1. Introduction
The rapid development of remote sensing technology is helping humans to better understand the earth [
1,
2]. As an important branch of remote sensing research, the use of optical remote sensing technologies is crucial in many fields such as target detection [
3], vegetation index calculation [
4,
5], scene classification [
6], and change detection [
7,
8]. Optical remotely sensed imagery plays an important role in earth science, military, agriculture, and hydrology [
9]. However, the majority of the Earth’s surface is shrouded in clouds or snow. Clouds cover more than half of the earth’s surface [
10]; more than 30% is covered by seasonal snow, and about 10% by permanent snow [
11]. Utilizing remote sensing data to its full capabilities is difficult due to the occlusion of underlying surfaces by clouds or snow cover. Typically, the initial step in most remote sensing studies is to identify clouds or snow [
12]; therefore, it is crucial to efficiently and precisely detect cloud and snow regions in remote sensing photographs.
In remote sensing for visible light, the active remote sensing method is generally used [
13], which uses the reflection characteristics of clouds and snow for imaging, and the imaging effect is better when the daytime sunshine conditions are good. The working band of visible light remote sensing sensor is limited to the visible light range (0.38–0.76
m). Since the visible light band is in the range of human perception, the ground staff can directly interpret and make decisions on image products [
14]. Common optical remote sensing systems include WorldView [
15], Pleiades [
16], and so on.
Because the diameter of the suspended particles in the cloud is greater than the wavelength of the electromagnetic spectrum of the solar radiation, there is non-selective scattering of the solar spectrum through the cloud, which is consistent with the degree of scattering of the red, blue, and green bands, so the cloud presents as bright white [
17]. In the visible range, the reflectivity of snow is close to 95%, almost completely reflected, and close to the peak in the blue band of 0.49
m. The reflectivity of snow decreases rapidly with the increase in wavelength, especially in the shortwave infrared band, which decreases to close to 0 at 1.5
m and 2.0
m [
18]. Both clouds and snow have low-temperature characteristics; the brightness temperatures of the two are relatively close in the thermal infrared band, so that the thermal infrared band is not conducive to distinguishing cloud from snow [
19].
Traditional methods mostly use a threshold for detection [
20,
21], or they extract features manually for identification [
22]. Zhang et al. [
23] suggested a unified cloud detection algorithm based on the spectral index, and proposed a quantitative cloud index (CI). Zhu et al. [
24] highlighted the target information by calculating the cloud and shadow index, and also studied a time series analysis method to identify clouds by employing optical imagery. Li et al. (2017) [
25] explored spectral feature-based threshold segmentation to produce cloud mask pictures. Qiu et al. [
26] used the time series of observations in the cirrus band (1.36-1.39
m) to detect cirrus targets. Zhang et al. [
27] studied the method of radiation compensation for visible band images using transformed images for the detection of cloud spatial distribution. An et al. [
28] studied cloud detection by using artificially stacked different image features. However, most of these methods rely on prior knowledge, and there are many problems such as its complex operation and being time-consuming, and prone to false detection and missed detection. Later, machine learning technology was applied to the task of detecting clouds/snow, such as support vector machine [
29], sparse perception [
30], etc., and the detection accuracy was improved.
