

Hybrid Bipedal Locomotion Based on Reinforcement Learning and Heuristics



Abstract
:
1. Introduction
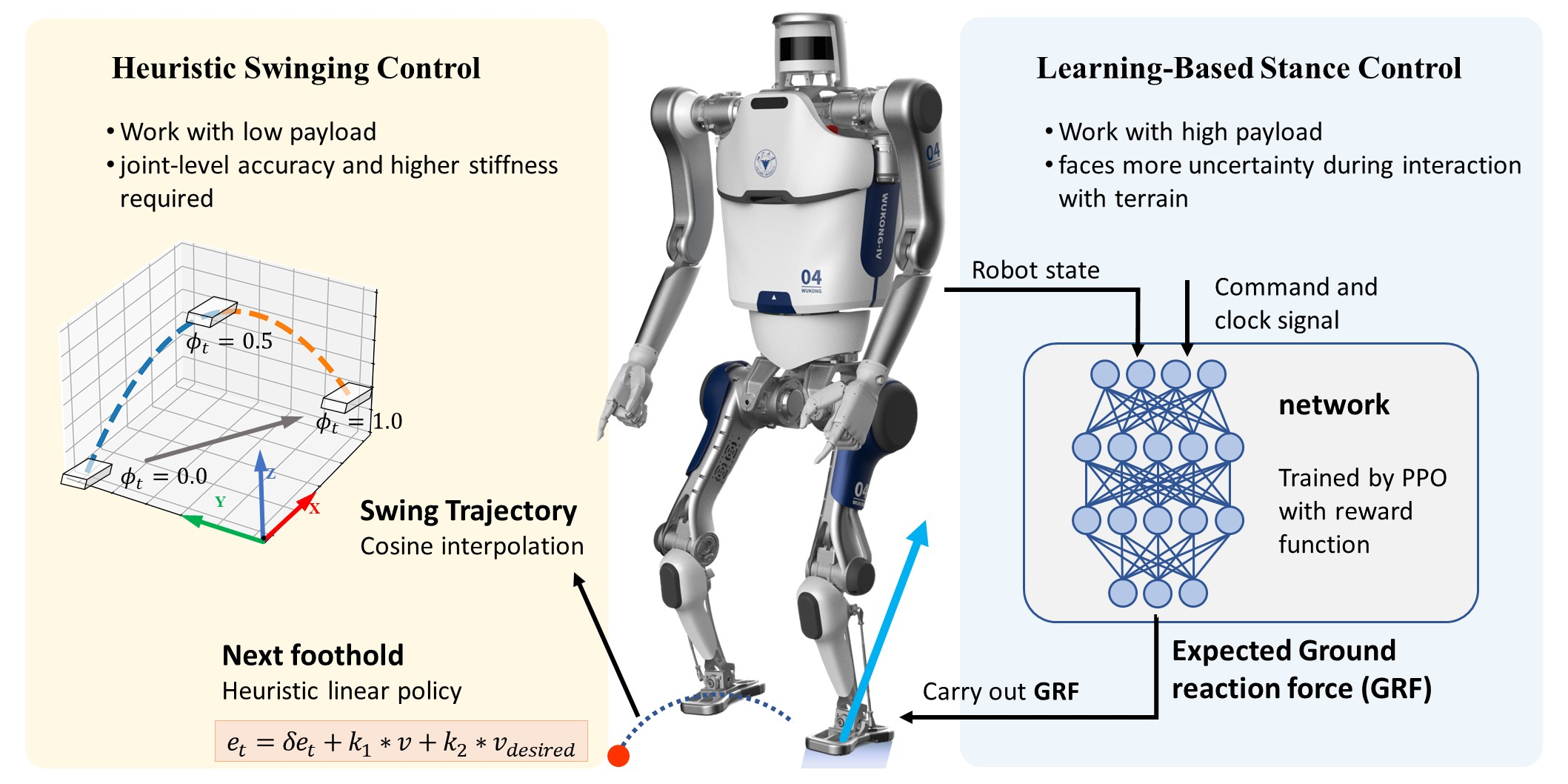
- We proposed an efficient hybrid locomotion policy that divides the task into a stance part using model-free learning-based stance control and a swing part using heuristics swing control. The trained policy can perform controllable and regulated gait.
