
Classification and Identification of Contaminants in Recyclable Containers Based on a Recursive Feature Elimination-Light Gradient Boosting Machine Algorithm Using an Electronic Nose

Abstract
:1. Introduction
2. Algorithm Theory
2.1. Light Gradient Boosting Machine (LightGBM)
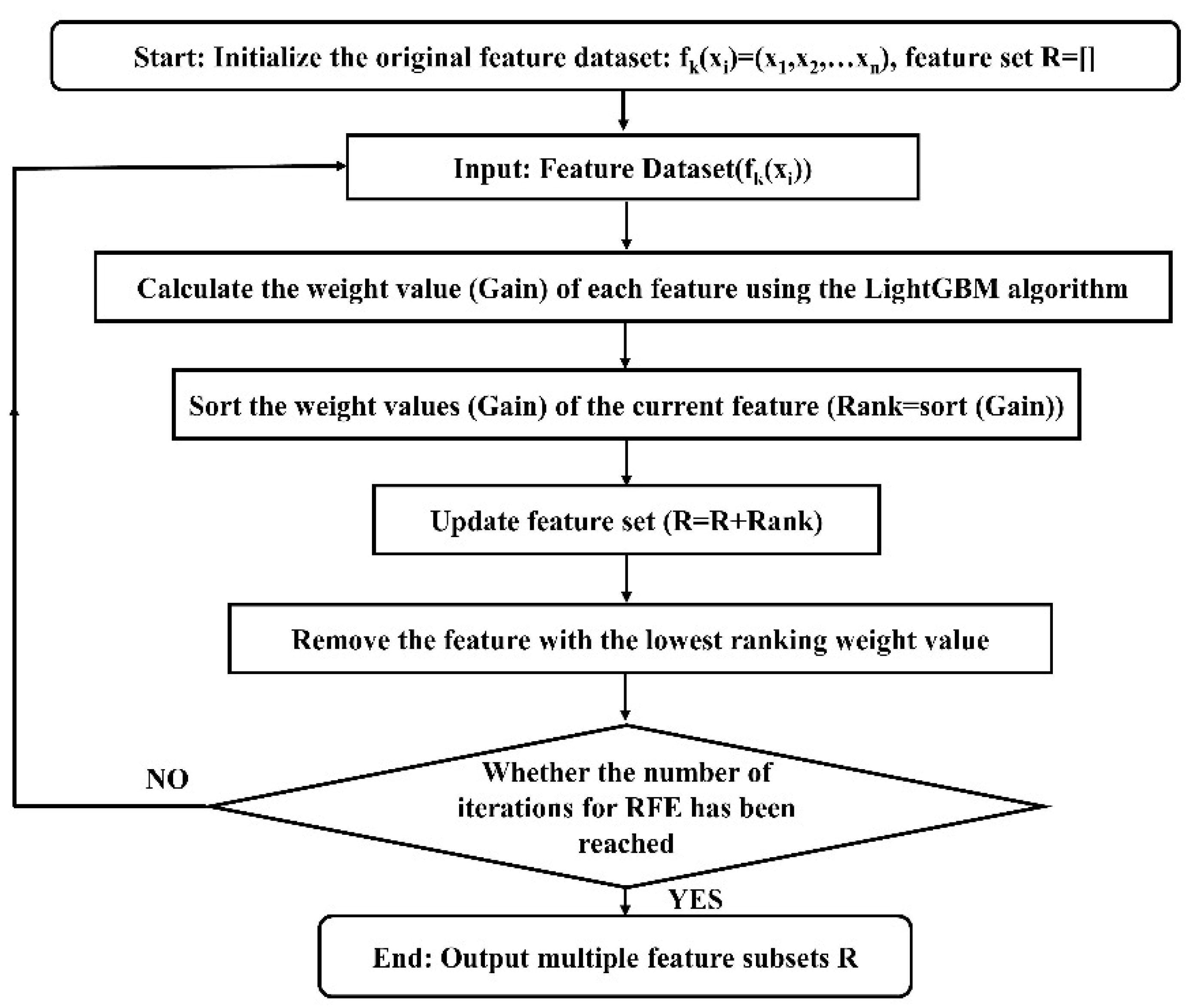