Deep learning has excelled in a wide range of industries in recent years thanks to its fast progress, especially in terms of images [
31,
32,
33,
34,
35]. Deep learning technology has incomparable advantages over other methods and can automatically capture the feature information of images during training [
36,
37]. It has much a higher accuracy than manual extraction. Earlier, convolutional neural network-based techniques have produced effective picture categorization outcomes in several cases [
38,
39], which further created the foundation for pixel-by-pixel categorization problems in the future. In 2015, Long [
40] first proposed a fully convolutional neural network (FCN) to achieve pixel-by-pixel classification in images. Replacing the fully connected layer with a pure convolutional structure means that the model can allow for the entry of images of any size. The results show that this is useful for pixel-by-pixel classification jobs; however, there are also obvious disadvantages: the segmentation is not fine enough, and it is not sensitive to the details in the image. Aiming at the problem of insufficient sample size, Ronneberger et al. [
41] developed a technique for data augmentation to make better use of dataset pictures, and suggested a U-shaped network (UNet) to obtain the location and context information. Although it solves the problem of insufficient data, it does not apply to all segmentation tasks. For example, some data cannot be enhanced, so it cannot exert its advantages. The DeepLab series models [
42] suggested by Chen et al. increase the receptive field by using dilated convolution. Although the receptive field area increases, this also sacrifices the spatial resolution, resulting in a loss of spatial information. The Pyramid Scene Parsing Network (PSPNet) [
43] proposed by Zhao et al. gathered context information from several places by using a pyramid pooling structure with the goal of obtaining global information. However, the operation of the image pyramid leads to an increase in the calculation of the model and consumes time. In order to solve the problem that most model parameters are too large to realize real-time reasoning, in 2016, Paszke et al. [
44] suggested a lightweight network (ENet) designed for tasks that require low latency operations. In 2018, DenseASPP [
45] used a densely connected structure for the first time to implement a collection between different feature layers, combining the advantages of the parallel and cascaded use of dilated convolutional layers, where more scale features are generated in a larger range. Yuan Y et al. [
46] proposed a new way to construct context information in semantic segmentation, namely enhancing the contribution of pixels from the same object while constructing context information, and the results show that the context information has a positive impact on the final effect of the model. For cloud/snow detection, Li et al. [
47] studied a cloud detection method based on weakly supervised learning. Compared with the supervised learning method, it has less dependence on data, and can reduce the workload caused by annotated data. Guo et al. [
48] suggested a neural network with a codec structure (CDnetV2) to extract cloud regions in satellite thumbnails. CDnetV2 can fully extract features from the coding layer for cloud detection, but it is limited to low-resolution satellite thumbnails. H Du et al. [
49] studied a new convolutional neural network (CNN) that uses a multi-scale feature fusion module to effectively extract the information of feature maps from different levels, and it can alleviate the adverse effects of cloud and snow detection. Qu et al. [
50] proposed a parallel asymmetric network with dual attention, which has both a high detection accuracy and a rapid detection speed, and can detect clouds in remote sensing images well, but it has no advantage in the case of the coexistence of cloud and snow. For the purpose of segmenting clouds in satellite pictures, Xia et al. [
51] devised a global attention fusion residual network that can handle various complex scenes, but it is susceptible to noise interference and has a weak ability to segment small-area thin cloud boundaries.
Since the clouds and snow have similar spectral characteristics and color attributes [
52], the difficulty of model detection is greatly increased. Previous semantic segmentation models all use convolution for feature extraction, which makes the models limited by local information, unable to establish the connection between global information, and susceptible to interference from complex underlying surfaces. There are a lot of misjudgments in the picture, and the processing effect of cloud/snow details is not ideal. To solve the above problems, we expect the model to be able to efficiently extract local characteristics, as well as pay attention to the connection between information in the global scope and grasp the internal correlation between pixels.
In recent years, researchers have found that a transformer can not only handle natural language processing tasks well, but it can also obtain good results by extending it to image tasks. For example, Liao et al. [
53] combined convolution and a transformer for feature extraction and used it for image classification tasks. Moreover, the multi-head attention system of transformers can focus on global information while also keeping a close eye on important regions, which makes it possible to focus on both key regions and grasp global information. Shi et al. [
54] added an attention mechanism to convolutional networks for the scene classification of remote sensing images, and found that it can still maintain a good degree of classification accuracy when the number of parameters is small. However, the effect on hyperspectral image types is unknown, and it is not suitable for pixel-level classification tasks. In 2020, Dosovitskiy et al. [
55] designed a Vision Transformer (ViT) to solve the image classification task, and applied the pure transformer module to image sequences to extract image information and to complete classification. Although ViT can surpass the traditional convolution algorithm using a large amount of training data, it has a large number of parameters and relies on huge amounts of training data. Later, more and more researchers have introduced the transformer into the field of imaging, and many variants based on the transformer appeared. Wang et al. [
56] introduced the pyramid structure into the transformer and proposed a new transformer-based variant network (PVT). Compared with ViT, which is specifically designed for image classification, PVT can perform various downstream intensive predicting operations such as segmentation. PVT can be used as an alternative to traditional convolutional networks, but it is not compatible with some modules that are specifically designed for convolutional networks. At this time, the research on transformer-based models in the visual field is still in its infancy. Afterwards, Wu et al. [
57] also tried to introduce convolution into the transformer, and proposed the convolutional vision transformer (CVT). Convolution is added to the model based on ViT in order to enhance its performance and efficiency. These changes introduce the ideal characteristics of convolution into ViT architecture while maintaining the advantages of the transformer. However, these methods have an enormous number of parameters at the expense of model’s speed, especially in cloud/snow detection, so these methods do not have an advantage.
