1. Introduction
A hyperspectral image (HSI) is a three-dimensional cube composed of spectral and spatial information. Among them, the spectral information consists of hundreds of continuous narrow bands that record the reflectance values of light from visible to infrared [
1]. The spatial information consists of pixels that describe the distribution of land cover [
2]. The abundant spectral and spatial information improves the reliability and stability of object analysis [
3]. Therefore, the interpretation of HSI is widely used in precision agriculture, land management, and environmental monitoring [
4].
HSI classification attempts to assign labels for each pixel and obtains the category of different objects [
5]. In the early stages, some classical machine learning models were proposed for HSI classification, such as k-means clustering [
6], multinomial logistic regression (MLR) [
7], random forest (RF) [
8], and support vector machine (SVM) [
9], et al., which extract the representative features and assign the categories with sufficient labeled samples [
10]. However, these models are difficult to capture the correlation of spectral and spatial information and to distinguish the approximate features.
Deep learning models apply neural networks to automatically extract local and global features, and fully consider the contextual semantics to obtain the abstract representation of spectral–spatial features [
11]. As the commonly used model, the convolutional neural network (CNN), with the characteristics of local connection and weight sharing, extracts spectral–spatial features simultaneously [
12]. 2D-CNN and 3D-CNN are used in HybridSN to capture the semantic features of the HSI patches [
13]. However, adjacent patch samples contain a large overlapping area, which entails expensive computational costs [
14]. To reduce the overlapping computation, spectral–spatial residual networks (SSRN) [
15], spectral–spatial fully convolutional networks (SSFCN) [
16], and fast patch-free global learning (FPGA) [
17] were proposed to take HSI cubes or entire images as training samples and upgrade pixel-to-pixel classification to image-to-image classification. The deep learning models utilize convolutional layers to expand the receptive field, andextract the correlation of long-range features to improve the classification accuracy [
18]. However, these models face the problem of detail loss during feature extraction, i.e., the details within a few pixels gradually decrease and are likely to disappear after several down-sampling.
To retain detailed features that provide sufficient information for label prediction, attention mechanisms have attracted widespread interest for their ability to emphasize important objects, which are like the eye of models, automatically capturing the important objects and ignoring the background, and the capability of feature extraction is significantly improved with a small computation sacrifice [
19]. In addition, the pooling operation and multilayer perceptron (MLP) are utilized to quickly evaluate the importance of features and assign the corresponding weights [
20]. Some classical attention mechanisms, such as “squeeze and excitation” (SE) [
21], convolutional block attention module (CBAM) [
22], and efficient channel attention (ECA) [
23], measure the importance of spectral and spatial features with weights, as well as delineate the attention regions. However, the pooling operation is difficult to distinguish the continuous and approximate features of HSI, and results in inaccurate attention regions, which is described as “attention escape”.
The inaccurate attention region is mainly caused by the imprecise evaluation of attention weights, and adjusting the evaluation manner could effectively mitigate this problem [
24]. Therefore, controllable factors are introduced to enlarge the differences in approximate features and enhance the sensitivity of attention mechanisms [
25]. For example, the deep square pooling operation was proposed to increase the difference in continuous features by using pixel-wise squares to generate more discriminative weights [
26]. The coordinate attention mechanism (CAM) was proposed to locate important objects to efficiently capture the long-range dependency of features [
27]. The residual attention mechanism (RAM) introduced residual branches to fuse shallow features and control the spatial semantics padding of trunk branches [
28]. These approaches adjust the evaluation manner of attention mechanisms and obtain more accurate attention weights to emphasize the important objects [
29]. However, controllable factors lack the dynamic adjustment ability to adapt to the complex and continuous feature environment of HSI.
