Evaluation of Statistical Treatment of Left-Censored Contamination Data: Example Involving Deoxynivalenol Occurrence in Pasta and Pasta Substitute Products

 , ,
, ,
Abstract
:1. Introduction
2. Results
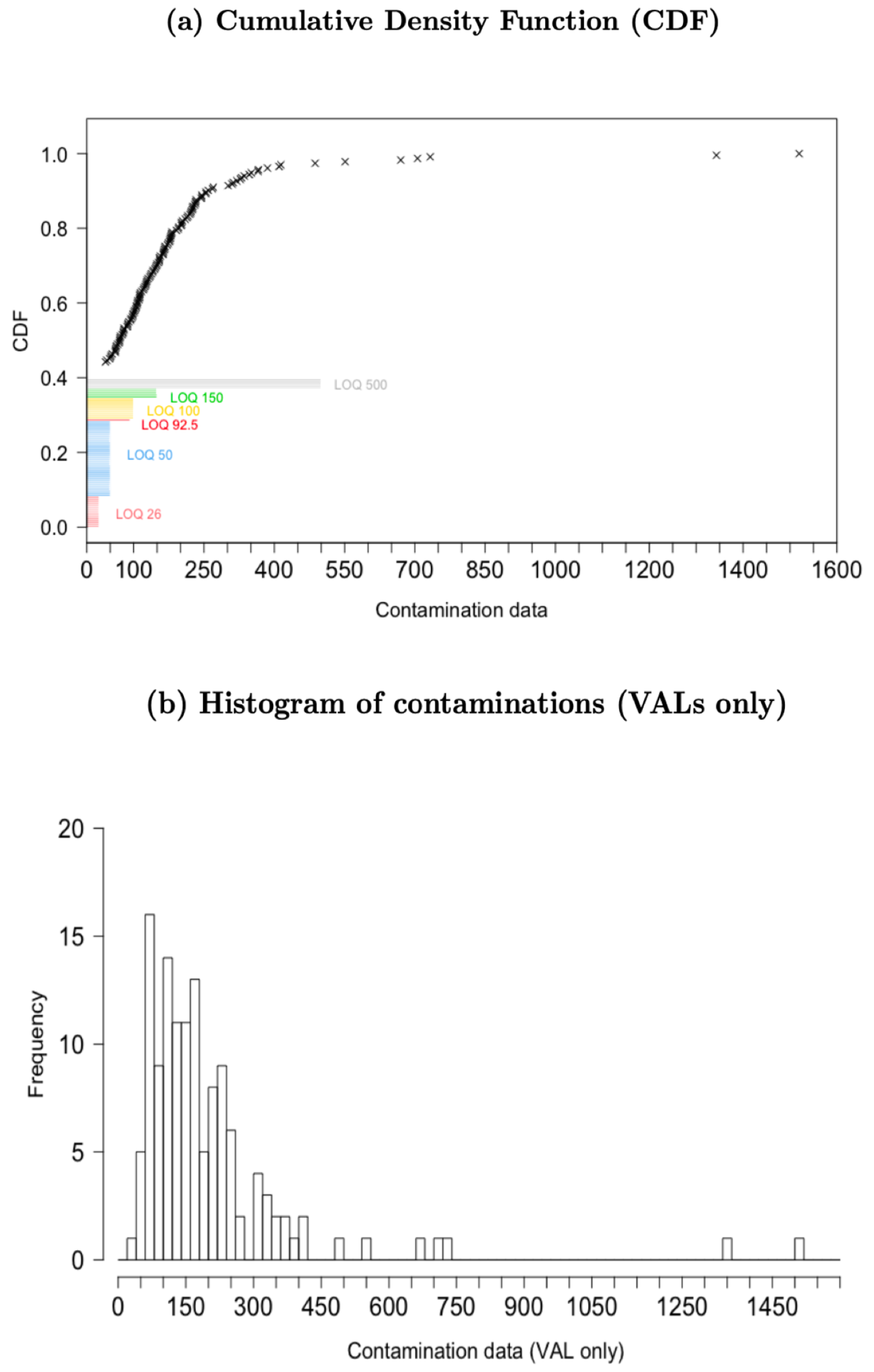
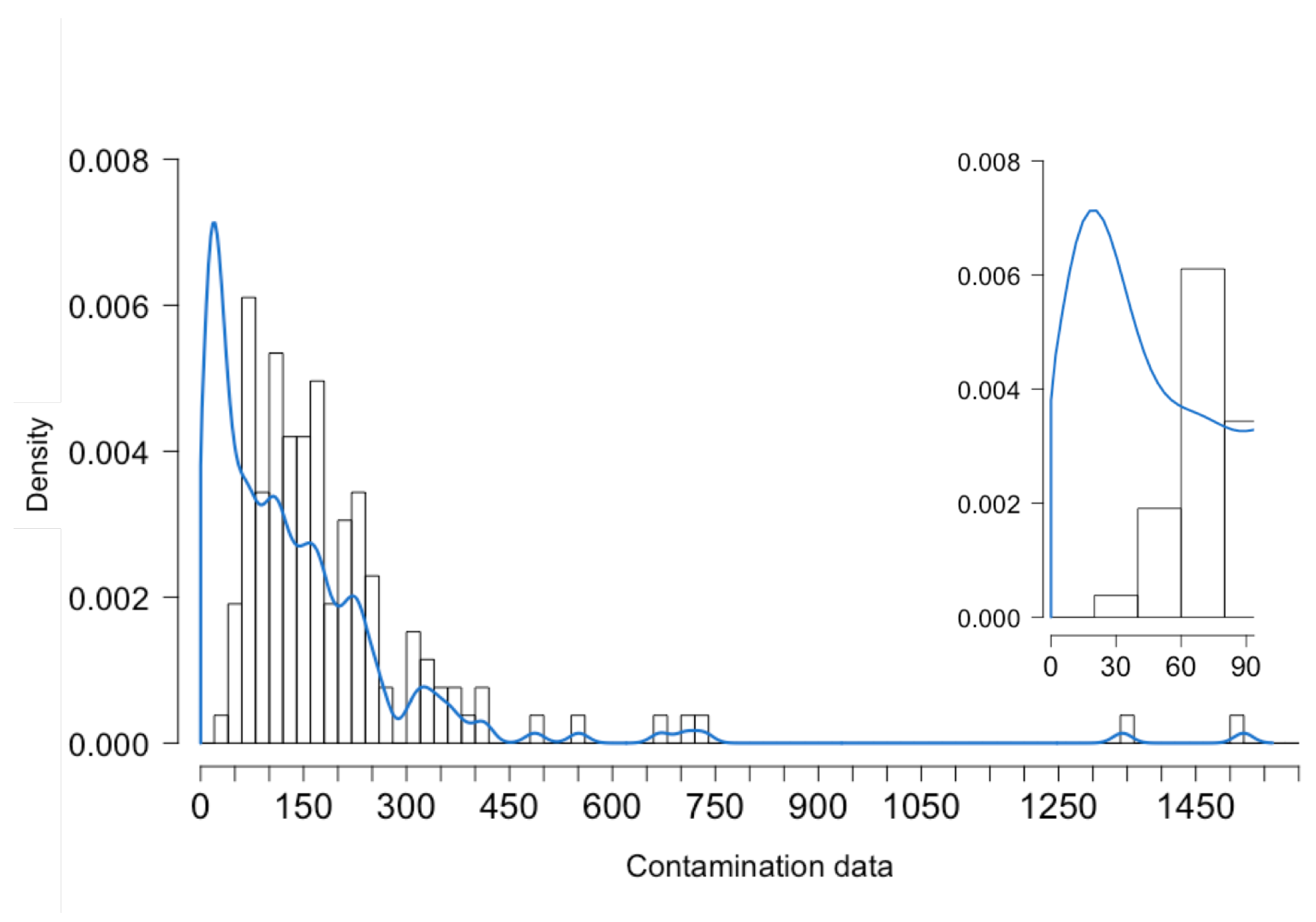
