
Artificial Intelligence-Based Prognostic Model for Urologic Cancers: A SEER-Based Study

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
- (1)
- Standard-of-care treatment is accessible and utilized;
- (2)
- Cancer-specific survival is not impacted by the definition of the standard-of-care treatment, as shown by previous studies [28,29,30,31]. For instance, the selection of available treatment options (e.g., radiation, surgery) for patients sharing similar clinicopathological information marginally alternates cancer-specific survival and, therefore, its effect is negligible at the population level;
- (3)
- Cancer-specific survival in the representative populations indirectly incorporate the risk of any significant oncologic event (e.g., failure of the initial treatment, recurrence) or a consequence of an oncologic condition (e.g., developing bone fracture in the setting of metastatic prostate cancer);
- (4)
- Cancer-specific survival estimates reflect the cancer-specific risk profile of a population with urologic cancers, given that exact life tables are not readily available [32];
- (5)
- Change in cancer-specific mortality risk over time (risk velocity) defines cancer progression risk, while differences in time to progression do not predict cancer-specific survival [33].
2.1. Model Development for Mortality Risk-Profile Reconstruction
2.2. Evaluation Metrics
2.3. Exploratory Studies for Potential Utility
2.3.1. Algorithms to Measure the Risk Velocity
- The collection of the survival probabilities (S) is defined as .We defined a set of 120 time points (P) for survival probabilities; we estimated the years elapsed (time lapse, f) from the age at diagnosis (a) to the median U.S. life expectancy [40] (b) (78 years); the time distance (k) between two time points was determined after dividing the time lapse by 120 time points.
