

RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP

Abstract
:1. Introduction
1.1. Remote Image Segmentation Method Based on CNN
1.2. Remote Image Segmentation Method Based on Transformer
1.3. Remote Image Segmentation Method Based on CNN and Transformer
1.4. Contributions
1.5. Article Structure
2. Methods and Data
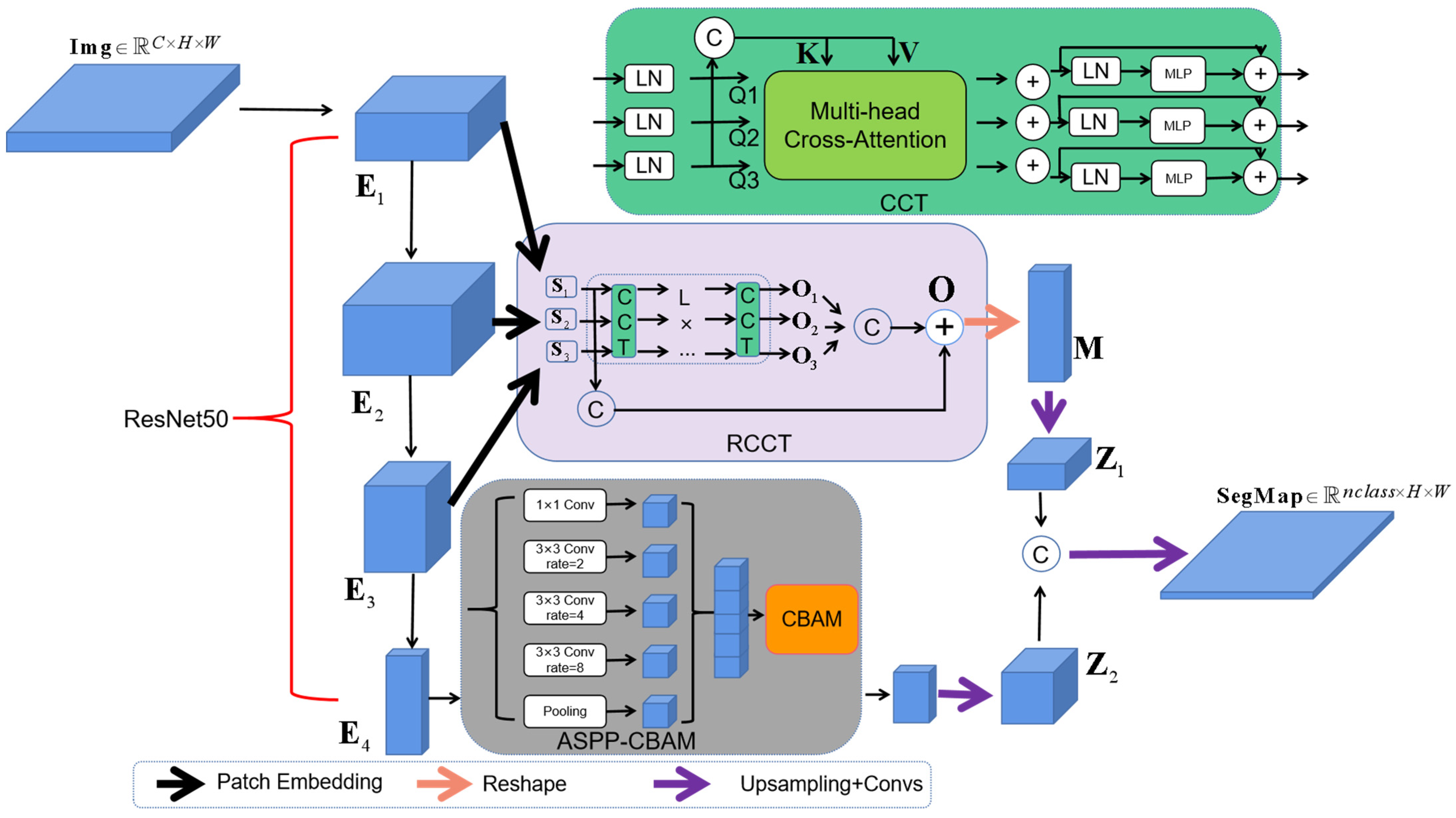
2.1. RCCT-ASPPNet Model Overview
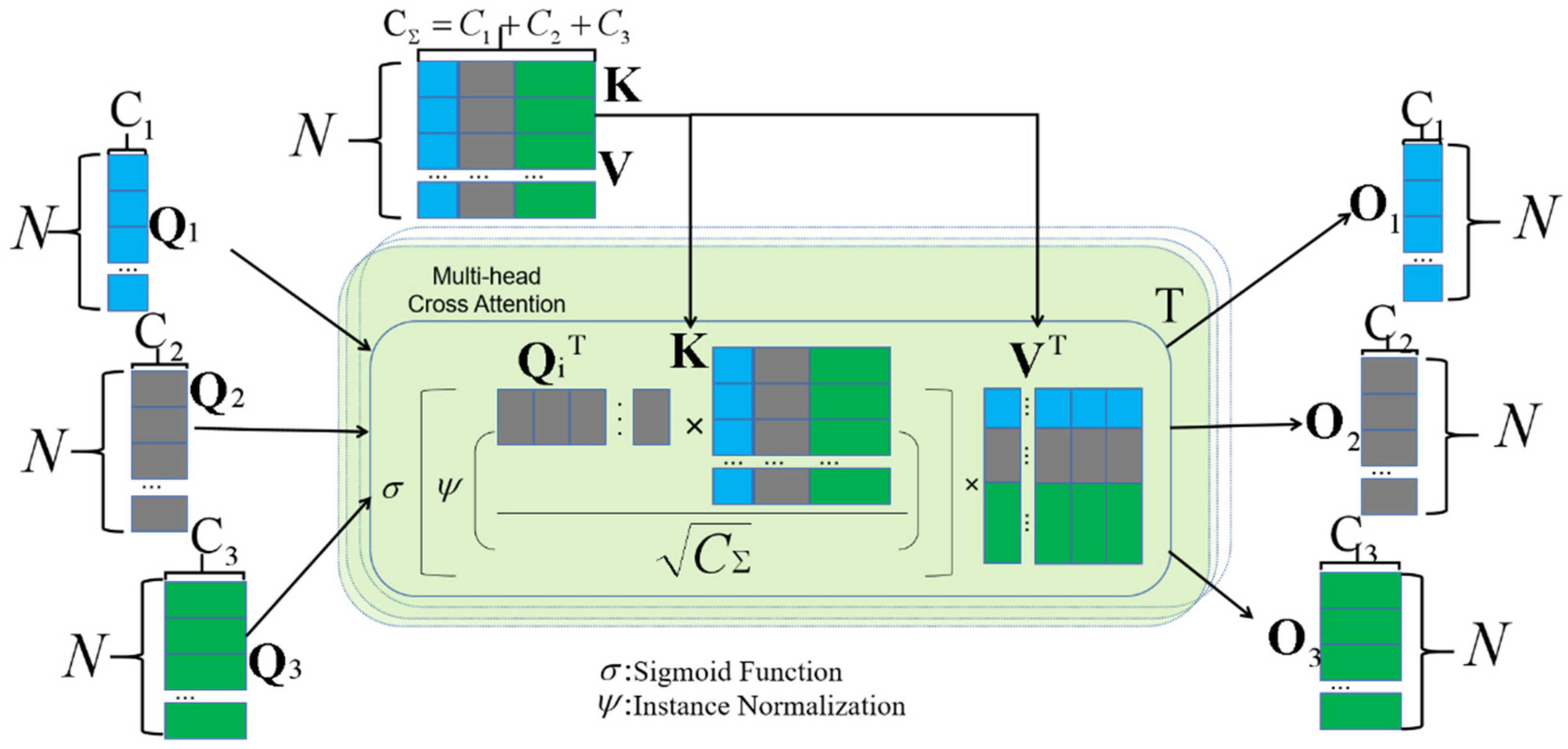
2.2. Residual Multi-Scale Channel Cross-Fusion Transformer (RCCT)
2.2.1. Multi-Scale Feature Embedding
2.2.2. Residual Channel Cross-Fusion Transformer
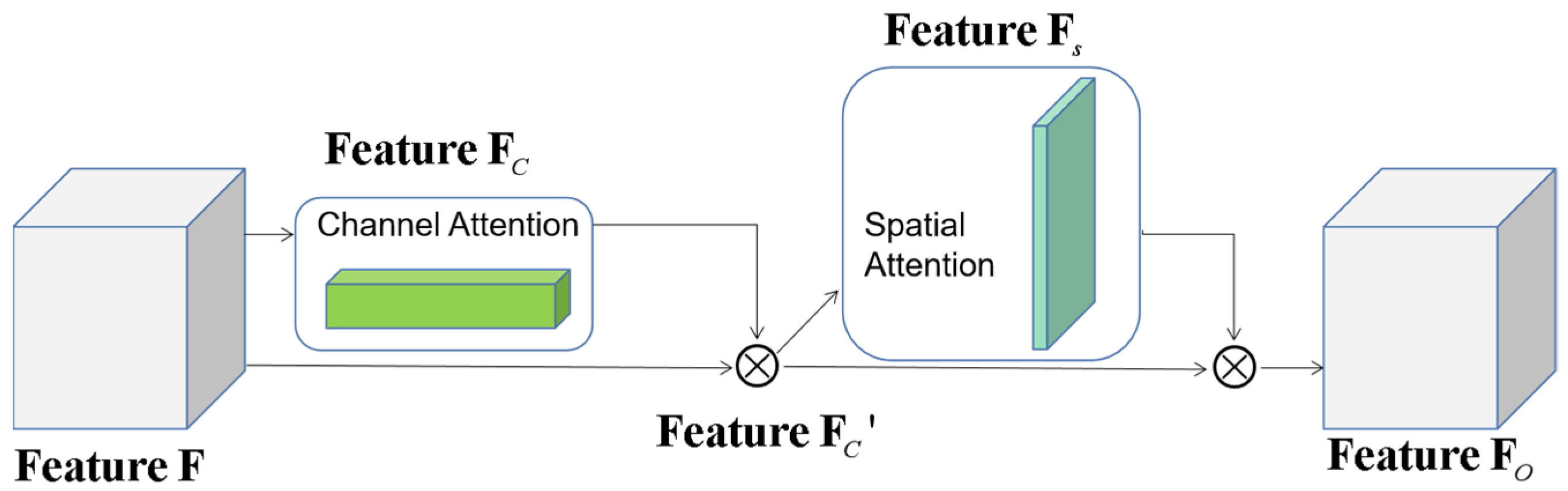
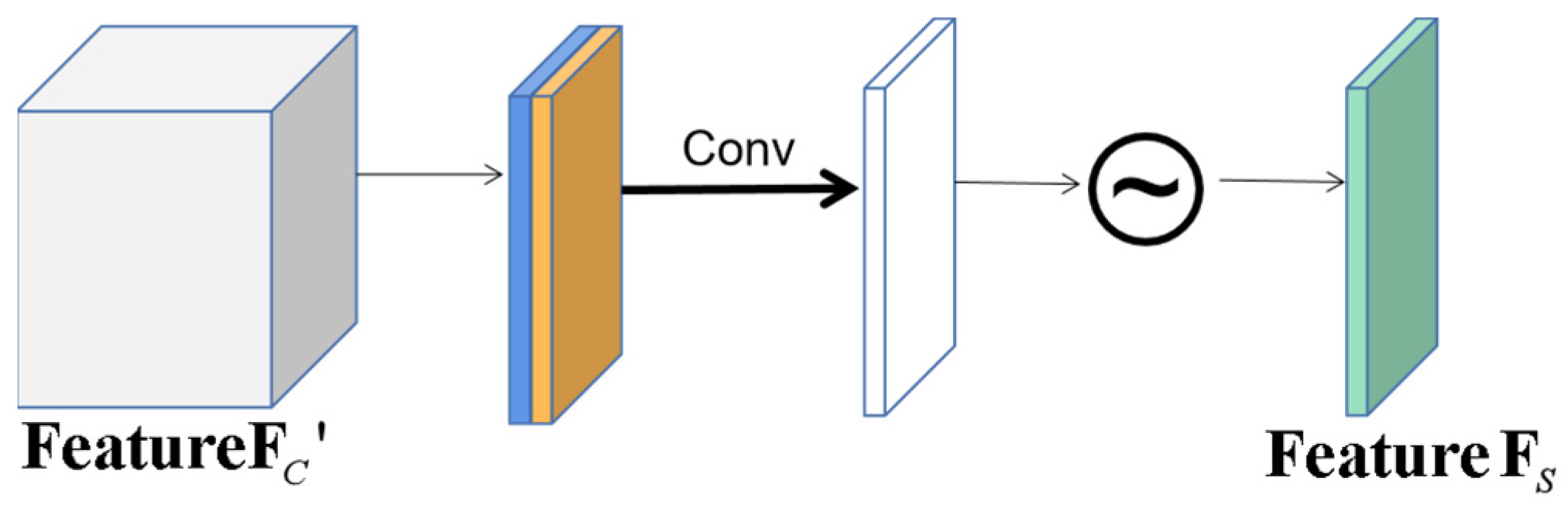
2.3. CBAM Module
2.4. Dual Encoders of ASPP-CBAM and RCCT
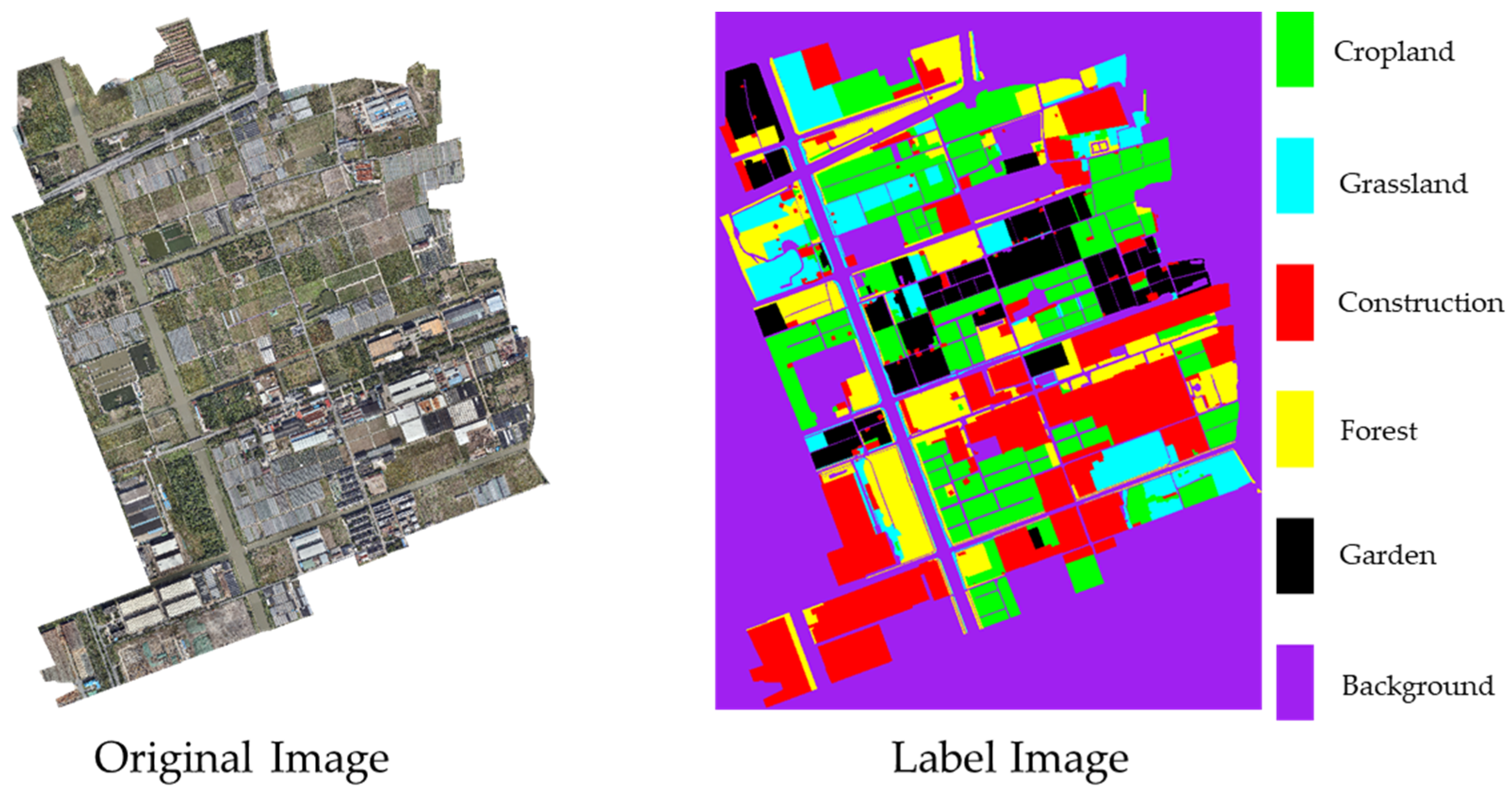
2.5. Data
2.5.1. Self-Made Dataset
2.5.2. AeroScapes Dataset
