
ATNet: A Defect Detection Framework for X-ray Images of DIP Chip Lead Bonding
 ,
,
Abstract
:1. Introduction
- A novel ATSPPF module is introduced, which enables comprehensive feature extraction. This module effectively combines features from various scales and employs adaptive weighting in both the spatial and channel domains to enhance the expression of features;
- Based on the ATSPPF module, an accurate and fast chip wire bonding defect detection model framework, ATNet, was specifically designed to achieve the automated, rapid, and highly accurate detection of lead bonding defects;
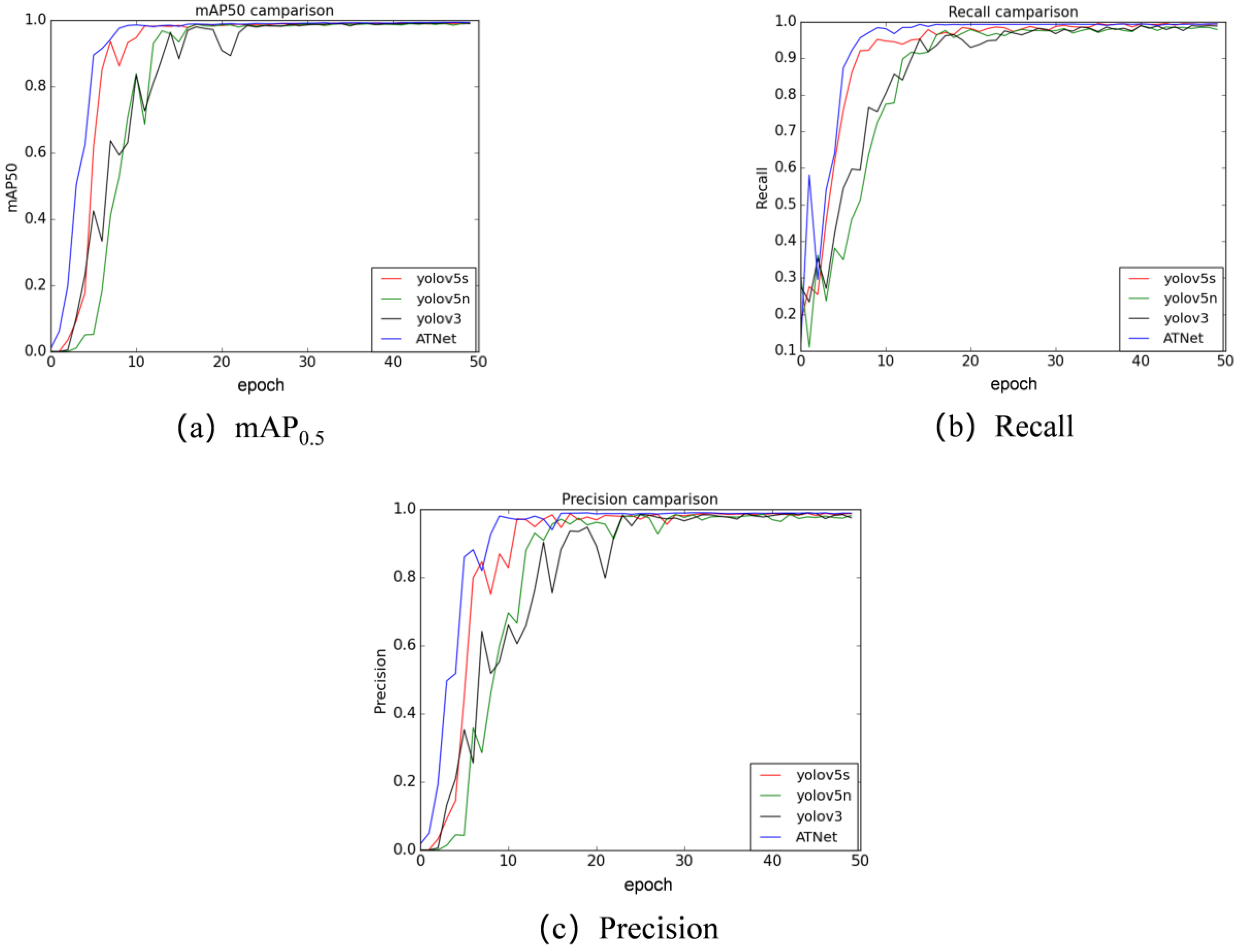
- Within the dataset, the average detection accuracy (mAP0.5) achieved was an impressive 99.4%, while the detection speed reached 146 frames per second (FPS), outperforming other state-of-the-art networks, such as yolov5s and yolox.
