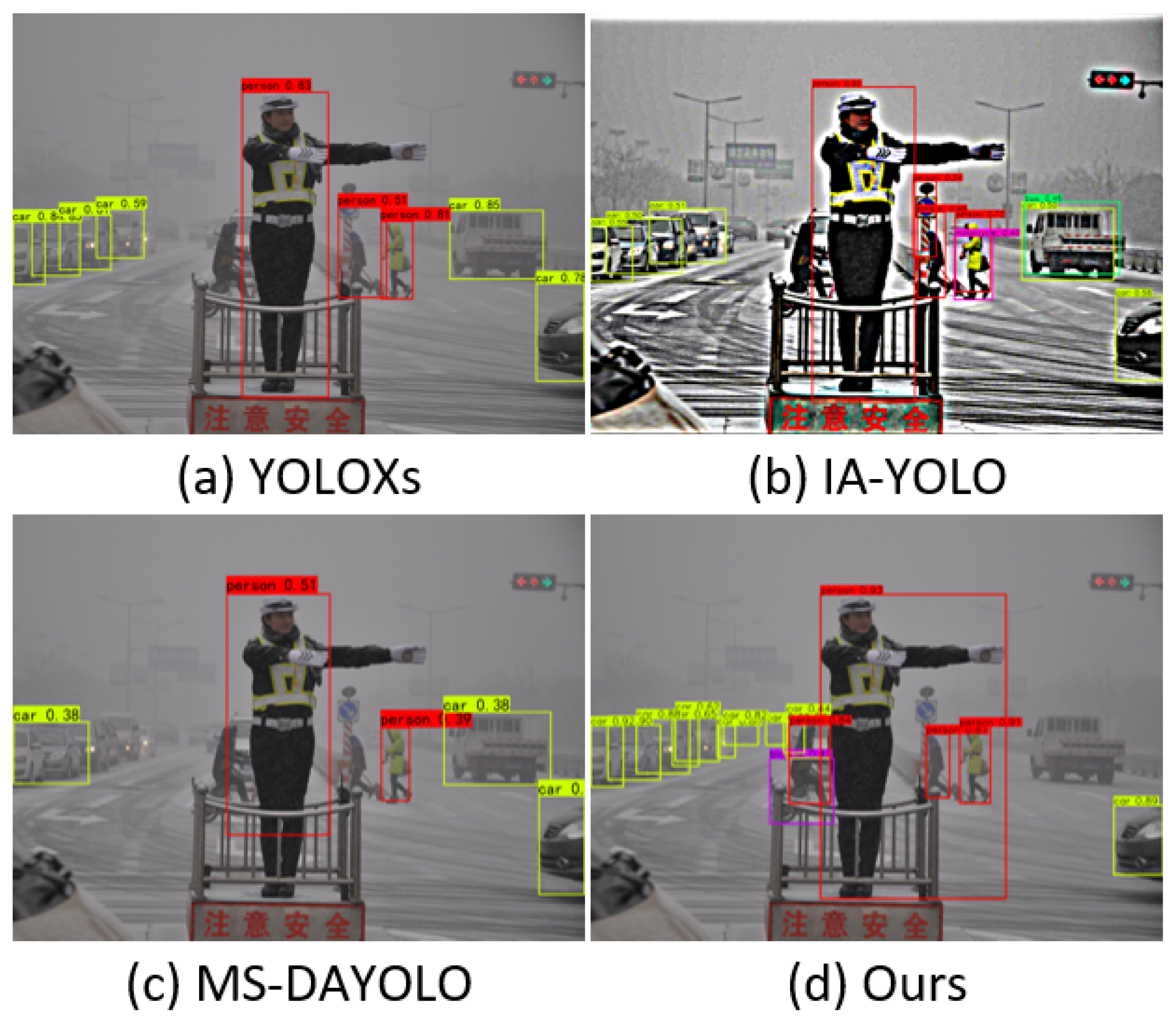
Figure 1.
Comparing of the detection results of different methods in real-world foggy environments: (a) YOLOXs, (b) IA-YOLO, (c) MS-DAYOLO, (d) the proposed method. The objects of interest, including people, cars, motorbikes, buses, and bicycles, are highlighted in red, green, blue, dark green, and purple, respectively (best viewed in color).
