1. Introduction
Land cover change detection (LCCD) using remote sensing images involves comparing the bitemporal images and extracting the land cover change [
1,
2], such as the land cover change before and after some land cover change events, such as a landslide or wildfire events. In this study, the task of land cover change detection on the earth’s surface was accomplished by comparing the images that cover the same geographical area but were acquired at different dates. LCCD using remote sensing images can capture large-scale land changes on the earth’s surface [
3]. The land cover change information plays a vital role in landslide and earthquake inventory mapping [
4,
5,
6], environmental quality assessment [
7,
8,
9], natural resource monitoring [
10,
11], urban development decision-making [
12,
13,
14], crop yield estimation [
15], and other applications [
16]. Therefore, LCCD with remote sensing images is attractive for practical applications [
16,
17,
18,
19].
Over the past decades, various LCCD methods have been developed. These methods can be divided into two major groups based on the type of bitemporal images used [
20]: change detection with homogeneous remote sensing images (Homo-CD) and change detection with heterogeneous remote sensing images (Hete-CD). The details of each group were reviewed as follows:
Homo-CD indicates that the images used for LCCD are homogeneous data acquired with the same remote sensors, possess similar spatial-spectral resolution, and exhibit consistent reflectance signatures [
16]. Accordingly, the images can be directly compared to determine the magnitude of the change and acquire land cover change information. Researchers have proposed several methods for Homo-CD. One of the most popular methods is the contextual information-based method [
19], such as the sliding window-based approach [
21], the mathematical model-based method [
22], and the adaptive region-based approach [
23,
24]. Deep learning methods for Homo-CD, such as convolutional neural networks [
25,
26,
27] and fully convolutional Siamese networks [
28,
29], have also been widely used. Many deep learning networks have been developed with multiscale convolution [
30,
31] and deep feature fusion [
32,
33] to cover more ground targets and utilize deep features. Moreover, change trend detection with multitemporal images has been attractive and popular in recent years [
17,
34,
35]. Although various change detection methods have been developed and have showcased excellent performance, demonstrating their feasibility and advantages for Homo-CD, two major drawbacks persist: Deep learning neural network training requires considerable samples, and preparing a large number of training samples is labor-intensive and time-consuming.
Homogeneous images may be unavailable in numerous application scenarios due to the physical limitations of remote sensing sensors. For example, optical satellite images are typically unavailable for detecting land cover change caused by nighttime wildfires or floods [
20]. Nevertheless, pre-event optical images are easily obtained with satellites. In addition, the image quality of optical satellite images is easily affected by weather [
36,
37]. Therefore, to address the limitations of Homo-CD in practical applications, Hete-CD is proposed and has gained popularity in recent years [
38].
In contrast with Homo-CD, the images used for Hete-CD are heterogeneous remote sensing images (HRSIs). The HRSIs have an advantage in complementing the insignificance of homogeneous images, such as an optical image reflecting the appearance of ground targets by visible, near-infrared, and short-wave infrared sensors. Consequently, the illumination and atmospheric conditions significantly affect the optical image quality. Meanwhile, a synthetic aperture radar (SAR) image depicts the physical scattering of ground targets. The appearance of a target in a SAR image depends on its roughness and microwave energy wavelength. When an optical image is available prior to a night flood or landslide, a SAR image is an alternative after a disaster because it is independent of visual light and weather conditions [
39]. Accordingly, immediate assessment of the damage caused by natural disasters using optical and SAR images is possible in certain urgent cases. The superiority of Hete-CD increases the corresponding demand for practical engineering.
Various methods have been promoted for Hete-CD in recent years. The most popular approach to Hete-CD focused on exploring the shared features and measuring the similarity between the shared features and bitemporal HRSIs. Wan et al. [
40] explored the statistical features of multisensor images for LCCD. Lei et al. [
41] extracted the adaptive local structure from HRSIs for Hete-CD. Sun et al. [
42] improved the adaptive structure feature based on sparse theory for Hete-CD. Moreover, techniques such as image regression [
43,
44,
45], graph representation theory [
46,
47,
48,
49,
50], and pixel transformation [
51] can be effectively used to investigate the mutual features needed to carry out change detection tasks with HRSIs. Although considerable traditional methods and their applications have demonstrated the feasibility and advantages of using HRSIs in LCCD, these algorithms are typically complex, and their optimal parameter involves trial-and-error experiments.
However, the aforementioned traditional methods aim at exploring the features that are focused on describing the pixel’s relationship [
52,
53]. In recent years, deep learning techniques have been promoted and widely used in the fields of computer vision [
54] and change detection [
55]. Particularly, deep learning techniques have been frequently used to analyze deep features from HRSIs and make them comparable for change detection. Zhan et al. [
56] proposed a log-based transformation feature learning network for Hete-CD with the goal of transforming heterogeneous images into similar ones. The experiments with four datasets verified the feasibility and advantages of the log-based transformation feature learning network [
56]. Encoders and decoders can explore the deep shared features of bitemporal heterogeneous images for change detection. Wu et al. [
57] developed a commonality auto-encoder for learning common features for Hete-CD. The experimental results with five pairs of real heterogeneous datasets clearly demonstrated the advantages of the proposed approach. Furthermore, generative adversarial networks used two networks competing against each other in the form of bitemporal heterogeneous images with the goal of learning the shared features of the pairwise images [
48]. Niu [
58] presented a conditional generative adversarial network for Hete-CD and achieved satisfactory detection performance with optical and SAR images. Although some applications have shown that deep learning techniques can learn deep features from HRSIs to be comparable, the deep learning-based Hete-CD methods typically necessitate many training samples.