2.2. Recursive Feature Elimination-Light Gradient Boosting Machine (RFE-LightGBM) Feature Selection Algorithm
2.3. Algorithm Evaluation Criteria
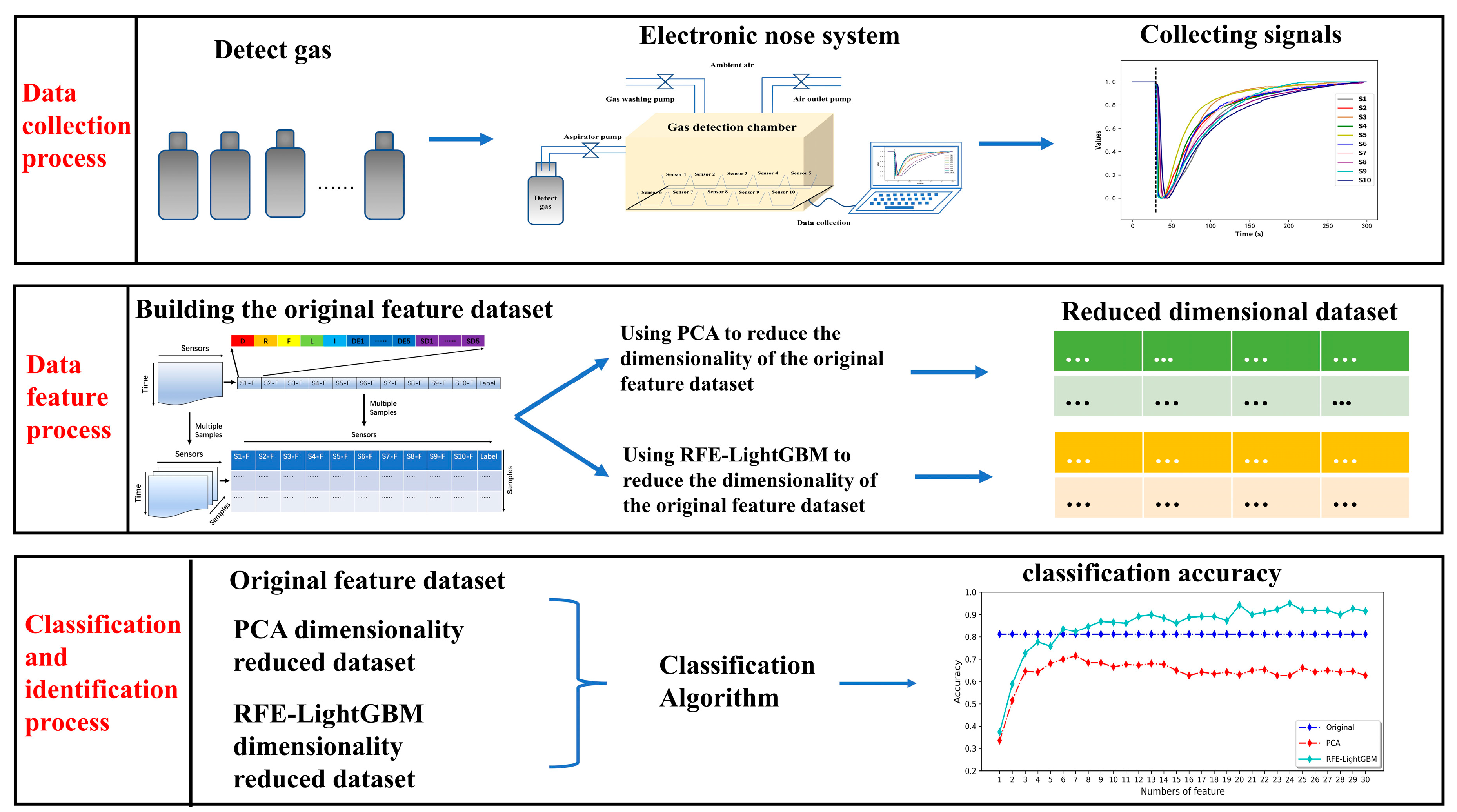
3. Materials and Methods
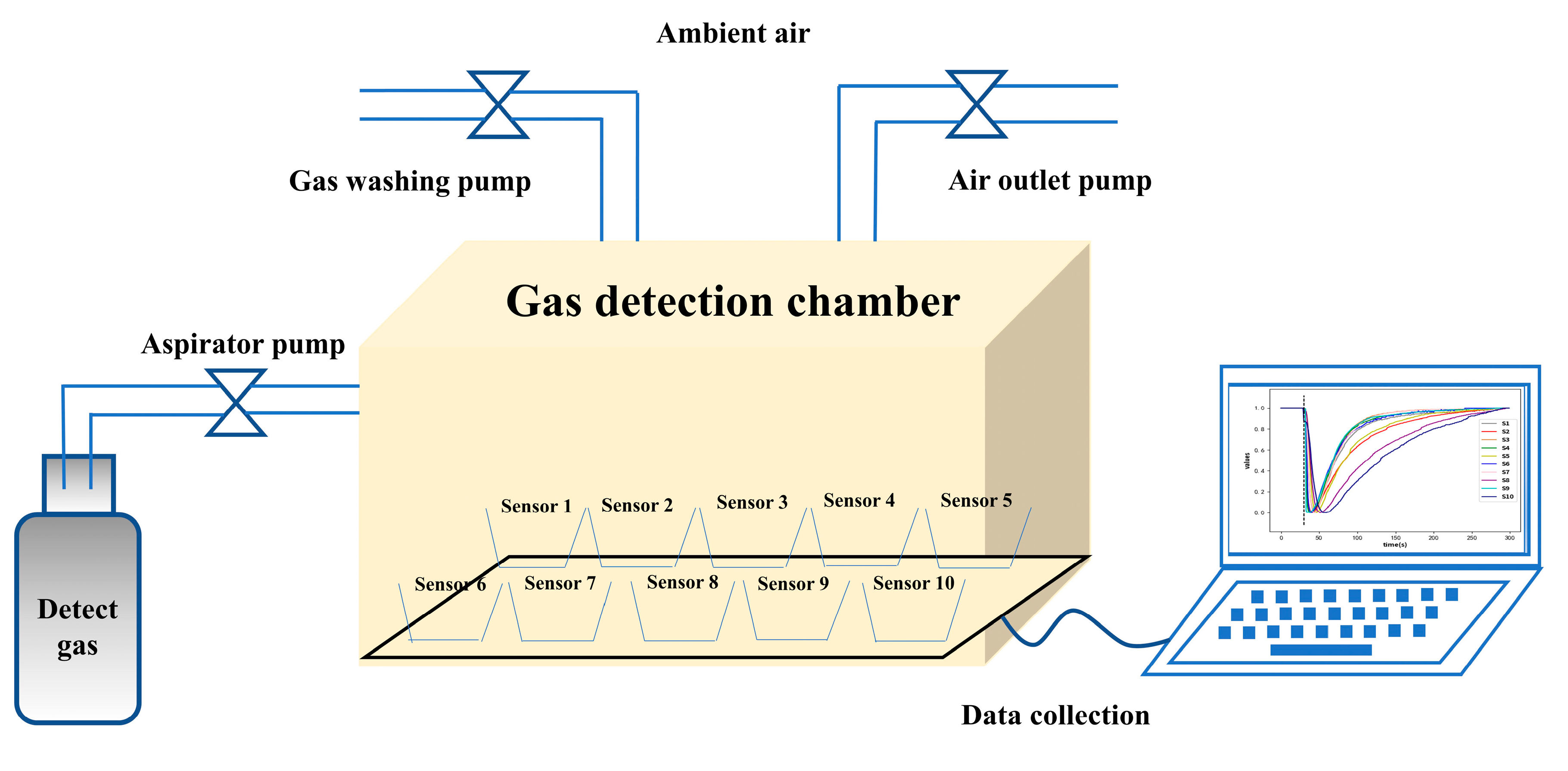
3.1. Electronic Nose System
3.2. Experimental Procedures
- (1)
- The sensing array was preheated for 30 s to bring the baseline sensor resistance values to a steady state.