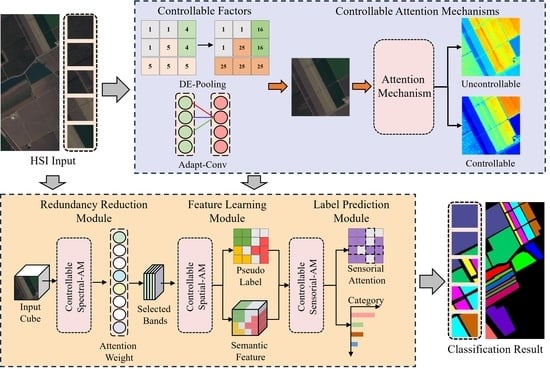
In this paper, a spectral-spatial-sensorial attention network (S3AN) with controllable factors is proposed for HSI classification. In S3AN, attention mechanisms and convolutional layers are encapsulated in the redundancy reduction module (RRM), feature learning module (FLM), and label prediction module (LPM). Specifically, dynamic exponential pooling (DE-Pooling) and adaptive convolution (Adapt-Conv), as controllable factors, participate in weight sharing and convey information via interfaces to balance the control effect of modules. In RRM, the spectral attention mechanism converts the spectral features into band weights, evaluates them by reconstructive convolution (Rec-Conv), and selects important bands to construct dimension-reduced features. In FLM, the spatial attention mechanism with double branches is utilized to pad details and emphasize spatial features, and cross-level feature learning (CFL) is utilized to extract the abstract representation of deep and shallow features. In LPM, the sensorial attention mechanism is utilized to search for the coordinates of labeled pixels and guides transition convolution (Trans-Conv) for pixel-wise classification. Finally, a lateral connection is used to fuse the three functional modules, gradually optimizing the representation of features and improving the classification accuracy. The main contributions of this paper are listed as follows:
A S3AN with controllable factors is proposed for HSI classification. The S3AN integrates redundancy reduction, feature learning, and label prediction processes based on the spectral-spatial-sensorial attention mechanism, which refines the transformation of features and improves the adaptability of attention mechanisms in HSI classification;
Two controllable factors, DE-Pooling and Adapt-Conv are developed to balance the differences in spectral–spatial features. The controllable factors are dynamically adjusted through backpropagation to accurately distinguish continuous and approximate features, and improve the sensitivity of attention mechanisms;
A new sensorial attention mechanism is designed to enhance the representation of detailed features. The category information in the pseudo label is transformed into the sensorial attention map to highlight important objects, and position details and improve the reliability of label prediction.
3. Materials and Methods
S
3AN designs functional modules based on attention mechanisms and convolutional layers, where the attention mechanism reweights feature maps to generate feature masks, and combines with convolution layers to extract abstract representation. A lateral connection is utilized to integrate these modules and interfaces are applied to convey feature maps and feedback information. As shown in
Figure 1, the HSI cube is defined as
, where
S and
C are the input size and the number of bands, respectively. The original image is transformed by RRM, the spectral feature is converted into a weight vector by spectral attention mechanism; Rec-Conv is utilized to update the weights; and the top
B bands with the highest weights are selected to construct the dimension-reduced feature that replaces the original image. Then, the dimension-reduced feature is delivered to FLM via the interface, and the spatial attention mechanism is applied to pad some shallow details; the spectral–spatial contextual semantic features are extracted by CFL, and the pseudo label is created through multi-scale feature fusion. Further, the pseudo label is transformed into a sensorial attention map by the sensorial attention mechanism, and Trans-Conv is guided to focus on the labeled pixels to optimize the representation of semantic features. Finally, the classification result is obtained by LPM.
3.1. Controllable Factors
To improve the ability of attention mechanisms to distinguish approximate spectral–spatial features, two controllable factors are proposed; that is, dynamic exponential pooling (DE-Pooling) and adaptive convolution (Adapt-Conv), and the detailed structure is shown in
Figure 2.
3.1.1. DE-Pooling
DE-Pooling adds a dynamic exponent computation before the global average pooling to control the fluctuation of spectral–spatial features [
44]. As shown in
Figure 2, taking the DE-Pooling of spectral feature as an example, the HSI cube is split into hundreds of bands, and then each band
is enlarged by an exponential multiple. This enlargement process highlights the differences in information between adjacent bands, making each band independently weighted. As seen in the band weights change, the approximate feature becomes more distinguishable. To adjust the spectral feature within a suitable range, the dynamic exponent is adjusted based on spectral attention weights, and the adjustment process is written as
where
denotes the mapping of dynamic exponent to spectral attention weights,
denotes the i-th spectral attention weight, and
denotes the maximum spectral attention weight. In addition, the original physical properties of HSI spectral–spatial features are altered as the dynamic exponent
continues to increase. Therefore, to avoid the infinite enlargement of the spectral features, expecting the feature value
x to change within the interval
,
is added to limit the variation in the dynamic exponent.
