
Generative Recorrupted-to-Recorrupted: An Unsupervised Image Denoising Network for Arbitrary Noise Distribution

Abstract
:1. Introduction
2. Problem Statement
2.1. Supervised Training
2.2. Self-Supervised Training
2.3. Unsupervised Training
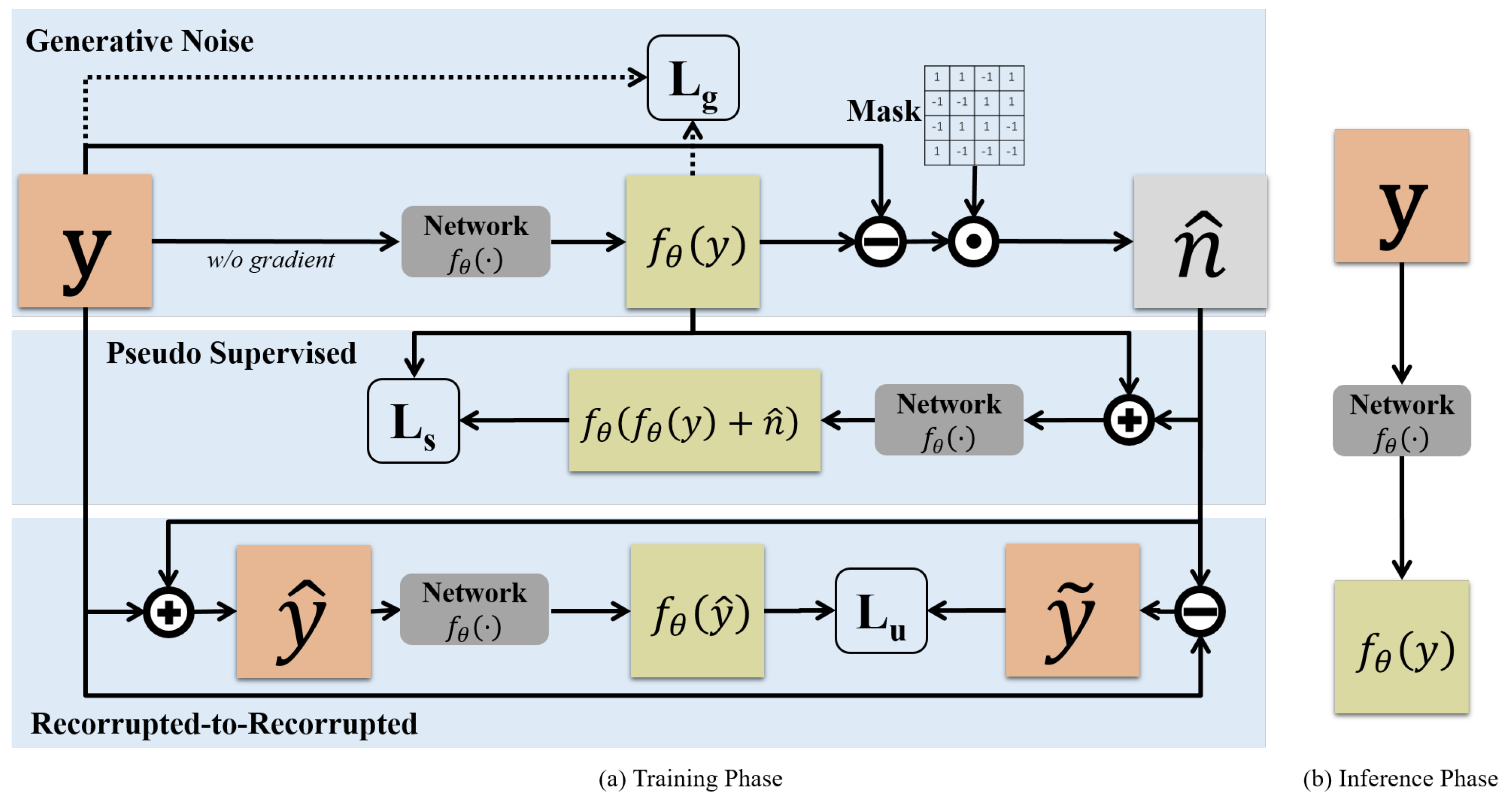
3. Theoretical Framework
3.1. Recorrupted2Recorrupted Module
3.2. Generative Noise Module
3.3. Pseudo Supervised
4. Experiments
4.1. Results for Synthetic Denoising
4.2. Results for Real-World Denoising
4.3. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Krull, A.; Buchholz, T.O.; Jug, F. Noise2void-Learning Denoising from Single Noisy Images. arXiv 2019, arXiv:1811.10980. [Google Scholar]
- Lin, H.; Zhuang, Y.; Huang, Y.; Ding, X.; Liu, X.; Yu, Y. Noise2Grad: Extract Image Noise to Denoise. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 830–836. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lehtinen, J.; Munkberg, J.; Hasselgren, J.; Laine, S.; Karras, T.; Aittala, M.; Aila, T. Noise2Noise: Learning Image Restoration without Clean Data. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2965–2974. [Google Scholar]
- Buchholz, T.O.; Jordan, M.; Pigino, G.; Jug, F. Cryo-care: Content-aware image restoration for cryo-transmission electron microscopy data. In Proceedings of the International Symposium on Biomedical Imaging, Venice, Italy, 8–11 April 2019; pp. 502–506. [Google Scholar]
- Ehret, T.; Davy, A.; Morel, J.M.; Facciolo, G.; Arias, P. Model-blind video denoising via frame-to-frame training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11369–11378. [Google Scholar]
- Hariharan, S.G.; Kaethner, C.; Strobel, N.; Kowarschik, M.; Albarqouni, S.; Fahrig, R.; Navab, N. Learning-based X-ray image denoising utilizing model-based image simulations. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 549–557. [Google Scholar]
- Wu, D.; Gong, K.; Kim, K.; Li, X.; Li, Q. Consensus neural network for medical imaging denoising with only noisy training samples. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 741–749. [Google Scholar]