- where k is a constant from ii and A is a set of time positions for survival probabilities P, thereby .
- 2.
- The timeline created by time points (P) was then divided into intervals (I), thereby resulting in sequences of interval-associated time points with survival probabilities. The interval length (l) is dynamic and corresponds to the half number of time points divided by the time lapse (e.g., for a time lapse of 12 years, the interval length would be 5 time points or 6 months). The total number of intervals (n) is the total time points (120) divided by the interval length. The following algorithm to define the intervals is adjusted according to the time lapse to facilitate the interval scaling:
- iv
- v
- where
- vi
- .
- 3.
- After generating the intervals (I), we estimated the risk velocity () per interval. The risk velocity (v) is the difference between the first (sp1) and the last (spl) survival probabilities [sp1, spl] of a time interval from I.
- vii
2.3.2. Simulation Study
- (1)
- Recommender for the minimum follow-up duration
- (2)
- Determine intervals with unchanged risk profiles
3. Results
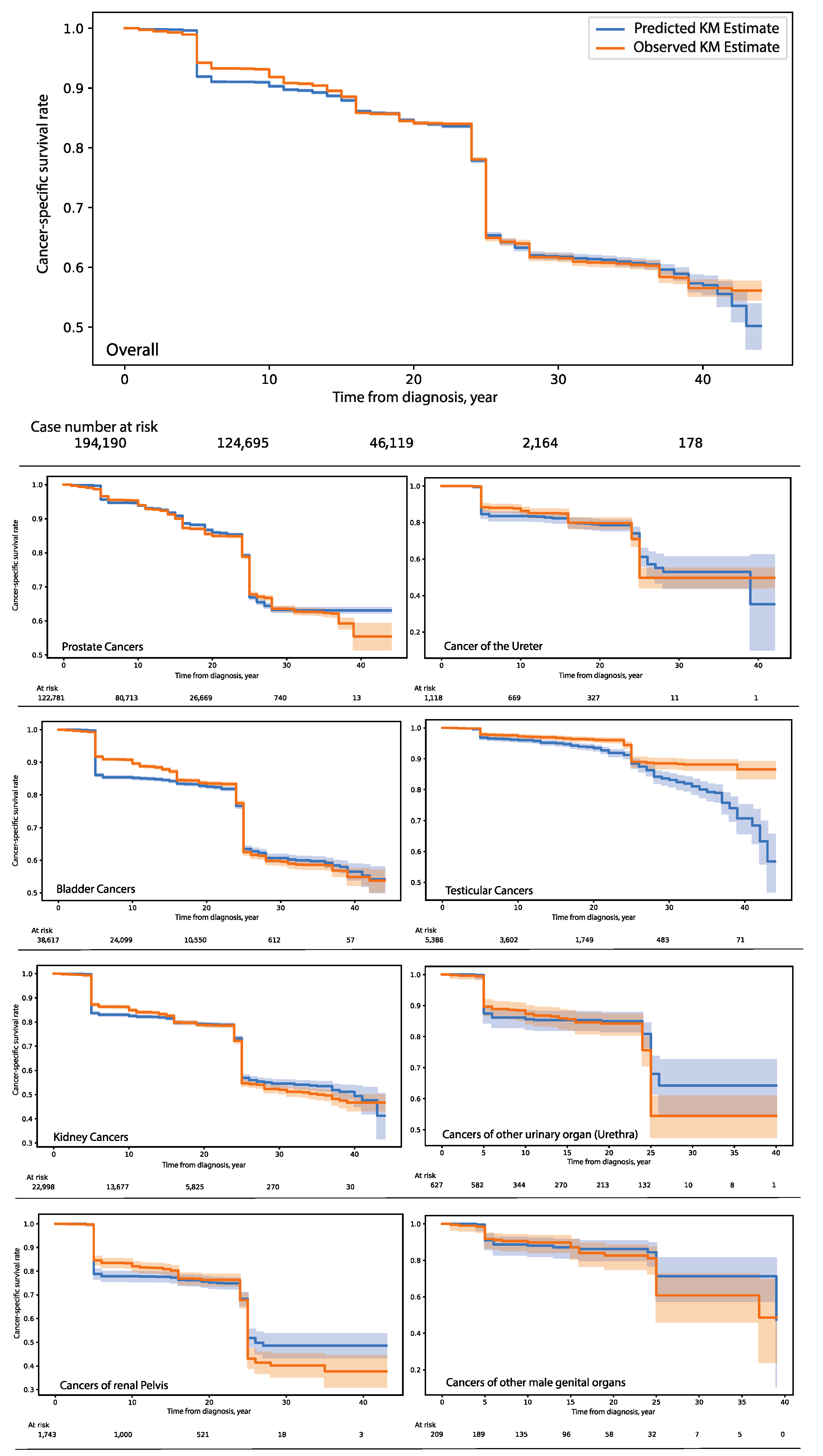
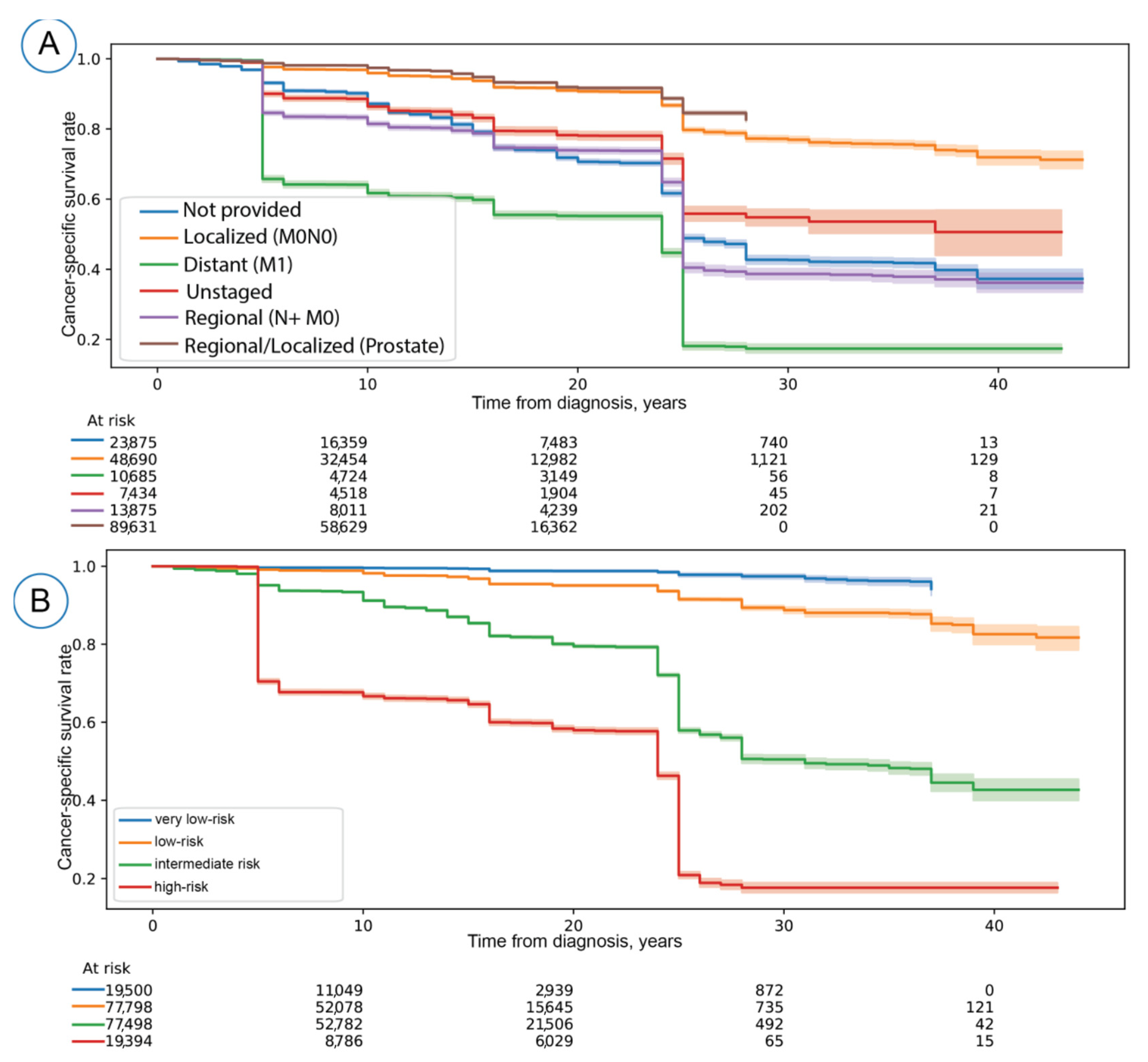
3.1. Model Development and Evaluation
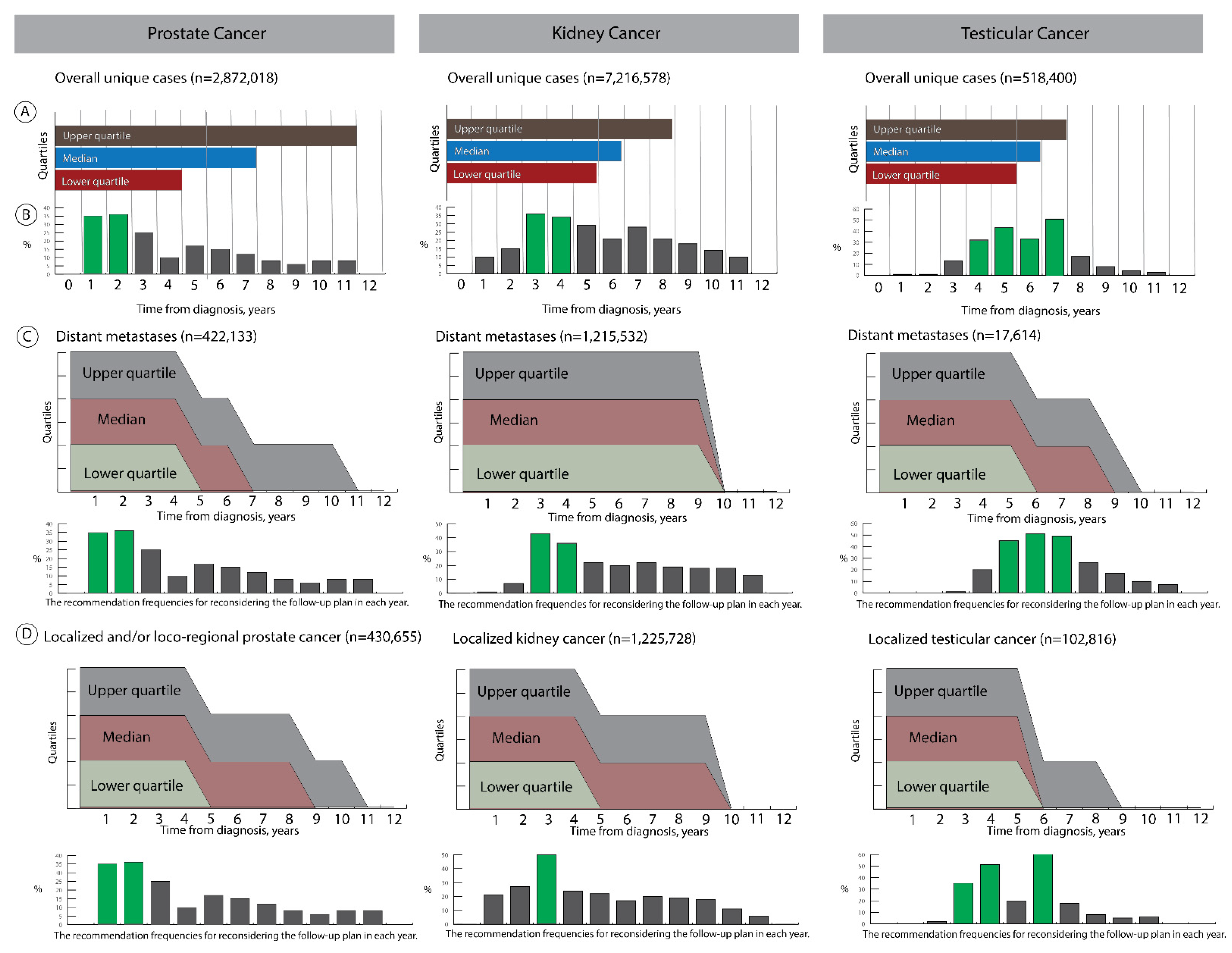
3.2. Exploratory Studies
- (1)
- Recommender for the minimum follow-up duration
- (2)
- Determine intervals with unchanged risk profiles
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef]
- Freedland, S.J.; Humphreys, E.B.; Mangold, L.A.; Eisenberger, M.; Dorey, F.J.; Walsh, P.C.; Partin, A.W. Risk of prostate cancer–specific mortality following biochemical recurrence after radical prostatectomy. JAMA 2005, 294, 433–439. [Google Scholar] [CrossRef] [Green Version]
