1. Introduction
The launch of the Sentinel-2 satellites in 2016 and 2017 has opened new avenues for crop identification based on optical satellite data [
1]. They acquire multi-spectral data at a ground sampling distance of 10 m and have a revisit frequency of five days at the equator [
2]. The resulting time series of images should make it possible to identify crops early in the season and to increase general classification accuracy [
3]. Using a time series of images poses a new challenge: the large number of images that need to be handled calls for an automated pre-processing system. Sen2-Agri addresses this need [
4]. It can be used to create a cropland mask and, in a second step, identify crop types [
5]. Another software tool, called Sentinels for Common Agricultural Policy (Sen4CAP), uses the same random forest (RF) classification engine [
6]. The RF algorithm [
7] is fast and relatively insensitive to overfitting [
8]. Unlike other machine-learning algorithms, RF does not need much finetuning of hyperparameters and can handle simple and complex classification functions [
9,
10].
Machine-learning algorithms are generally perceived to be data hungry, i.e., the more training data that are available, the better the resulting classification accuracies [
11]. Based on expert knowledge, the developers of Sen2-Agri generally recommend that for a given stratum, the user provides 75–100 samples for each main and 20–30 samples for each minor crop [
5]. Considering the 75% split of the samples into training and validation pixels, this rule of thumb is close to the 50 sample units (pixels, clusters of pixels, or polygons) per class suggested in other studies [
12,
13]. However, Congalton [
12] also pointed out that conventional statistical approaches to calculate sample sizes based on an approximation of a binominal distribution are only valid to estimate the OA of a single category. They are not appropriate to calculate the error matrix because they do not account for the confusion of specific categories or crop types, as in this study. He concluded that “because of the large number of pixels in a remotely sensed image, traditional thinking about sampling does not often apply” and that a balance between what is statistically sound and what is practically attainable must be found. Another approach has been to define the number of samples needed per class as a function of bands used for the analysis. The general recommendation was to use 10 to 30 times as many samples per discriminating waveband [
14]. However, using a machine-learning algorithm in combination with a Monte Carlo analysis for a multi-temporal crop classification, Van Niel et al. [
15] established that for their case study, approximately 2 to 4 samples per discriminating waveband were sufficient to attain 95% of the accuracy achieved with 30 samples. They further cautioned that, ultimately, the number of samples needs to be determined by considering the complexity of the discrimination problem. Based on an analysis of a binary classification, Waldner et al. [
16] demonstrated that the class proportions of the training data were more important for achieving a high classification accuracy than the sample size.
Apart from government agencies, which use the data to produce crop statistics [
17], many other types of organizations collect crop type information. Disaster and relief organizations rely on them for assessing crop production prospects [
5]. Policy planners and researchers use them for technology targeting [
18] or yield gap analyses for specific crops [
19]. The food processing industry tends to be interested in specific crops to forecast the supply of inputs as early as possible and plan the logistics after harvest. Focusing on just one crop versus everything else may also reduce the error rate in the training data. It can be challenging to accurately identify all the crops, especially when doing a wind-shield survey.
Most farming landscapes are dominated by few crops. If the training data are collected in a random manner, the predominant crops will also be strongly represented, whereas fewer fields of the minority crops will be collected [
20]. This may, in turn, decrease their classification accuracy, and the training data will most likely be imbalanced as well. The marginal return (in terms of classification accuracy) of adding fields of dominant crop types may diminish rather quickly. It might be better to pay more attention to the less dominant crops to improve their classification accuracy. But this could lead to an overestimation of the crops belonging to a minor class. Millard and Richardson [
21] showed how the change in the proportion of training samples affected the classification output and thus introduced errors. Accordingly, Mellor et al. [
22] reported that balanced training data, in which the crops have a proportional representation, resulted in the lowest overall error rates. However, they also noted that a sensible correction of imbalance can improve the classification performance for “difficult” classes.
Careful preparation of the in situ data is a prerequisite for successful crop classification. The general rule of thumb for machine learning is that 80–90% of the time is spent preparing the data, and the remainder is used for classification, analysis and interpretation of the results [
23]. Hence, guidelines, not only for practitioners but also for researchers, are needed to help them optimize the use of limited resources. Our paper will address the following questions:
Does a proportional or equal representation of each crop type in the training data generate better classification results?
What is the optimal number of training fields?
How does classification accuracy change with time across the season?
What kind of accuracies can be achieved with a binary classification, in which one focuses just on one crop vs. “everything else”?
In this paper, we first present the overall workflow (
Section 2.1) and then explain how we created the in situ data (
Section 2.2). Next, we describe the Sen2-Agri system (
Section 2.3) and how we created different scenarios (
Section 2.4) and naming conventions (
Section 2.5) to answer the above questions. The four questions are then used to structure the Result and Discussion sections.
2. Materials and Methods
2.1. Overall Workflow
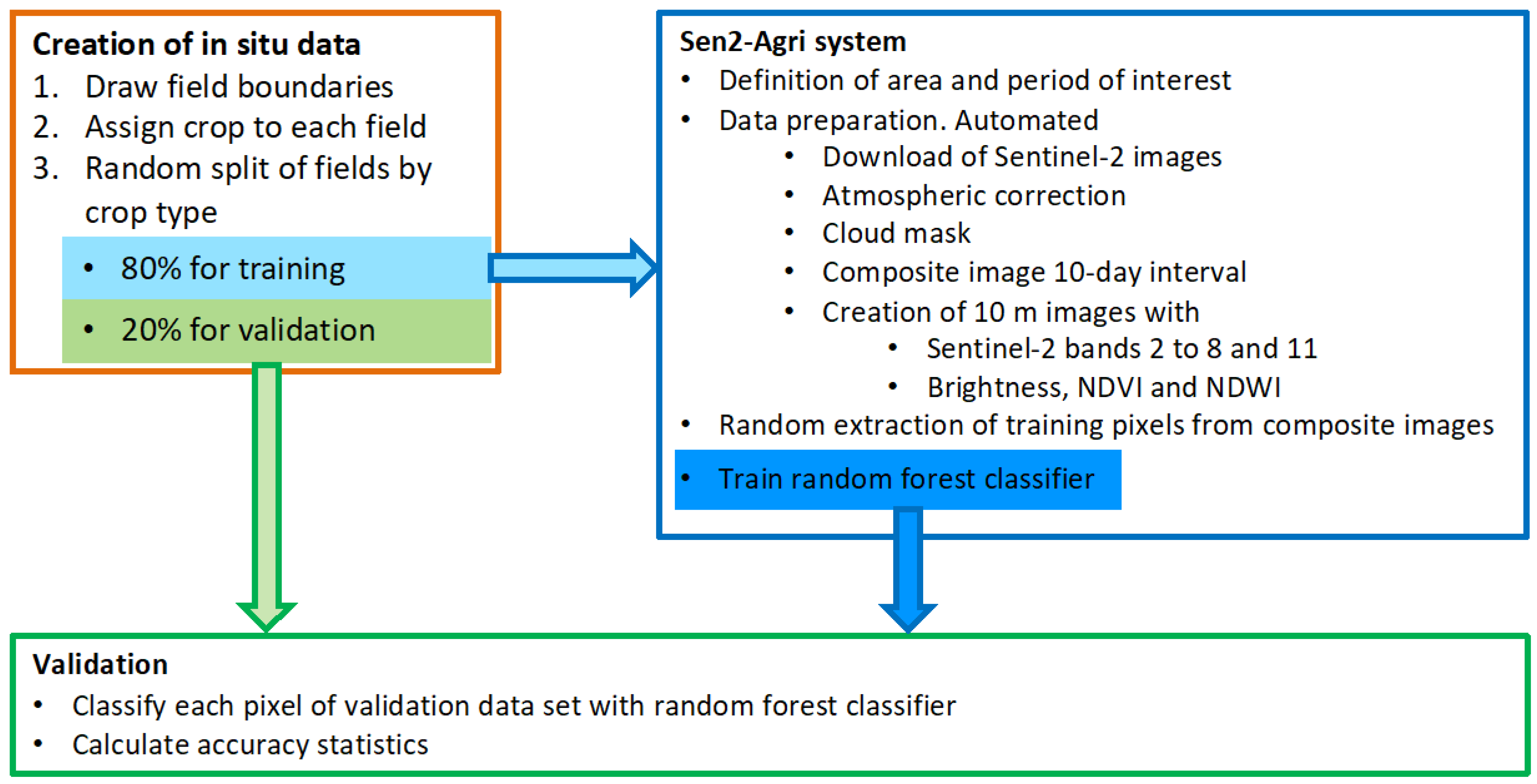
The workflow consisted of three main tasks, as shown in
Figure 1:
Figure 1.