3.1.2. Adapt-Conv
To relate local and global features and improve the interaction efficiency of band weights, Adapt-Conv utilizes 1D-convolution instead of MLP and sets an adaptive convolutional kernel to control the information interaction range [
45]. Adapt-Conv for band weight interaction is shown in
Figure 2, where the adaptive convolutional kernel size is set to 3. To achieve adaptive adjustment of the kernel size, the mapping is conducted to describe the relationship between the number of bands and the kernel size. Considering that there may also be a positive proportional mapping between the number of bands and the kernel size, the mapping is written as
where the kernel size
k,
and
b are controllable parameters. Since the number of bands
C is usually close to being a power of 2, the mapping relation is defined as a nonlinear function
. Thus, after a given number of bands
C, the kernel size
k is calculated using the inverse function, which is written as
where
denotes the mapping of the kernel size
k to the number of bands
C. Since the convolutional kernel slides with the center as an anchor point, whereas odd convolutional kernel has a natural center point. Therefore, the odd operation
is set in Adapt-Conv, and it is taken as an odd number close to
t.
3.2. Redundancy Reduction Module (RRM)
RRM converts the reduction in spectral redundancy to a band reconstruction task, i.e., recovering the complete image with a few important bands [
40]. Therefore, the band importance is evaluated by the spectral attention mechanism, and the spectral attention weights are updated by Rec-Conv, selecting the bands that are essential for spectral reconstruction to construct the dimension-reduced feature.
As shown in
Figure 3, the HSI cube
X is fed into the spectral attention mechanism, and DE-Pooling fully considers the difference in spectral features and assigns a unique band weight
to each band. Further, the band weights
are conveyed to Adapt-Conv for local and global features interaction and obtain the final spectral attention map
. Therefore, the generation of the spectral attention map is written as
where
is the sigmoid activation function,
denotes the adaptive convolution, and
denotes the dynamic exponential pooling. Furthermore, a band-wise multiplication operation is applied to create the interaction between the HSI cube and the spectral attention map to obtain the spectral feature mask
.
Rec-Conv aims to improve the weights of important bands and suppress the representation of redundant bands. This structure consists of two and a nearest interpolation function for recovering the spectral feature mask. Then, calculate the loss between the original and recovered images, and update the band weights. After several iterations, the important bands will obtain the higher weight. Finally, the top B bands with the highest weights are selected by sorting, and their indexes are conveyed to FLM.
3.3. Feature Learning Module (FLM)
In FLM, the spatial attention mechanism emphasizes global spatial features by the trunk branch and pads the details by the residual branch. Then, CFL is applied to extract the contextual semantics by skip connection and multi-scale feature fusion.
As shown in
Figure 4, the dimension-reduced feature
is received by the spatial attention mechanism and allocated to two branches for processing. In the trunk branch, DE-Pooling is utilized to balance the difference in spatial features and assign spatial attention weights to each pixel. Then, the spatial information interaction is performed by a
convolutional combination, and obtain the spatial attention map
. In the residual branch, the input feature
is fed into two convolution combinations of
to extract a shallow feature map
. Therefore, the generation of the spatial attention map is written as
where
denotes a convolution operation with a filter size of
. The pixel-wise multiplication operation is applied to create the interaction of spatial attention map and dimension-reduced feature to obtain the trunk feature mask
. Further, the trunk feature mask
T and the shallow feature map
R are concatenated by weighted fusion to obtain a spatial feature mask
.
CFL following the encoder-decoder structure is mainly applied to extract contextual semantics. Among them, the encoder utilizes several convolutional combinations for down-sampling and feature learning to obtain abundant semantic information. The decoder utilizes several nearest interpolation functions for up-sampling and spatial feature recovery to obtain the semantic feature map that is of the same size as the original image.
