
Exact Probability Distribution for the ROC Area under Curve


Abstract
:Simple Summary
Abstract
1. Background
2. Probability Distribution of the AUC-Value
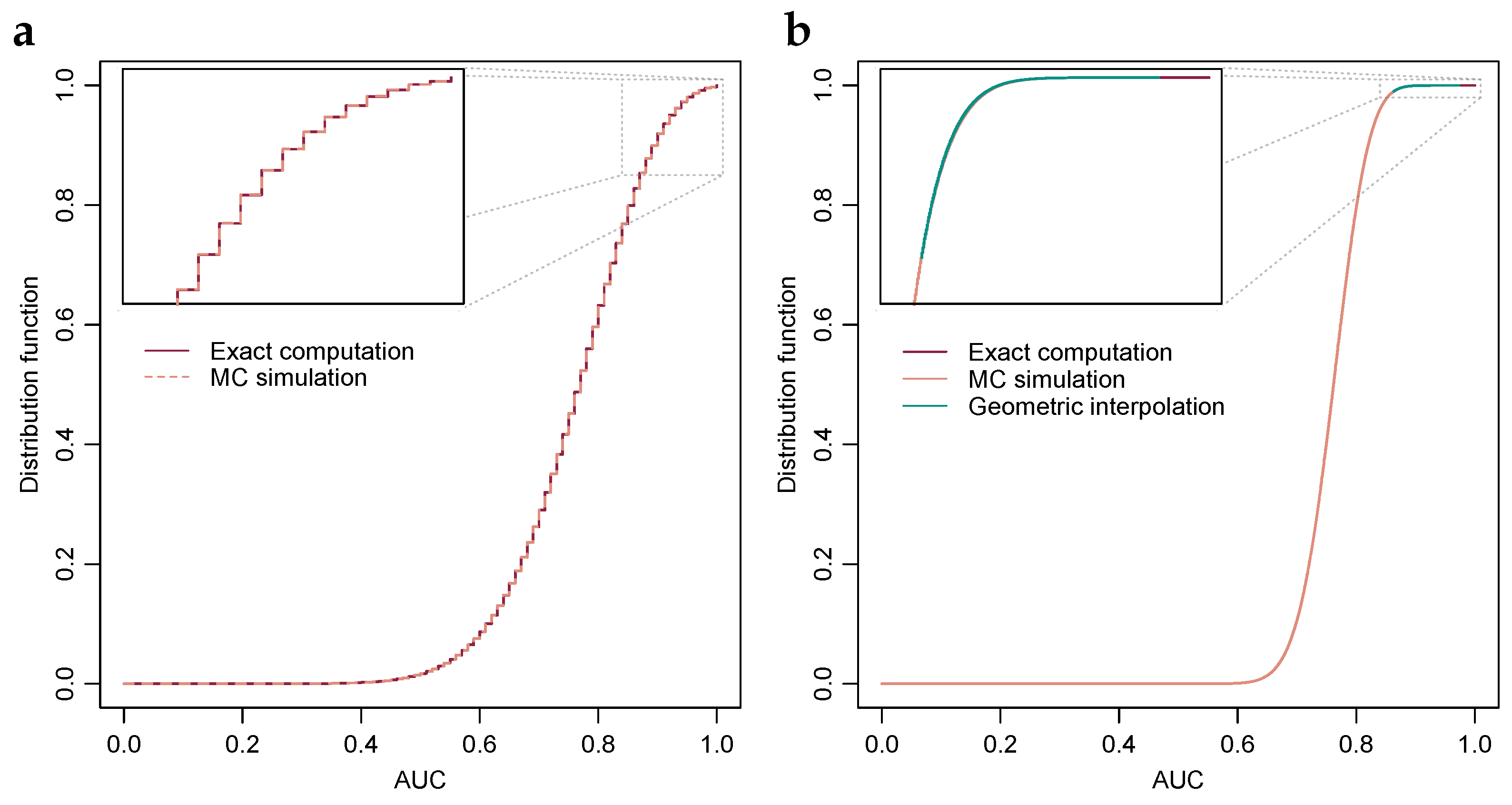
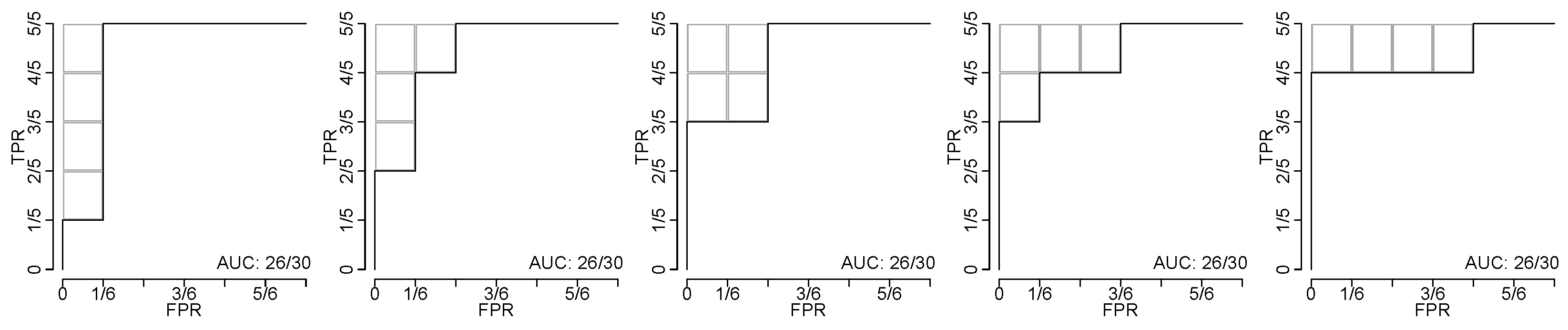
2.1. Exact Computation via Order Statistics
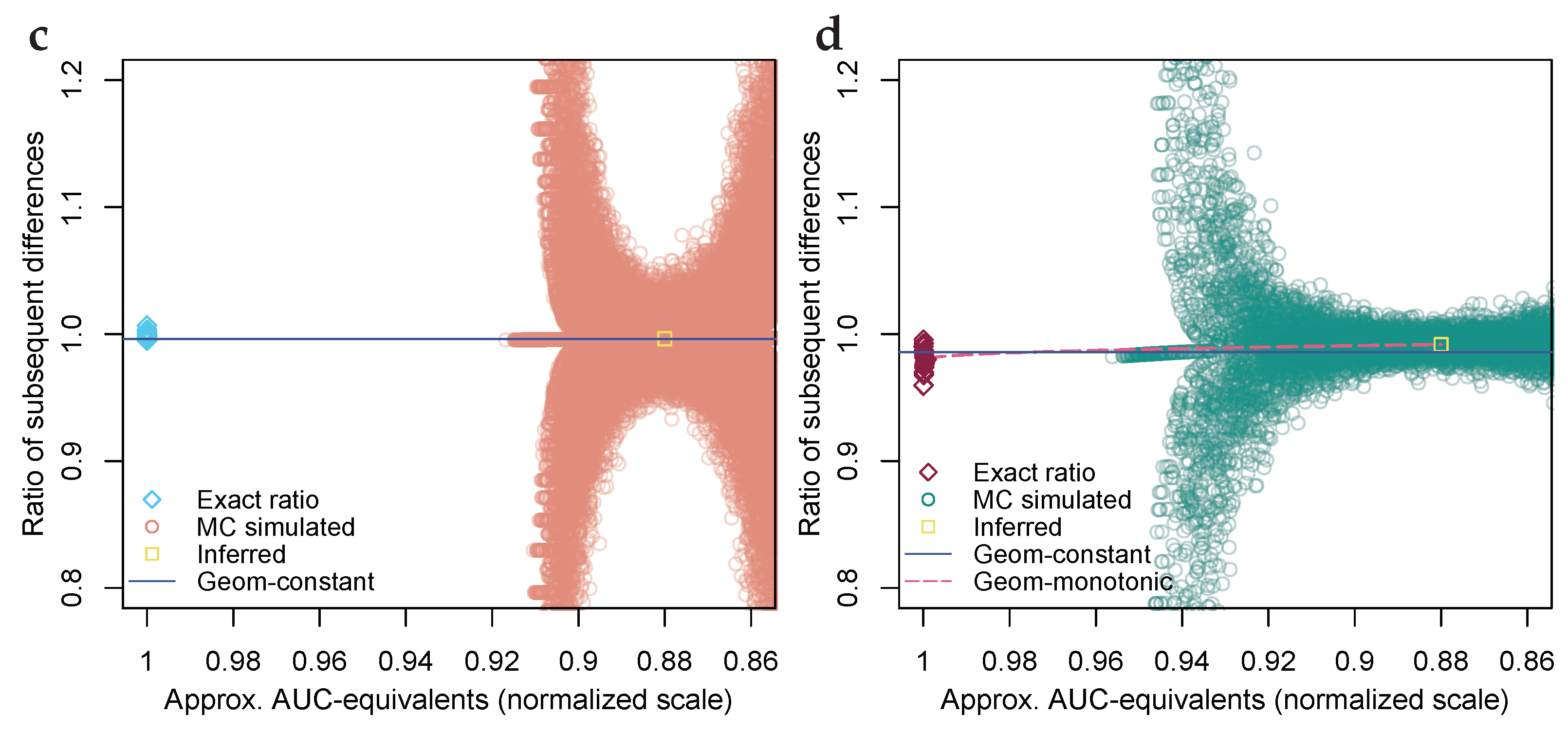