Overview of the workflow.
Figure 1.
Overview of the workflow.
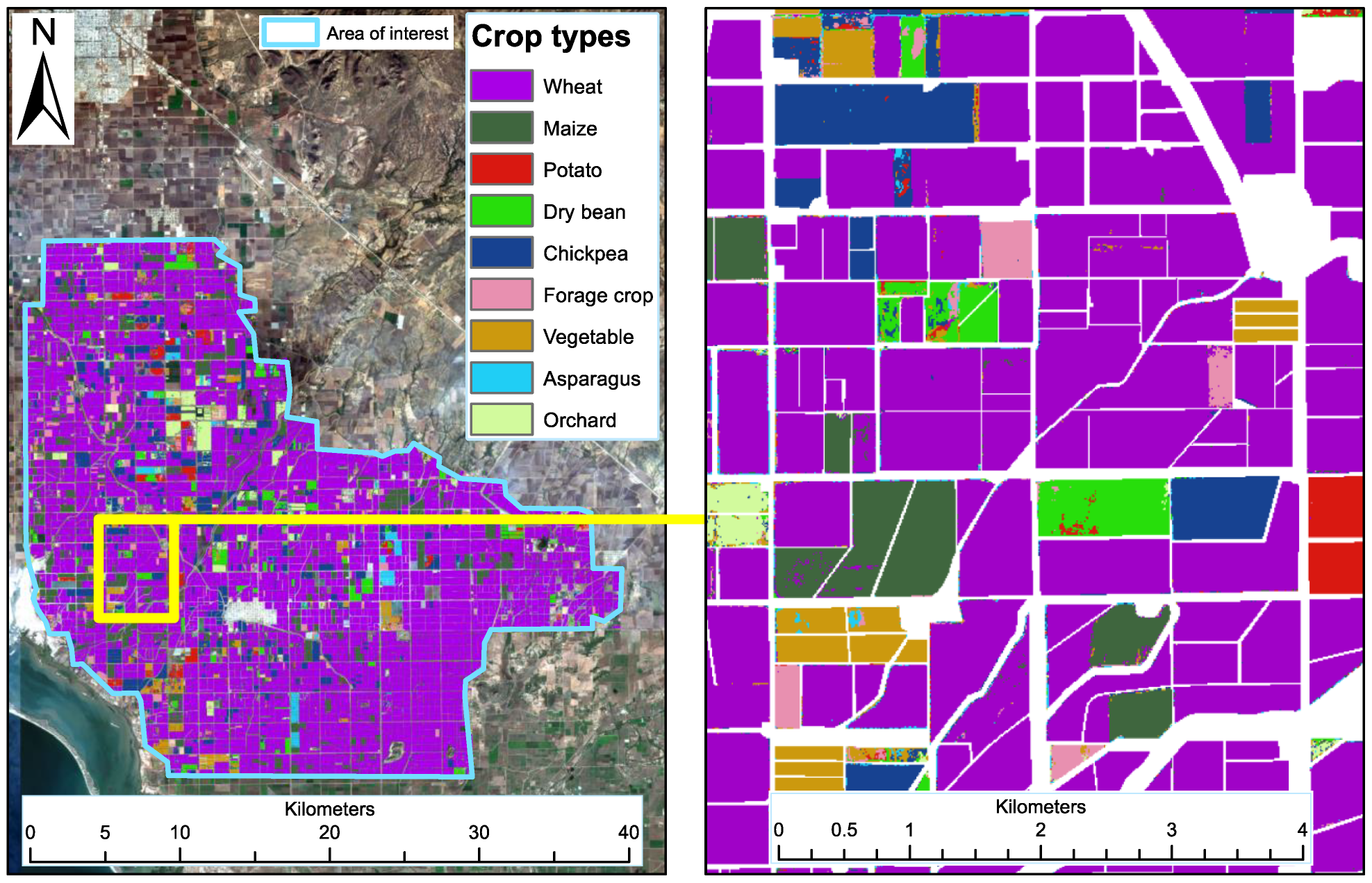
2.2. Characteristics of the Study Region and In Situ Data Preparation
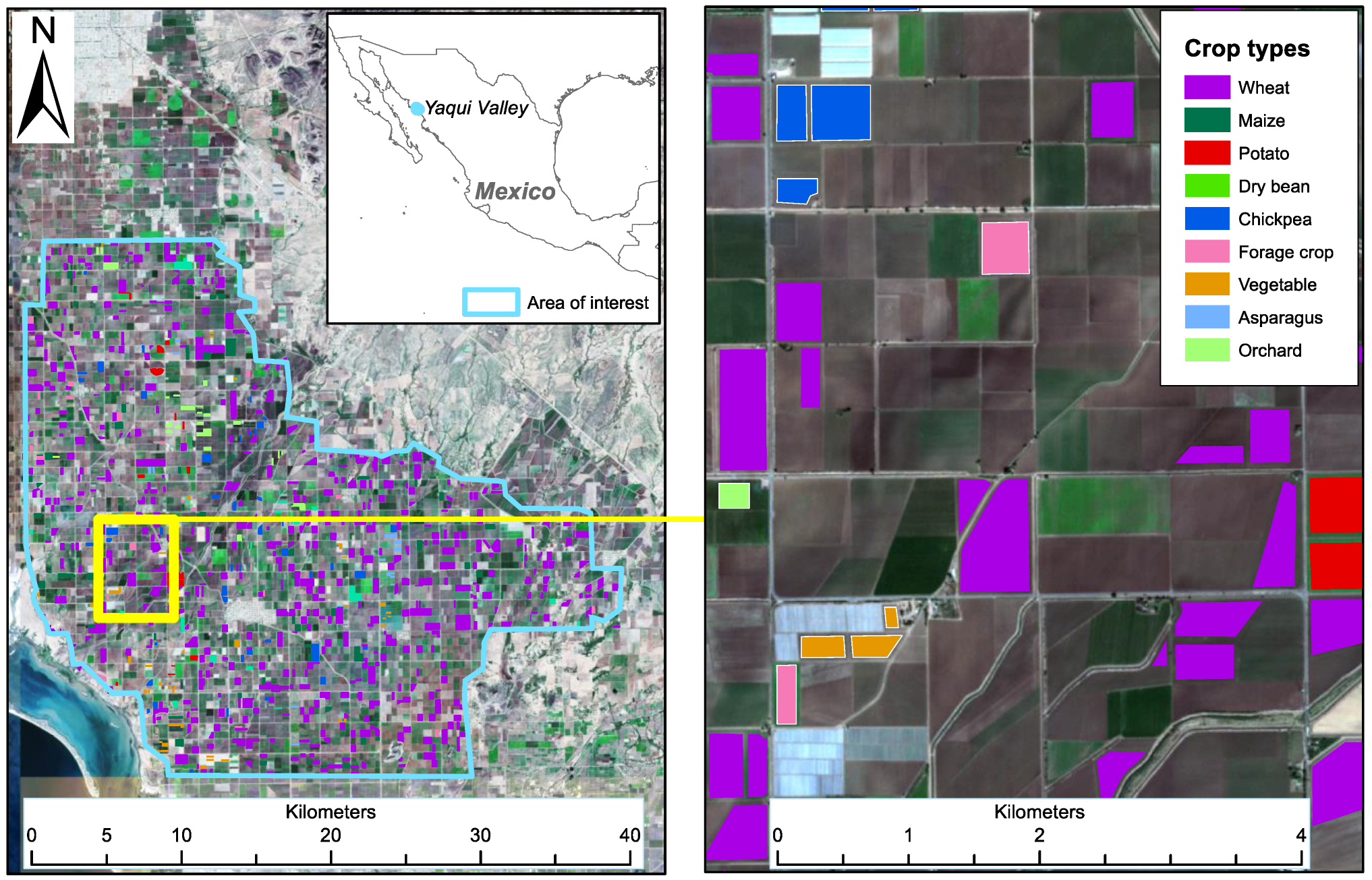
Our study region is located in the Northwest of Mexico, in the Yaqui Valley, where farmers grow crops under irrigated conditions during the winter months. Wheat, the dominant crop, is usually sown between mid-November and mid-December (
Table 1). However, some fields are sown as late as early January. Among the other eight crops that will be referred to as minority crops in this study, maize and chickpea were the most important ones. Sen2-Agri was developed with the primary goal of identifying major annual field crops, although we also included some permanent crops such as asparagus, alfalfa and pasture (grassland), as well as tree fruit and nuts, categorized as orchard. Alfalfa and pasture were categorized as forage crop. The fields near the coast showed more variability in the normalized difference vegetation index (NDVI) than those at a further distance, presumably due to elevated levels of soil salinity [
24]. However, we did not create an additional stratum for those fields.
The focus of this study is on the identification of crops within known field boundaries. Therefore, we did not generate a crop mask because any error in the crop mask would have led to the omission of crop or inclusion of non-crop pixels. The planners of the Yaqui Valley irrigation scheme had divided the land into blocks measuring 2 by 2 km. The blocks were further subdivided into 40 lots, each measuring 10 ha. The blocks and lots were numbered