- (2)
- The aspirator pump was turned on at the 30 s mark, and sent the gas to the detection chamber. The response signal of the sensor to the gas during the pumping time was collected.
- (3)
- The aspirator pump was turned off at the 35 s mark, and the gas washing pump and air outlet pump were turned on (purging the gas detection chamber with ambient air) until all sensor resistance values returned to the original baseline values.
- (4)
- Repeat the operations of steps 1–3 until data collection is completed for all target detectors.
4. Results
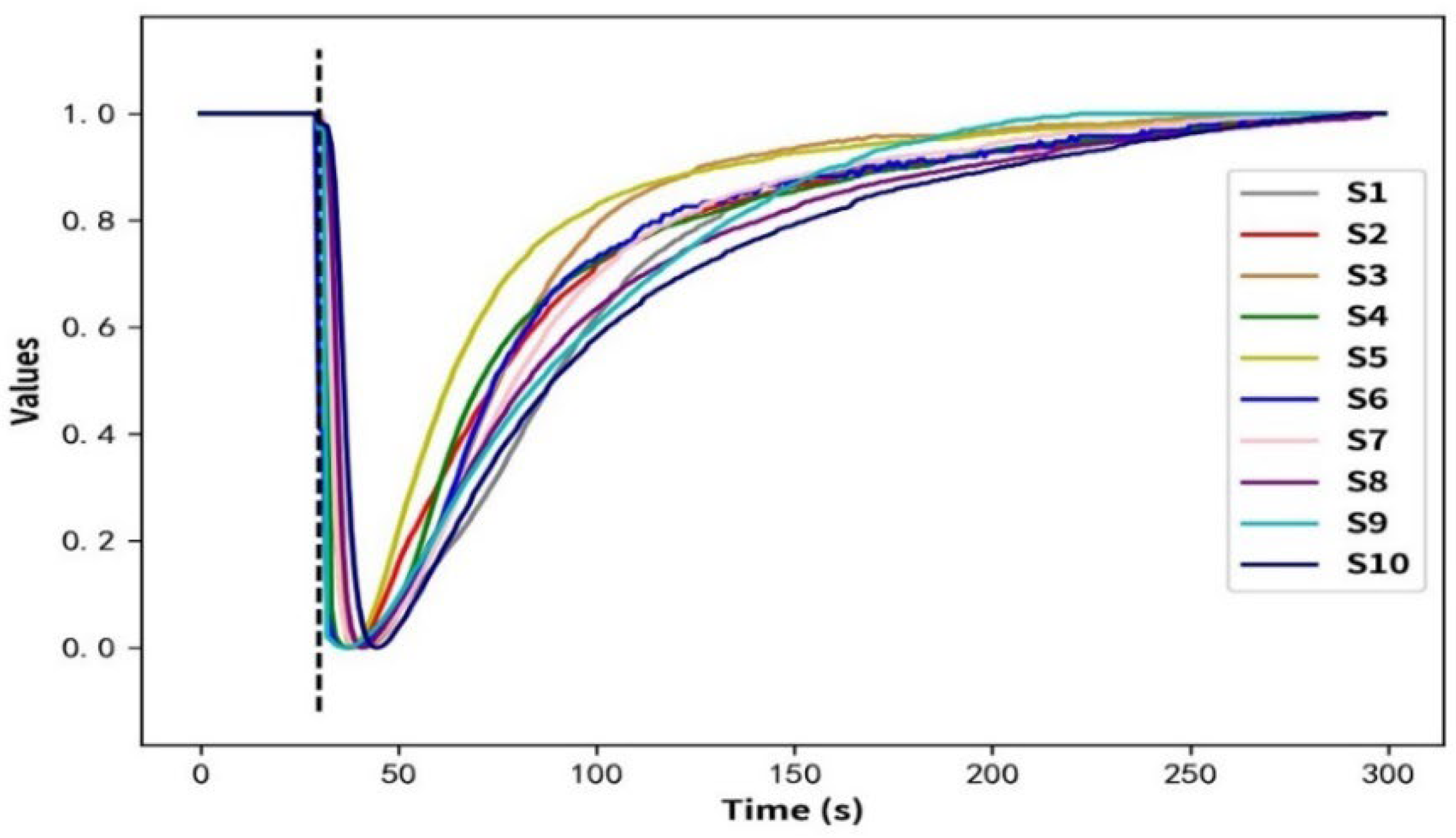
4.1. Response Curve of the Electronic Nose System
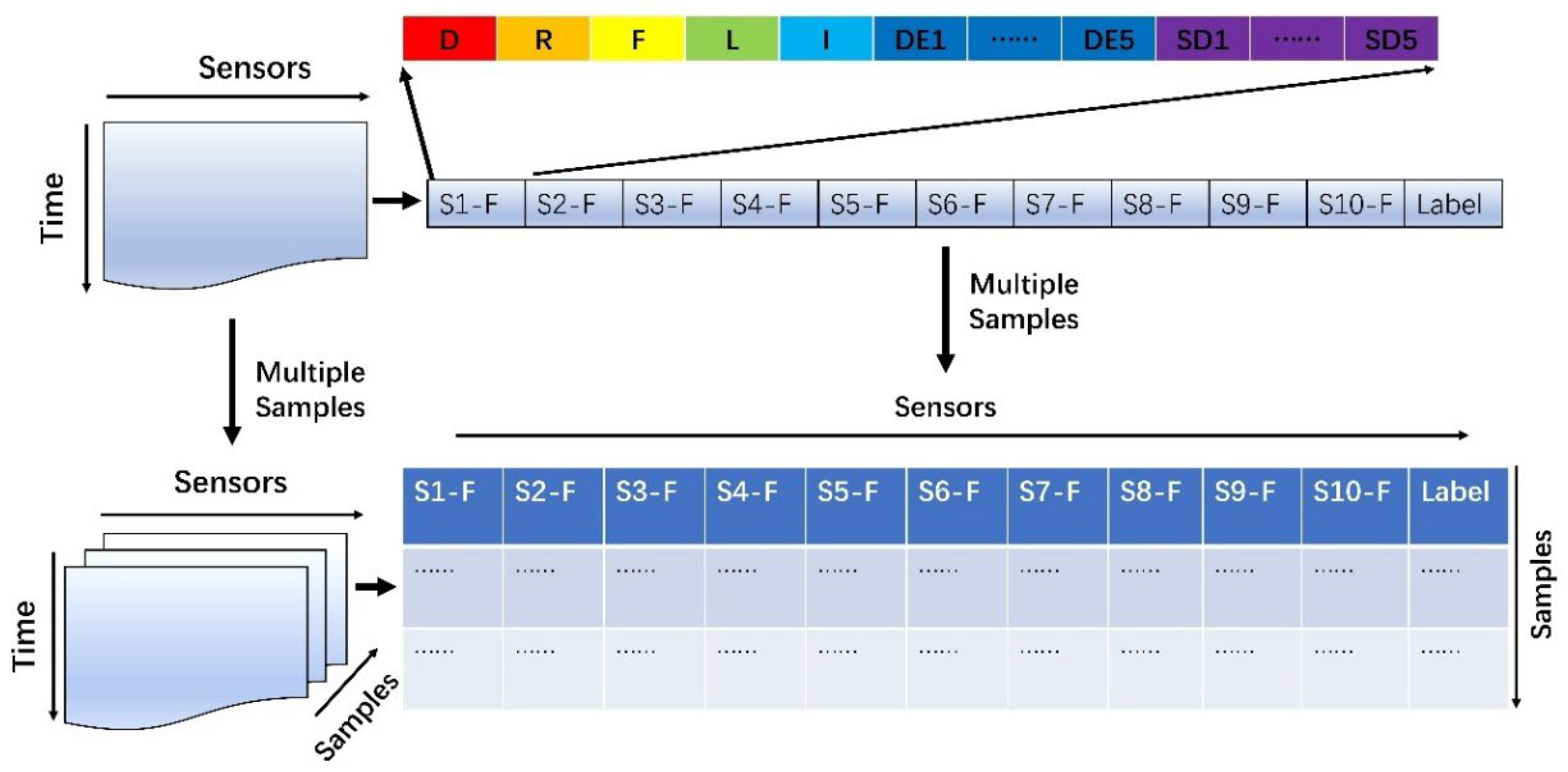
4.2. Feature Datasets Constructed by Manual Methods