2.2. Monte Carlo-Simulation of the AUC-Value Probabilities
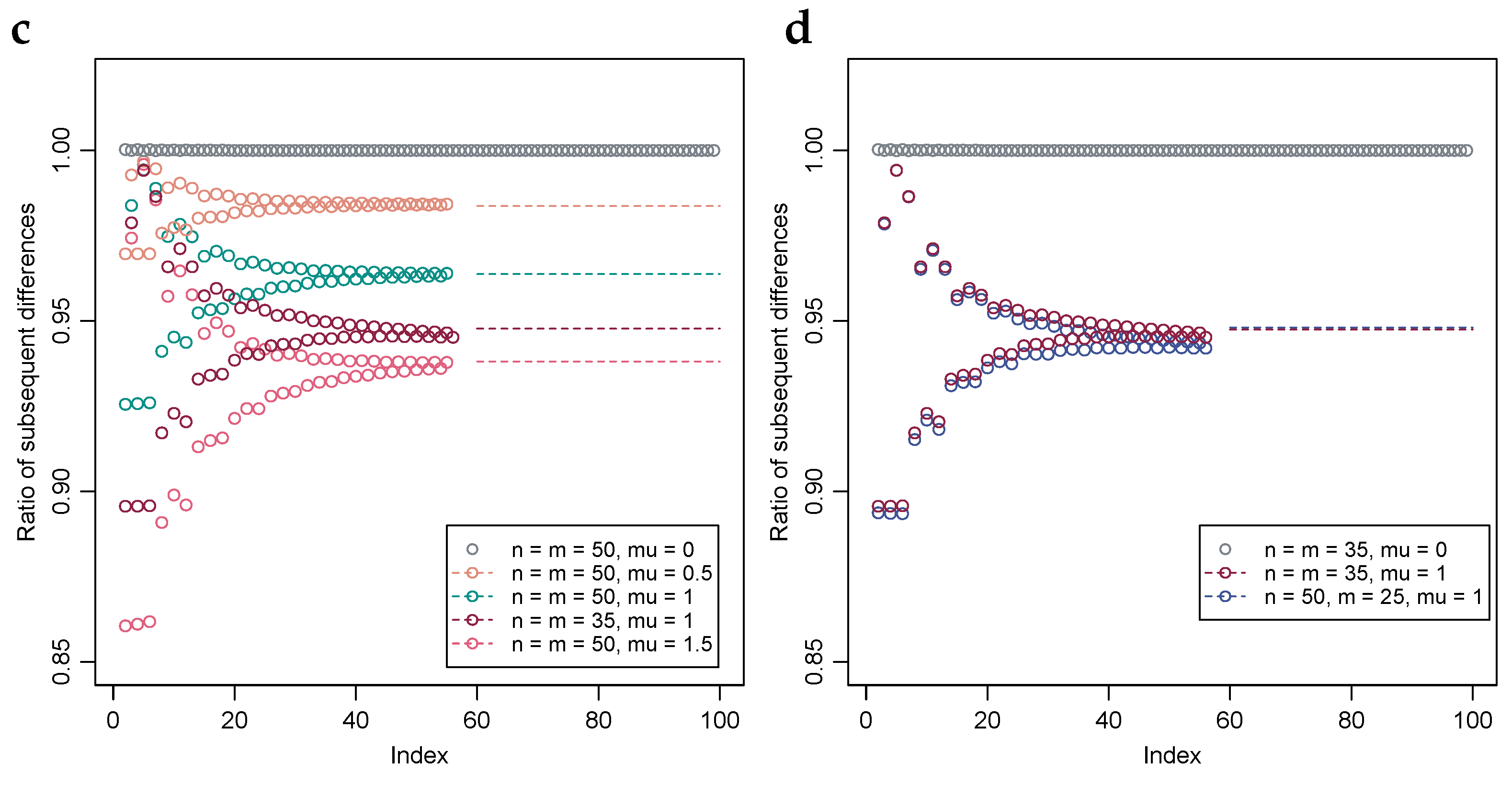
2.3. Geometric Interpolation
| Algorithm 1: Recursive algorithm returning the number of ROC curves that yield an input AUC-value |
|
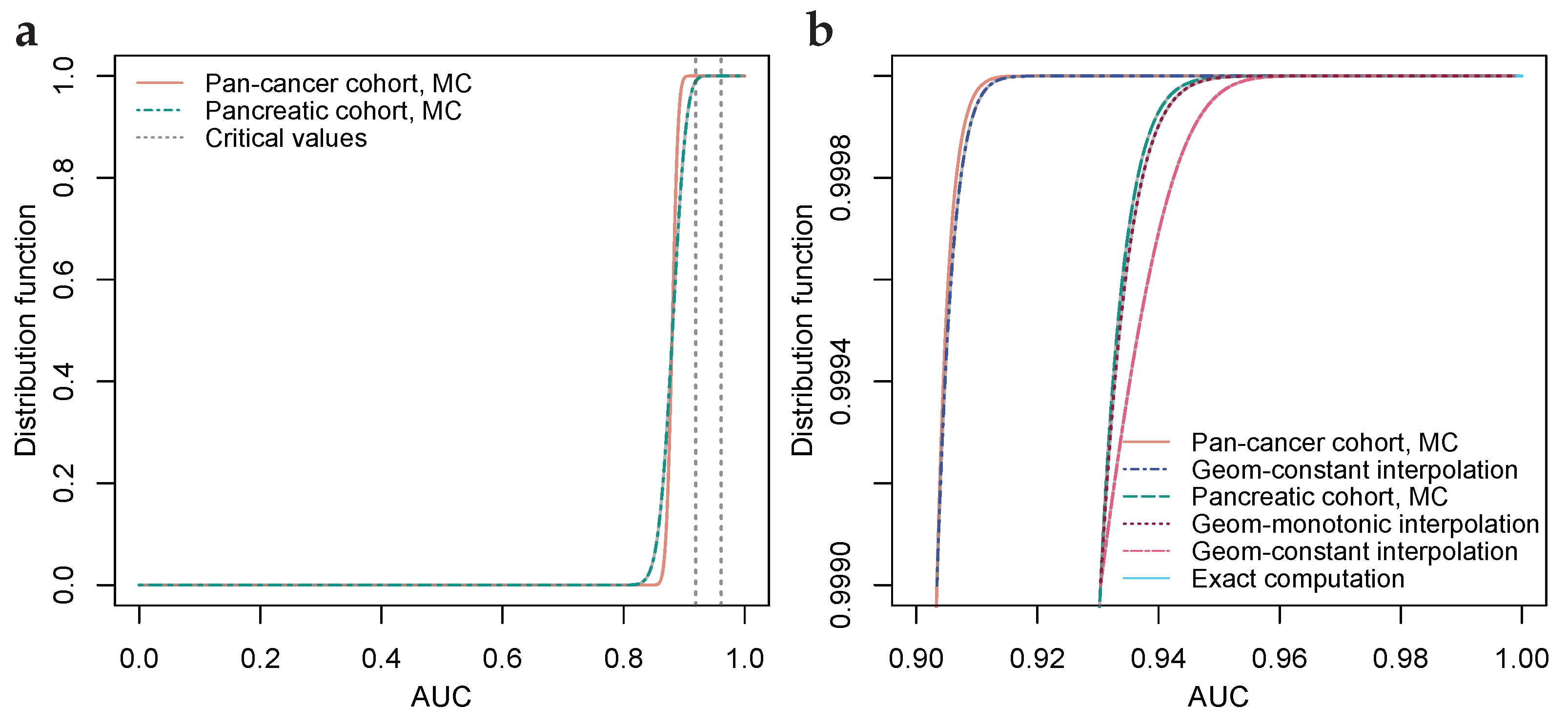
3. Statistical Hypothesis Testing of AUC-Values
4. Examples
4.1. Illustration through Simulated Data