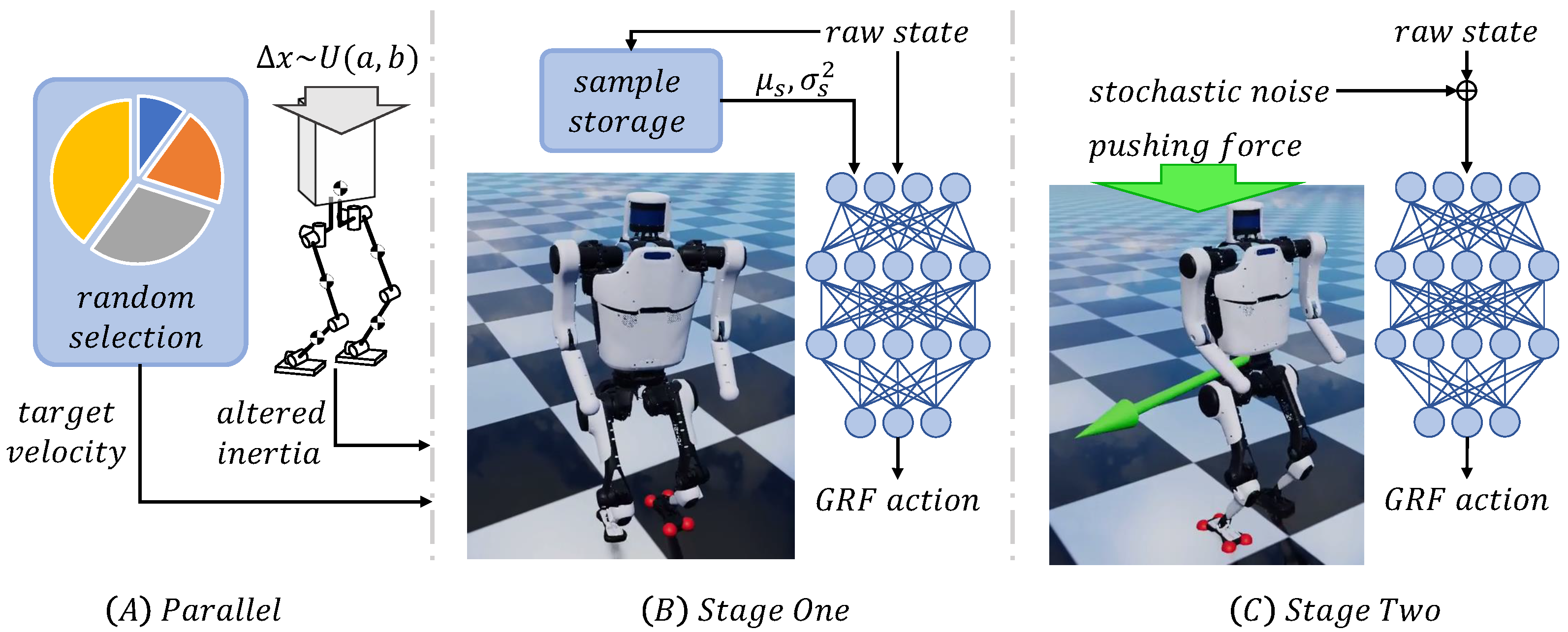
- To prevent policy divergence caused by fierce randomization at early stages, we proposed a parallel curriculum learning schema with two-stage progressive domain randomization for challenging locomotion tasks.
- To further reduce the magnitude of sensor randomization which withdraws training speed, we proposed heuristic-based regularization feedback loops on real-world robot systems in addition to a two-branch hybrid controller for resisting simulation model mismatch and assisting stabilization.
2. Platform and Notations
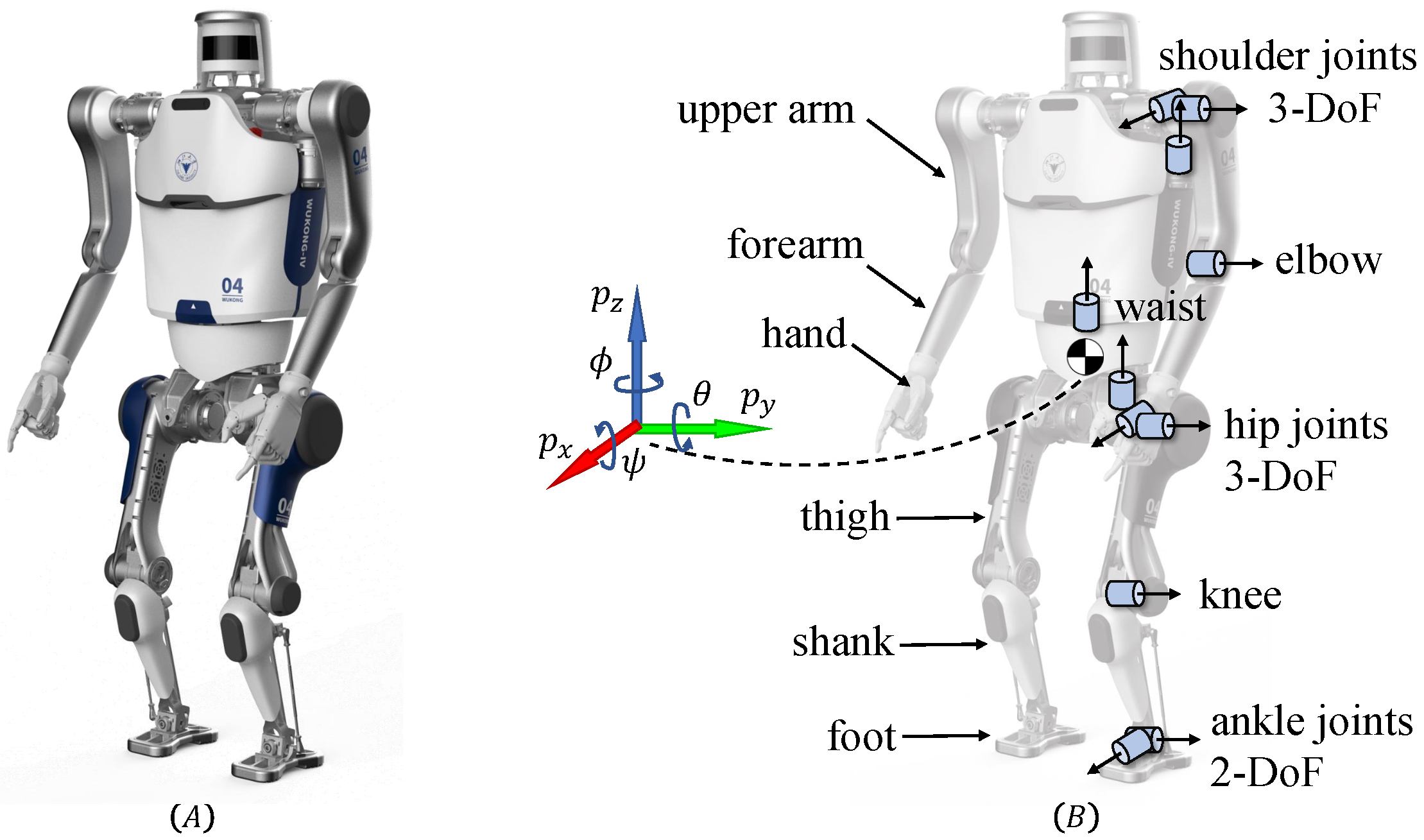
2.1. Robot Model
2.2. Math Notations
3. Materials and Methods
3.1. Learning-Based Stance Control
3.1.1. Observation Space and Action Space
3.1.2. Reward Design
3.1.3. Policy Representation
3.1.4. Adaptive Normalization
3.2. Curriculum Schema
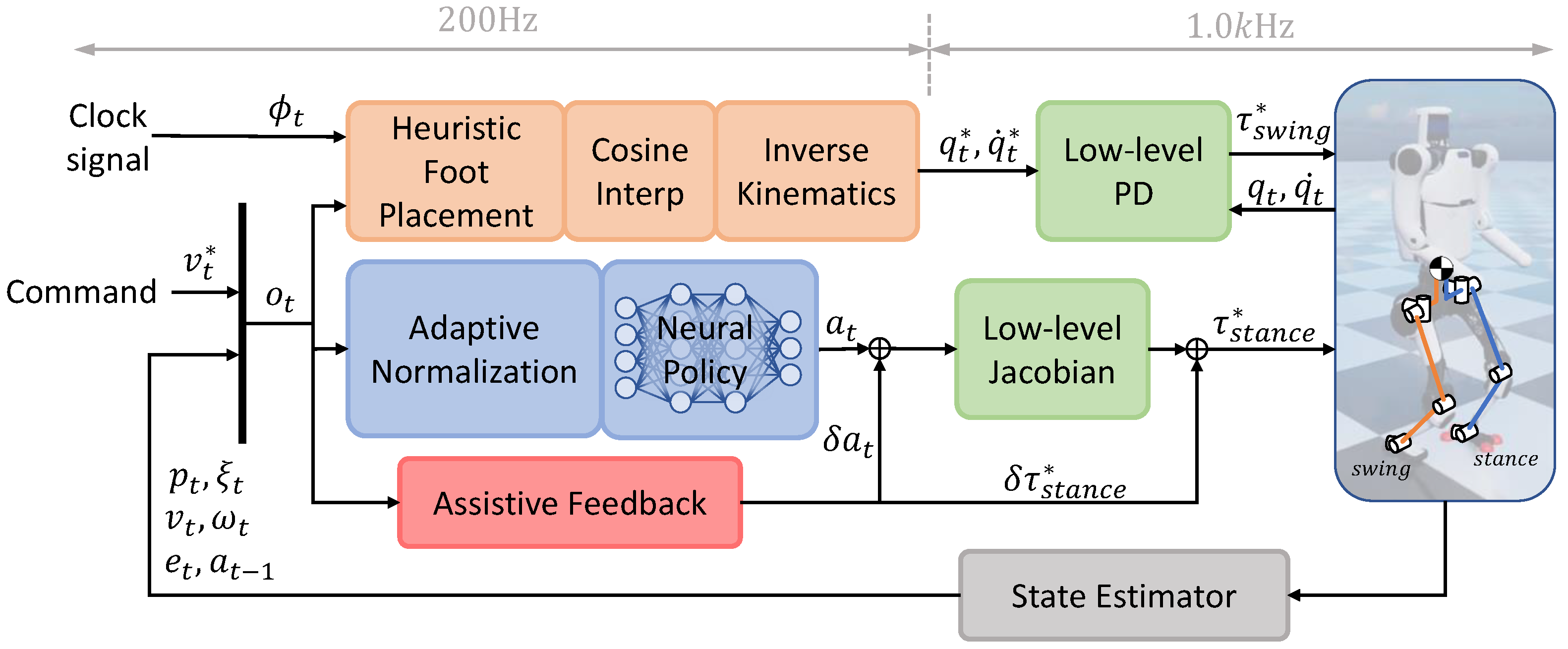
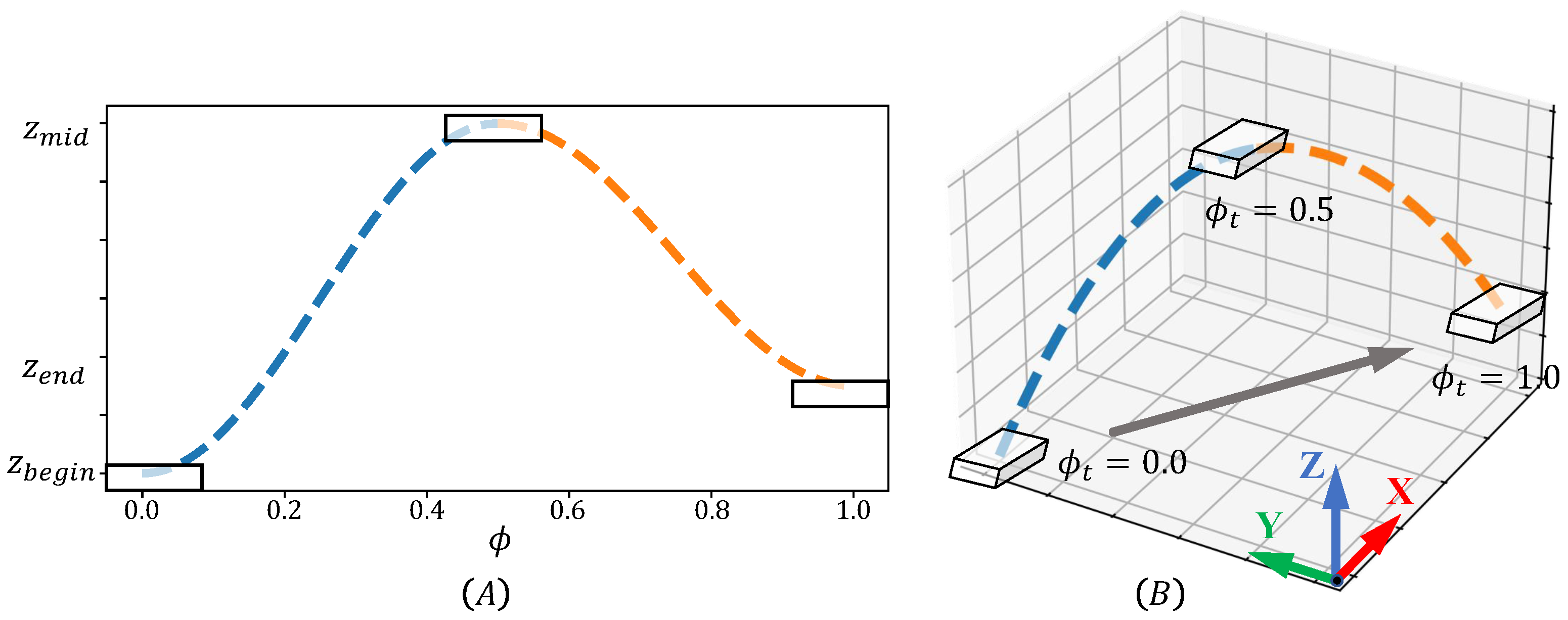
3.3. Heuristic Swinging Control
3.4. Low-Level Controller
3.5. Regularized Sim-to-Real Transfer
4. Results
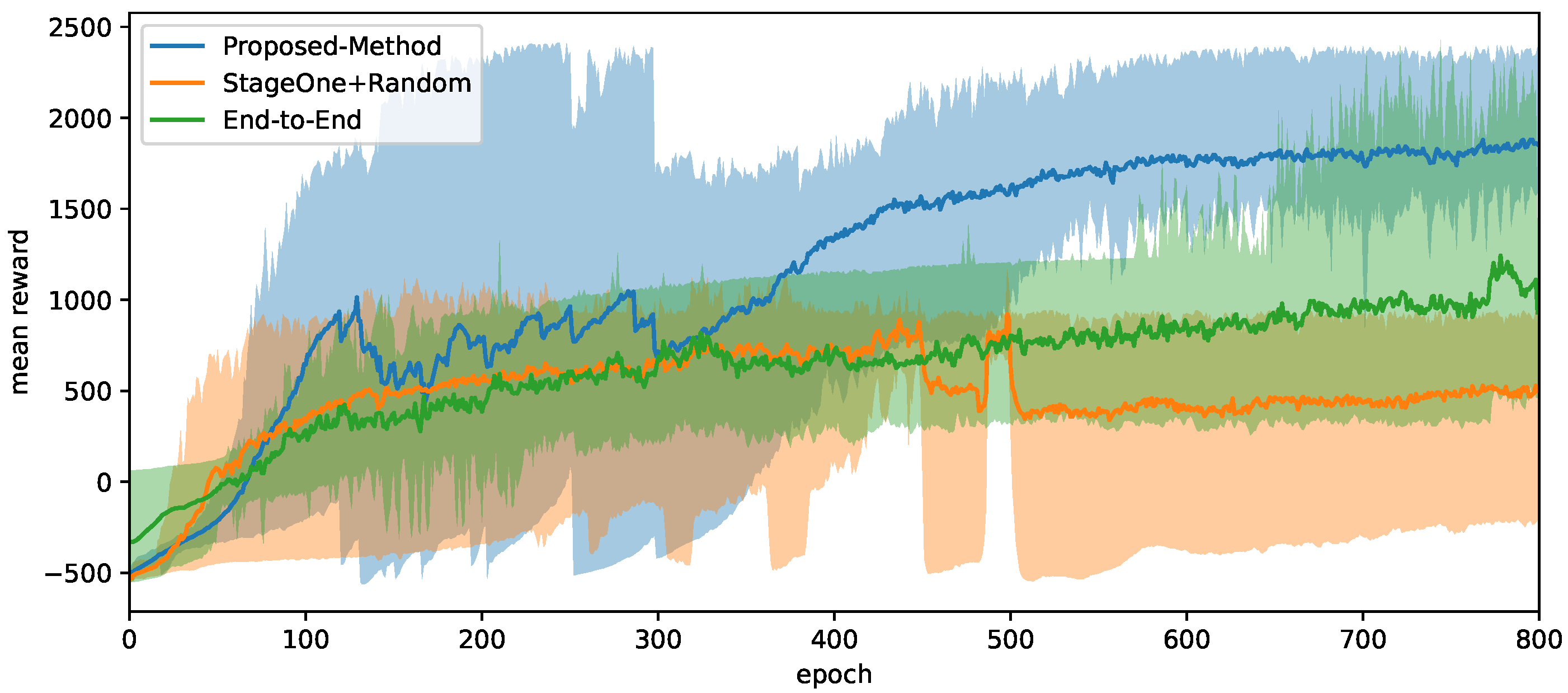
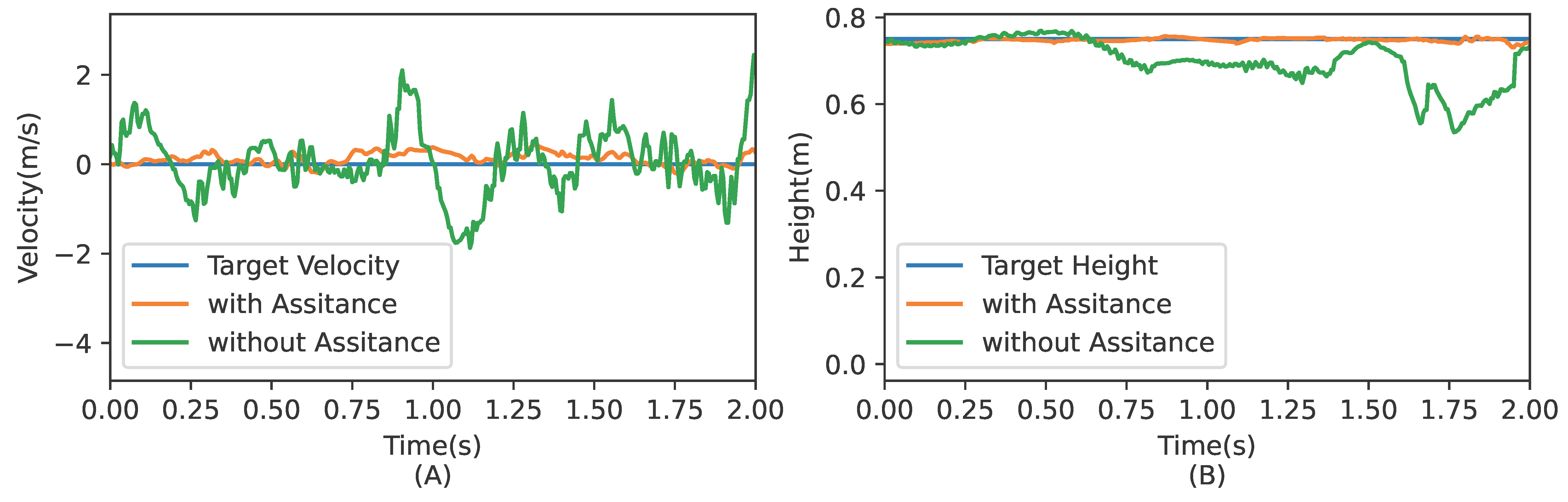
4.1. Simulation Training Results
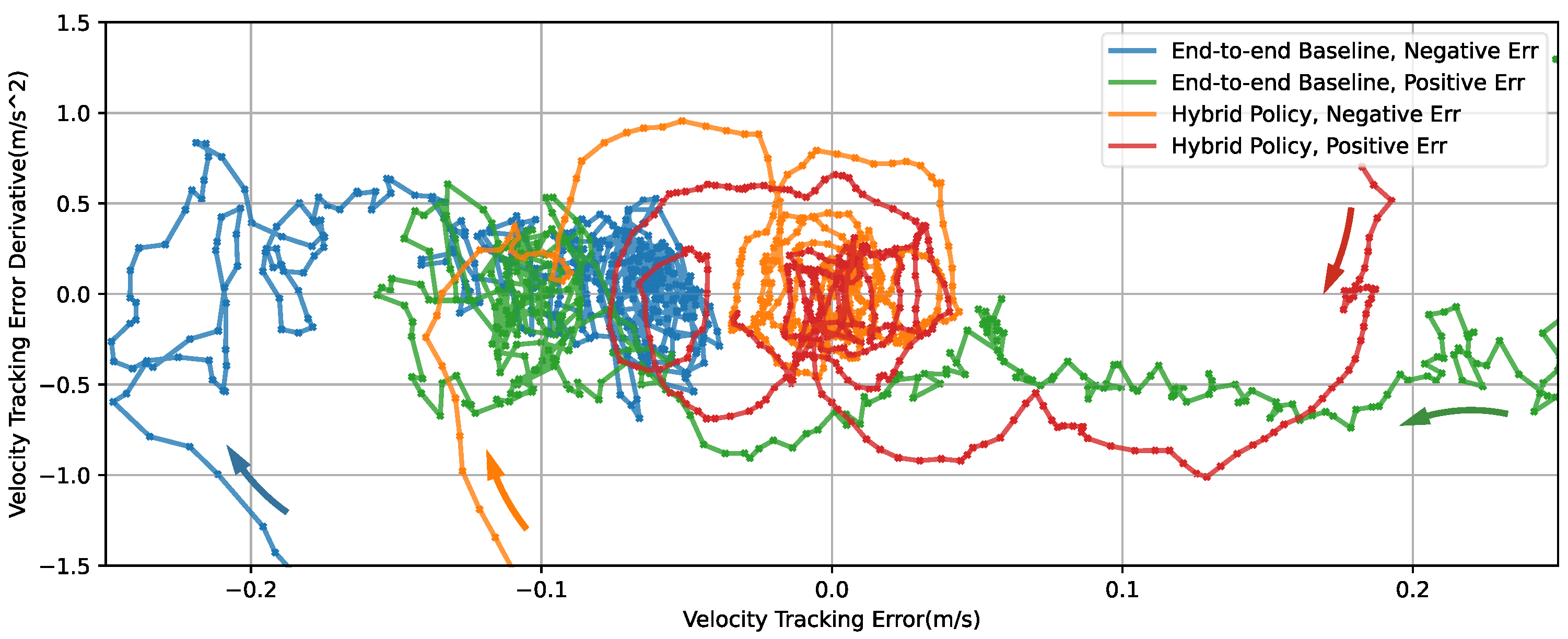
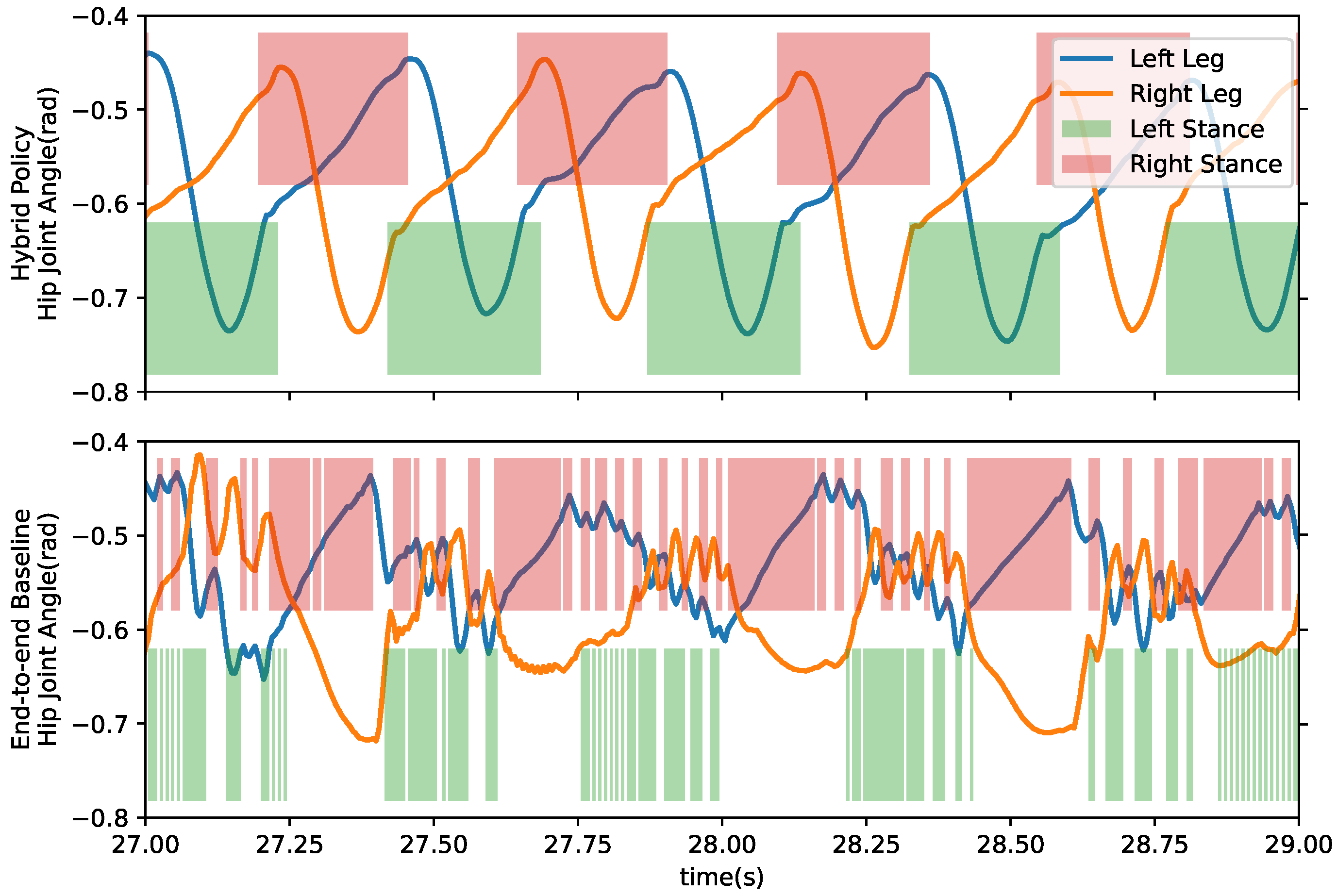
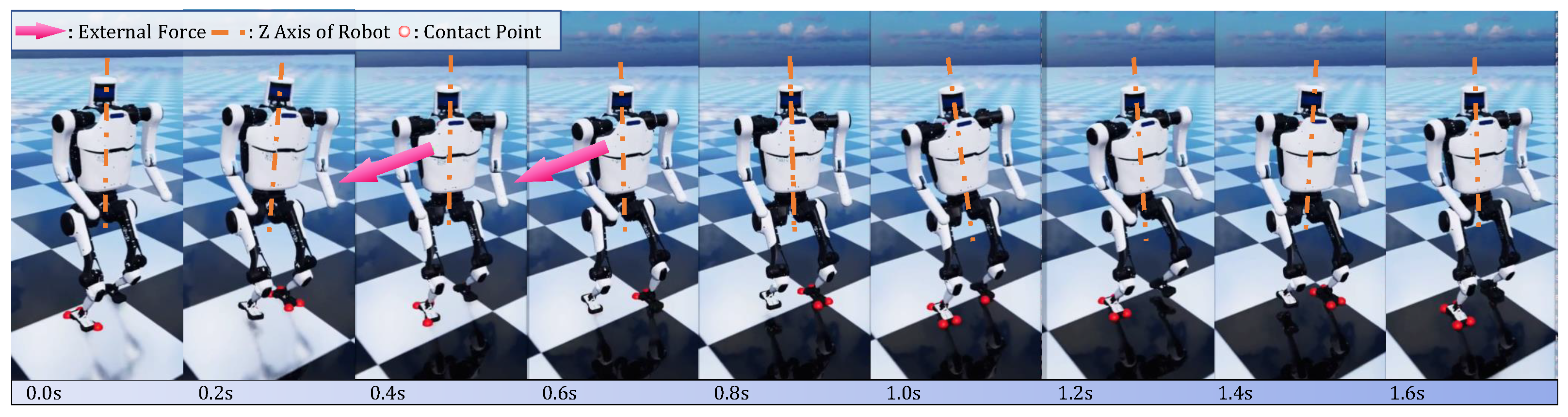
4.2. Sim-to-Real Transfer
5. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Parameter Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Mass | 45 kg |