Figure 1.
Comparing of the detection results of different methods in real-world foggy environments: (a) YOLOXs, (b) IA-YOLO, (c) MS-DAYOLO, (d) the proposed method. The objects of interest, including people, cars, motorbikes, buses, and bicycles, are highlighted in red, green, blue, dark green, and purple, respectively (best viewed in color).
Figure 2.
The architecture of our ODFC-YOLO, which is an end-to-end multi-task learning-based framework, which mainly includes a dehazing subnet and a detection subnet. It’s worth to mention that the dehazing subnet only participates during training, which generates the clean images, but these images are not used as input to the detection subnet in the inference time. The green dotted line plus the orange dotted line indicates the dehazing subnet; the green dotted line plus the purple dotted line indicates the detection subnet. CSP-Decoder: Cross-Stage Partial Fusion Decoder.
Figure 2.
The architecture of our ODFC-YOLO, which is an end-to-end multi-task learning-based framework, which mainly includes a dehazing subnet and a detection subnet. It’s worth to mention that the dehazing subnet only participates during training, which generates the clean images, but these images are not used as input to the detection subnet in the inference time. The green dotted line plus the orange dotted line indicates the dehazing subnet; the green dotted line plus the purple dotted line indicates the detection subnet. CSP-Decoder: Cross-Stage Partial Fusion Decoder.
Figure 3.
The architecture of Cross-Stage Partial Fusion Decoder (CSP-Decoder), which removes the negative impact of degraded images on feature extraction and produces high-quality clean features.
Figure 3.
The architecture of Cross-Stage Partial Fusion Decoder (CSP-Decoder), which removes the negative impact of degraded images on feature extraction and produces high-quality clean features.
Figure 4.
The Global Context Enhanced Extraction (GCEE) module, which is a mechanism for improving the feature extraction capability of our model by building global feature long-range dependencies.
Figure 4.
The Global Context Enhanced Extraction (GCEE) module, which is a mechanism for improving the feature extraction capability of our model by building global feature long-range dependencies.
Figure 5.
Visualization of regions of attention for our Global Context Enhanced Extraction (GCEE) module.
Figure 5.
Visualization of regions of attention for our Global Context Enhanced Extraction (GCEE) module.
Figure 6.
Detection results of our ODFC-YOLO and other advanced detection methods on Foggy Driving dataset. Obviously, the proposed ODFC-YOLO can detect more objects with higher confidence.
Figure 6.
Detection results of our ODFC-YOLO and other advanced detection methods on Foggy Driving dataset. Obviously, the proposed ODFC-YOLO can detect more objects with higher confidence.
Figure 7.
Detection results of our ODFC-YOLO and other advanced detection methods on real-world foggy dataset (RTTS).
Figure 7.
Detection results of our ODFC-YOLO and other advanced detection methods on real-world foggy dataset (RTTS).
Figure 8.
Detection results of our method and representative image adaptation methods (IA-YOLO) in low-light conditions.
Figure 8.
Detection results of our method and representative image adaptation methods (IA-YOLO) in low-light conditions.
Figure 9.
The detection results of the VisDrone dataset under different scenes.
Figure 9.
The detection results of the VisDrone dataset under different scenes.
Figure 10.
Detection results of our ODFC-YOLO and the other advanced detection methods without retrained on the RainCityscapes dataset.
Figure 10.
Detection results of our ODFC-YOLO and the other advanced detection methods without retrained on the RainCityscapes dataset.
Table 1.
For statistics on the total number of images and the number of instances per class for all datasets used, including voc-fog-tv (VOC-Foggy-train), voc-fog-ts (VOC-Foggy-test), RTTS and FoggyD (Foggy Driving dataset). We select only five classes from the dataset: car, person, bus, bicycle (bic), motorcycle (motc).
Table 1.