- Earle, C.C.; Neville, B.A.; Landrum, M.B.; Ayanian, J.Z.; Block, S.D.; Weeks, J.C. Trends in the aggressiveness of cancer care near the end of life. J. Clin. Oncol. 2004, 22, 315–321. [Google Scholar] [CrossRef] [PubMed]
- Wolf, A.M.; Wender, R.C.; Etzioni, R.B.; Thompson, I.M.; D’Amico, A.V.; Volk, R.J.; Brooks, D.D.; Dash, C.; Guessous, I.; Andrews, K. American Cancer Society guideline for the early detection of prostate cancer: Update 2010. CA Cancer J. Clin. 2010, 60, 70–98. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colombel, M.; Soloway, M.; Akaza, H.; Böhle, A.; Palou, J.; Buckley, R.; Lamm, D.; Brausi, M.; Witjes, J.A.; Persad, R. Epidemiology, staging, grading, and risk stratification of bladder cancer. Eur. Urol. Suppl. 2008, 7, 618–626. [Google Scholar] [CrossRef]
- Roobol, M.J.; Carlsson, S.V. Risk stratification in prostate cancer screening. Nat. Rev. Urol. 2013, 10, 38–48. [Google Scholar] [CrossRef]
- Sanda, M.G.; Cadeddu, J.A.; Kirkby, E.; Chen, R.C.; Crispino, T.; Fontanarosa, J.; Freedland, S.J.; Greene, K.; Klotz, L.H.; Makarov, D.V. Clinically localized prostate cancer: AUA/ASTRO/SUO guideline. Part I: Risk stratification, shared decision making, and care options. J. Urol. 2018, 199, 683–690. [Google Scholar] [CrossRef]
- Litwin, M.S.; Tan, H.-J. The diagnosis and treatment of prostate cancer: A review. JAMA 2017, 317, 2532–2542. [Google Scholar] [CrossRef] [PubMed]
- Wilt, T.J.; Vo, T.N.; Langsetmo, L.; Dahm, P.; Wheeler, T.; Aronson, W.J.; Cooperberg, M.R.; Taylor, B.C.; Brawer, M.K. Radical Prostatectomy or Observation for Clinically Localized Prostate Cancer: Extended Follow-up of the Prostate Cancer Intervention Versus Observation Trial (PIVOT). Eur. Urol. 2020, 77, 713–724. [Google Scholar] [CrossRef]
