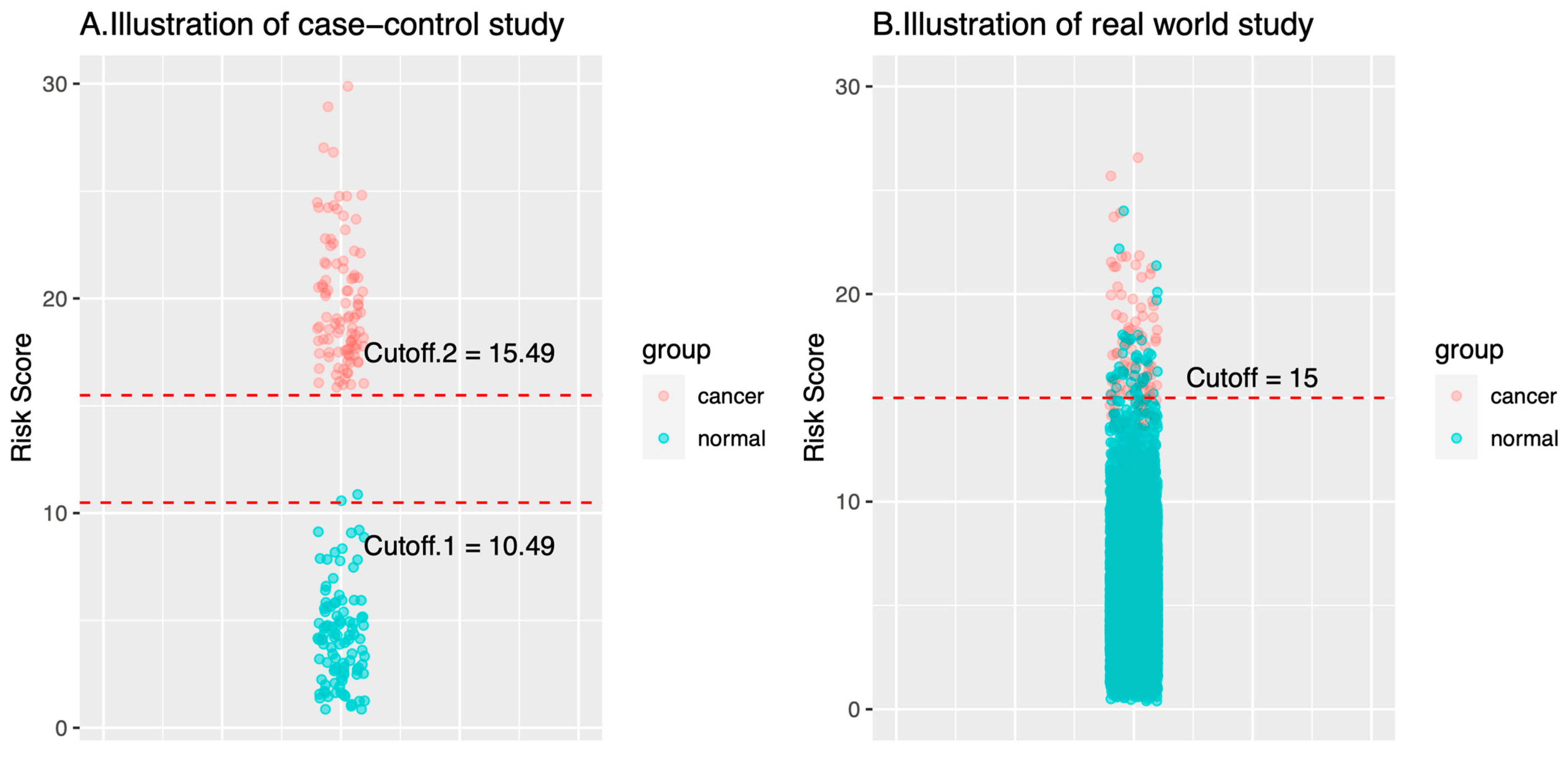
5.1. Impacts of Training Dataset: Case-Control, Retrospective Cohort, or Prospective Cohort?
- On cancer cases: Specimens of the cancer cases in a case-control study are typically collected in more advanced stages than the specimens of a real-world cohort study. The reason for that is that the specimens of the cancer cases in a case-control study are collected when the diagnosis of cancer has been made, which is often associated with symptoms/signs that are caused by cancers. In this case, the cancers show their malignant behaviors, like space occupying or mass effect. By contrast, specimens of the cancer cases in a real-world cohort are collected long before cancer diagnosis or any symptom/sign. Such conditions are usually closer to the health checkup population in the real world. Theoretically, biomarkers in presymptomatic or asymptomatic cancer cases would be closer to those of healthy controls than in the symptomatic cancer cases.
- On healthy cases: The number of healthy control cases in a case-control study is usually up to several hundred given the fact that the ratio of cancer versus control ratio is set around 1:1–1:4 [15,17,34,49]. The relatively small number cannot represent the large diversity in the healthy control cases. As a result, there are fewer outlier cases. Fewer healthy outliers would simplify the classification problem (i.e., classify cancers versus healthy). AI models trained with fewer healthy outliers may therefore not have a classification threshold that can be used in the real world.