For statistics on the total number of images and the number of instances per class for all datasets used, including voc-fog-tv (VOC-Foggy-train), voc-fog-ts (VOC-Foggy-test), RTTS and FoggyD (Foggy Driving dataset). We select only five classes from the dataset: car, person, bus, bicycle (bic), motorcycle (motc).
| Dataset | Images | Person | Bic | Car | Bus | Motc | Total |
|---|
| voc-fog-tv | 8111 | 13,256 | 1064 | 3267 | 822 | 1052 | 19,561 |
| voc-fog-ts | 2734 | 4528 | 377 | 1201 | 211 | 325 | 6604 |
| RTTS | 4322 | 7950 | 534 | 18,413 | 1838 | 862 | 29,577 |
| FoggyD | 101 | 269 | 17 | 425 | 17 | 9 | 737 |
Table 2.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the RTTS dataset. The mAP (mean Average Precision) used to evaluate object detection performance.
Table 2.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the RTTS dataset. The mAP (mean Average Precision) used to evaluate object detection performance.
| Methods | Person | Bicycle | Car | Motorbike | Bus | mAP |
|---|
| YOLOXs(arXiv’21) [12] | 80.81 | 74.14 | 83.63 | 75.35 | 86.40 | 80.07 |
| YOLOXs*(arXiv’21) [12] | 79.97 | 67.95 | 74.75 | 58.62 | 83.12 | 72.88 |
| AOD-YOLOXs*(ICCV’17) [55] | 81.26 | 73.56 | 76.98 | 71.18 | 83.08 | 77.21 |
| DCP-YOLOXs*(TPAMI’10) [54] | 81.58 | 78.80 | 79.75 | 78.51 | 85.64 | 80.86 |
| GCA-YOLOXs*(WACV’19) [56] | 81.50 | 80.89 | 84.18 | 78.42 | 77.69 | 80.53 |
| FFA-YOLOXs*(AAAI’20) [57] | 78.30 | 70.31 | 69.97 | 68.80 | 80.72 | 73.62 |
| MS-DAYOLO(ICIP’21) [19] | 82.52 | 75.62 | 86.93 | 81.92 | 90.10 | 83.42 |
| DS-Net(TPAMI’21) [50] | 72.44 | 60.47 | 81.27 | 53.85 | 61.43 | 65.89 |
| IA-YOLO(AAAI’22) [16] | 75.14 | 67.84 | 76.91 | 57.91 | 67.61 | 72.03 |
| TogetherNet(CGF’22) [51] | 87.62 | 78.19 | 85.92 | 84.03 | 93.75 | 85.90 |
| BAD-Net(TPAMI’23) [46] | - | - | - | - | - | 85.58 |
| ODFC-YOLO(Ours) | 86.67 | 88.83 | 91.16 | 86.60 | 86.85 | 88.02 |
Table 3.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the RTTS dataset.
Table 3.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the RTTS dataset.
| Methods | Person | Bicyle | Car | Motorbike | Bus | mAP |
|---|
| YOLOXs | 80.88 | 64.27 | 56.39 | 52.74 | 29.60 | 56.74 |
| YOLOXs* | 76.28 | 60.44 | 64.73 | 50.06 | 24.86 | 55.04 |
| AOD-YOLOXs* | 77.26 | 62.43 | 56.70 | 53.45 | 30.01 | 55.83 |
| GCA-YOLOXs* | 79.12 | 67.10 | 56.41 | 58.68 | 34.17 | 58.64 |
| DCP-YOLOXs* | 78.69 | 67.99 | 55.50 | 57.57 | 33.27 | 58.32 |
| FFA-YOLOXs* | 77.12 | 66.51 | 64.23 | 40.64 | 23.71 | 52.64 |
| MS-DAYOLO | 74.22 | 44.13 | 70.91 | 38.64 | 36.54 | 57.39 |
| DS-Net | 68.81 | 18.02 | 46.13 | 15.15 | 15.44 | 32.71 |
| IA-YOLO | 67.25 | 35.84 | 42.65 | 22.52 | 17.64 | 37.89 |
| TogetherNet | 82.70 | 57.27 | 75.31 | 55.40 | 37.04 | 61.55 |
| Ours | 79.63 | 68.71 | 74.26 | 68.41 | 34.23 | 62.05 |
Table 4.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the Foggy Driving dataset.
Table 4.
