


MS4D-Net: Multitask-Based Semi-Supervised Semantic Segmentation Framework with Perturbed Dual Mean Teachers for Building Damage Assessment from High-Resolution Remote Sensing Imagery


Abstract
:1. Introduction
2. Related Work
2.1. Building Damage Assessment
2.2. Semi-Supervised Semantic Segmentation
2.3. Semi-Supervised Learning for Building Damage Recognition
3. Methodology
3.1. Basic Model Architecture with Post-Processing
3.1.1. Multitask-Based SIAMESE Network
3.1.2. Loss Function
3.1.3. Object-Based Post-Processing
3.2. Semi-Supervised Semantic Segmentation Framework
3.2.1. Perturbed Dual Mean Teachers
3.2.2. Confidence Weighting
4. Experiment Setting
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
5. Experimental Results
5.1. Comparison with SL Competitors
5.2. Comparison with SSL Competitors
6. Discussion
6.1. Ablation Study
6.2. Time Analysis
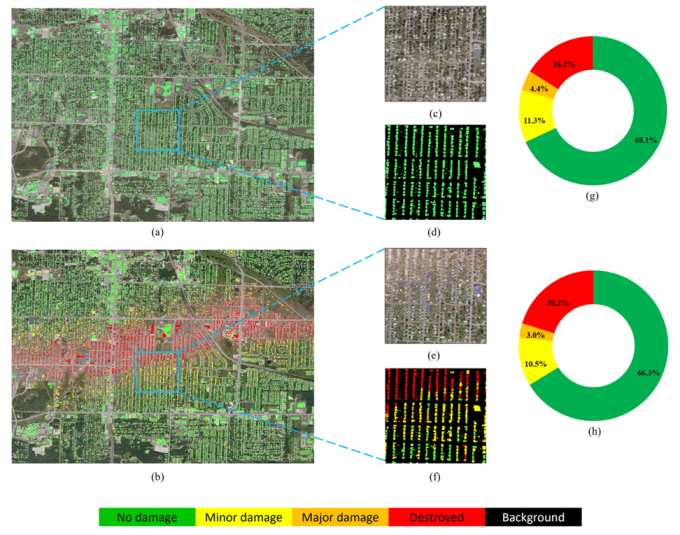
6.3. Damage Assessment of an Example Region
6.4. Limitations and Prospects
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ci, T.; Liu, Z.; Wang, Y. Assessment of the Degree of Building Damage Caused by Disaster Using Convolutional Neural Networks in Combination with Ordinal Regression. Remote Sens. 2019, 11, 2858. [Google Scholar] [CrossRef] [Green Version]
- Schweier, C.; Markus, M. Classification of Collapsed Buildings for Fast Damage and Loss Assessment. Bull. Earthq. Eng. 2006, 4, 177–192. [Google Scholar] [CrossRef]
- Liao, C.; Wang, J.; Xie, Q.; Baz, A.A.; Huang, X.; Shang, J.; He, Y. Synergistic Use of Multi-Temporal RADARSAT-2 and VENµS Data for Crop Classification Based on 1D Convolutional Neural Network. Remote Sens. 2020, 12, 832. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. Building Damage Assessment for Rapid Disaster Response with a Deep Object-Based Semantic Change Detection Framework: From Natural Disasters to Man-Made Disasters. Remote Sens. Environ. 2021, 265, 112636. [Google Scholar] [CrossRef]
- Gupta, R.; Goodman, B.; Patel, N.; Hosfelt, R.; Sajeev, S.; Heim, E.; Doshi, J.; Lucas, K.; Choset, H.; Gaston, M. Creating XBD: A Dataset for Assessing Building Damage from Satellite Imagery. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 10–17. [Google Scholar]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C.; Pan, D.; Chen, J.; Xiao, L.; Du, Q. BDANet: Multiscale Convolutional Neural Network with Cross-Directional Attention for Building Damage Assessment from Satellite Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Cotrufo, S.; Sandu, C.; Giulio Tonolo, F.; Boccardo, P. Building Damage Assessment Scale Tailored to Remote Sensing Vertical Imagery. Eur. J. Remote Sens. 2018, 51, 991–1005. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A Review on Deep Learning in UAV Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Oludare, V.; Kezebou, L.; Panetta, K.; Agaian, S. Semi-Supervised Learning for Improved Post-Disaster Damage Assessment from Satellite Imagery. In Proceedings of the Multimodal Image Exploitation and Learning 2021, SPIE Conference Proceedings, Online, 12–16 April 2021; Volume 11734, pp. 172–182. [Google Scholar]