5.2. Cross-Validation vs. Independent Testing: Generalizability or Continual Monitoring Matters?
6. Challenges and Opportunities
6.1. Data Quality and Quantity: Navigating the Complex Landscape
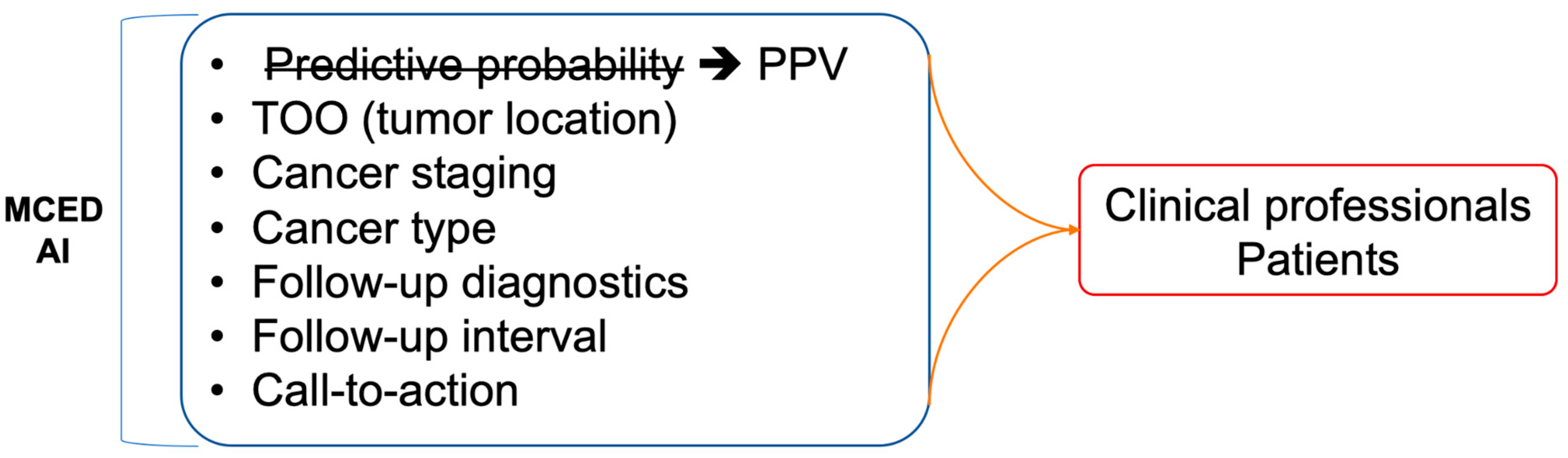
6.2. Interpretability, Explainability, and Integration: Bridging the Gap in AI-Driven Insights
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Acronyms and Abbreviations
| AI | artificial intelligence |
| BEAMing | beads, emulsions, amplification, and magnetics |
| CAPP-Seq | CAncer Personalized Profiling by deep Sequencing |
| CEA | carcinoembryonic antigen |
| cfDNA | cell-free DNA |
| CLE | confocal laser endomicroscopy |
| CTC | circulating tumor cells |
| ctDNA | circulating tumor DNA |
| ctRNA | circulating tumor RNA |
| CT | computed tomography |
| ddPCR | droplet digital PCR |
| DL | deep learning |
| HER2 | human epidermal growth factor receptor 2 |
| KFCV | k-fold cross-validation |
| MRI | magnetic resonance imaging |
| MAF | mutant allele fraction |
| MCED | multicancer early detection |
| ML | machine learning |
| NBI | narrow-band imaging |
| NGS | next generation sequencing |
| NKFCV | nested k-fold cross-validation |
| PET | positron emission tomography |
| TPA | tissue polypeptide antigen |
| TPS | tissue polypeptide specific antigen |
References
- Zutshi, V.; Kaur, G. Remembering George Papanicolaou: A Revolutionary Who Invented the Pap Smear Test. J. Colposc. Low. Genit. Tract. Pathol. 2023, 1, 47–49. [Google Scholar]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer statistics, 2022. CA Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef]
- Vogelstein, B.; Kinzler, K.W. The Path to Cancer—Three Strikes and You’re Out. N. Engl. J. Med. 2015, 373, 1895–1898. [Google Scholar] [CrossRef] [PubMed]
- Fedeli, U.; Barbiellini Amidei, C.; Han, X.; Jemal, A. Changes in cancer-related mortality during the COVID-19 pandemic in the United States. JNCI J. Natl. Cancer Inst. 2024, 116, 167–169. [Google Scholar] [CrossRef]
- Guerra, C.E.; Sharma, P.V.; Castillo, B.S. Multi-Cancesr Early Detection: The New Frontier in Cancer Early Detection. Annu. Rev. Med. 2024, 75, 67–81. [Google Scholar] [CrossRef]
- Wang, H.Y.; Chen, C.H.; Shi, S.; Chung, C.R.; Wen, Y.H.; Wu, M.H.; Lebowitz, M.S.; Zhou, J.; Lu, J.J. Improving Multi-Tumor Biomarker Health Check-Up Tests with Machine Learning Algorithms. Cancers 2020, 12, 1442. [Google Scholar] [CrossRef] [PubMed]
- Loud, J.T.; Murphy, J. Cancer Screening and Early Detection in the 21st Century. Semin. Oncol. Nurs. 2017, 33, 121–128. [Google Scholar] [CrossRef]
- Uncertainty Around Tests That Screen for Many Cancers—NCI [Internet]. 2022. Available online: https://www.cancer.gov/news-events/cancer-currents-blog/2022/finding-cancer-early-mced-tests (accessed on 25 October 2023).