| Height | 1.4 m |
| Thigh Length | 0.3 m |
| Shank Length | 0.3 m |
| DoF per Leg | 6 |
| DoF per Arm | 7 |
| Power Source | Lithium Battery |
| Joint Actuator | Brushless Motor |
| Reward Term | Coefficient |
|---|---|
| = 0.3, = 40 | |
| = 0.3, = 500 | |
| = 0.3, = 400 | |
| = 0.1, = 10 | |
| = 0.3, = 100 |
| Parameter | Value |
|---|---|
| Parallel Environment | 150 |
| Maximum time steps per epoch (Stage One) | 2000 |
| Learning Rate | 1 × 10 |
| Discount Factor | 0.996 |
| Curriculum Reward Threshold | 2300 |
| Variable | Distribution |
|---|---|
| Link Mass | |
| Link CoM Position | |
| Link Inertia | |
| Sensor | |
| External Force along X Axis | |
| External Force along Y Axis |
References
- Fukuda, T. Cyborg and Bionic Systems: Signposting the Future. Cyborg Bionic Syst. 2020, 2020, 1310389. [Google Scholar] [CrossRef]
- Raibert, M.; Tello, E. Legged robots that balance. IEEE Expert 1986, 1, 89. [Google Scholar] [CrossRef]
- Pratt, J.; Torres, A.; Dilworth, P.; Pratt, G. Virtual actuator control. In Proceedings of the 1996 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Osaka, Japan, 8 November 1996; Volume 3, pp. 1219–1226. [Google Scholar]
- Pratt, J.; Dilworth, P.; Pratt, G. Virtual model control of a bipedal walking robot. In Proceedings of the 1997 IEEE International Conference on Robotics and Automation (ICRA), Albuquerque, NM, USA, 25 April 1997; Volume 1, pp. 193–198. [Google Scholar]