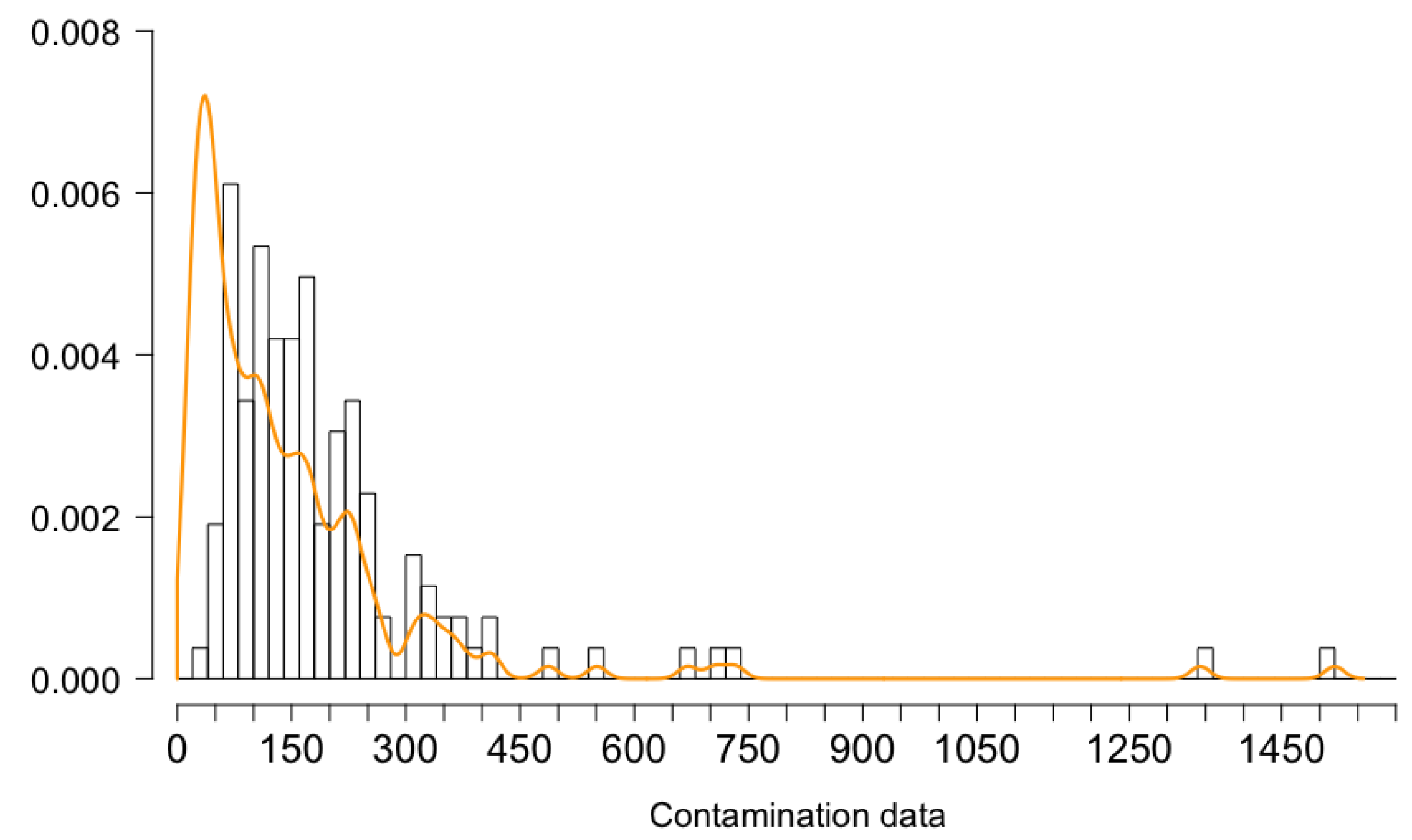
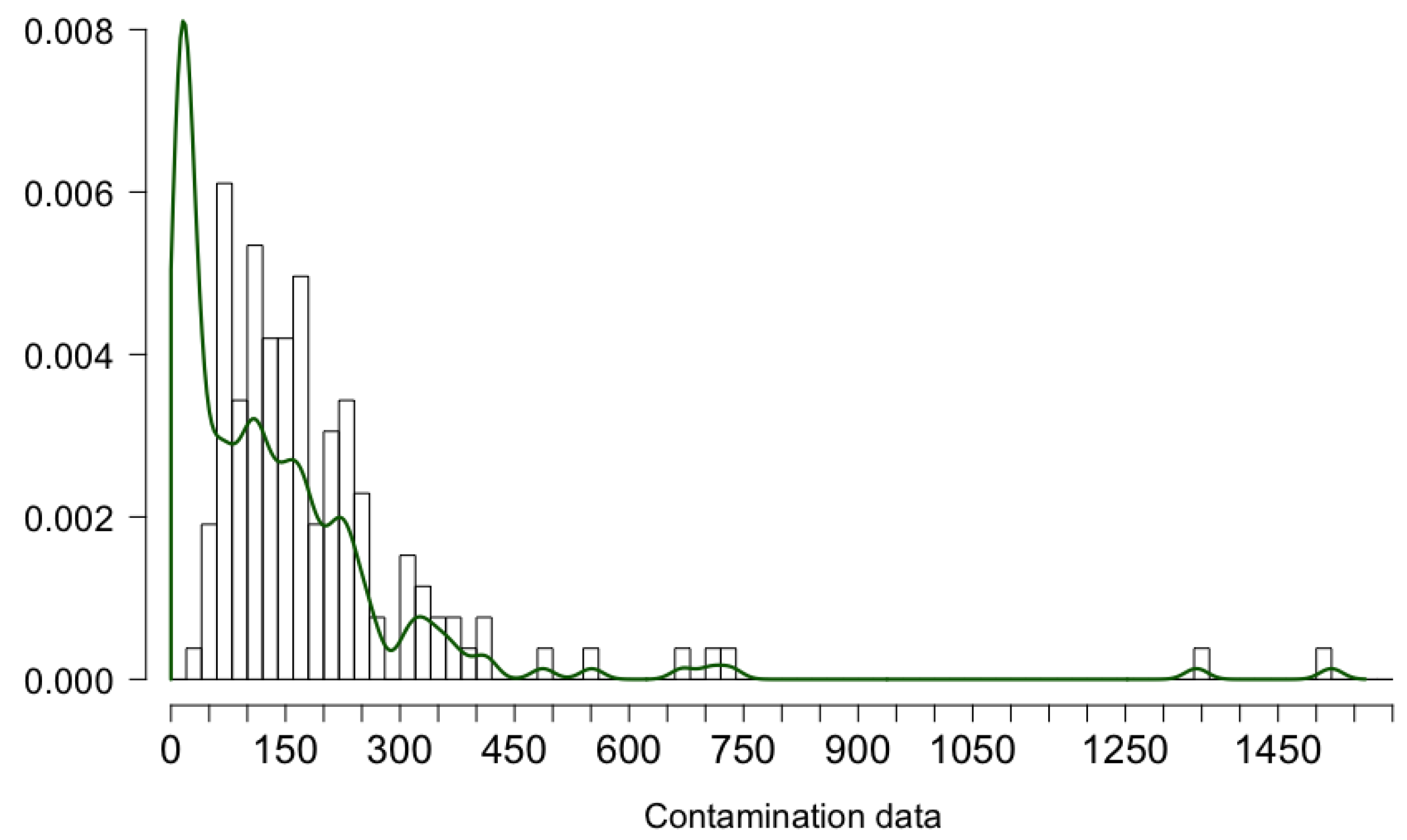
2.1. Exploratory Statistics
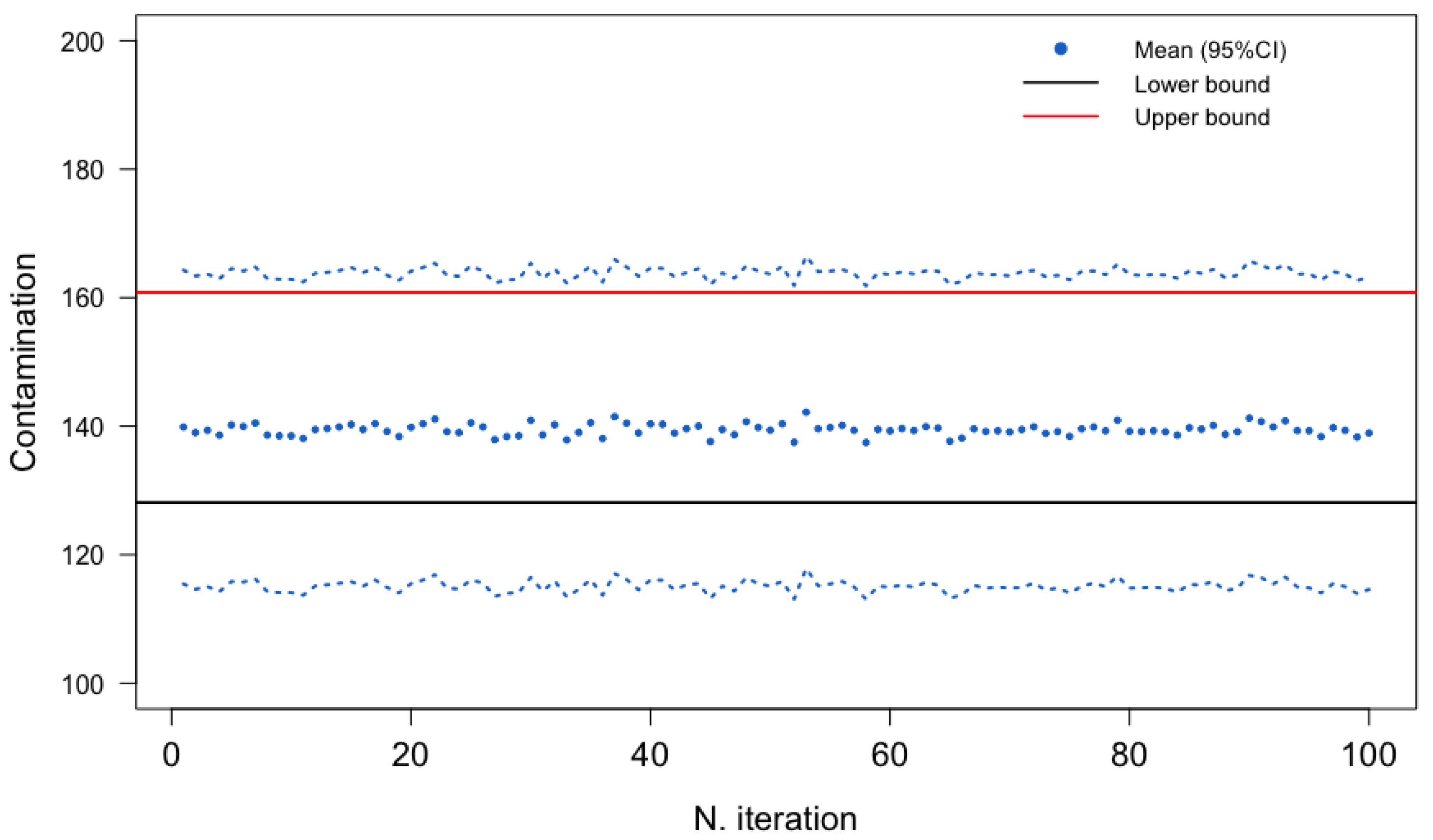
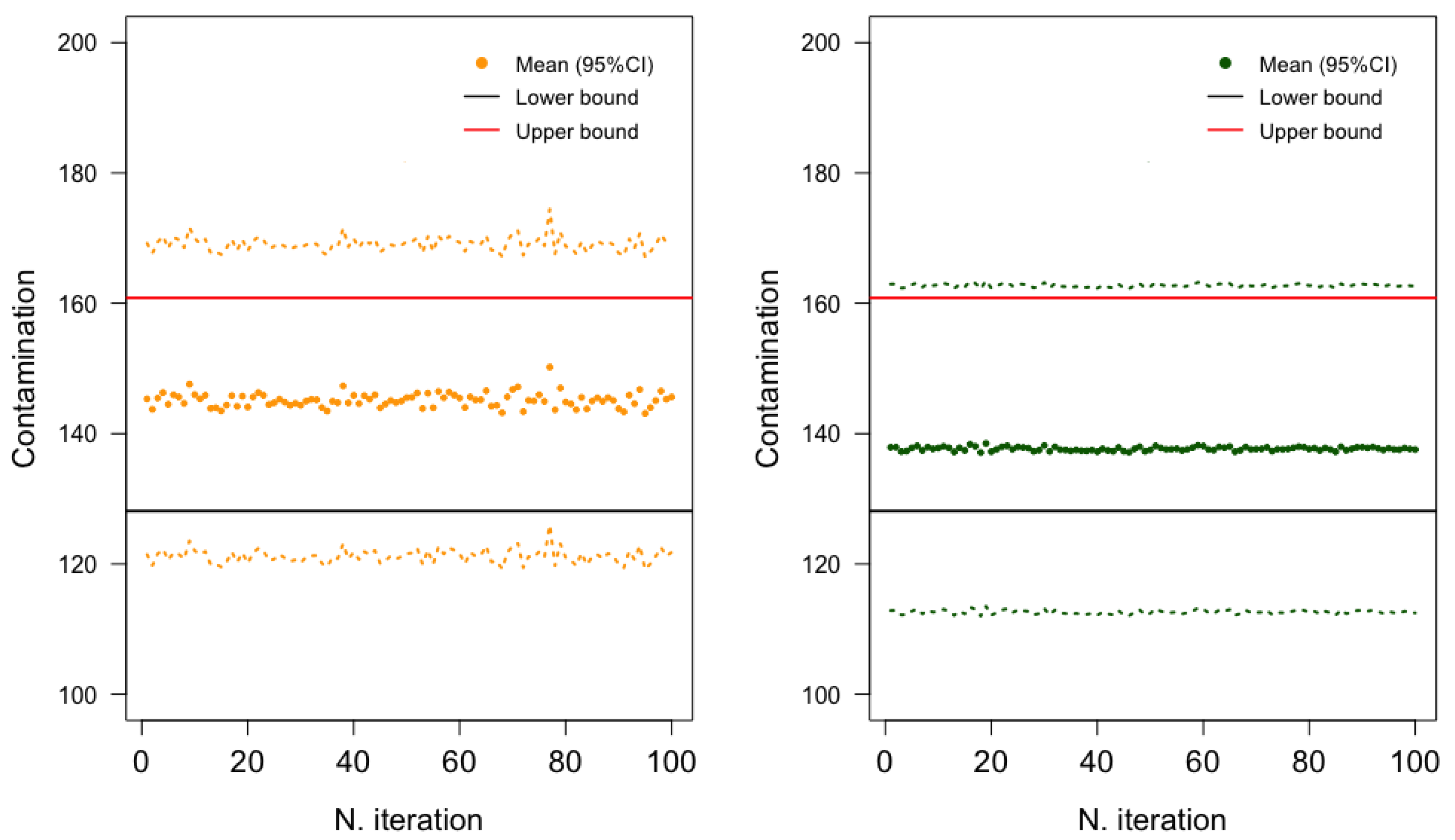
2.2. Comparing Stochastic and Deterministic Methods
3. Discussion
The Best Stochastic Procedure
4. Conclusions
5. Materials and Methods
5.1. Occurrence Data
5.2. The Proposed Stochastic Approach
- Consider a (possibly wide) family of candidate distributions;
- Estimate parameters for each candidate distribution;
- Assess the quality of fit and select the best distribution in terms of fit;
- Model-average the candidate distributions with weights proportional to penalized likelihood criteria;
- Impute non-detected values (three techniques) by drawing several (i.e., 100) values from the model-averaged distribution for each non-detected value.
- STEP 1. Specify the (possibly wide) family of candidate distributions
- STEP 2. Estimate parameters for each candidate distribution
- STEP 3. Assessing the quality of fit and selecting the best distribution in terms of fit
- STEP 4. Model averaging
- STEP 5. Impute non-detected values (All, Gold-Standard, Single)
- Procedure 1 (All).
- Procedure 2 (Gold-Standard).
- Procedure 3 (Single).