- Huguet, N.; Angier, H.; Rdesinski, R.; Hoopes, M.; Marino, M.; Holderness, H.; DeVoe, J.E. Cervical and colorectal cancer screening prevalence before and after Affordable Care Act Medicaid expansion. Prev. Med. 2019, 124, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Hackshaw, A.; Cohen, S.S.; Reichert, H.; Kansal, A.R.; Chung, K.C.; Ofman, J.J. Estimating the population health impact of a multi-cancer early detection genomic blood test to complement existing screening in the US and UK. Br. J. Cancer 2021, 125, 1432–1442. [Google Scholar] [CrossRef]
- Wang, H.Y.; Chang, S.C.; Lin, W.Y.; Chen, C.H.; Chiang, S.H.; Huang, K.Y.; Chu, B.Y.; Lu, J.J.; Lee, T.Y. Machine Learning-Based Method for Obesity Risk Evaluation Using Single-Nucleotide Polymorphisms Derived from Next-Generation Sequencing. J. Comput. Biol. 2018, 25, 1347–1360. [Google Scholar] [CrossRef]
- Tseng, Y.J.; Huang, C.E.; Wen, C.N.; Lai, P.Y.; Wu, M.H.; Sun, Y.C.; Wang, H.Y.; Lu, J.J. Predicting breast cancer metastasis by using serum biomarkers and clinicopathological data with machine learning technologies. Int. J. Med. Inf. 2019, 128, 79–86. [Google Scholar] [CrossRef]
- Tseng, Y.J.; Wang, H.Y.; Lin, T.W.; Lu, J.J.; Hsieh, C.H.; Liao, C.T. Development of a Machine Learning Model for Survival Risk Stratification of Patients with Advanced Oral Cancer. JAMA Netw. Open 2020, 3, e2011768. [Google Scholar] [CrossRef]
- Voitechovič, E.; Pauliukaite, R. Electrochemical multisensor systems and arrays in the era of artificial intelligence. Curr. Opin. Electrochem. 2023, 42, 101411. [Google Scholar] [CrossRef]
- Cohen, J.D.; Li, L.; Wang, Y.; Thoburn, C.; Afsari, B.; Danilova, L.; Douville, C.; Javed, A.A.; Wong, F.; Mattox, A. Detection and localization of surgically resectable cancers with a multi-analyte blood test. Science 2018, 359, 926–930. [Google Scholar] [CrossRef]
- Wang, H.Y.; Hsieh, C.H.; Wen, C.N.; Wen, Y.H.; Chen, C.H.; Lu, J.J. Cancers Screening in an Asymptomatic Population by Using Multiple Tumour Markers. PLoS ONE 2016, 11, e0158285. [Google Scholar] [CrossRef]
- Luan, Y.; Zhong, G.; Li, S.; Wu, W.; Liu, X.; Zhu, D.; Feng, Y.; Zhang, Y.; Duan, C.; Mao, M. A panel of seven protein tumour markers for effective and affordable multi-cancer early detection by artificial intelligence: A large-scale and multicentre case–control study. eClinicalMedicine 2023, 61, 102041. [Google Scholar] [CrossRef] [PubMed]
- Schrag, D.; Beer, T.M.; McDonnell, C.H.; Nadauld, L.; Dilaveri, C.A.; Reid, R.; Marinac, C.R.; Chung, K.C.; Lopatin, M.; Fung, E.T. Blood-based tests for multicancer early detection (PATHFINDER): A prospective cohort study. Lancet 2023, 402, 1251–1260. [Google Scholar] [CrossRef] [PubMed]
- Ahlquist, D.A. Universal cancer screening: Revolutionary, rational, and realizable. Npj Precis. Oncol. 2018, 2, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Neal, R.D.; Johnson, P.; Clarke, C.A.; Hamilton, S.A.; Zhang, N.; Kumar, H.; Swanton, C.; Sasieni, P. Cell-Free DNA–Based Multi-Cancer Early Detection Test in an Asymptomatic Screening Population (NHS-Galleri): Design of a Pragmatic, Prospective Randomised Controlled Trial. Cancers 2022, 14, 4818. [Google Scholar] [CrossRef] [PubMed]
- Hall, I.J. Patterns and Trends in Cancer Screening in the United States. Prev. Chronic. Dis. 2018, 15, E97. [Google Scholar] [CrossRef] [PubMed]
- Zugni, F.; Padhani, A.R.; Koh, D.M.; Summers, P.E.; Bellomi, M.; Petralia, G. Whole-body magnetic resonance imaging (WB-MRI) for cancer screening in asymptomatic subjects of the general population: Review and recommendations. Cancer Imaging 2020, 20, 34. [Google Scholar] [CrossRef] [PubMed]
- Brenner, D.J.; Elliston, C.D. Estimated Radiation Risks Potentially Associated with Full-Body CT Screening. Radiology 2004, 232, 735–738. [Google Scholar] [CrossRef] [PubMed]
- Brito-Rocha, T.; Constâncio, V.; Henrique, R.; Jerónimo, C. Shifting the Cancer Screening Paradigm: The Rising Potential of Blood-Based Multi-Cancer Early Detection Tests. Cells 2023, 12, 935. [Google Scholar] [CrossRef] [PubMed]
- Furtado, C.D.; Aguirre, D.A.; Sirlin, C.B.; Dang, D.; Stamato, S.K.; Lee, P.; Sani, F.; Brown, M.A.; Levin, D.L.; Casola, G. Whole-Body CT Screening: Spectrum of Findings and Recommendations in 1192 Patients. Radiology 2005, 237, 385–394. [Google Scholar] [CrossRef]