- Wilt, T.J.; Jones, K.M.; Barry, M.J.; Andriole, G.L.; Culkin, D.; Wheeler, T.; Aronson, W.J.; Brawer, M.K. Follow-up of Prostatectomy versus Observation for Early Prostate Cancer. N. Engl. J. Med. 2017, 377, 132–142. [Google Scholar] [CrossRef]
- Babjuk, M.; Böhle, A.; Burger, M.; Capoun, O.; Cohen, D.; Compérat, E.M.; Hernández, V.; Kaasinen, E.; Palou, J.; Rouprêt, M.; et al. EAU guidelines on non–muscle-invasive urothelial carcinoma of the bladder: Update 2016. Eur. Urol. 2017, 71, 447–461. [Google Scholar] [CrossRef] [PubMed]
- Ljungberg, B. Prognostic Factors in Renal Cell Carcinoma. Scand. J. Surg. 2004, 93, 118–125. [Google Scholar] [CrossRef]
- Rouprêt, M.; Babjuk, M.; Böhle, A.; Burger, M.; Compérat, E.; Cowan, N.; Kaasinen, E.; Palou, J.; Van Rhijn, B.; Sylvester, R. Urothelial Carcinomas of the Upper Urinary Uract; Springer: New York, NY, USA, 2013. [Google Scholar]
- Witjes, J.A.; Lebret, T.; Compérat, E.M.; Cowan, N.C.; De Santis, M.; Bruins, H.M.; Hernandez, V.; Espinós, E.L.; Dunn, J.; Rouanne, M. Updated 2016 EAU guidelines on muscle-invasive and metastatic bladder cancer. Eur. Urol. 2017, 71, 462–475. [Google Scholar] [CrossRef] [PubMed]
- Stephenson, A.; Eggener, S.E.; Bass, E.B.; Chelnick, D.M.; Daneshmand, S.; Feldman, D.; Gilligan, T.; Karam, J.A.; Leibovich, B.; Liauw, S.L. Diagnosis and treatment of early stage testicular cancer: AUA guideline. J. Urol. 2019, 202, 272–281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- George, A.; Stead, T.S.; Ganti, L. What’s the Risk: Differentiating Risk Ratios, Odds Ratios, and Hazard Ratios? Cureus 2020, 12, e10047. [Google Scholar] [CrossRef] [PubMed]