- Gubina, F.; Hemami, H.; McGhee, R.B. On the dynamic stability of biped locomotion. IEEE Trans. Biomed. Eng. 1974, BME-21, 102–108. [Google Scholar] [CrossRef] [PubMed]
- Henze, B.; Ott, C.; Roa, M.A. Posture and balance control for humanoid robots in multi-contact scenarios based on model predictive control. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 3253–3258. [Google Scholar]
- Bledt, G. Regularized Predictive Control Framework for Robust Dynamic Legged Locomotion. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2020. [Google Scholar]
- Haarnoja, T.; Ha, S.; Zhou, A.; Tan, J.; Tucker, G.; Levine, S. Learning to walk via deep reinforcement learning. arXiv 2018, arXiv:1812.11103. [Google Scholar]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-real: Learning agile locomotion for quadruped robots. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018; pp. 1–13. [Google Scholar]
- Hutter, M.; Gehring, C.; Jud, D.; Lauber, A.; Bellicoso, C.D.; Tsounis, V.; Hwangbo, J.; Bodie, K.; Fankhauser, P.; Bloesch, M.; et al. Anymal-a highly mobile and dynamic quadrupedal robot. In Proceedings of the 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 38–44. [Google Scholar]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Hwangbo, J.; Hutter, M. Robust recovery controller for a quadrupedal robot using deep reinforcement learning. arXiv 2019, arXiv:1901.07517. [Google Scholar]