Because clouds and snow have similar shallow features and color attributes, which make them similar in appearance, it is more challenging to deal with the coexistence of clouds and snow than a single cloud or snow. In order to accurately segment cloud and snow areas from the image, only extracting shallow information can no longer meet the needs of the task, and it is necessary to mine the deep features more accurately. The current single convolution or transformer method cannot meet the needs of feature extraction in cloud and snow images, so we studied a new backbone (see
Section 2.2) for feature extraction in cloud and snow segmentation tasks. In the process of feature extraction, a large amount of information will be generated in the feature maps of different levels. The existing problem is that this information cannot be effectively fused, and the noise and other factors can easily interfere with the results. Clouds and snow have very complex edge features. Retaining edge feature information in the process of segmenting cloud and snow regions has always been a difficult task. To solve the above two problems, we propose a new fusion module to fully integrate different levels of information (see
Section 2.3). The distribution characteristics of cloud and snow show irregular distribution, the shape is complex and changeable, and the complex background often interferes with the final result, which requires the model to grasp the details very accurately in the process of upsampling to restore the original image. The current method generally performs direct upsampling on deep features, which leads to the problem of information loss during the upsampling process, and the recovery of details is not ideal. To solve this problem, we propose a new decoder module (see
Section 2.4).
In this article, we combine convolution with a transformer to suggest a multi-branch convolutional attention network (MCANet). To reduce the weight of the model and to make it easy to train while ensuring accuracy, we use a new module in a transformer-based variant network (EdgViT) [
58] to form a branch of the backbone network. The transformer has such advantages as dynamic attention, global context, and better generalization ability, which are not available for convolution [
59]. On another branch, we construct a convolution module of the residual structure to grasp the local features in the picture. To make the two branches complement each other and to better extract image features, we construct a new fusion module to fuse the information between different branches and feature layers. Finally, in order to preserve the extracted deep information, a new decoder module is proposed. The new decoder module obtained by combining convolution with a transformer can retain important information to the greatest extent and filter noise. In the experimental part, we compare the proposed method with the current advanced methods on different datasets to prove the effectiveness of the proposed method. The following are the primary accomplishments of this paper:
A multi-branch convolutional attention network is proposed for cloud/snow detection. It combines convolution and a transformer, and focuses on the image’s local and global information. When the content in the image is too complex and there are many interference factors, this method is very effective.
A new fusion module is established to fuse the information among different feature layers of two branches, and strip convolution is added to enhance the ability of the model to recover edge details.
Considering that most networks lose information in the process of responding to the feature map, this paper establishes a new decoder module, which combines convolution and a transformer to focus on the important information during the upsampling process, filter out useless information, avoid the interference of useless information, and enhance the model’s capacity for interference rejection.
2. Methodology
To be able to accurately extract the cloud/snow region in the image, we propose a multi-branch convolutional attention network (MCANet). The network can efficiently extract both local and global information from images and correctly fuse them. It solves the problem that the current algorithm cannot accurately extract the effective information in the image, which leads to the inaccurate segmentation result [
60,
61].
The network proposed in this article can not only precisely identify the cloud and snow area in the image, but also effectively restore the edge details of cloud and snow. It has a certain resistance to the interference of complex background, and can accurately identify the cloud/snow area under the interference of different backgrounds. This section introduces the whole architecture of the model, the design method of the backbone, and different sub-modules.
2.1. Network Architecture
Aiming at the issue that the current algorithm cannot effectively extract the relevant features of cloud/snow in remotely sensed data, we propose a multi-branch feature extraction structure composed of convolution and transformer, which can effectively extract the cloud/snow features, accurately identify the cloud/snow area, and optimize the edge details to make the segmentation results more refined.