- Reddy, Y.C.A.P.; Viswanath, P.; Reddy, B.E. Semi-Supervised Learning: A Brief Review. Int. J. Eng. Technol. 2018, 7, 81–85. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Wei, F.; Hu, H.; Ye, Q.; Cui, J.; Wang, L. Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 22106–22118. [Google Scholar]
- Liu, Y.; Tian, Y.; Chen, Y.; Liu, F.; Belagiannis, V.; Carneiro, G. Perturbed and Strict Mean Teachers for Semi-Supervised Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4248–4257. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results. In Proceedings of the 31 Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ke, Z.; Wang, D.; Yan, Q.; Ren, J.; Lau, R. Dual Student: Breaking the Limits of the Teacher in Semi-Supervised Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6727–6735. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation With Cross-Consistency Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12671–12681. [Google Scholar]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.-L.; Bian, X.; Huang, J.-B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021; pp. 1–18. [Google Scholar]
- French, G.; Laine, S.; Aila, T.; Mackiewicz, M.; Finlayson, G. Semi-Supervised Semantic Segmentation Needs Strong, Varied Perturbations. In Proceedings of the 31st British Machine Vision Conference, Online, 7–10 September 2020; pp. 1–21. [Google Scholar]
- Ke, Z.; Qiu, D.; Li, K.; Yan, Q.; Lau, R.W.H. Guided Collaborative Training for Pixel-Wise Semi-Supervised Learning. In Proceedings of the 16th IEEE European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 429–445. [Google Scholar]
- He, Y.; Wang, J.; Liao, C.; Shan, B.; Zhou, X. ClassHyPer: ClassMix-Based Hybrid Perturbations for Deep Semi-Supervised Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 879. [Google Scholar] [CrossRef]
- Kang, J.; Wang, Z.; Zhu, R.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. PiCoCo: Pixelwise Contrast and Consistency Learning for Semisupervised Building Footprint Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10548–10559. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Zhang, Y.; Liao, C. Enhancement of Urban Floodwater Mapping From Aerial Imagery With Dense Shadows via Semi-Supervised Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9086–9101. [Google Scholar] [CrossRef]
- Chen, J.; Sun, B.; Wang, L.; Fang, B.; Chang, Y.; Li, Y.; Zhang, J.; Lyu, X.; Chen, G. Semi-Supervised Semantic Segmentation Framework with Pseudo Supervisions for Land-Use/Land-Cover Mapping in Coastal Areas. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102881. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Li, Y.; Wan, Y.; Guo, H.; Zheng, Z.; Yang, K. Semi-Supervised Deep Learning via Transformation Consistency Regularization for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 1–15. [Google Scholar] [CrossRef]
- Sun, C.; Wu, J.; Chen, H.; Du, C. SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sens. 2022, 14, 2801. [Google Scholar] [CrossRef]