Performance comparisons of our ODFC-YOLO with other advanced detection methods on the Foggy Driving dataset.
| Methods | Person | Bicycle | Car | Motorbike | Bus | mAP |
|---|
| YOLOXs | 24.36 | 27.25 | 55.08 | 8.04 | 44.79 | 33.06 |
| YOLOXs* | 26.58 | 23.67 | 56.22 | 6.74 | 41.87 | 32.49 |
| AOD-YOLOXs* | 26.15 | 33.72 | 56.95 | 6.44 | 34.89 | 32.51 |
| GCA-YOLOXs* | 27.96 | 34.11 | 56.36 | 6.77 | 34.21 | 33.77 |
| DCP-YOLOXs* | 22.64 | 11.07 | 56.37 | 4.66 | 36.03 | 31.56 |
| FFA-YOLOXs* | 19.22 | 21.40 | 50.64 | 3.69 | 43.85 | 28.74 |
| MS-DAYOLO | 21.52 | 34.57 | 57.41 | 18.20 | 46.75 | 34.89 |
| DS-Net | 26.74 | 20.54 | 54.16 | 7.14 | 36.11 | 29.74 |
| IA-YOLO | 20.24 | 19.04 | 50.67 | 8.11 | 22.97 | 25.70 |
| TogetherNet | 30.48 | 30.47 | 57.87 | 14.87 | 40.88 | 36.75 |
| Ours | 35.69 | 35.26 | 59.15 | 16.17 | 45.88 | 38.41 |
Table 5.
Performance comparison of our ODFC-YOLO with other detection methods on the RainCityscapes dataset. The mAP (mean Average Precision) used to evaluate object detection performance.
Table 5.
Performance comparison of our ODFC-YOLO with other detection methods on the RainCityscapes dataset. The mAP (mean Average Precision) used to evaluate object detection performance.
| Methods | Without-Retrained | Retrained |
|---|
| YOLOXs [12] | 35.49 | 40.62 |
| GCA-YOLOXs [56] | 36.76 | 39.15 |
| IA-YOLO [16] | 14.52 | 15.32 |
| MS-DAYOLO [19] | 40.43 | 44.37 |
| TogetherNet [51] | 35.34 | 39.14 |
| Ours | 42.48 | 48.20 |
Table 6.
Ablation study of different combination strategies of the proposed modules are performed on the RTTS dataset. Decoder represents the version of CSP-Decoder with SKFusion module, and Decoder* without SKFusion module.
Table 6.
Ablation study of different combination strategies of the proposed modules are performed on the RTTS dataset. Decoder represents the version of CSP-Decoder with SKFusion module, and Decoder* without SKFusion module.
| Modules | Base | Variants | Variants | Variants | Variants | Variants |
|---|
| Decoder* | w/o | ✓ | w/o | w/o | ✓ | w/o |
| Decoder | w/o | w/o | ✓ | w/o | w/o | ✓ |
| GCEE | w/o | w/o | w/o | ✓ | ✓ | ✓ |
| mAP | 56.74 | 59.06 | 59.76 | 57.76 | 60.65 | 62.05 |
Table 7.
Ablation study with different weight assignments for detection loss and dehazing loss. mAP* represents the detection performance applying the loss function without .
Table 7.
Ablation study with different weight assignments for detection loss and dehazing loss. mAP* represents the detection performance applying the loss function without .
| | mAP* | mAP |
|---|
| 0.7&0.3 | 0.314 | 56.01 | 55.63 |
| 0.6&0.4 | 0.412 | 57.35 | 57.83 |
| 0.4&0.6 | 0.608 | 58.82 | 59.98 |
| 0.3&0.7 | 0.706 | 59.82 | 60.65 |
| 0.2&1.0 | 1.004 | 58.89 | 60.66 |
| 0.2&0.8 | 0.804 | 61.02 | 62.05 |
Table 8.
Detection speed comparison of the proposed ODFC-YOLO with different advance detection methods.
Table 8.
Detection speed comparison of the proposed ODFC-YOLO with different advance detection methods.
| Method | Run Time | FPS |
|---|
| YOLOXs | 0.018 | 55.6 |
| DCP-YOLOXs | 1.238 | 0.8 |
| MS-DAYOLO | 0.037 | 27.0 |
| DS-Net | 0.035 | 28.6 |
| IA-YOLO | 0.039 | 25.6 |
| TogetherNet | 0.031 | 35.1 |
| ODFC-YOLO(Ours) | 0.026 | 36.5 |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}