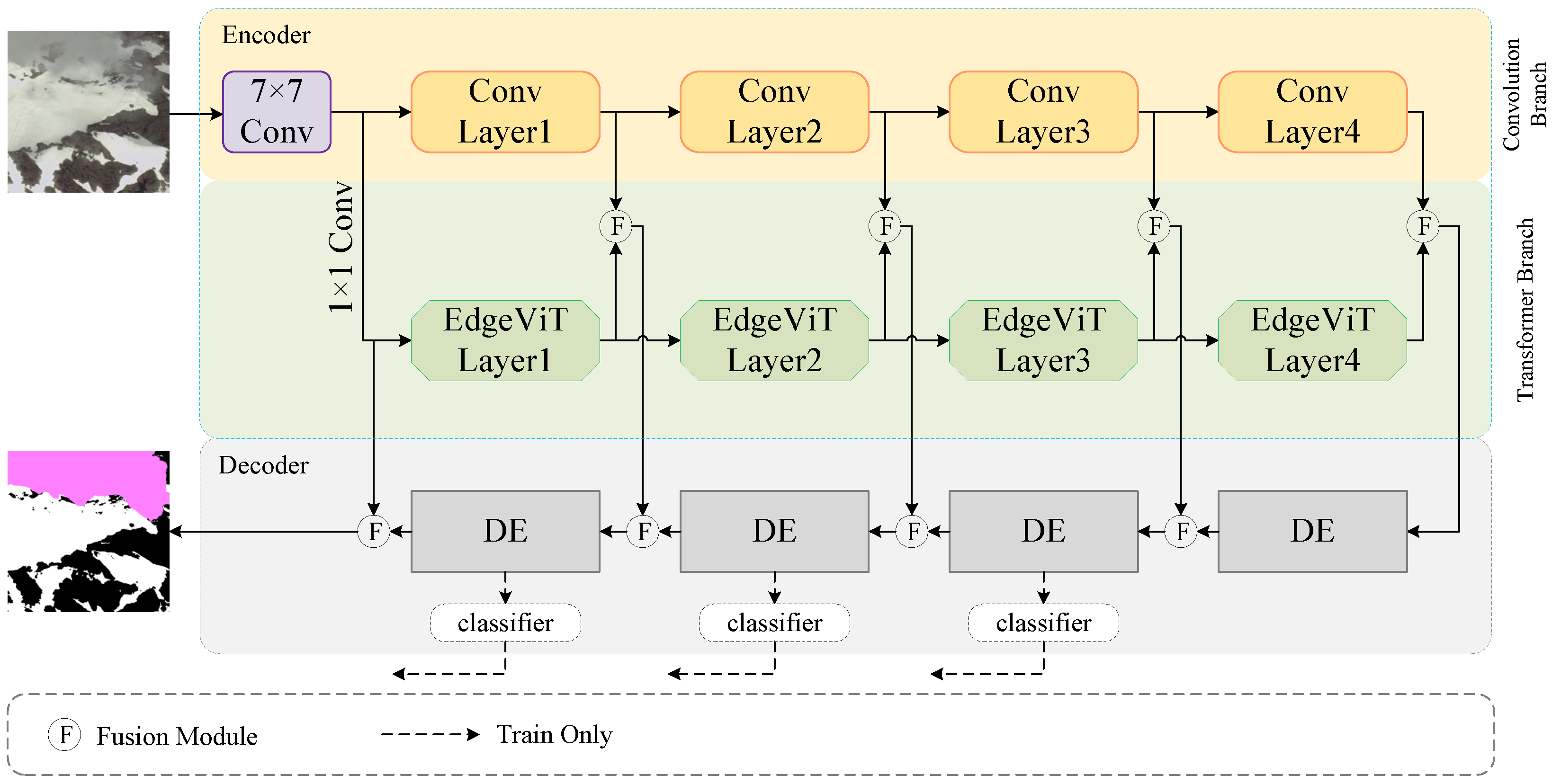
Figure 1 shows the whole architecture of the multi-branch convolutional attention network. Furthermore, Algorithm 1 shows the pseudocode of the data transmission process of the multi-branch convolutional attention network. The entire network uses an encoder–decoder design. We believe that the final segmentation accuracy is directly impacted by the precision of feature information extraction [
62,
63]. Previous studies have proven that convolution is excellent for the extraction of local information, but it lacks accuracy for the grasp of global information. The characteristics of the transformer can make up for this shortcoming. Therefore, a multi-branch mode is adopted in the encoder. The local characteristics of the images are extracted by using a convolution layer, and the transformer layer is used to grasp the global characteristics. After that, the feature data obtained from the two branches are effectively fused. The current fusion strategy just applies a straightforward linear splicing operation on the generated feature map, which is unable to retrieve the useful information. At the same time, the simple splicing operation can easily produce information redundancy, which is extremely unfavorable for the subsequent decoding operation. The integration module is introduced here, which can effectively combine the local and global information extracted from the two branches and filter it, only retaining the meaningful part of it, and it can improve the model efficiency.