2. Related Work
2.1. Data Acquisition and Augmentation
2.2. Object Detection
2.3. The Position of the Target Object
2.4. Activation Functions
3. Methodology
3.1. CGC Module
3.2. ATSPPF Module
3.3. Feature Map
4. Experiments
4.1. Experimental Setup
4.2. Evaluation Criterion
4.3. Ablation Studies
4.4. Comparison of State-of-the-Art Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tu, K.-N.; Liu, Y. Recent advances on kinetic analysis of solder joint reactions in 3D IC packaging technology. Mater. Sci. Eng. R Rep. 2019, 136, 1–12. [Google Scholar] [CrossRef]
- Aryan, P.; Sampath, S.; Sohn, H. An overview of non-destructive testing methods for integrated circuit packaging inspection. Sensors 2018, 18, 1981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsai, M.-Y.; Hsu, C.J.; Wang, C.T.O. Investigation of thermomechanical behaviors of flip chip BGA packages during manufacturing process and thermal cycling. IEEE Trans. Compon. Packag. Technol. 2004, 27, 568–576. [Google Scholar] [CrossRef]
- Borgesen, P.; Hamasha, S.; Obaidat, M.; Raghavan, V.; Dai, X.; Meilunas, M.; Anselm, M. Solder joint reliability under realistic service conditions. Microelectron. Reliab. 2013, 53, 1587–1591. [Google Scholar] [CrossRef]
- Pecht, M.; Barker, D.; Lall, P. Development of an alternative wire bond test technique. IEEE Trans. Compon. Packag. Manuf. Technol. Part A 1994, 17, 610–615. [Google Scholar] [CrossRef]
- Luo, H.; Lu, Z.; Nam, J.; Chen, P.; Lin, W. Evaluation of wire bond integrity through force detected wire vibration analysis. In Proceedings of the 2009 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Singapore, 14–17 July 2009; pp. 1–5. [Google Scholar]
- Feng, W.; Chen, X.; Wang, C.; Shi, Y. Application research on the time–frequency analysis method in the quality detection of ultrasonic wire bonding. Int. J. Distrib. Sens. Netw. 2021, 17, 15501477211018346. [Google Scholar] [CrossRef]
- Kannan, S.; Kim, B.; Taenzler, F. Forced-resonance test technique for multiple wirebonds in electronic packages. In Proceedings of the 2012 IEEE 14th Electronics Packaging Technology Conference (EPTC), Singapore, 5–7 December 2012; pp. 625–630. [Google Scholar]
- Hanke, R.; Fuchs, T.; Uhlmann, N. X-ray based methods for non-destructive testing and material characterization. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2008, 591, 14–18. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, J.; Zeng, D.; Tao, X.; Ma, J. Regularization strategies in statistical image reconstruction of low-dose x-ray CT: A review. Med. Phys. 2018, 45, e886–e907. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Zhou, W.; Kuang, Q.; Cao, L.; Gao, B. Defect detection of IC wafer based on spectral subtraction. IEEE Trans. Semicond. Manuf. 2010, 23, 141–147. [Google Scholar]