- Schöder, H.; Gönen, M. Screening for cancer with PET and PET/CT: Potential and limitations. J. Nucl. Med. Off. Publ. Soc. Nucl. Med. 2007, 48 (Suppl. 1), 4S–18S. [Google Scholar]
- Han, W.; Kong, R.; Wang, N.; Bao, W.; Mao, X.; Lu, J. Confocal Laser Endomicroscopy for Detection of Early Upper Gastrointestinal Cancer. Cancers 2023, 15, 776. [Google Scholar] [CrossRef]
- Kim, S.Y.; Kim, H.S.; Park, H.J. Adverse events related to colonoscopy: Global trends and future challenges. World J. Gastroenterol. 2019, 25, 190–204. [Google Scholar] [CrossRef]
- Barbany, G.; Arthur, C.; Liedén, A.; Nordenskjöld, M.; Rosenquist, R.; Tesi, B.; Wallander, K.; Tham, E. Cell-free tumour DNA testing for early detection of cancer—A potential future tool. J. Intern. Med. 2019, 286, 118–136. [Google Scholar] [CrossRef]
- Bettegowda, C.; Sausen, M.; Leary, R.J.; Kinde, I.; Wang, Y.; Agrawal, N.; Bartlett, B.R.; Wang, H.; Luber, B.; Alani, R.M. Detection of Circulating Tumor DNA in Early- and Late-Stage Human Malignancies. Sci. Transl. Med. 2014, 6, 224ra24. [Google Scholar] [CrossRef] [PubMed]
- Cree, I.A.; Uttley, L.; Buckley Woods, H.; Kikuchi, H.; Reiman, A.; Harnan, S.; Whiteman, B.L.; Philips, S.T.; Messenger, M. The evidence base for circulating tumour DNA blood-based biomarkers for the early detection of cancer: A systematic mapping review. BMC Cancer 2017, 17, 697. [Google Scholar] [CrossRef] [PubMed]
- Aravanis, A.M.; Lee, M.; Klausner, R.D. Next-Generation Sequencing of Circulating Tumor DNA for Early Cancer Detection. Cell 2017, 168, 571–574. [Google Scholar] [CrossRef] [PubMed]
- Wen, Y.H.; Chang, P.Y.; Hsu, C.M.; Wang, H.Y.; Chiu, C.T.; Lu, J.J. Cancer screening through a multi-analyte serum biomarker panel during health check-up examinations: Results from a 12-year experience. Clin. Chim. Acta Int. J. Clin. Chem. 2015, 450, 273–276. [Google Scholar] [CrossRef] [PubMed]
- Molina, R.; Marrades, R.M.; Augé, J.M.; Escudero, J.M.; Viñolas, N.; Reguart, N.; Ramirez, J.; Filella, X.; Molins, L.; Agustí, A. Assessment of a Combined Panel of Six Serum Tumor Markers for Lung Cancer. Am. J. Respir. Crit. Care Med. 2016, 193, 427–437. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Wang, H.Y.; Shi, P.; Sun, R.; Wang, X.; Luo, Z.; Zeng, F.; Lebowitz, M.S.; Lin, W.Y.; Lu, J.J. Long short-term memory model—A deep learning approach for medical data with irregularity in cancer predication with tumor markers. Comput. Biol. Med. 2022, 144, 105362. [Google Scholar] [CrossRef] [PubMed]
- Bodaghi, A.; Fattahi, N.; Ramazani, A. Biomarkers: Promising and valuable tools towards diagnosis, prognosis and treatment of Covid-19 and other diseases. Heliyon 2023, 9, e13323. [Google Scholar] [CrossRef] [PubMed]
- Hartl, J.; Kurth, F.; Kappert, K.; Horst, D.; Mülleder, M.; Hartmann, G.; Ralser, M. Quantitative protein biomarker panels: A path to improved clinical practice through proteomics. EMBO Mol. Med. 2023, 15, e16061. [Google Scholar] [CrossRef] [PubMed]
- Messner, C.B.; Demichev, V.; Wendisch, D.; Michalick, L.; White, M.; Freiwald, A.; Textoris-Taube, K.; Vernardis, S.I.; Egger, A.S.; Kreidl, M. Ultra-High-Throughput Clinical Proteomics Reveals Classifiers of COVID-19 Infection. Cell Syst. 2020, 11, 11–24.e4. [Google Scholar] [CrossRef]
- Landegren, U.; Hammond, M. Cancer diagnostics based on plasma protein biomarkers: Hard times but great expectations. Mol. Oncol. 2021, 15, 1715–1726. [Google Scholar] [CrossRef]
- Vignoli, A.; Tenori, L.; Morsiani, C.; Turano, P.; Capri, M.; Luchinat, C. Serum or Plasma (and Which Plasma), That Is the Question. J. Proteome Res. 2022, 21, 1061–1072. [Google Scholar] [CrossRef]
- Rai, A.J.; Gelfand, C.A.; Haywood, B.C.; Warunek, D.J.; Yi, J.; Schuchard, M.D.; Mehigh, R.J.; Cockrill, S.L.; Scott, G.B.; Tammen, H. HUPO Plasma Proteome Project specimen collection and handling: Towards the standardization of parameters for plasma proteome samples. Proteomics 2005, 5, 3262–3277. [Google Scholar] [CrossRef]