Furthermore, the pseudo label is generated by multi-scale feature fusion. The shallow feature map (feature1) and deep feature maps (feature2, feature3) extracted by the encoder are selected for feature concatenation. Since the size of the deep feature maps are 1/2 and 1/4 of the input image, respectively, and not directly usable for creating the pseudo label. Therefore, two nearest neighbor interpolation functions are used to recover the size of the deep feature maps, when the feature maps are of uniform size, they are then concatenated by using the operation. In this way, the obtained feature maps with object locations that are similar to the input image. Further, the argmax function value is computed to obtain the possible category information in each pixel. In general, the pseudo label is an advanced prediction result that provides the location and category information of ground objects.
3.4. Label Prediction Module (LPM)
In LPM, the sensorial attention mechanism is applied to search for the labeled pixels in the semantic feature map, and Trans-Conv is applied to transition the semantic feature map into the classification result. Therefore, the module improves the stability and reliability of label prediction by object position and feature transition.
As shown in
Figure 5, the sensorial attention mechanism extracts the location and category information in the pseudo label and guides the model to focus on the location where objects are likely to be present, so that important details are not ignored by the model. Specifically, the pseudo label is fed to the sensorial attention mechanism, and its row and column elements are extracted by using DE-Pooling and Adapt-Conv. Then, the row and column sensorial attention weights are cross-multiplied to generate the complete sensorial attention map
. Thus, the generation of the sensorial attention map is written as
where
and
indicate the row and column elements of the pseudo label, respectively. Then, a pixel-wise multiplication operation is applied to create the interaction of the sensorial attention map and the semantic feature map
to obtain the sensorial feature mask
.
Trans-Conv is applied to mitigate the dimensional mutation in the prediction layer and has a flexible design concept. Its depth is determined by the size of the semantic feature map
and the dimensional reduction coefficient
r. The appropriate Trans-Conv layers both increase the model depth and retain details for label prediction. Therefore, the mapping of the Trans-Conv layers
l and the semantic feature dimension
D is established as
where
r denotes the dimensional reduction coefficient. Since the number of channels of the semantic feature map is reduced to
, so the dimensional distance is
. Finally, the output of Trans-Conv is performed for label prediction to obtain the classification result
P.
3.5. S3AN for HSI Classification
To meet the requirements of HSI classification, S
3AN designs RRM, FLM, and LPM based on attention mechanisms with controllable factors to process the original image. Among them, controllable factors and detail processing approaches are utilized to address the problems of “attention escape” and detail loss. A lateral connection is applied to integrate three functional modules, and the interfaces are used to convey feature maps and feedback information between the modules. Therefore, the original image
X is transformed by these modules to obtain the classification result
P. To train the model and adjust the controllable factors, the cross-entropy is utilized as the loss function, which is written as
where
Y denotes ground truth and
P denotes the classification result.
M and
N refer to the number of categories and samples of the training datasets, respectively.
denotes the sign function with a result of 0 or 1.
denotes the probability of the pixel
i belongs to category
j.
6. Conclusions
In this paper, an effective S3AN is proposed for HSI classification. Driven by controllable factors (DE-Pooling and Adapt-Conv), attention mechanisms are able to distinguish differences in approximate spectral–spatial features and to generate more reliable regions of interest. To reduce the computational cost, the controllable spectral attention mechanism accurately highlights representative bands in the HSI and reduces spectral redundancy. The controllable spatial attention mechanism cooperates with cross-layer feature learning to automatically extract local contextual semantics, and enhances the ability of deep and shallow feature interaction. In addition, the controllable sensorial attention mechanism explores the location and category information of ground objects, which further enhances the HSI classification results. The experimental results on three public HSI datasets show that the proposed method enables fast and accurate HSI classification.
Based on the experimental results, it is known that the proposed controllable attention mechanisms are adaptable to the complex feature environment of HSI. However, all results are obtained under the condition of labeled datasets, which require a lot of time for labeling. In contrast, producing unlabeled datasets reduces the workload, and it is interesting to explore the self-supervised HSI classification in the future.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}