- Amin, M.B.; Greene, F.L.; Edge, S.B.; Compton, C.C.; Gershenwald, J.E.; Brookland, R.K.; Meyer, L.; Gress, D.M.; Byrd, D.R.; Winchester, D.P. The Eighth Edition AJCC Cancer Staging Manual: Continuing to build a bridge from a population-based to a more "personalized" approach to cancer staging. CA Cancer J. Clin. 2017, 67, 93–99. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Scheike, T.H.; Zhang, M.J. Checking Fine and Gray subdistribution hazards model with cumulative sums of residuals. Lifetime Data Anal. 2015, 21, 197–217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hess, K.R. Graphical methods for assessing violations of the proportional hazards assumption in Cox regression. Stat. Med. 1995, 14, 1707–1723. [Google Scholar] [CrossRef] [PubMed]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Katzman, J.L.; Shaham, U.; Cloninger, A.; Bates, J.; Jiang, T.; Kluger, Y. DeepSurv: Personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med. Res. Methodol. 2018, 18, 24. [Google Scholar] [CrossRef]
- Lee, C.; Zame, W.R.; Yoon, J.; van der Schaar, M. Deephit: A deep learning approach to survival analysis with competing risks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Nagpal, C.; Li, X.; Dubrawski, A. Deep Survival Machines: Fully Parametric Survival Regression and Representation Learning for Censored Data With Competing Risks. IEEE J. Biomed. Health Inform. 2021, 25, 3163–3175. [Google Scholar] [CrossRef] [PubMed]
- Giunchiglia, E.; Nemchenko, A.; Schaar, M.v.d. RNN-SURV: A deep recurrent model for survival analysis. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 23–32. [Google Scholar]
- Hao, L.; Kim, J.; Kwon, S.; Ha, I.D. Deep learning-based survival analysis for high-dimensional survival data. Mathematics 2021, 9, 1244. [Google Scholar] [CrossRef]
- Surveillance and End Results Program. Available online: https://seer.cancer.gov/analysis/ (accessed on 20 April 2020).