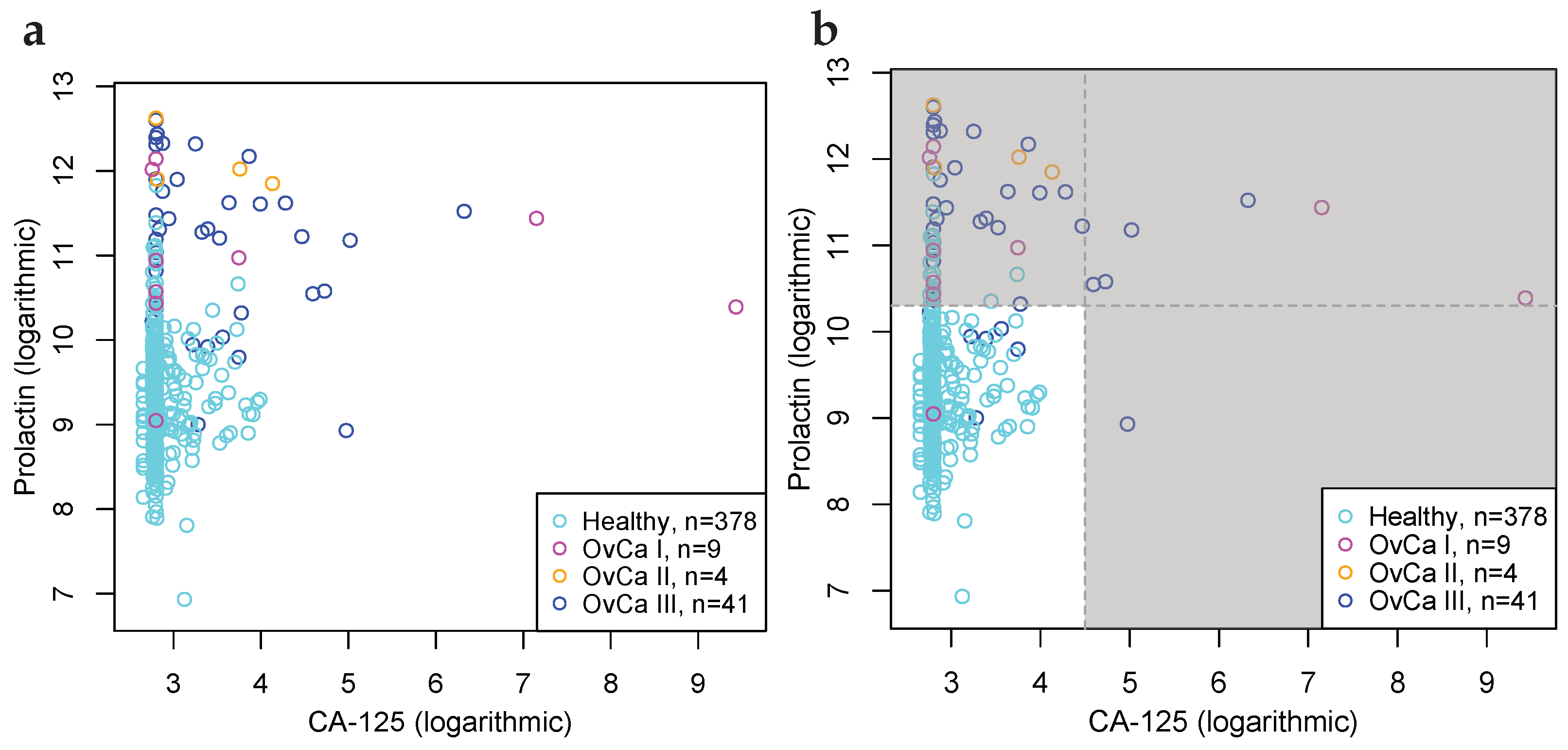
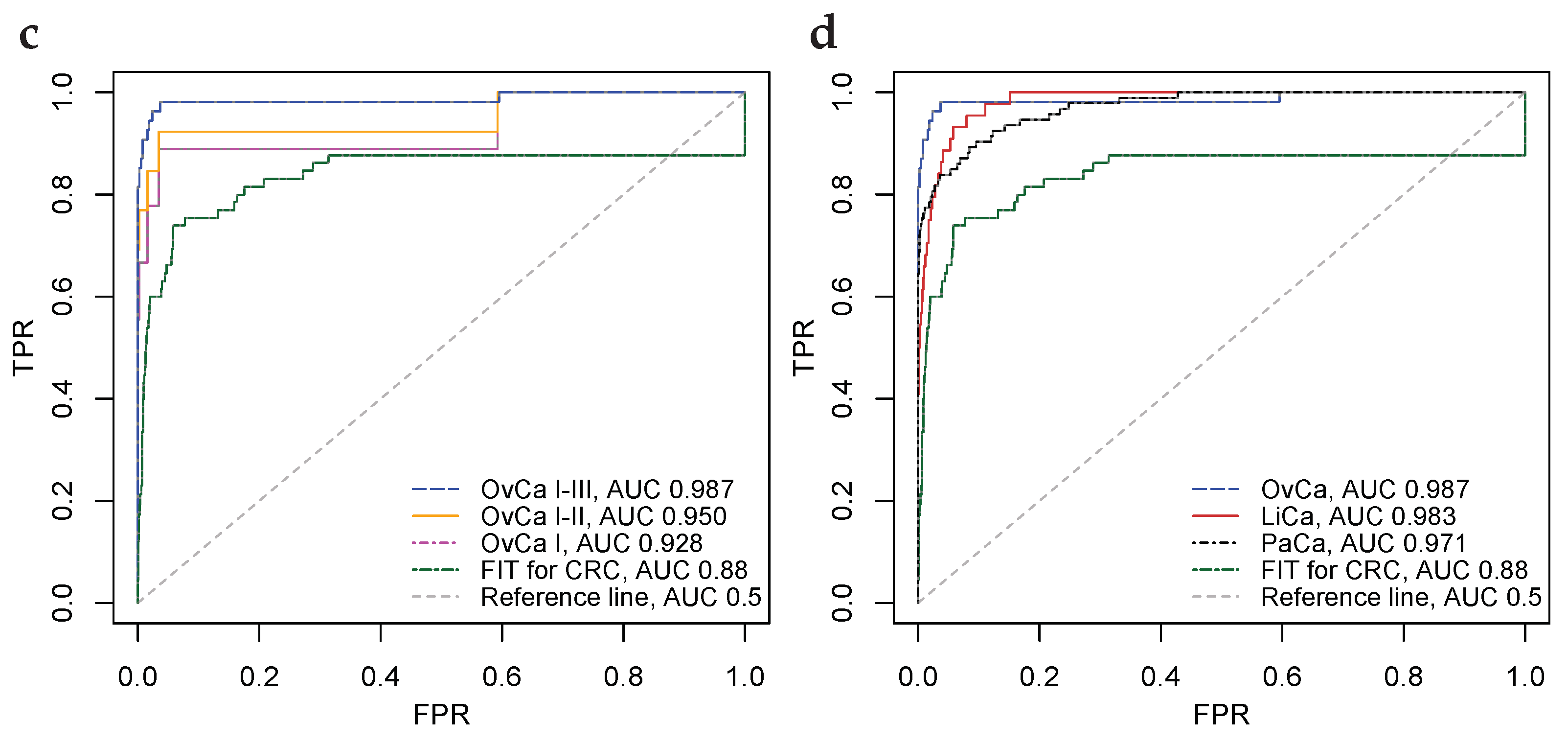
4.2. Illustration through Biomarker Data
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUC | area under curve |
| iid | independent and identically distributed |
| IVD | in vitro diagnostic |
| ROC | receiver operating characteristic |
| TN | true negative |
| TP | true positive |
References
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- FDA CDRH. Guidance for Industry and FDA Staff: Statistical Guidance on Reporting Results from Studies Evaluating Diagnostic Tests, Issued on 13 March 2007. Available online: https://www.fda.gov/media/71147/download (accessed on 7 February 2023).
- Garrett, P.E.; Lasky, F.D.; Meier, K.L. EP12-A2: User Protocol for Evaluation of Qualitative Test Performance; Approved Guideline, 2nd ed.; CLSI: Wayne, PA, USA, 2008; ISBN 1-56238-654-9. [Google Scholar]
- Kroll, M.H.; Biswas, B.; Budd, J.R.; Durham, P.; Gorman, R.T.; Gwise, T.E.; Halim, A.; Hatjimihail, A.T.; Hilden, J.; Song, K. EP24-A2: Assessment of the Diagnostic Accuracy of Laboratory Tests Using Receiver Operating Characteristic Curves; Approved Guideline, 2nd ed.; CLSI: Wayne, PA, USA, 2011; ISBN 1-56238-777-4. [Google Scholar]
- National Archives (U.S.). Code of Federal Regulations. Title 21, Part 860. Available online: https://www.ecfr.gov/current/title-21/ (accessed on 7 February 2023).