The challenges of Hete-CD were summarized as follows: (1) Direct comparison of bitemporal HRSIs is not feasible for change detection; (2) several existing deep learning approaches face challenges in terms of achieving satisfactory performance with a small number of training samples; (3) labeling training samples is necessary for deep learning-based methods; however, it is time-consuming and labor-intensive. We developed a novel framework for change detection using HRSIs with a limited initial sample set to address the challenges of Hete-CD. The major contributions of the proposed framework can be briefly summarized as follows:
A novel deep-learning framework is designed for Hete-CD. This simple framework offers several advantages in improving detection accuracy with a small number of initial samples. The deep learning framework’s simple yet competitive performance is attractive and preferred for practical engineering.
A non-parameter sample-enhanced algorithm is proposed to be embedded into a neural network. In particular, this algorithm explores the potential samples around each initial sample using a non-parameter and iterative approach. Although this idea was verified by Hete-CD with HRSIs in this study, it may be useful for other supervised remote sensing image applications, such as land cover classification, scene classification, and Homo-CD.
The remainder of this paper is organized as follows:
Section 2 presents the details of the proposed framework.
Section 3 presents the experiments and the related discussion.
Section 4 provides the conclusion.
2. Methods
In this section, we provided a detailed description of the proposed framework for Hete-CD, including an overview and backbone of the proposed neural network, a non-parameter sample-enhanced algorithm, and an accuracy assessment. Every part is detailed in the following section. It is worth noting that the proposed approach was realized with the Pytorch 1.9 software, Python 3.8 was used for coding, the version of the OpenCV library is 4.6, and our code has been released on GitHub, which can be accessed by clicking on the link in the abstract section.
2.1. Overview
The motivation behind this study was to achieve change detection in Hete-CD with a limited number of samples. Accordingly, a novel framework was designed here to achieve the objective.
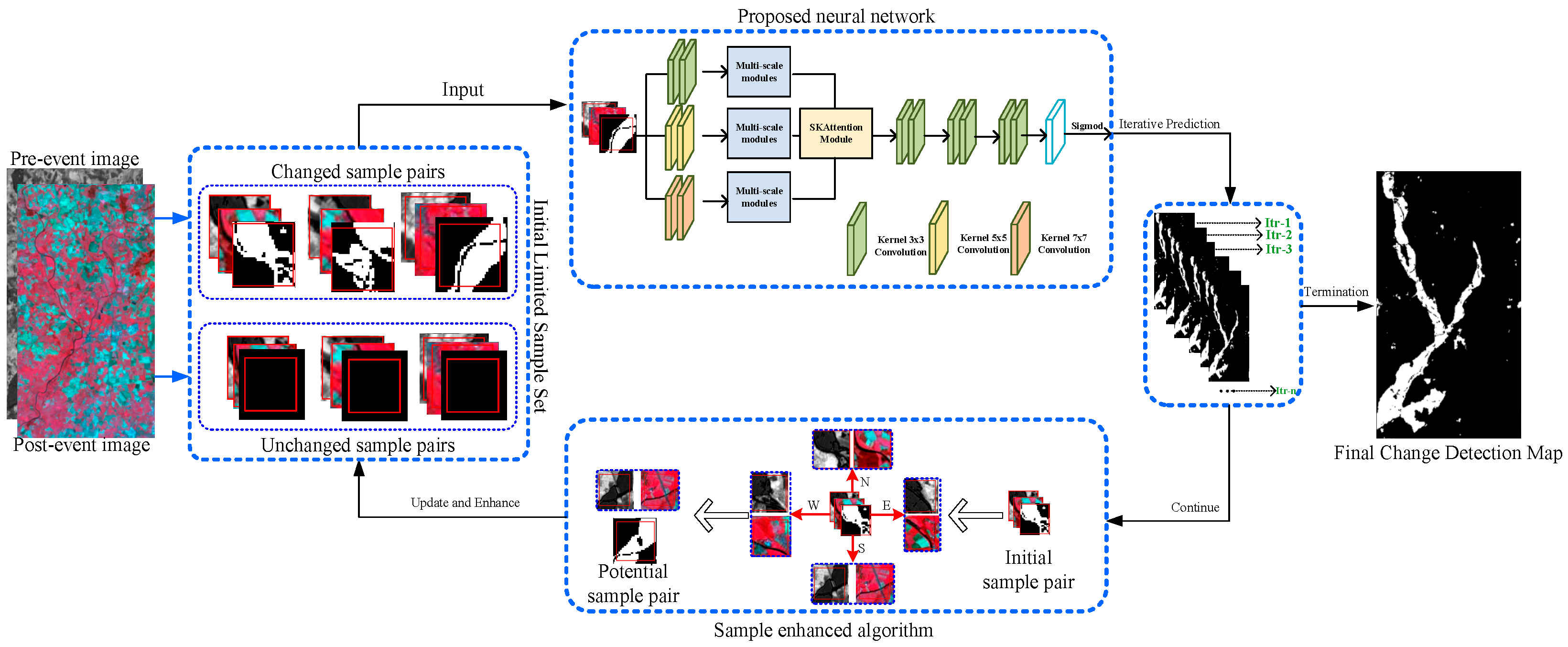
Figure 1 depicts the flowchart of the proposed framework, which has four major parts, including an overview of the proposed approach, a proposed deep-learning neural network, a non-parameter sample-enhanced algorithm, and an accuracy assessment.
The overview of the proposed framework indicated that the framework iteratively generated a change detection map, and the final detection map was outputted when the iteration was terminated. The framework was initialized with a small number of samples, and the initial training sample set was amplified using a proposed nonparametric sample-enhanced algorithm in every iteration. The details of the termination condition of the proposed framework are presented in the following section.
To clarify this concept, the matched pixels for changed and unchanged classes between three adjacent iterations were defined in Equation (1) as follows:
where in
, 0 and 1 denote the unchanged and changed classes, respectively.