- Eminaga, O.; Al-Hamad, O.; Boegemann, M.; Breil, B.; Semjonow, A. Combination possibility and deep learning model as clinical decision-aided approach for prostate cancer. Health Inform. J. 2020, 26, 945–962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beesley, L.J.; Morgan, T.M.; Spratt, D.E.; Singhal, U.; Feng, F.Y.; Furgal, A.C.; Jackson, W.C.; Daignault, S.; Taylor, J.M.G. Individual and Population Comparisons of Surgery and Radiotherapy Outcomes in Prostate Cancer Using Bayesian Multistate Models. JAMA Netw. Open 2019, 2, e187765. [Google Scholar] [CrossRef] [Green Version]
- Reix, B.; Bernhard, J.C.; Patard, J.J.; Bigot, P.; Villers, A.; Suer, E.; Vuong, N.S.; Verhoest, G.; Alimi, Q.; Beauval, J.B.; et al. Overall survival and oncological outcomes after partial nephrectomy and radical nephrectomy for cT2a renal tumors: A collaborative international study from the French kidney cancer research network UroCCR. Prog. Urol. 2018, 28, 146–155. [Google Scholar] [CrossRef]
- Hanna, N.; Einhorn, L.H. Testicular cancer: A reflection on 50 years of discovery. J. Clin. Oncol. 2014, 32, 3085–3092. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamdy, F.C.; Donovan, J.L.; Lane, J.A.; Mason, M.; Metcalfe, C.; Holding, P.; Davis, M.; Peters, T.J.; Turner, E.L.; Martin, R.M.; et al. 10-Year Outcomes after Monitoring, Surgery, or Radiotherapy for Localized Prostate Cancer. N. Engl. J. Med. 2016, 375, 1415–1424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Howlader, N.; Ries, L.A.; Mariotto, A.B.; Reichman, M.E.; Ruhl, J.; Cronin, K.A. Improved estimates of cancer-specific survival rates from population-based data. J. Natl. Cancer Inst. 2010, 102, 1584–1598. [Google Scholar] [CrossRef] [Green Version]
- Studer, U.E.; Whelan, P.; Wimpissinger, F.; Casselman, J.; de Reijke, T.M.; Knonagel, H.; Loidl, W.; Isorna, S.; Sundaram, S.K.; Collette, L.; et al. Differences in time to disease progression do not predict for cancer-specific survival in patients receiving immediate or deferred androgen-deprivation therapy for prostate cancer: Final results of EORTC randomized trial 30891 with 12 years of follow-up. Eur. Urol. 2014, 66, 829–838. [Google Scholar] [CrossRef] [PubMed]
- Steyerberg, E.W.; Moons, K.G.; van der Windt, D.A.; Hayden, J.A.; Perel, P.; Schroter, S.; Riley, R.D.; Hemingway, H.; Altman, D.G.; Group, P. Prognosis Research Strategy (PROGRESS) 3: Prognostic model research. PLoS Med. 2013, 10, e1001381. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in neural Information Processing Systems, Montreal, QB, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Leung, K.-M.; Elashoff, R.M.; Afifi, A.A. Censoring issues in survival analysis. Annu. Rev. Public Health 1997, 18, 83–104. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1321–1330. [Google Scholar]
- Gebski, V.; Gares, V.; Gibbs, E.; Byth, K. Data maturity and follow-up in time-to-event analyses. Int. J. Epidemiol. 2018, 47, 850–859. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harrell, F.E., Jr.; Lee, K.L.; Mark, D.B. Multivariable prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat. Med. 1996, 15, 361–387. [Google Scholar] [CrossRef]
- National Center for Health Statistics. Life Expectancy. Available online: https://www.cdc.gov/nchs/fastats/life-expectancy.htm (accessed on 20 February 2020).