In the decoding phase, the majority of modern networks directly upsample to return the original picture size. This can easily cause information loss during upsampling. Some networks use only a single convolution to decode the feature map, and some important feature information is preserved, but the convolution only focuses on local features and cannot establish long-distance connections in the feature map, so the recovery of large-scale cloud/snow areas is not ideal. This paper proposes a new decoder. Combining convolution with atransformer, the effective information in the deep feature is restored gradually. Because the high-level semantic information and spatial information in the upsampling process usually cause the final segmentation boundary to be rough, at the decoder, we again fuse the high-level feature map with the various levels of fusion feature data that the encoder has obtained, so that the important detail information can be retained to achieve an accurate segmentation of clouds/snow.
To increase the accuracy of the final segmentation result, the classifier module is added to the network, which is mainly composed of upsampling and convolution modules. Different levels of output characteristic graphs are drawn at the decoding end to calculate the auxiliary loss, which is used to accelerates the network’s convergence and increase prediction accuracy. The addition of the output strip convolution makes the final output prediction map more refined.
| Algorithm 1 The data-transmission process of MCANet |
- Input:
Training data: D = {(, ), (, ), …, (, )}; Attribute set: A - Output:
The final segmentation picture: = classifier(F(, )) and , i = 2, 3, 4 - 1:
The backbone network extracts features, and the backbone network routing convolution branch and attention branch are constituted - 2:
The convolution branch extracts features and outputs feature maps of different levels: - 3:
The transformer branch extracts features and outputs feature maps of different levels: - 4:
The features of different branches are fused, , i = 2, 3, 4, 5, and the output is obtained: - 5:
The high-level features are upsampled and passed through the decoder module: - 6:
for i = 5,4,3,2 do - 7:
Fusion of shallow features and deep features: - 8:
Through the decoder module: - 9:
if i! = 5 then - 10:
The output is obtained: - 11:
end if - 12:
end for - 13:
return = classifier(F(, )) and , i = 2, 3, 4
|
2.2. Backbone
Because clouds and snow have similar spectral characteristics and color attributes [
52], they are easily disturbed by complex underlying surfaces. A single convolution or transformer structure does not meet the need for feature extraction in cloud/snow images. We use the multi-branch structure of convolution and transformer as the backbone of the model to abstract the characteristic information of the image. Convolution extracts features by sharing convolution kernels to reduce network parameters and to improve model efficiency, and its translation invariance makes feature detection for images more sensitive, but its limited receptive field makes it less capable of extracting global information. However, the emergence of transformers enables the global information in the image to be captured, and transformers have shown phenomena beyond those of CNN in many visual tasks. In this study, we combine the benefits of transformer and convolution to extract different levels of characteristic information, which perfectly inherits the advantages of convolution and transformer, so as to enhance the model’s capacity for feature extraction.
Table 1 shows the specific structural parameters of the model.
As we can see in
Figure 2a, we use two layers of 3 × 3 convolutions as the block of our convolution branch. Algorithm 2 shows the pseudocode of the data transmission process of the convolution branch block. The addition of the residual structure makes the model lessen the rate of information loss, and it can protect the integrity of information when extracting features. The convolution branch’s computation procedure can be stated as follows:
where
and
represent the i-th layer input and output of the convolution branch, respectively; BN (.) represents batch normalization,
(.) is a representation of the nonlinear activation function ReLU; and
(.) is a representation of the 3 × 3 convolution operation.
