1. Introduction
The complex and changeable indoor environment brings great difficulties and challenges to indoor positioning technology. Due to factors such as wall occlusion and multipath effects, satellite signals cannot achieve stable positioning results indoors [
1]. Positioning methods based on Wi-Fi [
2], radiofrequency identification, Bluetooth [
3], ultrawideband (UWB) [
4], and ZigBee [
5] cannot achieve the mature positioning performance of GNSS because their accuracy is affected by problems such as electromagnetic interference, distance limitation, multipath effects, and high costs. The rapid development of the microelectromechanical system (MEMS) inertial measurement unit (IMU) has been widely used in the military, industrial, and civil fields by virtue of its low cost, low power consumption, and small size. It often appears in various integrated navigation systems with unique advantages. In addition, machine vision positioning promoted by artificial intelligence stands out because it does not require additional equipment [
6,
7,
8]. This image-based method makes it possible to achieve good positioning performance in an economical and applicable way [
9]. At present, indoor positioning technology based on a fingerprint database is one of the hotspots of visual localization. This method mainly includes two stages. The first is the offline fingerprint database construction stage, i.e., collecting fingerprint information in the indoor environment and recording the corresponding location labels. The second is position estimation in the online stage, i.e., comparing the fingerprint information input with the database so as to obtain the coordinates of the point to be located.
To obtain high-precision positioning results in a low-cost way and ensure the accuracy of dataset construction with cheap and popular equipment, it is necessary to obtain coordinates that can provide strong support for future navigation. Therefore, in the offline dataset construction stage, we consider the image acquisition equipment, acquisition methods, and how to obtain image attitude and position. Using the image and corresponding information obtained in the offline stage, the disadvantages of the current positioning method are studied to establish the necessity of using epipolar geometry for positioning. According to the analysis of the current pose acquisition methods under the epipolar constraint, we determine the implementation of this study. Lastly, the problems existing in other location determination methods are studied to determine the realization route of obtaining the three-dimensional positioning result.
Image fingerprint acquisition devices are divided into three categories, monocular, binocular, and RGB-D cameras that can obtain depth information. The Kinect sensor developed by Microsoft is most widely used to capture depth information. Some studies [
10,
11,
12] took a depth camera as the carrier to acquire indoor color and depth images, and then built a visual positioning framework on the basis of image features and depth information. The binocular camera can obtain the depth data of target points according to the focal length, baseline, and parallax matrix. However, depth and binocular cameras are expensive, significantly reducing their ease of use and universality. With the popularity of smartphone terminals and the reduction in the cost of vision sensors, indoor visual positioning based on monocular images has broader application prospects.
There exist some practical problems indoors, such as a large area with complex and changeable environments. It is an important problem to construct an effective fingerprint database with limited resources on the premise of ensuring localization efficiency and accuracy. Monocular images can be used to build offline databases by shooting videos [
13,
14,
15], constructing landmark feature descriptors [
16], and obtaining fingerprint information at reference points [
17,
18]. When building an offline database, we prefer getting images with accurate positions and poses. The error divergence is fast when only using IMU for navigation; thus, it cannot complete the task of indoor positioning alone. However, the built-in IMU of smartphones can obtain precise pose information, significantly improving the accuracy of dataset construction. Therefore, we took images at fixed reference points to build an accurate offline dataset. The poses calculated by the built-in accelerometer and magnetometer are used as location labels.
The main task of the online stage is to obtain an accurate position. Some scholars are devoted to research on image retrieval technology [
19,
20], returning the location label of the retrieved image to the user as the positioning result. Although these image retrieval methods gradually achieve higher accuracy, directly using the retrieval results as localization results depends on the image acquisition density of the dataset [
21]. Intensive collection points improve the accuracy, but also have the disadvantages of increasing the workload of dataset construction and the number of retrieval operations, as well as reducing the efficiency. The development of depth restoration technology solves the mutual exclusion of acquisition density and database size. Image-based depth estimation methods directly calculate the depth information from the input RGB images [
22,
23]. There is no need for expensive equipment, providing a broader application space [
24]. According to the number of required input images, it can be divided into monocular depth estimation and multi-view depth estimation. Due to the lack of depth clues, monocular depth estimation often needs to obtain information on the basis of perspective projections, shadows, and other environmental assumptions for calculation, which is an ill-posed problem. The multi-view depth estimation method calculates the depth information on the basis of several observed images. Classical methods include structure from motion (SfM), multi-view system (MVS), and triangulation. However, these methods need to obtain the actual coordinates of some feature points, which is a massive requirement in the offline dataset establishment.
In addition, iterative closest point (ICP) is used to solve the device pose estimation problem in 3D. The depth estimation of monocular images can obtain the relative pose from the object coordinate system to the camera coordinate system through perspective-n-point (PnP) and its improved algorithms [
25,
26,
27]. It can solve the pose estimation problem between 3D and 2D when
n 3D points and their projection positions are known. Both ICP and PnP need to know the actual 3D coordinates of some features. This kind of method has a massive workload in the offline database construction of large buildings, and it is straightforward to introduce random deviation into the final positioning result due to tool and operation errors.
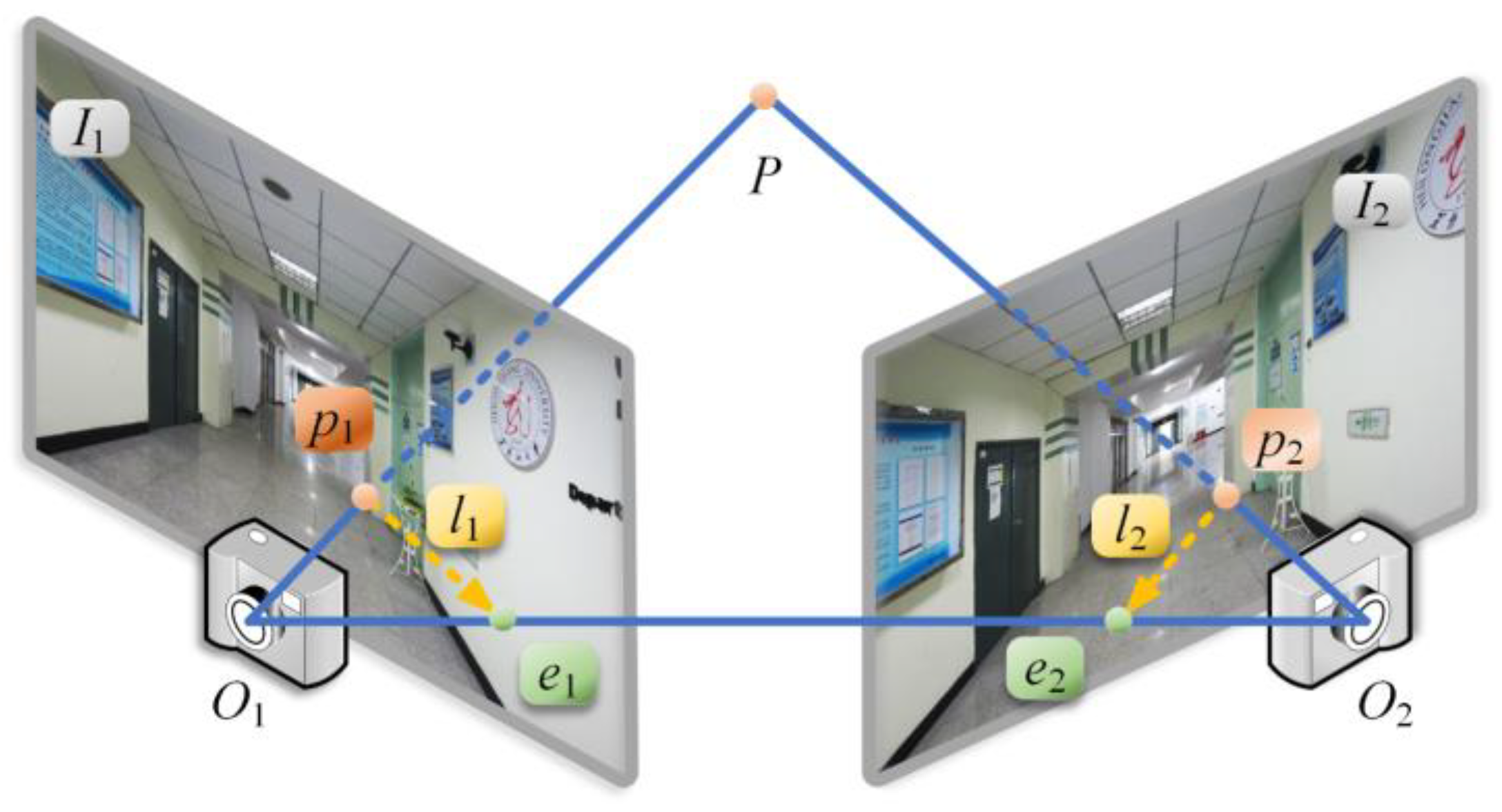
For monocular images, the fundamental matrix is calculated according to the principle of epipolar geometry, so as to obtain the camera position and pose changes in 2D [
28]. The existing fundamental matrix estimation methods can be roughly divided into three types: linear estimation based on algebraic error, nonlinear estimation based on iteration, and hypothesis testing strategy. Among them, the linear estimation method includes the traditional normalized eight-point method [
29], seven-point method, n-point method, and improved eight-point method. Fischler et al. proposed a random sample consensus (RANSAC) algorithm [
30]. It can estimate the parameters of a mathematical model iteratively from a set of observation data containing outlier points, and it is widely used in solving fundamental matrices. With the deepening of the problem, researchers have proposed improved methods based on the inspection strategy least median of squares (LMedS) [
31].