- Wong, Y.L.; Ramanathan, A.; Yuen, K.M.; Mustafa, W.M.W.; Abraham, M.T.; Tay, K.K.; Rahman, Z.A.A.; Chen, Y. Comparative sera proteomics analysis of differentially expressed proteins in oral squamous cell carcinoma. PeerJ 2021, 9, e11548. [Google Scholar] [CrossRef]
- Bader, J.M.; Albrecht, V.; Mann, M. MS-Based Proteomics of Body Fluids: The End of the Beginning. Mol. Cell Proteom. MCP 2023, 22, 100577. [Google Scholar] [CrossRef]
- Fu, Q.; Kowalski, M.P.; Mastali, M.; Parker, S.J.; Sobhani, K.; van den Broek, I.; Hunter, C.L.; Van Eyk, J.E. Highly Reproducible Automated Proteomics Sample Preparation Workflow for Quantitative Mass Spectrometry. J. Proteome Res. 2018, 17, 420–428. [Google Scholar] [CrossRef]
- Wang, Z.; Tober-Lau, P.; Farztdinov, V.; Lemke, O.; Schwecke, T.; Steinbrecher, S.; Muenzner, J.; Kriedemann, H.; Sander, L.E.; Hartl, J. The human host response to monkeypox infection: A proteomic case series study. EMBO Mol. Med. 2022, 14, e16643. [Google Scholar] [CrossRef]
- Percy, A.J.; Yang, J.; Chambers, A.G.; Mohammed, Y.; Miliotis, T.; Borchers, C.H. Protocol for Standardizing High-to-Moderate Abundance Protein Biomarker Assessments Through an MRM-with-Standard-Peptides Quantitative Approach. Adv. Exp. Med. Biol. 2016, 919, 515–530. [Google Scholar]
- Füzéry, A.K.; Levin, J.; Chan, M.M.; Chan, D.W. Translation of proteomic biomarkers into FDA approved cancer diagnostics: Issues and challenges. Clin. Proteom. 2013, 10, 13. [Google Scholar] [CrossRef] [PubMed]
- Van Gorp, T.; Cadron, I.; Despierre, E.; Daemen, A.; Leunen, K.; Amant, F.; Timmerman, D.; De Moor, B.; Vergote, I. HE4 and CA125 as a diagnostic test in ovarian cancer: Prospective validation of the Risk of Ovarian Malignancy Algorithm. Br. J. Cancer 2011, 104, 863–870. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.S.; Kang, K.N.; Shin, Y.S.; Lee, J.E.; Jang, J.Y.; Kim, C.W. Diagnostic value of combining tumor and inflammatory biomarkers in detecting common cancers in Korea. Clin. Chim. Acta 2021, 516, 169–178. [Google Scholar] [CrossRef] [PubMed]
- Salvi, S.; Gurioli, G.; De Giorgi, U.; Conteduca, V.; Tedaldi, G.; Calistri, D.; Casadio, V. Cell-free DNA as a diagnostic marker for cancer: Current insights. OncoTargets Ther. 2016, 9, 6549–6559. [Google Scholar] [CrossRef] [PubMed]
- De Mattos-Arruda, L.; Caldas, C. Cell-free circulating tumour DNA as a liquid biopsy in breast cancer. Mol. Oncol. 2016, 10, 464–474. [Google Scholar] [CrossRef] [PubMed]
- Gao, Q.; Zeng, Q.; Wang, Z.; Li, C.; Xu, Y.; Cui, P.; Zhu, X.; Lu, H.; Wang, G.; Cai, S. Circulating cell-free DNA for cancer early detection. Innovation 2022, 3, 100259. [Google Scholar] [CrossRef]
- Bronkhorst, A.J.; Ungerer, V.; Holdenrieder, S. The emerging role of cell-free DNA as a molecular marker for cancer management. Biomol. Detect. Quantif. 2019, 17, 100087. [Google Scholar] [CrossRef] [PubMed]
- Kalendar, R.; Shustov, A.V.; Akhmetollayev, I.; Kairov, U. Designing Allele-Specific Competitive-Extension PCR-Based Assays for High-Throughput Genotyping and Gene Characterization. Front. Mol. Biosci. 2022, 9, 773956. [Google Scholar] [CrossRef]
- Ahmad, E.; Ali, A.; Nimisha; Kumar Sharma, A.; Ahmed, F.; Mehdi Dar, G.; Mohan Singh, A.; Apurva Kumar, A.; Athar, A.; Parveen, F. Molecular approaches in cancer. Clin. Chim. Acta Int. J. Clin. Chem. 2022, 537, 60–73. [Google Scholar] [CrossRef]
- Ito, K.; Suzuki, Y.; Saiki, H.; Sakaguchi, T.; Hayashi, K.; Nishii, Y.; Watanabe, F.; Hataji, O. Utility of Liquid Biopsy by Improved PNA-LNA PCR Clamp Method for Detecting EGFR Mutation at Initial Diagnosis of Non-Small-Cell Lung Cancer: Observational Study of 190 Consecutive Cases in Clinical Practice. Clin. Lung Cancer 2018, 19, 181–190. [Google Scholar] [CrossRef]
- Heitzer, E.; Haque, I.S.; Roberts, C.E.S.; Speicher, M.R. Current and future perspectives of liquid biopsies in genomics-driven oncology. Nat. Rev. Genet. 2019, 20, 71–88. [Google Scholar] [CrossRef]
- Zhai, J.; Arikit, S.; Simon, S.A.; Kingham, B.F.; Meyers, B.C. Rapid construction of parallel analysis of RNA end (PARE) libraries for Illumina sequencing. Methods 2014, 67, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Belic, J.; Koch, M.; Ulz, P.; Auer, M.; Gerhalter, T.; Mohan, S.; Fischereder, K.; Petru, E.; Bauernhofer, T.; Geigl, J.B. Rapid Identification of Plasma DNA Samples with Increased ctDNA Levels by a Modified FAST-SeqS Approach. Clin. Chem. 2015, 61, 838–849. [Google Scholar] [CrossRef] [PubMed]