consecutively. At the beginning of the winter growing season, the irrigation district, called Distrito del Riego del Rio Yaqui, requires each farmer to declare the type of crop they plan to grow on each irrigated lot. Most farmers do not follow the initial lot boundaries any more. Some lots were split up, whereas most were merged. If farmers had merged several lots, they would use the number of their first lot as an anchor and also report the area of the entire field, i.e., the merged lots, that were planted with the same crop. Based on the farmer’s declarations, which include the crop type, block, lot and field size, the crop types were then assigned to the field boundaries, which had been manually drawn beforehand, using a Sentinel-2 image from 13 March 2017 as a background. This resulted in 6048 labeled fields (
Figure 2). The average area of a field was 11.5 ha. Subsequently, they were randomly split into two sets: 80% of the fields of each crop type were set aside for training, and the remaining 20% were used for independent validation of the classifications (
Table 2). Thus, all accuracy assessments were conducted against the same set of validation data. To reduce the effects of mixed border pixels, we applied a 1-pixel (10 m) inner buffer to all fields that were used for training but not for validation.
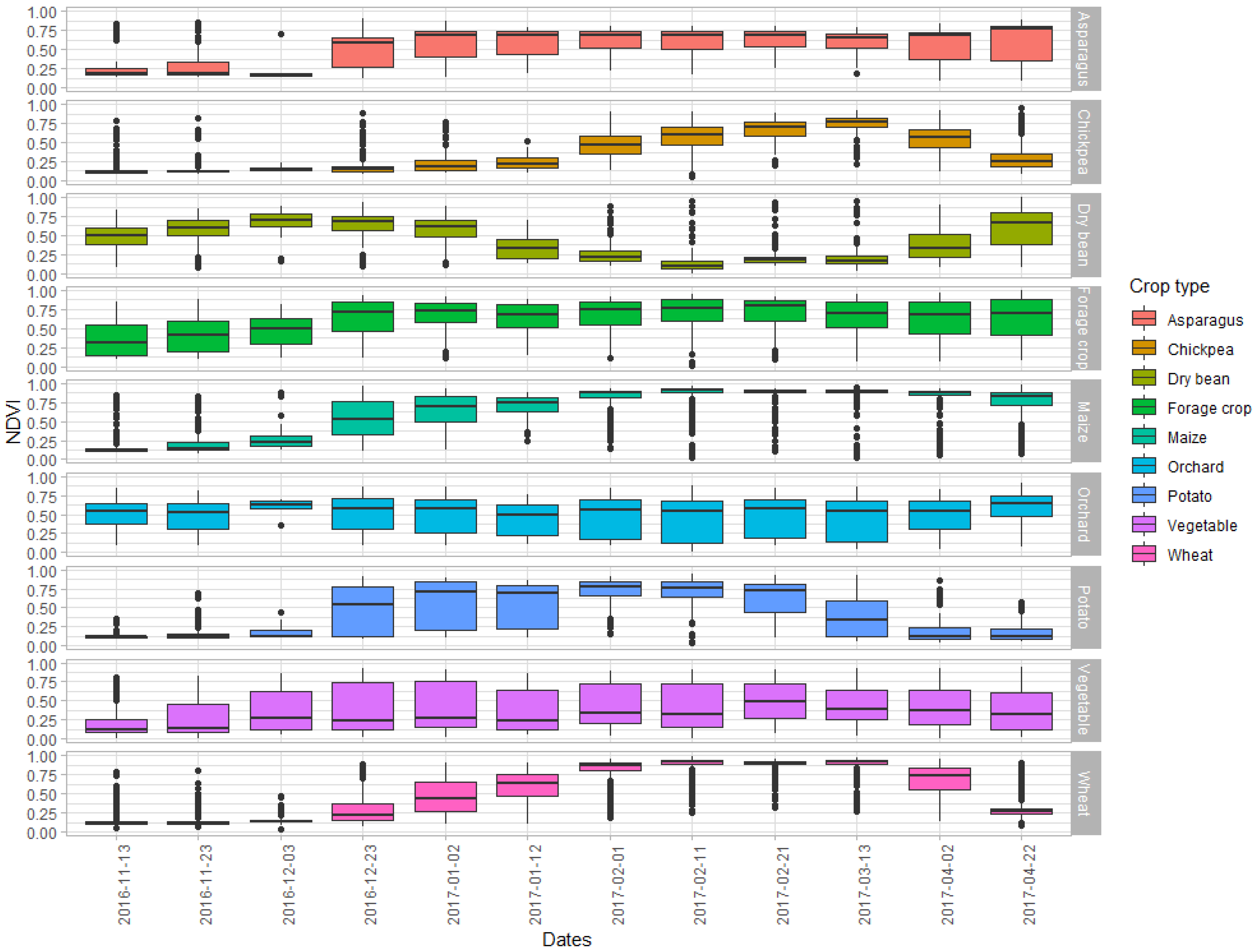
All in all, 12 images, acquired by Sentinel-2A for tile 12RXR between 13 November 2016, and 22 April 2017, could be used for the analysis. The acquisition dates are shown in
Figure 3, together with the dynamics of the NDVI [
25] of the labeled fields across the growing season.