W and
H denote the width and height of an input image.
and
are the similarity measurements in terms of the
-th classification map and (
)th-classification map for the L-class, and they can be calculated by using Equations (2) and (3), respectively. “<—>” represents the matched pixels with the same label, including the changed and unchanged labels. For example, if the pairwise pixels at position (
i,j) were marked with the “changed” or “unchanged” label in
and
, then the pairwise pixels were defined as “matched”. Equation (1) demonstrated the similarity between the detection map from the (
k − 1)th and
kth and
kth and (
k + 1)th iterations. Moreover,
was a small constant, and it was fixed at 0.0001 in our proposed framework. The training sample was dynamically adjusted in the iterative process. For example, if the change class satisfies Equation (1), then the corresponding changed sample will not be enhanced in the next iteration. Moreover, Equation (1) will be checked again in every iteration. Equation (1) indicated that the iteration of the proposed framework was terminated when the difference between the matched ratio among the (
k − 1)th,
kth, and (
k + 1) detection maps was less than
for the unchanged and changed classes.
In addition to the overview of the proposed framework, the two major parts were the proposed deep learning neural network and the non-parameter sample-enhanced algorithm. The details are presented as follows:
2.2. Proposed Deep-Learning Neural Network
Different ground targets were performed with varying sizes in remote sensing images, and distinguishing a target, such as a lake or a building, required an appropriate scale from the human visual perspective [
59,
60]. Accordingly, three aspects were considered in the proposed neural network, as shown in
Figure 1. First, the bitemporal images were concatenated into one image and fed into three parallel branches. Each branch contained two convolution layers and one multiscale module. Every convolution layer in each branch had a different kernel size. The objective of this operation was to learn multiscale features for describing the various targets with different sizes. Second, a selective kernel (SK) attention module [
61] was used to adaptively adjust its receptive field size based on multiple scales of the input information, with the aim of guiding the module to learn a selective scale for a specific target. After that, six convolutional layers with a
kernel size were used. The SK-attention was also utilized to smooth the detection noise further. Finally, the proposed neural network was activated by using the Sigmoid function.
The proposed neural network was trained with 20 epochs for one iteration in the entire framework and used to predict one change detection map. When the training samples were enhanced, the proposed neural network was trained again with the new sample set. During the training, a widely used loss function named cross-entropy was adopted, and was utilized for prediction.
Non-Parameter Sample-Enhanced Algorithm
Labeling training samples is widely recognized to be time-consuming and labor-intensive, and a sufficient number of samples are required to train a deep learning model effectively [
62]. Therefore, a non-parameter sample-enhanced algorithm was proposed and embedded in our proposed framework. The details of the sample-enhanced algorithm are presented as follows:
Here,
and
represented the image blocks with
pixels of the pre-event and post-event, respectively.
and
were defined as the known samples. The neighboring image blocks around the known sample position (
i,
j) were selected as the potential training samples. Every potential sample was overlapped by a quarter with the known sample. In this study, the correlation between
and
was measured by the Pearson correlation coefficient (PCC), as follows:
where
is an expectation;
and
represent the pixel within the spatial domain of
and the mean of these pixels in terms of gray value, respectively;
is the standard deviation of the pixels within
; and
reflects the linear correlation between the pixels of the samples from the HRSIs. The label of the samples around the known sample pair
is distinguished as follows based on the definition:
where
denotes the sample’s label;
and
denote the changed and unchanged classes. Therefore,
and
denote the correlation relationship similarity between the pairwise image blocks (
and
) which are the known samples, and the central pixel of the known sample image blocks at the position (
i,
j) are the changed and unchanged labels. In addition,
and
denote the samples extracted from the bitemporal images that were acquired at date-t1 and date-t2, respectively. The defined rules indicated that when the label of the known sample was “changed” and if the correlation between the pairwise neighboring potential samples (
and
) was less than or equal to that of the known sample (
and
), then the label of the pairwise neighboring potential sample will be marked as “changed”. By contrast, when the label of the known sample was “unchanged” and if
, then the label of the pairwise neighboring potential sample will be marked as “unchanged”. Based on this definition, the initial sample set with a limited size was gradually amplified during the iteration, and the enhanced sample set was re-used to train the proposed neural network to generate the preferred detection performance.
These PCC-based rules were effective for investigating potential samples around each known sample with regard to the following intuitive assumptions: (1) PCC can measure the correlation between two datasets from different modalities; (2) Around a sample with a changed label, the lower correlation between pairwise heterogonous image blocks indicates a lower possibility of change between them; (3) Around a sample with an unchanged label, the higher correlation between the pairwise heterogonous image blocks indicates a higher possibility of change between them.
2.3. Accuracy Assessment
Nine widely used evaluation indicators are used in our study to investigate performance quantitatively. The details are summarized in
Table 1. Here, four variables are defined to clarify the referred indicators: True positive (TP) refers to the number of accurately detected changed pixels; true negative (TN) is the number of accurately detected unchanged pixels; false positive (FP) is the number of inaccurately detected changed pixels; and false negative (FN) is the number of inaccurately detected unchanged pixels.
3. Experiments
Two experiments are designed here to verify the superiority and performance of our proposed framework for Hete-CD. The first experiment aims to compare the proposed approach with state-of-the-art methods with four pairs of real HRSIs to verify the feasibility and advantages of the proposed approach. The second experiment focused on revealing the relationship between the number of initial samples and the detection accuracy of the proposed approach. The experiments are performed on four pairs of actual HRSIs. The detailed descriptions of the experiments are presented in the following section.