3. Results
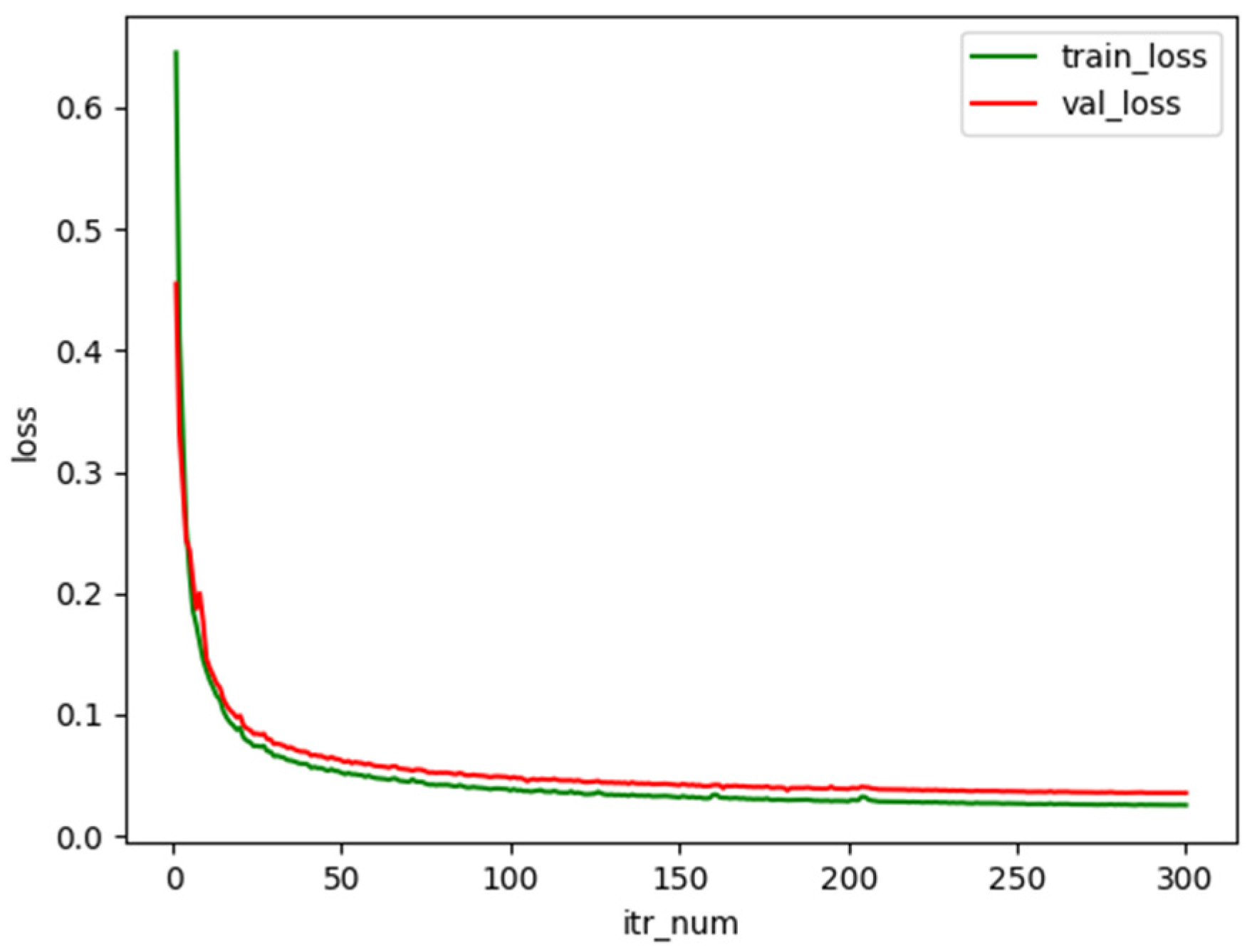
3.1. Experimental Environment and Parameter Setting
3.2. Evaluation Index and Loss Function
3.3. Ablation Experiment of RCCT Module with Different Feature Combinations
3.4. Ablation Experiment of Different Attention Combinations in the ASPP Module
3.5. Ablation Experiment of Dual Encoders
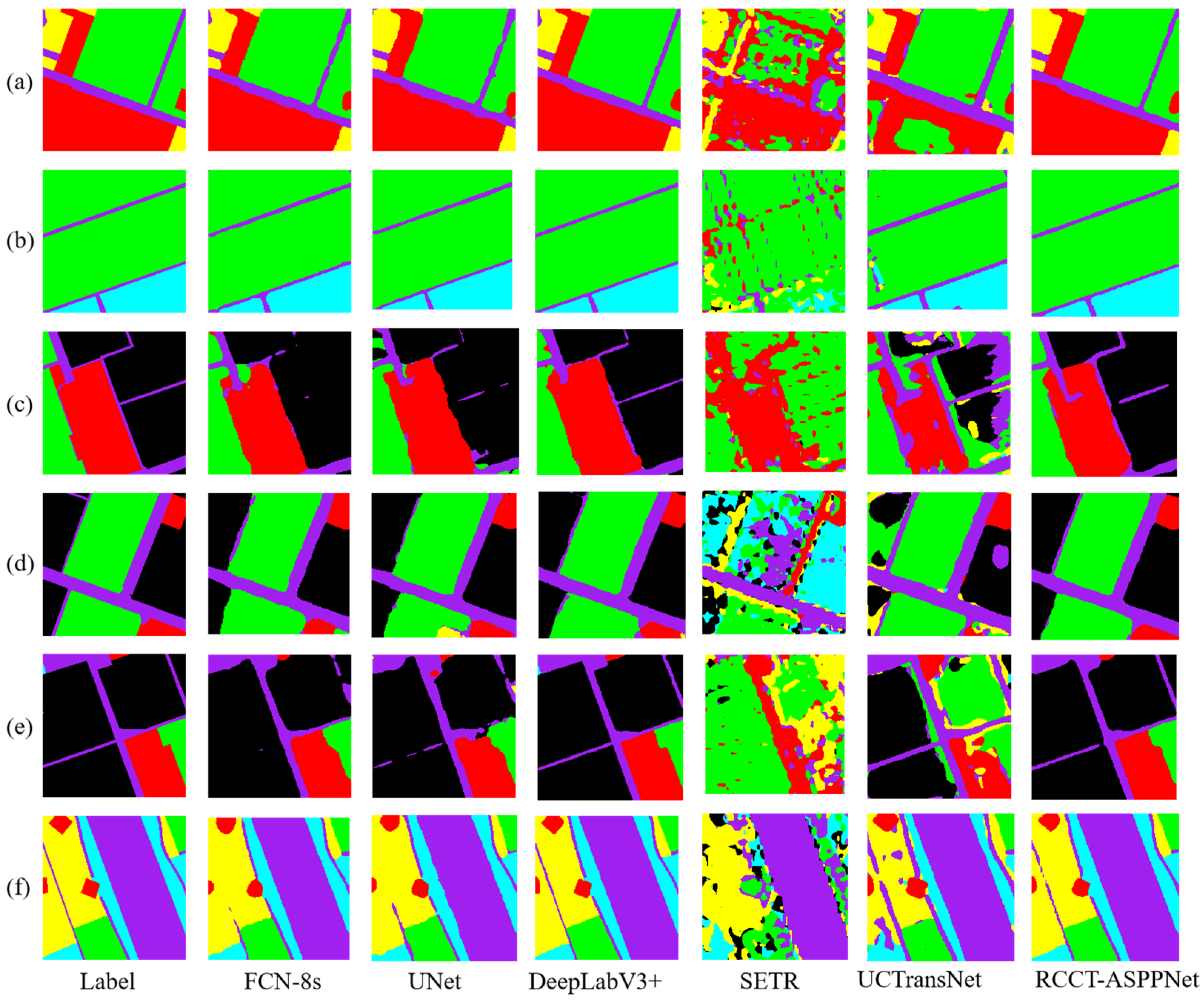
3.6. Comparative Experiment of Different Network Models
4. Discussion
4.1. Visual Analysis
4.2. Analysis of Experimental Results
4.2.1. Analysis between Network Models
4.2.2. Analysis of Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote. Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Lai, C.; Yang, Q.; Guo, Y.; Bai, F.; Sun, H. Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection. Remote Sens. 2022, 14, 3874. [Google Scholar] [CrossRef]