2.3. Sen2-Agri Crop Classification System
Sen-Agri had been designed to run crop classifications in an operational manner [
5]. It automatically downloads the images for a defined area of interest (AOI) or accesses them when set up in a cloud infrastructure; it masks out clouds and shadows and applies an atmospheric correction using the MACCS ATCOR Joint Algorithm (MAJA) [
26]. Masked-out pixels are gap filled, based on a linear interpolation between cloud-free pixels of the previous and subsequent image(s). This results in a series of images with a 10-day interval spanning the entire growing season. For the crop classification, Sen2-Agri uses the 10 m bands (2, 3, 4 and 8) of Sentinel-2, the 20 m red-edge bands (5, 6 and 7) and the SWIR band (11), resampled to 10 m. In addition to the surface reflectance of the different bands, Sen2-Agri calculates NDVI, the normalized difference water index (NDWI) [
27] and brightness, defined as the Euclidean norm of the surface reflectance values in bands 3, 4, 8 and 11.
For the cropland and crop-type identification, the user needs to supply a shapefile with polygons of the in situ data. If needed, it is possible to stratify the target area to accommodate differences in climate, soil, or management practices. Although Sen2-Agri requires the user to prepare the training data as polygons, it does the crop classification at the pixel level. The in situ data typically represent entire crop fields. Sen2-Agri splits them into a training and a separate, independent validation data set. The default split is 75% of the fields of each crop type for training and 25% for validation. The system then puts all the training pixels into one bag and the validation pixels into another. When drawing the pixels from the training bag, it does not consider the crop type. This implies that the more pixels of a given crop type are provided, the higher its chances of being used for training. Having been developed for practitioners, the Sen2-Agri system is optimized for predefined sequences of operations, and only a few intermediary products are stored to reduce the required storage capacity.
Sen2-Agri can also process 30 m Landsat-8 images. However, we did not include them because the fields of the minority crops tended to be small (
Table 1), which would have resulted in many mixed pixels. Relying on a toolbox did not allow us to test the behavior of other classification algorithms, nor could we fine-tune the algorithm by optimizing various parameters.
2.4. Scenarios
To assess the impact of the size and composition of the training data on the resulting classification accuracies, we tested different scenarios:
Scenario 1, called “Ratio”: Different ratios were randomly drawn from the training data set, maintaining the proportional representation of the crop types. Based on the 80% of the fields set aside for training, we tested the following ratios: 0.08, 0.10, 0.12, 0.18, 0.31 and 0.64. Thus, the smallest ratio (0.08) corresponds to 6.4% of the fields and the highest ratio (0.64) to 49.6% of the fields of the study area. Potato with 105, and asparagus with 131 labeled fields, constrained the boundary for the lowest ratio that could be realistically tested. The number of fields available for each crop type and ratio level is listed in
Table 2.
Scenario 2, called “Equal”: In this scenario, each crop type was represented by the same number of fields for the training of the classifier. We increased the number of fields by 10, from 10 to 80, resulting in eight levels. For each level, the random selection of the fields was made separately.
Scenario 3, called “In-season”: To determine how early and accurately crops can be identified in the season, we ran Ratio-0.31 over four different periods, at monthly increments. We had picked this ratio for the analysis because the results from Scenario 1 indicated that its classification accuracies were relatively stable and did not fluctuate much. All four periods started in November and ended in January, February, March or April.
Scenario 4, called “Binary in-season classification”: To test the feasibility of focusing on just one crop, we created two classes: (1) crop of interest; in this analysis, this was either maize or wheat, and (2) all other classes merged into a single class, non-maize or non-wheat, respectively. In addition, we wanted to assess how early in the season it would be possible to identify either.
2.5. Nomenclature and Statistical Analyses
We used the following naming convention: a crop classification conducted for a proportional representation of fields is called “Ratio” followed by the fraction of fields used; e.g., “Ratio-0.08” stands for a proportional use of 8% of the fields of each crop type. Likewise, “Equal-10” uses ten fields of each crop type. To smooth out the random variability of the performances of each classifier, the treatments for scenarios Ratio and Equal were run six times. Each run was initiated with a different random seed number.
All classification results reported in this paper are based on the same 20% of fields of each crop type set aside initially for an independent validation of the classifications. We used the standard confusion matrix to summarize the classification accuracies at the pixel level. The following statistical parameters were calculated: precision, recall, F-score and OA [
28].
3. Results
3.1. Evolution and Dispersion of Crop-Specific NDVI over Time
The dynamics of NDVI distribution per crop vs. time during the investigation period are shown in
Figure 3. The two main crops, wheat and maize, indicate considerable heterogeneity in NDVI during the late December and January period, presumably resulting from a wide range in sowing dates. These two crops had similar NDVI development patterns, although the plateau was more prolonged for maize. Most wheat fields had reached senescence by late April, whereas most maize fields were still green. Forage fields, which are being cut several times during the winter growing season, exhibited a wide range of NDVI throughout the monitoring period. Asparagus, another permanent crop, had low vegetation cover during its main harvest period in November and December. For orchards, the average NDVI remained stable. Most dry bean fields were sown in October and reached maturity in January. However, the graph also shows a few fields that were sown as late as January. Chickpea fields were sown last, in late January. There was considerable spread during the planting and harvest periods among the potato fields. The majority was planted in December and got harvested by March. The vegetable class, which was quite diverse and consisted of different types of tomato, broccoli, pumpkin, salads and others, had no uniform development either.