- Duggan, M.A.; Anderson, W.F.; Altekruse, S.; Penberthy, L.; Sherman, M.E. The surveillance, epidemiology and end results (SEER) program and pathology: Towards strengthening the critical relationship. Am. J. Surg. Pathol. 2016, 40, e94–e102. [Google Scholar] [CrossRef] [PubMed]
- Betensky, R.A. Measures of follow-up in time-to-event studies: Why provide them and what should they be? Clin. Trials 2015, 12, 403–408. [Google Scholar] [CrossRef] [Green Version]
- Tsymbal, A. The problem of concept drift: Definitions and related work. Comput. Sci. Dep. Trinity Coll. Dublin 2004, 106, 58. [Google Scholar]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef] [Green Version]
- Horwich, A.; Shipley, J.; Huddart, R. Testicular germ-cell cancer. Lancet 2006, 367, 754–765. [Google Scholar] [CrossRef]
- Tamada, S.; Iguchi, T.; Kato, M.; Asakawa, J.; Kita, K.; Yasuda, S.; Yamasaki, T.; Matsuoka, Y.; Yamaguchi, K.; Matsumura, K.; et al. Time to progression to castration-resistant prostate cancer after commencing combined androgen blockade for advanced hormone-sensitive prostate cancer. Oncotarget 2018, 9, 36966–36974. [Google Scholar] [CrossRef] [Green Version]
- Aus, G.; Abbou, C.C.; Bolla, M.; Heidenreich, A.; Schmid, H.P.; van Poppel, H.; Wolff, J.; Zattoni, F.; European Association of Urology. EAU guidelines on prostate cancer. Eur. Urol. 2005, 48, 546–551. [Google Scholar] [CrossRef]
- Ljungberg, B.; Bensalah, K.; Canfield, S.; Dabestani, S.; Hofmann, F.; Hora, M.; Kuczyk, M.A.; Lam, T.; Marconi, L.; Merseburger, A.S. EAU guidelines on renal cell carcinoma: 2014 update. Eur. Urol. 2015, 67, 913–924. [Google Scholar] [CrossRef] [PubMed]
- Patel, H.D.; Singla, N.; Ghandour, R.A.; Freifeld, Y.; Cheaib, J.G.; Woldu, S.L.; Pierorazio, P.M.; Bagrodia, A. Site of extranodal metastasis impacts survival in patients with testicular germ cell tumors. Cancer 2019, 125, 3947–3952. [Google Scholar] [CrossRef] [PubMed]
- Reuter, V.E. Origins and molecular biology of testicular germ cell tumors. Mod. Pathol. 2005, 18, S51–S60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luck, M.; Sylvain, T.; Cardinal, H.; Lodi, A.; Bengio, Y. Deep learning for patient-specific kidney graft survival analysis. arXiv 2017, arXiv:1705.10245. [Google Scholar]
- Katzman, J.L.; Shaham, U.; Cloninger, A.; Bates, J.; Jiang, T.; Kluger, Y. Deep survival: A deep cox proportional hazards network. Stat 2016, 1050, 1–10. [Google Scholar]
- Zadeh, S.G.; Schmid, M. Bias in cross-entropy-based training of deep survival networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3126–3137. [Google Scholar] [CrossRef]
- Roblin, E.; Cournede, P.-H.; Michiels, S. On the Use of Neural Networks with Censored Time-to-Event Data. In Proceedings of the International Symposium on Mathematical and Computational Oncology, San Diego, CA, USA, 8–10 October 2020; pp. 56–67. [Google Scholar]
- Blanche, P.; Kattan, M.W.; Gerds, T.A. The c-index is not proper for the evaluation of-year predicted risks. Biostatistics 2019, 20, 347–357. [Google Scholar] [CrossRef]
- Harrell, F.E. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis; Springer: New York, NY, USA, 2001; Volume 608. [Google Scholar]
- FDA. FDA Expands Approval of Sutent to Reduce the Risk of Kidney Cancer Returning. Available online: https://www.fda.gov/news-events/press-announcements/fda-expands-approval-sutent-reduce-risk-kidney-cancer-returning (accessed on 21 June 2022).
