
Visual Feature Learning on Video Object and Human Action Detection: A Systematic Review

 ,
,
Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Contributions
1.3. Paper Organization
2. Machine Learning-Based Evaluation Metrics and Video-Based Datasets
2.1. Machine Learning-Based Evaluation Metrics
2.2. Video-Based Datasets for Object Detection and Action Recognition
3. Video Frame-Based Object Detection Algorithms
3.1. One-Stage Video Object Detection
3.1.1. You Only Look Once (YOLO)
3.1.2. YOLO9000 (YOLOv2)
3.1.3. YOLOv3
3.1.4. YOLOv4
3.1.5. Using-Dilated-Convolution Unmanned Aerial Vehicle (UAV) Detection
3.1.6. FastUAV-NET
3.1.7. Single Shot MultiBox Detector (SSD) and Other Improved Versions
3.2. Two-Stage Video Object Detection
3.3. Mixed-Stage Video Object Detection
4. Extracting the Key Frames for the Video Detection
5. Video Detection Using the Temporal Information
5.1. LSTM-Based Video Detection
5.1.1. Association Long Short-Term Memory (Association LSTM)
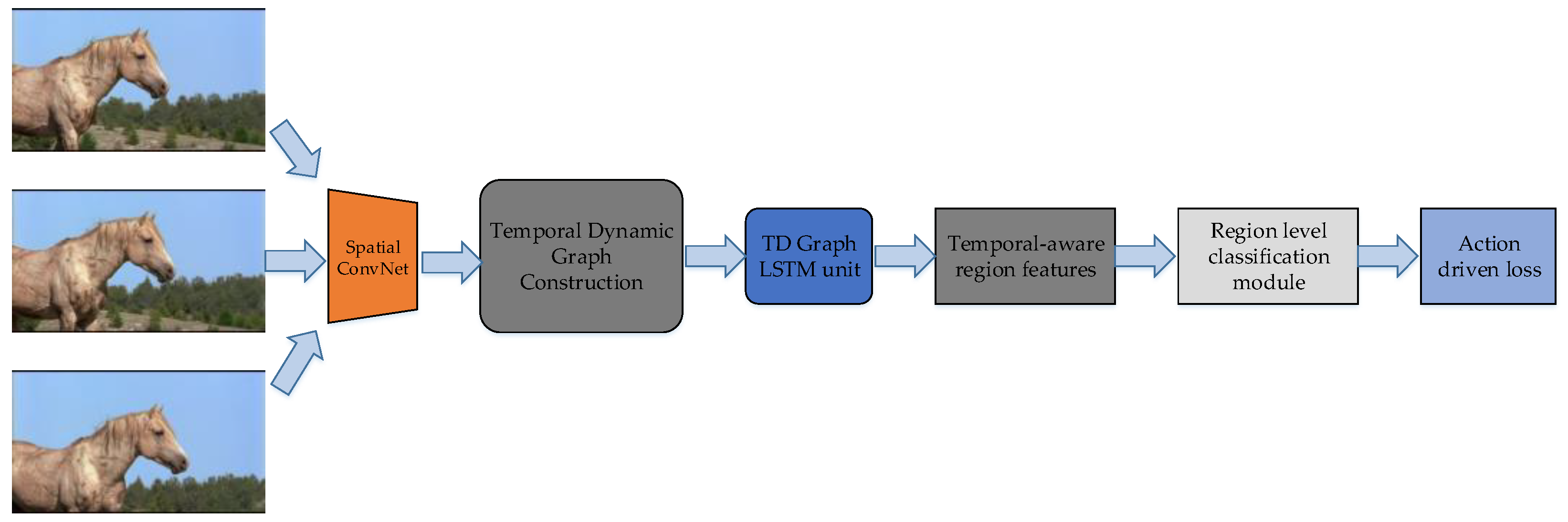
5.1.2. Temporal Dynamic Graph LSTM (TD-Graph LSTM)
5.1.3. Bottleneck-LSTM
5.1.4. Patchwork
5.1.5. Progressive Sparse Local Attention (PSLA)
5.1.6. Mobile High Performance Video Object Detection
5.1.7. Learnable Spatio-Temporal Sampling (LSTS)
5.1.8. LiDAR-Based Online 3D Video Object Detection
5.1.9. Memory-Guided Mobile Video Object Detection
5.1.10. Two-Path Convolutional LSTM (convLSTM) Pyramid
5.1.11. Spatial-Temporal Memory Network (STMN)
5.2. Video Detection Using Optical Flow
5.2.1. Tubelets with Convolutional Neural Networks (T-CNN)
5.2.2. Deep Feature Flow (DFF)
5.2.3. Flow-Guided Feature Aggregation (FGFA)
5.2.4. Fully Motion-Aware Net (MANet)
5.2.5. Long Short-Term Feature Aggregation (LSFA)
5.3. Video Detection Using Convolution among Adjacent Frames
5.3.1. 3D Convolution
5.3.2. Temporal Convolutional Network (TCN)
5.3.3. Detect to Tracks and Tracks to Detect (D&T)
5.3.4. Recurrent Residual Module (RRM)
5.3.5. Spatiotemporal Sampling Network (STSN)
5.3.6. Integrated Video Object Detection and Tracking
5.3.7. Relation Distillation Networks (RDN)
5.3.8. Long-Range Temporal Relationships
5.3.9. Sequence Level Semantics Aggregation (SELSA)
5.3.10. Detection System for Extended Video Analysis
5.3.11. Memory Enhanced Global-Local Aggregation (MEGA)
5.3.12. Temporal Shift Module (TSM)
5.3.13. Context Region with Convolutional Neural Network (Context R-CNN)
5.3.14. RetinaNet-VIDeo (RN-VID)
5.3.15. Plug & Play Convolutional Regression Tracker
5.3.16. Geometry-Aware Spatio-Temporal Network (GAST-Net)
5.3.17. High Quality Object Linking
5.3.18. Spatio-Temporal-Interactive Network (STINet)
5.3.19. Pose-Embedding Network (PEN)
5.3.20. Short-Term Anchor Linking and Long-Term Self-Guided Attention
5.3.21. Temporal Convolutional Network (TCN)
6. Discussion of the Video Object and Human Action Detection Methods
6.1. The Performance of the Deep Learning-Based Video Detection Methods
6.2. The Evaluation Methods of Video Detection
7. Remark of the Limitations and Future Research Directions of Video Detection
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 881, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1152, pp. 1150–1157. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Haar, A. Zur theorie der orthogonalen funktionensysteme. Math. Ann. 1910, 69, 331–371. [Google Scholar] [CrossRef]
- Farid, H. Blind inverse gamma correction. IEEE Trans. Image Process. 2001, 10, 1428–1433. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Barron, J.L.; Fleet, D.J.; Beauchemin, S.S. Performance of Optical-Flow Techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Brox, T.; Malik, J. Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the Computer Vision—ECCV 2010, Berlin/Heidelberg, Germany, 5–11 September 2010; pp. 282–295. [Google Scholar]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7464–7473. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The ApolloScape Dataset for Autonomous Driving. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–10676. [Google Scholar]