3.1. Dataset Description
Four pairs of HRSIs are used for the experiments. In
Figure 2, these images refer to water body change, building construction, floods, and wildfire change events. The image acquired before the occurrence of the change event is defined as a “pre-event image”. Meanwhile, the image acquired after the occurrence of the change event is defined as a “post-event image”. The details of each image pair are detailed as follows:
Dataset-1: This dataset contained different optical images acquired from various sources. The pre-event image was acquired by Landsat-5 in September 1995 and exhibited a size of pixels with 30 m/pixel. The post-event image was acquired in July 1996 and clipped from Google Earth; its size was pixels with 30 m/pixel. This type of pairwise HRSI was easily available. Here, these images were used to detect the expansion area of the Sarindia (Italy) Lake.
Dataset-2: This dataset contained a SAR pre-event image acquired with the Radarsat-2 satellite in June 2008 and an optical post-event image extracted from Google Earth in September 2012. The sizes of the HRSIs were and pixels with 8 m/pixel resolution. The change event was the building construction located in Shuguang Village, China.
Dataset-3: This dataset included SPOT Xs-ERS and SPOT images for the pre-event and post-event, respectively. The pre-event and post-event images were acquired in October 1999 and October 2000, before and after a flood over Gloucester, U.K. The size of these images was pixels with a 15 m/pixel resolution. The pre-event image and post-event image have one and three bands, respectively. In particular, the ERS image reflected the roughness of the ground before the flood, and the multispectral SPOT HRV image described the color of the ground during the flood. The detection task aimed at calculating the change areas by comparing the bitemporal heterogonous images.
Dataset-4: This dataset contained two images acquired by using different sensors (Landsat-5 TM and Landsat-8) over Bastrop County, Texas, USA, for a wildfire event on 4 September 2011. The size of the bi-temporal images was pixels and 30 m/pixel. The modality difference between the bi-temporal images lay in the pre-event image, which was acquired by Landsat-5 and composed of 4–3–2 bands, and the post-event image, which was obtained by Landsat-8 and composed of 5–4–3 bands.
Furthermore, the pre-processing operations for each dataset, including radiation correction, resampling, and co-registration, have been achieved by the owner of the datasets. Dataset-1 to Dataset-4 are open-accessible datasets widely used for evaluating the performance of change detection with heterogeneous remote sensing images, and the pre-processing operations have been conducted before release. Additional details, including the acquiring platform and the preprocessing steps for the datasets, can be found in reference [
20].
3.2. Experimental Setup
In the experiments, nine state-of-the-art change detection methods, including three traditional methods and six deep learning methods, were selected for comparison. The details are presented as follows:
- (i)
In the first part of the experiments, the three relatively new and highly cited related methods were as follows: The first method, named adaptive graph and structure cycle consistency (AGSCC) (
https://github.com/yulisun/AGSCC, accessed on 1 May 2023) [
45], focused on exploring the shared structural features of the bitemporal HRSIs. The explored shared structural features were comparable for change detection. The second method, named graph-based image regression and MRF segmentation method (GIR-MRF) (
https://github.com/yulisun/GIR-MRF, accessed on 1 May 2023) [
50], aimed at learning the shared features via graph-based image regression. The third method, called the sparse constrained adaptive structure consistency-based method (SCASC) (
https://github.com/yulisun/SCASC, accessed on 1 May 2023) [
42], attempted to improve the adaptive structural extraction efficiency for Hete-CD. These studies [
42,
45,
50] were typical in the field of change detection with HRSIs. Accordingly, these studies were adopted for comparison with our proposed framework. Based on the comparisons, the parameters of the selected methods [
42,
45,
50] were the same as those used in the original studies. Twelve unchanged samples (six pairs) and changed samples (six pairs) were randomly selected from the ground reference map for framework initialization in our proposed framework.
- (ii)
The second part of the experiments aimed at verifying the advantages and feasibility of the proposed framework while comparing it with some state-of-the-art deep learning methods. The first method, named fully convolutional Siamese difference (FC-Siam-diff) [
28], was an extension of UNet. The second method, named crosswalk detection network (CDNet) [
55], aimed at learning the change magnitude between the bitemporal images through a cross-convolution strategy. The experimental results based on four datasets clearly demonstrated the robustness and superiority of the proposed CDNet. The selected method, called feature difference convolutional neural network (FDCNN) [
26], conducted convolutions on the feature difference map and obtained the binary change detection map. A deeply supervised image fusion network (DSIFN) [
63] concentrated on exploring highly representative deep features of bi-temporal images through a fully convolutional two-stream architecture for LCCD with HRSIs. A cross-layer convolutional neural network (CLNet) was first proposed for LCCD with HRSIs to learn the correlation between the bi-temporal images at different features. The four experimental applications clearly demonstrated the superiority of the proposed approach [
27]. In addition, a multiscale fully convolutional network (MFCN) was constructed for the ground land cover change area with various shapes and sizes [
30]. The following parameters are set for each network: learning rate = 0.0001, batch size = 3, and epochs = 20. All the selected deep learning methods used the same training samples randomly clipped and extracted from the ground reference map to guarantee comparative fairness. Moreover, the quantity of training samples for the state-of-the-art deep learning methods is equal to the number of enhanced samples when the iteration of our proposed framework is terminated.
- (iii)
The ratio between the training samples, validation samples, and testing samples was about 2:1:7. The number of initial samples for each approach and dataset was 12 pairs. The initial samples for each dataset were randomly obtained based on the ground reference.