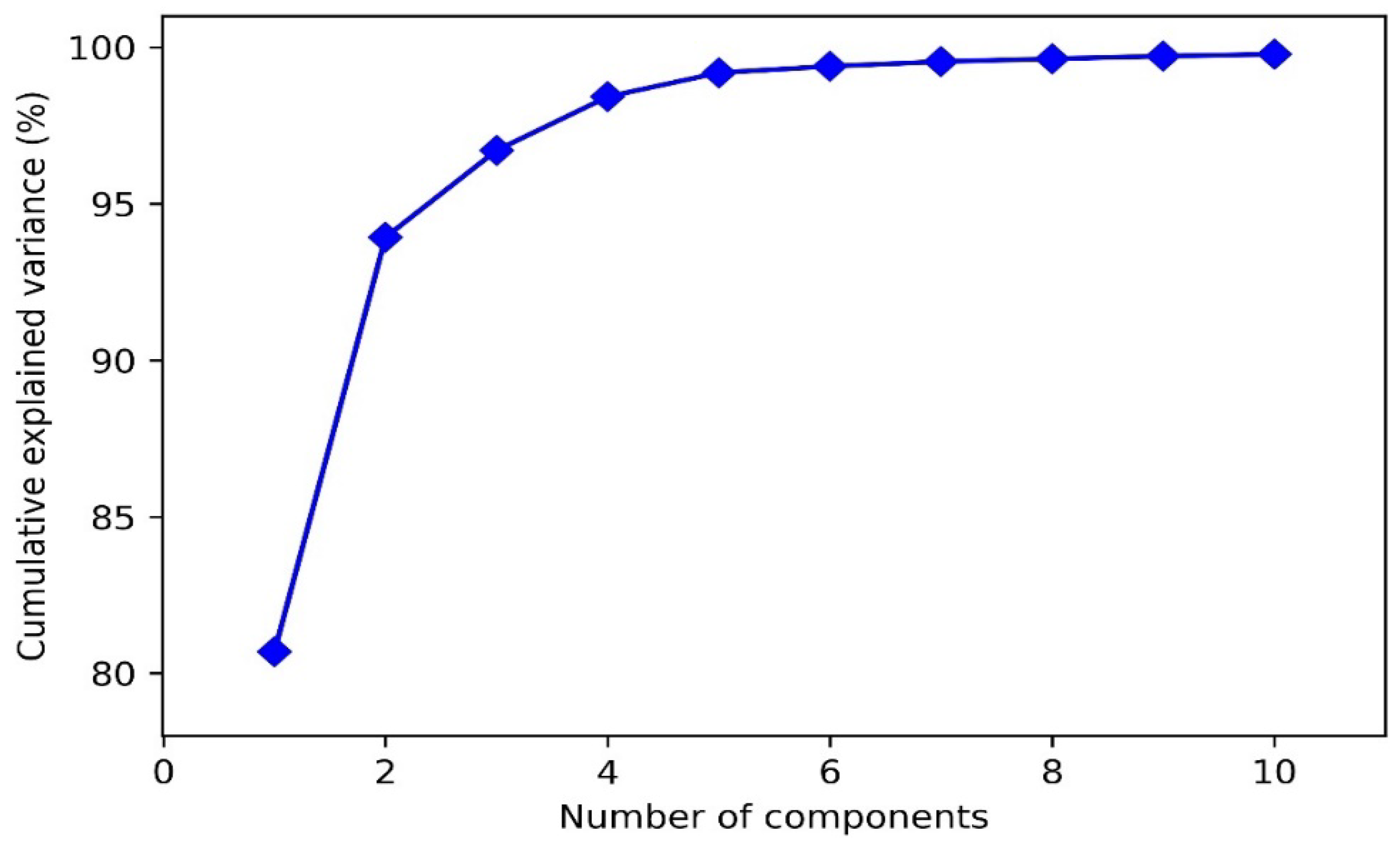
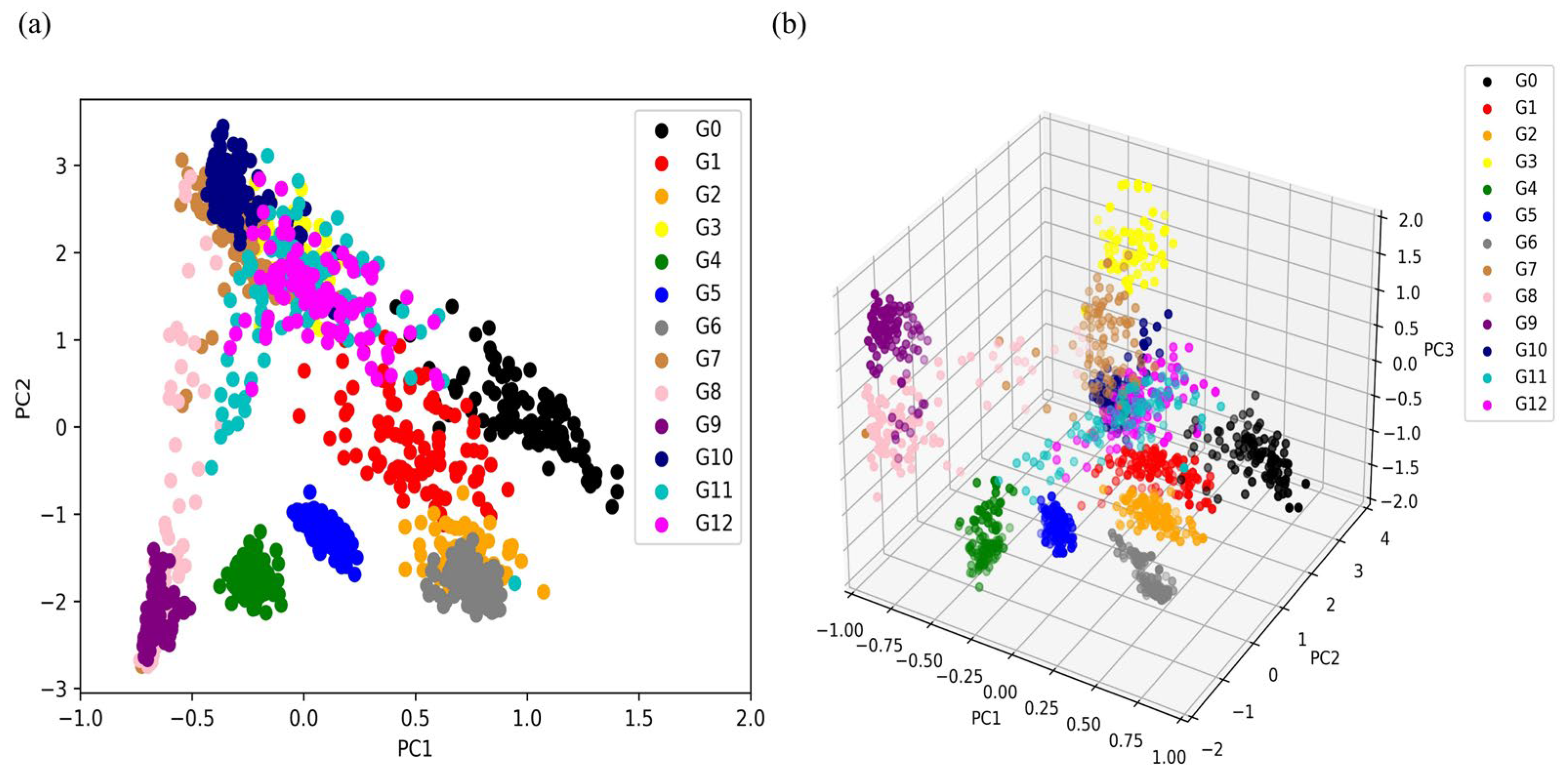
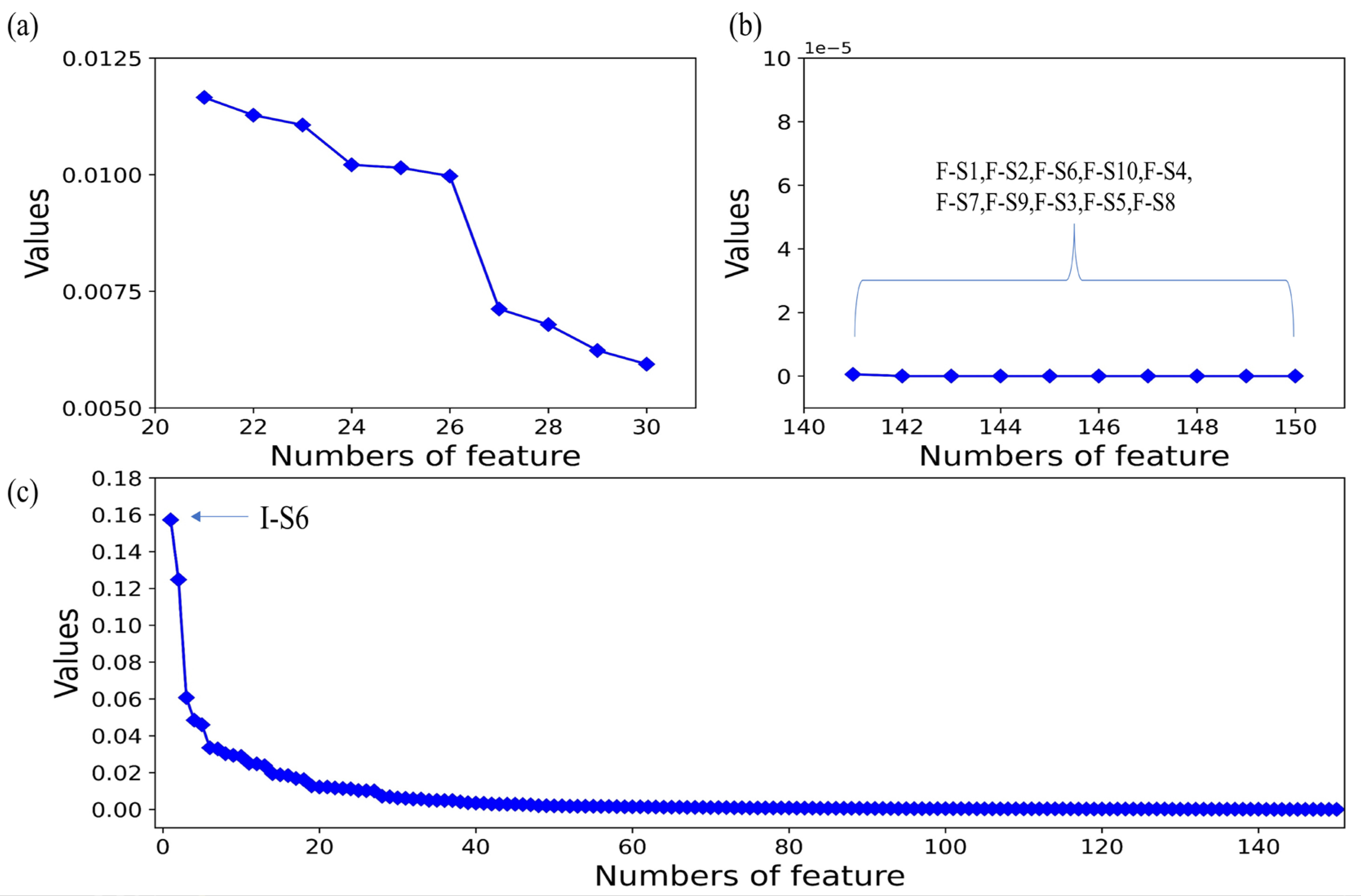
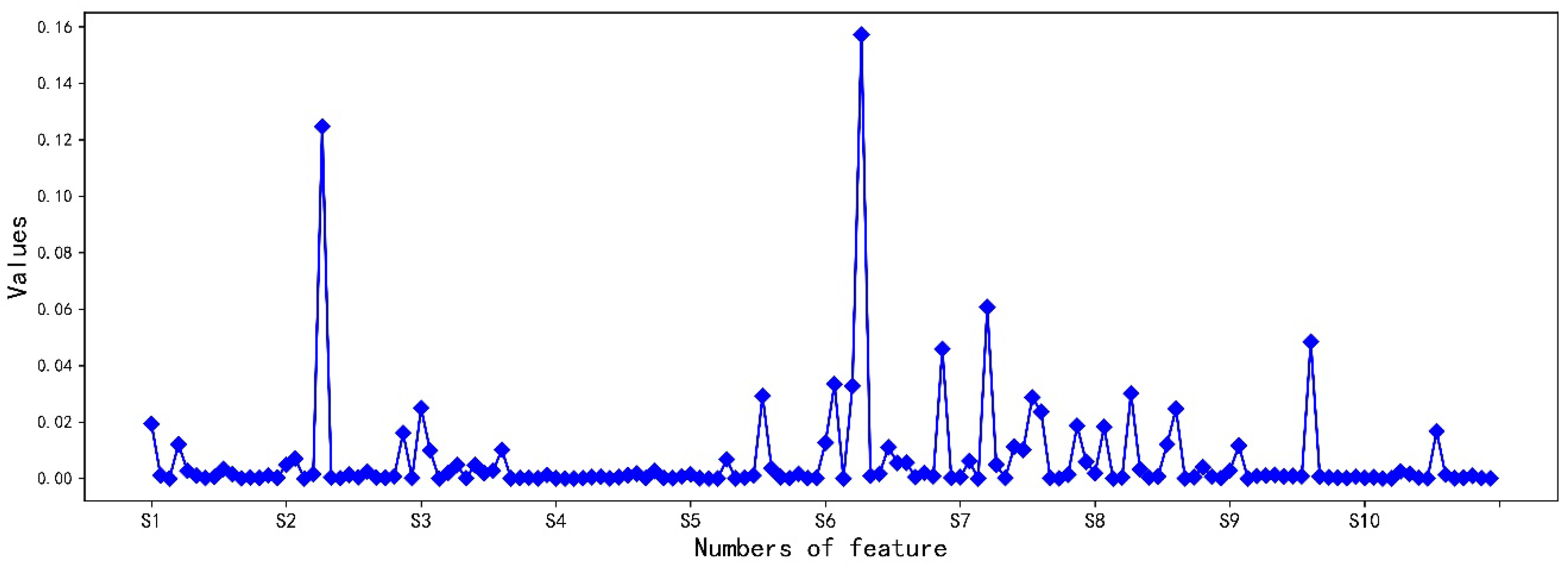
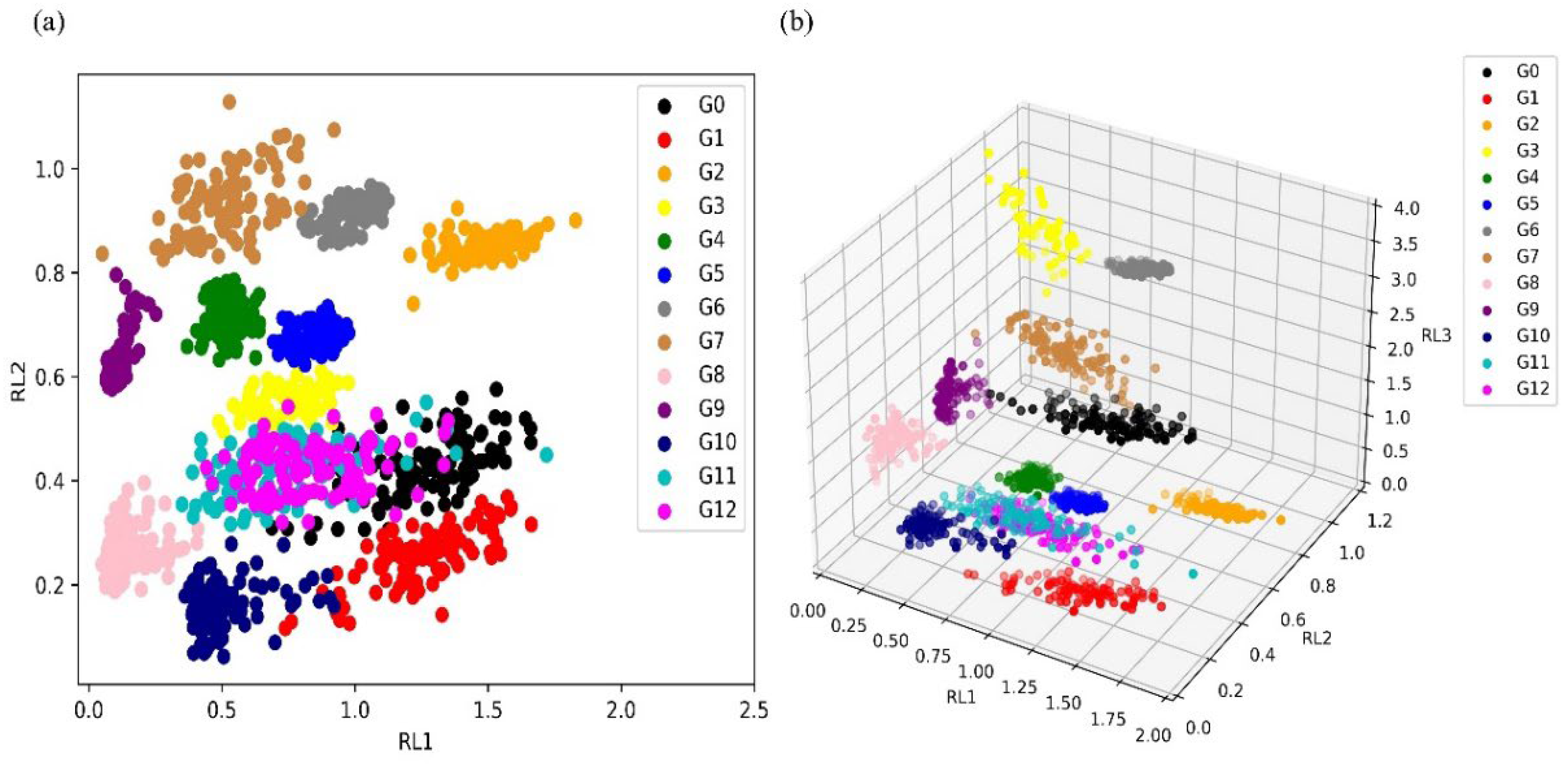
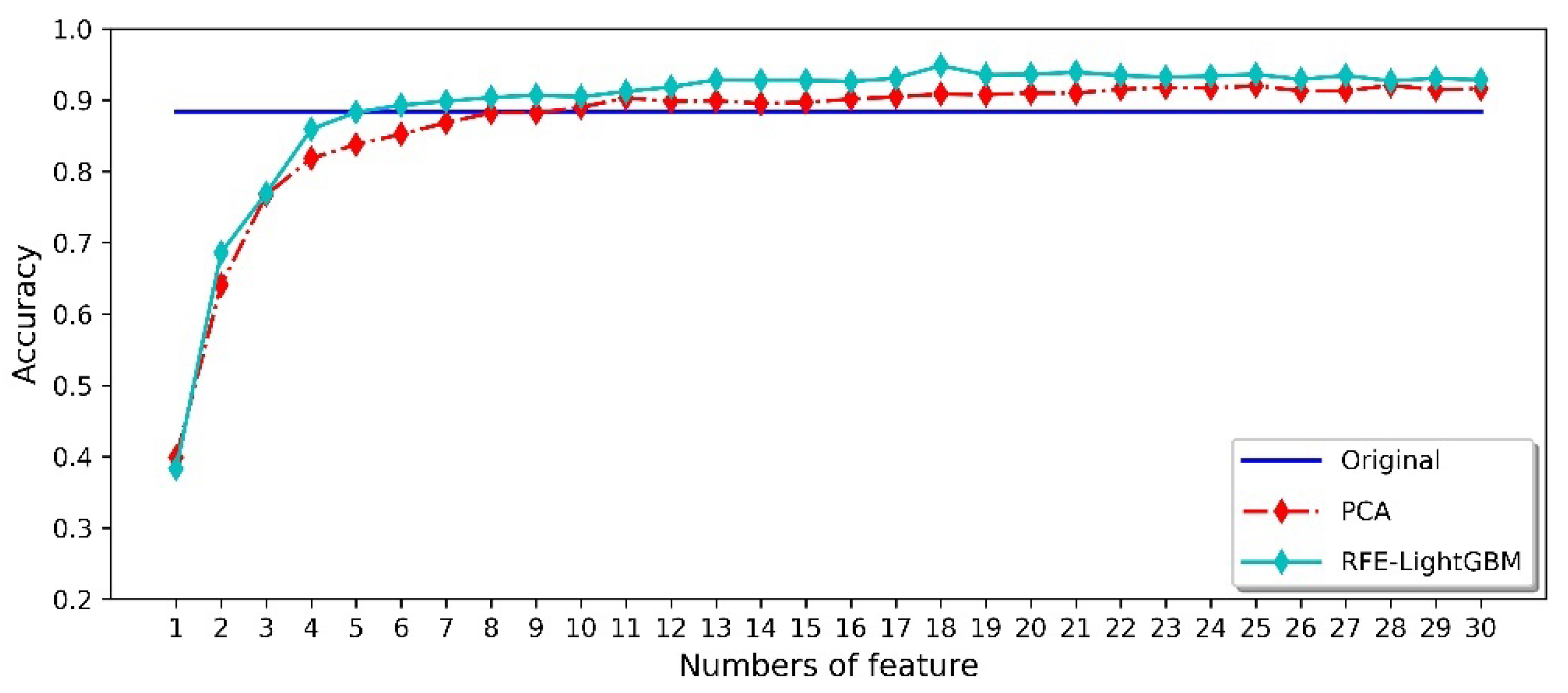
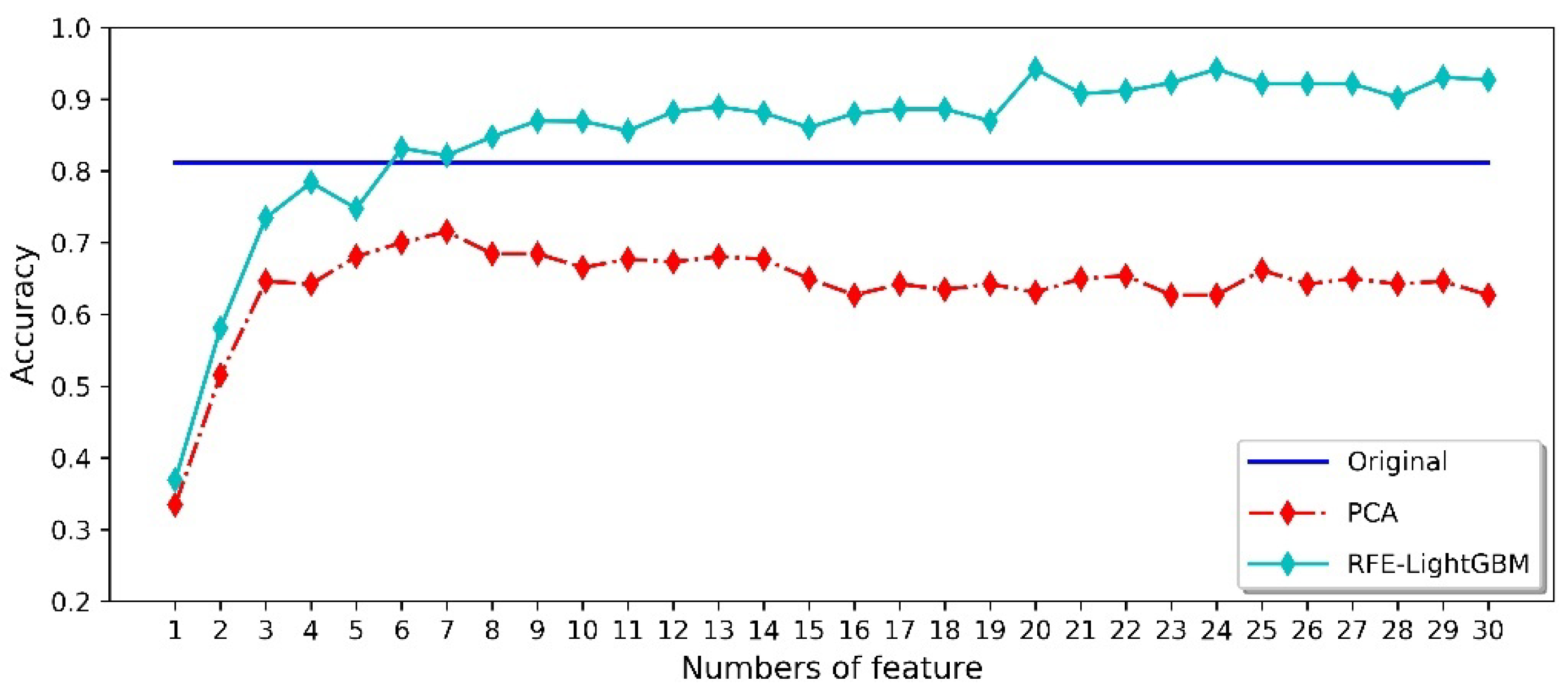
4.3. Dimensionality Reduction of Feature Datasets
5. Discussion
6. Conclusions
- i.
- The use of electronic nose systems in the classification and identification of recyclable containers can compensate for the shortcomings of manual and other intelligent devices.
- ii.
- Compared with PCA, RFE-LightGBM is an effective feature extraction method. It can not only reduce the dimensionality of the feature dataset, but also improve the classification accuracy.
- iii.