| Algorithm 2 Data transmission process of the convolution branch block |
- Input:
The output feature map of the previous layer: - Output:
- 1:
- 2:
- 3:
return
|
For the transformer branch, considering the number of parameters and the computational complexity of the model, we use the block in EdgViTs [
58] as the component part of our transformer branch. EdgViTs is a new lightweight ViT family, and it is achieved by introducing a high-cost local–global–local (LGL) information exchange bottleneck based on the optimal integration of self-attention and convolution. The particular structure is displayed in
Figure 2b, and Algorithm 3 shows the pseudocode of the data transmission process of the transformer branch block. It mainly includes three operations: (1) local aggregation, utilizing effective depthwise convolutions, local information aggregation from neighbor tokens (each corresponding to a distinct patch); (2) global sparse attention, generating a sparse collection of regularly spaced delegate tokens for distant information exchange via self-attention; and (3) local propagation, using transposed convolutions to spread updated information from delegate tokens to non-delegate tokens in nearby areas. The main calculation process can be expressed as follows:
where
denotes the input tensor, Norm (.) denotes Layer Normalization, LocalAgg (.) denotes the local aggregation operator, FFN (.) denotes the perceptron with two layers, GlobalSparseAttn (.) denotes global sparse self-attention, and LocalProp (.) denotes global sparse self-attention.
| Algorithm 3 Data transmission process of the transformer branch block |
- Input:
The output feature map of the previous layer: - Output:
- 1:
- 2:
- 3:
- 4:
- 5:
return
|
Because of the restriction of the receptive field, the perception of the objective in the picture is always limited. To enlarge the receptive field, dilated convolution can be applied to the current method, but considering the complexity of remote sensing image content, a single use of the convolution operation makes large-scale targets, and the small-scale cloud/snow area is always impossible to take into account, so the transformer branch joins the perfect solution to this problem. The two branches complement each other, taking into account the extraction of small targets and the effective identification of large-scale clouds/snow, and self-attention enables the effective learning of global information and long-distance dependencies. This is useful for avoiding the interference of similar color attributes of cloud and snow, so that the model can effectively distinguish cloud and snow.
2.3. Fusion Module
Clouds and snow have complex edge shapes relative to other targets. Accurately restoring the edge features of clouds and snow has always been a difficult task. In addition, the feature maps produced by different layers of the model will provide an enormous amount of useless information. Filtering this information is particularly important. If the information contained in the feature map cannot be fully integrated, the noise and other factors contained in it will have a huge influence on the final categorization outcomes.