- Wang, Y.; Jodoin, P.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An Expanded Change Detection Benchmark Dataset. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 23–28 June 2014; pp. 393–400. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbeláez, P.; Sorkine-Hornung, A.; Van Gool, L. The 2017 davis challenge on video object segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Gool, L.V.; Gross, M.; Sorkine-Hornung, A. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Chan, A.; Vasconcelos, N. Ucsd pedestrian dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2886–2895. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Kristan, M.; Pflugfelder, R.; Leonardis, A.; Matas, J.; Čehovin, L.; Nebehay, G.; Vojíř, T.; Fernández, G.; Lukežič, A.; Dimitriev, A.; et al. The Visual Object Tracking VOT2014 Challenge Results. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Cham, Switzerland, 6–7 September 2014; pp. 191–217. [Google Scholar]
- Dendorfer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S.; Leal-Taixé, L. Motchallenge: A benchmark for single-camera multiple target tracking. Int. J. Comput. Vis. 2021, 129, 845–881. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Kliper-Gross, O.; Hassner, T.; Wolf, L. The action similarity labeling challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 615–621. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Jiang, Y.G.; Wu, Z.; Wang, J.; Xue, X.; Chang, S.F. Exploiting Feature and Class Relationships in Video Categorization with Regularized Deep Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 352–364. [Google Scholar] [CrossRef] [PubMed]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 510–526. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. AVA: A Video Dataset of Spatio-Temporally Localized Atomic Visual Actions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6047–6056. [Google Scholar]
- Fouhey, D.F.; Kuo, W.; Efros, A.A.; Malik, J. From Lifestyle Vlogs to Everyday Interactions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4991–5000. [Google Scholar]
- Zhao, H.; Torralba, A.; Torresani, L.; Yan, Z. HACS: Human Action Clips and Segments Dataset for Recognition and Temporal Localization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8667–8677. [Google Scholar]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5843–5851. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2003, 2, 577–584. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-Shot Image Semantic Segmentation With Prototype Alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9196–9205. [Google Scholar]
- Yavariabdi, A.; Kusetogullari, H.; Cicek, H. UAV detection in airborne optic videos using dilated convolutions. J. Opt.-India 2021, 50, 569–582. [Google Scholar] [CrossRef]
- Yavariabdi, A.; Kusetogullari, H.; Celik, T.; Cicek, H. FastUAV-NET: A Multi-UAV Detection Algorithm for Embedded Platforms. Electronics 2021, 10, 724. [Google Scholar] [CrossRef]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Li, D.; Li, J.; Nie, B.; Sun, S. Deconvolution single shot multibox detector for supermarket commodity detection and classification. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP 2017), Hong Kong, China, 19–22 May 2017; p. 104202R. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lao, D.; Sundaramoorthi, G. Minimum Delay Object Detection From Video. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5096–5105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Cham, Switzerland, 6–7 September 2014; pp. 818–833. [Google Scholar]
- Lyu, Y.; Yang, M.Y.; Vosselman, G.; Xia, G.S. Video object detection with a convolutional regression tracker. Isprs J. Photogramm. Remote Sens. 2021, 176, 139–150. [Google Scholar] [CrossRef]
- Sabater, A.; Montesano, L.; Murillo, A.C. Robust and efficient post-processing for video object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10536–10542. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 11–14 October 2016; pp. 850–865. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Ustinova, E.; Lempitsky, V. Learning deep embeddings with histogram loss. arXiv 2016, arXiv:1611.00822. [Google Scholar]