3.3. Results
The experimental results of the four pairs of HRSIs were obtained according to the above-mentioned parameter setting. The details are as follows:
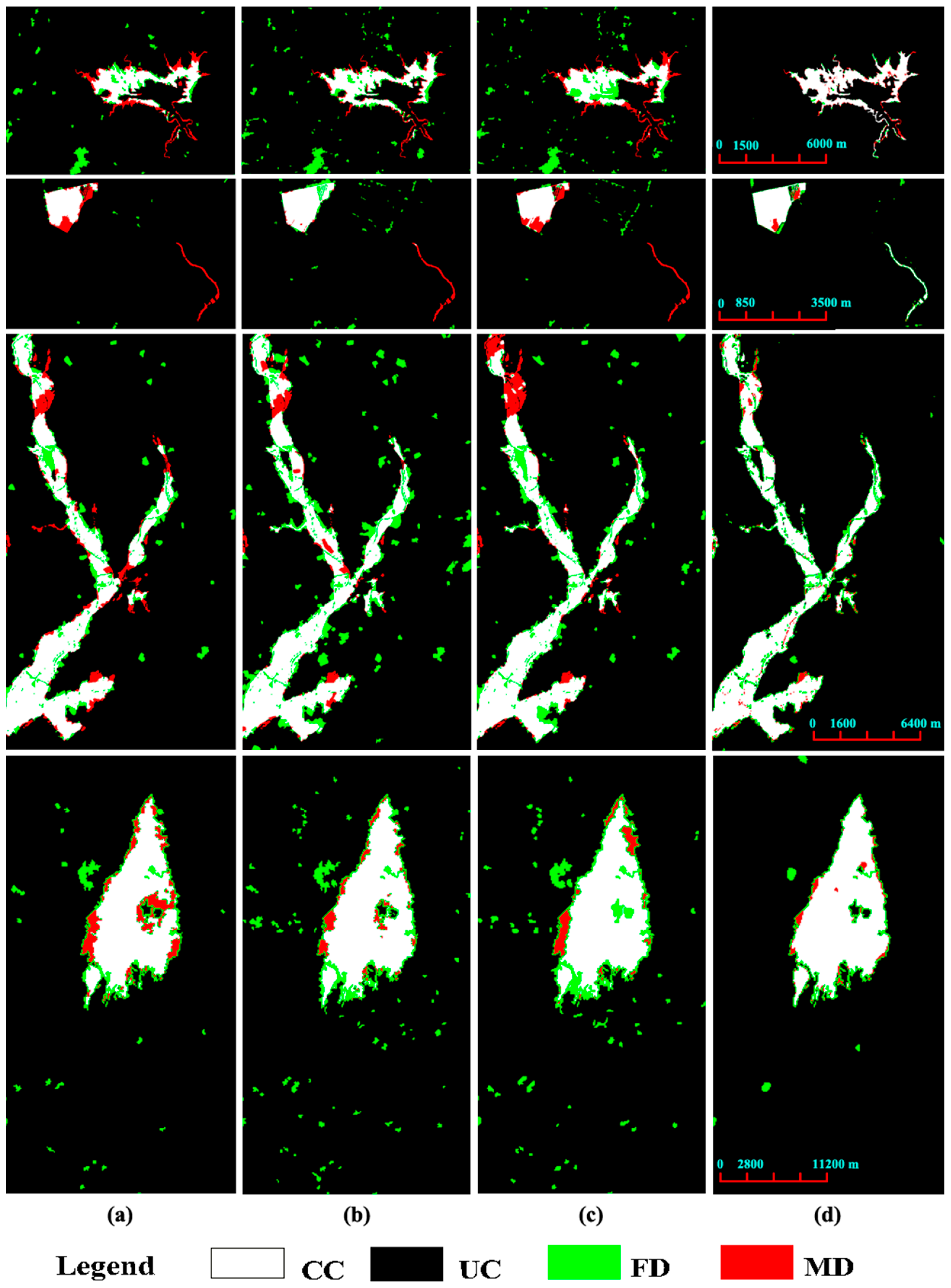
- (i)
Comparisons with traditional methods: The visual performance of AGSCC [
45], GIR-MRF [
50], and SCASC [
42] is presented in
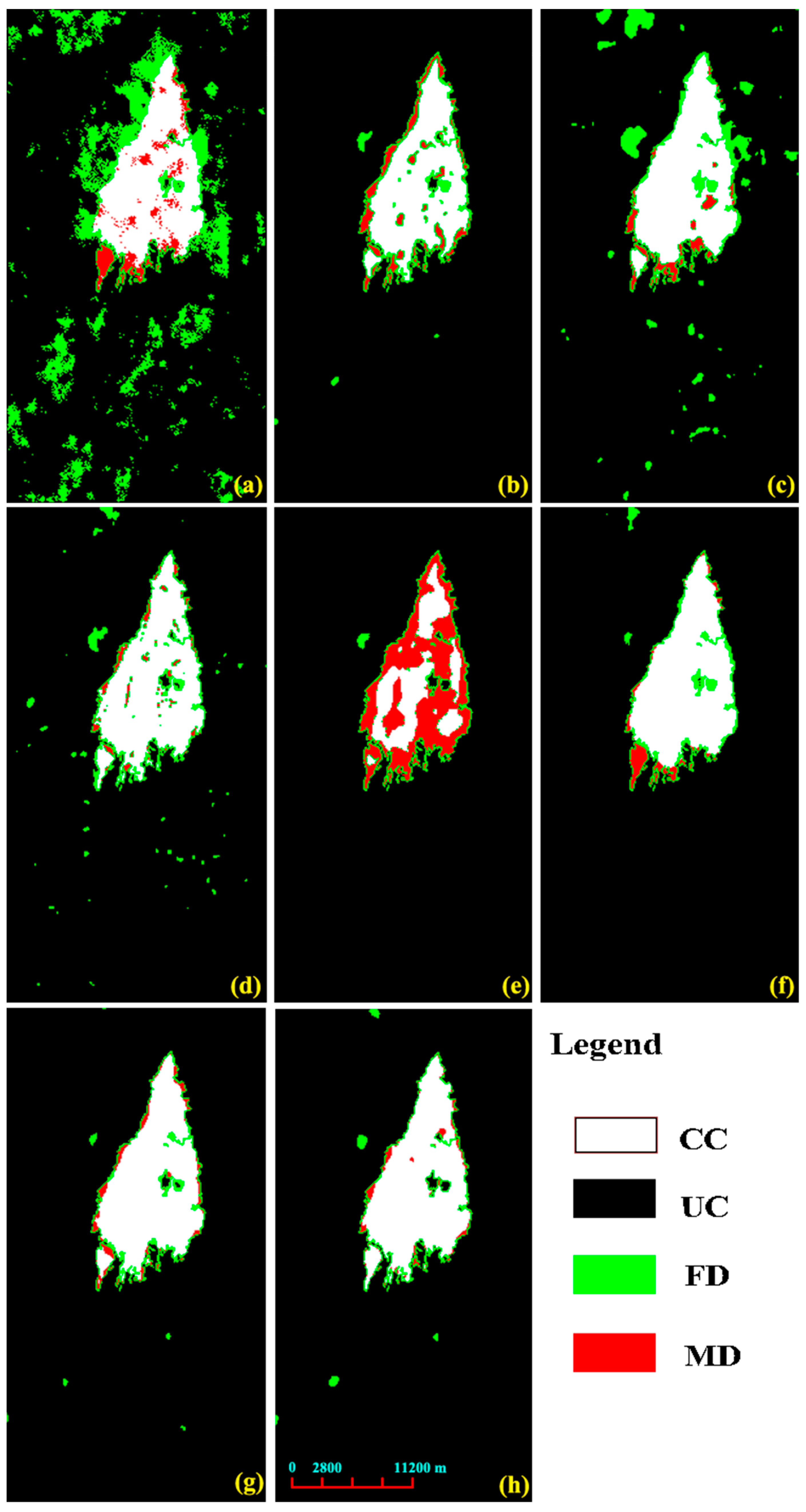
Figure 3a–c, respectively. In comparison with the results based on our proposed framework,
Figure 3d shows that our proposed framework achieved the best detection performance with the fewest false alarm (green) and missed alarm (red) pixels. The corresponding quantitative results in
Table 2 further supported the conclusion from the visual observation comparisons. For example, the proposed framework achieved 99.04%, 98.75%, 96.77%, and 97.92% in terms of OA for the four datasets. These values were the best among the results from AGSCC [
45], GIR-MRF [
50], SCASC [
42], and our proposed framework.
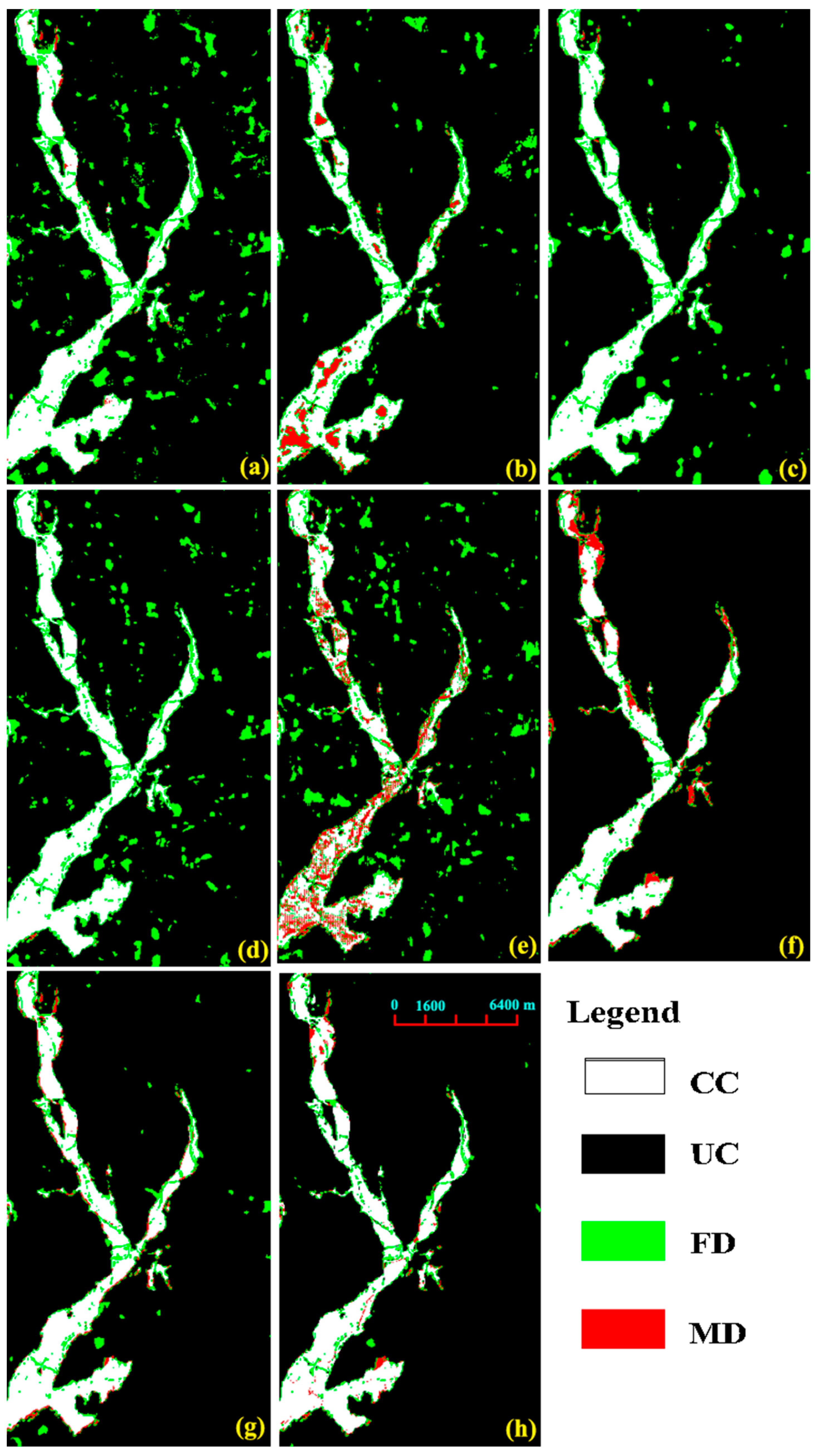
- (ii)
Comparisons with deep learning methods: We further verified the robustness of the proposed framework by comparing it with some state-of-the-art deep learning methods. The detection maps presented in
Figure 4,
Figure 5,
Figure 6 and
Figure 7 are acquired by using different deep-learning methods for the four datasets. These visual comparisons indicated that the proposed framework performed better with fewer false and missed alarms. During the removal of the sample-enhanced algorithm from the entire proposed framework, as denoted by “Proposed-” in
Table 3,
Table 4,
Table 5 and
Table 6, the improvement was achieved compared with that of the other approaches for the same datasets. For example, the proposed approach obtained the best OA = 99.04% and the based FA = 0.33%. In comparison with the results based on the proposed approach without the proposed sample enhancement approach, the improvement of the proposed approach coupled with the sample-enhanced algorithm was approximately 2.0% in terms of OA for Dataset-1. Multiscale information extraction and selective kernel attention in the promoted neural network were complementary to learning more accuracy in our proposed framework. The following quantitative comparisons in
Table 3,
Table 4,
Table 5 and
Table 6 further supported the visually observed conclusion.