To solve the problems described above, we suggest a fusion module to fuse the information from different layers. In the backbone, the different levels of features abstracted by the convolution branch and the transformer branch need to establish a complementary relationship in order for the model to perfectly inherit the benefits of convolution and the transformer. At the decoder level, the category information with rich high-level characteristics can direct the classification of low-level characteristics, while the location information retained by the low-level features can supplement the spatial location information of the high-level characteristics.
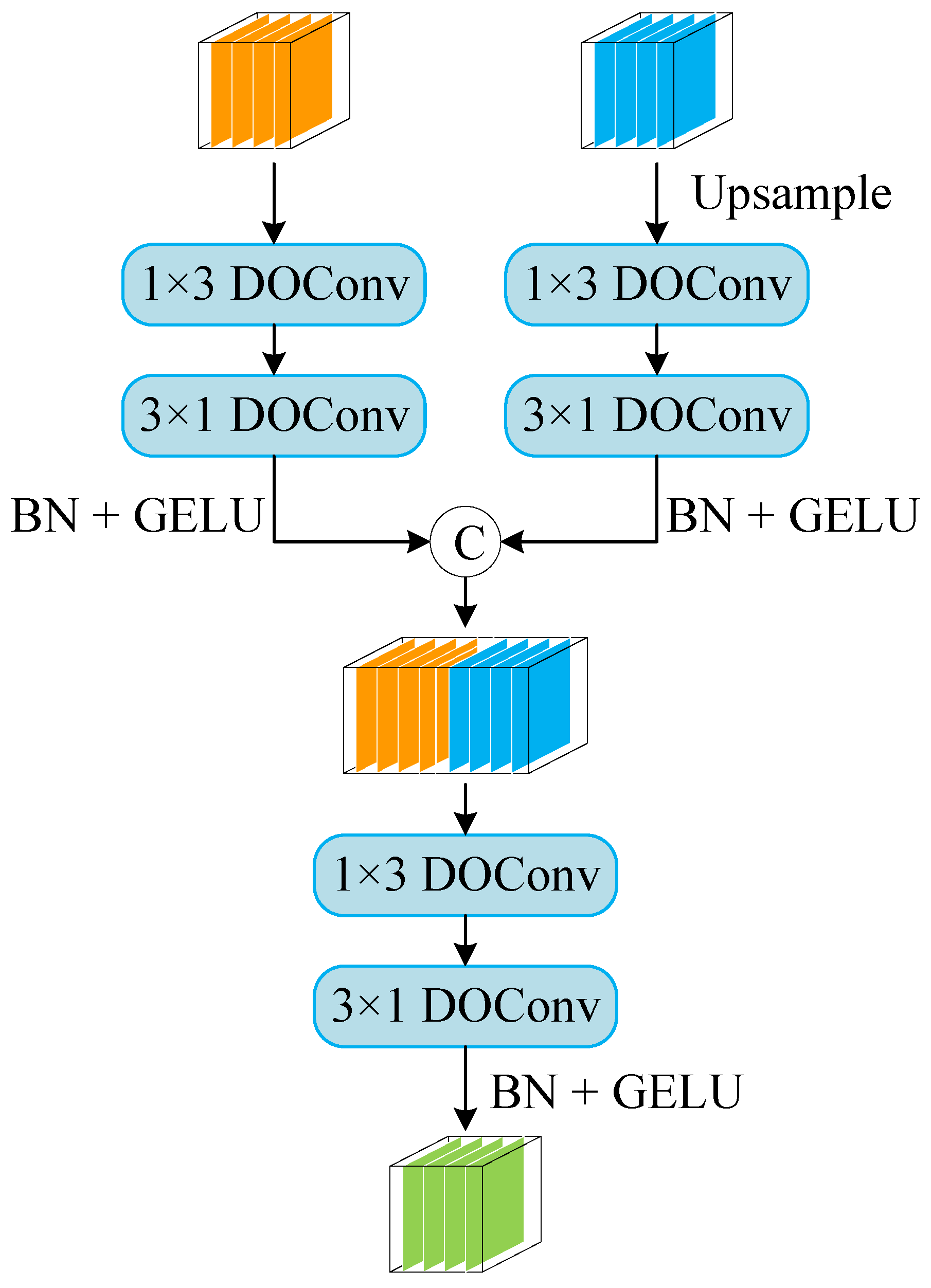
Figure 3 demonstrates the general layout of the fusion module that is proposed in this study, and Algorithm 4 shows the pseudocode of the data transmission process of Fusion Module. In this module, we use DO-Conv [
64] to replace the traditional convolution. DO-Conv is a depthwise over-parameterized convolutional layer that adds learnable parameters, which has positive significance for many visual tasks.
| Algorithm 4 Data transmission process of the Fusion Module |
- Input:
Feature maps of different levels in our network: and - Output:
- 1:
- 2:
- 3:
- 4:
- 5:
return
|
The use of stripe convolution enables the model to more effectively extract the edge features of clouds and snow. As far as we can see in the figure, there are two parallel branches that make up the fusion module. Firstly, the deep-level features are amplified to the same level as the low-level features of another branch, and then the strip convolution is used to filter the information in the deep-level features and the low-level features, and enhance the feature extraction ability. The strip convolution architecture is mainly composed of two convolution kernels with sizes of 1 × 3 and 3 × 1, a batch normalization layer, and an activation function GELU [
65]. Then, the information abstracted by two branches is combined and finally sent to the next level of the network after the action of two layers of the strip convolution layer. The calculation process is as follows:
and represent the two inputs of the fusion module, represents the output, (.) represents the convolution procedure using an n × m convolution kernel, Up (.) represents the bilinear interpolation upsampling operation, Concat (.) represents the splicing operation based on the channel dimension, and BN (.) and G (.) represent batch normalization and the nonlinear activation function GELU. The use of the GELU activation function to replace the traditional ReLU is due to the idea of random regularization added to GELU, which improves the network accuracy.