- Zhang, Y.F.; Wang, C.Y.; Wang, X.G.; Zeng, W.J.; Liu, W.Y. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Yavariabdi, A.; Hall, J.; Lavesson, N. DIGITNET: A Deep Handwritten Digit Detection and Recognition Method Using a New Historical Handwritten Digit Dataset. Big Data Res. 2021, 23, 100182. [Google Scholar] [CrossRef]
- Qin, L.L.; Yu, N.W.; Zhao, D.H. Applying the Convolutional Neural Network Deep Learning Technology to Behavioural Recognition in Intelligent Video. Teh. Vjesn. 2018, 25, 528–535. [Google Scholar] [CrossRef] [Green Version]
- Mühling, M.; Korfhage, N.; Müller, E.; Otto, C.; Springstein, M.; Langelage, T.; Veith, U.; Ewerth, R.; Freisleben, B. Deep learning for content-based video retrieval in film and television production. Multimed. Tools Appl. 2017, 76, 22169–22194. [Google Scholar] [CrossRef]
- Hu, X.; Hu, S.Q.; Huang, Y.P.; Zhang, H.L.; Wu, H.B. Video anomaly detection using deep incremental slow feature analysis network. Iet Comput. Vis. 2016, 10, 258–267. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Shao, L. Video salient object detection via fully convolutional networks. IEEE Trans. Image Process. 2017, 27, 38–49. [Google Scholar] [CrossRef] [Green Version]
- Li, N.N.; Guo, H.W.; Zhao, Y.; Li, T.; Li, G. Active Temporal Action Detection in Untrimmed Videos via Deep Reinforcement Learning. IEEE Access 2018, 6, 59126–59140. [Google Scholar] [CrossRef]
- Protasov, S.; Khan, A.M.; Sozykin, K.; Ahmad, M. Using deep features for video scene detection and annotation. Signal Image Video Process. 2018, 12, 991–999. [Google Scholar] [CrossRef]
- Wang, X.; Ji, Q. Hierarchical Context Modeling for Video Event Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1770–1782. [Google Scholar] [CrossRef]
- Hu, L.; Hong, C.Q.; Zeng, Z.Q.; Wang, X.D. Two-stream person re-identification with multi-task deep neural networks. Mach. Vis. Appl. 2018, 29, 947–954. [Google Scholar] [CrossRef]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cao, W.M.; Yuan, J.H.; He, Z.H.; Zhang, Z.; He, Z.Q. Fast Deep Neural Networks With Knowledge Guided Training and Predicted Regions of Interests for Real-Time Video Object Detection. IEEE Access 2018, 6, 8990–8999. [Google Scholar] [CrossRef]
- Takahashi, N.; Gygli, M.; Van Gool, L. Aenet: Learning deep audio features for video analysis. IEEE Trans. Multimed. 2017, 20, 513–524. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.C.; Ranjan, R.; Sankaranarayanan, S.; Kumar, A.; Chen, C.H.; Patel, V.M.; Castillo, C.D.; Chellappa, R. Unconstrained Still/Video-Based Face Verification with Deep Convolutional Neural Networks. Int. J. Comput. Vis. 2018, 126, 272–291. [Google Scholar] [CrossRef]
- Zheng, K.; Yan, W.Q.; Nand, P. Video dynamics detection using deep neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 2, 224–234. [Google Scholar] [CrossRef]
- Hou, R.; Chen, C.; Shah, M. Tube convolutional neural network (T-CNN) for action detection in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 Octorber2017; pp. 5822–5831. [Google Scholar]
- Yao, Y.; Shi, Y.; Weng, S.; Guan, B. Deep Learning for Detection of Object-Based Forgery in Advanced Video. Symmetry 2017, 10, 3. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Ren, J.C.; Zhang, D.; Sun, M.J.; Jiang, J.M. A deep-learning based feature hybrid framework for spatiotemporal saliency detection inside videos. Neurocomputing 2018, 287, 68–83. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.; Chen, Q.Q. Learning an video frame-based face detection system for security fields. J. Vis. Commun. Image Represent. 2018, 55, 457–463. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion. IEEE Trans. Ind. Electron. 2017, 65, 4392–4400. [Google Scholar] [CrossRef]
- Li, L.; Hu, Q.; Li, X. Moving Object Detection in Video via Hierarchical Modeling and Alternating Optimization. IEEE Trans. Image Process. 2018, 28, 2021–2036. [Google Scholar] [CrossRef]
- Tao, H.; Lu, X. Automatic smoky vehicle detection from traffic surveillance video based on vehicle rear detection and multi-feature fusion. IET Intell. Transp. Syst. 2018, 13, 252–259. [Google Scholar] [CrossRef]