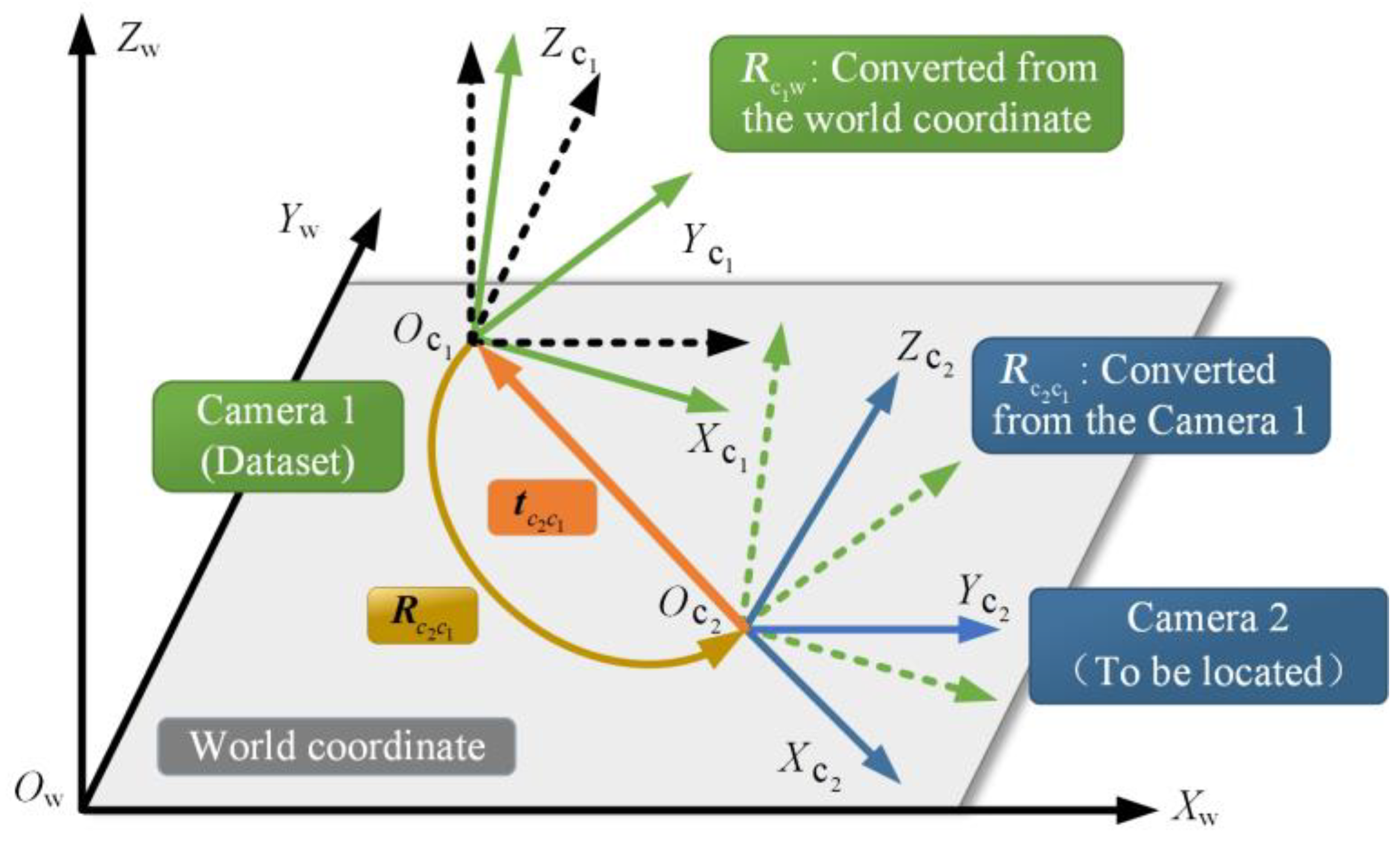
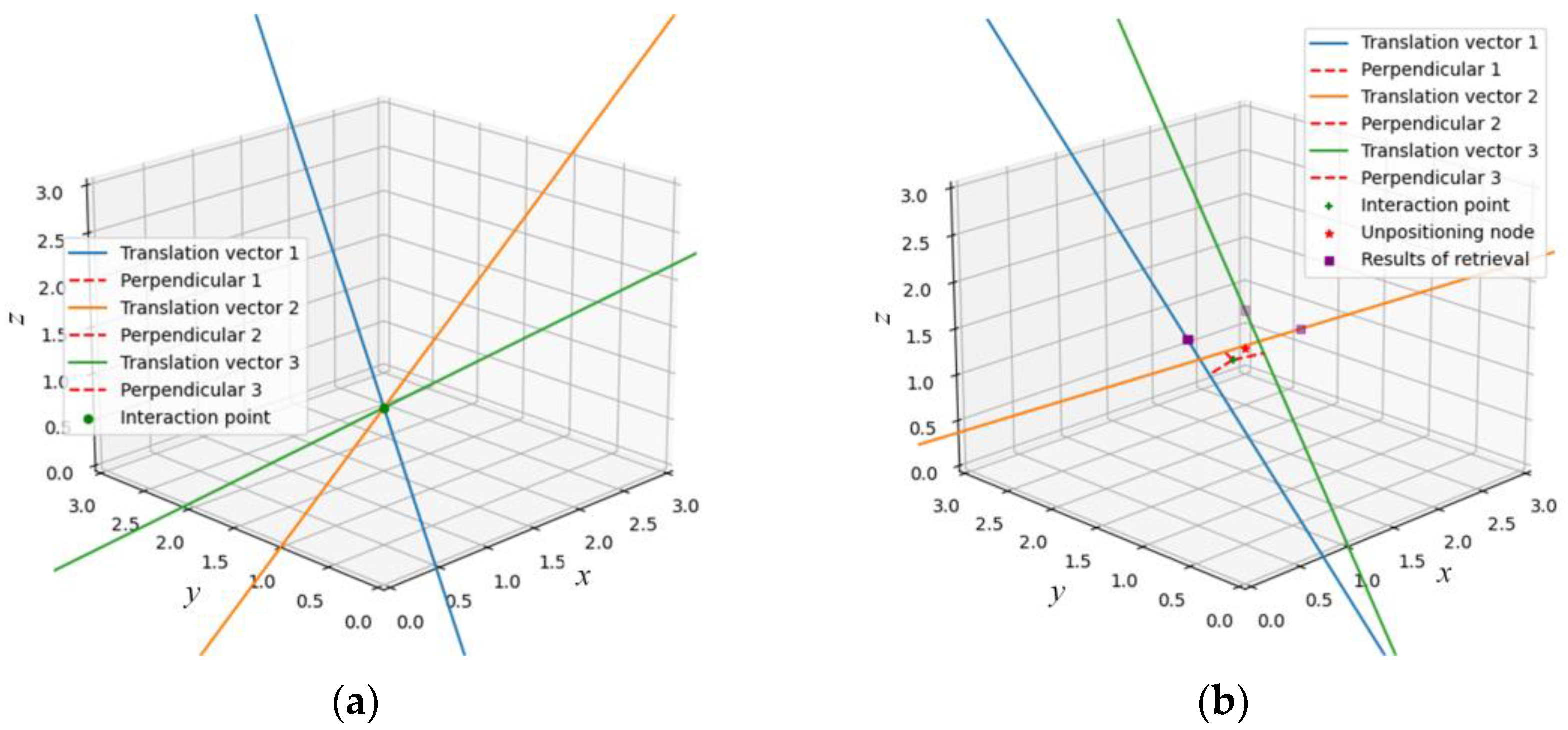
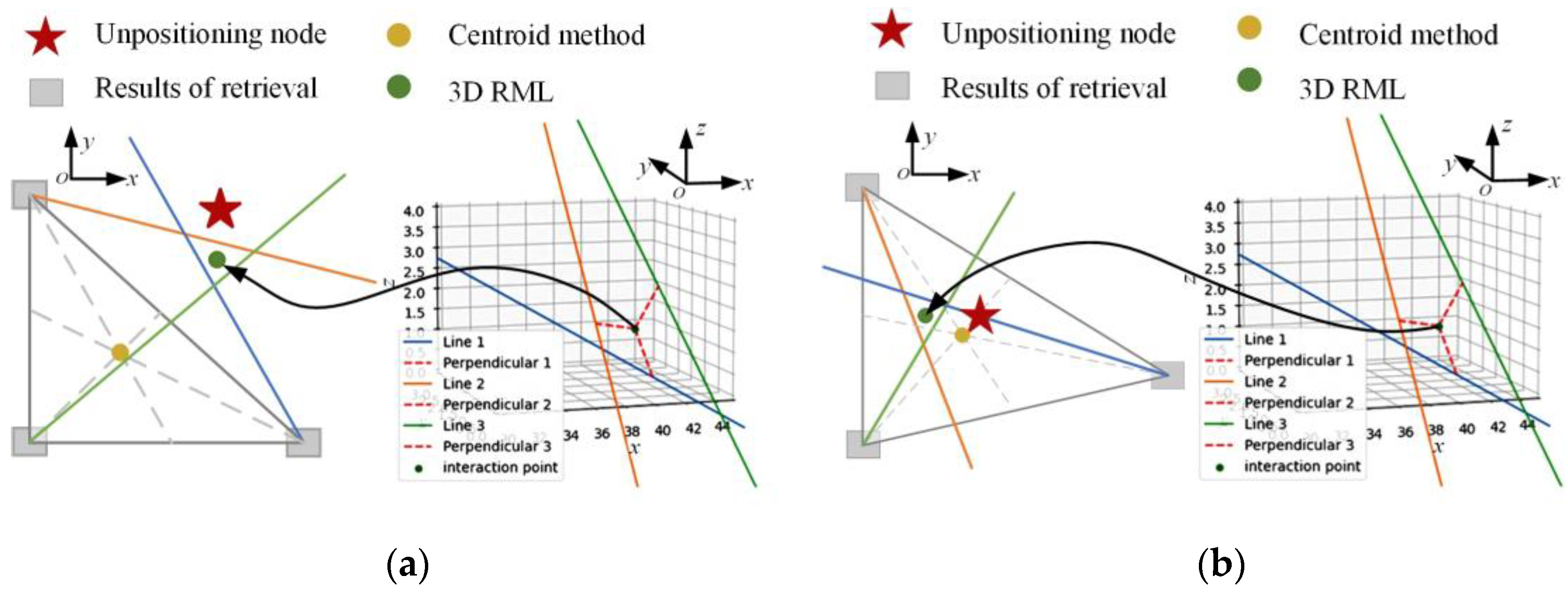
After obtaining the pose information, namely, the rotation vector and the translation vector, it is the last step in the positioning process to determine the final coordinates according to the direction vector whose modulus length is unknown and only represents the relative position relation. A geometric relationship composed of multiple direction vectors can be constructed through the pose transformation of a single query image and multiple dataset images. All direction vectors will theoretically intersect at the same point, i.e., the undetermined point where the user is located. However, it is difficult for multiple vectors to converge under the influence of measurement and calculation errors. The authors of [
32,
33] calculated the distance from each direction vector intersection point to other direction vectors, and returned the coordinates of the intersection point with the minimum distance to the user. The authors of [
34] considered the correct matching of the retrieved images. For each intersection point, its distance to each retrieved image was calculated, and the number of correct matching pairs was used as a weight to multiply the distance. Lastly, the minimum sum of weighted distance of the corresponding intersection point was obtained as the positioning coordinates. Although the above methods can obtain the positioning point, they all project the three-dimensional vector to the two-dimensional plane for calculation. They increase intersection points by reducing dimension and losing altitude information. In addition, they all choose the intersection point that may occur at infinity as the final result, which is prone to being wide of the mark.
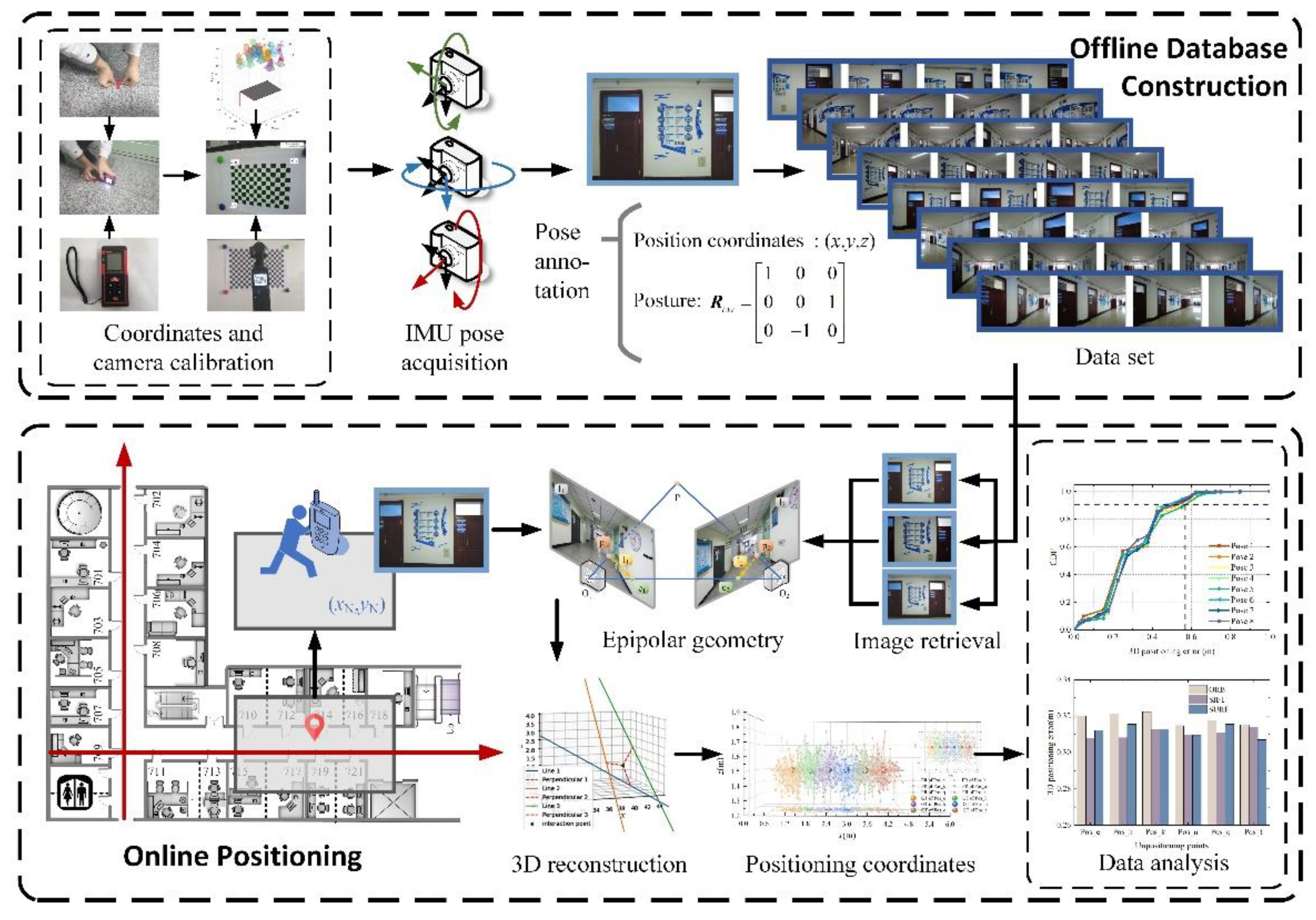
For this reason, in view of the shortcomings of the existing position determination methods that can only obtain 2D coordinates, taking into account the fact that a single positioning method cannot meet the positioning accuracy requirements of complex and changeable indoor environments, a Three-dimensional reconstruction localization method based on threshold dynamic selection (3D RLM-TDS) is proposed. This method uses an accelerometer and magnetometer to obtain accurate pose labels to construct the dataset. Then, it calculates the relative pose relationship between several images from the dataset with pose labels and the image taken at the point to be located according to the epipolar constraint. In the case that the direction vectors pointing to the undetermined point from the retrieved dataset images cannot converge due to the existence of mixed error, the positioning problem is transformed into solving the minimum distance in 3D space. In this way, we can solve the problem that the direction vector modulus length obtained from the epipolar geometry calculation is unknown, and we can achieve the effect of reconstructing the 3D information in positioning. The roadmap of this paper is shown in
Figure 1. The main contributions are as follows:
An image collection framework is designed with accurate poses to construct the offline database. It uses built-in sensors of a smartphone to obtain relevant data on the basis of Matlab Mobile, and then calculates the Euler angles of the device when shooting images of the dataset.