- Sreenivasan, K.K.; Srinath, M.; Khotanzad, A. Automated vision system for inspection of IC pads and bonds. IEEE Trans. Compon. Hybrids Manuf. Technol. 1993, 16, 333–338. [Google Scholar] [CrossRef]
- Huang, Y.; Pan, Q.; Liu, Q.; He, X.P.; Liu, Y.F.; Yu, Y.Q. Application of improved canny algorithm on the ic chip pin inspection. Adv. Mater. Res. 2011, 317–319, 854–858. [Google Scholar] [CrossRef]
- Perng, D.-B.; Lee, S.-M.; Chou, C.-C. Automated bonding position inspection on multi-layered wire IC using machine vision. Int. J. Prod. Res. 2010, 48, 6977–7001. [Google Scholar] [CrossRef]
- Zhan, D.; Lin, J.; Yang, X.; Huang, R.; Yi, K.; Liu, M.; Zheng, H.; Xiong, J.; Cai, N.; Wang, H.; et al. A Lightweight Method for Detecting IC Wire Bonding Defectsin X-ray Images. Micromachines 2023, 14, 1119. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.Y.; Yiu, K.F.C.; Lam, H.-K.; Wong, B.W. Ball bonding inspections using a conjoint framework with machine learning and human judgement. Appl. Soft Comput. 2021, 102, 107115. [Google Scholar] [CrossRef]
- Xie, Q.; Long, K.; Lu, D.; Li, D.; Zhang, Y.; Wang, J. Integrated Circuit Gold Wire Bonding Measurement Via 3-D Point Cloud Deep Learning. IEEE Trans. Ind. Electron. 2021, 69, 11807–11815. [Google Scholar] [CrossRef]
- Kao, S.X.; Chien, C.F. Deep Learning Based Positioning Error Fault Diagnosis of Wire Bonding Equipment and an Empirical Study for IC Packaging. IEEE Trans. Semicond. Manuf. 2023. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, Z.; Wu, F. A data-driven method for enhancing the image-based automatic inspection of IC wire bonding defects. Int. J. Prod. Res. 2021, 59, 4779–4793. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 10781–10790. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y.J.a.p.a. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Work-Shops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Liu, M.; Chen, Y.; He, L.; Zhang, Y.; Xie, J. LF-YOLO: A lighter and faster yolo for weld defect detection of X-ray image. arXiv 2021, arXiv:2110.15045. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y. PP-PicoDet: A better real-time object detector on mobile devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample |  |  |  |  |  |
| Number | 712 | 724 | 642 | 664 | 656 |
| Type | high loop | broken wire | low loop | wire missing | sagged wire |
| Layer Name | Filters | Output Shape |
|---|---|---|
| CBL | 128 | 20 × 20 × 128 |
| MaxPool (k = 5) | / | 20 × 20 × 128 |
| MaxPool (k = 9) | / | 20 × 20 × 128 |
| MaxPool (k = 13) | / | 20 × 20 × 128 |
| Concat | / | 20 × 20 × 512 |
| CBL | 256 | 20 × 20 × 256 |
| CBAM | 256 | 20 × 20 × 256 |
| Concat | / | 20 × 20 × 512 |
| CBL | 256 | 20 × 20 × 256 |
| Add | / | 20 × 20 × 256 |
| Number | C3 | CGC | ATSPPF | mAP0.5–0.95 | FPS | |
|---|---|---|---|---|---|---|
| 1 | ✓ | — | — | 0.992 | 0.677 | 142 |
| 2 | — | ✓ | — | 0.993 | 0.687 | 151 |
| 3 | ✓ | — | ✓ | 0.989 | 0.695 | 97 |