- Murtaza, M.; Dawson, S.J.; Tsui, D.W.Y.; Gale, D.; Forshew, T.; Piskorz, A.M.; Parkinson, C.; Chin, S.F.; Kingsbury, Z.; Wong, A.S. Non-invasive analysis of acquired resistance to cancer therapy by sequencing of plasma DNA. Nature 2013, 497, 108–112. [Google Scholar] [CrossRef]
- Newman, A.M.; Lovejoy, A.F.; Klass, D.M.; Kurtz, D.M.; Chabon, J.J.; Scherer, F.; Stehr, H.; Liu, C.L.; Bratman, S.V.; Say, C. Integrated digital error suppression for improved detection of circulating tumor DNA. Nat. Biotechnol. 2016, 34, 547–555. [Google Scholar] [CrossRef]
- Lanman, R.B.; Mortimer, S.A.; Zill, O.A.; Sebisanovic, D.; Lopez, R.; Blau, S.; Collisson, E.A.; Divers, S.G.; Hoon, D.S.; Kopetz, E.S. Analytical and Clinical Validation of a Digital Sequencing Panel for Quantitative, Highly Accurate Evaluation of Cell-Free Circulating Tumor DNA. PLoS ONE 2015, 10, e0140712. [Google Scholar] [CrossRef]
- García-Foncillas, J.; Alba, E.; Aranda, E.; Díaz-Rubio, E.; López-López, R.; Tabernero, J.; Vivancos, A. Incorporating BEAMing technology as a liquid biopsy into clinical practice for the management of colorectal cancer patients: An expert taskforce review. Ann. Oncol. Off. J. Eur. Soc. Med. Oncol. 2017, 28, 2943–2949. [Google Scholar] [CrossRef] [PubMed]
- Fiala, C.; Diamandis, E.P. Utility of circulating tumor DNA in cancer diagnostics with emphasis on early detection. BMC Med. 2018, 16, 166. [Google Scholar] [CrossRef] [PubMed]
- Manokhina, I.; Singh, T.K.; Peñaherrera, M.S.; Robinson, W.P. Quantification of cell-free DNA in normal and complicated pregnancies: Overcoming biological and technical issues. PLoS ONE 2014, 9, e101500. [Google Scholar] [CrossRef] [PubMed]
- Davies, M.P.A.; Sato, T.; Ashoor, H.; Hou, L.; Liloglou, T.; Yang, R.; Field, J.K. Plasma protein biomarkers for early prediction of lung cancer. eBioMedicine 2023, 93, 104686. [Google Scholar] [CrossRef] [PubMed]
- Trinidad, C.V.; Pathak, H.B.; Cheng, S.; Tzeng, S.C.; Madan, R.; Sardiu, M.E.; Bantis, L.E.; Deighan, C.; Jewell, A.; Rayamajhi, S. Lineage specific extracellular vesicle-associated protein biomarkers for the early detection of high grade serous ovarian cancer. Sci. Rep. 2023, 13, 18341. [Google Scholar] [CrossRef] [PubMed]
- Tivey, A.; Church, M.; Rothwell, D.; Dive, C.; Cook, N. Circulating tumour DNA—Looking beyond the blood. Nat. Rev. Clin. Oncol. 2022, 19, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Han, S.J.; Yoo, S.; Choi, S.H.; Hwang, E.H. Actual half-life of alpha-fetoprotein as a prognostic tool in pediatric malignant tumors. Pediatr. Surg. Int. 1997, 12, 599–602. [Google Scholar] [CrossRef] [PubMed]
- Riedinger, J.M.; Wafflart, J.; Ricolleau, G.; Eche, N.; Larbre, H.; Basuyau, J.P.; Dalifard, I.; Hacene, K.; Pichon, M.F. CA 125 half-life and CA 125 nadir during induction chemotherapy are independent predictors of epithelial ovarian cancer outcome: Results of a French multicentric study. Ann. Oncol. Off. J. Eur. Soc. Med. Oncol. 2006, 17, 1234–1238. [Google Scholar] [CrossRef]
- Halner, A.; Hankey, L.; Liang, Z.; Pozzetti, F.; Szulc, D.A.; Mi, E.; Liu, G.; Kessler, B.M.; Syed, J.; Liu, P.J. DEcancer: Machine learning framework tailored to liquid biopsy based cancer detection and biomarker signature selection. iScience 2023, 26, 106610. [Google Scholar] [CrossRef]
- Lin, W.Y.; Chen, C.H.; Tseng, Y.J.; Tsai, Y.T.; Chang, C.Y.; Wang, H.Y.; Chen, C.K. Predicting post-stroke activities of daily living through a machine learning-based approach on initiating rehabilitation. Int. J. Med. Inf. 2018, 111, 159–164. [Google Scholar] [CrossRef] [PubMed]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef]
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2007, 2, 59–77. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Huang, G. Application of support vector machine in cancer diagnosis. Med. Oncol. Northwood Lond. Engl. 2011, 28 (Suppl. 1), S613–S618. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.Y.; Chung, C.R.; Chen, C.J.; Lu, K.P.; Tseng, Y.J.; Chang, T.H.; Wu, M.H.; Huang, W.T.; Lin, T.W.; Liu, T.P.; et al. Clinically Applicable System for Rapidly Predicting Enterococcus faecium Susceptibility to Vancomycin. Microbiol. Spectr. 2021, 9, e0091321. [Google Scholar] [CrossRef] [PubMed]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef]