- Using the RFE-LightGBM method in gas classification can overcome the influence of odor change over time. The highest classification accuracy reaches 95%.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Song, X.-C.; Lin, Q.-B.; Zhang, Y.-C.; Li, Z.; Zeng, Y.; Chen, Z.-F. Rapid classification of virgin and recycled EPS containers by Fourier transform infrared spectroscopy and chemometrics. Food Addit. Contam. Part A 2018, 35, 2220–2229. [Google Scholar] [CrossRef] [PubMed]
- Al-Salem, S.M.; Lettieri, P.; Baeyens, J. Recycling and recovery routes of plastic solid waste (PSW): A review. Waste Manag. 2009, 29, 2625–2643. [Google Scholar] [CrossRef] [PubMed]
- Güler, P.; Bekiroglu, Y.; Gratal, X.; Pauwels, K.; Kragic, D. What’s in the container? Classifying object contents from vision and touch. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 4–18 September 2014; pp. 3961–3968. [Google Scholar]
- Resti, Y.; Mohruni, A.; Rodiana, T.; Zayanti, D. Study in Development of Cans Waste Classification System Based on Statistical Approaches. J. Phys. Conf. Ser. 2019, 1198, 092004. [Google Scholar] [CrossRef]
- Petrovskaya, A.; Khatib, O. Global localization of objects via touch. IEEE Trans. Robot. 2011, 27, 569–585. [Google Scholar] [CrossRef]
- Pezzementi, Z.; Plaku, E.; Reyda, C.; Hager, G. Tactile-object recognition from appearance information. IEEE Trans. Robot. 2011, 27, 473–487. [Google Scholar] [CrossRef]
- Valente, M.; Silva, H.; Caldeira, J.M.L.P.; Soares, V.N.G.J.; Gaspar, P.D. Detection of Waste Containers Using Computer Vision. Appl. Syst. Innov. 2019, 2, 11. [Google Scholar] [CrossRef]
- Nerin, C.; Alfaro, P.; Aznar, M.; Domeno, C. The challenge of identifying non-intentionally added substances from food packaging materials: A review. Anal. Chim. Acta 2013, 775, 14–24. [Google Scholar] [CrossRef]
- Brito, G.; Andrade, J.; Havel, J.; Díaz, C.; García, F.; Peña-Méndez, E. Classification of some heat-treated liver pastes according to container type, using heavy metals content and manufacturer’s data, by principal components analysis and potential curves. Meat Sci. 2006, 74, 296–302. [Google Scholar] [CrossRef]
- Norman, J.; Norman, H.; Clayton, A.; Lianekhammy, J.; Zielke, G. The visual and haptic perception of natural object shape. Percept. Psychophys. 2004, 66, 342–351. [Google Scholar] [CrossRef]
- Jamali, N.; Sammut, C. Majority voting: Material classification by tactile sensing using surface texture. IEEE Trans. Robot. 2011, 27, 508–521. [Google Scholar] [CrossRef]
- Abdoli, S. RFID application in municipal solid waste management system. IJER 2009, 3, 447–454. [Google Scholar]
- Gnoni, M.G.; Lettera, G.; Rollo, A. A feasibility study of a RFID traceability system in municipal solid waste management. Int. J. Inf. Technol. Manag. 2013, 12, 27. [Google Scholar] [CrossRef]
- Pfeisinger, C. Material recycling of post-consumer polyolefin bulk plastics: Influences on waste sorting and treatment processes in consideration of product qualities achievable. Waste Manag. Res. 2016, 35, 141–146. [Google Scholar] [CrossRef]
- Ragaert, K.; Delva, L.; Van, G.K. Mechanical and chemical recycling of solid plastic waste. Waste Manag. 2017, 69, 24–58. [Google Scholar] [CrossRef]
- Wang, Z.; Peng, B.; Huang, Y.; Sun, G. Classification for plastic bottles recycling based on image recognition. Waste Manag. 2019, 88, 170–181. [Google Scholar] [CrossRef]
- Ziouzios, D.; Tsiktsiris, D.; Baras, N.; Dasygenis, M. A Distributed Architecture for Smart Recycling Using Machine Learning. Futur. Internet 2020, 12, 141. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, X.; Mu, X.; Wang, Z.; Tian, R.; Wang, X.; Liu, X. Recyclable waste image recognition based on deep learning. Resour. Conserv. Recycl. 2021, 171, 105636. [Google Scholar] [CrossRef]
- Wang, J.; Tang, M.; Wang, H. Research on the Design of Intelligent Recycling System for Cosmetics Based on Extenics. Procedia Comput. Sci. 2022, 199, 937–945. [Google Scholar] [CrossRef]
- Wen, J.; Zhao, Y.; Rong, Q.; Yang, Z.; Yin, J.; Peng, Z. Rapid odor recognition based on reliefF algorithm using electronic nose and its application in fruit identification and classification. J. Food Meas. Charact. 2022, 16, 2422–2433. [Google Scholar] [CrossRef]
- De Vito, S.; Massera, E.; Miglietta, M.; Di Palma, P.; Fattoruso, G.; Brune, K.; Di Francia, G. Detection and quantification of composite surface contaminants with an e-nose for fast and reliable pre-bond quality assessment of aircraft components. Sens. Actuators B Chem. 2016, 222, 1264–1273. [Google Scholar] [CrossRef]
- Herrero, J.L.; Lozano, J.; Santos, J.P.; Fernandez, J.A.; Marcelo, J.I.S. A Web-Based Approach for Classifying Environmental Pollutants Using Portable E-nose Devices. IEEE Intell. Syst. 2016, 31, 108–112. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.; Nie, H.; Dang, L.; Li, G.; Ye, Q.; Kadri, C. Classification of multiple indoor air contaminants by an electronic nose and a hybrid support vector machine. Sens. Actuators B Chem. 2012, 174, 114–125. [Google Scholar] [CrossRef]
- Liu, Q.; Zhao, N.; Zhou, D.; Sun, Y.; Sun, K.; Pan, L.; Tu, K. Discrimination and growth tracking of fungi contamination in peaches using electronic nose. Food Chem. 2018, 262, 226–234. [Google Scholar] [CrossRef]
- Mesías, M.; Barea-Ramos, J.D.; Lozano, J.; Morales, F.J.; Martín-Vertedor, D. Application of an Electronic Nose Technology for the Prediction of Chemical Process Contaminants in Roasted Almonds. Chemosensors 2023, 11, 287. [Google Scholar] [CrossRef]
- Luo, S.; Chen, T. Two Derivative Algorithms of Gradient Boosting Decision Tree for Silicon Content in Blast Furnace System Prediction. IEEE Access 2020, 8, 196112–196122. [Google Scholar] [CrossRef]
- Nobre, J.; Neves, R.F. Combining principal component analysis, discrete wavelet transform and XGBoost to trade in the financial markets. Expert Syst. Appl. 2019, 125, 181–194. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Sanz, H.; Valim, C.; Vegas, E.; Oller, J.M.; Reverter, F. SVM-RFE: Selection and visualization of the most relevant features through non-linear kernels. BMC Bioinform. 2018, 19, 1–18. [Google Scholar] [CrossRef]
- Kumari, S.; Singh, K.; Khan, T.; Ariffin, M.M.; Mohan, S.K.; Baleanu, D.; Ahmadian, A. A Novel Approach for Continuous Authentication of Mobile Users Using Reduce Feature Elimination (RFE): A Machine Learning Approach. Mob. Networks Appl. 2023, 1–15. [Google Scholar] [CrossRef]
- Casey, M.; Chen, B.; Zhou, J.; Zhou, N. A Machine Learning Approach to Prostate Cancer Risk Classification through Use of RNA Sequencing Data. In Big Data—BigData 2019. BIGDATA 2019; Chen, K., Seshadri, S., Zhang, L.J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11514. [Google Scholar] [CrossRef]