3.2. Classification Results for Ratio and Equal
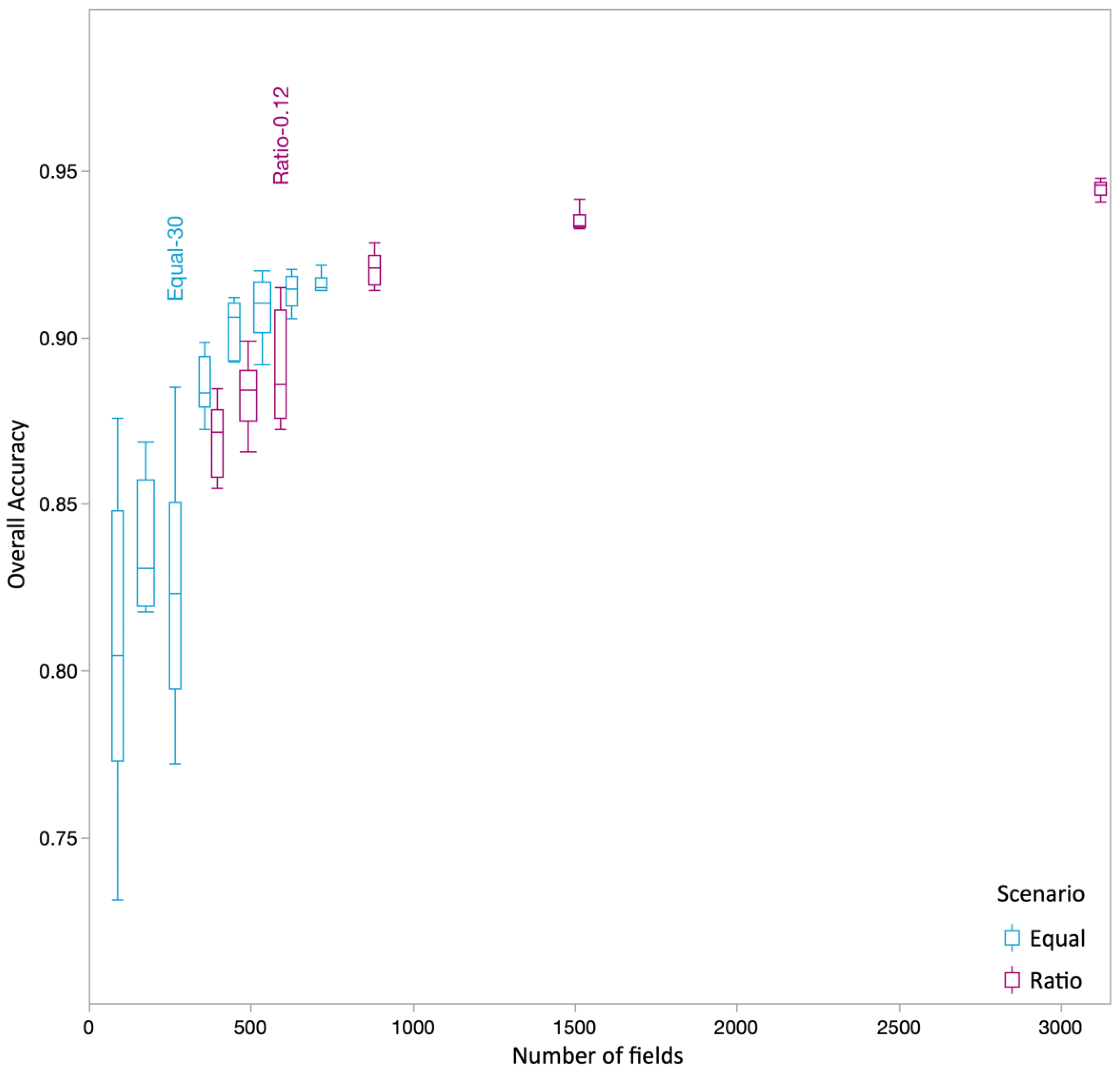
Our data set allowed us to investigate the limits of accuracy that can be obtained by using a relatively large number of fields for the training of the RF classifier. As expected, using more fields resulted in higher OAs for both Ratio and Equal (
Figure 4). The three Ratio treatments with the highest number of fields, Ratio-0.18 (876 fields), Ratio-0.31 (1509 fields) and Ratio-0.64 (3018 fields), achieved a higher OA than the best Equal treatment, which was based on 80 fields per crop or 720 in total. A relatively large range in OAs was observed for the three Equal and Ratio treatments with the lowest number of training fields in their respective categories, indicating unstable classifications. When the number of fields was in a similar range, i.e., 360 to 630, Equal trended higher than Ratio. For Ratio, only a slight improvement was observed when increasing the number of training fields above 876. For Equal, the increase started to level off after 540 fields in total, or 60 fields per crop.
To illustrate the classification challenges, we first compared the results from two scenarios: Ratio-0.18 and Equal-80 (
Table 3). They had identical OAs of 0.92. For Equal, this was the highest OA that could be achieved. For Ratio-0.18, 618 wheat fields were used for training, together with a combined total of 258 fields representing the other eight crop types. Their numbers ranged from 15 potato to 52 maize fields (
Table 2). This contrasts with 80 fields of each crop type and a total of 720 fields used for Equal.
Figure 5 shows the classification results obtained for Ratio-0.18, using a random seed of zero. There were few misclassified pixels within the wheat fields, whereas misclassified pixels were well noticeable within the dry bean fields.
For Ratio-0.18, wheat achieved the highest precision (0.98) and recall (0.96). The high precision indicates that the error of commission was only 2%. Since wheat was the predominant crop, the total of 37,345 pixels misclassified as wheat still caused relatively large errors in the precision of the other crops. It accounted for 87% of the errors in maize and 46% in chickpea, 36% in potato, 35% in forage crop, and 33% in vegetable and asparagus. Pixels misclassified as potato and vegetable also contributed a combined 63% to the classification errors in dry bean, causing a relatively low precision of 0.74. Chickpea achieved the second highest recall (0.90), whereas its precision (0.84) ranked third, after wheat and maize. Forage crop had the lowest precision (0.44) and second lowest recall (0.59). Only vegetable had a lower recall (0.56). Precision of asparagus was also low (0.48), but its recall ranked fourth (0.79). Confusion with wheat, orchard and dry bean was the main cause for its low precision.