- Mekyska, J.; Espinosa-Duro, V.; Faundez-Zanuy, M. Face segmentation: A comparison between visible and thermal images. In Proceedings of the 44th Annual 2010 IEEE International Carnahan Conference on Security Technology, San Jose, CA, USA, 5–8 October 2010; pp. 185–189. [Google Scholar] [CrossRef]
- Khan, K.; Khan, R.U.; Ahmad, K.; Ali, F.; Kwak, K.-S. Face Segmentation: A Journey from Classical to Deep Learning Paradigm, Approaches, Trends, and Directions. IEEE Access 2020, 8, 58683–58699. [Google Scholar] [CrossRef]
- Masi, I.; Mathai, J.; AbdAlmageed, W. Towards Learning Structure via Consensus for Face Segmentation and Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5507–5517. [Google Scholar] [CrossRef]
- Wang, Y.; Dong, M.; Shen, J.; Wu, Y.; Cheng, S.; Pantic, M. Dynamic Face Video Segmentation via Reinforcement Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6959–6969. [Google Scholar]
- Abdelrahman, A.; Viriri, S. Kidney Tumor Semantic Segmentation Using Deep Learning: A Survey of State-of-the-Art. J. Imaging 2022, 8, 55. [Google Scholar] [CrossRef]
- Arbabshirani, M.R.; Dallal, A.H.; Agarwal, C.; Patel, A.; Moore, G. Accurate Segmentation of Lung Fields on Chest Radio-graphs Using Deep Convolutional Networks. In Proceedings of the Medical Imaging: Image Processing, Orlando, FL, USA, 11–16 February 2017; pp. 37–42. [Google Scholar]
- Dai, P.; Dong, L.; Zhang, R.; Zhu, H.; Wu, J.; Yuan, K. Soft-CP: A Credible and Effective Data Augmentation for Semantic Segmentation of Medical Lesions. arXiv 2022. [Google Scholar] [CrossRef]