In the online stage, an indoor visual positioning method with three-dimensional coordinates using accelerometer and magnetometer is proposed to solve the problems of modulus length loss and only 2D coordinates being obtained in position determination after epipolar geometry. The relative direction of the query image is determined according to the direction vector of the retrieved image pointing to itself. The localization problem is transformed into solving the distance between one point and multiple lines in 3D space to solve the situation that the positioning lines do not converge due to errors.
A WeChat positioning mini-program mounted on the mobile intelligent terminal is built, and the user’s location is determined in the experimental scene by means of human–computer interaction. The localization error is calculated under different image retrieval schemes, three feature extraction methods, and eight shooting poses, so as to verify the accuracy, robustness, and adaptability of the positioning method proposed in this paper.
4. Performance Verification
4.1. Dataset Selection
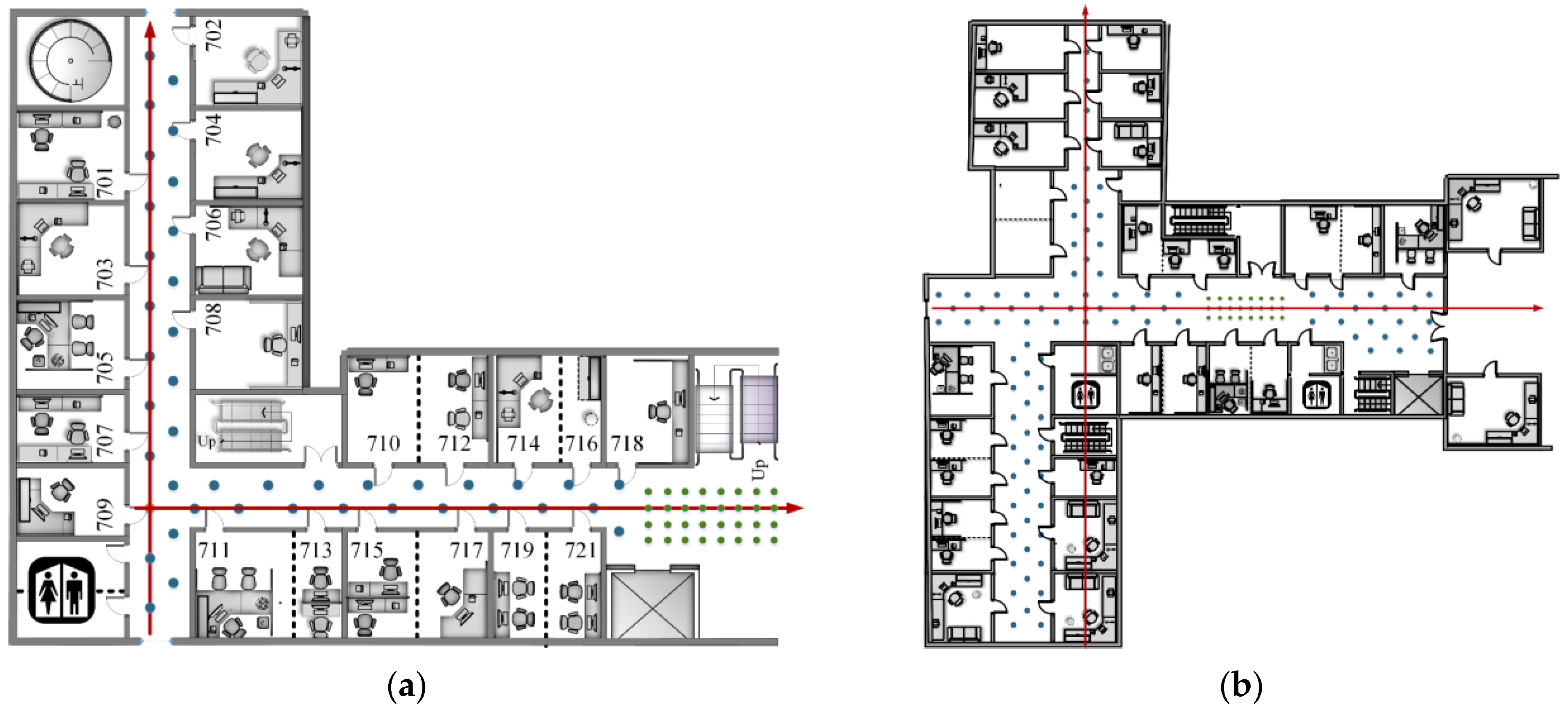
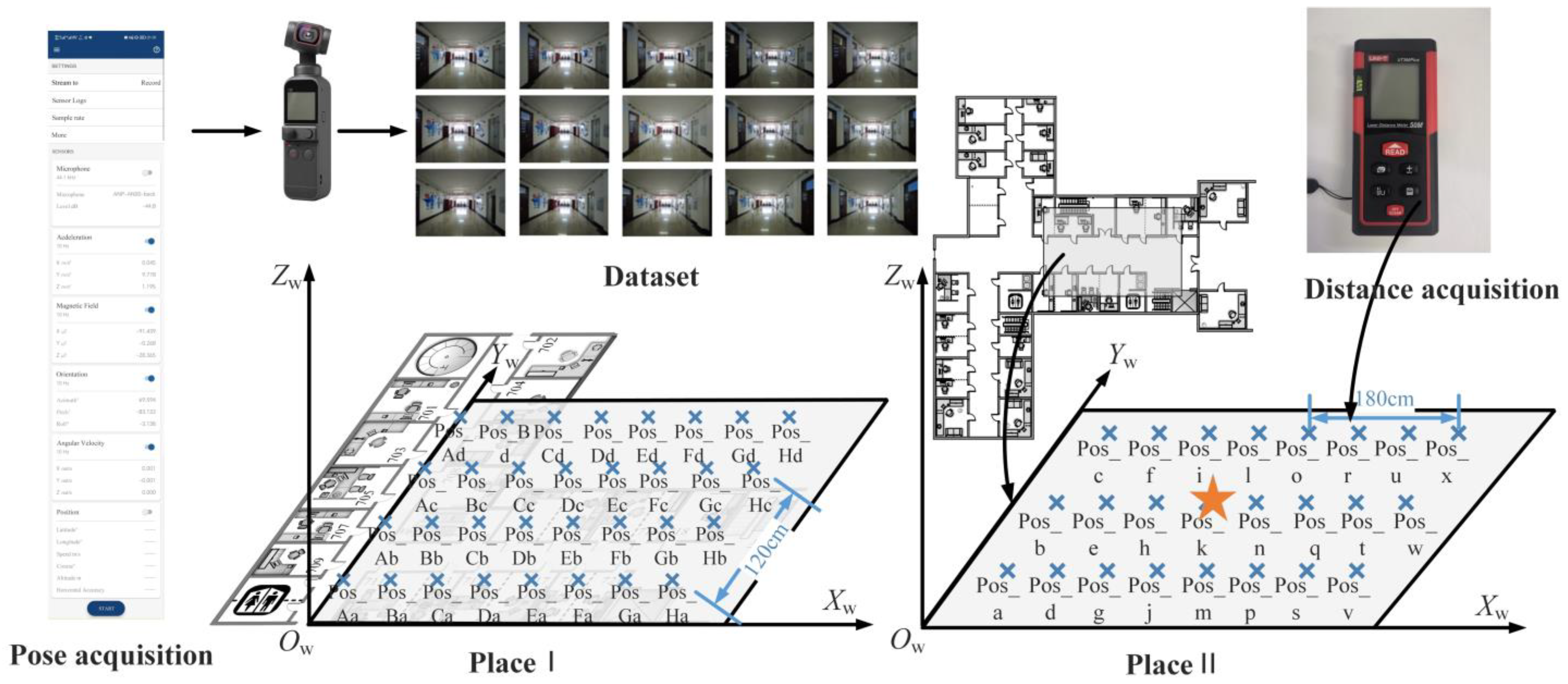
Large indoor places such as shopping malls, supermarkets, teaching buildings, hospitals, and parking lots are located in complex buildings. As shown in the first column of yellow lines in
Figure 17, although the overall structure of the building presents a symmetrical distribution, the external outline is irregular, and the layout of the rooms in the building is also crisscrossed. The corridors, stairwells, and passageways between the buildings are intricate. Therefore, it is necessary to conduct indoor positioning for this kind of environment.
This experiment chose a teaching building as scene Ⅱ, including multimedia classrooms, conference rooms, lecture halls, offices, laboratories, and underground parking lots. The structure of the building is complex, and there are many corridors and intersections. The orange rectangle in the middle of
Figure 17 shows the corridors, and the corresponding blue arrow shows their direction. Therefore, it is in line with the building structure that needs indoor positioning. As shown by the blue circle in the last column of
Figure 15, the building contains a large number of corners, columns, partitions, etc., which meets the condition of uneven occlusion of the building to the line of sight and the requirements for performance verification of the positioning method. In order to avoid the contingency of a single scene experiment, we selected the laboratory building as scene Ⅰ, which is similar in structure to scene Ⅱ.
In order to verify that the localization method can cope with different image retrieval methods and apply different poses and feature extraction methods, we traversed all possible retrieved images to obtain the final localization result. Eight representative directions were used to represent different poses, and three classical feature extraction methods were selected, covering the extraction of spot and corner features. The positioning results were visualized, and the positioning accuracy was compared.
4.2. Positioning Effect
In order to verify the accuracy of positioning, experiments were carried out on the two scenes mentioned in
Section 3.1.1, and the positioning point arrangement is shown in
Figure 18.
The corridor in the building was narrow in scene Ⅰ; hence, the square hall in scene Ⅱ was selected as the main test site. Data were collected from five effective shooting directions of 32 test points in this corridor. Considering that the width of the corridor in the actual scene and the positioning performance to be verified need to ensure the diversity of poses, the center line of the corridor was selected as the central axis of the test point in scene Ⅱ, which was expanded at an interval of 0.6 m. The 24 sampling points covered all eight representative directions for image shooting. In order to verify the comprehensive positioning effect and accuracy, scene Ⅱ was taken as an example of the subsequent positioning experiment.
4.2.1. Effect of Different Range of Image Retrieval Results on Localization Accuracy
The purpose of image retrieval is to obtain several images that are most similar to the image to be located. Due to the large camera angle of view, the retrieved results may also be obtained because some local patterns in the angle of view are very similar. However, the distance between the images is far at this time. As shown in
Figure 16, the images in the dataset were all taken in the same local area in the same direction. The minimum distance between the images was 0.6 m, and the furthest distance was about 3 m. The similarity between images was too great to ensure that the source range of retrieval results was in a stable state.
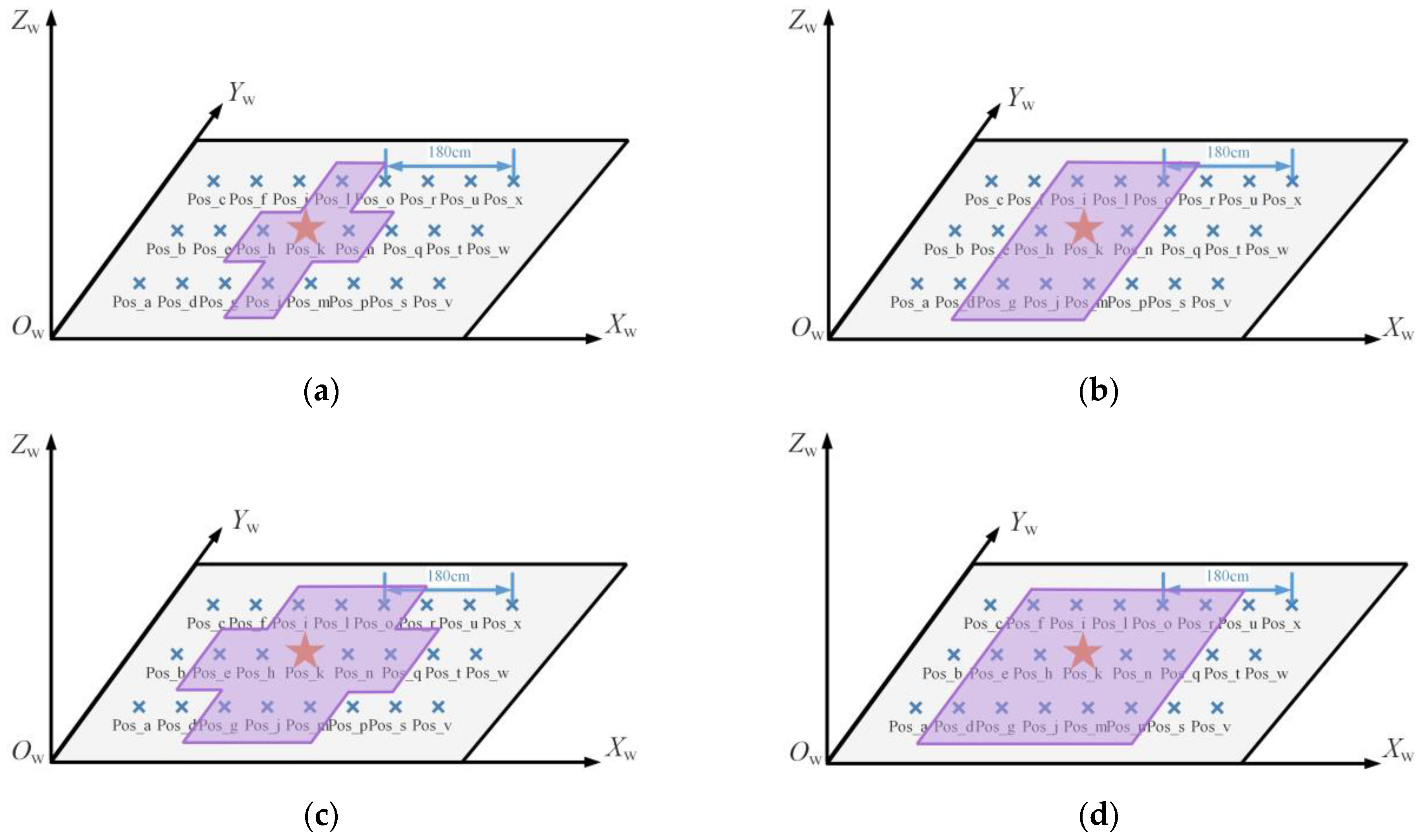
Therefore, in order to explore the influence of the distance between the image retrieval result and the point to be located on the positioning accuracy, the experiment was conducted on the range of the result source. Scene Ⅱ was taken as an example, corresponding to the reference points in green in
Figure 8b. The position of point Pos_k, represented by an asterisk in
Figure 18, is the point to be located, while the remaining points Pos_a to Pos_x are the positions of the images in the dataset.