- Marceau, D.J.; Howarth, P.J.; Dubois, J.M.M.; Gratton, D.J. Evaluation of the Grey-Level Co-Occurrence Matrix Method for Land-Cover Classification Using Spot Imagery. IEEE Trans. Geosci. Remote Sens. 1990, 28, 513–519. [Google Scholar] [CrossRef]
- Shensa, M.J. The Discrete Wavelet Transform—Wedding the a Trous and Mallat Algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Bilal, M.; Hanif, M.S. High Performance Real-Time Pedestrian Detection Using Light Weight Features and Fast Cascaded Kernel SVM Classification. J. Signal Process. Syst. Signal Image Video Technol. 2019, 91, 117–129. [Google Scholar] [CrossRef]
- Ma, M.; Marturi, N.; Li, Y.B.; Leonardis, A.; Stolkin, R. Region-sequence based six-stream CNN features for general and fine-grained human action recognition in videos. Pattern Recognit. 2018, 76, 506–521. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Nascimento, J.C.; Marques, J.S. Performance evaluation of object detection algorithms for video surveillance. IEEE Trans. Multimed. 2006, 8, 761–774. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Multiplier Networks for Video Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar]
- Liu, Z.; Yeh, R.A.; Tang, X.; Liu, Y.; Agarwala, A. Video Frame Synthesis Using Deep Voxel Flow. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4473–4481. [Google Scholar]
- Zhu, X.; Jing, X.Y.; You, X.; Zhang, X.; Zhang, T. Video-based Person Re-identification by Simultaneously Learning Intra-video and Inter-video Distance Metrics. IEEE Trans. Image Process. 2018, 27, 5683–5695. [Google Scholar] [CrossRef]
- Denton, E.L. Unsupervised learning of disentangled representations from video. arXiv 2017, arXiv:1705.10915. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Shafiee, M.J.; Chywl, B.; Li, F.; Wong, A. Fast YOLO: A fast you only look once system for real-time embedded object detection in video. arXiv 2017, arXiv:1709.05943. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceeding of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Yorozu, Y.; Hirano, M.; Oka, K.; Tagawa, Y. Binarized normed gradients for objectness estimation. Comput. Vis. Pattern Recognit. 2014, 2014, 3286–3293. [Google Scholar]
- Galteri, L.; Seidenari, L.; Bertini, M.; Bimbo, A.D. Spatio-Temporal Closed-Loop Object Detection. IEEE Trans. Image Process. 2017, 26, 1253–1263. [Google Scholar] [CrossRef]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual Tracking with Fully Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Yuan, Y.; Xiong, Z.; Wang, Q. An incremental framework for video-based traffic sign detection, tracking, and recognition. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1918–1929. [Google Scholar] [CrossRef]
- Deng, H.; Hua, Y.; Song, T.; Zhang, Z.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Object Guided External Memory Network for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 6677–6686. [Google Scholar]
- Chen, X.; Wu, Z.; Yu, J.; Wen, L. Rethinking Temporal Object Detection from Robotic Perspectives. arXiv 2019, arXiv:1912.10406. [Google Scholar]
- Bengar, J.Z.; Gonzalez-Garcia, A.; Villalonga, G.; Raducanu, B.; Aghdam, H.H.; Mozerov, M.; Lopez, A.M.; Weijer, J.v.d. Temporal Coherence for Active Learning in Videos. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 914–923. [Google Scholar]
- Yang, X.; Mirmehdi, M.; Burghardt, T. Great Ape Detection in Challenging Jungle Camera Trap Footage via Attention-Based Spatial and Temporal Feature Blending. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 255–262. [Google Scholar]
- Banerjee, S.; VidalMata, R.G.; Wang, Z.; Scheirer, W.J. Report on UG2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms. arXiv 2019, arXiv:1907.11529. [Google Scholar] [CrossRef]
- Luo, H.; Huang, L.; Shen, H.; Li, Y.; Huang, C.; Wang, X. Object Detection in Video with Spatial-temporal Context Aggregation. arXiv 2019, arXiv:1907.04988. [Google Scholar]
- Shankar, V.; Dave, A.; Roelofs, R.; Ramanan, D.; Recht, B.; Schmidt, L. Do Image Classifiers Generalize Across Time? arXiv 2019, arXiv:1906.02168. [Google Scholar]
- Wang, T.; Xiong, J.; Xu, X.; Shi, Y. Scnn: A general distribution based statistical convolutional neural network with application to video object detection. arXiv 2019, arXiv:1903.07663. [Google Scholar] [CrossRef] [Green Version]