- Zhang, Y.; Zhu, Y.; Nichols, E.; Wang, Q.; Zhang, S.; Smith, C.; Howard, S. A poisson-gaussian denoising dataset with real fluorescence microscopy images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11710–11718. [Google Scholar]
- Batson, J.; Royer, L. Noise2self: Blind denoising by self-supervision. In Proceedings of the International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2019; pp. 524–533. [Google Scholar]
- Krull, A.; Vičar, T.; Prakash, M.; Lalit, M.; Jug, F. Probabilistic noise2void: Unsupervised content-aware denoising. Front. Comput. Sci. 2020, 2, 5. [Google Scholar] [CrossRef] [Green Version]
- Huang, T.; Li, S.; Jia, X.; Lu, H.; Liu, J. Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14781–14790. [Google Scholar]
- Pang, T.; Zheng, H.; Quan, Y.; Ji, H. Recorrupted-to-Recorrupted: Unsupervised Deep Learning for Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2043–2052. [Google Scholar]
- Wang, W.; Wen, F.; Yan, Z.; Liu, P. Optimal Transport for Unsupervised Denoising Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2104–2118. [Google Scholar] [CrossRef] [PubMed]
- Quan, Y.; Chen, M.; Pang, T.; Ji, H. Self2self with dropout: Learning self-supervised denoising from single image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1887–1895. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bora, A.; Price, E.; Dimakis, A.G. Ambientgan: Generative models from lossy measurements. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Moran, N.; Schmidt, D.; Zhong, Y.; Coady, P. Noisier2noise: Learning to denoise from unpaired noisy data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12064–12072. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wang, Z.; Liu, J.; Li, G.; Han, H. Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2027–2036. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Franzen, R. Kodak Lossless True Color Image Suite. 1999. Available online: http://r0k.us/graphics/kodak (accessed on 29 December 2022).