The ranges of different sources of image retrieval results are shown in purple in
Figure 17. When the retrieval results all came from the four points around Pos_k, namely, Pos_h, Pos_j, Pos_l and Pos_n, as shown in
Figure 19a, the distance between the retrieval results and the undetermined site was 0.6 m. When the results came from the surrounding eight, 10, and 14 points, the corresponding source ranges of search results are as shown in
Figure 19b–d. The number of surrounding points represents the distance range between the dataset and the node to be located, and the corresponding relationship is shown in
Table 2.
With different image retrieval results, different source ranges of points were used to determine coordinates, resulting in different final positioning accuracy. When the retrieval results came from eight representative directions of the surrounding
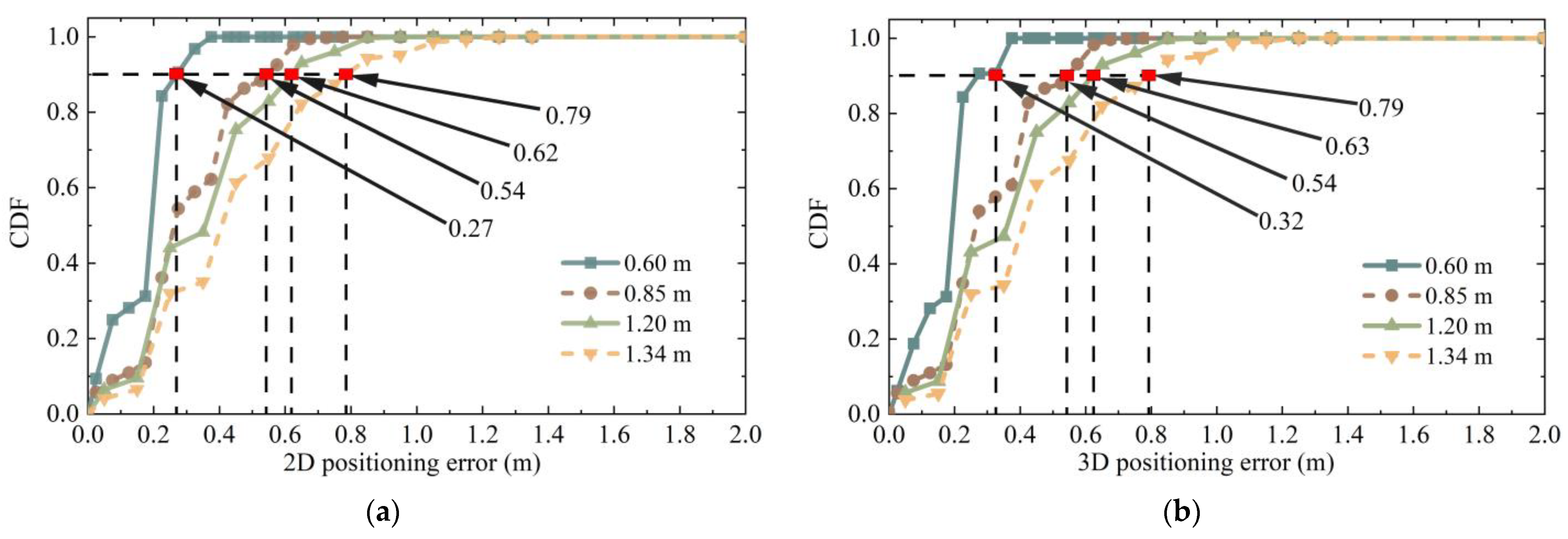
nodes, Pos_k was used as the test point for the experiment with the localization method proposed in this paper, and the first three most similar retrieved images were used for localization. Considering that the retrieval results obtained by different retrieval methods differ, all possible results were traversed according to
. When the maximum distance between the retrieved image and the test point was 0.6 m, 0.85 m, 1.2 m, and 1.34 m, the number of data obtained was 32, 448, 960, and 1760, respectively. The cumulative distribution function of the corresponding positioning error is shown in
Figure 20. Compared with directly taking the retrieval results as the positioning results, the positioning accuracy improvement rate and other relevant data of the positioning method proposed in this paper are shown in
Table 2.
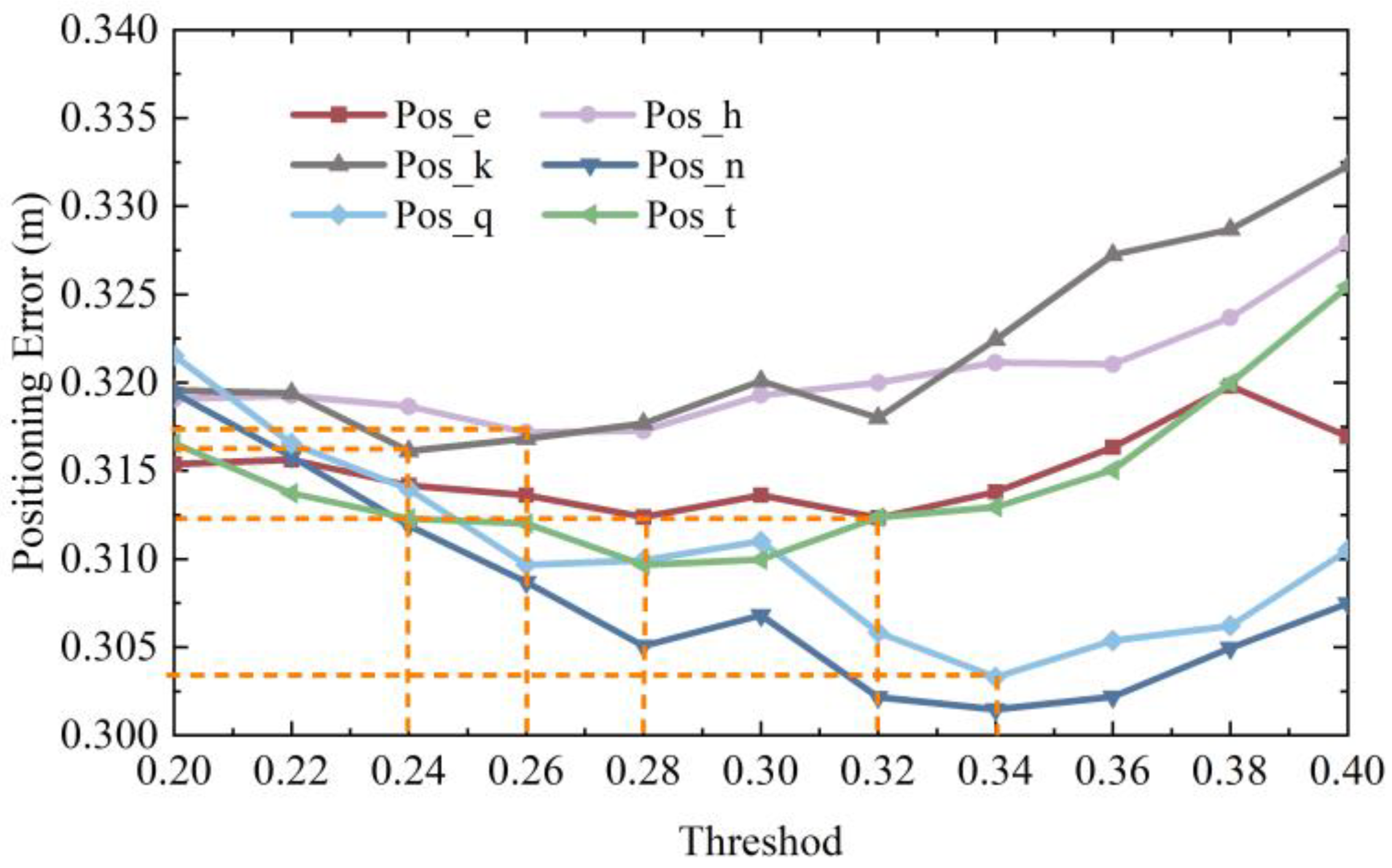
When the source of image retrieval results was within 0.6 m around the node to be located, the 2D error of 90% of nodes could reach 0.27 m using 3D RLM-TDS, improving by 55%. When the distance between the image retrieval result and the actual point to be located was within 1.34 m, and the maximum distance between the retrieved images was 2.68 m, 90% of the 2D and 3D positioning errors were within 0.79 m, improving by 41.04%. Among the four groups of experiments, the second one had the slightest improvement in positioning accuracy at only 36.47%.
In order to verify that the positioning method proposed in this paper could achieve a higher positioning accuracy, the conditions that led the positioning accuracy to present the lowest state were selected in the subsequent positioning experiments. That is to say, the image retrieval range was eight points around the node to be located, and the distance between the retrieval result and the point to be located was 0.85 m. If, under these conditions, 3D RLM-TDS can resist the influence of the two conditions to be verified and present stable positioning accuracy, then it can achieve higher localization accuracy when the retrieval results show the other three groups in better states.
4.2.2. Visualization of Positioning Effect
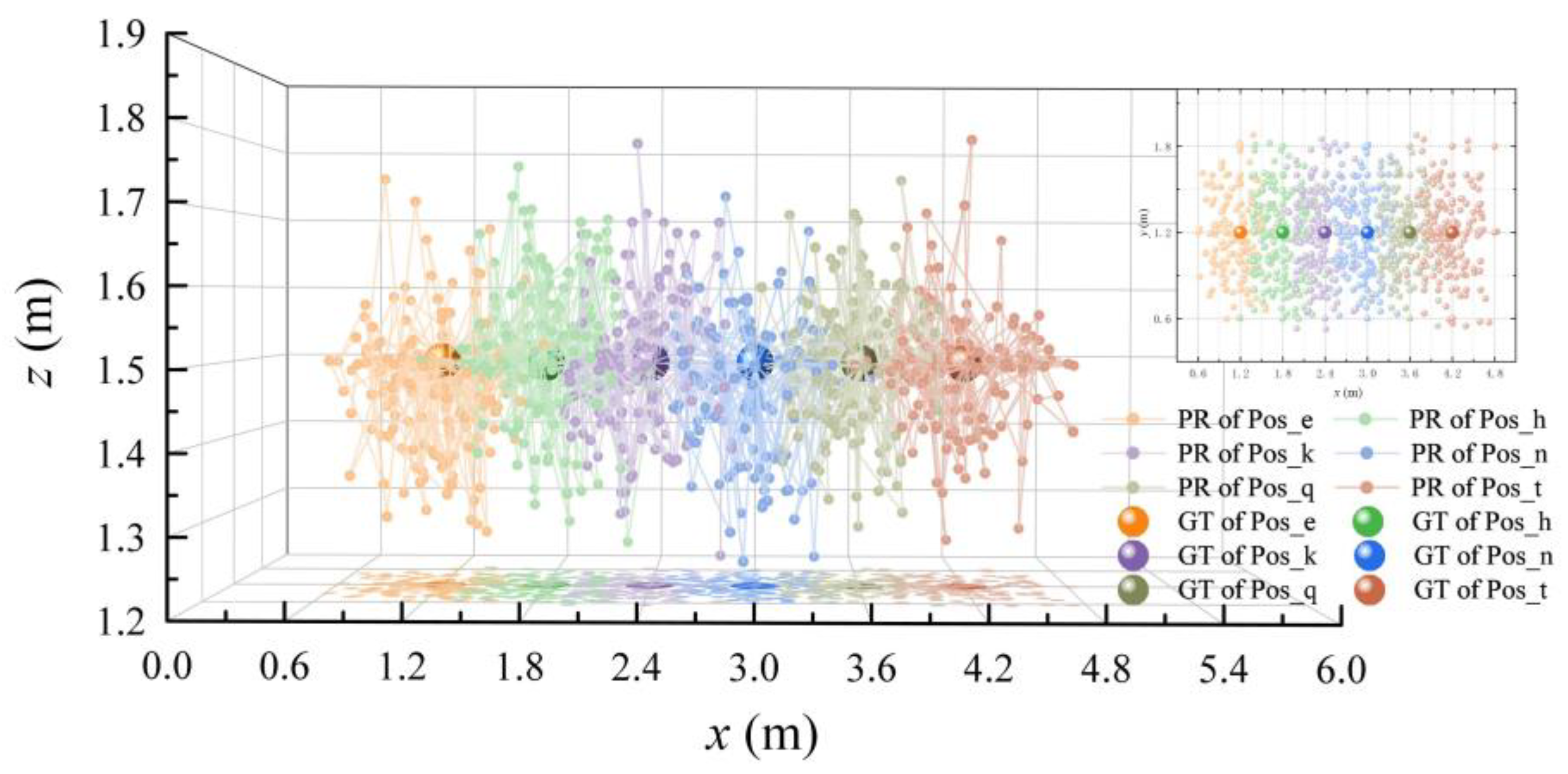
In order to observe the localization experimental results of the proposed method in detail, scene Ⅱ was taken as an example to locate the six points Pos_e, Pos_h, Pos_k, Pos_n, Pos_q, and Pos_t, and the positioning results were visualized. According to the reasons mentioned in
Section 4.2.1, eight known points near the test node were selected as the subsequent positioning sources. Three points were randomly selected for epipolar geometry pose calculation. According to
, there were 56 groups of experimental data in total. The above verification was carried out on the images of the six points and eight directions; thus, 6 × 56 × 8 = 2688 positioning results were obtained. The 2D and 3D positioning results are shown in
Figure 21.