- Liu, M.C.; Oxnard, G.R.; Klein, E.A.; Swanton, C.; Seiden, M.V.; CCGA Consortium. Sensitive and specific multi-cancer detection and localization using methylation signatures in cell-free DNA. Ann. Oncol. Off. J. Eur. Soc. Med. Oncol. 2020, 31, 745–759. [Google Scholar] [CrossRef]
- Cebekhulu, E.; Onumanyi, A.J.; Isaac, S.J. Performance Analysis of Machine Learning Algorithms for Energy Demand–Supply Prediction in Smart Grids. Sustainability 2022, 14, 2546. [Google Scholar] [CrossRef]
- Yu, J.R.; Chen, C.H.; Huang, T.W.; Lu, J.J.; Chung, C.R.; Lin, T.W.; Wu, M.H.; Tseng, Y.J.; Wang, H.Y. Energy Efficiency of Inference Algorithms for Clinical Laboratory Data Sets: Green Artificial Intelligence Study. J. Med. Internet Res. 2022, 24, e28036. [Google Scholar] [CrossRef] [PubMed]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Yang, S.; Zhu, F.; Ling, X.; Liu, Q.; Zhao, P. Intelligent Health Care: Applications of Deep Learning in Computational Medicine. Front. Genet. 2021, 12, 607471. [Google Scholar] [CrossRef]
- Wan, K.W.; Wong, C.H.; Ip, H.F.; Fan, D.; Yuen, P.L.; Fong, H.Y.; Ying, M. Evaluation of the performance of traditional machine learning algorithms, convolutional neural network and AutoML Vision in ultrasound breast lesions classification: A comparative study. Quant. Imaging Med. Surg. 2021, 11, 1381–1393. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, A.J.; Schonfeld, E.; Varshneya, K.; Stienen, M.N.; Staartjes, V.E.; Jin, M.C.; Veeravagu, A. Comparison of Deep Learning and Classical Machine Learning Algorithms to Predict Postoperative Outcomes for Anterior Cervical Discectomy and Fusion Procedures with State-of-the-art Performance. Spine 2022, 47, 1637–1644. [Google Scholar] [CrossRef] [PubMed]
- Chung, C.R.; Wang, H.Y.; Lien, F.; Tseng, Y.J.; Chen, C.H.; Lee, T.Y.; Liu, T.P.; Horng, J.T.; Lu, J.J. Incorporating Statistical Test and Machine Intelligence into Strain Typing of Staphylococcus haemolyticus Based on Matrix-Assisted Laser Desorption Ionization-Time of Flight Mass Spectrometry. Front. Microbiol. 2019, 10, 2120. [Google Scholar] [CrossRef]
- Feng, J.; Phillips, R.V.; Malenica, I.; Bishara, A.; Hubbard, A.E.; Celi, L.A.; Pirracchio, R. Clinical artificial intelligence quality improvement: Towards continual monitoring and updating of AI algorithms in healthcare. NPJ Digit. Med. 2022, 5, 66. [Google Scholar] [CrossRef] [PubMed]
- Editor, M.B. What Are T Values and P Values in Statistics? [Internet]. Available online: https://blog.minitab.com/en/statistics-and-quality-data-analysis/what-are-t-values-and-p-values-in-statistics (accessed on 13 December 2023).
- Parsons, V.L. Stratified Sampling. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2017; pp. 1–11. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/9781118445112.stat05999.pub2 (accessed on 29 December 2023).
- Eche, T.; Schwartz, L.H.; Mokrane, F.Z.; Dercle, L. Toward Generalizability in the Deployment of Artificial Intelligence in Radiology: Role of Computation Stress Testing to Overcome Underspecification. Radiol. Artif. Intell. 2021, 3, e210097. [Google Scholar] [CrossRef] [PubMed]
- Lapić, I.; Šegulja, D.; Dukić, K.; Bogić, A.; Lončar Vrančić, A.; Komljenović, S.; Šparakl, T.; Grdiša Teodorović, K.; Cigula Kurajica, V.; Baršić Lapić, I.; et al. Analytical validation of 39 clinical chemistry tests and 17 immunoassays on the Alinity analytical system. Scand. J. Clin. Lab. Investig. 2022, 82, 199–209. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Li, J.; Xu, Y.; Zhang, T.; Wang, X. Deep learning versus conventional methods for missing data imputation: A review and comparative study. Expert. Syst. Appl. 2023, 227, 120201. [Google Scholar] [CrossRef]
- Ndugga, N.; Published, S.A. Disparities in Health and Health Care: 5 Key Questions and Answers [Internet]. KFF. 2023. Available online: https://www.kff.org/racial-equity-and-health-policy/issue-brief/disparities-in-health-and-health-care-5-key-question-and-answers/ (accessed on 24 December 2023).