- Oncology Drugs Approved by the FDA in Early 2018. Am. Health Drug Benefits 2018, 11, 209–210.
- Program SEER Quality Improvement. Available online: https://seer.cancer.gov/qi/ (accessed on 21 June 2022).
- Margaret Adamo, R.; Lewis, D.R.; Peace, S. Revising the Multiple Primary and Histology Coding Rules. J. Regist. 2007, 34, 81. [Google Scholar]
- Boustead, G.B.; Fowler, S.; Swamy, R.; Kocklebergh, R.; Hounsome, L.; Section of Oncology, B. Stage, grade and pathological characteristics of bladder cancer in the UK: British Association of Urological Surgeons (BAUS) urological tumour registry. BJU Int. 2014, 113, 924–930. [Google Scholar] [CrossRef] [Green Version]
- Grignon, D.J. The current classification of urothelial neoplasms. Mod. Pathol. 2009, 22, S60–S69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Germa-Lluch, J.R.; Garcia del Muro, X.; Maroto, P.; Paz-Ares, L.; Arranz, J.A.; Guma, J.; Alba, E.; Sastre, J.; Aparicio, J.; Fernandez, A.; et al. Clinical pattern and therapeutic results achieved in 1490 patients with germ-cell tumours of the testis: The experience of the Spanish Germ-Cell Cancer Group (GG). Eur. Urol. 2002, 42, 553–562, discussion 562–553. [Google Scholar] [CrossRef]
- Ljungberg, B.; Albiges, L.; Abu-Ghanem, Y.; Bensalah, K.; Dabestani, S.; Fernandez-Pello, S.; Giles, R.H.; Hofmann, F.; Hora, M.; Kuczyk, M.A.; et al. European Association of Urology Guidelines on Renal Cell Carcinoma: The 2019 Update. Eur. Urol. 2019, 75, 799–810. [Google Scholar] [CrossRef] [PubMed]
- Roupret, M.; Babjuk, M.; Comperat, E.; Zigeuner, R.; Sylvester, R.; Burger, M.; Cowan, N.; Bohle, A.; Van Rhijn, B.W.; Kaasinen, E.; et al. European guidelines on upper tract urothelial carcinomas: 2013 update. Eur. Urol. 2013, 63, 1059–1071. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:14123555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Computation. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:arXiv:14126980. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural Networks for Machine Learning Lecture 6a Overview of Mini-Batch Gradient Descent. Available online: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 21 June 2022).
- Brent, R.P. Algorithms for Minimization without Derivatives. Available online: https://maths-people.anu.edu.au/~brent/pub/pub011.html (accessed on 21 June 2022).
- Royston, P.; Altman, D.G. External validation of a Cox prognostic model: Principles and methods. BMC Med Res. Methodol. 2013, 13, 33. [Google Scholar] [CrossRef] [Green Version]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eminaga, O.; Shkolyar, E.; Breil, B.; Semjonow, A.; Boegemann, M.; Xing, L.; Tinay, I.; Liao, J.C. Artificial Intelligence-Based Prognostic Model for Urologic Cancers: A SEER-Based Study. Cancers 2022, 14, 3135. https://doi.org/10.3390/cancers14133135
Eminaga O, Shkolyar E, Breil B, Semjonow A, Boegemann M, Xing L, Tinay I, Liao JC. Artificial Intelligence-Based Prognostic Model for Urologic Cancers: A SEER-Based Study. Cancers. 2022; 14(13):3135. https://doi.org/10.3390/cancers14133135
Chicago/Turabian StyleEminaga, Okyaz, Eugene Shkolyar, Bernhard Breil, Axel Semjonow, Martin Boegemann, Lei Xing, Ilker Tinay, and Joseph C. Liao. 2022. "Artificial Intelligence-Based Prognostic Model for Urologic Cancers: A SEER-Based Study" Cancers 14, no. 13: 3135. https://doi.org/10.3390/cancers14133135