The positions of the big ball in
Figure 21 represent the ground truth of the six test points, and the small balls with the same color of each test point represent the positioning result of the test point using 3D RLM-TDS. According to the distribution of the positioning points, it can be seen that the positions obtained using the positioning method proposed in this paper were all near the actual nodes, and there were no outliers with a large gap.
4.3. Positioning Accuracy Verification
4.3.1. Verification of Positioning Accuracy under Different Positions and Poses
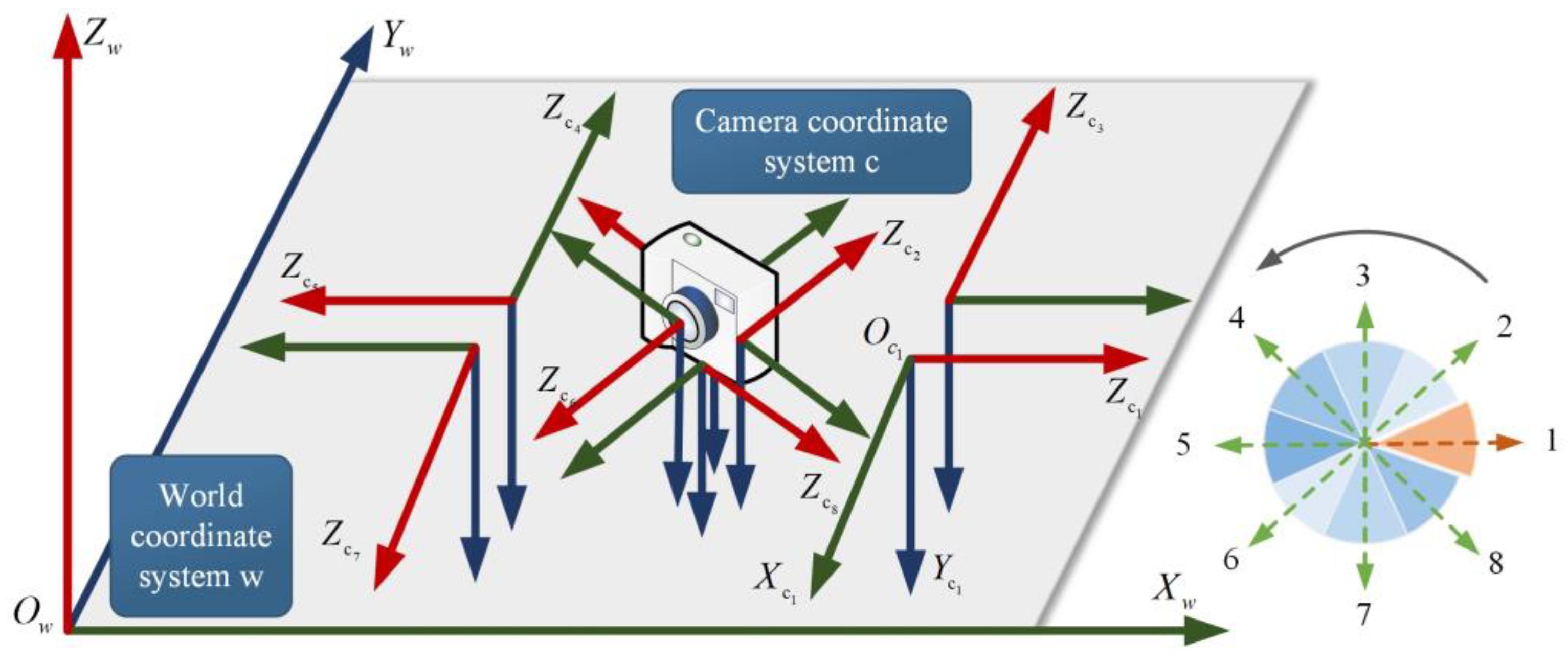
The localization effect of images taken from different directions was verified in two experimental scenes. The images with eight representative poses are shown in
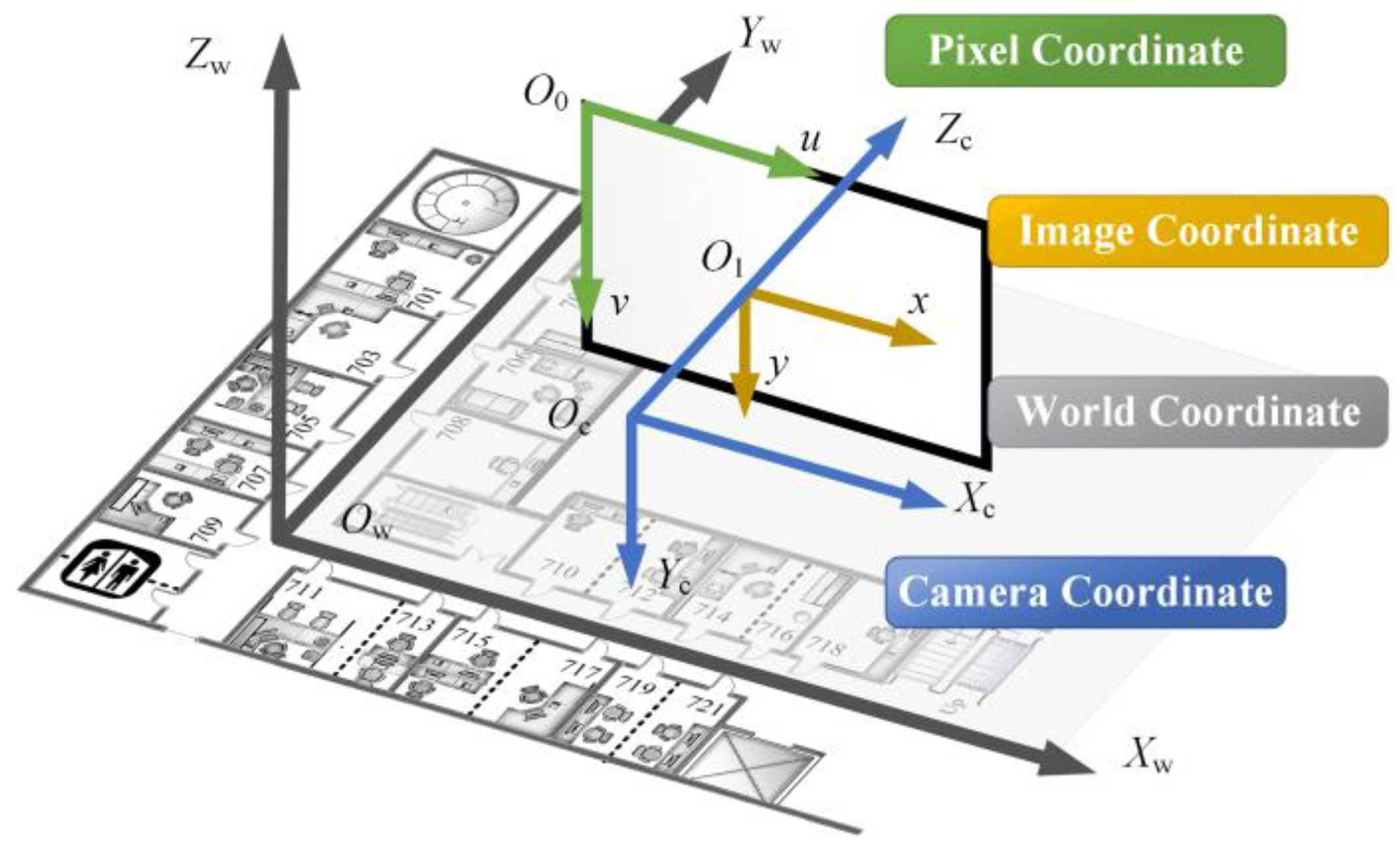
Figure 22. The dataset contained more pose information collected by the built-in smartphone sensors. We took the camera’s optical axis, i.e., the
Zc axis of the camera coordinate system, consistent with the positive direction of the
Xw axis of the world coordinate system, specified as direction 1. Rotating counterclockwise in 45° increments, the sequence had directions 2–8. The Euler angle and rotation matrix corresponding to the orientation pose are shown in
Table 3.
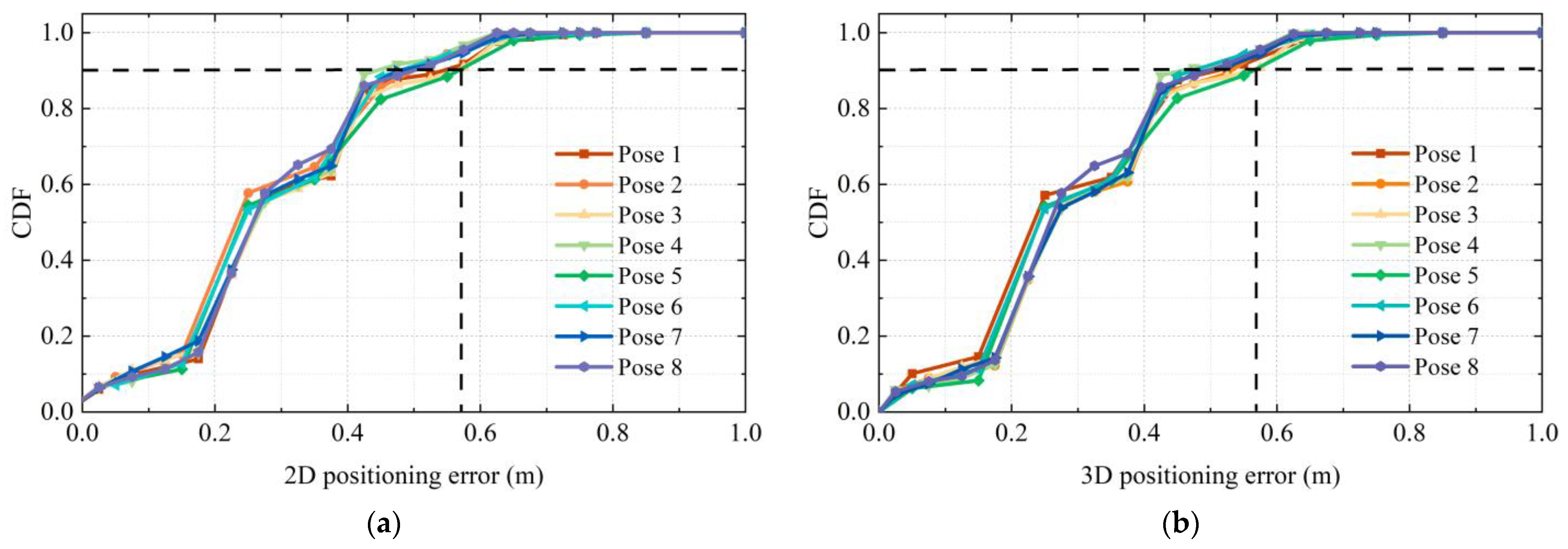
The 3D RLM-TDS proposed in this paper was used to locate the images taken in eight representative directions, and the 2D and 3D positioning errors are shown in
Figure 23. The cumulative distribution trend of positioning errors in all directions was consistent, indicating that the positioning method was not limited to a specific pose. The 2D positioning error and the 3D positioning error showed a uniform trend. Specifically, 90% of the 3D positioning errors were within 0.58 m, verifying the method’s robustness under different poses and meeting the positioning accuracy requirements in practical applications.