| 4 | — | ✓ | ✓ | 0.994 | 0.693 | 146 |
| SE | CA | CBAM | mAP0.5–0.95 | |
|---|---|---|---|---|
| ✓ | — | — | 0.992 | 0.692 |
| — | ✓ | — | 0.992 | 0.687 |
| — | — | ✓ | 0.994 | 0.693 |
| Method | (%) | FPS | GFLOPs (G) | Params (M) |
|---|---|---|---|---|
| Faster R-CNN-ResNet50 | 95.8 | 23 | 250.0 | 108.0 |
| Dynamic R-CNN-ResNet50 | 95.9 | 21 | 248.5 | 107.0 |
| RetinaNet-ResNet50 | 95.9 | 28 | 227.9 | 93.4 |
| SSD300-VGG16 | 94.4 | 56 | 30.8 | 92.5 |
| VFNet-ResNet50 | 95.1 | 21 | 224.5 | 98.3 |
| Yolov5n | 98.8 | 105 | 4.5 | 1.9 |
| YOLOv3 | 98.8 | 64 | 155.0 | 117.0 |
| YOLOv3-tiny | 99.2 | 143 | 13.0 | 8.28 |
| YOLOv5s | 99.1 | 96 | 16.0 | 7.2 |
| YOLOXs | 97.1 | 56 | 13.2 | 8.5 |
| GhostNet-YOLOv5s | 99.0 | 53 | 8.3 | 5.4 |
| ATNet(ours) | 99.4 | 146 | 7.2 | 3.97 |
| Method | Backbone | Recall | Precision | |||
|---|---|---|---|---|---|---|
| Original | Yolov3 | \ | 0.988 | 0.993 | 0.988 | 0.703 |
| Faster-rcnn | resnet50 | 0.990 | 0.984 | 0.958 | 0.692 | |
| SSD | vgg16 | 0.938 | 0.952 | 0.944 | 0.681 | |
| SSD | mobilenetv2 | 0.942 | 0.957 | 0.935 | 0.686 | |
| YoloR | \ | 0.965 | 0.956 | 0.961 | 0.689 | |
| LFyolo | \ | 0.981 | 0.978 | 0.971 | 0.699 | |
| Sclaed_yolov4 | \ | 0.931 | 0.956 | 0.959 | 0.708 | |
| With ATSPPF | Yolov3 | \ | 0.996 | 0.997 | 0.992 | 0.719 |
| Faster-rcnn | resnet50 | 0.987 | 0.987 | 0.965 | 0.698 | |
| SSD | vgg16 | 0.945 | 0.966 | 0.957 | 0.690 | |
| SSD | mobilenetv2 | 0.954 | 0.953 | 0.942 | 0.692 | |
| LFyolo | \ | 0.959 | 0.966 | 0.984 | 0.696 | |
| YoloR | \ | 0.987 | 0.982 | 0.981 | 0.709 | |
| Sclaed_yolov4 | \ | 0.961 | 0.966 | 0.976 | 0.711 |
| Method | (%) | (%) | GFLOPs (G) | Size (M) |
|---|---|---|---|---|
| YOLOv5-mobilenetv3 | 67.6 | 32.6 | 11.3 | 13.8 |
| YOLOxs | 63.3 | 31.2 | 13.2 | 68.5 |
| SSD300-VGG16 | 67.6 | 29.6 | 30.8 | 186.0 |
| YOLOv7-tiny | 65.5 | 29.1 | 13.2 | 12.3 |
| YoloR | 61.8 | 26.2 | 80.7 | 141.0 |
| LF-YOLO | 59.5 | 23.4 | 16.3 | 14.9 |
| PicoDst-s [42] | 59.1 | 24.3 | 13.8 | 3.1 |
| Yolov3-tiny | 52.1 | 20.2 | 13.0 | 17.5 |
| YOLOv5s | 69.8 | 32.5 | 16.0 | 6.7 |
| ATNet(ours) | 71.5 | 35.2 | 7.2 | 8.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.; Zhan, D.; Yang, X.; Zhou, B.; Tang, L.; Cai, N.; Wang, H.; Qiu, B. ATNet: A Defect Detection Framework for X-ray Images of DIP Chip Lead Bonding. Micromachines 2023, 14, 1375. https://doi.org/10.3390/mi14071375
Huang R, Zhan D, Yang X, Zhou B, Tang L, Cai N, Wang H, Qiu B. ATNet: A Defect Detection Framework for X-ray Images of DIP Chip Lead Bonding. Micromachines. 2023; 14(7):1375. https://doi.org/10.3390/mi14071375
Chicago/Turabian StyleHuang, Renbin, Daohua Zhan, Xiuding Yang, Bei Zhou, Linjun Tang, Nian Cai, Han Wang, and Baojun Qiu. 2023. "ATNet: A Defect Detection Framework for X-ray Images of DIP Chip Lead Bonding" Micromachines 14, no. 7: 1375. https://doi.org/10.3390/mi14071375