- Wang, J.; Valaee, S. From Whole to Parts: Medical Imaging Semantic Segmentation with Very Imbalanced Data. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote. Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Peng, B.; Zhang, W.; Hu, Y.; Chu, Q.; Li, Q. LRFFNet: Large Receptive Field Feature Fusion Network for Semantic Segmentation of SAR Images in Building Areas. Remote. Sens. 2022, 14, 6291. [Google Scholar] [CrossRef]
- Li, Y.; Si, Y.; Tong, Z.; He, L.; Zhang, J.; Luo, S.; Gong, Y. MQANet: Multi-Task Quadruple Attention Network of Multi-Object Semantic Segmentation from Remote Sensing Images. Remote. Sens. 2022, 14, 6256. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision–ECCV 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-Wise Perspective with Transformer. Proc. Conf. AAAI Artif. Intell. 2022, 36, 2441–2449. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A Guide to Convolution Arithmetic for Deep Learning. arXiv 2018, arXiv:1603.07285. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122, 615. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. arXiv 2017. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble Knowledge Transfer for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1499–1508. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The Lovász-Softmax Loss: A Tractable Surrogate for the Optimization of the Inter-section-over-Union Measure in Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4413–4421. [Google Scholar]
- Jaccard, P. The Distribution of The Flora in The Alpine Zone. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Feature | Farmland | AeroScapes | ||
|---|---|---|---|---|
| mIoU (%) | mPA (%) | mIoU (%) | mPA (%) | |
| , , | 93.97 | 96.83 | 60.86 | 84.20 |
| , | 93.46 | 96.75 | 60.47 | 83.61 |