3.4. Discussion
The novelty of the proposed approach lies in promoting a novel way to improve the change detection performance of LCCD with HRSIs. Accordingly, a novel sample augmentation algorithm for change detection with HRSIs was proposed to achieve this objective. The proposed approach allowed us to obtain a satisfactory change detection map with a small initial training sample set for practical applications. Here, two aspects of the training samples for the proposed framework are discussed and analyzed to promote further use and understanding of this framework, as follows:
- (i)
Relationship between the initial and the final samples: According to
Section 2, the proposed framework was initialized with a small number of training samples, which were iteratively amplified at every iteration. Accordingly, observing the relationship between the initial and final samples helps us understand the balancing ability for unchanged and changed classes in our proposed framework.
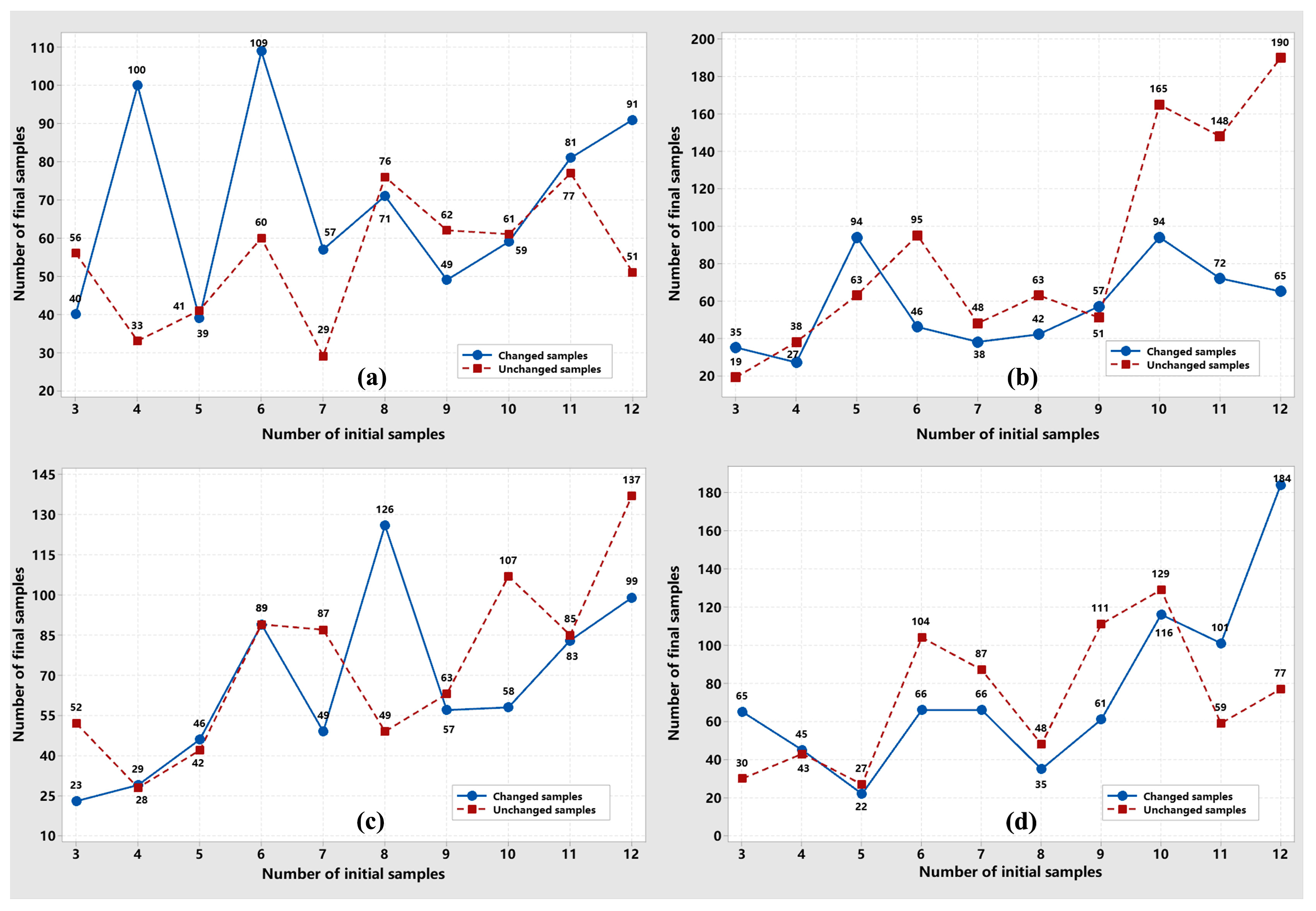
Figure 8 shows that the quantity of samples for the changed and unchanged classes is equal for initialization. When the iteration of the proposed framework was terminated, the number of samples for the unchanged and changed classes was automatically adjusted to be different because the size of the area was distinct in an image scene. Detecting them with an unequal sample is beneficial for balancing their detection accuracies.