5.3. Comparison between Deterministic Substitution Methods and Stochastic Approaches
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| iid | Independent and identically distributed |
| MLE | Maximum likelihood estimation |
| LOD | Limit of detection |
| LOQ | Limit of quantification |
| VAL | Detected values |
| CP | Control plan |
| DON | Deoxynivalenol |
| CDF | Cumulative density function |
| AIC | Akaike information criterion |
| MA | Model averaging |
| MI | Multiple imputation |
| UB | Upper bound |
| LB | Lower bound |
Appendix A


References
- Keith, L.H.; Crummett, W.; Deegan, J.; Libby, R.A.; Taylor, J.K.; Wentler, G. Principles of environmental analysis. Anal. Chem. 1983, 55, 2210–2218. [Google Scholar] [CrossRef]
- Girard, J. Principles of Environmental Chemistry; Jones & Bartlett Publishers: Burlington, MA, USA, 2013; ISBN 1449693520. [Google Scholar]
- MacDougall, D.; Crummett, W.B. Guidelines for data acquisition and data quality evaluation in environmental chemistry. Anal. Chem. 1980, 52, 2242–2249. [Google Scholar] [CrossRef]
- Armbruster, D.A.; Pry, T. Limit of blank, limit of detection and limit of quantitation. Clin. Biochem. Rev. 2008, 29, S49. [Google Scholar]
- Wenzl, T.; Haedrich, J.; Schaechtele, A.; Piotr, R.; Stroka, J.; Eppe, G.; Scholl, G. Guidance Document on the Estimation of LOD and LOQ for Measurements in the Field of Contaminants in Food and Feed; Publications Office of the European Union: Luxembourg, 2016. [Google Scholar]
- EFSA Panel on Contaminants in the Food Chain. Management of left-censored data in dietary exposure assessment of chemical substances. EFSA J. 2010, 8, 1557. [Google Scholar]
- Joint FAO/WHO Expert Meeting on Dietary Exposure Assessment Methodologies for Residues of Veterinary Drugs. In Proceedings of the Project to Review and Update the Principles and Methodology to Assess Dietary Exposure to Residues of Veterinary Drugs, Rome, Italy, 7–11 November 2011.
- Hornung, R.W.; Reed, L.D. Estimation of average concentration in the presence of nondetectable values. Appl. Occup. Environ. Hyg. 1990, 5, 46–51. [Google Scholar] [CrossRef]
- Glass, D.C.; Gray, C.N. Estimating mean exposures from censored data: Exposure to benzene in the Australian petroleum industry. Ann. Occup. Hyg. 2001, 45, 275–282. [Google Scholar] [CrossRef]
- Ganser, G.H.; Hewett, P. An accurate substitution method for analyzing censored data. J. Occup. Environ. Hyg. 2010, 7, 233–244. [Google Scholar] [CrossRef]
- Helsel, D.R. Fabricating data: How substituting values for nondetects can ruin results, and what can be done about it. Chemosphere 2006, 65, 2434–2439. [Google Scholar] [CrossRef]
- Hwang, M.; Lee, S.C.; Park, J.H.; Choi, J.; Lee, H.J. Statistical methods for handling nondetected results in food chemical monitoring data to improve food risk assessments. Food Sci. Nutr. 2023, 1–13. [Google Scholar] [CrossRef]
- Jones, M.P. Linear regression with left-censored covariates and outcome using a pseudolikelihood approach. Environmetrics 2018, 29, e2536. [Google Scholar] [CrossRef]
- Kuiper-Goodman, T.; Hilts, C.; Billiard, S.; Kiparissis, Y.; Richard, I.; Hayward, S. Health risk assessment of ochratoxin A for all age-sex strata in a market economy. Food Addit. Contam. 2010, 27, 212–240. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, N.; Norwood, S.; Rock, J. A Strategy for Occupational Exposure Assessment; American Industrial Hygiene Association: Fairview, VA, USA, 1991; ISBN 0932627463. [Google Scholar]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1958, 53, 457–481. [Google Scholar] [CrossRef]
- Schmoyeri, R.; Beauchamp, J.; Brandt, C.; Hoffman, F. Difficulties with the lognormal model in mean estimation and testing. Environ. Ecol. Stat. 1996, 3, 81–97. [Google Scholar] [CrossRef]
- She, N. Analyzing censored water quality data using a non-parametric approach. JAWRA J. Am. Water Resour. Assoc. 1997, 33, 615–624. [Google Scholar] [CrossRef]
- Čonková, E.; Laciakova, A.; Kováč, G.; Seidel, H. Fusarial toxins and their role in animal diseases. Vet. J. 2003, 165, 214–220. [Google Scholar] [CrossRef] [PubMed]