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 9–12 July 2001; pp. 416–423. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1692–1700. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Laine, S.; Karras, T.; Lehtinen, J.; Aila, T. High-quality self-supervised deep image denoising. arXiv 2019, arXiv:1901.10277. [Google Scholar]
- Wu, X.; Liu, M.; Cao, Y.; Ren, D.; Zuo, W. Unpaired learning of deep image denoising. In Proceedings of the European conference on computer vision, Glasgow, UK, 23–28 August 2020; pp. 352–368. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Noise Type | Method | Input | KODAK | BSD300 | SET14 |
|---|---|---|---|---|---|
| Gaussian | Baseline, N2C [21] | Paired Input | 32.43/0.884 | 31.05/0.879 | 31.40/0.869 |
| Baseline, N2N [6] | Paired Input | 32.41/0.884 | 31.04/0.878 | 31.37/0.868 | |
| BM3D [29] | Non Noise Prior | 31.87/0.868 | 30.48/0.861 | 30.88/0.854 | |
| Self2Self [17] | Non Noise Prior | 31.28/0.864 | 29.86/0.849 | 30.08/0.839 | |
| N2V [3] | Non Noise Prior | 30.32/0.821 | 29.34/0.824 | 28.84/0.802 | |
| Laine19-mu [30] | Noise Prior | 30.62/0.840 | 28.62/0.803 | 29.93/0.830 | |
| Laine19-pme [30] | Noise Prior | 32.40/0.883 | 30.99/0.877 | 31.36/0.866 | |
| Noisier2Noise [20] | Noise Prior | 30.70/0.845 | 29.32/0.833 | 29.64/0.832 | |
| DBSN [31] | Noise Independent | 31.64/0.856 | 29.80/0.839 | 30.63/0.846 | |
| R2R [15] | Noise Prior | 32.25/0.880 | 30.91/0.872 | 31.32/0.865 | |
| Ours | Non Noise Prior | 32.34/0.882 | 31.08/0.879 | 31.20/0.862 | |
| Gaussian | Baseline, N2C [21] | Paired Input | 32.51/0.875 | 31.07/0.866 | 31.41/0.863 |
| Baseline, N2N [6] | Paired Input | 32.50/0.875 | 31.07/0.866 | 31.39/0.863 | |
| BM3D [29] | Non Noise Prior | 32.02/0.860 | 30.56/0.847 | 30.94/0.849 | |
| Self2Self [17] | Non Noise Prior | 31.37/0.860 | 29.87/0.841 | 29.97/0.849 | |
| N2V [3] | Non Noise Prior | 30.44/0.806 | 29.31/0.801 | 29.01/0.792 | |
| Laine19-mu [30] | Noise Prior | 30.52/0.833 | 28.43/0.794 | 29.71/0.822 | |
| Laine19-pme [30] | Noise Prior | 32.40/0.870 | 30.95/0.861 | 31.21/0.855 | |
| DBSN [31] | Noise Independent | 30.38/0.826 | 28.34/0.788 | 29.49/0.814 | |
| R2R [15] | Noise Prior | 31.50/0.850 | 30.56/0.855 | 30.84/0.850 | |
| Ours | Non Noise Prior | 32.46/0.875 | 31.13/0.867 | 31.02/0.856 | |
| Poisson | Baseline, N2C [21] | Paired Input | 31.78/0.876 | 30.36/0.868 | 30.57/0.858 |
| Baseline, N2N [6] | Paired Input | 31.77/0.876 | 30.35/0.868 | 30.56/0.857 | |
| BM3D [29] | Non Noise Prior | 30.53/0.856 | 29.18/0.842 | 29.44/0.837 | |
| Self2Self [17] | Non Noise Prior | 30.31/0.857 | 28.93/0.840 | 28.84/0.839 | |
| N2V [3] | Non Noise Prior | 28.90/0.788 | 28.46/0.798 | 27.73/0.774 | |
| Laine19-mu [30] | Noise Prior | 30.19/0.833 | 28.25/0.794 | 29.35/0.820 | |