- Peterson, W.; Birdsall, T.; Fox, W. The theory of signal detectability. Trans. IRE Prof. Group Inf. Theory 1954, 4, 171–212. [Google Scholar] [CrossRef]
- Egan, J.P. Recognition Memory and the Operating Characteristic; Tech. Note AFCRC-TN-58-51; Indiana University, Hearing and Communication Laboratory: Bloomington, IN, USA, 1958. [Google Scholar]
- Bamber, D. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J. Math. Psycol. 1975, 12, 387–415. [Google Scholar] [CrossRef]
- Hoeffding, W. A class of statistics with asymptotically normal distribution. Ann. Math. Statist. 1948, 19, 239–325. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef] [Green Version]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- McNeil, B.J.; Hanley, J.A. Statistical Approaches to the Analysis of Receiver Operating Characteristic (ROC) Curves. Med. Decis. Making 1984, 4, 137–150. [Google Scholar] [CrossRef]
- McClish, D.K. Analyzing a portion of the ROC curve. Med. Decis. Making 1989, 9, 190–195. [Google Scholar] [CrossRef]
- Zou, K.H.; Hall, W.J.; Shapiro, D.E. Smooth non-parametric receiver operating characteristic (ROC) curves for continuous diagnostic tests. Statist. Med. 1997, 16, 2143–2156. [Google Scholar] [CrossRef]
- Pepe, M.S. The Statistical Evaluation of Medical Tests for Classification and Prediction; Oxford University Press: New York, NY, USA, 2003; ISBN 0-1985-0984-7. [Google Scholar]
- Qin, G.; Zhou, X.H. Empirical likelihood inference for the area under the ROC curve. Biometrics 2006, 62, 613–622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lloyd, C.J. Using smoothed receiver operating characteristic curves to summarize and compare diagnostic systems. J. Am. Statist. Assoc. 1998, 93, 1356–1364. [Google Scholar] [CrossRef]
- Feng, D.; Cortese, G.; Baumgartner, R. A comparison of confidence/credible interval methods for the area under the ROC curve for continuous diagnostic tests with small sample size. Statist. Meth. Med. Res. 2017, 26, 2603–2621. [Google Scholar] [CrossRef] [PubMed]
- Eng, J. Sample Size Estimation: A Glimpse beyond Simple Formulas. Radiology 2004, 230, 606–612. [Google Scholar] [CrossRef] [Green Version]
- Cortese, G.; Ventura, L. Accurate higher-order likelihood inference on P(Y < X). Computat. Statist. 2013, 28, 1035–1059. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations Theory and Applications; World Scientific: Singapore, 2003; ISBN 981-238-057-4. [Google Scholar]
- Swets, J.A. Signal Detection Theory and ROC Analysis in Psychology and Diagnostics: Collected Papers, 1st ed.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1996; ISBN 0-8058-1834-0. [Google Scholar]
- Zhou, X.H.; Obuchowski, N.A.; McClish, D.K. Statistical Methods in Diagnostic Medicine, 2nd. ed.; Wiley: Hoboken, NJ, USA, 2011; ISBN 0-4701-8314-4. [Google Scholar]
- Obuchowski, N.A.; Bullen, J.A. Receiver operating characteristic (ROC) curves: Review of methods with applications in diagnostic medicine. Phys. Med. Biol. 2018, 63, 07TR01. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C: The Art of Scientific Computing, 2nd ed.; Cambridge: New York, NY, USA, 1992; ISBN 8-1856-1816-X. [Google Scholar]
- Dudley, R.M. Real Analysis and Probability; New Edition; Cambridge: New York, NY, USA, 2002; ISBN 0-5218-0972-X. [Google Scholar]
- Cohen, J.D.; Li, L.; Wang, Y.; Thoburn, C.; Afsari, B.; Danilova, L.; Douville, C.; Javed, A.A.; Wong, F.; Mattox, A.; et al. Detection and localization of surgically resectable cancers with a multi-analyte blood test. Science 2018, 359, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. Statistical Methods for Research Workers, 3rd ed.; Oliver and Boyd: London, UK, 1936. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; ISBN 3-900051-07-0. [Google Scholar]
- Prakash, A.; Athanas, M.; Sarracino, D.; Krastins, B.; Rezai, T.; Lope, M. Efficiently Generating Multi Biomarker ROC Curves to Identify Significant Multi-Biomarkers. Thermo Fisher Scientific, 2010. Available online: https://fscimage.fishersci.com/images/D00299~.pdf (accessed on 7 February 2023).
- FDA. Pre-Market Approval Application P130017, Summary of Safety and Effectiveness Data, Device Trade Name: ColoGuard, Applicant: Exact Sciences Corp, 2013. Available online: https://www.accessdata.fda.gov/cdrh_docs/pdf13/P130017B.pdf (accessed on 7 February 2023).
- FDA. Pre-Market Approval Database. Available online: https://www.accessdata.fda.gov/premarket/ftparea/pma.zip (accessed on 21 October 2021).