- De Boevre, M.; Jacxsens, L.; Lachat, C.; Eeckhout, M.; Di Mavungu, J.D.; Audenaert, K.; Maene, P.; Haesaert, G.; Kolsteren, P.; De Meulenaer, B.; et al. Human exposure to mycotoxins and their masked forms through cereal-based foods in Belgium. Toxicol. Lett. 2013, 218, 281–292. [Google Scholar] [CrossRef]
- Sumarah, M.W. The deoxynivalenol challenge. J. Agric. Food Chem. 2022, 70, 9619–9624. [Google Scholar] [CrossRef]
- EFSA Panel on Contaminants in the Food Chain. Risks to human and animal health related to the presence of deoxynivalenol and its acetylated and modified forms in food and feed. EFSA J. 2017, 15, e04718. [Google Scholar]
- Klötzel, M.; Schmidt, S.; Lauber, U.; Thielert, G.; Humpf, H.U. Comparison of different clean-up procedures for the analysis of deoxynivalenol in cereal-based food and validation of a reliable HPLC method. Chromatographia 2005, 62, 41–48. [Google Scholar] [CrossRef]
- MacDonald, S.J.; Chan, D.; Brereton, P.; Damant, A.; Wood, R.; Dao Duy, K.; Felgueiras, I.; Feron, T.; Herry, M.; Ioannou-Kakouri, E.; et al. Determination of deoxynivalenol in cereals and cereal products by immunoaffinity column cleanup with liquid chromatography: Interlaboratory study. J. AOAC Int. 2005, 88, 1197–1204. [Google Scholar] [CrossRef]
- Sulyok, M.; Berthiller, F.; Krska, R.; Schuhmacher, R. Development and validation of a liquid chromatography/tandem mass spectrometric method for the determination of 39 mycotoxins in wheat and maize. Rapid Commun. Mass Spectrom. 2006, 20, 2649–2659. [Google Scholar] [CrossRef]
- Sulyok, M.; Krska, R.; Schuhmacher, R. A liquid chromatography/tandem mass spectrometric multi-mycotoxin method for the quantification of 87 analytes and its application to semi-quantitative screening of moldy food samples. Anal. Bioanal. Chem. 2007, 389, 1505–1523. [Google Scholar] [CrossRef]
- Varga, E.; Glauner, T.; Berthiller, F.; Krska, R.; Schuhmacher, R.; Sulyok, M. Development and validation of a (semi-) quantitative UHPLC-MS/MS method for the determination of 191 mycotoxins and other fungal metabolites in almonds, hazelnuts, peanuts and pistachios. Anal. Bioanal. Chem. 2013, 405, 5087–5104. [Google Scholar] [CrossRef]
- Malachová, A.; Sulyok, M.; Beltrán, E.; Berthiller, F.; Krska, R. Optimization and validation of a quantitative liquid chromatography–tandem mass spectrometric method covering 295 bacterial and fungal metabolites including all regulated mycotoxins in four model food matrices. J. Chromatogr. A 2014, 1362, 145–156. [Google Scholar] [CrossRef]
- De Santis, B.; Debegnach, F.; Gregori, E.; Russo, S.; Marchegiani, F.; Moracci, G.; Brera, C. Development of a LC-MS/MS method for the multi-mycotoxin determination in composite cereal-based samples. Toxins 2017, 9, 169. [Google Scholar] [CrossRef] [PubMed]
- Burnham, K.P. Model Selection and Multimodel Inference. A Practical Information-Theoretic Approach; Springer: New York, NY, USA, 2002. [Google Scholar]
- Hansen, M.H.; Kooperberg, C. Spline adaptation in extended linear models (with comments and a rejoinder by the authors. Stat. Sci. 2002, 17, 2–51. [Google Scholar] [CrossRef]
- Belov, D.I.; Armstrong, R.D. Distributions of the Kullback–Leibler divergence with applications. Br. J. Math. Stat. Psychol. 2011, 64, 291–309. [Google Scholar] [CrossRef] [PubMed]
- Paulo, M.J.; van der Voet, H.; Jansen, M.J.; ter Braak, C.J.; van Klaveren, J.D. Risk assessment of dietary exposure to pesticides using a Bayesian method. Pest Manag. Sci. Former. Pestic. Sci. 2005, 61, 759–766. [Google Scholar] [CrossRef]
- Shoari, N.; Dubé, J.S. Toward improved analysis of concentration data: Embracing nondetects. Environ. Toxicol. Chem. 2018, 37, 643–656. [Google Scholar] [CrossRef] [PubMed]
- Aitchison, J.; Brown, J.A.C. The Lognormal Distribution, with Special Reference to Its Uses in Economics; Cambridge University Press: Cambridge, UK, 1957; Volume 16, pp. 228–230. [Google Scholar]
- Shimizu, K. History, Genesis, and Properties, Chap. 1 in Lognormal Distributions: Theory and Applications; Crow, E.L., Shimizu, K., Eds.; CRC Press: Boca Raton, FL, USA, 1988; ISBN 9780367580278. [Google Scholar]