| Laine19-pme [30] | Noise Prior | 31.67/0.874 | 30.25/0.866 | 30.47/0.855 | |
| DBSN [31] | Noise Independent | 30.07/0.827 | 28.19/0.790 | 29.16/0.814 | |
| R2R [15] | Noise Prior | 30.50/0.801 | 29.47/0.811 | 29.53/0.801 | |
| Ours | Non Noise Prior | 30.69/0.855 | 29.73/0.856 | 29.23/0.831 | |
| Poisson | Baseline, N2C [21] | Paired Input | 31.19/0.861 | 29.79/0.848 | 30.02/0.842 |
| Baseline, N2N [6] | Paired Input | 31.18/0.861 | 29.78/0.848 | 30.02/0.842 | |
| BM3D [29] | Non Noise Prior | 29.40/0.836 | 28.22/0.815 | 28.51/0.817 | |
| Self2Self [17] | Non Noise Prior | 29.06/0.834 | 28.15/0.817 | 28.83/0.841 | |
| N2V [3] | Non Noise Prior | 28.78/0.758 | 27.92/0.766 | 27.43/0.745 | |
| Laine19-mu [30] | Noise Prior | 29.76/0.820 | 27.89/0.778 | 28.94/0.808 | |
| Laine19-pme [30] | Noise Prior | 29.60/0.811 | 27.81/0.771 | 28.72/0.800 | |
| DBSN [31] | Noise Independent | 29.60/0.811 | 27.81/0.771 | 28.72/0.800 | |
| R2R [15] | Noise Prior | 29.14/0.732 | 28.68/0.771 | 28.77/0.765 | |
| Ours | Non Noise Prior | 30.19/0.839 | 29.26/0.839 | 28.90/0.822 |
| Method | Network | SIDD Benchmark | SIDD Validation |
|---|---|---|---|
| Baseline, N2C [21] | U-Net | 50.60/0.991 | 51.19/0.991 |
| Baseline, N2N [6] | U-Net | 50.62/0.991 | 51.21/0.991 |
| BM3D [29] | - | 48.60/0.986 | 48.92/0.986 |
| N2V [3] | U-Net | 48.01/0.983 | 48.55/0.984 |
| Laine19-mu [30] | U-Net | 49.82/0.989 | 50.44/0.990 |
| Laine19-pme [30] | U-Net | 42.17/0.935 | 42.87/0.939 |
| DBSN [31] | DBSN | 49.56/0.987 | 50.13/0.988 |
| NBR2NBR [14] | U-Net | 50.47/0.990 | 51.06/0.991 |
| R2R [15] | U-Net | 46.70/0.978 | 47.20/0.980 |
| Ours | U-Net | 50.75/0.991 | 51.29/0.991 |
| 0 | 2 | 5 | 10 | 15 | 30 | |
|---|---|---|---|---|---|---|
| PSNR/SSIM | 49.41/0.989 | 51.23/0.991 | 51.29/0.991 | 51.23/0.991 | 51.20/0.991 | 51.06/0.991 |
| Network | GR2R/o | GR2R/w |
|---|---|---|
| ResNet | 49.56/0.935 | 50.84/0.973 |
| DensNet | 49.63/0.956 | 50.89/0.968 |
| U-Net | 50.15/0.947 | 51.29/0.991 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wan, B.; Shi, D.; Cheng, X. Generative Recorrupted-to-Recorrupted: An Unsupervised Image Denoising Network for Arbitrary Noise Distribution. Remote Sens. 2023, 15, 364. https://doi.org/10.3390/rs15020364
Liu Y, Wan B, Shi D, Cheng X. Generative Recorrupted-to-Recorrupted: An Unsupervised Image Denoising Network for Arbitrary Noise Distribution. Remote Sensing. 2023; 15(2):364. https://doi.org/10.3390/rs15020364
Chicago/Turabian StyleLiu, Yukun, Bowen Wan, Daming Shi, and Xiaochun Cheng. 2023. "Generative Recorrupted-to-Recorrupted: An Unsupervised Image Denoising Network for Arbitrary Noise Distribution" Remote Sensing 15, no. 2: 364. https://doi.org/10.3390/rs15020364