- Siekmann, J.; Valluri, S.; Dao, J.; Bermillo, L.; Duan, H.; Fern, A.; Hurst, J. Learning memory-based control for human-scale bipedal locomotion. In Proceedings of the Robotics: Science and Systems (RSS), Virtual Event, 12–17 July 2020; pp. 1–8. [Google Scholar]
- Siekmann, J.; Godse, Y.; Fern, A.; Hurst, J. Sim-to-real learning of all common bipedal gaits via periodic reward composition. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7309–7315. [Google Scholar]
- Siekmann, J.; Green, K.; Warila, J.; Fern, A.; Hurst, J. Blind bipedal stair traversal via sim-to-real reinforcement learning. In Proceedings of the Robotics: Science and Systems (RSS), Virtual Event, 12–16 July 2021; pp. 1–9. [Google Scholar]
- Yang, C.; Yuan, K.; Heng, S.; Komura, T.; Li, Z. Learning natural locomotion behaviors for humanoid robots using human bias. IEEE Robot. Autom. Lett. 2020, 5, 2610–2617. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Yuan, K.; Zhu, Q.; Yu, W.; Li, Z. Multi-expert learning of adaptive legged locomotion. Sci. Robot. 2020, 5, eabb2174. [Google Scholar] [CrossRef] [PubMed]
- Acero, F.; Yuan, K.; Li, Z. Learning perceptual locomotion on uneven terrains using sparse visual Observations. IEEE Robot. Autom. Lett. 2022, 7, 8611–8618. [Google Scholar] [CrossRef]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef]