For Equal-80, similar results as for Ratio-0.18 were observed. However, a larger number of maize and forage crop pixels were misclassified as wheat, causing a drop in recall of wheat to 0.94, as compared to 0.96 in Ratio. Wheat pixels that were not classified as such were the predominant source of error in the precision of the other crops. They accounted for 96% of the errors in the precision of maize and more than 60% in vegetable, forage crop and chickpea. Another reason for the high percentage contribution of wheat to the error of precision of the minority crops was that among them, fewer pixels got misclassified. In Equal-80, 42,237 pixels got misclassified, whereas, in Ratio-0.18, the number was 55,030. The opposite pattern was observed for the false positive pixels classified as wheat, although the differences between Equal and Ratio were smaller. On average, precision for all minority crops was 0.66 for Ratio and 0.67 for Equal, and recall was 0.72 for Ratio and 0.83 for Equal. The largest improvements in recall of Equal over Ratio were observed for forage crop, potato and chickpea. Chickpea was the only crop with a higher recall in Ratio than in Equal.
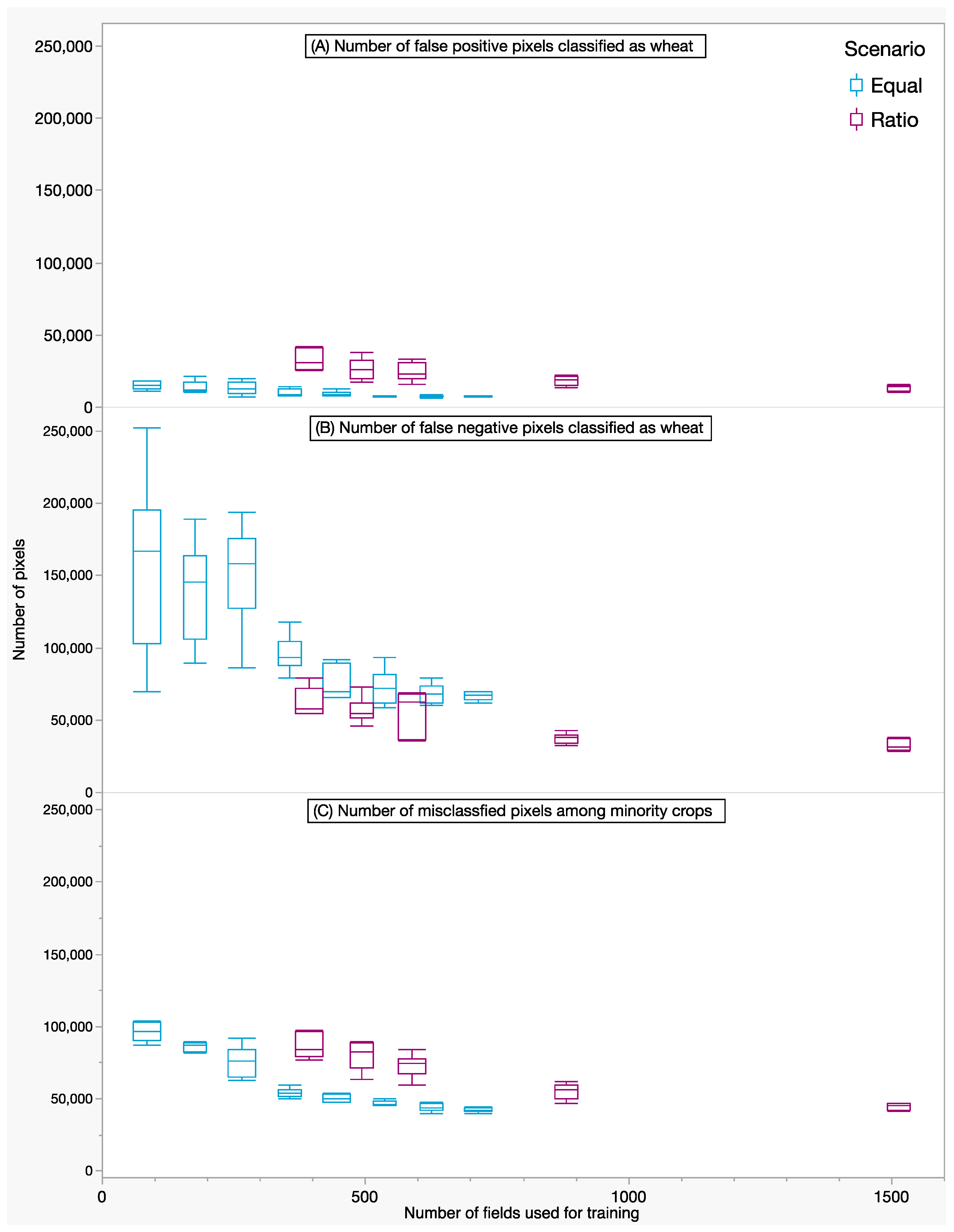
Figure 6 shows that the differences between Equal and Ratio were persistent among all treatment levels. For a given number of fields, the errors of omission (number of false negative pixels) in wheat were larger for Equal than for Ratio. For Equal-10 to 30, the average number was much higher and more variable than for the other scenario levels. On the other hand, Ratio for wheat had a higher number of false positive pixels than the Equal scenarios for a similar number of training fields. When considering only the misclassifications among the minority crops, Equal clearly had fewer misclassifications than Ratio for the range in which the number of training fields was similar.