- Chin, T.-W.; Ding, R.; Marculescu, D. Adascale: Towards real-time video object detection using adaptive scaling. arXiv 2019, arXiv:1902.02910. [Google Scholar]
- Kumar, A.R.; Ravindran, B.; Raghunathan, A. Pack and detect: Fast object detection in videos using region-of-interest packing. arXiv 2018, arXiv:1809.01701. [Google Scholar]
- Han, W.; Khorrami, P.; Paine, T.L.; Ramachandran, P.; Babaeizadeh, M.; Shi, H.; Li, J.; Yan, S.; Huang, T.S. Seq-nms for video object detection. arXiv 2016, arXiv:1602.08465. [Google Scholar]
- Chen, K.; Wang, J.; Yang, S.; Zhang, X.; Xiong, Y.; Loy, C.C.; Lin, D. Optimizing Video Object Detection via a Scale-Time Lattice. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7814–7823. [Google Scholar]
- Pouyanfar, S.; Chen, S.C. Automatic Video Event Detection for Imbalance Data Using Enhanced Ensemble Deep Learning. Int. J. Semant. Comput. 2017, 11, 85–109. [Google Scholar] [CrossRef]
- Luo, H.; Xie, W.; Wang, X.; Zeng, W. Detect or track: Towards cost-effective video object detection/tracking. arXiv 2018, arXiv:1811.05340. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-Guided Feature Aggregation for Video Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Lu, C.; Tang, C.K. Online Video Object Detection Using Association LSTM. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2363–2371. [Google Scholar]
- Yuan, Y.; Liang, X.; Wang, X.; Yeung, D.Y.; Gupta, A. Temporal Dynamic Graph LSTM for Action-Driven Video Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1819–1828. [Google Scholar]
- Zhu, M.; Liu, M. Mobile Video Object Detection with Temporally-Aware Feature Maps. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5686–5695. [Google Scholar]
- Chai, Y. Patchwork: A Patch-Wise Attention Network for Efficient Object Detection and Segmentation in Video Streams. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 3414–3423. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Gu, J.; Zhang, Q.; Xiang, S.; Prinet, V.; Pan, C. Progressive Sparse Local Attention for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 3908–3917. [Google Scholar]
- Zhu, X.; Dai, J.; Zhu, X.; Wei, Y.; Yuan, L. Towards high performance video object detection for mobiles. arXiv 2018, arXiv:1804.05830. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Häusser, P.; Hazirbas, C.; Golkov, V.; Smagt, P.v.d.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Mobilenets, H.A. Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Jiang, Z.; Liu, Y.; Yang, C.; Liu, J.; Gao, P.; Zhang, Q.; Xiang, S.; Pan, C. Learning Where to Focus for Efficient Video Object Detection. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 18–34. [Google Scholar]
- Yin, J.; Shen, J.; Guan, C.; Zhou, D.; Yang, R. LiDAR-Based Online 3D Video Object Detection With Graph-Based Message Passing and Spatiotemporal Transformer Attention. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11492–11501. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Liu, M.; Zhu, M.; White, M.; Li, Y.; Kalenichenko, D. Looking fast and slow: Memory-guided mobile video object detection. arXiv 2019, arXiv:1903.10172. [Google Scholar]
- Zhang, C.; Kim, J. Video Object Detection With Two-Path Convolutional LSTM Pyramid. IEEE Access 2020, 8, 151681–151691. [Google Scholar] [CrossRef]
- Xiao, F.; Jae Lee, Y. Video object detection with an aligned spatial-temporal memory. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 485–501. [Google Scholar]
- Kombrink, S.; Mikolov, T.; Karafiát, M.; Burget, L. Recurrent neural network based language modeling in meeting recognition. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Kang, K.; Li, H.; Xiao, T.; Ouyang, W.; Yan, J.; Liu, X.; Wang, X. Object Detection in Videos with Tubelet Proposal Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 889–897. [Google Scholar]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep Feature Flow for Video Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4141–4150. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards High Performance Video Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Wang, S.; Zhou, Y.; Yan, J.; Deng, Z. Fully motion-aware network for video object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 542–557. [Google Scholar]