| , | 94.11 | 97.10 | 61.19 | 84.58 |
| , | 94.00 | 96.97 | 61.05 | 84.55 |
| Attention Combination | Farmland | AeroScapes | ||
|---|---|---|---|---|
| mIoU (%) | mPA (%) | mIoU (%) | mPA (%) | |
| ASPP | 93.97 | 96.83 | 60.86 | 84.20 |
| ASPP + CA | 94.12 | 97.06 | 61.22 | 84.22 |
| ASPP+ SA | 94.02 | 96.87 | 61.13 | 84.25 |
| ASPP + CBAM | 94.14 | 97.12 | 61.30 | 84.36 |
| Module | Farmland | AeroScapes | ||
|---|---|---|---|---|
| mIoU (%) | mPA (%) | mIoU (%) | Mpa (%) | |
| RCCT | 91.52 | 93.68 | 59.72 | 82.18 |
| ASPP | 92.72 | 94.81 | 60.35 | 80.65 |
| RCCT + ASPP | 93.97 | 96.83 | 60.86 | 84.20 |
| Network Model | Farmland | AeroScapes | Model | ||
|---|---|---|---|---|---|
| mIoU (%) | mPA (%) | mIoU (%) | mPA (%) | Parameters (M) | |
| FCN-8s | 92.21 | 96.43 | 40.23 | 78.69 | 80 |
| UNet | 89.38 | 95.06 | 42.38 | 50.41 | 124 |
| DeepLabV3+ | 92.80 | 96.28 | 59.63 | 67.07 | 170 |
| SETR | 49.53 | 64.82 | 30.63 | 37.38 | 348 |
| UCTransNet | 92.82 | 93.27 | 52.33 | 81.67 | 363 |
| RCCT-ASPPNet | 94.14 | 97.12 | 61.30 | 84.36 | 411 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Cheng, Z.; Wang, C.; Zhao, J.; Huang, L. RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP. Remote Sens. 2023, 15, 379. https://doi.org/10.3390/rs15020379
Li Y, Cheng Z, Wang C, Zhao J, Huang L. RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP. Remote Sensing. 2023; 15(2):379. https://doi.org/10.3390/rs15020379
Chicago/Turabian StyleLi, Yazhou, Zhiyou Cheng, Chuanjian Wang, Jinling Zhao, and Linsheng Huang. 2023. "RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP" Remote Sensing 15, no. 2: 379. https://doi.org/10.3390/rs15020379