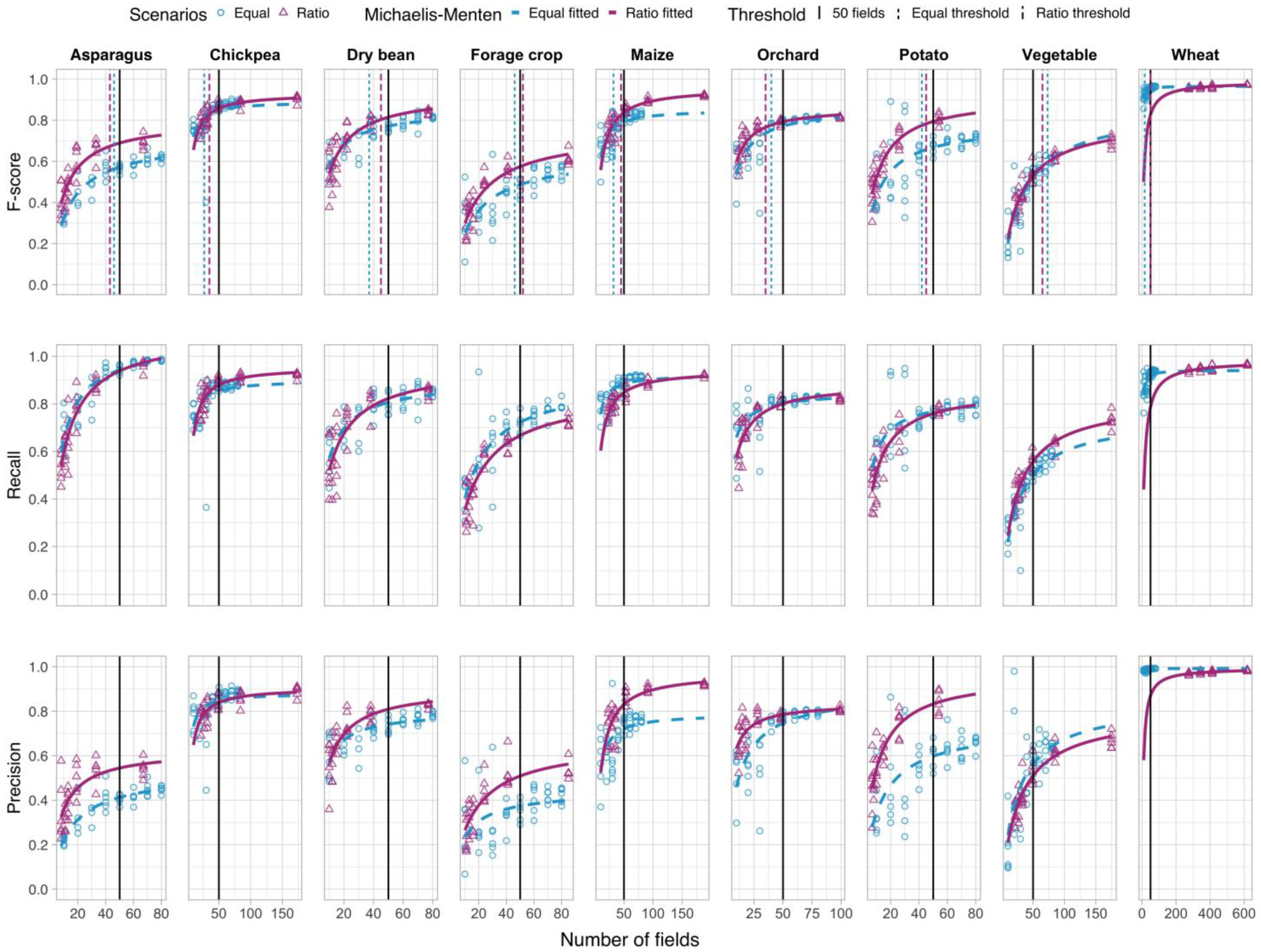
3.3. How Many Fields Are Needed for Training?
To determine the optimal number of fields required for training, we analyzed the resulting F-score, recall and precision of each crop type (
Figure 7) under the Ratio and Equal scenarios. As a breakpoint at which it may not be worthwhile to add more fields to the training data, we set a somewhat arbitrary threshold, at which the increase in the F-scores falls to less than 2.5% for an additional ten fields of a given crop type used for training. A dotted vertical line marks this point in the F-score boxes of
Figure 7, where the slope of the first derivative of the Michaelis-Menten curve [
29] had declined to 0.0025.
The F-scores indicate that for a given number of training fields per crop type, Ratio tended to perform better than Equal for most crops. Overall, wheat, followed by chickpea, was classified with the highest accuracy. For the Equal treatments of wheat with a low field number, recall tended to range between 0.8 and 0.9. Since wheat represented about 75% of the crop pixels in the study area, an omission error of 10–20% resulted in a large number of misclassified pixels, which in turn decreased the other crops’ precision. For asparagus and dry bean, Equal failed to identify these crops in a total of four instances. The resulting data points with a value of zero were excluded from the fitted Michaelis-Menten curves. Chickpea, forage crop, orchard and potato of the Equal scenario also had a few data points that largely deviated from the fitted curves.
The fitted curves for recall followed similar patterns for Equal and Ratio. The largest difference was observed for vegetables, where Equal did not perform as well as Ratio. Precision of Equal tended to be lower than of Ratio for most crops, except for chickpea, vegetables and wheat.
The impact of adding more fields to the training sets on the F-score leveled off, i.e., the rate of return or increase in accuracy gradually diminished. The threshold of an increase in F-score by 2.5% for an additional ten fields was reached with fewer fields by the Ratio treatment for asparagus, orchard and vegetables. For the other crops, Ratio required more fields than Equal. On average, Equal reached the breakpoint with 40 fields (Std 15.7) and Ratio with 46 fields (Std 9.1). However, the higher average of Ratio was mainly due to wheat.
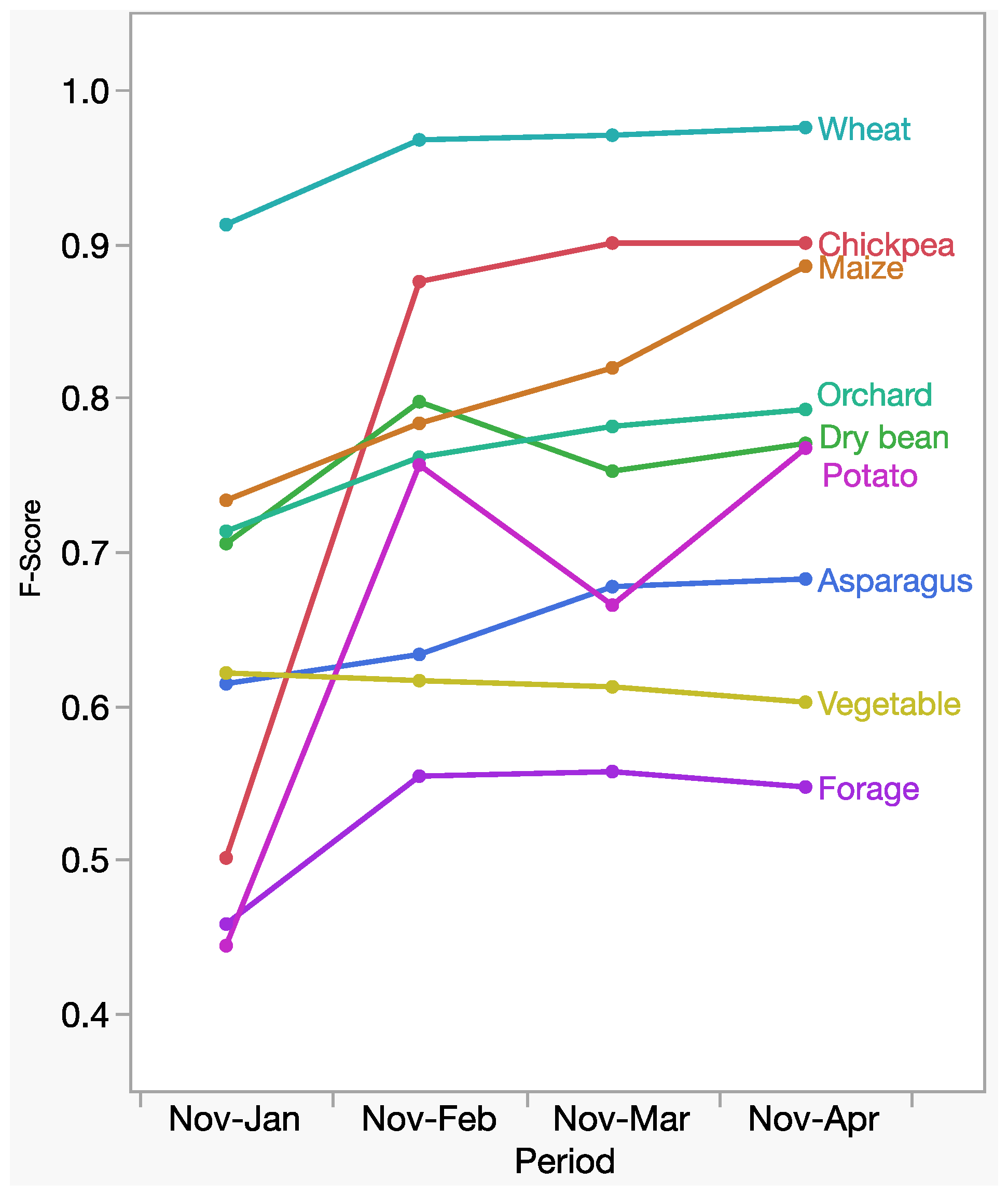
3.4. Change of Classification Accuracy across the Season
We investigated how the classification accuracies improve over the course of the cropping season by comparing four periods based on the Ratio-0.31 treatment (
Figure 8). The results for the first period, November to January, were generally the least accurate in terms of the F-score. The only exception was vegetable, which did not improve over time. The F-scores for wheat (0.97) and forage crops (0.55) had reached a plateau by February, and adding images acquired thereafter did not improve them any further. Maize steadily improved from 0.73 in January to 0.88 in April, whereas orchard increased from 0.71 to 0.79 over the same periods. Potato and dry bean, both of which are harvested in March, saw a drop in the November to March period, as compared to the previous period ending in February.