- Wang, X.G.; Huang, Z.J.; Liao, B.C.; Huang, L.C.; Gong, Y.C.; Huang, C. Real-time and accurate object detection in compressed video by long short-term feature aggregation. Comput. Vis. Image Underst. 2021, 206, 103188. [Google Scholar] [CrossRef]
- Joe Yue-Hei, N.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Ye, H.; Wu, Z.; Zhao, R.-W.; Wang, X.; Jiang, Y.-G.; Xue, X. Evaluating two-stream CNN for video classification. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 435–442. [Google Scholar]
- Wu, Z.; Wang, X.; Jiang, Y.-G.; Ye, H.; Xue, X. Modeling spatial-temporal clues in a hybrid deep learning framework for video classification. In Proceedings of the 23rd ACM International Conference on Multimedia, New York, NY, USA, 26–30 October 2015; pp. 461–470. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to Track and Track to Detect. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3057–3065. [Google Scholar]
- Pan, B.; Lin, W.; Fang, X.; Huang, C.; Zhou, B.; Lu, C. Recurrent Residual Module for Fast Inference in Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1536–1545. [Google Scholar]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Zhang, Z.; Cheng, D.; Zhu, X.; Lin, S.; Dai, J. Integrated object detection and tracking with tracklet-conditioned detection. arXiv 2018, arXiv:1811.11167. [Google Scholar]
- Deng, J.; Pan, Y.; Yao, T.; Zhou, W.; Li, H.; Mei, T. Relation Distillation Networks for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 7022–7031. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Shvets, M.; Liu, W.; Berg, A. Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 9755–9763. [Google Scholar]
- Wu, H.; Chen, Y.; Wang, N.; Zhang, Z.X. Sequence Level Semantics Aggregation for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 9216–9224. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W. The epic-kitchens dataset: Collection, challenges and baselines. IEEE Comput. Archit. Lett. 2020, 43, 4125–4141. [Google Scholar] [CrossRef]
- Liu, W.; Kang, G.; Huang, P.-Y.; Chang, X.; Qian, Y.; Liang, J.; Gui, L.; Wen, J.; Chen, P. Argus: Efficient activity detection system for extended video analysis. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshops, Snowmass, CO, USA, 1–5 March 2020; pp. 126–133. [Google Scholar]
- Chen, Y.; Cao, Y.; Hu, H.; Wang, L. Memory Enhanced Global-Local Aggregation for Video Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10334–10343. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 7082–7092. [Google Scholar]
- Goldberg, K.; Roeder, T.; Gupta, D.; Perkins, C. Eigentaste: A constant time collaborative filtering algorithm. Inf. Retr. 2001, 4, 133–151. [Google Scholar] [CrossRef]
- Beery, S.; Wu, G.; Rathod, V.; Votel, R.; Huang, J. Long term temporal context for per-camera object detection. arXiv 2019, arXiv:1912.03538. [Google Scholar]
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beery, S.; Van Horn, G.; Mac Aodha, O.; Perona, P. The iwildcam 2018 challenge dataset. arXiv 2019, arXiv:1904.05986. [Google Scholar]
- Zhang, S.; Wu, G.; Costeira, J.P.; Moura, J.M.F. Understanding Traffic Density from Large-Scale Web Camera Data. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4264–4273. [Google Scholar]
- Perreault, H.; Héritier, M.; Gravel, P.; Bilodeau, G.-A.; Saunier, N. RN-VID: A Feature Fusion Architecture for Video Object Detection. arXiv 2020, arXiv:2003.10898. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.-C.; Qi, H.; Lim, J.; Yang, M.-H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. arXiv 2015, arXiv:1511.04136. [Google Scholar] [CrossRef] [Green Version]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Lyu, Y.; Yang, M.Y.; Vosselman, G.; Xia, G.-S. Plug & Play Convolutional Regression Tracker for Video Object Detection. arXiv 2020, arXiv:2003.00981. [Google Scholar]