- Lee, E.T. Statistical Methods for Survival Data Analysis; Wiley: Hoboken, NJ, USA, 1992; ISBN 1118095022. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Beta distributions. Contin. Univariate Distrib. 1994, 2, 210–275. [Google Scholar]
- Hui, Y.H. Handbook of Food Science, Technology, and Engineering; CRC Press: Boca Raton, FL, USA, 2006; Volume 149, ISBN 9780849398476. [Google Scholar]
- Jongenburger, I.; Reij, M.; Boer, E.; Zwietering, M.; Gorris, L. Modelling homogeneous and heterogeneous microbial contaminations in a powdered food product. Int. J. Food Microbiol. 2012, 157, 35–44. [Google Scholar] [CrossRef] [PubMed]
- De Oliveira, T.L.C.; de Araújo Soares, R.; Piccoli, R.H. A Weibull model to describe antimicrobial kinetics of oregano and lemongrass essential oils against Salmonella Enteritidis in ground beef during refrigerated storage. Meat Sci. 2013, 93, 645–651. [Google Scholar] [CrossRef] [PubMed]
- Shoari, N.; Dubé, J.S. Estimating the mean and standard deviation of environmental data with below detection limit observations: Considering highly skewed data and model misspecification. Chemosphere 2015, 138, 599–608. [Google Scholar] [CrossRef] [PubMed]
- Ben-Israel, A. A Newton-Raphson method for the solution of systems of equations. J. Math. Anal. Appl. 1966, 15, 243–252. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Akaike, H. Information Theory and an Extension of the Maximum Likelihood Principle. In Proceedings of the International Symposium on Information Theory, Tsahkadsor, Armenia, 2–8 September 1971; Petrov, B.N., Csaki, F., Eds.; Akadémiai Kiadó: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detected | Non-Detected | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| LOQ (μg/kg) | n | % | Mean (μg/kg) | Median (μg/kg) | SD | n | % | n | % |
| 26 | 23 | 59.0 | 111.5 | 101.0 | 56.9 | 16 | 41.0 | 39 | 18.8 |
| 50 | 94 | 70.7 | 225.6 | 169.2 | 230.8 | 39 | 29.3 | 133 | 63.9 |
| 92.5 | 3 | 75.0 | 371.0 | 220.5 | 288.4 | 1 | 25.0 | 4 | 1.9 |
| 100 | 9 | 45.0 | 203.2 | 164.0 | 99.6 | 11 | 55.0 | 20 | 9.6 |
| 150 | 2 | 28.6 | 207.0 | 207.0 | 35.3 | 5 | 71.4 | 7 | 3.4 |
| 500 | 0 | 0.0 | - | - | - | 5 | 100.0 | 5 | 2.4 |
| CONTAMINATION VALUES | ||||||
|---|---|---|---|---|---|---|
| Procedure | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
| All | 0.3 | 29.7 | 98.9 | 139.4 | 180.1 | 1519.6 |
| Gold-standard | 5.1 | 44.0 | 101.0 | 145.3 | 181.0 | 1519.6 |
| Single | 0.4 | 20.1 | 98.9 | 137.7 | 181.0 | 1519.6 |
| LB | 0.0 | 0.0 | 94.2 | 128.1 | 178.9 | 1519.6 |
| UB | 26.0 | 50.0 | 108.2 | 160.8 | 195.2 | 1519.6 |
| Region | Production Method | LOQ | N. VAL | %VAL | N. LOQ |
|---|---|---|---|---|---|
| Basilicata | Unknown | 50 | 1 | 100 | 0 |
| 92.5 | 3 | 75 | 1 | ||
| Emilia Romagna | Non-organic production | 50 | 39 | 87 | 6 |
| Friulia-Venezia Giulia | Non-organic production | 100 | 8 | 73 | 3 |
| Lazio | Unknown | 26 | 23 | 59 | 16 |
| Liguria | Unknown | 50 | 2 | 67 | 1 |
| Lombardia | Organic production | 100 | 0 | 0 | 5 |
| Piemonte | Unknown | 50 | 2 | 50 | 2 |
| 500 | 0 | 0 | 5 | ||
| Puglia | Unknown | 50 | 50 | 63 | 30 |
| Sicilia | Unknown | 100 | 0 | 0 | 3 |
| Umbria | Unknown | 150 | 2 | 29 | 5 |
| Veneto | Unknown | 100 | 1 | 100 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feraldi, A.; De Santis, B.; Finocchietti, M.; Debegnach, F.; Mandile, A.; Alfò, M. Evaluation of Statistical Treatment of Left-Censored Contamination Data: Example Involving Deoxynivalenol Occurrence in Pasta and Pasta Substitute Products. Toxins 2023, 15, 521. https://doi.org/10.3390/toxins15090521
Feraldi A, De Santis B, Finocchietti M, Debegnach F, Mandile A, Alfò M. Evaluation of Statistical Treatment of Left-Censored Contamination Data: Example Involving Deoxynivalenol Occurrence in Pasta and Pasta Substitute Products. Toxins. 2023; 15(9):521. https://doi.org/10.3390/toxins15090521
Chicago/Turabian StyleFeraldi, Alessandro, Barbara De Santis, Marco Finocchietti, Francesca Debegnach, Antonio Mandile, and Marco Alfò. 2023. "Evaluation of Statistical Treatment of Left-Censored Contamination Data: Example Involving Deoxynivalenol Occurrence in Pasta and Pasta Substitute Products" Toxins 15, no. 9: 521. https://doi.org/10.3390/toxins15090521