- Guo, H.; Shi, Q.; Marinoni, A.; Du, B.; Zhang, L. Deep Building Footprint Update Network: A Semi-Supervised Method for Updating Existing Building Footprint from Bi-Temporal Remote Sensing Images. Remote Sens. Environ. 2021, 264, 112589. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A Semisupervised Convolutional Neural Network for Change Detection in High Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5891–5906. [Google Scholar] [CrossRef]
- You, Z.-H.; Wang, J.-X.; Chen, S.-B.; Tang, J.; Luo, B. FMWDCT: Foreground Mixup Into Weighted Dual-Network Cross Training for Semisupervised Remote Sensing Road Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5570–5579. [Google Scholar] [CrossRef]
- Li, Q.; Shi, Y.; Zhu, X.X. Semi-Supervised Building Footprint Generation With Feature and Output Consistency Training. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623217. [Google Scholar] [CrossRef]
- Li, Y.; Ye, S.; Bartoli, I. Semisupervised Classification of Hurricane Damage from Postevent Aerial Imagery Using Deep Learning. J. Appl. Remote Sens. 2018, 12, 045008. [Google Scholar] [CrossRef]
- Saito, K.; Spence, R.J.S.; Going, C.; Markus, M. Using High-Resolution Satellite Images for Post-Earthquake Building Damage Assessment: A Study Following the 26 January 2001 Gujarat Earthquake. Earthq. Spectra 2004, 20, 145–169. [Google Scholar] [CrossRef]
- Dong, L.; Shan, J. A Comprehensive Review of Earthquake-Induced Building Damage Detection with Remote Sensing Techniques. ISPRS J. Photogramm. Remote Sens. 2013, 84, 85–99. [Google Scholar] [CrossRef]
- Lucks, L.; Bulatov, D.; Thönnessen, U.; Böge, M. Superpixel-Wise Assessment of Building Damage from Aerial Images. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech Republic, 25–27 February 2019; pp. 211–220. [Google Scholar]
- Li, P.; Xu, H.; Liu, S.; Guo, J. Urban Building Damage Detection from Very High Resolution Imagery Using One-Class SVM and Spatial Relations. Int. Geosci. Remote Sens. Symp. (IGARSS) 2009, 5, V-112–V-114. [Google Scholar] [CrossRef]
- Qing, Y.; Ming, D.; Wen, Q.; Weng, Q.; Xu, L.; Chen, Y.; Zhang, Y.; Zeng, B. Operational Earthquake-Induced Building Damage Assessment Using CNN-Based Direct Remote Sensing Change Detection on Superpixel Level. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102899. [Google Scholar] [CrossRef]
- Lee, J.; Xu, J.Z.; Sohn, K.; Lu, W.; Berthelot, D.; Gur, I.; Khaitan, P.; Ke-Wei, H.; Koupparis, K.; Kowatsch, B. Assessing Post-Disaster Damage from Satellite Imagery Using Semi-Supervised Learning Techniques. arXiv 2020, arXiv:2011.14004. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.-L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 596–608. [Google Scholar]