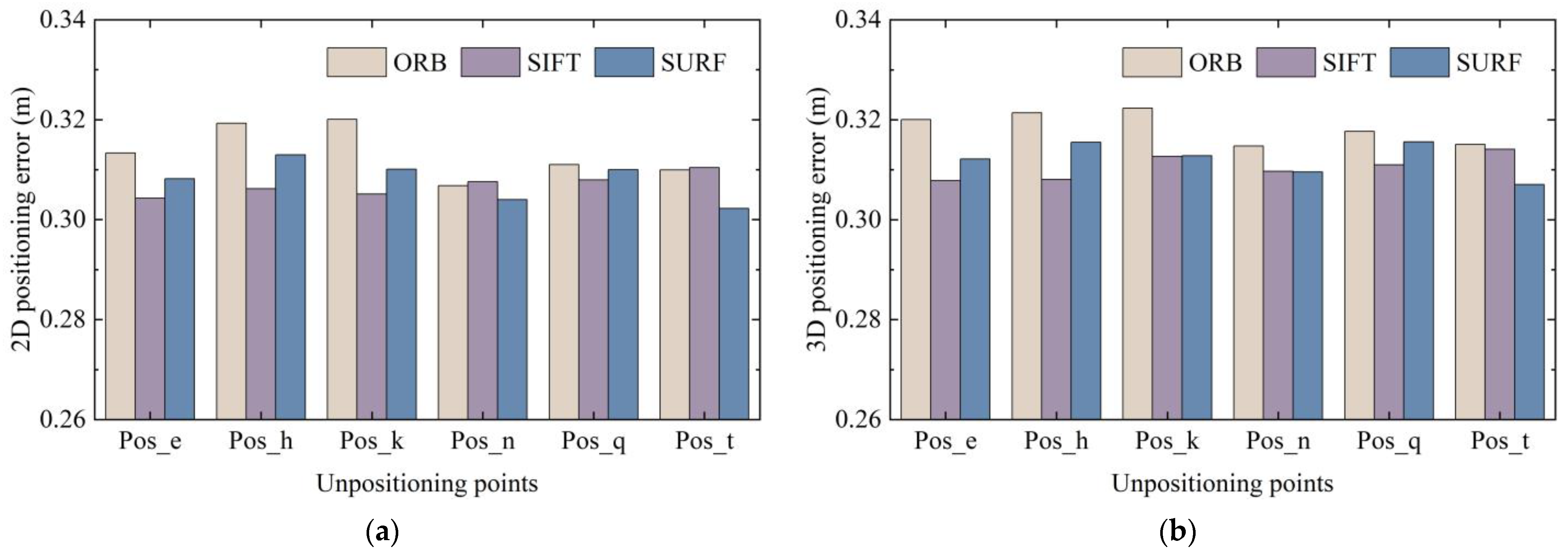
4.3.2. Verification of Positioning Accuracy Using Three Feature Extraction Methods
In the experiment, different methods were selected for feature extraction and matching. The poses calculated using the epipolar constraint differed in terms of feature matching pairs. As described in
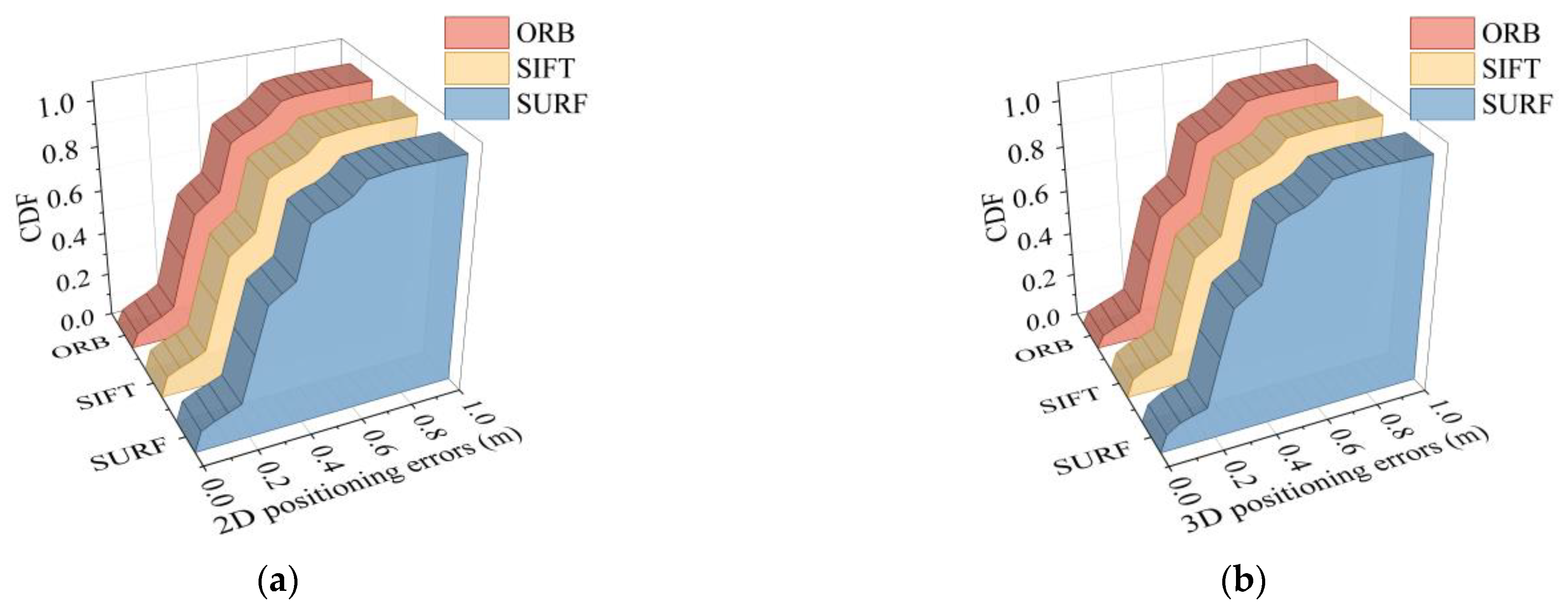
Section 2.1, classical image extraction and matching algorithms include SIFT, SURF, and ORB. Therefore, these methods were used to locate the six points of Pos_e, Pos_h, Pos_k, Pos_n, Pos_q, and Pos_t among the 24 coordinate points in scene Ⅱ. Image retrieval was derived from a dataset of eight points around the point to be located, and each node is verified against the dataset images in eight directions. The corresponding 2D and 3D positioning accuracies are shown in
Figure 24.
It can be observed that, no matter which feature extraction method was used for epipolar geometry calculation, the final positioning accuracy showed a uniform trend. It can be seen from the data statistics that 90% of the positioning errors obtained by the three methods were all lower than 0.575 m.
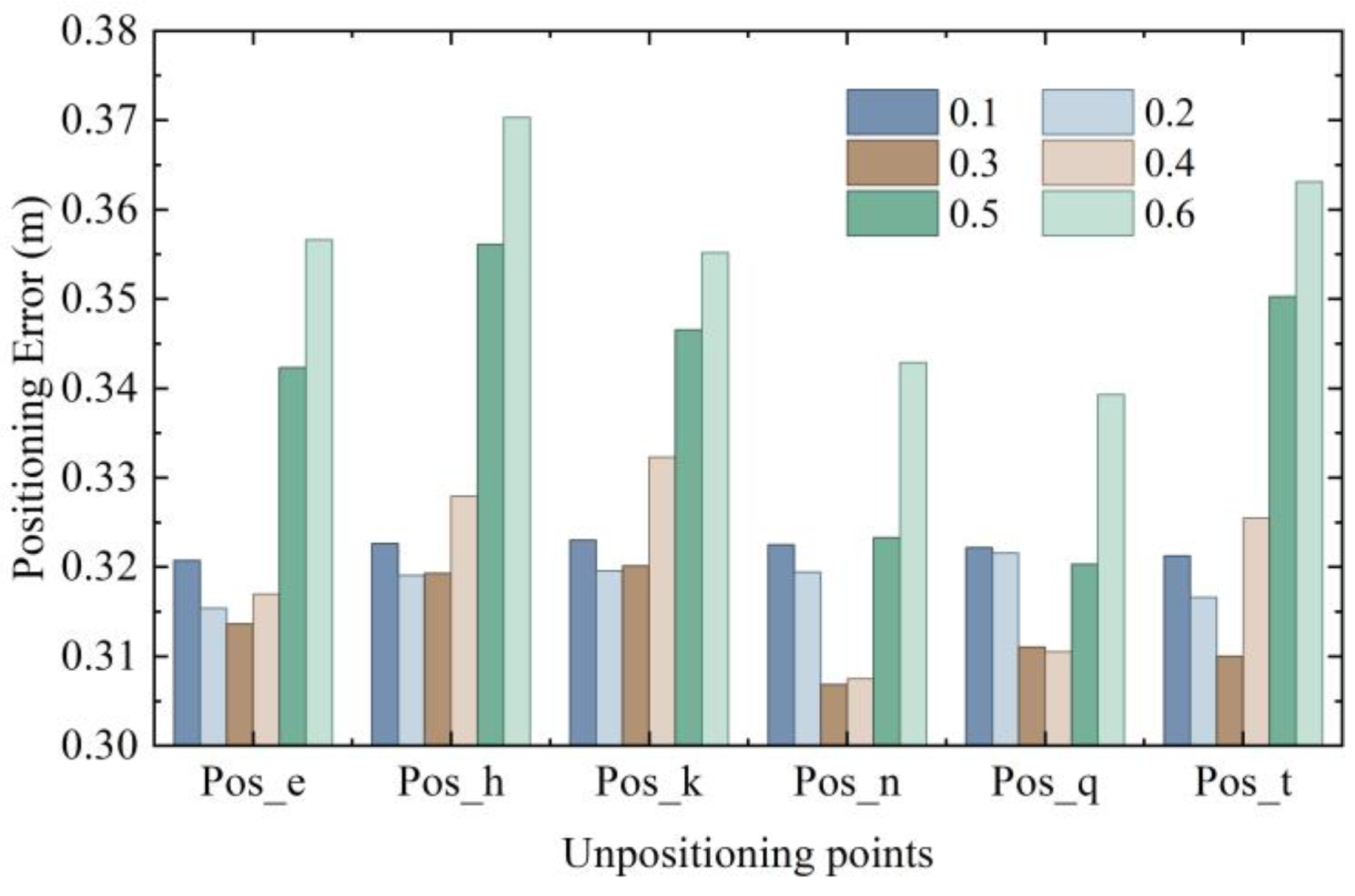
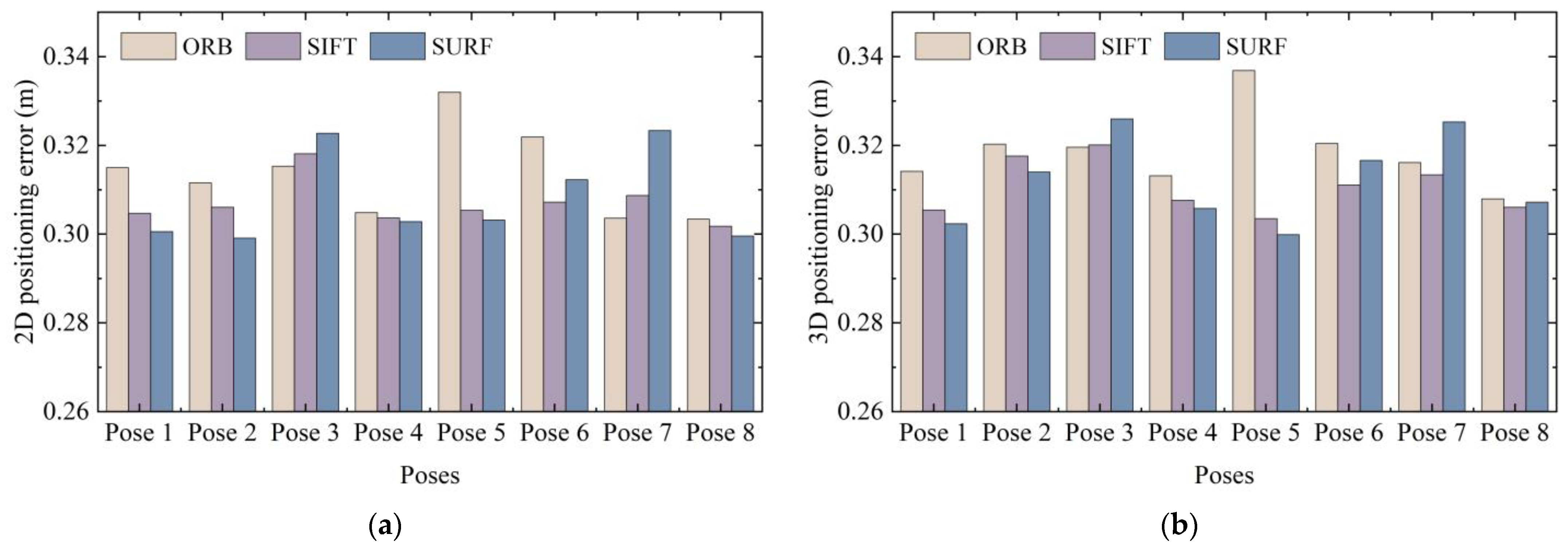
We compared the CDF of positioning error of different pose images and different feature extraction methods. The average positioning error was sorted out to further observe the errors clearly. The average 3D positioning error of the 2688 data obtained using the ORB, SIFT, and SURF methods was 0.3186, 0.3106, and 0.3121 m, respectively. The 2D and 3D average positioning errors of different poses and different positioning points are shown in
Figure 25 and
Figure 26.