Figure 8 also demonstrates that the relationship between the initial and final samples is nonlinear. For example, for the unchanged and changed samples of Dataset-1, when the initial samples for the unchanged class increased from three to four pairs, its final samples decreased from 56 pairs to 33 pairs. Moreover, different datasets exhibit the relationship between the initial and final samples for our proposed framework. Therefore, determining the suitable quantity of samples for initializing the proposed framework may involve conducting trial-and-error experiments in practical applications.
- (ii)
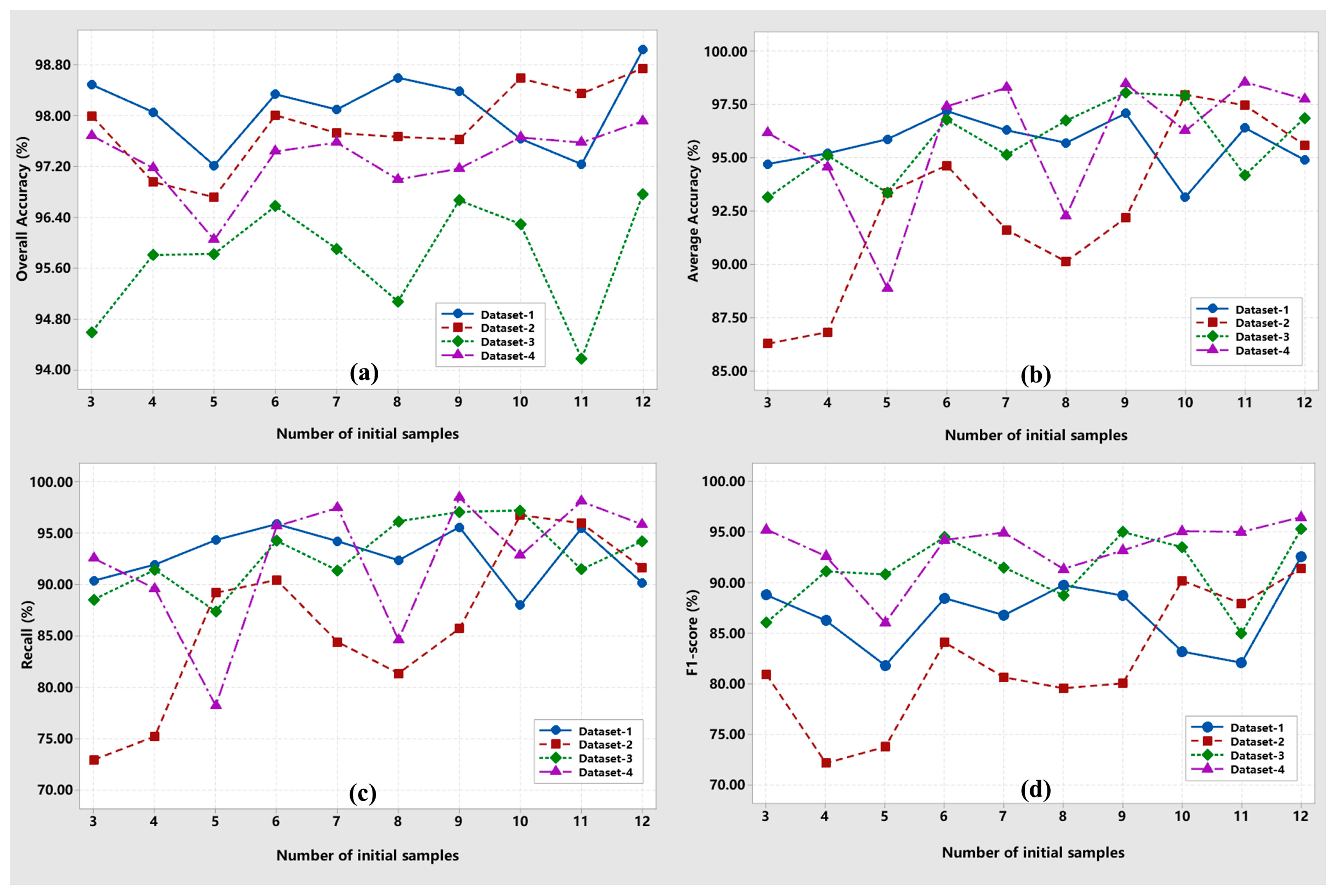
Relationship between the initial samples and detection accuracies: The observation results indicated that the detection accuracy initially decreased with the increment of the initial samples for some datasets (
Figure 9). Moreover, the accuracy increased and appeared to be a state with a small variation. For example, the OA for Dataset-2 and -4 decreased when the initial samples increased from three pairs to four pairs, and then it increased and vibrated within [96.72%, 98.75%] and [96.05%, 97.92%], respectively. Some explored samples may be marked with missed labels, which negatively affected the learning performance. However, the sample with missed labels becomes the minority in the total enhanced sample set with the increment of the initial training samples. Consequently, an uncertain relationship may cause detection accuracy variation when training our proposed framework with the sample set. The observation illustrated in
Figure 9 indicates the proposed approach can explore samples. However, the detection accuracy did not always linearly improve with the number of samples. This phenomenon is due to the distinct variability, spectral homogeneity, and uncertainty of each dataset.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}