- Wu, K.; Otoo, E.; Shoshani, A. Optimizing Connected Component Labeling Algorithms. In Proceedings of the Medical Imaging 2005: Image Processing, San Diego, CA, USA, 12–17 February 2005; Volume 5747, pp. 1965–1976. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–18. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Dunnhofer, M.; Antico, M.; Sasazawa, F.; Takeda, Y.; Camps, S.; Martinel, N.; Micheloni, C.; Carneiro, G.; Fontanarosa, D. Siam-U-Net: Encoder-Decoder Siamese Network for Knee Cartilage Tracking in Ultrasound Images. Med. Image Anal. 2020, 60, 101631. [Google Scholar] [CrossRef]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster Damage Detection through Synergistic Use of Deep Learning and 3D Point Cloud Features Derived from Very High Resolution Oblique Aerial Images, and Multiple-Kernel-Learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Image Pairs | Split | Patch Size (Pixels) | Sensor | Band | ||
|---|---|---|---|---|---|---|---|
| Train | Validation | Test | |||||
| Joplin Tornado | 554 | 368 | 56 | 111 | 512 × 512 | Pre: QuickBird Post: WorldView-2 | RGB |
| Moore Tornado | 767 | 509 | 77 | 154 | 512 × 512 | Pre: WorldView-2 Post: GeoEye-1 | RGB |
| Hurricane Michael | 2065 | 1235 | 351 | 414 | 512 × 512 | Pre: WorldView-2 Post: GeoEye-1 | RGB |
| Dataset | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| No Dmg. | Minor Dmg. | Major Dmg. | Destroyed | |||||
| Joplin Tornado | Siamese U-Net | - | - | 62.35 | 80.46 | 56.72 | 35.71 | 76.51 |
| BDANet | - | - | 64.29 | 82.92 | 59.43 | 38.03 | 76.78 | |
| Ours (MT) | 74.25 | 90.22 | 67.40 | 83.23 | 60.13 | 44.54 | 81.71 | |
| Ours (MT + PP) | 75.53 | 90.22 | 69.24 | 83.01 | 62.47 | 48.50 | 82.98 | |
| Moore Tornado | Siamese U-Net | - | - | 68.74 | 91.33 | 48.48 | 53.06 | 82.07 |
| BDANet | - | - | 69.31 | 90.78 | 47.95 | 55.48 | 83.02 | |
| Ours (MT) | 77.46 | 92.46 | 71.03 | 91.41 | 54.64 | 56.27 | 81.79 | |
| Ours (MT + PP) | 80.11 | 92.46 | 74.82 | 91.37 | 62.63 | 59.76 | 85.53 | |
| Hurricane Michael | Siamese U-Net | - | - | 49.31 | 69.78 | 40.06 | 44.04 | 43.37 |
| BDANet | - | - | 49.59 | 67.75 | 44.75 | 48.30 | 37.58 | |
| Ours (MT) | 60.09 | 83.85 | 49.90 | 71.04 | 41.77 | 48.41 | 38.39 | |
| Ours (MT + PP) | 61.09 | 83.85 | 51.34 | 70.13 | 46.50 | 48.81 | 39.91 | |
| Method | 5% (19) | 10% (38) | 20% (76) | 100% (387) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SL | 59.71 | 82.48 | 49.95 | 63.34 | 84.78 | 54.15 | 69.57 | 86.65 | 62.25 | 75.53 | 90.22 | 69.24 |
| CutMix-Seg | 66.87 | 87.99 | 57.82 | 69.66 | 88.10 | 61.75 | 72.23 | 89.28 | 64.92 | - | - | - |
| PseudoSeg | 67.17 | 83.06 | 60.36 | 69.13 | 87.20 | 61.39 | 71.98 | 88.68 | 64.82 | - | - | - |
| CCT | 67.83 | 87.38 | 59.45 | 68.98 | 88.22 | 60.74 | 72.62 | 89.63 | 65.33 | - | - | - |
| CPS | 68.17 | 87.10 | 60.05 | 70.62 | 88.14 | 63.11 | 72.84 | 89.16 | 65.85 | - | - | - |
| Ours | 70.30 | 88.73 | 62.40 | 71.48 | 88.54 | 64.17 | 73.55 | 89.37 | 66.77 | - | - | - |
| Method | 5% (27) | 10% (54) | 20% (108) | 100% (536) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SL | 72.39 | 88.76 | 65.38 | 74.34 | 90.37 | 67.46 | 75.81 | 91.59 | 69.04 | 80.11 | 92.46 | 74.82 |
| CutMix-Seg | 76.14 | 90.46 | 70.00 | 76.93 | 91.29 | 70.77 | 77.88 | 92.17 | 71.76 | - | - | - |
| PseudoSeg | 76.84 | 88.87 | 71.69 | 77.25 | 91.00 | 71.36 | 78.41 | 91.78 | 72.67 | - | - | - |