- Kruk, M.E.; Gage, A.D.; Arsenault, C.; Jordan, K.; Leslie, H.H.; Roder-DeWan, S.; Adeyi, O.; Barker, P.; Daelmans, B.; Doubova, S.V.; et al. High-quality health systems in the Sustainable Development Goals era: Time for a revolution. Lancet Glob. Health 2018, 6, e1196–e1252. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics, 2023. CA Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef]
- Youssef, A.; Ng, M.Y.; Long, J.; Hernandez-Boussard, T.; Shah, N.; Miner, A.; Larson, D.; Langlotz, C.P. Organizational Factors in Clinical Data Sharing for Artificial Intelligence in Health Care. JAMA Netw. Open. 2023, 6, e2348422. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.W.; Bulgarelli, L.; Shen, L.; Gayles, A.; Shammout, A.; Horng, S.; Pollard, T.J.; Hao, S.; Moody, B.; Gow, B.; et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 2023, 10, 1. [Google Scholar] [CrossRef] [PubMed]
- Wang, H. DARTA—A Permissionless Biomarker Data Marketplace [Internet]. 2023. Available online: https://github.com/HsinYaoWang/DARTA (accessed on 24 December 2023).
- Shah, N.H.; Halamka, J.D.; Saria, S.; Pencina, M.; Tazbaz, T.; Tripathi, M.; Callahan, A.; Hildahl, H.; Anderson, B. A Nationwide Network of Health AI Assurance Laboratories. JAMA 2024, 331, 245–249. [Google Scholar] [CrossRef] [PubMed]
- Gregg, A.R.; Skotko, B.G.; Benkendorf, J.L.; Monaghan, K.G.; Bajaj, K.; Best, R.G.; Klugman, S.; Watson, M.S. Noninvasive prenatal screening for fetal aneuploidy, 2016 update: A position statement of the American College of Medical Genetics and Genomics. Genet Med. 2016, 18, 1056–1065. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCED Products | Biomarkers | Cancer Types | Algorithms | Model Development | Performance | Report | Comments |
|---|---|---|---|---|---|---|---|
| Gallery [18,78] | cfDNA methylation (>100,000 informative methylation regions) | More than 50 types | Logistic regression | Train: CCD Validation:
| Sen: 28.9% Spe: 99.1% NNS: 189 |
|
|
| OneTest [6,35] | Protein biomarkers (six tumor markers for male: AFP, CEA, CA19-9, CYFRA21-1, SCC, and PSA, and seven protein tumor markers for females: AFP, CEA, CA19-9, CYFRA21-1, SCC, CA125, and CA15-3) | More than 20 types | Classical ML algorithms; Long short-term memory algorithm | Train: RWD Validation:
| Sen: 82.3% Spe: 80.8% NNS: 125 (male); 200 (female) |
|
|
| OncoSeek [17] | Protein biomarkers (seven protein tumor markers: AFP, CA125, CA15-3, CA19-9, CA72-4, CEA, and CYFRA 21-1) | Nine types: breast, colorectum, liver, lung, lymphoma, osophagus, ovary, pancreas, and stomach | Classical ML algorithms | Train: CCD Validation:
| Sen: 51.7% Spe: 92.9% |
|
|
| CancerSeek [15] | cfDNA + protein biomarkers (61 genetic markers and 8 protein tumor markers: CA125, CA19-9, CEA, HGF, myeloperoxidase, OPN, prolactin, TIMP-1) | Eight types: ovary, liver, stomach, pancreas, esophagus, colorectum, lung, and breast | Logistic regression | Train: CCD Validation:
| Sen: 70% Spe: 99% |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.-Y.; Lin, W.-Y.; Zhou, C.; Yang, Z.-A.; Kalpana, S.; Lebowitz, M.S. Integrating Artificial Intelligence for Advancing Multiple-Cancer Early Detection via Serum Biomarkers: A Narrative Review. Cancers 2024, 16, 862. https://doi.org/10.3390/cancers16050862
Wang H-Y, Lin W-Y, Zhou C, Yang Z-A, Kalpana S, Lebowitz MS. Integrating Artificial Intelligence for Advancing Multiple-Cancer Early Detection via Serum Biomarkers: A Narrative Review. Cancers. 2024; 16(5):862. https://doi.org/10.3390/cancers16050862
Chicago/Turabian StyleWang, Hsin-Yao, Wan-Ying Lin, Chenfei Zhou, Zih-Ang Yang, Sriram Kalpana, and Michael S. Lebowitz. 2024. "Integrating Artificial Intelligence for Advancing Multiple-Cancer Early Detection via Serum Biomarkers: A Narrative Review" Cancers 16, no. 5: 862. https://doi.org/10.3390/cancers16050862