Due to the differences in the patterns and objects in the images captured at different nodes with different poses, the extracted feature points also changed accordingly; thus, the average positioning error obtained also fluctuated. However, it was basically concentrated at about 0.3–0.32 m, showing a relatively stable state. Therefore, 3D RLM-TDS proposed in this paper can cope with different shooting poses, adapt to different feature extraction methods, and resist the influence caused by different source ranges of image retrieval results. It has high robustness and achieves the effect of stably meeting the demand for accuracy in practical positioning applications.
4.4. Real-Time Performance Analysis
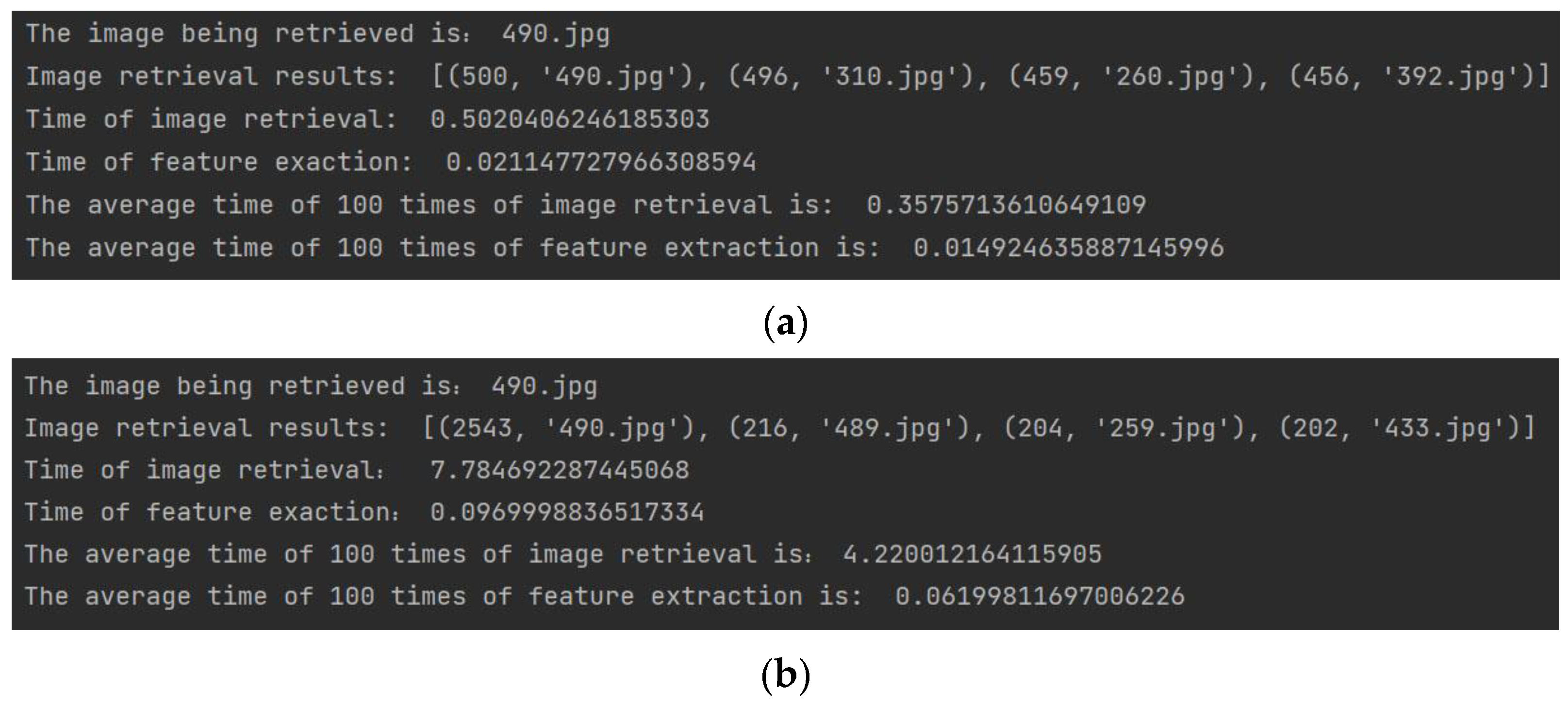
To verify that the positioning method proposed in this paper can meet the requirements of engineering practice, 100 positioning experiments were carried out, and the time consumption of each involved process was statistically analyzed. In engineering, response times for software interfaces are typically based on certain criteria. When the response time is below 2 s, it is considered a “very attractive” user experience. Users rate a response within 5 s as a “relatively good” experience. However, if the response time is between 5 s and 10 s, it is considered a “bad” experience, and, if no response is received after 10 s, the request is judged to have failed. Therefore, if the time is less than 5 s from when the user uploads the image to when the positioning coordinate is obtained, the positioning system can be considered to be real-time and meet the needs of practical applications.
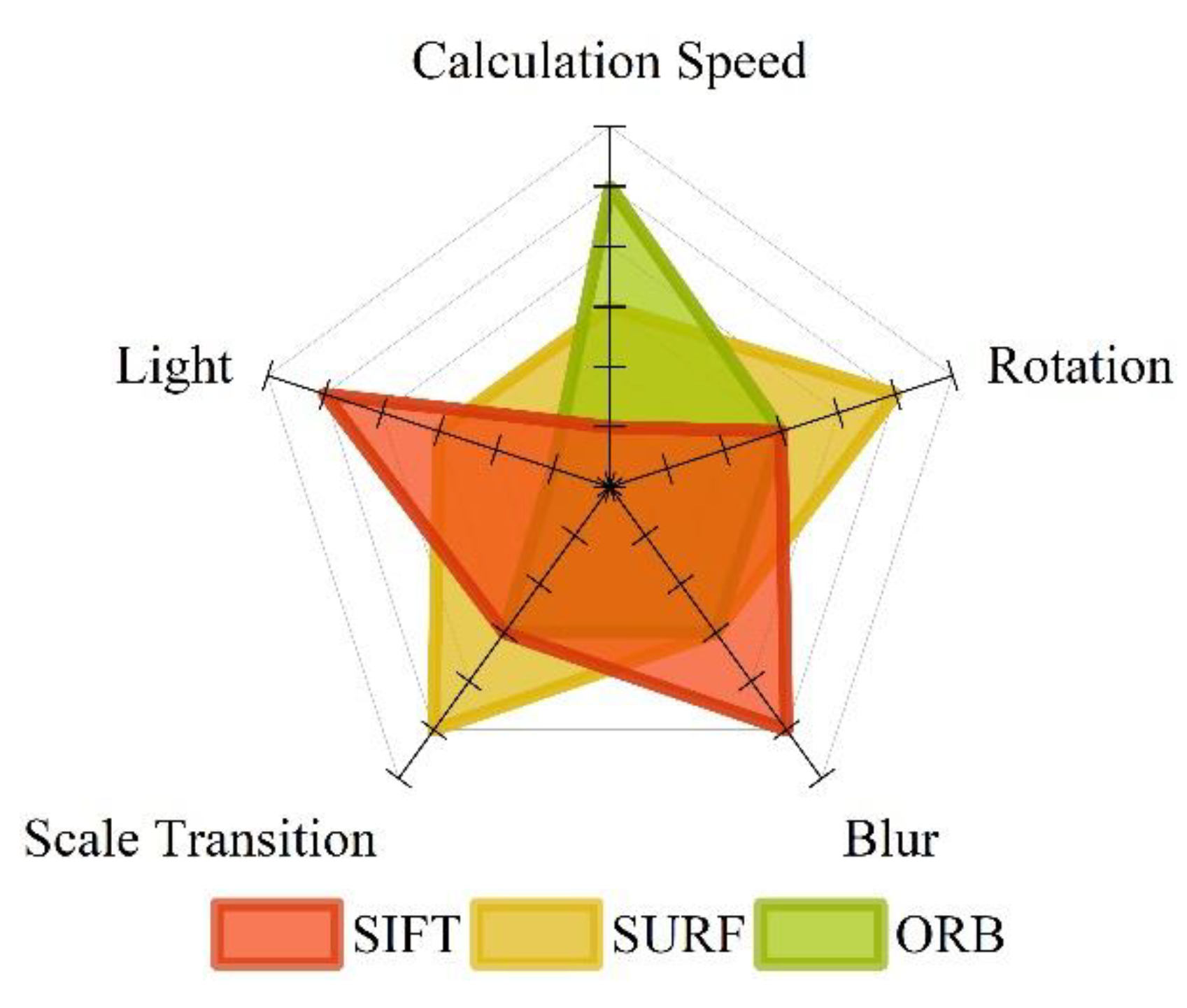
After the user uploads the image, it needs to go through four main steps: feature extraction, dataset image retrieval, relative pose calculation, and 3D RML-TDS location determination. According to the relevant features shown in
Figure 2, ORB and SURF, which are relatively efficient, were selected for feature extraction and retrieval to shorten the overall positioning response time. A total of 100 positioning experiments were carried out at different nodes. The image feature extraction and retrieval time were determined, and the average value was calculated. The program operation results are shown in
Figure 27.
The experiment showed that the feature extraction time of ORB and SURF was 14.9246 ms and 61.9981 ms, respectively. The time of image retrieval is related to the method, dataset size, and the similarity degree of dataset images. In this experiment, the dataset consisted of 500 images, and the average time of 100 retrievals for ORB and SURF features was 0.3576 s and 4.22 s, respectively. The relative pose calculation process of a pair of images was about 30 ms. We selected the three most similar images to get poses. Therefore, acquiring the three translation vectors required a total of 90 ms. The matrix operation and position switching based on a threshold in 3D RML-TDS consumed a short time, and the acquisition from attitude calculation to final positioning result could be achieved in 100 ms. To sum up, the overall time of feature extraction and image retrieval based on ORB and SURF with 3D RML-TDS for positioning was 472.5246 ms and 4381.9981 ms, respectively. That is, 3D ML-TDS (ORB) and 3D ML-TDS (SURF) could be positioned within 0.5 s and 5 s, respectively, meeting real-time requirements.
4.5. Construction of Positioning Mini Program and Comparison of Localization Performance
4.5.1. Performance Comparison of Location Determination Methods
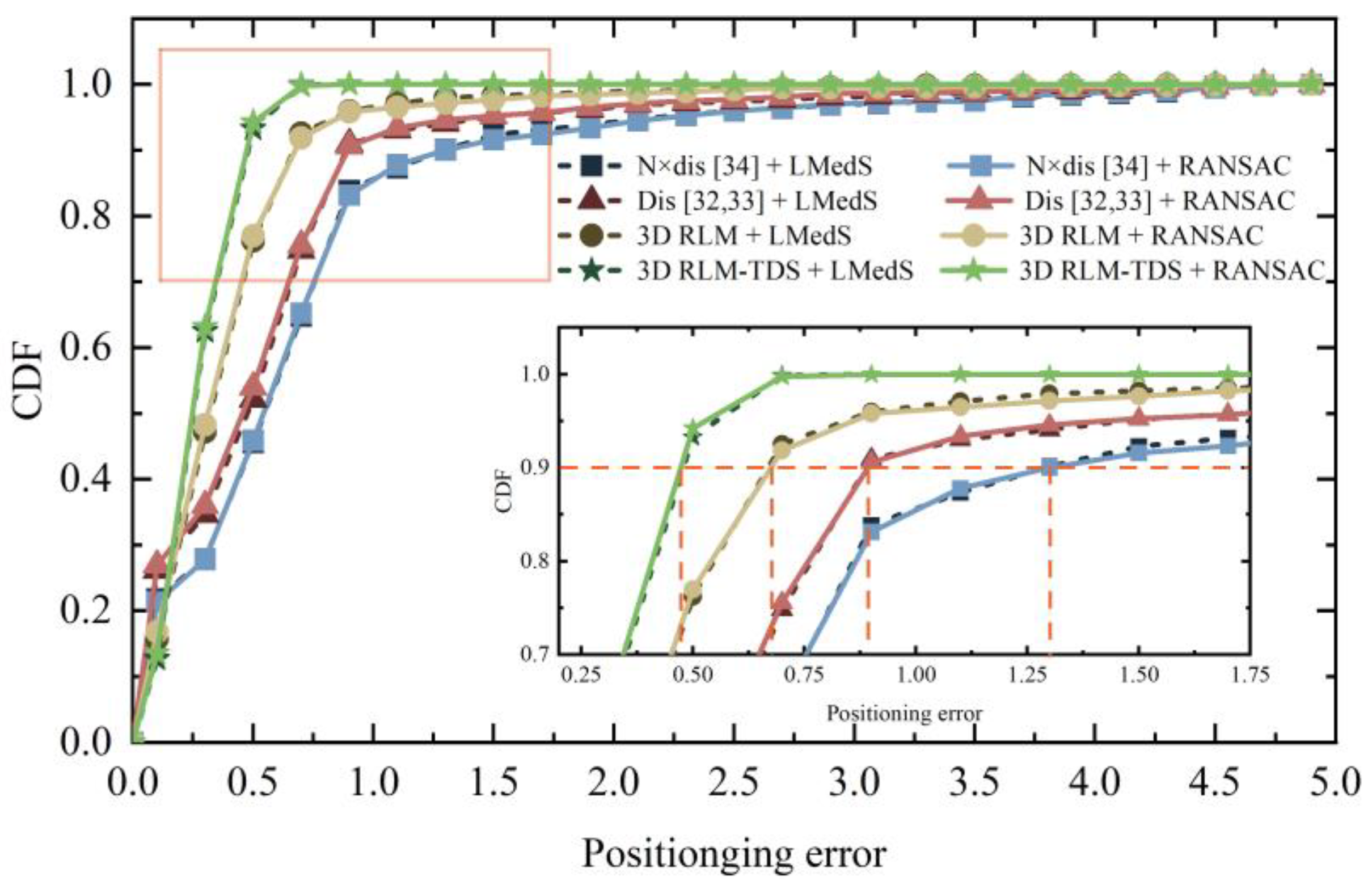
In order to further verify the performance of the positioning method proposed in this paper, the pose estimation method proposed in [
30,
31] and the position determination method used in [
32,
33,
34] were selected for combined experiment. In order to unify the preconditions for comparison, the three most similar images obtained from image retrieval were selected for pose determination and positioning point calculation. The cumulative distribution of positioning errors and average positioning errors are shown in
Figure 28 and
Table 4, respectively. Among them, 3D RLM is the positioning error obtained by solving the minimum distance sum in three-dimensional space without threshold constraints. N × dis is the positioning method considering the quantity of feature matching in [
34], and Dis corresponds to [
32,
33]. The first two items in
Table 4 refer to the location obtained by direct image retrieval using ORB and SURF, respectively.