- Viviant, M.; Trites, A.W.; Rosen, D.A.S.; Monestiez, P.; Guinet, C. Prey capture attempts can be detected in Steller sea lions and other marine predators using accelerometers. Polar Biol. 2010, 33, 713–719. [Google Scholar] [CrossRef]
- Yin, J.; Zhao, Y.; Peng, Z.; Ba, F.; Peng, P.; Liu, X.; Rong, Q.; Guo, Y.; Zhang, Y. Rapid Identification Method for CH4/CO/CH4-CO Gas Mixtures Based on Electronic Nose. Sensors 2023, 23, 2975. [Google Scholar] [CrossRef]
- Peng, Z.; Zhao, Y.; Yin, J.; Peng, P.; Ba, F.; Liu, X.; Guo, Y.; Rong, Q.; Zhang, Y. A Comprehensive Evaluation Model for Optimizing the Sensor Array of Electronic Nose. Appl. Sci. 2023, 13, 2338. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, Y.; Peyraut, F.; Planche, M.; Ilavsky, J.; Liao, H.; Montavon, G.; Lasalle, A.; Allimant, A. Parametric Analysis and Modeling for the Porosity Prediction in Suspension Plasma-Sprayed Coatings. J. Therm. Spray Tech. 2020, 29, 51–59. [Google Scholar] [CrossRef]
- Zhao, Y.L.; Zhao, C.H.; Huang, J.; Zhao, B. LaMnO3–Ni0.75Mn2.25O4 Supported Bilayer NTC Thermistors. J. Am. Ceram. Soc. 2014, 97, 1016–1019. [Google Scholar] [CrossRef]
- Zhao, C.; Zhao, Y. The investigation of Zn content on the structure and electrical properties of ZnxCu0.2Ni0.66Mn2.14−xO4 negative temperature coefficient ceramics. J. Mater. Sci. Mater. Electron. 2012, 23, 1788–1792. [Google Scholar] [CrossRef]
- Tong, Y.; Zhao, B.; Zhao, Y.; Yang, T.; Yang, F.; Hu, Q.; Zhao, C. Novel Anode-Supported Tubular Solid-Oxide Electrolytic Cell for Direct NO Decomposition in N2 Environment. Int. J. Electrochem. Sci. 2015, 10, 5338–5349. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, C.; Tong, Y. Spinel-structured Ni-free Zn0.9CuxMn2.1-xO4 (0.1 ≤ x ≤ 0.5) thermistors of negative temperature coefficient. J. Electroceramics 2013, 31, 286–290. [Google Scholar] [CrossRef]
- Yan, J.; Guo, X.; Duan, S.; Jia, P.; Wang, L.; Peng, C.; Zhang, S. Electronic Nose Feature Extraction Methods: A Review. Sensors 2015, 15, 27804–27831. [Google Scholar] [CrossRef] [PubMed]
- Gewers, F.L.; Ferreira, G.R.; De Arruda, H.F.; Silva, F.N.; Comin, C.H.; Amancio, D.R.; Costa, L.D.F. Principal Component Analysis. ACM Comput. Surv. 2021, 54, 70. [Google Scholar] [CrossRef]
- Wang, L.; Zeng, Y.; Chen, T. Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst. Appl. 2014, 42, 855–863. [Google Scholar] [CrossRef]
- Ghasemi-Varnamkhasti, M.; Mohammad-Razdari, A.; Yoosefian, S.H.; Izadi, Z.; Siadat, M. Aging discrimination of French cheese types based on the optimization of an electronic nose using multivariate computational approaches combined with response surface method (RSM). LWT 2019, 111, 85–98. [Google Scholar] [CrossRef]
- Huang, X.; Xin, J.; Zhao, J. A novel technique for rapid evaluation of fish freshness using colorimetric sensor array. J. Food Eng. 2011, 105, 632–637. [Google Scholar] [CrossRef]
- Bougrini, M.; Tahri, K.; Haddi, Z.; El Bari, N.; Llobet, E.; Jaffrezic-Renault, N.; Bouchikhi, B. Aging time and brand determination of pasteurized milk using a multisensor e-nose combined with a voltammetric e-tongue. Mater. Sci. Eng. C 2014, 45, 348–358. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Main Test Objects | Detection Range (ppm) | Response Time (s) |
|---|---|---|---|
| S1 | Ethanol, Acetone, Hydrogen Sulfide | 0.1–500 | <20 |
| S2 | VOCs, Smog | 1–500 | <10 |
| S3 | Ethanol, Hydrogen Sulfide, Acetone | 1–500 | <20 |
| S4 | Hydrogen | 0.1–300 | <10 |
| S5 | Hydrogen Sulfide | 0.5–300 | <20 |
| S6 | Ammonia | 10–300 | <10 |
| S7 | Ethanol | 1–500 | <20 |
| S8 | VOCs | 10–500 | <20 |
| S9 | Hydrogen Sulfide, Carbon Monoxide | 1–500 | <10 |
| S10 | Acetone, Hydrogen Sulfide | 0.1–500 | <10 |
| Sample Label | Contaminant | Gas percentage Concentration |
|---|---|---|
| G0 | Water | 100% |
| G1 | Cigarette | 10% |
| G2 | Cigarette | 30% |
| G3 | Cigarette | 50% |
| G4 | Coffee | 10% |
| G5 | Coffee | 30% |
| G6 | Coffee | 50% |
| G7 | Liquor | 10% |
| G8 | Liquor | 30% |
| G9 | Liquor | 50% |
| G10 | Vinegar | 10% |
| G11 | Vinegar | 30% |
| G12 | Vinegar | 50% |
| Symbol Mark | Number | Feature Description | Function |
|---|---|---|---|
| D | 1 | Difference | |
| R | 1 | Relative difference | |
| F | 1 | Fractional difference | |
| L | 1 | Logarithm difference | |
| I | 1 | Integral | |
| DE | 5 | Derivative | |
| SD | 5 | Second derivative |
| Feature Name | Importance |
|---|---|
| I-S6 | 0.1571 |
| I-S2 | 0.1246 |
| L-S7 | 0.0607 |
| DE5-S9 | 0.0484 |
| SD4-S6 | 0.0458 |
| R-S6 | 0.0334 |
| L-S6 | 0.0327 |
| I-S8 | 0.0301 |
| DE4-S5 | 0.0292 |
| DE4-S7 | 0.0287 |
| D-S3 | 0.0250 |
| DE5-S8 | 0.0247 |
| DE5-S7 | 0.0236 |
| D-S1 | 0.0194 |
| SD4-S7 | 0.0187 |
| R-S8 | 0.0183 |
| DE4-S10 | 0.0167 |
| SD4-S2 | 0.0161 |
| D-S6 | 0.0127 |
| L-S1 | 0.0121 |
| DE4-S8 | 0.0121 |
| R-S9 | 0.0116 |
| DE2-S7 | 0.0112 |
| DE3-S6 | 0.0110 |
| DE5-S3 | 0.0102 |
| DE3-S7 | 0.0101 |
| SUM | 0.8442 |
| Datasets | Number of Days of Training Data Collection | Number of Days of Testing Data Collection |
|---|---|---|
| Scheme 1 | 2-3-4-5 | 1 |
| Scheme 2 | 1-3-4-5 | 2 |
| Scheme 3 | 1-2-4-5 | 3 |
| Scheme 4 | 1-2-3-5 | 4 |
| Scheme 5 | 1-2-3-4 | 5 |
| Dataset | Random | Scheme 1 | Scheme 2 | Scheme 3 | Scheme 4 | Scheme 5 |
|---|---|---|---|---|---|---|
| Average accuracy of raw feature data | 88.38% | 81.15% | 85.38% | 84.23% | 83.85% | 83.46% |
| Maximum accuracy of PCA | 92.02% | 71.54% | 70.38% | 75.77% | 74.62% | 62.31% |
| RFE-LightGBM highest accuracy | 94.84% | 94.23% | 93.08% | 95.00% | 93.46% | 94.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ba, F.; Peng, P.; Zhang, Y.; Zhao, Y. Classification and Identification of Contaminants in Recyclable Containers Based on a Recursive Feature Elimination-Light Gradient Boosting Machine Algorithm Using an Electronic Nose. Micromachines 2023, 14, 2047. https://doi.org/10.3390/mi14112047
Ba F, Peng P, Zhang Y, Zhao Y. Classification and Identification of Contaminants in Recyclable Containers Based on a Recursive Feature Elimination-Light Gradient Boosting Machine Algorithm Using an Electronic Nose. Micromachines. 2023; 14(11):2047. https://doi.org/10.3390/mi14112047
Chicago/Turabian StyleBa, Fushuai, Peng Peng, Yafei Zhang, and Yongli Zhao. 2023. "Classification and Identification of Contaminants in Recyclable Containers Based on a Recursive Feature Elimination-Light Gradient Boosting Machine Algorithm Using an Electronic Nose" Micromachines 14, no. 11: 2047. https://doi.org/10.3390/mi14112047