3.5. Binary In-Season Classification
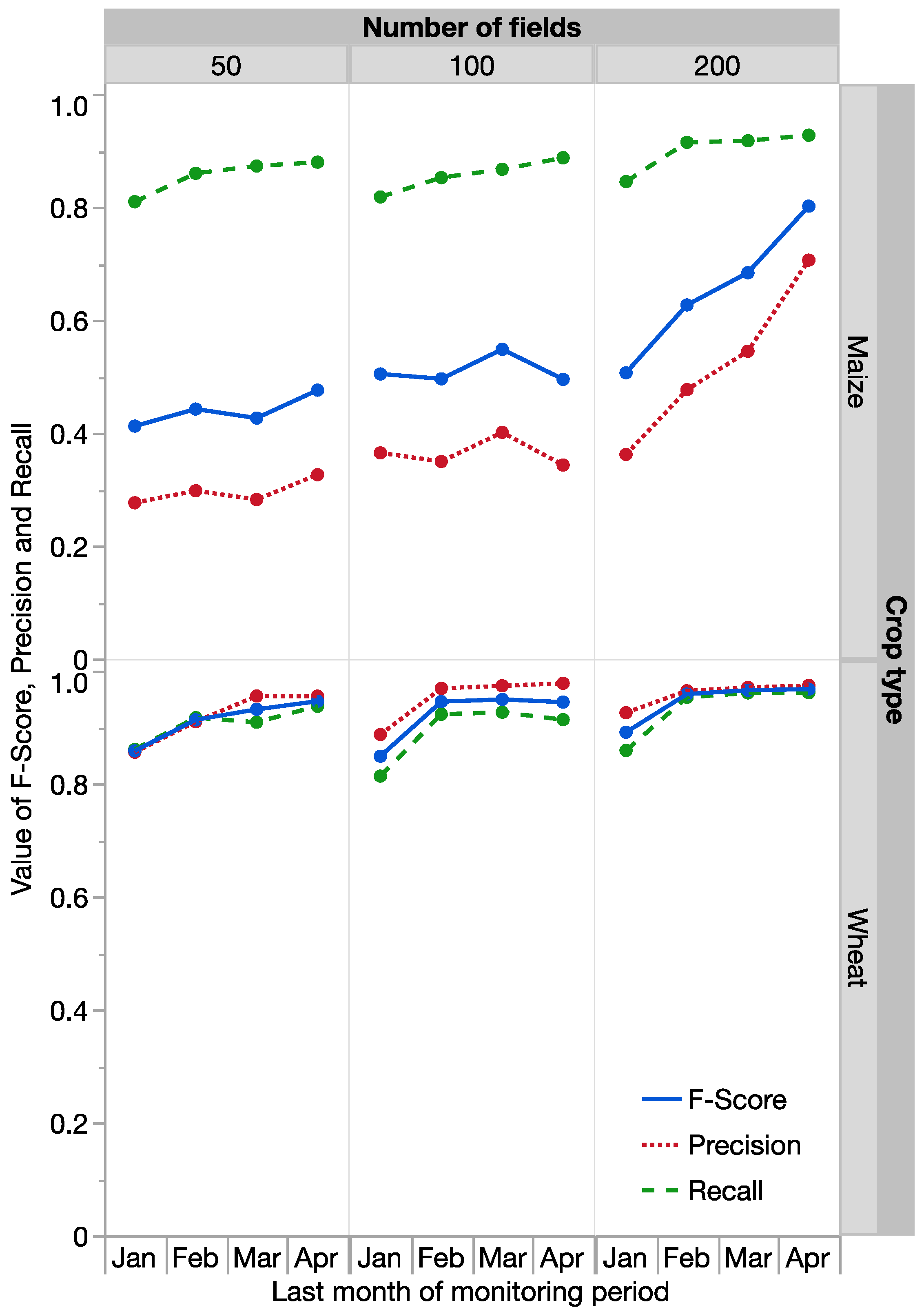
We conducted a similar in-season analysis for the binary scenarios. For maize with 50 and 100 fields, precision remained low throughout the season, but it gradually increased over time for the treatment with 200 fields (
Figure 9). However, its recall was above 0.8 in all instances. For wheat, high precision and recall were achieved. Accuracies for the period from November to January tended to be slightly lower than for the longer periods, for which F-scores in the range of 0.91 to 0.97 were observed.
5. Conclusions
We aimed to generate guidance for the practitioners who are using Sen2-Agri or Sen4Cap in an operational manner. Sen2-Agri can achieve high classification accuracies by the time the crops reach peak NDVI when F-scores higher than 0.95 were obtained for wheat, which was the dominant crop. The test of whether Sen2-Agri is suitable for a binary classification gave mixed results: It worked well for wheat, which dominated the landscape. For maize, a recall above 0.8 could be obtained with only 50 fields, but precision was low. Thus, binary classifications must be carefully examined before applying them at large scales. A proportional representation of the crop types in the data set for training results in better classification accuracies, not only for the dominant crop but also for the minority crops. An accurate classification of the dominant crop reduces the errors of commission for the minority crops. It seems that there is not only an optimal number but also a minimal number of fields that need to be considered for training: Using less than 30 fields yielded unstable results. For the minority crops, the optimal is around 40–45 fields for training, whereas the number for the dominant crops is higher, resulting in a total of around 500 fields. However, additional testing should be done in regions with more than one dominant crop or with frequent cloud cover. Sen2-Agri generates standardized data at a 10-day interval. Hence, it might be possible to apply a classifier developed in one year to images acquired in a different year over the same region. This would be a great step forward toward fully automating crop identification.





 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}