- Xu, D.; Xie, W.; Zisserman, A. Geometry-Aware Video Object Detection for Static Cameras. arXiv 2019, arXiv:1909.03140. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. arXiv 2017, arXiv:1711.03938. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. arXiv 2016, arXiv:1609.01775. [Google Scholar]
- Tang, P.; Wang, C.; Wang, X.; Liu, W.; Zeng, W.; Wang, J. Object Detection in Videos by High Quality Object Linking. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1272–1278. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Gao, J.; Mao, J.; Liu, Y.; Anguelov, D.; Li, C. STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11343–11352. [Google Scholar]
- Jiao, Y.; Yao, H.; Xu, C. PEN: Pose-embedding network for pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1150–1162. [Google Scholar] [CrossRef]
- Cores, D.; Brea, V.M.; Mucientes, M. Short-term anchor linking and long-term self-guided attention for video object detection. Image Vis. Comput. 2021, 110, 104179. [Google Scholar] [CrossRef]
- Kang, K.; Ouyang, W.; Li, H.; Wang, X. Object Detection from Video Tubelets with Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 81–825. [Google Scholar]
- Mao, H.; Yang, X.; Dally, B. A Delay Metric for Video Object Detection: What Average Precision Fails to Tell. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 Octorber–2 November 2019; pp. 573–582. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Hu, Q.; Ling, H. Vision Meets Drones: Past, Present and Future. arXiv 2020, arXiv:2001.06303. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 791–798. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ngiam, J.; Chen, Z.; Koh, P.W.; Ng, A.Y. Learning deep energy models. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, WA, USA, 28 June–2 July 2011; pp. 1105–1112. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Washington, WA, USA, 28 June–2 July 2011; pp. 833–840. [Google Scholar]
- Jin, Z.; Lou, Z.; Yang, J.Y.; Sun, Q.S. Face detection using template matching and skin-color information. Neurocomputing 2007, 70, 794–800. [Google Scholar] [CrossRef]
- Wang, J.; Yang, H. Face detection based on template matching and 2DPCA algorithm. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; pp. 575–579. [Google Scholar]
- Cox, I.J.; Ghosn, J.; Yianilos, P.N. Feature-based face recognition using mixture-distance. In Proceedings of the CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 209–216. [Google Scholar]
- Yow, K.C.; Cipolla, R. Feature-based human face detection. Image Vis. Comput. 1997, 15, 713–735. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2299–2308. [Google Scholar]
- Gross, R.; Matthews, I.; Baker, S. Appearance-based face recognition and light-fields. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 449–465. [Google Scholar] [CrossRef]
- Turk, M.A.; Pentland, A.P. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991; pp. 586–591. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, L. Gabor feature based sparse representation for face recognition with gabor occlusion dictionary. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 448–461. [Google Scholar]
- Huang, D.; Ardabilian, M.; Wang, Y.H.; Chen, L.M. 3-D Face Recognition Using eLBP-Based Facial Description and Local Feature Hybrid Matching. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1551–1565. [Google Scholar] [CrossRef] [Green Version]
- Smith, A. Sequential Monte Carlo Methods in Practice; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Wang, H.; Stone, H.; Chang, S.-F. FaceTrack: Tracking and Summarizing Faces from Compressed Video. In Proceedings of the Multimedia Storage and Archiving Systems IV, Boston, MA, USA, 20–22 September 1999; Volume 3846. [Google Scholar]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar] [CrossRef]
- Fu, J.C.; Lien, H.C.; Wong, S.T. Wavelet-based histogram equalization enhancement of gastric sonogram images. Comput. Med. Imaging Graph 2000, 24, 59–68. [Google Scholar] [CrossRef]
- Anwar, M.I.; Khosla, A. Vision enhancement through single image fog removal. Eng. Sci. Technol. Int. J. Jestech 2017, 20, 1075–1083. [Google Scholar] [CrossRef]