Combining
Figure 28 and
Table 4, it can be observed that the errors of these four positioning methods were similar when the pose estimation method was changed. Since N × dis and Dis methods map 3D vectors to 2D, large outliers are generated when translation vectors are obtained by LMedS. RANSAC can achieve a more stable positioning situation. However, 3D RLM-TDS does not select the intersection point that may occur at infinity as the positioning result and adds the constraint on the location of the retrieved image; thus, the error obtained is significantly lower than other methods.
4.5.2. Construction of WeChat Positioning Mini Program and Positioning Results
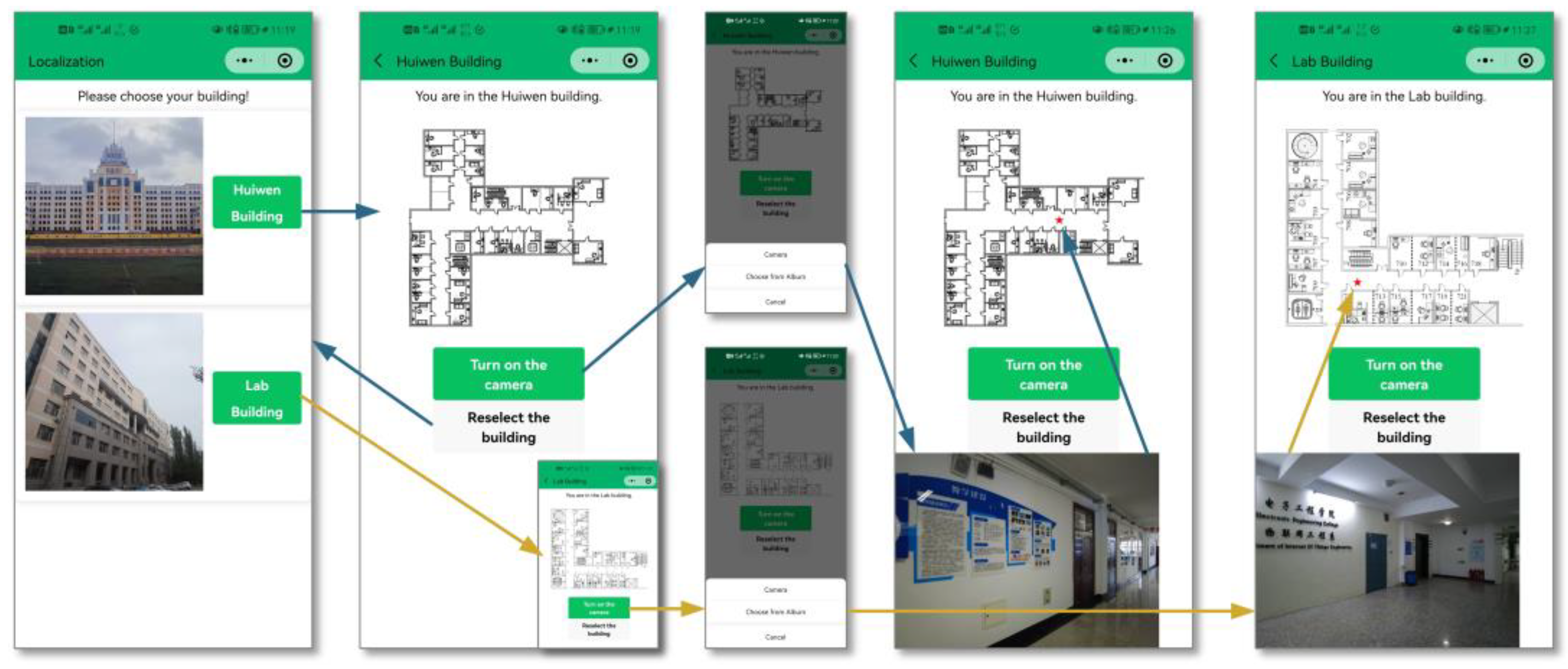
In order to verify the positioning performance of this positioning method in an actual scenario, we developed the WeChat positioning mini program mounted on the mobile smart terminal. It is based on the WeChat developer tools, and the .wxml, .json, .js, and .wxss files were written to build the program interface, as shown in
Figure 29. The instruction to retrieve corresponding dataset by SURF is sent according to the building selected by the user. Photos chosen from albums or taken by users are compressed and uploaded to obtain poses by RANSAC. Lastly, the adjusted coordinates calculated by 3D RLM-TDS are transmitted to the mini program for marking.
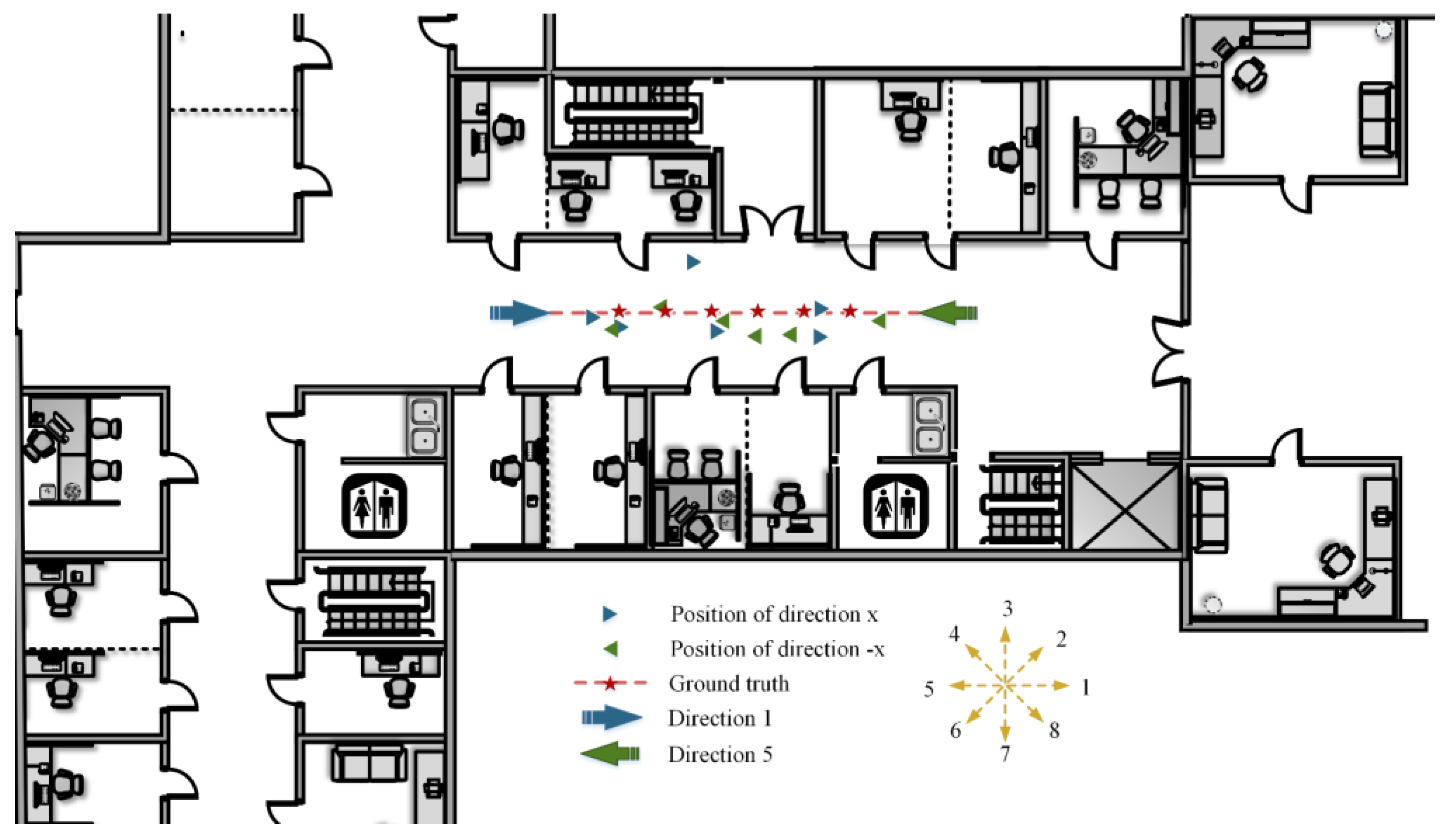
In order to verify the actual positioning performance of the WeChat mini program and the localization method proposed in this paper, a positioning experiment for a user was conducted in scene Ⅱ to simulate the real situation. The corresponding positioning results are shown in
Figure 30.
In the experiment, we walked along the central red dotted line in the corridor in directions 1 and 5. Then, we stopped, uploaded a clear photo taken at each asterisk location, and obtained the positioning result. The asterisk positions are the pre-marked fixed points. The locations of the blue and green triangles correspond to the results according to different images obtained in directions 1 and 5, respectively. It can be seen that the method proposed in this paper can acquire an accurate location without additional equipment, meet the application requirements of the actual indoor environment for user positioning, and achieve the effect of real time and practicability.
6. Conclusions
This paper studied the visual positioning of large indoor places such as teaching buildings, hospitals, libraries, shopping malls, and parking lots. Both ICP and PnP need to obtain the actual 3D coordinates of some feature points in space to achieve 3D–3D and 3D–2D position estimation. Considering factors such as ease of use, equipment price, and deployment cost, it is more cost-effective to obtain location information from 2D images. However, the existing methods to calculate the positioning coordinates using the pose obtained from the epipolar geometry project the 3D vector onto the 2D plane and select the intersection point, which may be at infinity as a result. Therefore, we proposed an indoor visual positioning method with 3D coordinates using an accelerometer and magnetometer to realize the precise positioning of indoor users.
Firstly, the checkerboard calibration board was established, and the internal parameters satisfying the reprojection error were obtained according to Zhang’s calibration method for fundamental matrix calculation. We constructed an offline dataset in two scenes and marked the pose obtained by built-in smartphone sensors and the position acquired by a laser rangefinder onto the images taken at corresponding locations. Secondly, 3D RLM-TDS was designed to transform the positioning problem into solving the minimum distance from one point in the space to multiple straight lines. Experiments were carried out to determine the optimal threshold of the constraint method so as to limit the location of the positioning results. Thirdly, the localization experiment and result visualization were carried out in three situations of different range images as the retrieval results, with different camera poses and different feature extraction methods. The findings indicated that, even when the retrieval results are the worst, the positioning method could still achieve 90% positioning effect with an error of less than 0.58 m under different poses. Moreover, the method was not limited to a single feature extraction method, and the average positioning error was lower than 0.32 m. Lastly, a WeChat mini program mounted on mobile devices was designed to realize dynamic experiments, and the positioning method proposed in this paper was compared with other recent work. The results showed that the proposed 3D RLM-TDS achieves ease of use under the condition of low equipment and deployment cost, while meeting the error requirements of user positioning in practical applications.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}