- Miki, T.; Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning robust perceptive locomotion for quadrupedal robots in the wild. Sci. Robot. 2022, 7, eabk2822. [Google Scholar] [CrossRef]
- Kumar, A.; Fu, Z.; Pathak, D.; Malik, J. RMA: Rapid motor adaptation for legged robots. In Proceedings of the Robotics: Science and Systems (RSS), Virtual Event, 12–16 July 2021; pp. 1–11. [Google Scholar]
- Iscen, A.; Caluwaerts, K.; Tan, J.; Zhang, T.; Coumans, E.; Sindhwani, V.; Vanhoucke, V. Policies modulating trajectory generators. In Proceedings of the 2nd Conference on Robot Learning (PMLR), Zürich, Switzerland, 29–31 October 2018; Volume 87, pp. 916–926. [Google Scholar]
- Shao, Y.; Jin, Y.; Liu, X.; He, W.; Wang, H.; Yang, W. Learning free gait transition for quadruped robots Via phase-guided controller. IEEE Robot. Autom. Lett. 2022, 7, 1230–1237. [Google Scholar] [CrossRef]
- Green, K.; Godse, Y.; Dao, J.; Hatton, R.L.; Fern, A.; Hurst, J. Learning spring mass locomotion: Guiding policies with a reduced-order model. IEEE Robot. Autom. Lett. 2021, 6, 3926–3932. [Google Scholar] [CrossRef]
- Xie, Z.; Da, X.; van de Panne, M.; Babich, B.; Garg, A. Dynamics randomization revisited: A case study for quadrupedal locomotion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 4955–4961. [Google Scholar]