- Aghito, S.M.; Forchhammer, S. Context-based coding of bilevel images enhanced by digital straight line analysis. IEEE Trans. Image Process. 2006, 15, 2120–2130. [Google Scholar] [CrossRef]
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Convolution Kernel | Stride | Output | |
|---|---|---|---|---|
| Conv. | 32 | 3 × 3 | 224 × 224 | |
| Maxpool | 2 × 2 | 2 | 112 × 112 | |
| Conv. | 64 | 3 × 3 | 112 × 112 | |
| Maxpool | 2 × 2 | 2 | 56 × 56 | |
| Conv. | 128 | 3 × 3 | 56 × 56 | |
| Conv. | 64 | 1 × 1 | 56 × 56 | |
| Conv. | 128 | 3 × 3 | 56 × 56 | |
| Maxpool | 2 × 2 | 2 | 28 × 28 | |
| Conv. | 256 | 3 × 3 | 28 × 28 | |
| Conv. | 128 | 1 × 1 | 28 × 28 | |
| Conv. | 256 | 3 × 3 | 28 × 28 | |
| Maxpool | 2 × 2 | 2 | 14 × 14 | |
| Conv. | 512 | 3 × 3 | 14 × 14 | |
| Conv. | 256 | 1 × 1 | 14 × 14 | |
| Conv. | 512 | 3 × 3 | 14 × 14 | |
| Conv. | 256 | 1 × 1 | 14 × 14 | |
| Conv. | 512 | 3 × 3 | 14 × 14 | |
| Maxpool | 2 × 2 | 2 | 7 × 7 | |
| Conv. | 1024 | 3 × 3 | 7 × 7 | |
| Conv. | 512 | 1 × 1 | 7 × 7 | |
| Conv. | 1024 | 3 × 3 | 7 × 7 | |
| Conv. | 512 | 1 × 1 | 7 × 7 | |
| Conv. | 1024 | 3 × 3 | 7 × 7 | |
| Conv. | 1000 | 1 × 1 | 7 × 7 | |
| Averagepool | Global | 1000 | ||
| Softmax |
| Algorithm | Category | Dataset | Results |
|---|---|---|---|
| AlexNet | image detection | 2012 ImageNet Classification Challenge | Champion |
| FCN | image segmentation | VOC2011, VOC2012 | mean IU: more than 62.0% |
| YOLOv1 | video detection | VOC2007 and 2012 | mAP: 63.4%, FPS: 45 |
| YOLOv2 | video detection | VOC2007 and 2012 | mAP: 78.6%, FPS: 40 |
| YOLOv3 | video detection | COCO | mAP-50: 57.9%, Inference time: 51 ms |
| SSD | image detection | VOC2007 | mAP: 72.1%, FPS: 58 |
| DSSD | image detection | VOC2007 and 2012 | mAP: more than 80.0% |
| RSSD | image detection | VOC2007 and 2012 | mAP: 80.8% |
| FSSD | image detection | VOC2007 and 2012 | mAP: 84.5%, FPS: 35.7 |
| FPN | image detection | COCO mini-val set | AP at 0.5 IOU: 56.9% |
| Algorithm | Dataset | Results | Note |
|---|---|---|---|
| R-CNN | VOC2007 | mAP: 66% | |
| SPP Net | VOC2007, ILSVRC 2014 | mAP: 60.9%(VOC), 2nd(ILSVRC) | Input image of any size |
| Fast R-CNN | VOC 2007 and 2012 | mAP: 70% | Training and testing time reduced |
| Faster R-CNN | VOC 2007 and 2012 | mAP: 73.2% | Input image of any size |
| ResNet-101 | COCO VOC 2007 and 2012 ILSVRC 2015 | mAP: 48.4% mAP: 76.4% champion | |
| GoogLeNet | ILSVRC 2014 ImageNet | champion Top-5 error: 3.8%(Inception-v4) | |
| Mask R-CNN | COCO | 50% IoU Keypoint, AP: 87.3% |
| Algorithm | Dataset | Results |
|---|---|---|
| 3D Convolution | TRECVID KTH | AP: 0.7137 accuracy: 90.2% |
| T-CNN (Kang et al.) | ILSVRC2015 | Champion |
| TCN (Bai et al.) | Sequential MNIST Permuted MNIST | accuracy: 99% accuracy: 97.2% |
| DFF | ImageNet VID Cityscapes | mAP: 73.1% mIoU: 69.2% |
| FGFA | ImageNet VID | mAP: 83.5% |
| Association LSTM | Youtube-Objects | mAP: 72.14% |
| STMN | ImageNet VID | mAP: 80.5% |
| MANet | ImageNet VID | mAP: 86.9% |
| D&T | ImageNet VID | mAP: 79.8% |
| ST-Lattice | ImageNet VID | mAP: 79.0%, FPS: 62 |
| TD-Graph LSTM | Charades | mAP: 19.52% |
| STSN | ImageNet VID | mAP: 80.4% |
| Patchwork | ImageNet VID | mAP: 58.7% |
| PSLA | ImageNet VID | mAP: 81.4% |
| RDN | ImageNet VID | mAP: 84.7% |
| LSTS | ImageNet VID | mAP: 82.1% |
| SELSA | ImageNet VID | mAP: 86.91% |
| MEGA | ImageNet VID | mAP: 85.4% |
| TSM | Kinetics UCF101 HMDB51 Something-Something ImageNet VID | accuracy: 74.1% accuracy: 95.9% accuracy: 73.5% accuracy: 47.3% mAP: 83.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Wang, R.; Chen, P.; Xie, C.; Zhou, Q.; Jia, X. Visual Feature Learning on Video Object and Human Action Detection: A Systematic Review. Micromachines 2022, 13, 72. https://doi.org/10.3390/mi13010072
Li D, Wang R, Chen P, Xie C, Zhou Q, Jia X. Visual Feature Learning on Video Object and Human Action Detection: A Systematic Review. Micromachines. 2022; 13(1):72. https://doi.org/10.3390/mi13010072
Chicago/Turabian StyleLi, Dengshan, Rujing Wang, Peng Chen, Chengjun Xie, Qiong Zhou, and Xiufang Jia. 2022. "Visual Feature Learning on Video Object and Human Action Detection: A Systematic Review" Micromachines 13, no. 1: 72. https://doi.org/10.3390/mi13010072