| CCT | 74.43 | 91.01 | 67.33 | 76.59 | 91.32 | 70.28 | 77.92 | 92.01 | 71.88 | - | - | - |
| CPS | 76.69 | 89.94 | 71.02 | 77.60 | 90.79 | 71.95 | 78.51 | 91.37 | 72.99 | - | - | - |
| Ours | 77.46 | 91.57 | 71.42 | 78.91 | 91.76 | 73.41 | 79.88 | 92.25 | 74.58 | - | - | - |
| Method | 5% (65) | 10% (130) | 20% (260) | 100% (1300) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SL | 51.82 | 79.81 | 39.82 | 53.94 | 81.36 | 42.19 | 56.17 | 82.93 | 44.71 | 61.09 | 83.85 | 51.34 |
| CutMix-Seg | 55.35 | 82.20 | 43.84 | 57.09 | 82.08 | 46.37 | 58.17 | 82.93 | 47.56 | - | - | - |
| PseudoSeg | 54.00 | 80.82 | 42.51 | 56.49 | 81.56 | 45.74 | 58.35 | 83.39 | 47.62 | - | - | - |
| CCT | 54.18 | 82.29 | 42.14 | 55.61 | 81.47 | 44.52 | 57.78 | 83.02 | 46.96 | - | - | - |
| CPS | 55.55 | 82.24 | 44.11 | 56.31 | 83.13 | 44.81 | 57.34 | 83.63 | 46.08 | - | - | - |
| Ours | 56.52 | 81.94 | 45.62 | 58.06 | 83.45 | 47.18 | 59.43 | 83.87 | 48.96 | - | - | - |
| Baseline | MT | SSL | CW | PP | Joplin Tornado | Moore Tornado | Hurricane Michael | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | - | - | 46.44 | - | - | 61.50 | - | - | 39.45 | ||||
| √ | 57.39 | 82.48 | 46.64 | 70.04 | 88.76 | 62.01 | 51.27 | 79.81 | 39.04 | ||||
| √ | √ | 59.71 | 82.48 | 49.95 | 72.39 | 88.76 | 65.38 | 51.82 | 79.81 | 39.82 | |||
| √ | √ | 68.60 | 88.01 | 60.27 | 74.43 | 91.01 | 67.33 | 52.56 | 79.77 | 40.89 | |||
| √ | √ | √ | 70.00 | 88.01 | 62.27 | 77.03 | 91.01 | 71.03 | 55.23 | 79.77 | 44.72 | ||
| √ | √ | √ | 69.04 | 88.62 | 60.64 | 76.00 | 91.57 | 69.32 | 53.90 | 81.94 | 41.88 | ||
| √ | √ | √ | √ | 71.02 | 88.62 | 63.47 | 77.46 | 91.57 | 71.42 | 56.52 | 81.94 | 45.62 | |
| Dataset | Pipeline | Labeled Data | Training Time (min) | |||
|---|---|---|---|---|---|---|
| Joplin Tornado | SL | 20% (76) | 69.57 | 86.65 | 62.25 | 39 |
| SSL | 5% (19) | 70.30 | 88.73 | 62.40 | 67 | |
| Moore Tornado | SL | 20% (108) | 75.81 | 91.59 | 69.04 | 44 |
| SSL | 5% (27) | 77.46 | 91.57 | 71.42 | 85 | |
| Hurricane Michael | SL | 20% (260) | 56.17 | 82.93 | 44.71 | 79 |
| SSL | 5% (65) | 56.52 | 81.94 | 45.62 | 195 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Wang, J.; Liao, C.; Zhou, X.; Shan, B. MS4D-Net: Multitask-Based Semi-Supervised Semantic Segmentation Framework with Perturbed Dual Mean Teachers for Building Damage Assessment from High-Resolution Remote Sensing Imagery. Remote Sens. 2023, 15, 478. https://doi.org/10.3390/rs15020478
He Y, Wang J, Liao C, Zhou X, Shan B. MS4D-Net: Multitask-Based Semi-Supervised Semantic Segmentation Framework with Perturbed Dual Mean Teachers for Building Damage Assessment from High-Resolution Remote Sensing Imagery. Remote Sensing. 2023; 15(2):478. https://doi.org/10.3390/rs15020478
Chicago/Turabian StyleHe, Yongjun, Jinfei Wang, Chunhua Liao, Xin Zhou, and Bo Shan. 2023. "MS4D-Net: Multitask-Based Semi-Supervised Semantic Segmentation Framework with Perturbed Dual Mean Teachers for Building Damage Assessment from High-Resolution Remote Sensing Imagery" Remote Sensing 15, no. 2: 478. https://doi.org/10.3390/rs15020478