- Kumar, A.; Li, Z.; Zeng, J.; Pathak, D.; Sreenath, K.; Malik, J. Adapting rapid motor adaptation for bipedal robots. arXiv 2022, arXiv:2205.15299. [Google Scholar]
- Xie, Z.; Berseth, G.; Clary, P.; Hurst, J.; van de Panne, M. Feedback control for cassie with deep reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1241–1246. [Google Scholar]
- Duan, H.; Dao, J.; Green, K.; Apgar, T.; Fern, A.; Hurst, J. Learning task space actions for bipedal locomotion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 1276–1282. [Google Scholar]
- Krishna, L.; Mishra, U.A.; Castillo, G.A.; Hereid, A.; Kolathaya, S. Learning linear policies for robust bipedal locomotion on terrains with varying slopes. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 5159–5164. [Google Scholar]
- Krishna, L.; Castillo, G.A.; Mishra, U.A.; Hereid, A.; Kolathaya, S. Linear policies are sufficient to realize robust bipedal walking on challenging terrains. IEEE Robot. Autom. Lett. 2022, 7, 2047–2054. [Google Scholar] [CrossRef]
- Namiki, A.; Yokosawa, S. Origami Folding by Multifingered Hands with Motion Primitives. Cyborg and Bionic Systems 2021, 2021, 9851834. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Hutter, M. Per-contact iteration method for solving contact dynamics. IEEE Robot. Autom. Lett. 2018, 3, 895–902. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 1–12. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems 12 (NIPS 1999), Denver, CO, USA, 29 November–4 December 1999; Volume 12, pp. 1008–1014. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-baselines3: Reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Pratt, J.; Carff, J.; Drakunov, S.; Goswami, A. Capture point: A step toward humanoid push recovery. In Proceedings of the 6th IEEE-RAS International Conference on Humanoid Robots (HUMANOIDS), Genova, Italy, 4–6 December 2006; pp. 200–207. [Google Scholar]











| Parameters | Value |
|---|---|
| Network Type | MLP |
| Latent Layer | 2 |
| Latent Node Number | 256 |
| Activation | Tanh |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wei, W.; Xie, A.; Zhang, Y.; Wu, J.; Zhu, Q. Hybrid Bipedal Locomotion Based on Reinforcement Learning and Heuristics. Micromachines 2022, 13, 1688. https://doi.org/10.3390/mi13101688
Wang Z, Wei W, Xie A, Zhang Y, Wu J, Zhu Q. Hybrid Bipedal Locomotion Based on Reinforcement Learning and Heuristics. Micromachines. 2022; 13(10):1688. https://doi.org/10.3390/mi13101688
Chicago/Turabian StyleWang, Zhicheng, Wandi Wei, Anhuan Xie, Yifeng Zhang, Jun Wu, and Qiuguo Zhu. 2022. "Hybrid Bipedal Locomotion Based on Reinforcement Learning and Heuristics" Micromachines 13, no. 10: 1688. https://doi.org/10.3390/mi13101688