- Baker, S.G. The central role of receiver operating characteristic (ROC) curves in evaluating tests for the early detection of cancer. J. Natl. Cancer Inst. 2003, 95, 511–515. [Google Scholar] [CrossRef] [Green Version]
- Hanash, S.M. Why have protein biomarkers not reached the clinic? Genome Med. 2011, 3, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Diamandis, E.P. The failure of protein cancer biomarkers to reach the clinic: Why, and what can be done to address the problem? BMC Med. 2012, 10, 87. [Google Scholar] [CrossRef] [Green Version]
- Drucker, E.; Krapfenbauer, K. Pitfalls and limitations in translation from biomarker discovery to clinical utility in predictive and personalised medicine. EPMA J. 2013, 4, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ioannidis, J.P.A. Biomarker failures. Clin. Chem. 2013, 59, 202–204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pavlou, M.P.; Diamandis, E.P.; Blasutig, I.M. The long journey of cancer biomarkers from the bench to the clinic. Clin. Chem. 2013, 59, 147–157. [Google Scholar] [CrossRef] [Green Version]
- Yotsukura, S.; Mamitsuka, H. Evaluation of serum-based cancer biomarkers: A brief review from a clinical and computational viewpoint. Crit. Rev. Oncol. Hematol. 2015, 93, 103–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tumor Type | Number of | Critical Value | Number of | |
|---|---|---|---|---|
| Cohort | TPs | TNs | 99%, corrct’d | sign. biom. |
| Breast | 209 | 800 | 0 | |
| Colorectal | 388 | 800 | 0 | |
| Esophagus | 45 | 800 | 0 | |
| Liver | 44 | 800 | 4 | |
| Lung | 104 | 800 | 0 | |
| Ovary | 54 | 372 | 14 | |
| Pancreas | 93 | 800 | 8 | |
| Stomach | 68 | 800 | 0 | |
| Pan-cancer | 1004 | 800 | 0 | |
| Tumour Type | Proteins * | Regulation ‡ | AUC | pAUC § | p-Value ¶ |
|---|---|---|---|---|---|
| Liver | HGF↑ OPN↑ | Either | 0.983 | 0.183 | |
| AFP↑ OPN↑ | Either | ||||
| HGF↑ PRL↑ | Either | ||||
| GDF15↑ IL-8↑ | Both | ||||
| Ovary | CA-125↑ PRL↑ | Either | 0.987 | 0.194 | |
| CA-125↑ TIMP-1↑ | Either | 0.984 | 0.186 | ||
| CA-125↑ TSP2↓ | Either | 0.985 | 0.192 | ||
| CA-125↑ IL-6↑ | Either | 0.982 | 0.184 | ||
| CA125↑ IL-6↑ | Both | 0.981 | 0.181 | ||
| PRL↑ TIMP-1↑ | Either | 0.980 | 0.180 | ||
| CA-125↑ GDF15↑ | Either | 0.978 | 0.182 | ||
| CA-125↑ CEA↓ | Either | 0.977 | 0.179 | ||
| CA-125↑ OPN↑ | Both | 0.977 | 0.182 | ||
| CA-125↑ TGF-↑ | Either | 0.976 | 0.184 | ||
| CA-125↑ OPN↑ | Either | 0.976 | 0.182 | ||
| CA-125↑ sFas↓ | Either | 0.976 | 0.176 | ||
| IL-6↑ sFas↓ | Both | 0.975 | 0.178 | ||
| CA-125↑ ENG↑ | Either | 0.974 | 0.177 | ||
| Pancreas | CA19-9↑ sErbB2↑ | Either | 0.971 | 0.176 | |
| CA19-9↑ GDF15↑ | Either | 0.967 | 0.172 | ||
| CA19-9↑ OPN↑ | Either | 0.966 | 0.171 | ||
| CA19-9↑ IL-6↑ | Either | 0.966 | 0.172 | ||
| CA19-9↑ TIMP-2↑ | Either | 0.964 | 0.172 | ||
| CA19-9↑ IL-8↑ | Either | 0.962 | 0.168 | ||
| CA19-9↑ PRL↑ | Either | 0.962 | 0.170 | ||
| CA19-9↑ HGF↑ | Either | 0.961 | 0.173 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ekström, J.; Åkerrén Ögren, J.; Sjöblom, T. Exact Probability Distribution for the ROC Area under Curve. Cancers 2023, 15, 1788. https://doi.org/10.3390/cancers15061788
Ekström J, Åkerrén Ögren J, Sjöblom T. Exact Probability Distribution for the ROC Area under Curve. Cancers. 2023; 15(6):1788. https://doi.org/10.3390/cancers15061788
Chicago/Turabian StyleEkström, Joakim, Jim Åkerrén Ögren, and Tobias Sjöblom. 2023. "Exact Probability Distribution for the ROC Area under Curve" Cancers 15, no. 6: 1788. https://doi.org/10.3390/cancers15061788