2.4. Decoder Module
The distribution characteristics of cloud and snow are not uniform in distribution, and the shape is complex and changeable. Similar color attributes also make it more difficult to distinguish them. The interference of a complex background often causes the phenomenon of misjudgment or omission. During the upsampling procedure, the current methods often directly decode the high-level feature map or use a single convolution to decode the feature map and restore the original image features. This will make the model lose information due to the wrong attention to feature information throughout the upsampling phase, which makes it challenging to recover the details. As a result, the model cannot correctly differentiate between clouds and snow, and it is susceptible to misjudgment due to interference from complex backgrounds.
We provide a new decoder module as a solution to the aforementioned issues. Inspired by Xia X et al. [
66], who previously proposed that a complementary convolution and transformer can make up for the deficiency of single use, the scheme of combining the CNN and transformer is adopted to construct a hybrid module that is composed of convolution and a transformer, to significantly increase the efficiency of information flow. As we can see in
Figure 4, we first used a 1 × 1 convolution layer to modify the quantity of input channels, and then a transformer module is involved to establish a long-distance dependency in the feature map. A channel splitting layer is introduced into the module, and the ratio r is used to adjust the proportion of the convolution module in the hybrid module to further improve the efficiency. We suppose that the amount of the input channel is
, that the amount of the output channel after the transformer module is
, and that the amount of the output channel after the convolution module is
. Finally, the results of the transformer module and convolution module are concatenated to obtain the final output. The calculation process is as follows:
where
(.) represents the convolution procedure using a 1 × 1 convolution kernel, Trans (.) and Conv (.) represent the passing transformer module and convolution module, respectively, and Concat (.) represents the splicing operation based on the channel dimension. Algorithm 5 shows the pseudocode of the data transmission process of the Decoder Module.
| Algorithm 5 Data transmission process of the transformer Decoder Module |
- Input:
The output feature map of the previous layer: - Output:
- 1:
- 2:
- 3:
- 4:
- 5:
return
|
2.5. Experiment Details
The PyTorch framework was used for all our expriments. The version number was 1.10.0, and the Python version was 3.8.12. The experimental equipment includes the NVIDIA series graphics card, the graphics card model is NVIDIA GeForce RTX 3060, the graphics memory is 12 G, the CPU is i5-11400, and its computing memory is 16 G.
Due to restrictions on GPU memory, we defined the batch size for each iteration to 4 when using the CSWV Dataset for training, and the training batch size of the other two datasets was set to 8, while the training period was 300 epochs. When training the dataset, we used the equal interval adjustment learning rate (StepLR) strategy. As the number of training epochs increased, the learning rate was reduced accordingly to achieve better training results. In the initial stage of training, the learning rate was set to 0.00015, the attenuation coefficient was 0.98, and the learning rate was updated every three epochs. The learning rate for each epoch is calculated as follows:
where
is the learning rate of the Nth training,
is the initial learning rate,
is the attenuation coefficient, and s is the update interval.
We chose the cross-entropy loss function as the loss function of model training, and the calculation formula of the loss function is as follows:
where x is the output tensor of the model, and class is the real label.
As the traditional adaptive learning-rate optimizer (including Adam, RMSProp, etc.) faces the risk of falling into bad local optimization, we used the RAdam optimizer [
67] as our optimizer. RAdam provides a dynamic heuristic to provide automatic variance attenuation, and it is more robust to changes in learning rate than other optimizers. It can provide a better training accuracy and generalization ability in various datasets, and brings better training performance to the model.
To improve the model’s capacity for generalization, and to prevent overfitting during training, we also performed data augmentation on the dataset. Because clouds and snow have similar color properties, in addition to randomly rotating and flipping the image, the contrast, sharpening, brightness, and color saturation of the image were randomly adjusted with a probability of 0.2 during training.
For the purpose of assessing the model’s real performance, this paper introduces the evaluation indexes of pixel accuracy (PA), mean pixel accuracy (MPA), F1, frequency weighted intersection over union (FWIOU), and mean intersection over union (MIOU) to evaluate the performance of the model in practical applications. Their calculation formulas are as follows:
where
P is Precision, which represents the probability that the pixels in the prediction result are predicted correctly; R is the recall rate Recall, which represents the probability that the pixels in the true value are predicted correctly;
k stands for the number of classes (excluding the background scene);
identifies the number of pixels in category
i and predicted as category
i;
is the number of pixels in category
i that are predicted to be in category
j; and
is the number of pixels in category
j that are predicted to be in category
i.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}